Padronização total
Preparei este material para o meu discurso na conferência e perguntei ao nosso diretor técnico qual era a principal característica do Kubernetes para nossa organização. Ele respondeu:
Os próprios desenvolvedores não entendem quanto trabalho extra fizeram.
Aparentemente, ele foi inspirado pelo livro recentemente lido “Factfulness” - é difícil perceber mudanças menores e contínuas para melhor, e constantemente perdemos de vista nosso progresso.
Mas a mudança para o Kubernetes definitivamente não é insignificante.

Quase 30 de nossas equipes executam todas ou algumas das cargas de trabalho nos clusters. Cerca de 70% do nosso tráfego HTTP é gerado por aplicativos em clusters Kubernetes. Essa é provavelmente a maior convergência de tecnologias desde que entrei na empresa depois que a Forward comprou o uSwitch em 2010, quando mudamos de .NET e servidores físicos para a AWS e de um sistema monolítico para microsserviços .
E tudo aconteceu muito rapidamente. No final de 2017, todas as equipes usavam sua infraestrutura da AWS. Eles configuram balanceadores de carga, instâncias do EC2, atualizações de cluster do ECS e coisas assim. Pouco mais de um ano se passou e tudo mudou.
Passamos um tempo mínimo convergindo e, como resultado, o Kubernetes nos ajudou a resolver problemas prementes - nossa nuvem estava se expandindo, a organização estava se tornando mais complicada e dificilmente podíamos inserir novas pessoas nas equipes. Não mudamos a organização para usar o Kubernetes. Pelo contrário - usamos o Kubernetes para mudar a organização.
Os desenvolvedores podem não ter notado grandes mudanças, mas os dados falam por si. Mais sobre isso mais tarde.
Muitos anos atrás, eu estava em uma conferência de Clojure e ouvi uma palestra de Michael Nygard sobre arquitetura que não pode ser levada ao seu estado final . Ele abriu meus olhos. Um sistema limpo e organizado parece caricaturado quando compara as lojas de TV com os produtos de cozinha e a arquitetura de software em larga escala - o sistema existente parece uma faca estúpida, e algum tipo de mingau sai em vez de fatias iguais. Sem uma faca nova, não há nada para pensar em salada.
É sobre como as organizações adoram projetos de três anos: o primeiro ano é de desenvolvimento e preparação, o segundo ano é de implementação e o terceiro é retorno. Em uma palestra, ele diz que esses projetos geralmente são realizados de forma contínua e raramente chegam ao final do segundo ano (geralmente devido à aquisição por outra empresa e a uma mudança de direção e estratégia); portanto, a arquitetura usual é
estratificação da mudança em alguma aparência de estabilidade.
E o uSwitch é um ótimo exemplo.
Mudamos para a AWS por várias razões - nosso sistema não suportava picos de carga e a organização era prejudicada por um sistema muito rígido e equipes estreitamente relacionadas, formadas para projetos específicos e divididas por especialização.
Não íamos parar de tudo, transferir todos os sistemas e começar de novo. Criamos novos serviços com proxy por meio do balanceador de carga existente e gradualmente sufocamos o aplicativo antigo . Queríamos mostrar imediatamente o retorno e, na primeira semana, realizamos testes A / B da primeira versão do novo serviço em produção. Como resultado, pegamos produtos de longo prazo e começamos a formar equipes para desenvolvedores, designers, analistas, etc. E vimos o resultado imediatamente. Em 2010, isso pareceu uma verdadeira revolução.
Ano após ano, adicionamos novas equipes, serviços e aplicativos e gradualmente "estrangulamos" o sistema monolítico. As equipes progrediram rapidamente - agora trabalhavam independentemente e consistiam em especialistas em todos os campos necessários. Minimizamos as interações da equipe para lançamentos de produtos. Alocamos vários comandos apenas para a configuração do balanceador de carga.
As próprias equipes escolheram métodos, ferramentas e linguagens de desenvolvimento. Estabelecemos uma tarefa para eles, e eles mesmos encontraram uma solução, porque eram os melhores versados no assunto. Com a AWS, essas alterações se tornaram mais fáceis.
Intuitivamente, seguimos os princípios de programação - as equipes que são pouco conectadas entre si se comunicam com menos frequência e não precisamos gastar recursos preciosos na coordenação de seu trabalho. Tudo isso é ótimo descrito no livro recentemente publicado Accelerate .
Como resultado, como Michael Nygard descreveu, obtivemos um sistema de várias camadas de mudanças - alguns sistemas foram automatizados com Puppet, outros com Terraform, em algum lugar que usamos ECS, em algum lugar EC2.
Em 2012, estávamos orgulhosos de nossa arquitetura, que poderia ser facilmente alterada para experimentar , encontrar soluções de sucesso e desenvolvê-las.
Mas em 2017, percebemos que muita coisa mudou.
Agora, a AWS é muito mais complexa do que em 2010. Ela oferece várias opções e recursos - mas não sem consequências. Hoje, qualquer equipe que trabalha com o EC2 precisa escolher uma VPC, configuração de rede e muito mais.
Experimentamos isso por conta própria - as equipes começaram a reclamar que estavam gastando cada vez mais tempo na manutenção da infraestrutura, por exemplo, atualizando instâncias em clusters AWS ECS , máquinas EC2, alternando de balanceadores ELB para ALB, etc.
Em meados de 2017, em um evento corporativo, pedi a todos que padronizassem seu trabalho para melhorar a qualidade geral dos sistemas. Eu usei a metáfora do iceberg hackneyed para mostrar como criamos e mantemos o software:

Eu disse que a maioria das equipes da nossa empresa deve criar serviços ou produtos e se concentrar na solução de problemas, código de aplicativos, plataformas e bibliotecas, etc. Nessa ordem. Muito trabalho permanece debaixo d'água - integração de toras, aumento da observabilidade, gerenciamento de segredos etc.
Naquele momento, cada equipe de desenvolvedores de aplicativos lidou com quase todo o iceberg e tomou todas as decisões por si só - escolhendo a linguagem, o ambiente de desenvolvimento, a ferramenta de biblioteca e métricas, o sistema operacional, o tipo de instância e o armazenamento.
Na base da pirâmide, tínhamos a infraestrutura do Amazon Web Services. Mas nem todos os serviços da AWS são iguais. Eles possuem um BaaS (back-end como serviço) , por exemplo, para autenticação e armazenamento de dados. E existem outros serviços de nível relativamente baixo, como o EC2. Eu queria estudar os dados e entender que as equipes têm motivos para reclamar e realmente gastam mais tempo trabalhando com serviços de baixo nível e tomam muitas das decisões não mais importantes.
Dividi os serviços em categorias, usando o CloudTrail, coletei todas as estatísticas disponíveis e depois usei o BigQuery , Athena e ggplot2 para ver como a situação dos desenvolvedores mudou recentemente. Crescimento para serviços como RDS, Redshift etc., consideramos desejável (e esperado) e crescimento para EC2, CloudFormation etc. - pelo contrário.

Cada ponto do diagrama mostra os percentis 90 (vermelho), 80 (verde) e 50 (azul) para o número de serviços de baixo nível que nosso pessoal utilizava toda semana por um determinado período. Eu adicionei linhas de suavização para mostrar a tendência.
Embora tenhamos como objetivo abstrações de alto nível ao implantar software, por exemplo, usando contêineres e Amazon ECS , nossos desenvolvedores usavam regularmente cada vez mais serviços da AWS e não desconsideravam suficientemente as dificuldades de gerenciar sistemas. Em dois anos, o número de serviços dobrou para 50% dos funcionários e quase triplicou para 20%.
Isso limitou o crescimento de nossa empresa. As equipes buscavam autonomia, mas como contratar novas pessoas? Precisávamos de fortes desenvolvedores de aplicativos e produtos e conhecimento do sistema AWS, cada vez mais sofisticado.
Queríamos expandir nossas equipes e, ao mesmo tempo, preservar os princípios com os quais fomos bem-sucedidos: autonomia, coordenação mínima e infraestrutura de autoatendimento.
Com o Kubernetes, conseguimos isso com abstrações focadas em aplicativos e com a capacidade de manter e configurar clusters com o mínimo de coordenação da equipe.
Abstrações focadas em aplicativos
Os conceitos do Kubernetes são fáceis de combinar com o idioma que o desenvolvedor do aplicativo usa. Suponha que você esteja gerenciando versões de aplicativos como uma implantação . Você pode executar várias réplicas atrás do serviço e mapeá-las para HTTP através do Ingress . E através dos recursos do usuário, você pode expandir e especializar esse idioma, dependendo do que você precisa.
As equipes trabalham com mais eficiência com essas abstrações. Basicamente, este exemplo tem tudo o que você precisa para implantar e executar um aplicativo Web. O resto é Kubernetes.
Na foto com o iceberg, esses conceitos estão no nível da água e combinam as tarefas do desenvolvedor de cima com a plataforma abaixo. A equipe de gerenciamento de cluster pode tomar decisões insignificantes e de baixo nível (sobre o gerenciamento de métricas, logs etc.) e, ao mesmo tempo, falar o mesmo idioma com os desenvolvedores acima da água.
Em 2010, o uSwitch possuía equipes tradicionais para atender a um sistema monolítico e, mais recentemente, tínhamos um departamento de TI que gerenciava parcialmente nossa conta da AWS. Parece-me que a falta de conceitos comuns dificultou seriamente o trabalho dessa equipe.
Tente dizer algo útil se você tiver apenas instâncias do EC2 em seu vocabulário, balanceadores de carga e sub-redes. Era difícil ou mesmo impossível descrever a essência do aplicativo. Pode ser um pacote Debian, implantação através do Capistrano e assim por diante. Não foi possível descrever o aplicativo em um idioma comum a todos.
No início dos anos 2000, trabalhei na ThoughtWorks em Londres. Na entrevista, fui aconselhado a ler o Projeto Orientado a Problemas de Eric Evans. Comprei um livro a caminho de casa e comecei a ler no trem. Desde então, lembro-me dela em quase todos os projetos e sistemas.
Um dos principais conceitos do livro é um idioma único no qual diferentes equipes se comunicam. O Kubernetes apenas fornece uma linguagem unificada para desenvolvedores e equipes de manutenção de infraestrutura, e essa é uma de suas principais vantagens. Além disso, ele pode ser expandido e complementado com outras áreas e linhas de negócios.
A comunicação em um idioma comum é mais produtiva, mas ainda precisamos limitar a interação entre as equipes o máximo possível.
Mínimo necessário de interação
Os autores do Accelerate destacam as características de uma arquitetura pouco acoplada à qual as equipes de TI trabalham com mais eficiência:
Em 2017, o sucesso da entrega contínua dependia de a equipe poder:
Altere seriamente a estrutura do seu sistema sem a permissão do gerenciamento.
Altere seriamente a estrutura do seu sistema, sem esperar que outras equipes mudem as deles e sem criar muito trabalho desnecessário para outras equipes.
Desempenhe suas tarefas sem comunicar ou coordenar seu trabalho com outras equipes.
Implante e libere um produto ou serviço sob demanda, independentemente de outros serviços associados a ele.
Faça a maioria dos testes sob demanda, sem um ambiente de teste integrado.
Precisávamos de clusters de multilocatário de software centralizado para todas as equipes, mas, ao mesmo tempo, queríamos manter essas características. Ainda não alcançamos o ideal, mas estamos tentando da melhor maneira possível:
- Temos vários clusters de trabalho e as próprias equipes escolhem onde executar o aplicativo. Ainda não usamos a federação (estamos aguardando o suporte da AWS), mas temos o Envoy para balanceamento de carga nos balanceadores do Ingress em diferentes clusters. Automatizamos a maioria dessas tarefas usando o pipeline de entrega contínua (temos o Drone ) e outros serviços da AWS.
- Todos os clusters têm o mesmo espaço para nome . Cerca de um para cada equipe.
- Controlamos o acesso aos namespaces por meio do RBAC (controle de acesso baseado em função). Para autenticação e autorização, usamos identidade corporativa no Active Directory.
- Os clusters são dimensionados automaticamente e fazemos o possível para otimizar o tempo de inicialização do nó. Ainda leva alguns minutos, mas, em geral, mesmo com grandes cargas de trabalho, fazemos sem coordenação.
- Os aplicativos são dimensionados automaticamente com base nas métricas no nível do aplicativo do Prometheus. As equipes de desenvolvimento controlam o dimensionamento automático de seus aplicativos por métricas de consulta por segundo, operações por segundo, etc. Graças ao dimensionamento automático do cluster, o sistema prepara os nós quando a demanda exceder os recursos do cluster atual.
- Escrevemos o Go com uma ferramenta de linha de comando chamada u que padroniza a autenticação de comandos no Kubernetes, usa o Vault , solicitações de credenciais temporárias da AWS e assim por diante.
Não tenho certeza de que com o Kubernetes tenhamos mais autonomia, mas ele definitivamente permaneceu em um nível alto e, ao mesmo tempo, nos livramos de alguns problemas.
A mudança para o Kubernetes foi rápida. O diagrama mostra o número total de espaços para nome (aproximadamente igual ao número de comandos) em nossos clusters de trabalho. O primeiro apareceu em fevereiro de 2017.
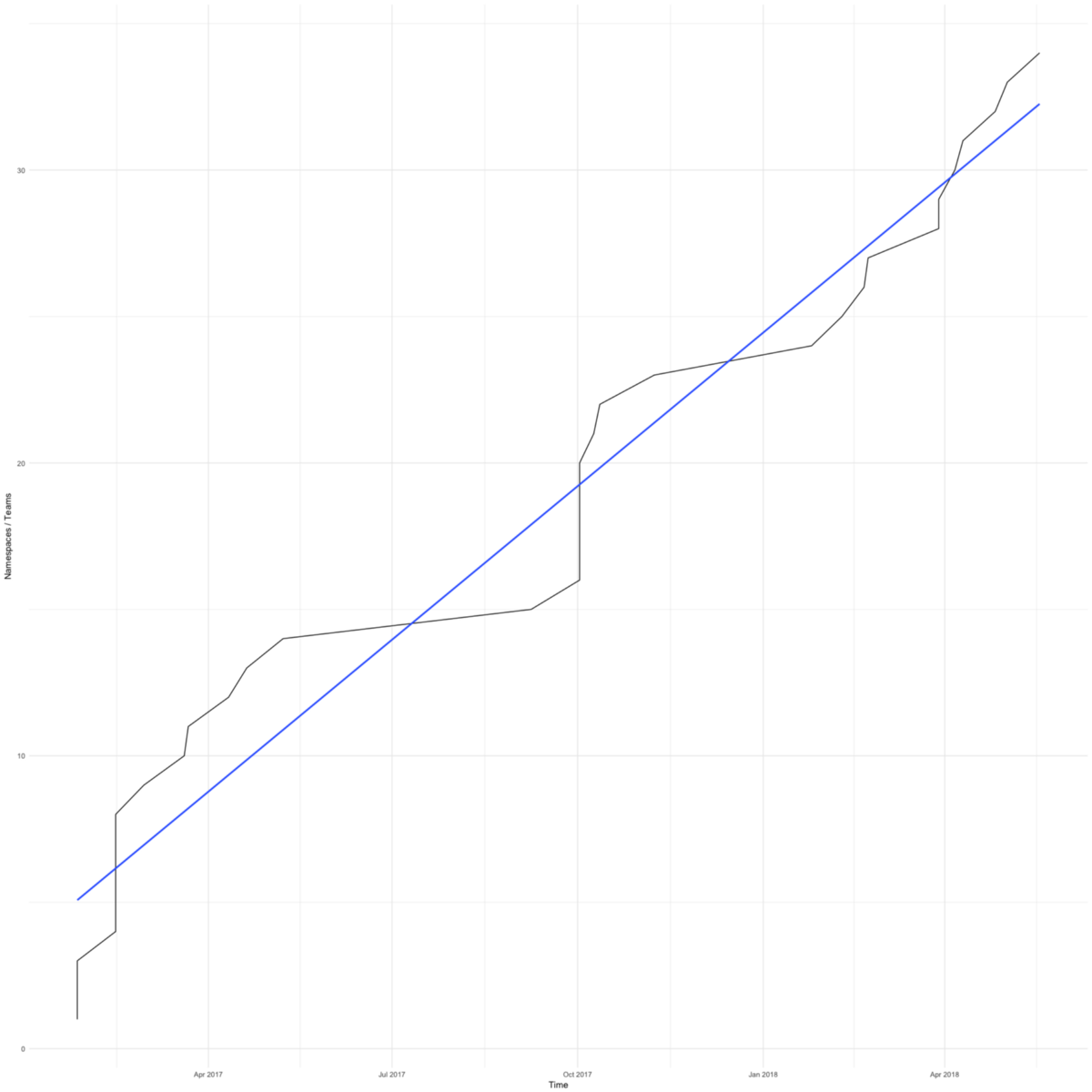
Tínhamos motivos para nos apressar - queríamos salvar as pequenas equipes focadas em seus produtos das preocupações com a infraestrutura.
A primeira equipe concordou em mudar para o Kubernetes quando o servidor de aplicativos ficou sem espaço devido a configurações incorretas de rotação do log. A transição levou apenas alguns dias e eles voltaram aos negócios.
Recentemente, as equipes mudaram para o Kubetnetes para obter ferramentas aprimoradas. Os clusters Kubernetes simplificam a integração com o Hashicorp Vault , o Google Cloud Trace e ferramentas semelhantes. Todas as nossas equipes obtêm recursos ainda mais eficazes.
Eu já mostrei um gráfico com percentis do número de serviços que nossos funcionários usavam todas as semanas entre o final de 2014 e 2017. E aqui está uma continuação deste diagrama até hoje.
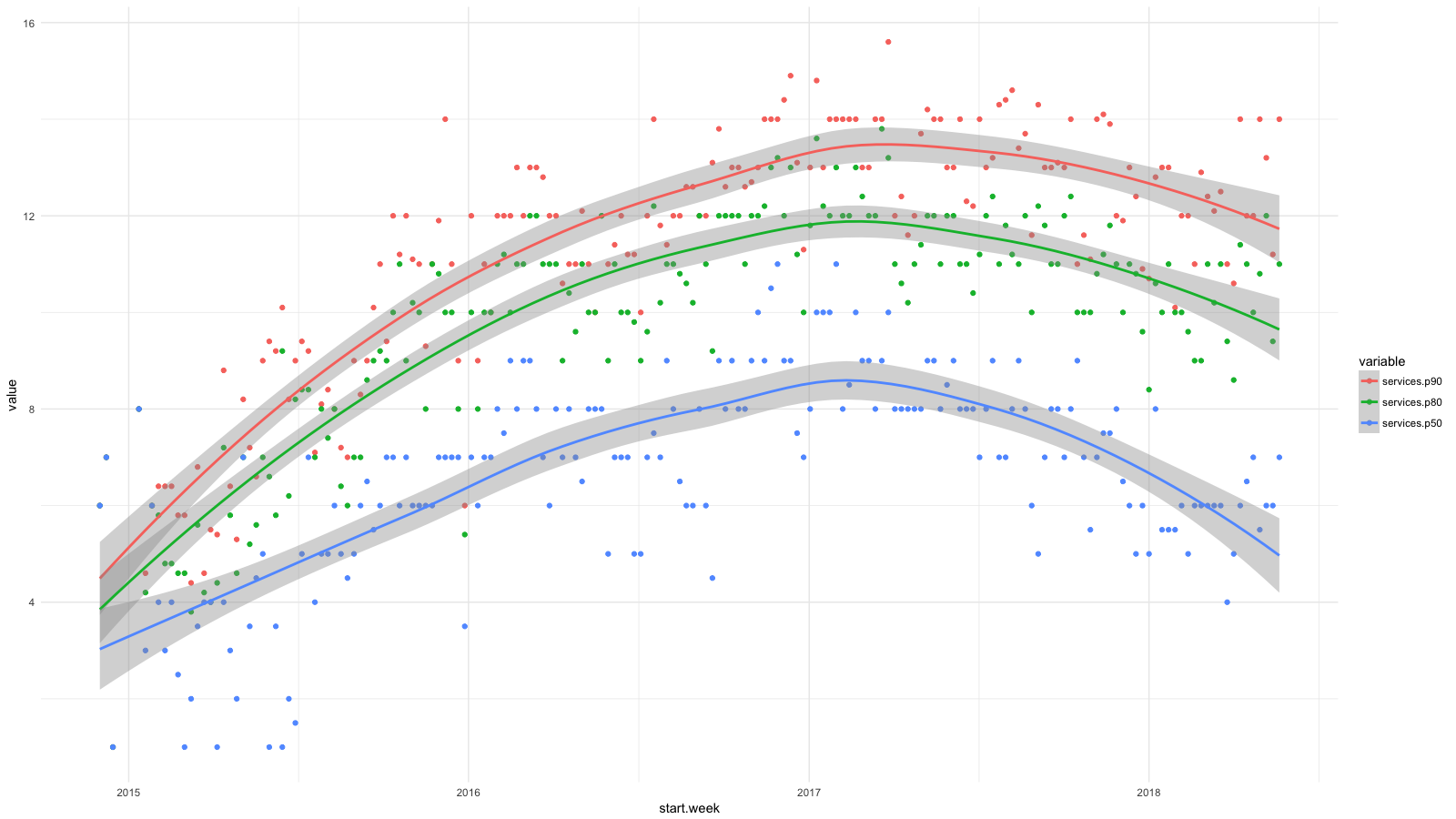
Avançamos no gerenciamento da complexa estrutura da AWS. Fico feliz que agora metade dos funcionários esteja fazendo a mesma coisa que no início de 2015. Temos 4-6 funcionários na equipe de computação em nuvem, algo em torno de 10% do número total - não é de surpreender que o percentil 90 quase não tenha mudado. Mas espero progredir aqui também.
Por fim, falarei sobre como nosso ciclo de desenvolvimento mudou e relembrarei novamente o livro Accelerate, lido recentemente.
O livro menciona duas métricas de desenvolvimento enxuto: lead time e tamanho do pacote. O lead time é considerado desde a solicitação até a entrega da solução finalizada. Tamanho do pacote é a quantidade de trabalho. Quanto menor o tamanho da embalagem, mais eficiente é o trabalho:
Quanto menor o pacote, menor o ciclo de produção, menor variabilidade do processo, menor risco, despesa e custo, obtemos feedback mais rapidamente, trabalhamos com mais eficiência, temos mais motivação, tentamos finalizar mais rapidamente e adiar a entrega com menos frequência.
O livro sugere medir o tamanho dos pacotes pela frequência de implantação - quanto mais freqüentemente a implantação, menores os pacotes.
Temos dados para algumas implantações. Os dados não são totalmente precisos - algumas equipes enviam releases diretamente para a ramificação principal do repositório, outras usam outros mecanismos. Isso não inclui todos os aplicativos, mas os dados por 12 meses podem ser considerados indicativos.
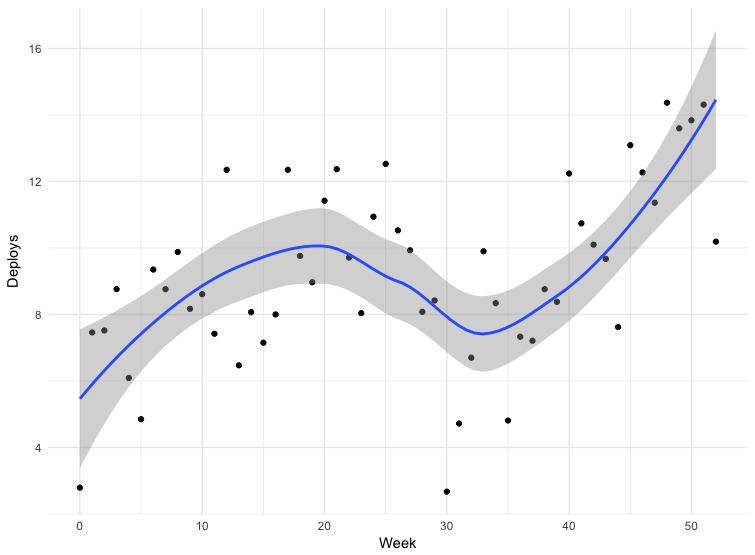
O fracasso na trigésima semana é o Natal. Quanto ao resto, vemos que a frequência de implantação aumenta, o que significa que o tamanho do pacote diminui. De março a maio de 2018, a frequência de lançamentos quase dobrou e, recentemente, às vezes fazemos mais de cem edições por dia.
Mudar para o Kubernetes é apenas parte de nossa estratégia de padronizar, automatizar e aprimorar ferramentas. Provavelmente, todos esses fatores influenciaram a frequência dos lançamentos.
O Accelerate também fala sobre o relacionamento entre a frequência de implantação e o número de funcionários e a rapidez com que uma empresa pode trabalhar se a equipe aumentar. Os autores enfatizam as limitações da arquitetura e equipes relacionadas:
Tradicionalmente, acredita-se que expandir uma equipe aumenta a produtividade geral, mas diminui a produtividade de desenvolvedores individuais.
Se coletarmos os mesmos dados sobre a frequência das implantações e fizermos um diagrama da dependência do número de usuários, podemos ver que podemos aumentar a frequência das liberações, mesmo se tivermos mais pessoas.

No começo do artigo, mencionei o livro Factfulness (que inspirou nosso CTO). A transição para o Kubernetes se tornou para nossos desenvolvedores a convergência mais significativa e rápida da tecnologia. Nós avançamos em pequenos passos, e é fácil não perceber o quanto tudo mudou para melhor. É bom que tenhamos dados, e eles mostram que alcançamos o que queremos - nosso pessoal está envolvido em seu produto e toma decisões importantes em seu campo.
Costumava ser bom para nós. Tínhamos microsserviços, AWS, equipes bem estabelecidas de produtos, desenvolvedores responsáveis por seus serviços de produção, equipes e arquitetura fracamente acopladas. Eu falei sobre isso no relatório “Nossa Era da Iluminação” (“Nossa Era da Iluminação”) em uma conferência em 2012. Mas não há limite para a perfeição.
No final, quero citar outro livro - Scale . Eu o iniciei recentemente, e há um fragmento interessante sobre o consumo de energia em sistemas complexos:
Para manter a ordem e a estrutura em um sistema em desenvolvimento, é necessário um influxo constante de energia e isso cria desordem. Portanto, para manter a vida, precisamos comer o tempo todo para derrotar a inevitável entropia.
Lutamos contra a entropia fornecendo mais energia para crescimento, inovação, manutenção e reparo, o que se torna mais difícil à medida que o sistema envelhece, e essa batalha é a base de qualquer discussão séria sobre envelhecimento, mortalidade, sustentabilidade e auto-suficiência de qualquer sistema, seja um organismo vivo , empresa ou sociedade.
Eu acho que você pode adicionar sistemas de TI aqui. Espero que nossos últimos esforços mantenham a entropia por um tempo.