Olá, meu nome é Maxim, sou administrador de sistemas. Três anos atrás, meus colegas e eu começamos a transferir produtos para microsserviços e decidimos usar o Openstack como plataforma, e encontramos vários ancinhos não óbvios ao automatizar circuitos de teste. Este post é sobre as nuances da configuração do OpenStack, que dificilmente são encontradas na quinta página dos resultados dos mecanismos de pesquisa (ou melhor, são facilmente na primeira).
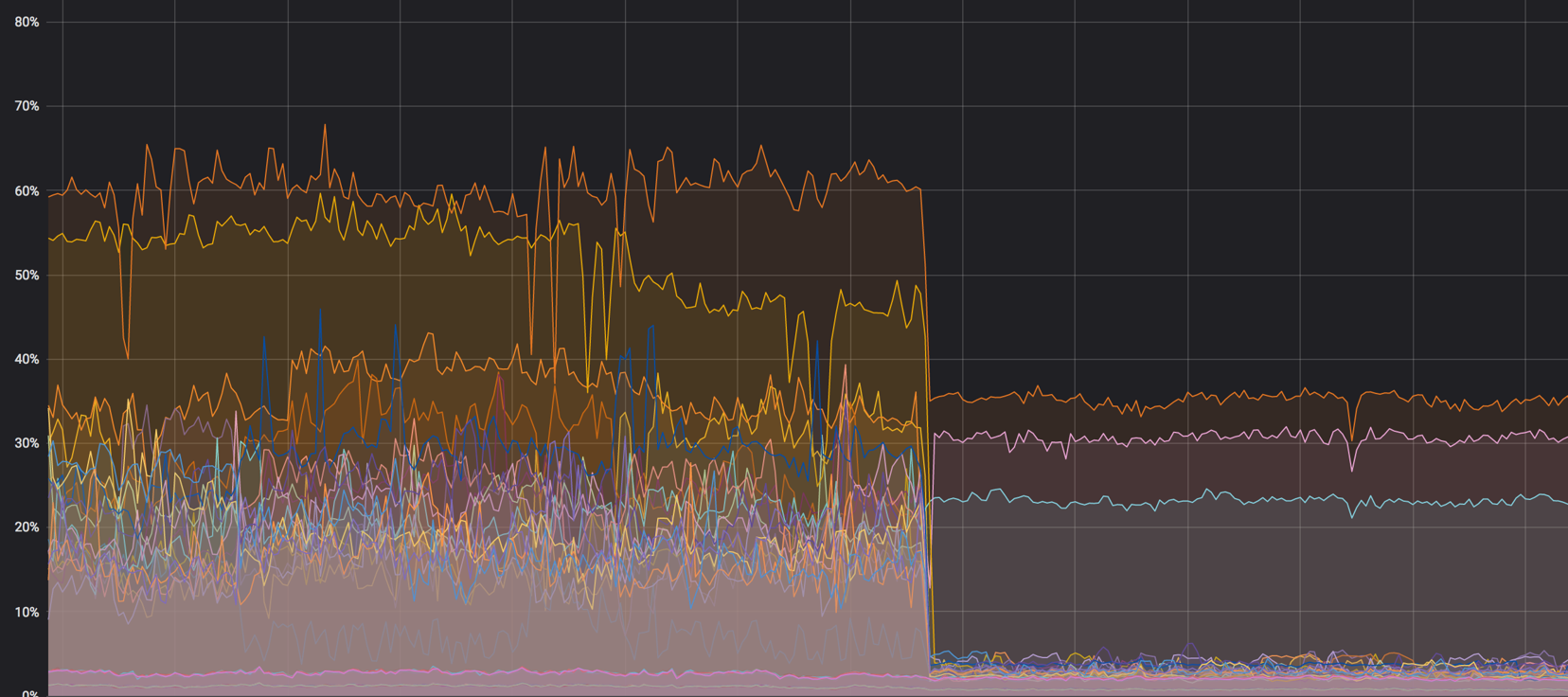
A carga nos núcleos: foi - tornou-se
NAT
Em alguns casos, usamos dualstack. É quando a máquina virtual recebe dois endereços ao mesmo tempo - IPv4 e IPv6. Primeiro, garantimos que o endereço v4 “flutuante” fosse atribuído na rede interna por NAT e a máquina recebesse v6 por BGP, mas há alguns problemas com isso.
NAT - um nó adicional na rede, onde, mesmo sem ele, você precisa monitorar a distribuição de carga normal. A aparência do NAT na rede quase sempre leva a dificuldades com a depuração - no host, um IP, no banco de dados, e fica difícil rastrear a solicitação. As pesquisas em massa são iniciadas e a solução ainda estará dentro do OpenStack.
Ainda assim, o NAT não permite fazer uma segmentação normal de acesso entre projetos. Todos os projetos têm suas próprias sub-redes, os IPs flutuantes migram constantemente e, com o NAT, torna-se absolutamente impossível gerenciar isso. Algumas instalações falam sobre o uso do NAT 1 em 1 (o endereço interno não difere do externo), mas isso ainda deixa links desnecessários na cadeia de interação com serviços externos. Chegamos à conclusão de que para nós a melhor opção é uma rede BGP.
Quanto mais simples, melhor
Tentamos várias ferramentas de automação, mas optamos pelo Ansible. Essa é uma boa ferramenta, mas sua funcionalidade padrão (mesmo levando em consideração módulos adicionais) pode não ser suficiente em algumas situações difíceis.
Por exemplo, através do módulo Ansible, você não pode especificar de quais endereços de sub-rede serão alocados. Ou seja, você pode especificar uma rede, mas não pode definir um pool de endereços específico. O comando shell que cria o IP flutuante ajudará aqui:
openstack floating ip create -c floating_ip_address -f value -project \ {{ project name }} —subnet private-v4 CLOUD_NET
Outro exemplo de funcionalidade ausente: devido ao dualstack, não podemos criar corretamente um roteador com duas portas para v4 e v6. É aqui que um script bash é útil:
O script cria um roteador, adiciona sub-redes v4 e v6 e atribui um gateway externo.
Repetir
Em qualquer situação incompreensível - reinicie. Tente novamente, crie uma instância, um roteador ou um registro DNS, porque você nem sempre entende rapidamente qual é o seu problema. A nova tentativa pode atrasar a degradação do serviço e, nesse momento, você pode, com calma e sem nervos, resolver o problema.
Todas as dicas acima realmente funcionam muito bem com Terraform, Puppet e qualquer outra coisa.
Tudo tem o seu lugar
Qualquer serviço grande (o OpenStack não é uma exceção) combina muitos serviços menores que podem interferir no trabalho um do outro. Aqui está um exemplo.
Agente de rede O agente Neutron-L2 é responsável pela conectividade de rede no OpenStack. Se todos os outros agentes estiverem parcialmente nos controladores, L2, devido às especificidades, estará presente em todos os lugares.
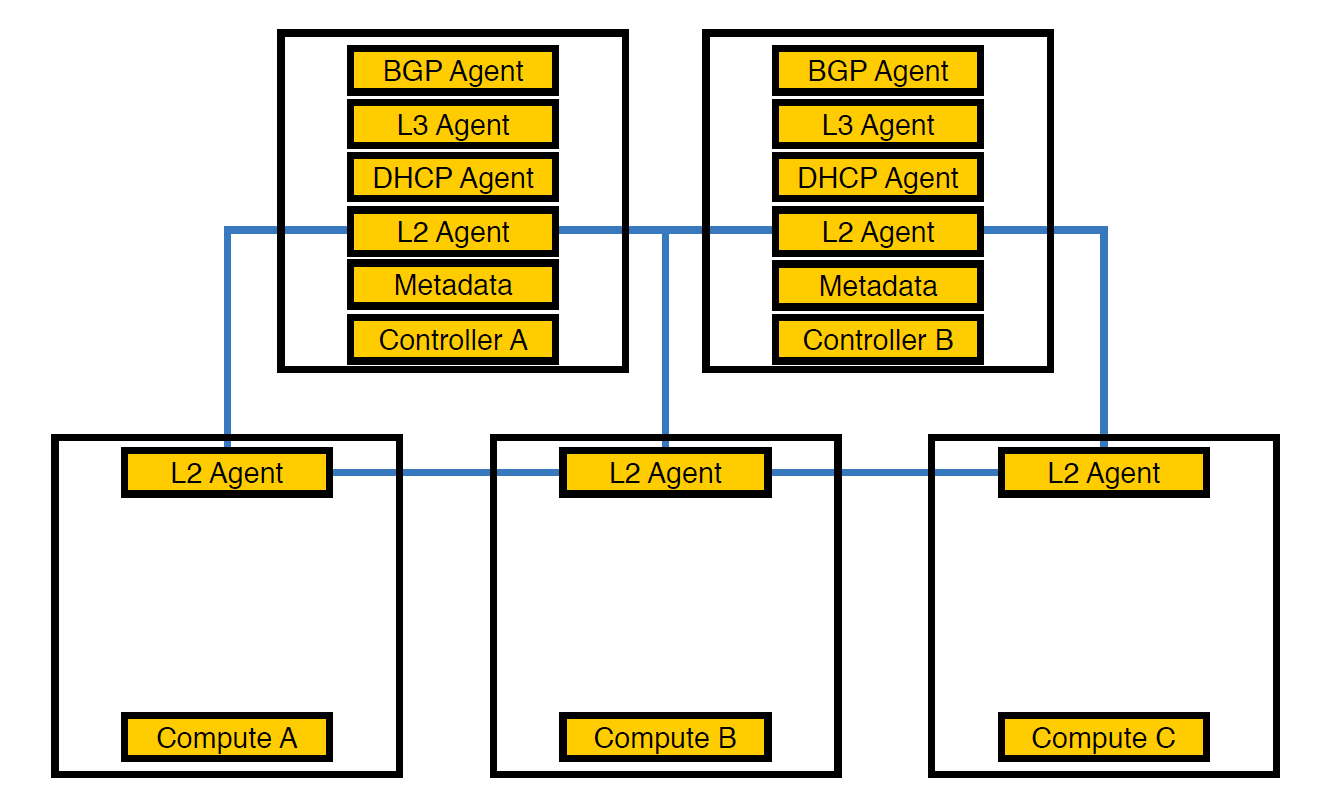
Foi assim que nossa infraestrutura ficou no início, até o número de esquemas exceder 50
Nesse ponto, percebemos que, devido a esse arranjo de agentes, os controladores não podiam lidar com a carga e transferimos os agentes para os nós de computação. Eles são mais poderosos que os controladores e, além disso, o controlador não precisa lidar com o processamento de tudo - deve dar a tarefa ao nó de execução e o nó irá executá-lo.

Agentes transferidos para calcular nós
No entanto, isso não foi suficiente, porque esse arranjo teve um efeito ruim no desempenho das máquinas virtuais. Com uma densidade de 14 núcleos virtuais por físico, se um agente de rede começar a carregar o fluxo, isso poderá afetar várias máquinas virtuais ao mesmo tempo.
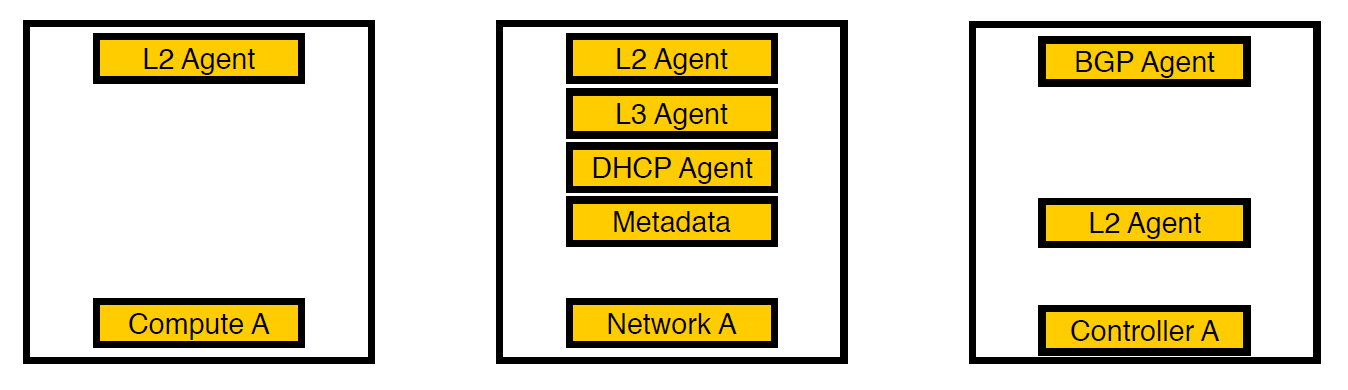
Terceira iteração. Nós selecionados apareceram.
Pensamos e movemos os agentes para separar os nós da rede. Agora, apenas os serviços para máquinas virtuais permanecem nos nós de computação, todos os agentes trabalham nos nós da rede e apenas os agentes bgp que lidam com a rede v6 permanecem nos controladores (já que um agente bgp pode servir apenas um tipo de rede). L2 permaneceu em todo lugar, porque sem ele, como escrevemos acima, não haveria conectividade na rede.
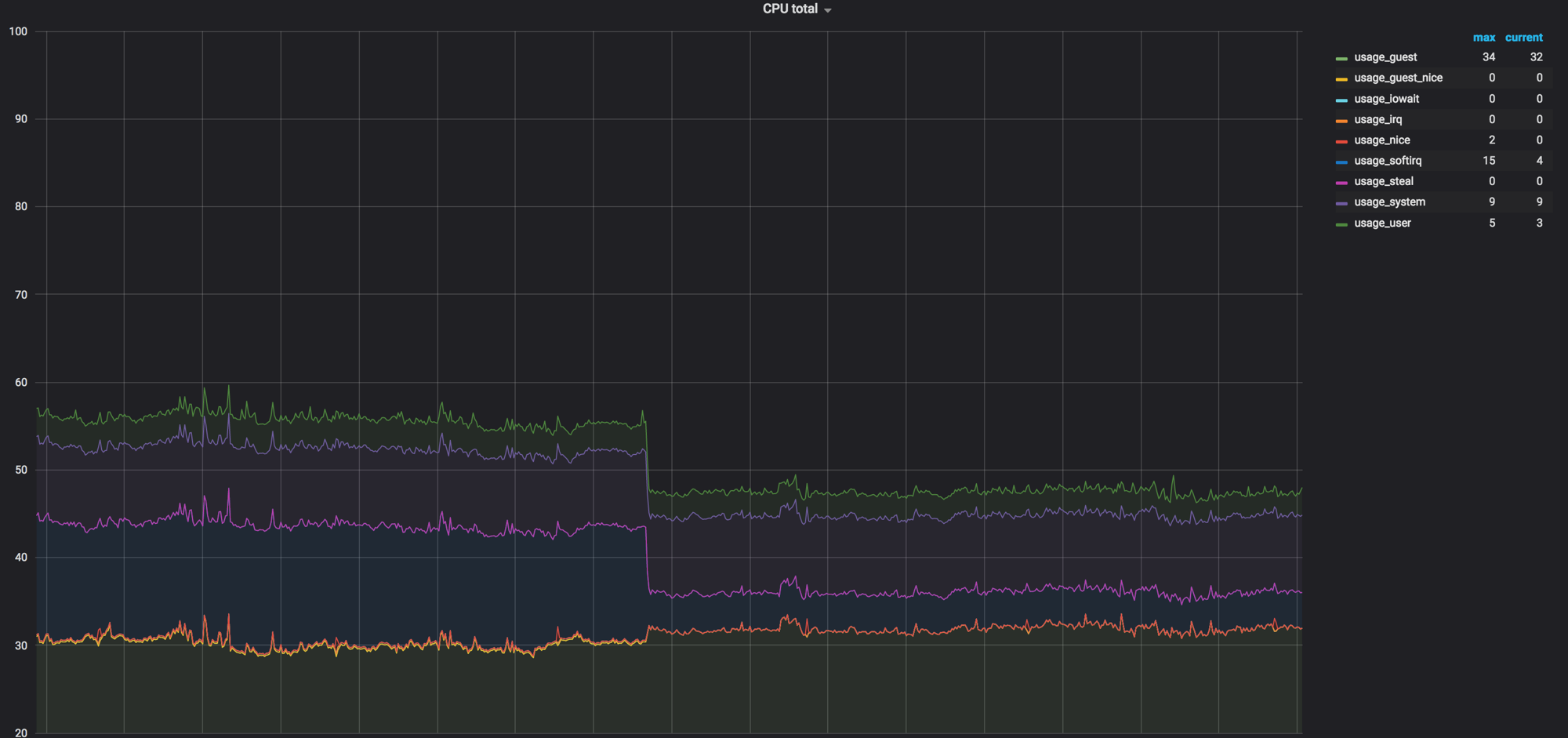
Carregue o gráfico dos nós de computação antes que tudo seja misturado. Era cerca de 60%, mas a carga caiu insignificante

A carga no softirq antes que os agentes de rede removessem os nós de computação. Três núcleos permaneceram carregados. Naquela época, pensávamos que era normal
Código como documentação
Às vezes acontece que o código é a documentação, especialmente em serviços grandes como o OpenStack. Com um ciclo de lançamento de seis meses, os desenvolvedores esquecem ou simplesmente não têm tempo para documentar algumas coisas, e isso acontece como no exemplo abaixo.
Sobre tempos limite
Uma vez que vimos que as chamadas da Neutron para o Open vSwitch não cabem em cinco segundos e caem no tempo limite.
127.0.0.1:29696: no response to inactivity probe after 10 seconds, disconnecting neutron.agent.ovsdb.native.commands TimeoutException: Commands [DbSetCommand(table=Port, col_values=(('tag', 11),), record=qtoq69a81c6-e2)] exceeded timeout 5 seconds
Obviamente, assumimos que em algum lugar nas configurações isso é corrigido. Examinamos as configurações, a documentação e o pacote deb, mas a princípio eles não encontraram nada. Como resultado, a descrição da configuração desejada foi encontrada na quinta página dos resultados da pesquisa - examinamos o código novamente e encontramos o lugar certo. A configuração é esta:
ovs_vsctl_timeout = 30
Definimos por 30 segundos (eram 5) e tudo começou a funcionar um pouco melhor.
Aqui está outro argumento: quando você reinicia os componentes de rede, algumas configurações do Open vSwitch podem ser redefinidas. Isso, por exemplo, acontece com ovs-vsctl inactivity_probe. Também é um tempo limite, mas afeta as chamadas do próprio ovs-vsctl para o banco de dados. Nós o adicionamos ao systemd init, o que nos permitiu iniciar todos os switches com os parâmetros necessários na inicialização.
ovs-vsctl set Controller "br-int" inactivity_probe=30000
Sobre as configurações da pilha de rede
Também tivemos que nos afastar um pouco das configurações geralmente aceitas na pilha de rede, que usamos em nossos outros servidores.
Aqui está a configuração de quanto tempo leva para armazenar registros ARP em uma tabela:
net.ipv4.neigh.default.base_reachable_time = 60 net.ipv4.neigh.default.gc_stale_time=60
O valor padrão é 1 dia. Em geral, um esquema pode durar algumas semanas, mas por um dia, os esquemas podem ser recriados 4-6 vezes, enquanto a correspondência do endereço MAC e do endereço IP está mudando constantemente. Para que o lixo não se acumule, definimos o tempo para um minuto.
net.ipv4.conf.default.arp_notify = 1 net.nf_conntrack_max = 1000000 (default 262144) net.netfilter.nf_conntrack_max = 1000000 (default 262144)
Além disso, forçamos o envio de notificações ARP ao elevar a interface de rede. Também aumentamos a tabela conntrack, porque ao usar NAT e ip flutuante, não tínhamos o valor padrão. Aumentado para um milhão (com o padrão em 262 144), tudo ficou ainda melhor.
Corrigimos o tamanho da tabela MAC do próprio Open vSwitch:
ovs-vsctl set bridge bt-int other-config:mac-table-size=50000 (default 2048)

Depois de todas as configurações, 40% da carga se transformou em quase zero
rx-fluxo-hash
Para distribuir o processamento do tráfego udp entre todas as filas e threads do processador, incluímos rx-flow-hash. Nas placas de rede Intel, ou seja, no driver i40e, esta opção está desativada por padrão. Temos hipervisores com 72 núcleos em nossa infraestrutura e, se apenas um estiver ocupado, isso não será o ideal.
É feito assim:
ethtool -N eno50 rx-flow-hash udp4 sdfn

Uma conclusão importante: você pode configurar tudo. A configuração padrão se ajustará em algum momento (como fizemos), mas o problema com tempos limite tornou necessário a pesquisa. E isso é normal.
Regras de segurança
De acordo com os requisitos do serviço de segurança, todos os projetos na empresa têm regras pessoais e globais - existem muitos deles. Quando nos mudamos para o exterior de 300 máquinas virtuais para um hypervisor, tudo isso se transformou em 80 mil regras para iptables. Para o próprio iptables, isso não é um problema, mas o Neutron carrega essas regras do RabbitMQ em um fluxo (porque está escrito em Python e tudo fica triste com o multithreading). O agente de nêutrons congela, perde a conexão com o RabbitMQ e uma reação em cadeia por tempos limite. Após a recuperação, o Neutron solicita novamente todas as regras, inicia a sincronização e tudo começa novamente.
Junto com isso, o tempo para a criação de stands aumentou de 20 a 40 minutos para, no máximo, uma hora.
No início, acabamos de empacotar tudo com recuperações (já nesse estágio percebemos que o problema não podia ser resolvido tão rapidamente) e, em seguida, começamos a usar o FWaaS . Com isso, adotamos regras de segurança com nós de computação para separar os nós da rede onde o roteador está localizado.

Fonte - docs.openstack.org
Assim, dentro do projeto, há acesso total a tudo o que é necessário e regras de segurança são aplicadas para conexões externas. Portanto, reduzimos a carga no Neutron e voltamos a 20 a 30 minutos para criar um ambiente de teste.
Sumário
O OpenStack é uma coisa interessante em que você pode reciclar ferro, criar uma nuvem interna e criar algo mais com base nela. Além disso, há uma grande comunidade e um grupo ativo no Telegram , onde eles nos informavam sobre o tempo limite.
Isso é tudo. Faça perguntas, meus colegas e eu estamos prontos para responder e compartilhar nossa experiência.