Trabalho como desenvolvedor no
hh.ru e quero ir para datasines, mas até agora não há habilidades suficientes. Portanto, no meu tempo livre, estudo aprendizado de máquina e tento resolver problemas práticos dessa área. Recentemente, eles me deram a tarefa de agrupar nossos currículos. O post será sobre como eu o resolvi usando o cluster hierárquico aglomerativo. Se você não quiser ler, mas o resultado for interessante, poderá ver a
demonstração imediatamente.

Antecedentes
O mercado de trabalho está em constante dinâmica, novas profissões estão surgindo, outras estão desaparecendo e eu quero ter uma categorização relevante dos currículos. O catálogo de áreas profissionais e especializações no hh.ru está desatualizado há muito tempo: muito está ligado a ele, portanto elas não fazem alterações há muito tempo. Seria útil aprender a editar sem problemas essas categorias. Estou tentando identificar automaticamente essas categorias. Espero que no futuro isso ajude a resolver o problema.
Sobre a abordagem escolhida e sobre cluster
Ao agrupar, entenderei a combinação de objetos com os recursos mais semelhantes em um grupo. No meu caso, sob o objeto é considerado um currículo, e sob os signos do objeto estão os dados resumidos: por exemplo, a frequência da palavra "gerente" no currículo ou o tamanho do salário. A similaridade dos objetos é determinada por uma métrica pré-selecionada. Por enquanto, você pode pensar nisso como uma caixa preta que recebe dois objetos na entrada e a saída produz um número que reflete, por exemplo, a distância entre objetos no espaço vetorial: quanto menor a distância, mais semelhantes os objetos são.
A abordagem que usei pode ser chamada de cluster hierárquico aglomerativo ascendente. O resultado do agrupamento é uma árvore binária, onde nas folhas existem elementos individuais e a raiz da árvore é uma coleção de todos os elementos. É chamado ascendente porque o agrupamento começa no nível mais baixo da árvore, com folhas, onde cada elemento individual é considerado como um agrupamento.

Em seguida, você precisa encontrar os dois clusters mais próximos e mesclá-los em um novo cluster. Este procedimento deve ser repetido até que exista apenas um cluster com todos os objetos dentro. Quando os clusters são combinados, a distância entre eles é registrada. No futuro, essas distâncias podem ser usadas para determinar o local em que essas distâncias são grandes o suficiente para considerar os clusters selecionados como separados.
A maioria dos métodos de clustering supõe que o número de clusters seja conhecido antecipadamente ou tenta isolar clusters independentemente, dependendo do algoritmo e dos parâmetros desse algoritmo. A vantagem do armazenamento em cluster hierárquico é que você pode tentar determinar o número necessário de clusters examinando as propriedades da árvore resultante, por exemplo, selecionar subárvores com diferentes distâncias entre grupos diferentes. É conveniente trabalhar com a estrutura resultante para procurar clusters nela. Convenientemente, essa estrutura é construída uma vez e não precisa ser reconstruída ao procurar o número necessário de clusters.
Entre as deficiências, eu mencionaria que o algoritmo é bastante exigente na memória consumida. E, em vez de atribuir uma classe específica, gostaria de ter a probabilidade de que o currículo pertença à classe, a fim de olhar não para a especialidade mais próxima, mas para a totalidade.
Coleta e preparação de dados
A parte mais importante no trabalho com dados é a preparação, seleção e recuperação de atributos. É com base em quais sinais serão obtidos no final, dependerá se existem padrões neles, se esses padrões correspondem ao resultado esperado e se esse "resultado esperado" é possível. Antes de alimentar os dados para algum tipo de algoritmo de aprendizado de máquina, é necessário ter uma idéia de cada sinal, se existem lacunas, a que tipo o sinal pertence, quais propriedades esse tipo de sinal e qual a distribuição de valores nesse sinal. Também é muito importante escolher o algoritmo certo com o qual os dados disponíveis serão processados.
Tirei currículos atualizados nos últimos seis meses. Foram 2,7 milhões e, a partir dos dados do currículo, escolhi os sinais mais simples, nos quais, a meu ver, a participação no currículo deveria depender de um ou outro grupo. Olhando para o futuro, direi que o resultado do agrupamento de todos os currículos de uma só vez não me satisfez. Portanto, tivemos que dividir o currículo pelas 28 áreas profissionais existentes.
Para cada característica, plotei a distribuição para ter uma idéia de como os dados pareciam. Talvez devessem ser de alguma forma convertidos ou completamente abandonados.
Região Para que os valores desse recurso possam ser comparados, atribuai o número total de currículos que pertencem a essa região a cada região e peguei o logaritmo desse número para suavizar a diferença entre cidades muito grandes e pequenas.
Paul Convertido em um sinal binário.
Data de nascimento . Contado no número de meses. Nem todo mundo tem aniversário. Preenchi as lacunas com os valores médios da idade da especialização à qual esse currículo pertence.
Nível de escolaridade . Este é um sinal categórico. Eu o
codifiquei com um
LabelBinarizer .
O nome do item de linha . Eu dirigi pelo
TfidfVectorizer com ngram_range = (1,2), usei um
stemmer .
Salário . Traduziu todos os valores em rublos. Preenchi as lacunas da mesma forma que na minha idade. Tomou o logaritmo do valor.
Horário de trabalho . LabelBinarizer codificado.
Taxa de emprego . Eu o tornei binário, dividindo-o em duas partes: tempo integral e todo o resto.
Proficiência no idioma . Eu escolhi o top mais usado. Cada idioma é definido como um recurso separado. Os níveis de propriedade são correspondidos por números de 0 a 5.
Habilidades-chave . Eu dirigi através TfidfVectorizer. Como uma palavra final, montei um pequeno dicionário de habilidades gerais e palavras que, como me pareceu, não afetam a especialidade. Todas as palavras são passadas pelo radical. Cada habilidade principal pode consistir não apenas em uma palavra, mas também em várias. No caso de várias palavras na habilidade principal, classifiquei as palavras e também usei cada palavra como um atributo separado. Esse recurso só correu bem no campo profissional "Tecnologias da informação, Internet, Telecom", porque as pessoas geralmente indicam habilidades relevantes para sua especialidade. Em outras áreas profissionais, eu não o usei por causa da abundância nas habilidades de palavras gerais.
Especializações Defino cada uma das especializações especificadas pelo usuário como um atributo binário.
Experiência de trabalho . Tomou o logaritmo do número de meses + 1, porque existem pessoas sem experiência de trabalho.
Padronização
Como resultado, cada currículo começou a ser um vetor de sinais numéricos. O algoritmo de agrupamento selecionado é baseado no cálculo da distância entre objetos. Como determinar como cada recurso deve contribuir para essa distância? Por exemplo, há um sinal binário - 0 e 1 e outro sinal pode assumir muitos valores de 0 a 1000.
A padronização vem em socorro. Eu usei o
StandardScaler . Ele transforma cada característica de forma que seu valor médio seja zero e o desvio padrão da média seja um. Portanto, estamos tentando trazer todos os dados para a mesma distribuição - o padrão normal. Obviamente, está longe de ser um fato que os próprios dados tenham a natureza de uma distribuição normal. Essa é apenas uma das razões para criar gráficos da distribuição de seus parâmetros e ficar feliz por eles parecerem um gaussiano.
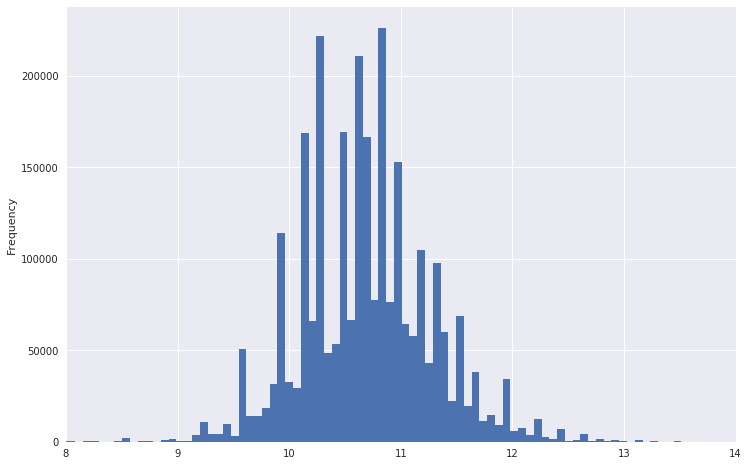
Assim, por exemplo, parecia um gráfico de distribuição salarial.

Pode-se ver que ele tem uma cauda muito pesada. Para tornar a distribuição mais normal, você pode obter o logaritmo desses dados. Ao mesmo tempo, as emissões não serão tão fortes.
Downgrade
Agora faz sentido transferir os dados para um espaço de menor dimensão, para que no futuro o algoritmo de agrupamento possa digeri-los em um tempo e memória aceitáveis. Eu usei o
TruncatedSVD ,
porque ele sabe trabalhar com matrizes esparsas e, na saída, fornece a matriz densa usual, necessária para trabalhos futuros. A propósito, o TruncatedSVD também precisa enviar dados padronizados.
No mesmo estágio, vale a pena tentar visualizar o conjunto de dados resultante, convertendo-o em espaço bidimensional usando
t-SNE . Este é um passo muito importante. Se nenhuma estrutura estiver visível na imagem resultante ou, inversamente, essa estrutura parecer muito estranha, seus dados não terão a regularidade necessária ou um erro foi cometido em algum lugar.
Recebi muitas imagens muito suspeitas antes de tudo correr bem. Por exemplo, uma vez que havia uma imagem tão bonita:

O motivo dos worms resultantes foi obter identificadores de currículo no conjunto de dados. E aqui está algo mais semelhante à verdade:

Agrupamento
Se tudo estiver em ordem com os dados, você poderá iniciar o cluster. Eu usei o pacote de
cluster hierárquico do SciPy. Permite clustering usando o
método de ligação . Tentei todas as métricas de distância do cluster sugeridas no algoritmo. O melhor resultado foi dado pelo
método de Ward .
O principal problema que encontrei é o algoritmo de agrupamento que calcula a matriz de distância entre todos os elementos, o que significa uma dependência quadrática da memória do número de elementos. Para 2,7 milhões de currículos, não tive sucesso, porque A quantidade de memória necessária é de terabytes. Todos os cálculos foram realizados em um computador comum. Eu não tenho tanta memória RAM. Portanto, pareceu-me razoável que você possa primeiro combinar os currículos próximos, ocupar os centros dos grupos resultantes e já agrupá-los com o algoritmo desejado. Peguei o
MiniBatchKMeans , formei 30.000 clusters e os enviei para o cluster hierárquico. Funcionou, mas o resultado foi mais ou menos. Muitos dos grupos de currículo mais impressionantes se destacaram, mas o detalhamento não é suficiente para encontrar especializações em um bom nível.
Para melhorar a qualidade das especializações obtidas, quebrei os dados em campos profissionais. Descobriu conjuntos de dados de 400.000 currículos e menos. Nesse momento, ocorreu-me que agrupar uma amostra de dados é melhor do que usar dois algoritmos seguidos. Então, desisti do MiniBatchKMeans e peguei até 100.000 currículos para cada especialização, para que o método de ligação pudesse digeri-los. Como 32 Gb de RAM não era suficiente, aloquei 100 Gb adicionais para a troca. Como resultado, a ligação fornece uma matriz com as distâncias entre os clusters combinados em cada etapa e o número de elementos no cluster resultante.
Como uma métrica de controle de qualidade para comparar diferentes versões de conjuntos de dados e diferentes métodos para calcular a distância entre clusters, o algoritmo usou o coeficiente de correlação copenética obtido do
cophenet . Este coeficiente mostra quão bem o dendrograma resultante reflete a diferença de objetos entre si. Quanto mais próximo o valor da unidade, melhor.
Visualização
A melhor maneira de validar a qualidade do clustering era a visualização. O método
dendrograma desenha os dendrogramas resultantes nos quais você pode selecionar clusters por distância ou por nível na árvore:

O gráfico a seguir mostra a dependência da distância entre os clusters no número da etapa de iteração, na qual os dois clusters mais próximos são combinados em um novo. A linha verde mostra como a aceleração muda - a velocidade da distância entre os clusters que estão sendo unidos.
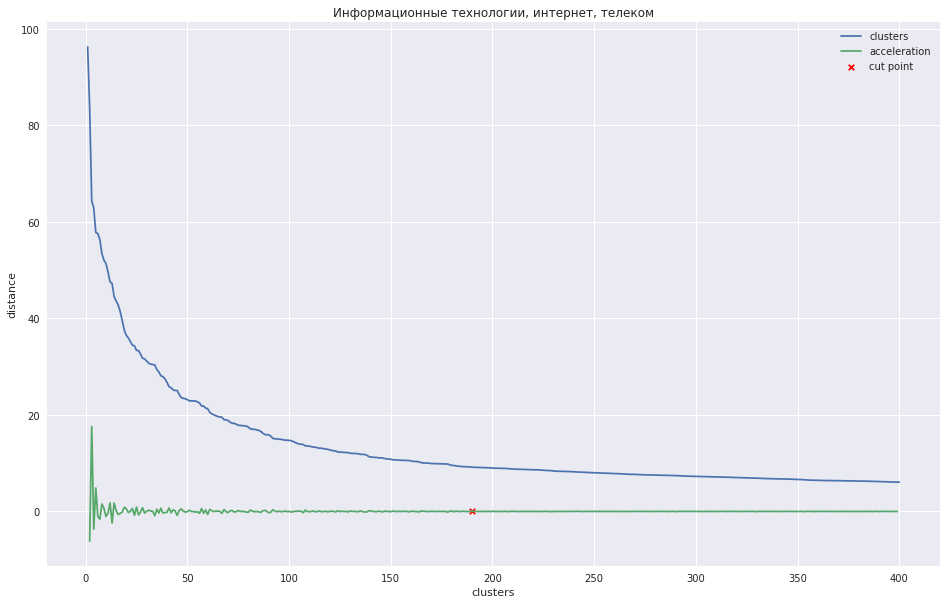
No caso de um pequeno número de clusters, pode-se tentar podar a árvore no ponto em que a aceleração é máxima, ou seja, a distância no momento em que os dois clusters foram combinados era ainda maior e já menor no próximo passo. No meu caso, tudo é diferente - eu tenho muitos clusters e sugeri que é melhor cortar o dendrograma no ponto em que a aceleração começa a diminuir mais monotonamente, ou seja, as distâncias entre os clusters nesse nível não indicam mais um grupo separado. No gráfico, esse local é aproximadamente no ponto em que a linha verde para de dançar.
Alguém poderia inventar algum tipo de método programático, mas acabou sendo mais rápido marcar esses locais com 28 mãos para 28 domínios profissionais e
passar o número desejado de clusters para o método
fcluster , que cortará a árvore no lugar certo.
Salvei os dados obtidos anteriormente do t-SNE e anotei os clusters resultantes neles. Parece muito bom:

Como resultado, criei uma interface da web na qual você pode ver o resumo de cada cluster, sua posição no gráfico e fornecer um nome significativo. Por conveniência, deduzi o título mais comum do currículo - ele geralmente caracteriza bem o nome do cluster.
Você pode ver o resultado do agrupamento
aqui .
Concluí por mim mesmo que o sistema estava funcionando. Embora a repartição em clusters seja imperfeita e alguns grupos sejam muito semelhantes entre si, mas alguns podem, pelo contrário, ser divididos em partes, mas as principais tendências do mercado de especialidades são claramente visíveis. Você também pode ver como novos grupos se formam. A descarga do currículo foi realizada no verão, de modo que os
motoristas, que queriam trabalhar na Copa do Mundo , se destacaram, por exemplo. Se você aprender a combinar clusters entre si, do lançamento ao lançamento, poderá observar como as principais áreas de especialização mudam ao longo do tempo. De fato, as idéias para melhorar a qualidade e o desenvolvimento ainda estão cheias. Se eu conseguir encontrar a motivação certa em mim, vou me aprofundar mais.
Materiais adicionais
Vídeo sobre cluster hierárquico aglomerativo do curso sobre a procura de uma estrutura em dados
Sobre escala e normalização de sinaisTutorial sobre cluster hierárquico da biblioteca SciPy, que eu tomei como base para minha tarefa
Comparação de diferentes tipos de armazenamento em
cluster usando as bibliotecas sklearn como exemplo
Pouco bônus. Eu pensei que é interessante para as pessoas como alguém trabalha em uma tarefa. Quero dizer que, em algumas questões, tive um bom desempenho enquanto fazia esse projeto. Tentei várias opções, estudei, ponderei como isso ou aquilo funciona. Em muitos lugares, a falta de uma boa base matemática foi compensada pela desenvoltura e um grande número de tentativas. E gostaria de compartilhar a
folha de notas sempre sofrida na qual tomei notas enquanto trabalhava na tarefa. As reflexões nele foram destinadas apenas a mim, existem muitas heresias e incompreensões, mas acho que isso é normal.
UPD: Postei laptops com
preparação de dados e código de
cluster . Não pretendia fazer o upload do código, desculpe pela qualidade.