
Com os testes para o código, tudo fica claro (bem, pelo menos o fato de que eles precisam ser escritos). Com os testes de configuração, tudo fica muito menos óbvio, começando com a própria existência. Alguém os escreve? Isso é importante? Isso é difícil? Que tipo de resultados podem ser alcançados com a ajuda deles?
Acontece que isso também é muito útil, começar a fazê-lo é muito simples e, ao mesmo tempo, existem muitas nuances no teste da configuração. Quais - pintados sob o corte com base na experiência prática.
O material é baseado na transcrição de um relatório de Ruslan cheremin Cheremin (desenvolvedor Java do Deutsche Bank). A seguir, fala em primeira pessoa.Meu nome é Ruslan, trabalho no Deutsche Bank. Começamos com isso:

Há muito texto, de longe parece russo. Mas isso não é verdade. Esta é uma linguagem muito antiga e perigosa. Fiz uma tradução para o russo simples:
- Todos os personagens são compostos
- Use com cuidado
- Funeral às suas próprias custas
Vou descrever brevemente o que vou falar hoje. Suponha que tenhamos um código:

Ou seja, inicialmente tivemos algum tipo de tarefa, escrevemos um código para resolvê-lo e, supostamente, ganha dinheiro. Se, por algum motivo, esse código não funcionar corretamente, ele resolve a tarefa errada e ganha o dinheiro errado. Os negócios não gostam desse tipo de dinheiro - eles parecem ruins nas demonstrações financeiras.
Portanto, para o nosso código importante, temos testes:

Geralmente lá. Agora, provavelmente, quase todo mundo tem. Os testes verificam se o código resolve o problema certo e gera o dinheiro certo. Mas o serviço não se limita ao código e, ao lado do código, há também uma configuração:

Pelo menos em quase todos os projetos em que participei, essa configuração era, de uma forma ou de outra. (Lembro-me apenas de alguns casos dos meus primeiros anos de interface do usuário, onde não havia arquivos de configuração, mas tudo foi configurado por meio da interface do usuário). Nesta configuração, existem portas, endereços e parâmetros de algoritmo.
Por que a configuração é importante para testar?
Aqui está o truque: erros na configuração prejudicam a execução do programa, não menos que erros no código. Eles também podem fazer com que o código execute a tarefa errada - e veja acima.
E encontrar erros na configuração é ainda mais difícil do que no código, pois a configuração geralmente não é compilada. Citei os arquivos de propriedades como exemplo, em geral existem opções diferentes (JSON, XML, alguém armazena no YAML), mas é importante que nada disso seja compilado e, portanto, não seja verificado. Se você acidentalmente selou um arquivo Java - provavelmente, ele simplesmente não passará na compilação. Um erro de digitação aleatório na propriedade não excitará ninguém, ele funcionará.
E o IDE também não destaca o erro na configuração, porque sabe apenas o mais primitivo sobre o formato (por exemplo) dos arquivos de propriedades: que deve haver uma chave e um valor e "igual", dois pontos ou espaço entre eles. Mas o fato de que o valor deve ser um número, uma porta de rede ou um endereço - o IDE não sabe de nada.
E mesmo se você testar o aplicativo em um UAT ou em um ambiente temporário, isso também não garante nada. Como a configuração, em regra, em cada ambiente é diferente, e no UAT você testou apenas a configuração do UAT.
Outra sutileza é que, mesmo na produção, os erros de configuração às vezes não aparecem imediatamente. Um serviço pode não iniciar - e este é um bom cenário. Mas ele pode começar e trabalhar por muito tempo - até o momento X, quando será necessário exatamente o parâmetro em que o erro. E aqui você descobre que um serviço que nem mudou muito recentemente parou de funcionar repentinamente.
Depois de tudo o que eu disse - parece que as configurações de teste devem ser um tópico importante. Mas, na prática, parece algo como isto:
Pelo menos foi esse o caso conosco - até um certo ponto. E uma das tarefas do meu relatório é parar de parecer assim também para você. Espero poder empurrar você para isso.
Três anos atrás, no nosso Deutsche Bank, na minha equipe, Andrei Satarin trabalhou como líder de controle de qualidade. Foi ele quem trouxe a ideia de testar configurações - ou seja, ele simplesmente fez e realizou o primeiro teste desse tipo. Seis meses atrás, no Heisenbug anterior, ele
falou sobre o teste da configuração como a vê. Eu recomendo que você olhe, porque lá ele deu uma visão ampla do problema: tanto do lado de artigos científicos quanto da experiência de grandes empresas que encontraram erros de configuração e suas conseqüências.
Meu relatório será mais restrito - sobre a experiência prática. Vou falar sobre quais problemas, como desenvolvedor, encontrei quando escrevi testes de configuração e como resolvi esses problemas. Minhas decisões podem não ser as melhores, não são as melhores práticas - esta é minha experiência pessoal, tentei não fazer generalizações amplas.
Descrição geral do relatório:
- “O que você pode fazer antes da segunda-feira à tarde”: exemplos simples e úteis.
- "Segunda-feira, dois anos depois": onde e como fazer melhor.
- Suporte para refatoração da configuração: como obter uma cobertura densa; modelo de configuração de software.
A primeira parte é motivacional: descreverei os testes mais simples com os quais tudo começou conosco. Haverá uma grande variedade de exemplos. Espero que pelo menos um deles ressoe com você, ou seja, você verá algum tipo de problema semelhante e sua solução.
Os testes em si na primeira parte são simples, até primitivos - do ponto de vista da engenharia, não há ciência de foguetes. Mas apenas o fato de que eles podem ser feitos rapidamente é especialmente valioso. Essa é uma "entrada fácil" nos testes de configuração e é importante porque existe uma barreira psicológica para a escrita desses testes. E quero mostrar que "você pode fazer isso": agora fizemos, funcionou bem para nós e, embora ninguém tenha morrido, vivemos há três anos.
A segunda parte é sobre o que fazer depois. Quando você escreveu muitos testes simples, surge a questão do suporte. Alguns deles começam a cair, você entende os erros que eles supostamente destacaram. Acontece que isso nem sempre é conveniente. E surge a questão de escrever testes mais complexos - afinal, você já cobriu casos simples, quero algo mais interessante. E aqui novamente não há práticas recomendadas, apenas descreverei algumas das soluções que funcionaram para nós.
A terceira parte é sobre como o teste pode suportar a refatoração de uma configuração bastante complexa e confusa. Novamente estudo de caso - como fizemos. Do meu ponto de vista, este é um exemplo de como o teste de configuração pode ser escalado para resolver tarefas maiores, e não apenas para corrigir pequenos orifícios.
Parte 1. "Você pode fazer assim"
Agora é difícil entender qual foi o primeiro teste de configuração conosco. Andrei está sentado no corredor, ele pode dizer que eu menti. Mas parece-me que tudo começou com isso:

A situação é a seguinte: temos n serviços no mesmo host, cada um deles eleva seu próprio servidor JMX em sua porta, exporta alguns JMXs de monitoramento. Portas para todos os serviços são configuradas no arquivo. Mas o arquivo ocupa várias páginas e existem muitas outras propriedades - geralmente acontece que as portas de diferentes serviços entram em conflito. É fácil cometer um erro. Então, tudo é trivial: alguns serviços não aumentam, depois não aumentam para os dependentes - os testadores ficam furiosos.
Este problema é resolvido em várias linhas. Esse teste, que (me parece) foi o primeiro, ficou assim:

Não é nada complicado: examinamos a pasta onde os arquivos de configuração estão localizados, carregamos, analisamos como propriedades, filtramos os valores cujo nome contém “jmx.port” e verificamos se todos os valores são únicos. Não é necessário nem mesmo converter valores em número inteiro. Presumivelmente, existem apenas portas.
Minha primeira reação quando vi isso foi confusa:
Primeira impressão: o que há nos meus belos testes de unidade? Por que entramos no sistema de arquivos?
E então a surpresa veio: "O que poderia ser isso?"
Estou falando disso porque parece haver algum tipo de barreira psicológica que dificulta a realização de tais testes. Três anos se passaram desde então, o projeto está cheio desses testes, mas muitas vezes vejo que meus colegas, encontrando um erro cometido na configuração, não escrevem testes nele. Para o código, todo mundo já está acostumado a escrever testes de regressão - para que o erro encontrado não seja mais reproduzido. Mas eles não fazem isso para configuração, algo está interferindo. Há algum tipo de barreira psicológica que precisa ser resolvida - é por isso que menciono uma reação para que você a reconheça de si mesma se ela aparecer.
O exemplo a seguir é quase o mesmo, mas ligeiramente modificado - removi todo o "jmx". Desta vez, verificamos todas as propriedades chamadas algo-lá-porta. Eles devem ser valores inteiros e ser uma porta de rede válida. O Matcher validNetworkPort () oculta nosso Matcher hamcrest personalizado, que verifica se o valor está acima do intervalo de portas do sistema, abaixo do intervalo de portas efêmeras, bem, sabemos que algumas portas de nossos servidores estão pré-ocupadas - aqui está toda a lista delas também está oculta isso é igual.
Este teste ainda é muito primitivo. Observe que não há nenhuma indicação sobre qual propriedade específica estamos verificando - ela é massiva. Um único teste pode verificar 500 propriedades com o nome "... porta" e verificar se todas elas são números inteiros no intervalo desejado, com todas as condições necessárias. Uma vez que eles escreveram, uma dúzia de linhas - e é isso. Esse é um recurso muito conveniente, parece que a configuração possui um formato simples: duas colunas, uma chave e um valor. Portanto, pode ser processado em massa.
Outro exemplo de teste. O que estamos verificando aqui?

Ele verifica se as senhas reais não vazam para a produção. Todas as senhas devem ter algo parecido com isto:

Você pode escrever muitos testes para arquivos de propriedades. Não vou dar mais exemplos - não quero me repetir, a ideia é muito simples, então tudo deve ficar claro.
... e depois de escrever o suficiente desses testes, surge uma pergunta interessante: o que queremos dizer com configuração, onde está sua borda? Consideramos o arquivo de propriedades como uma configuração, cobrimos - e o que mais pode ser coberto no mesmo estilo?
O que considerar uma configuração
Acontece que existem muitos arquivos de texto no projeto que não são compilados - pelo menos no processo normal de compilação. Eles não são verificados de maneira alguma até serem executados no servidor, ou seja, os erros aparecem atrasados. Todos esses arquivos - com certa extensão - podem ser chamados de configuração. Pelo menos, eles serão testados aproximadamente da mesma forma.
Por exemplo, temos um sistema de patches SQL que são rolados no banco de dados durante o processo de implantação.

Eles são escritos para o SQL * Plus. O SQL * Plus é uma ferramenta dos anos 60 e requer todo tipo de coisas estranhas: por exemplo, para garantir que o final do arquivo esteja em uma nova linha. Claro, as pessoas regularmente esquecem de colocar o fim da linha lá, porque não nasceram nos anos 60.
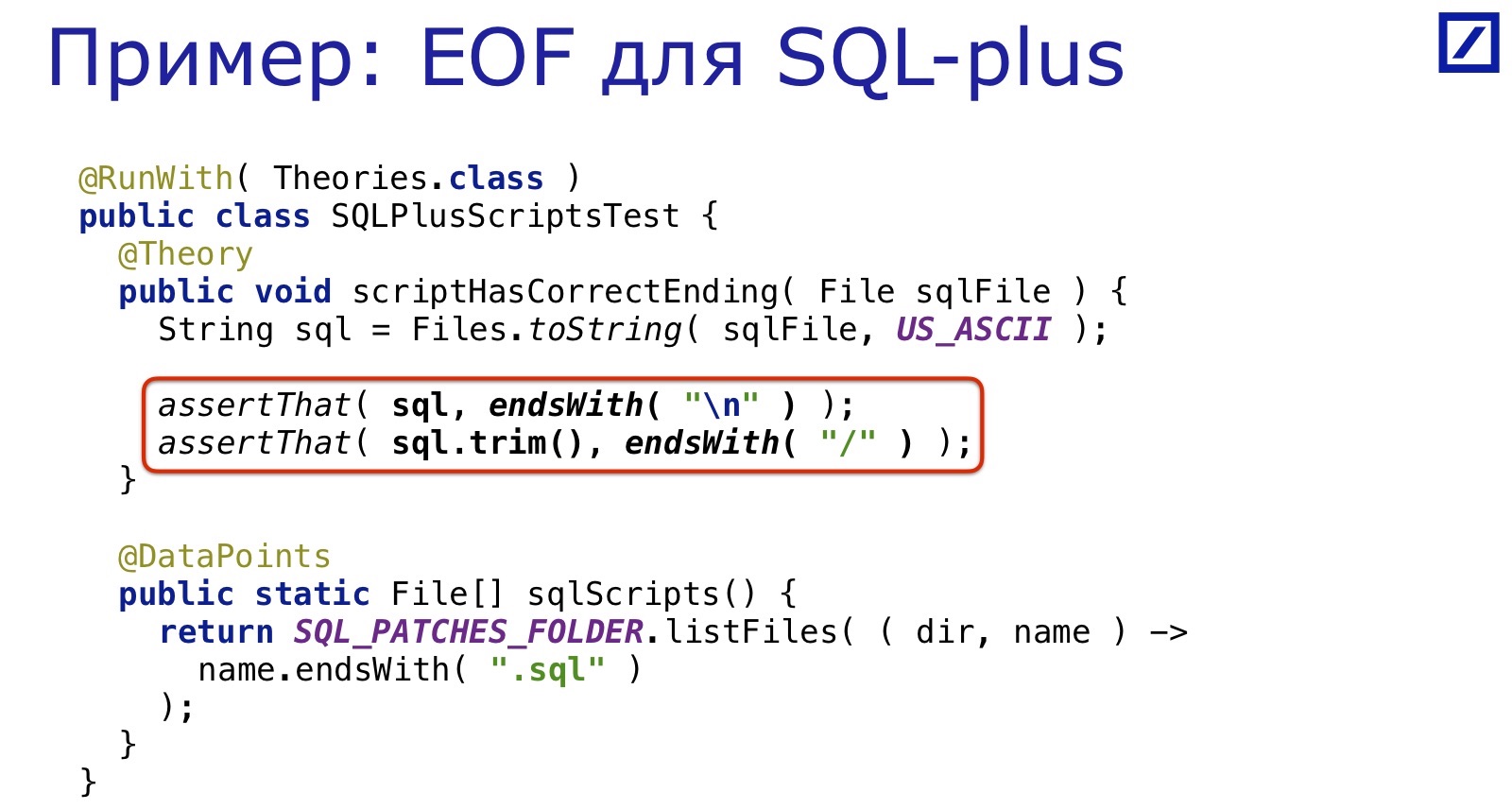
E, novamente, é resolvido pelas mesmas dezenas de linhas: selecionamos todos os arquivos SQL, verificamos se há uma barra final no final. Simples, conveniente, rápido.
Outro exemplo de "como um arquivo de texto" é o crontabs. Nossos serviços crontab começam e param. Eles costumam causar dois erros:
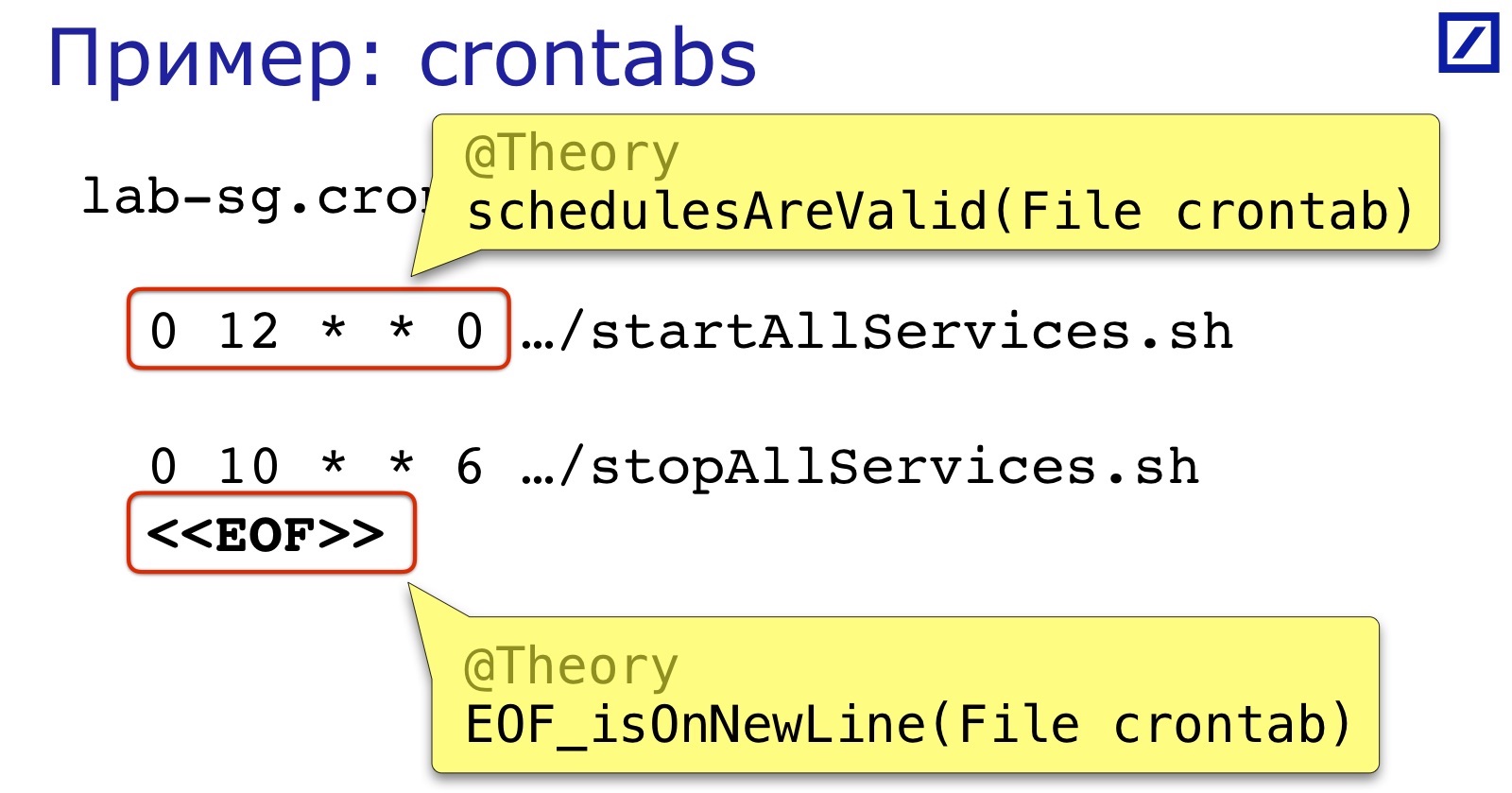
Primeiro, o formato da expressão de agendamento. Não é tão complicado, mas ninguém o verifica antes do lançamento, por isso é fácil colocar um espaço extra, vírgula e coisas do gênero.
Em segundo lugar, como no exemplo anterior, o final do arquivo também deve estar em uma nova linha.
E tudo isso é muito fácil de verificar. O final do arquivo é compreensível, mas para verificar a programação, você pode encontrar bibliotecas prontas que analisam a expressão cron. Antes do relatório, pesquisei no Google: havia pelo menos seis deles. Encontrei seis, mas em geral pode haver mais. Quando escrevemos, pegamos o mais simples dos encontrados, porque não precisávamos verificar o conteúdo da expressão, mas apenas sua correção sintática, para que o cron a carregasse com êxito.
Em princípio, você pode encerrar mais verificações - verifique se inicia no dia certo da semana, se não interrompe os serviços no meio do dia de trabalho. Mas isso acabou não sendo tão útil para nós, e não nos incomodamos.
Outra idéia que funciona muito bem é o shell scripts. Obviamente, escrever em Java um analisador completo de scripts bash é um prazer para os corajosos. Mas o ponto principal é que um grande número desses scripts não é uma festa completa. Sim, existem scripts bash nos quais o código é direto, inferno e inferno, onde eles aparecem uma vez por ano e, jurando, fogem. Mas muitos scripts bash têm as mesmas configurações. Há várias variáveis de sistema e variáveis de ambiente definidas para o valor desejado, configurando outros scripts que usam essas variáveis. E é fácil obter essas variáveis a partir deste arquivo bash e verificar algo sobre elas.

Por exemplo, verifique se JAVA_HOME está instalado em cada ambiente ou se alguma biblioteca jni que usamos está localizada em LD_LIBRARY_PATH. De alguma forma, passamos de uma versão do Java para outra e expandimos o teste: verificamos que JAVA_HOME contém "1,8" naquele mesmo subconjunto de ambiente, que gradualmente transferimos para a nova versão.
Aqui estão alguns exemplos. Deixe-me resumir a primeira parte das conclusões:
- Testes de configuração são confusos no início, há uma barreira psicológica. Mas, após superá-lo, há muitos lugares no aplicativo que não são cobertos por cheques e podem ser cobertos.
- Em seguida, eles são escritos com facilidade e alegria : existem muitas "frutas baixas" que rapidamente oferecem grandes benefícios).
- Reduza o custo de detecção e correção de erros de configuração. Como esses são, de fato, testes de unidade, você pode executá-los no seu computador, mesmo antes de confirmar - isso reduz muito o Feedback Loop. Muitos deles, é claro, teriam sido testados no estágio de implantação do teste, por exemplo. E muitos não seriam testados - se esta for uma configuração de produção. E assim eles são verificados diretamente no computador local.
- Eles dão uma segunda juventude. No sentido de que há uma sensação de que você ainda pode testar muitas coisas interessantes. De fato, no código não é mais tão fácil encontrar o que você pode testar.
Parte 2. Casos mais complexos
Vamos passar para testes mais complexos. Depois de cobrir a maioria das verificações triviais, como as mostradas aqui, surge a pergunta: é possível verificar algo mais complicado?
O que significa "mais difícil"? Os testes que acabei de descrever têm aproximadamente a seguinte estrutura:

Eles verificam algo em relação a um arquivo específico. Ou seja, examinamos os arquivos, aplicamos uma determinada verificação de condição a cada um. Assim, muito pode ser verificado, mas há cenários mais úteis:
- O aplicativo de interface do usuário se conecta ao servidor de seu ambiente.
- Todos os serviços do mesmo ambiente se conectam ao mesmo servidor de gerenciamento.
- Todos os serviços no mesmo ambiente usam o mesmo banco de dados.
Por exemplo, um aplicativo de interface do usuário se conecta ao seu servidor de ambiente. Provavelmente, a interface do usuário e o servidor são módulos diferentes, se não são projetos, e têm configurações diferentes; é improvável que eles usem os mesmos arquivos de configuração. Portanto, você precisará vinculá-los para que todos os serviços de um ambiente sejam conectados a um servidor de gerenciamento de chaves através do qual os comandos são distribuídos. Novamente, provavelmente, esses são módulos diferentes, serviços diferentes e equipes geralmente diferentes os desenvolvem.
Ou todos os serviços usam o mesmo banco de dados, a mesma coisa - serviços em módulos diferentes.
De fato, existe uma imagem: muitos serviços, cada um deles com sua própria estrutura de configuração, é necessário reduzir alguns deles e verificar algo no cruzamento:

Obviamente, você pode fazer exatamente isso: carregar um, o segundo, retirar algo em algum lugar, colar no código de teste. Mas você pode imaginar o tamanho do código e a legibilidade dele. Começamos com isso, mas depois percebemos o quão difícil é. Como fazer melhor?
Se você sonha, seria mais conveniente, então eu sonhei que o teste seria como se eu o explicasse em linguagem humana:
@Theory public void eachEnvironmentIsXXX( Environment environment ) { for( Server server : environment.servers() ) { for( Service service : server.services() ) { Properties config = buildConfigFor( environment, server, service );
Para cada ambiente, uma condição é atendida. Para verificar isso, você precisa do ambiente para encontrar uma lista de servidores, uma lista de serviços. Em seguida, carregue as configurações e verifique algo no cruzamento. Consequentemente, eu preciso disso, chamei de Layout de Implantação.
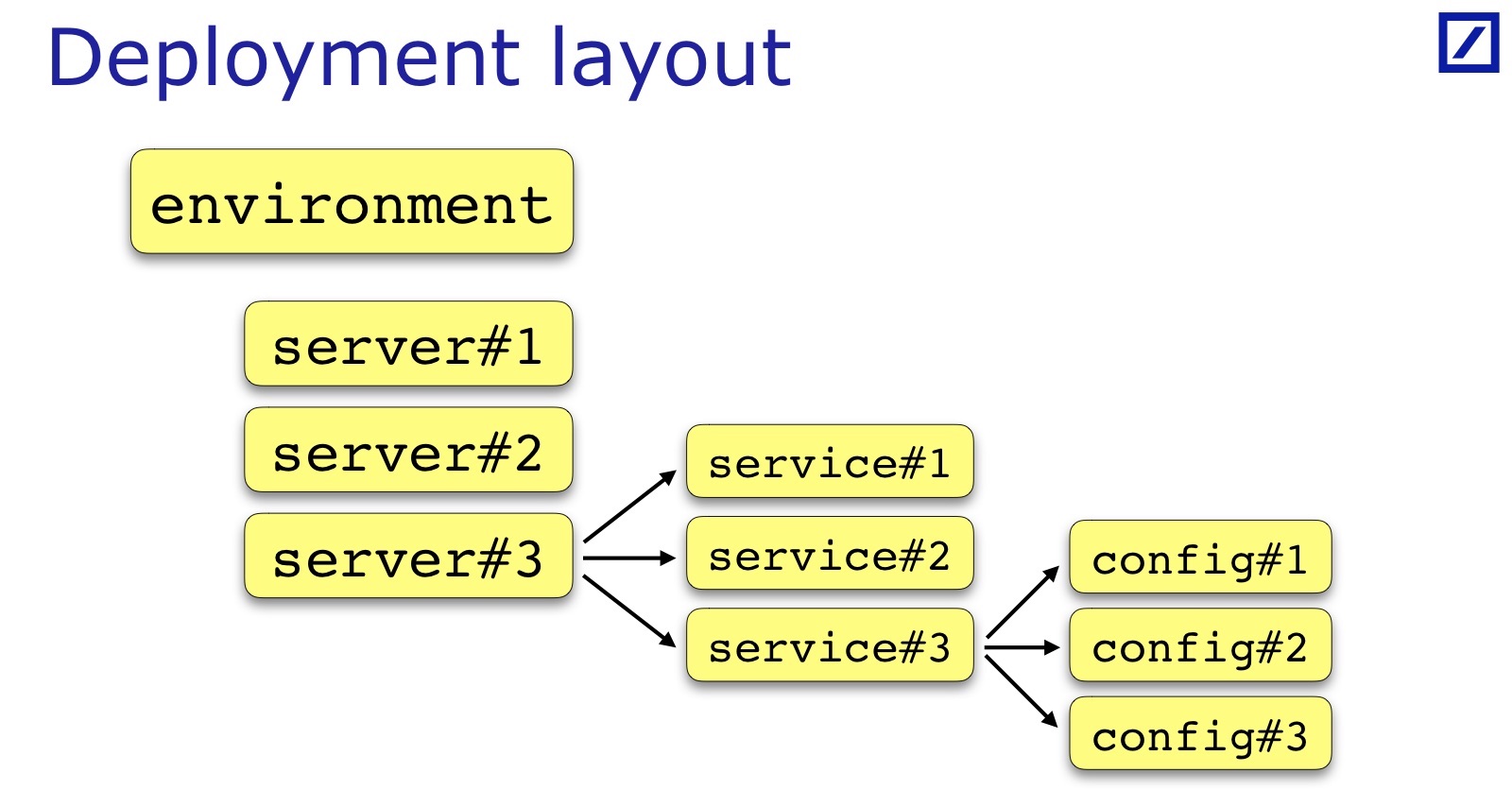
Precisamos de uma oportunidade do código para obter acesso a como o aplicativo é implantado: em quais servidores, quais serviços são colocados, em qual ambiente - para obter essa estrutura de dados. E, partindo disso, começo a carregar a configuração e a processá-la.
O Layout de implantação é específico para cada equipe e cada projeto. Eu desenhei - este é um caso geral: geralmente há um conjunto de servidores, serviços, um serviço às vezes tem um conjunto de arquivos de configuração, e não apenas um. Às vezes, são necessários parâmetros adicionais úteis para testes, que precisam ser adicionados. Por exemplo, o rack no qual o servidor está localizado pode ser importante. Andrey, em seu relatório, deu um exemplo de quando era importante para os serviços deles que os serviços de Backup / Primário devessem estar em racks diferentes - no seu caso, ele precisaria manter uma indicação do rack no layout de implantação:
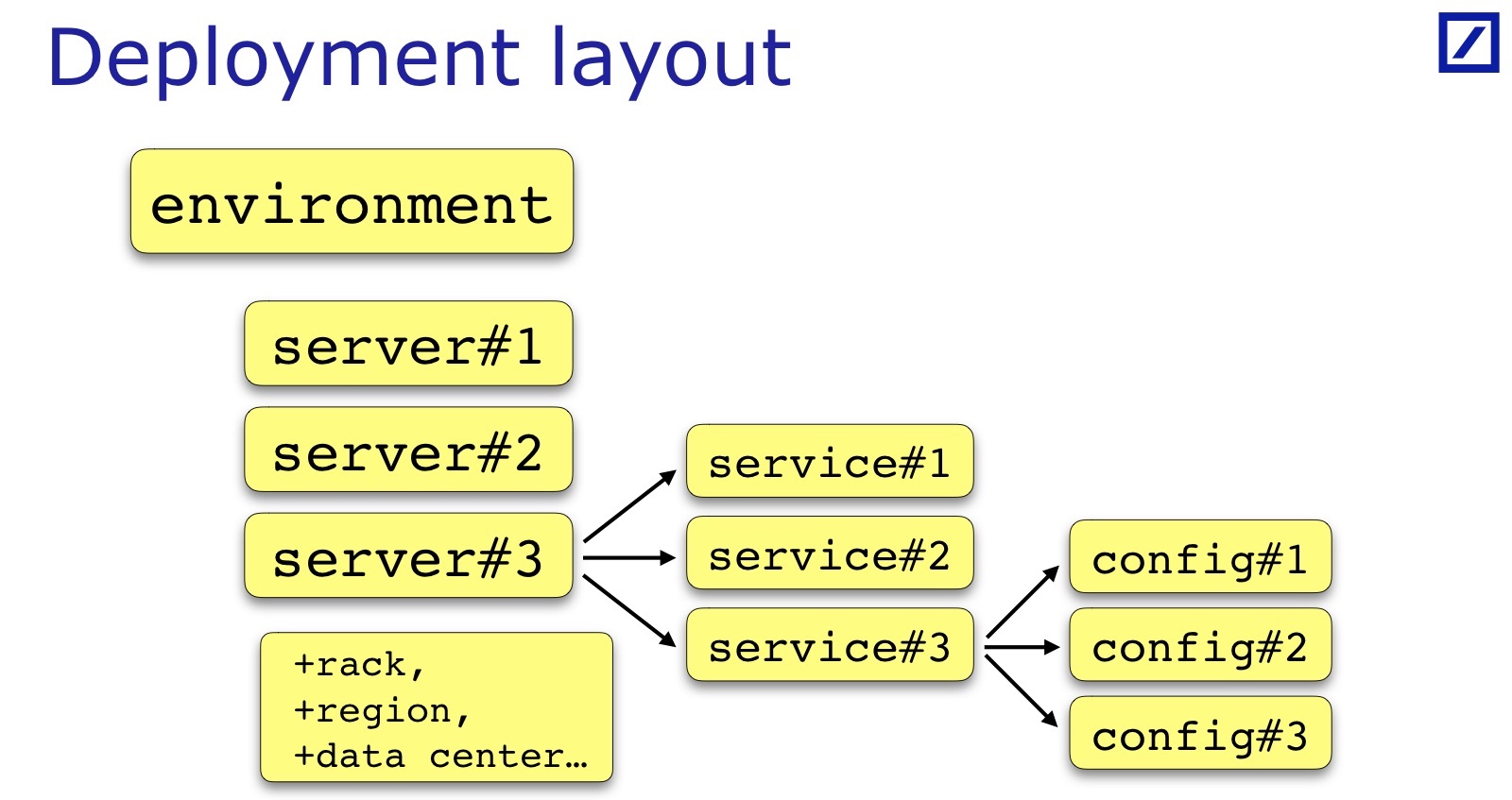
Para nossos propósitos, a região do servidor é importante, o data center específico, também em princípio, para que o Backup / Primary esteja em diferentes data centers. Essas são propriedades adicionais do servidor, são específicas do projeto, mas no slide é um denominador comum.
Onde obter o layout de implantação? Parece que em qualquer grande empresa existe um sistema de gerenciamento de infraestrutura, tudo é descrito lá, é confiável, confiável e tudo o mais ... na verdade não.
Pelo menos, minha prática em dois projetos mostrou que é mais fácil codificar primeiro e depois de três anos ... deixar a pele dura.
Vivemos com esse projeto há três anos. No segundo, ao que parece, ainda nos integramos ao Gerenciamento de infraestrutura em um ano, mas todos esses anos vivemos assim. Por experiência, faz sentido adiar a tarefa de integração com o IM, a fim de obter testes prontos o mais rápido possível, o que mostrará que eles funcionam e são úteis. E então, pode ser que essa integração não seja tão necessária, porque a distribuição de serviços entre servidores não é alterada com tanta frequência.
O hardcode pode literalmente ser assim:
public enum Environment { PROD( PROD_UK_PRIMARY, PROD_UK_BACKUP, PROD_US_PRIMARY, PROD_US_BACKUP, PROD_SG_PRIMARY, PROD_SG_BACKUP ) … public Server[] servers() {…} } public enum Server { PROD_UK_PRIMARY(“rflx-ldn-1"), PROD_UK_BACKUP("rflx-ldn-2"), PROD_US_PRIMARY(“rflx-nyc-1"), PROD_US_BACKUP("rflx-nyc-2"), PROD_SG_PRIMARY(“rflx-sng-1"), PROD_SG_BACKUP("rflx-sng-2"), public Service[] services() {…} }
A maneira mais fácil que usamos em nosso primeiro projeto é enumerar o Environment com uma lista de servidores em cada um deles. Existe uma lista de servidores e, ao que parece, deve haver uma lista de serviços, mas enganamos: temos scripts de início (que também fazem parte da configuração).

Eles executam serviços para cada ambiente. E o método services () simplesmente grep'a todos os serviços do arquivo de seu servidor. Isso é feito porque não existem tantos Ambientes e os servidores também raramente são adicionados ou excluídos - mas existem muitos serviços e eles são embaralhados com bastante frequência. Fazia sentido carregar o layout real dos serviços a partir de scripts para não alterar o layout codificado com muita frequência.
Depois de criar esse modelo de configuração de software, bônus agradáveis aparecem. Por exemplo, você pode escrever um teste como este:

O teste é que, em todos os ambientes, todos os principais serviços estão presentes. Suponha que haja quatro serviços principais, e o resto pode ou não ser, mas sem esses quatro não faz sentido. Você pode verificar se não os esqueceu em nenhum lugar, se todos eles têm backups no mesmo ambiente. Na maioria das vezes, esses erros ocorrem ao configurar o UAT dessas instâncias, mas também podem vazar para o PROD. No final, erros no UAT também perdem tempo e nervosismo dos testadores.
Surge a questão de manter a relevância do modelo de configuração. Você também pode escrever um teste para isso.
public class HardCodedLayoutConsistencyTest { @Theory eachHardCodedEnvironmentHasConfigFiles(Environment env){ … } @Theory eachConfigFileHasHardCodedEnvironment(File configFile){ … } }
Existem arquivos de configuração e um layout de implantação no código. E você pode verificar isso para cada ambiente / servidor / etc. existe um arquivo de configuração correspondente e para cada arquivo do formato necessário - o ambiente correspondente. Assim que você esquecer de adicionar algo a um lugar, o teste será reprovado.
A linha inferior é o layout de implantação:
- Simplifica a gravação de testes complexos que reúnem configurações de diferentes partes do aplicativo.
- Torna-os mais claros e mais legíveis. Eles têm a aparência que você pensa deles em alto nível, e não a maneira como eles passam pelas configurações.
- Durante a sua criação, quando as pessoas fazem perguntas, há muitas coisas interessantes sobre a implantação. Limitações, conhecimento sagrado implícito, surgem, por exemplo, sobre a possibilidade de hospedar dois ambientes em um servidor. Acontece que os desenvolvedores pensam de maneira diferente e escrevem seus serviços de acordo. E esses momentos são úteis para se estabelecer entre os desenvolvedores.
- Bem complementa a documentação (especialmente se não for). Mesmo se houver, é mais agradável para mim, como desenvolvedor, ver isso no código. Além disso, você pode escrever comentários importantes para mim, e não para outra pessoa. E você também pode codificar. Ou seja, se você decidir que não pode haver dois ambientes no mesmo servidor, poderá inserir uma verificação e agora não. Pelo menos você descobrirá se alguém tentar. Ou seja, esta é a documentação com a capacidade de aplicá-la. Isso é muito útil.
Vamos seguir em frente. Depois que os testes foram escritos, eles "se estabeleceram" por um ano, alguns começam a cair. Alguns começam a cair mais cedo, mas não é tão assustador. É assustador quando um teste escrito um ano atrás cai, você olha para a mensagem de erro e não entende.

Suponha que eu compreenda e concorde que essa é uma porta de rede inválida - mas onde ela está? Antes da palestra, observei o fato de termos 1.200 arquivos de propriedades no projeto, espalhados por 90 módulos, com um total de 24.000 linhas. (Embora eu tenha ficado surpreso, mas se você contar, então este não é um número tão grande - para um serviço para 4 arquivos.) Onde fica essa porta?
É claro que assertThat () tem um argumento de mensagem; você pode inserir algo que ajudará a identificar o local. Mas quando você escreve um teste, não pensa nisso. E mesmo que você pense, ainda precisa adivinhar qual descrição será detalhada o suficiente para ser entendida em um ano. Gostaria de automatizar esse momento, para que haja uma maneira de escrever testes com geração automática de uma descrição mais ou menos clara, pela qual você pode encontrar um erro.
Mais uma vez, eu sonhei e sonhei com algo assim:
SELECT environment, server, component, configLocation, propertyName, propertyValue FROM configuration(environment, server, component) WHERE propertyName like “%.port%” and propertyValue is not validNetworkPort()
Isso é tão pseudo-SQL - bem, eu apenas conheço SQL, e o cérebro jogou a solução fora do que é familiar. A idéia é que a maioria dos testes de configuração consiste em várias partes do mesmo tipo. Primeiro, um subconjunto de parâmetros é selecionado pela condição:

Então, em relação a esse subconjunto, verificamos algo em relação ao valor:

E então, se havia propriedades cujos valores não satisfazem o desejo, esta é a "planilha" que queremos receber na mensagem de erro:

Ao mesmo tempo, pensei até em escrever um analisador como o SQL, pois agora não é difícil. Mas então percebi que o IDE não o apoiaria e sugeriria, para que as pessoas tivessem que escrever às cegas nesse "SQL" criado por si próprio, sem avisos do IDE, sem compilação, sem verificação - isso não é muito conveniente. Portanto, tive que procurar soluções suportadas pela nossa linguagem de programação. Se tivéssemos .NET, o LINQ ajudaria, é quase como o SQL.
Não há LINQ em Java, o mais próximo possível dos fluxos. É assim que esse teste deve parecer nos fluxos:
ValueWithContext[] incorrectPorts = flattenedProperties( environment ) .filter( propertyNameContains( ".port" ) ) .filter( !isInteger( propertyValue ) || !isValidNetworkPort( propertyValue ) ) .toArray(); assertThat( incorrectPorts, emptyArray() );
flattenedProperties () pega todas as configurações desse ambiente, todos os arquivos para todos os servidores, serviços e os expande para uma tabela grande. Esta é essencialmente uma tabela semelhante a SQL, mas na forma de um conjunto de objetos Java. E flattenedProperties () retorna esse conjunto de strings como um fluxo.

Em seguida, você adiciona algumas condições neste conjunto de objetos Java. Neste exemplo: selecionamos aqueles que contêm "port" em propertyName e filtramos aqueles em que os valores não são convertidos em Inteiro ou não no intervalo válido. Esses são valores errados e, em teoria, deveriam ser um conjunto vazio.

Se eles não forem um conjunto vazio, lançamos um erro que será parecido com este:

Parte 3. Teste como suporte para refatoração
Normalmente, o teste de código é um dos mais poderosos recursos de refatoração. A refatoração é um processo perigoso, com muitas refazer e quero garantir que, depois disso, o aplicativo ainda seja viável. Uma maneira de garantir isso é primeiro sobrepor tudo com testes de todos os lados e depois refatorá-lo.
E agora, diante de mim, estava a tarefa de refatorar a configuração. Há um aplicativo que foi escrito há sete anos por uma pessoa inteligente. A configuração deste aplicativo é mais ou menos assim:

Este é um exemplo, há muitos mais. Permutações de aninhamento triplo, e isso é usado em toda a configuração:

Existem poucos arquivos na própria configuração, mas eles são incluídos um no outro. Ele usa uma pequena extensão do iu Properties - Apache Commons Configuration, que suporta apenas inclusões e permissões entre chaves.
E o autor fez um trabalho fantástico usando apenas essas duas coisas. Acho que ele construiu uma máquina de Turing sobre eles. Em alguns lugares, realmente parece que ele está tentando fazer cálculos usando inclusões e substituições. Não sei se esse sistema de Turing está completo, mas ele, na minha opinião, tentou provar que é assim.
E o homem foi embora. Escreveu, o aplicativo funciona e ele saiu do banco. Tudo funciona, apenas ninguém entende completamente a configuração.
Se tomarmos um serviço separado, ocorrerão 10 inclusões, para uma profundidade tripla e, no total, se tudo for expandido, 450 parâmetros. De fato, esse serviço em particular usa de 10 a 15% deles, o restante dos parâmetros são para outros serviços, porque os arquivos são compartilhados, eles são usados por vários serviços. Mas o que exatamente 10-15% usa esse serviço específico não é tão fácil de entender. O autor aparentemente entendeu. Pessoa muito inteligente, muito.
A tarefa, respectivamente, era simplificar a configuração, sua refatoração. Ao mesmo tempo, eu queria manter o aplicativo funcionando, pois nessa situação as chances são baixas. Eu quero:
- Simplifique a configuração.
- Para que após a refatoração, cada serviço ainda tenha todos os parâmetros necessários.
- Para que ele não tenha parâmetros extras. 85% dos que não estão relacionados a ele não devem confundir a página.
- Esses serviços ainda se conectaram com êxito em clusters e executaram colaboração.
O problema é que não se sabe quão bem eles se conectam agora, porque o sistema é altamente redundante. Por exemplo, olhando para o futuro: durante a refatoração, descobriu-se que em uma das configurações de produção deveria haver quatro servidores no clipe de backup, mas na verdade havia dois. Devido ao alto nível de redundância, ninguém percebeu isso - o erro veio à tona acidentalmente, mas, na verdade, o nível de redundância ficou por muito tempo abaixo do esperado. O ponto é que não podemos confiar no fato de que a configuração atual está correta em todos os lugares.
Eu levo ao fato de que você não pode simplesmente comparar a nova configuração com a antiga. Pode ser equivalente, mas permanece ao mesmo tempo em algum lugar errado. É necessário verificar o conteúdo lógico.
Programa mínimo: isole cada parâmetro separado de cada serviço necessário e verifique se a porta é uma porta, o endereço é um endereço, o TTL é um número positivo etc. E verifique os principais relacionamentos aos quais os serviços se conectam basicamente nos principais pontos finais. Eu queria conseguir isso, pelo menos. Ou seja, diferente dos exemplos anteriores, a tarefa aqui não é verificar parâmetros individuais, mas cobrir toda a configuração com uma rede completa de verificações.
Como testá-lo?
public class SimpleComponent { … public void configure( final Configuration conf ) { int port = conf.getInt( "Port", -1 ); if( port < 0 ) throw new ConfigurationException(); String ip = conf.getString( "Address", null ); if( ip == null ) throw new ConfigurationException(); … } … }
Como eu resolvi esse problema? Há algum componente simples, no exemplo, é simplificado ao máximo. (Para aqueles que não se depararam com o Apache Commons Configuration: o objeto Configuration é como Properties, apenas ele ainda possui os métodos digitados getInt (), getLong (), etc .; podemos assumir que esses são juProperties em pequenos esteróides.) Suponha que um componente precise de dois parâmetros: por exemplo, um endereço TCP e uma porta TCP. Nós os retiramos e verificamos. Quais são as quatro partes comuns aqui?

Este é o nome do parâmetro, tipo, valores padrão (aqui são triviais: nulo e -1, às vezes há valores sãos) e algumas validações. A porta aqui é validada de maneira muito simples e incompleta - você pode especificar a porta que passará por ela, mas não será uma porta de rede válida. Portanto, eu gostaria de melhorar esse momento também. Mas antes de tudo, quero transformar essas quatro coisas em uma coisa. Por exemplo, isto:
IProperty<Integer> PORT_PROPERTY = intProperty( "Port" ) .withDefaultValue( -1 ) .matchedWith( validNetworkPort() ); IProperty<String> ADDRESS_PROPERTY = stringProperty( "Address" ) .withDefaultValue( null ) .matchedWith( validIPAddress() );
Esse objeto composto é uma descrição de uma propriedade que sabe seu nome, valor padrão, pode validar (aqui eu uso o correspondente de hamcrest novamente). E este objeto tem algo como esta interface:
interface IProperty<T> { FetchedValue<T> fetch( final Configuration config ) } class FetchedValue<T> { public final String propertyName; public final T propertyValue; … }
Ou seja, depois de criar um objeto específico para uma implementação específica, você pode solicitar que ele extraia o parâmetro que ele representa da configuração. E ele retirará esse parâmetro, verificará o processo; se não houver parâmetro, ele fornecerá um valor padrão, direcionará para o tipo desejado e retornará imediatamente com o nome.
Ou seja, aqui está o nome do parâmetro e um valor real que o serviço verá se solicita dessa configuração. Isso permite que você agrupe várias linhas de código em uma entidade; esta é a primeira simplificação que precisarei.
A segunda simplificação necessária para solucionar o problema foi a introdução de um componente que precisa de várias propriedades para sua configuração. Modelo de configuração de componentes:

Tivemos um componente usando essas duas propriedades, existe um modelo para sua configuração - a interface IConfigurationModel, que essa classe implementa. IConfigurationModel faz tudo o que o componente faz, mas apenas a parte relacionada à configuração. Se o componente precisar de parâmetros em uma determinada ordem com certos valores padrão - IConfigurationModel combina essas informações em si, o encapsula. Todas as outras ações do componente não são importantes para ele. Este é um modelo de componente em termos de acesso à configuração.

O truque dessa visão é que os modelos são combináveis. Se houver um componente que use outros componentes e eles forem combinados, da mesma maneira, o modelo desse componente complexo poderá mesclar os resultados das chamadas de dois subcomponentes.
Ou seja, é possível construir uma hierarquia de modelos de configuração paralela à hierarquia dos próprios componentes. No modelo superior, chame fetch (), que retornará a planilha dos parâmetros que ele extraiu da configuração com seus nomes - exatamente aqueles que o componente correspondente precisará em tempo real. Se escrevemos todos os modelos corretamente, é claro.
Ou seja, a tarefa é escrever esses modelos para cada componente no aplicativo que tem acesso à configuração. No meu aplicativo, havia alguns desses componentes: o aplicativo em si é bastante frondoso, mas reutiliza ativamente o código, para que apenas 70 classes principais sejam configuradas. Para eles, eu tive que escrever 70 modelos.
Quanto custa:
- 12 serviços
- 70 classes configuráveis
- => 70 modelos de configuração (~ 60 são triviais);
- Semanas de 1-2 pessoas.
Simplesmente abri a tela com o código do componente que se configura e, na tela seguinte, escrevi o código para o ConfigurationModel correspondente. A maioria deles é trivial, como o exemplo mostrado. Em alguns casos, existem ramificações e transições condicionais - aí o código se torna mais ramificado, mas tudo também é resolvido. Em uma hora e meia a duas semanas, resolvi esse problema; para todos os 70 componentes, descrevi os modelos.
Como resultado, quando reunimos tudo, obtemos o seguinte código:

Para cada serviço / ambiente / etc. pegamos o modelo de configuração, ou seja, o nó superior desta árvore e pedimos para obter tudo da configuração. Nesse ponto, todas as validações passam para dentro, cada uma das propriedades, quando sai da configuração, verifica seu valor quanto à exatidão. Se pelo menos um não for aprovado, uma exceção será exibida. Todo o código é obtido verificando se todos os valores são válidos isoladamente.
Interdependências de Serviço
Ainda tínhamos uma pergunta sobre como verificar a interdependência dos serviços. Isso é um pouco mais complicado, você precisa observar que tipo de interdependência existe. Descobri que as interdependências se resumem ao fato de que os serviços devem "atender" nos pontos de extremidade da rede. O serviço A deve ouvir exatamente o endereço para o qual o serviço B envia pacotes e vice-versa. No meu exemplo, todas as dependências entre as configurações de diferentes serviços se resumiram a isso. Foi possível resolver esse problema de maneira simples: obtenha portas e endereços de diferentes serviços e verifique-os. Haveria muitos testes, eles seriam volumosos. Sou uma pessoa preguiçosa e não queria isso. Portanto, eu fiz o contrário.
Em primeiro lugar, eu queria abstrair de alguma forma esse ponto de extremidade da rede. Por exemplo, para uma conexão TCP, você precisa de apenas dois parâmetros: endereço e porta. Para uma conexão multicast, quatro parâmetros. Eu gostaria de colapsá-lo em algum tipo de objeto. Fiz isso no objeto Endpoint, que oculta tudo o que você precisa. O slide é um exemplo de OutcomingTCPEndpoint, uma conexão de rede TCP de saída.
IProperty<IEndpoint> TCP_REQUEST = outcomingTCP(
Endpoint matches(), Endpoint, , .
« »? , : , , - , — . , , / . , , .
, , ---, , Endpoint. ConfigurationModels — , . ? :
ValueWithContext[] allEndpoints = flattenedConfigurationValues(environment) .filter( valueIsEndpoint() ) .toArray(); ValueWithContext[] unpairedEndpoints = Arrays.stream( allEndpoints ) .filter( e -> !hasMatchedEndpoint(e, allEndpoints) ) .toArray(); assertThat( unpairedEndpoints, emptyArray() );
environment' endpoint', , , , . . « » O(n^2), , endpoint' , .
Endpoint , , . , , - .
, , , «» — , . . , , . , .
. , , . , , , c, , .
ConfigurationModel :
, . , , , — . : , . , , , , .
. , ConfigurationModels, . , UDP- , , .
, endpoints , .dot. . — .
. Conclusões:
Heisenbug 2018 Piter , : 6-7 Heisenbug . . 1 — .