Parte I. R extrai e desenha
Obviamente, o PostgreSQL foi criado desde o início como um DBMS universal, e não como um sistema OLAP especializado. Mas uma das grandes vantagens do Postgres é o suporte a linguagens de programação, com as quais você pode fazer algo com isso. Dada a abundância de linguagens processuais internas, ela simplesmente não tem igual. PL / R - implementação de servidor do
R - a linguagem favorita dos analistas - um deles. Mas mais sobre isso mais tarde.
R é uma linguagem incrível com tipos de dados peculiares - a
list , por exemplo, pode incluir não apenas dados de tipos diferentes, mas também funções (em geral, a linguagem é eclética e não falaremos sobre sua pertença a uma família em particular, para não causar discussões perturbadoras). Ele tem um tipo de dados
data.frame que simula uma tabela RDBMS - é uma matriz na qual as colunas contêm diferentes tipos de dados comuns no nível da coluna. Portanto (e por outros motivos), trabalhar com bancos de dados em R é bastante conveniente.
Trabalharemos na linha de comando no ambiente
RStudio e nos conectaremos ao PostgreSQL através do
driver ODBC RpostgreSQL . Eles são fáceis de instalar.
Como o R foi criado como uma espécie de variante da linguagem
S para quem está envolvido em estatística, também daremos exemplos de estatísticas simples com gráficos simples. Não temos o objetivo de introduzir a linguagem, mas existe o objetivo de mostrar a interação do
R e do PostgreSQL .
Existem três maneiras de processar dados armazenados no PostgreSQL.
Em primeiro lugar, você pode bombear dados do banco de dados por qualquer meio conveniente, empacotá-lo, digamos, em JSON - R entende-o - e processá-lo ainda mais em R. Isso geralmente não é a maneira mais eficiente e certamente não é a mais interessante, não vamos considerá-lo aqui.
Em segundo lugar, você pode se comunicar com o banco de dados - ler dele e despejar dados nele - do ambiente R como cliente, usando o driver ODBC / DBI, processando os dados em R. Vamos mostrar como isso é feito.
E, finalmente, você pode fazer o processamento com as ferramentas R já no servidor de banco de dados, usando PL / R como uma linguagem processual integrada. Isso faz sentido em vários casos, pois em R existem, por exemplo, meios convenientes de agregar dados que não estão no
pl/pgsql . Também mostraremos isso.
Uma abordagem comum é usar as 2ª e 3ª opções em diferentes fases do projeto: primeiro depure o código como um programa externo e depois transfira-o para a base.
Vamos começar. R linguagem interpretada. Portanto, você pode seguir as etapas ou despejar o código em um script. Uma questão de gosto: os exemplos neste artigo são curtos.
Primeiro, é claro, você precisa conectar o driver apropriado:
# install.packages("RPostgreSQL") require("RPostgreSQL") drv <- dbDriver("PostgreSQL")
A operação de atribuição parece em R, como você pode ver, peculiar. Em geral, em R a <- b, significa o mesmo que b -> a, mas a primeira maneira de escrever é mais comum.
Usaremos o banco de dados finalizado: a
demobase de transporte aéreo , usada pelos
materiais de treinamento do
Postgres Professional . Nesta página, você pode escolher a opção de banco de dados a ser avaliada (ou seja, tamanho) e ler sua descrição. Reproduzimos o esquema de dados por conveniência:
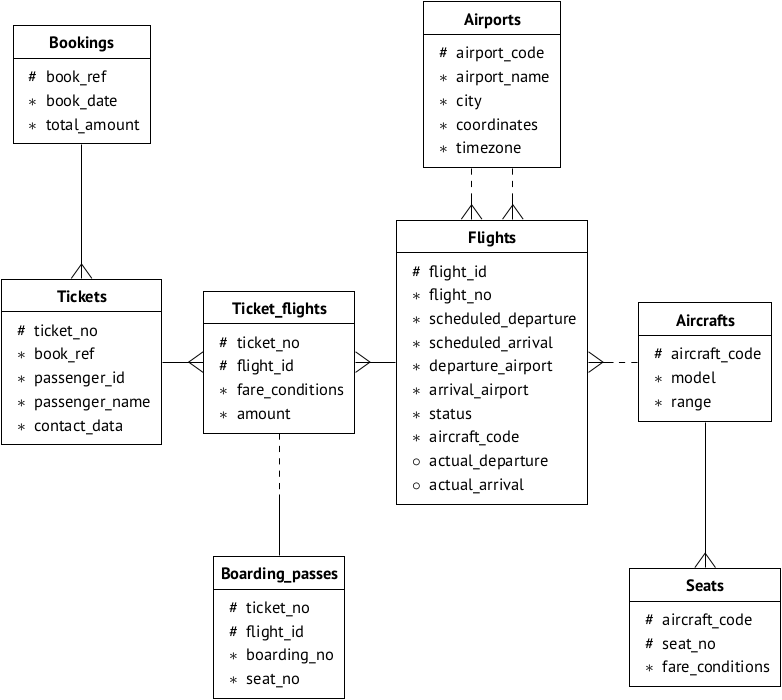
Suponha que a base esteja instalada no servidor 192.168.1.100 e seja chamada de
demo . Conectar:
con <- dbConnect(drv, dbname = "demo", host = "192.168.1.100", port = 5434, user = "u_r")
Nós continuamos. Vamos ver com essa solicitação para quais voos das cidades costumam se atrasar:
SELECT ap.city, avg(extract(EPOCH FROM f.actual_arrival) - extract(EPOCH FROM f.scheduled_arrival))/60.0 t FROM airports ap, flights f WHERE ap.airport_code = f.departure_airport AND f.scheduled_arrival < f.actual_arrival AND f.departure_airport = ap.airport_code GROUP BY ap.city ORDER BY t DESC LIMIT 10;
Para atrasar alguns minutos, usamos a construção
extract(EPOCH FROM ...) postgres
extract(EPOCH FROM ...) para extrair os segundos "absolutos" de um campo de
timestamp e divididos por 60,0, em vez de 60, para evitar descartar o restante ao dividir, entendido como inteiro.
EXTRACT MINUTE não pode ser usado, pois há atrasos por mais de uma hora. Nós calculamos a média do atraso pelo operador
avg .
Passamos o texto para a variável e enviamos a solicitação ao servidor:
sql1 <- "SELECT ... ;" res1 <- dbGetQuery(con, sql1)
Agora vamos descobrir de que forma a solicitação veio. Para fazer isso, a linguagem R possui uma função
class() class (res1)
Isso mostrará que o resultado foi compactado no tipo
data.frame , ou seja, lembramos, um análogo da tabela base: na verdade, é uma matriz com colunas de tipos arbitrários. A propósito, ela sabe os nomes das colunas, e as colunas, se houver, podem ser acessadas, por exemplo, assim:
print (res1$city)
É hora de pensar em como visualizar os resultados. Para fazer isso, você pode ver o que temos. Por exemplo, selecione a programação apropriada
nesta lista :
- Gráficos R-Bar (Bar)
- R-Boxplots (estoque)
- Histogramas R
- Gráficos de linha R (gráficos)
- Gráficos de dispersão-R (ponto)
Deve-se ter em mente que, para cada tipo de entrada, é fornecido um tipo de dados adequado para a imagem. Escolha um gráfico de barras (barras reclinadas). Requer dois vetores para valores axiais. O tipo "vetor" em R é simplesmente um conjunto de valores do mesmo tipo.
c() é um construtor de vetores.
Você pode gerar os dois vetores necessários a partir de um resultado do tipo
data.frame seguinte maneira:
Time <- res1[,c('t')] City <- res1[,c('city')] class (Time) class (City)
As expressões no lado direito parecem estranhas, mas é uma técnica conveniente. Além disso, várias expressões podem ser escritas de forma muito compacta em R. Entre colchetes antes da vírgula, o índice da série, após a vírgula - o índice da coluna. O fato de a vírgula não valer nada significa apenas que todos os valores serão selecionados na coluna correspondente.
A classe Time é
numeric e a classe City é
character . Estas são variedades de vetores.
Agora você pode fazer a própria visualização. Você deve especificar um arquivo de imagem.
png(file = "/home/igor_le/R/pics/bars_horiz.png")
Depois disso, segue um procedimento tedioso: defina os parâmetros (
par ) dos gráficos. E para não dizer que tudo nos pacotes gráficos R era intuitivo. Por exemplo, o parâmetro
las determina a posição dos rótulos com valores ao longo dos eixos em relação aos próprios eixos:
- 0 e, por padrão, paralelo aos eixos;
- 1 - sempre na horizontal;
- 2 - perpendicular aos eixos;
- 3 - sempre na vertical
Não pintaremos todos os parâmetros. Em geral, existem muitos: campos, escalas, cores - procure, experimente à vontade.
par(las=1) par(mai=c(1,2,1,1))
Por fim, construímos um gráfico a partir das colunas reclinadas:
barplot(Time, names.arg=City, horiz=TRUE, xlab=" ()", col="green", main=" ", border="red", cex.names=0.9)
Isso não é tudo. Devo dizer uma última coisa:
dev.off()

Para uma mudança, desenharemos ainda o diagrama de pontos do atraso. Remova LIMIT da solicitação, o restante é o mesmo. Mas um gráfico de dispersão precisa de um vetor, não de dois.
Dots <- res2[,c('t')] png(file = "/home/igor_le/R/scripts/scatter.png") plot(input5, xlab="",ylab="",main=" ") dev.off()
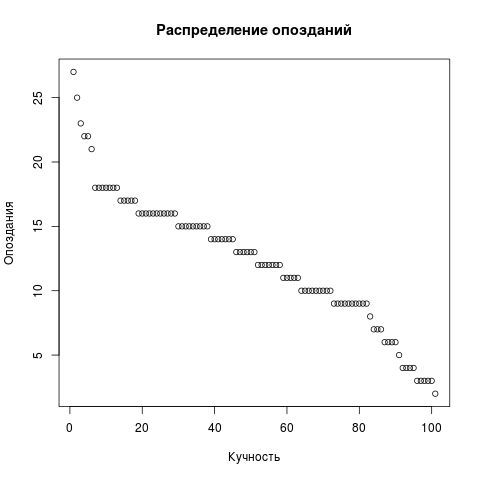
Para visualização, usamos pacotes padrão. É claro que R é uma linguagem popular e existem pacotes em torno do infinito. Você pode perguntar sobre os já instalados como este:
library()
Parte II R gera aposentados
R é conveniente usar não apenas para análise de dados, mas também para sua geração. Onde existem funções estatísticas ricas, não pode haver uma variedade de algoritmos para criar seqüências aleatórias. Em particular, você pode usar distribuições típicas (Gaussian) e não muito típicas (Zipf) para simular consultas ao banco de dados.
Mas mais sobre isso na próxima parte.