Este artigo se concentrará em escrever e dar suporte a uma especificação útil e relevante para um projeto de API REST, que economizará muito código extra e melhorará seriamente a integridade, a confiabilidade e a transparência do projeto como um todo.
O que é uma API RESTful?
Isso é um mito.
Sério, se você acha que seu projeto possui uma API RESTful, provavelmente está enganado. A idéia do RESTful é criar uma API que, em todos os aspectos, atenda às regras e restrições de arquitetura descritas pelo estilo REST, mas em condições reais isso é quase impossível .
Por um lado, o REST contém muitas definições vagas e ambíguas. Por exemplo, alguns termos dos dicionários de métodos HTTP e códigos de status não são utilizados para o objetivo pretendido na prática, enquanto muitos deles não são utilizados.
Por outro lado, o REST cria muitas restrições. Por exemplo, o uso atômico de recursos no mundo real não é racional para as APIs usadas por aplicativos móveis. Uma recusa completa em armazenar estado entre solicitações é essencialmente uma proibição do mecanismo de sessões do usuário usado em muitas APIs.
Mas espere, nem tudo é tão ruim!
Por que precisamos da especificação da API REST?
Apesar dessas deficiências, com uma abordagem razoável, o REST ainda permanece uma excelente base para o design de APIs realmente legais. Essa API deve ter uniformidade interna, uma estrutura clara, documentação conveniente e boa cobertura de teste de unidade. Tudo isso pode ser alcançado através do desenvolvimento de uma especificação de qualidade para sua API.
Na maioria das vezes, a especificação da API REST está associada à sua documentação . Diferentemente da primeira (que é uma descrição formal da sua API), a documentação deve ser lida por pessoas: por exemplo, desenvolvedores de um aplicativo móvel ou da Web usando sua API.
No entanto, além de realmente criar a documentação, uma descrição adequada da API ainda pode trazer muitos benefícios. No artigo, quero compartilhar exemplos de como, usando o uso competente da especificação, você pode:
- tornar o teste de unidade mais simples e mais confiável;
- configurar pré-processamento e validação de dados de entrada;
- automatize a serialização e garanta a integridade das respostas;
- e até aproveite a digitação estática.
Openapi
O formato geralmente aceito para descrever a API REST hoje é o OpenAPI , também conhecido como Swagger . Esta especificação é um único arquivo no formato JSON ou YAML, consistindo em três seções:
- um cabeçalho contendo o nome, descrição e versão da API, além de informações adicionais;
- uma descrição de todos os recursos, incluindo seus identificadores, métodos HTTP, todos os parâmetros de entrada, bem como códigos e formatos do corpo da resposta, com links para definições;
- todas as definições de objetos no formato JSON Schema que podem ser usadas nos parâmetros de entrada e nas respostas.
O OpenAPI tem uma séria desvantagem - a complexidade da estrutura e, frequentemente, a redundância . Para um projeto pequeno, o conteúdo do arquivo JSON de especificação pode aumentar rapidamente para vários milhares de linhas. Não é possível manter este arquivo manualmente neste formulário. Essa é uma séria ameaça à própria idéia de manter uma especificação atualizada à medida que a API evolui.
Existem muitos editores visuais que permitem descrever a API e formar a especificação OpenAPI resultante. Por sua vez, serviços adicionais e soluções em nuvem são baseados neles, por exemplo, Swagger , Apiary , Stoplight , Restlet e outros.
No entanto, para mim, esses serviços não eram muito convenientes devido à dificuldade de editar rapidamente a especificação e combiná-la com o processo de escrita do código. Outro ponto negativo é a dependência do conjunto de funções de cada serviço específico. Por exemplo, é quase impossível implementar testes de unidade completos somente por meio de um serviço em nuvem. A geração de código e até a criação de "plugs" para terminais, embora pareça muito possível, são praticamente inúteis na prática.
Tinyspec
Neste artigo, usarei exemplos baseados no formato de descrição da API REST nativa - tinyspec . O formato são pequenos arquivos que descrevem os pontos de extremidade e modelos de dados usados no projeto com uma sintaxe intuitiva. Os arquivos são armazenados ao lado do código, o que permite verificar com eles e editá-los diretamente no processo de escrita. Ao mesmo tempo, o tinyspec é automaticamente compilado em uma OpenAPI de pleno direito, que pode ser usada imediatamente no projeto. É hora de dizer exatamente como.
Neste artigo, darei exemplos de Node.js (koa, express) e Ruby on Rails, embora essas práticas se apliquem à maioria das tecnologias, incluindo Python, PHP e Java.
Quando a especificação é incrivelmente útil
1. Testes unitários de endpoints
O BDD (Behavior-driven Development) é ideal para o desenvolvimento de uma API REST. A maneira mais conveniente de escrever testes de unidade não é para classes, modelos e controladores individuais, mas para pontos de extremidade específicos. Em cada teste, você emula uma solicitação HTTP real e verifica a resposta do servidor. No Node.js, para emular solicitações de teste, há supertest e chai-http , no Ruby on Rails - no ar .
Suponha que tenhamos um esquema de User e um ponto de extremidade GET /users que retorne todos os usuários. Aqui está a sintaxe tinyspec que descreve isso:
- Arquivo User.models.tinyspec :
User {name, isAdmin: b, age?: i}
- Arquivo users.endpoints.tinyspec :
GET /users => {users: User[]}
É assim que nosso teste será:
Node.js
describe('/users', () => { it('List all users', async () => { const { status, body: { users } } = request.get('/users'); expect(status).to.equal(200); expect(users[0].name).to.be('string'); expect(users[0].isAdmin).to.be('boolean'); expect(users[0].age).to.be.oneOf(['boolean', null]); }); });
Ruby on Rails
describe 'GET /users' do it 'List all users' do get '/users' expect_status(200) expect_json_types('users.*', { name: :string, isAdmin: :boolean, age: :integer_or_null, }) end end
Quando temos uma especificação que descreve os formatos de resposta do servidor, podemos simplificar o teste e simplesmente verificar a resposta nessa especificação . Para fazer isso, aproveitaremos o fato de que nossos modelos tinyspec são transformados em definições OpenAPI, que por sua vez correspondem ao formato do esquema JSON.
Qualquer objeto literal em JS (ou Hash em Ruby, um dict em Python, uma matriz associativa em PHP e até um Map em Java) pode ser testado quanto à conformidade com um esquema JSON. E existem até plugins correspondentes para estruturas de teste, por exemplo, jest-ajv (npm), chai-ajv-json-schema (npm) e json_matchers (rubygem) para o RSpec.
Antes de usar os esquemas, você deve conectá-los ao projeto. Primeiro, geraremos o arquivo de especificação openapi.json com base no tinyspec (essa ação pode ser executada automaticamente antes de cada teste):
tinyspec -j -o openapi.json
Node.js
Agora podemos usar o JSON recebido no projeto e pegar a chave de definitions , que contém todos os esquemas JSON. Os esquemas podem conter referências cruzadas ( $ref ); portanto, se tivermos esquemas aninhados (por exemplo, Blog {posts: Post[]} ), precisamos "expandi-los" para usá-los nas validações. Para fazer isso, usaremos json-schema-deref-sync (npm).
import deref from 'json-schema-deref-sync'; const spec = require('./openapi.json'); const schemas = deref(spec).definitions; describe('/users', () => { it('List all users', async () => { const { status, body: { users } } = request.get('/users'); expect(status).to.equal(200);
Ruby on Rails
json_matchers pode manipular os links $ref , mas requer arquivos separados com esquemas no sistema de arquivos de uma certa maneira, então primeiro você precisa "dividir" o swagger.json em muitos arquivos pequenos (mais sobre isso aqui ):
Depois disso, podemos escrever nosso teste assim:
describe 'GET /users' do it 'List all users' do get '/users' expect_status(200) expect(result[:users][0]).to match_json_schema('User') end end
Nota: escrever testes dessa maneira é incrivelmente conveniente. Especialmente se o seu IDE oferecer suporte à execução de testes e depuração (como WebStorm, RubyMine e Visual Studio). Portanto, você não pode usar nenhum outro software e todo o ciclo de desenvolvimento da API é reduzido para três etapas consecutivas:
- design de especificação (por exemplo, em tinyspec);
- escrever um conjunto completo de testes para pontos finais adicionados / alterados;
- desenvolvendo código que satisfaça todos os testes.
2. Validação de entrada
O OpenAPI descreve o formato não apenas de respostas, mas também de dados de entrada. Isso nos permite validar os dados recebidos do usuário durante a solicitação.
Suponha que tenhamos a seguinte especificação que descreve a atualização dos dados do usuário, bem como todos os campos que podem ser alterados:
Anteriormente, examinamos os plugins para validação em testes, no entanto, para casos mais gerais, existem módulos de validação ajv (npm) e json-schema (rubygem), vamos usá-los e escrever um controlador com validação.
Node.js (Koa)
Este é um exemplo para Koa , o sucessor do Express, mas para o Express, o código será semelhante.
import Router from 'koa-router'; import Ajv from 'ajv'; import { schemas } from './schemas'; const router = new Router();
Neste exemplo, se os dados de entrada não atenderem à especificação, o servidor retornará uma resposta 500 Internal Server Error ao cliente. Para impedir que isso aconteça, podemos interceptar o erro do validador e formar nossa própria resposta, que conterá informações mais detalhadas sobre campos específicos que não passaram no teste e também está em conformidade com a especificação .
Adicione uma descrição do modelo FieldsValidationError no arquivo FieldsValidationError :
Error {error: b, message} InvalidField {name, message} FieldsValidationError < Error {fields: InvalidField[]}
E agora nós o indicamos como uma das possíveis respostas de nosso endpoint:
PATCH /users/:id {user: UserUpdate} => 200 {success: b} => 422 FieldsValidationError
Essa abordagem permitirá que você escreva testes de unidade que verifiquem a correção da formação de erros com dados incorretos recebidos do cliente.
3. Serialização de modelos
Quase todas as estruturas de servidor modernas usam o ORM de uma maneira ou de outra. Isso significa que a maioria dos recursos usados na API dentro do sistema é apresentada na forma de modelos, suas instâncias e coleções.
O processo de geração de uma representação JSON dessas entidades para transmissão na resposta da API é chamado serialização . Existem vários plugins para estruturas diferentes que executam funções de serialização, por exemplo: sequelizar para json (npm), atos_as_api (rubygem), jsonapi-rails (rubygem). De fato, esses plug-ins permitem que um modelo específico especifique uma lista de campos que devem ser incluídos no objeto JSON, além de regras adicionais, por exemplo, para renomeá-los ou calcular valores dinamicamente.
As dificuldades começam quando precisamos ter várias representações JSON diferentes do mesmo modelo ou quando um objeto contém entidades aninhadas - associações. É necessário herdar, reutilizar e vincular serializadores .
Módulos diferentes resolvem esses problemas de maneiras diferentes, mas vamos pensar: a especificação pode nos ajudar novamente? De fato, de fato, todas as informações sobre os requisitos para representações JSON, todas as combinações possíveis de campos, incluindo entidades aninhadas, já estão nele. Para que possamos escrever um serializador automático.
Chamo a atenção um pequeno módulo sequelize-serialize (npm), que permite fazer isso nos modelos Sequelize. Ele utiliza uma instância do modelo ou matriz, bem como o circuito necessário, e constrói iterativamente um objeto serializado, levando em consideração todos os campos necessários e usando circuitos aninhados para as entidades associadas.
Portanto, suponha que seja necessário retornar da API a todos os usuários que têm postagens no blog, incluindo comentários nessas postagens. Descrevemos isso usando a seguinte especificação:
Agora podemos criar a consulta usando Sequelize e retornar um objeto serializado que corresponda exatamente à especificação descrita acima:
import Router from 'koa-router'; import serialize from 'sequelize-serialize'; import { schemas } from './schemas'; const router = new Router(); router.get('/blog/users', async (ctx) => { const users = await User.findAll({ include: [{ association: User.posts, required: true, include: [Post.comments] }] }); ctx.body = serialize(users, schemas.UserWithPosts); });
É quase mágico, certo?
4. Digitação estática
Se você é tão legal que está usando o TypeScript ou o Flow, já deve ter se perguntado: "E meus queridos tipos estáticos?!" . Usando os módulos sw2dts ou swagger-to-flowtype, você pode gerar todas as definições necessárias com base nos esquemas JSON e usá-las para tipagem estática de testes, dados de entrada e serializadores.
tinyspec -j sw2dts ./swagger.json -o Api.d.ts --namespace Api
Agora podemos usar tipos em controladores:
router.patch('/users/:id', async (ctx) => { // Specify type for request data object const userData: Api.UserUpdate = ctx.request.body.user; // Run spec validation await validate(schemas.UserUpdate, userData); // Query the database const user = await User.findById(ctx.params.id); await user.update(userData); // Return serialized result const serialized: Api.User = serialize(user, schemas.User); ctx.body = { user: serialized }; });
E nos testes:
it('Update user', async () => { // Static check for test input data. const updateData: Api.UserUpdate = { name: MODIFIED }; const res = await request.patch('/users/1', { user: updateData }); // Type helper for request response: const user: Api.User = res.body.user; expect(user).to.be.validWithSchema(schemas.User); expect(user).to.containSubset(updateData); });
Observe que as definições de tipo geradas podem ser usadas não apenas no projeto da API, mas também em projetos de aplicativos clientes para descrever os tipos de funções nas quais a API trabalha. Os desenvolvedores angulares de clientes ficarão especialmente satisfeitos com esse presente.
5. Conversão de tipo da string de consulta
Se, por algum motivo, sua API aceitar solicitações com o tipo MIME application/x-www-form-urlencoded e não application/json , o corpo da solicitação terá a seguinte aparência:
param1=value¶m2=777¶m3=false
O mesmo se aplica aos parâmetros de consulta (por exemplo, em solicitações GET). Nesse caso, o servidor da Web não poderá reconhecer automaticamente os tipos - todos os dados estarão na forma de cadeias ( aqui está uma discussão no repositório do módulo qpm npm), portanto, após a análise, você obterá o seguinte objeto:
{ param1: 'value', param2: '777', param3: 'false' }
Nesse caso, a solicitação não será validada de acordo com o esquema, o que significa que será necessário verificar manualmente se cada parâmetro tem o formato correto e trazê-lo para o tipo necessário.
Como você pode imaginar, isso pode ser feito usando os mesmos esquemas de nossa especificação. Imagine que temos esse ponto final e esquema:
Aqui está um exemplo de uma solicitação para esse terminal
GET /posts?search=needle&offset=10&limit=1&filter[isRead]=true
Vamos escrever uma função castQuery , que castQuery todos os parâmetros nos tipos necessários para nós. Será algo parecido com isto:
function castQuery(query, schema) { _.mapValues(query, (value, key) => { const { type } = schema.properties[key] || {}; if (!value || !type) { return value; } switch (type) { case 'integer': return parseInt(value, 10); case 'number': return parseFloat(value); case 'boolean': return value !== 'false'; default: return value; } }); }
Sua implementação mais completa, com suporte para esquemas aninhados, matrizes e tipos null está disponível no cast-with-schema (npm). Agora podemos usá-lo em nosso código:
router.get('/posts', async (ctx) => {
Observe como das quatro linhas do código do terminal, os três usam esquemas da especificação.
Melhores práticas
Esquemas separados para criar e modificar
Normalmente, os esquemas que descrevem a resposta do servidor são diferentes daqueles que descrevem a entrada usada para criar e modificar modelos. Por exemplo, a lista de campos disponíveis para solicitações POST e PATCH deve ser estritamente limitada, enquanto nas solicitações PATCH , geralmente todos os campos do esquema são opcionais. Os esquemas que determinam a resposta podem ser mais gratuitos.
A geração automática de terminais CRUDL tinyspec usa os postfixes New e Update . User* podem ser definidos da seguinte maneira:
User {id, email, name, isAdmin: b} UserNew !{email, name} UserUpdate !{email?, name?}
Tente não usar os mesmos esquemas para diferentes tipos de ações, a fim de evitar problemas acidentais de segurança devido à reutilização ou herança de esquemas antigos.
Semântica nos nomes de esquema
O conteúdo dos mesmos modelos pode variar em diferentes pontos de extremidade. Use os postfixes With* e For* nos nomes dos esquemas para mostrar como eles diferem e para que servem. Nos modelos tinyspec também podem ser herdados um do outro. Por exemplo:
User {name, surname} UserWithPhotos < User {photos: Photo[]} UserForAdmin < User {id, email, lastLoginAt: d}
As correções posteriores podem ser variadas e combinadas. O principal é que o nome reflete a essência e simplifica a familiaridade com a documentação.
Separação de terminais por tipo de cliente
Geralmente, os mesmos pontos de extremidade retornam dados diferentes, dependendo do tipo de cliente ou da função do usuário que acessa o ponto de extremidade. Por exemplo, os pontos finais de GET /users e GET /messages podem ser muito diferentes para os usuários do seu aplicativo móvel e para os gerentes de back office. Ao mesmo tempo, alterar o nome do terminal em si pode ser muita complicação.
Para descrever o mesmo terminal várias vezes, você pode adicionar seu tipo entre colchetes após o caminho. Além disso, é útil usar tags: isso ajudará a dividir a documentação de seus pontos de extremidade em grupos, cada um dos quais será projetado para um grupo específico de clientes da sua API. Por exemplo:
Mobile app: GET /users (mobile) => UserForMobile[] CRM admin panel: GET /users (admin) => UserForAdmin[]
Documentação da API REST
Depois de ter uma especificação no formato tinyspec ou OpenAPI, você pode gerar uma documentação bonita em HTML e publicá-la para o prazer dos desenvolvedores que usam sua API.
Além dos serviços em nuvem mencionados anteriormente, existem ferramentas de CLI que convertem o OpenAPI 2.0 em HTML e PDF, após o qual você pode baixá-lo para qualquer hospedagem estática. Exemplos:
Você conhece mais exemplos? Compartilhe-os nos comentários.
Infelizmente, o OpenAPI 3.0, lançado há um ano, ainda é pouco suportado e não pude encontrar nenhum exemplo digno de documentação com base nele: nem entre soluções em nuvem nem entre as ferramentas CLI. Pelo mesmo motivo, o OpenAPI 3.0 ainda não é suportado no tinyspec.
Publicar no GitHub
Uma das maneiras mais fáceis de publicar documentação é o GitHub Pages . Apenas ative o suporte à página estática para o diretório /docs nas configurações do seu repositório e armazene a documentação HTML nesta pasta.
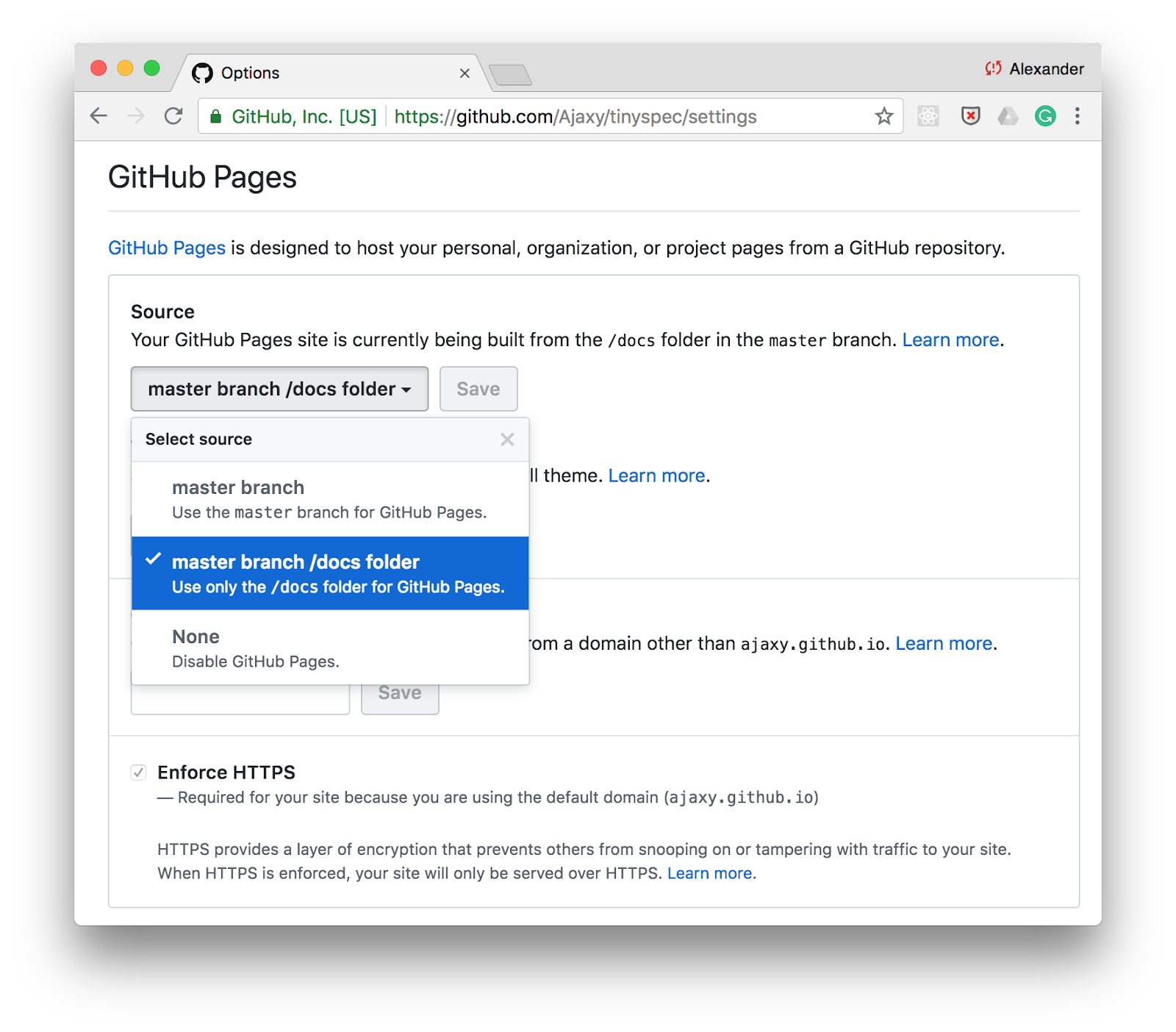
Você pode adicionar um comando para gerar documentação através de tinyspec ou outra ferramenta CLI nos scripts em package.json e atualizar a documentação com cada confirmação:
"scripts": { "docs": "tinyspec -h -o docs/", "precommit": "npm run docs" }
Integração contínua
Você pode incluir a geração de documentação no ciclo do IC e publicá-la, por exemplo, no Amazon S3 em diferentes endereços, dependendo do ambiente ou versão da sua API, por exemplo: /docs/2.0 , /docs/stable , /docs/staging .
Nuvem Tinyspec
Se você gostou da sintaxe tinyspec, pode se registrar como adotante antecipado em tinyspec.cloud . Vamos construir com base em um serviço em nuvem e CLI para publicação automática de documentação com uma ampla seleção de modelos e a capacidade de desenvolver nossos próprios modelos.
Conclusão
O desenvolvimento de uma API REST é talvez a atividade mais agradável de todas as que existem no processo de trabalhar em serviços móveis e da Web modernos. Não há zoológico de navegadores, sistemas operacionais e tamanhos de tela, tudo está completamente sob nosso controle - "ao seu alcance".
Manter a especificação atual e os bônus na forma de várias automações, fornecidas ao mesmo tempo, torna esse processo ainda mais agradável. Essa API se torna estruturada, transparente e confiável.
De fato, mesmo se estamos envolvidos na criação de um mito, por que não o fazemos bonito?