Tarefas longas e monótonas são frequentemente encontradas no trabalho, cuja solução é necessária para muitas pessoas. Por exemplo, decifre várias centenas de gravações de áudio, marque milhares de imagens ou filtre comentários, cujo número está em constante crescimento. Para esses fins, você pode manter dezenas de funcionários em período integral. Mas todos eles precisam ser encontrados, selecionados, motivados, controlados, assegurados desenvolvimento e crescimento na carreira. E se a quantidade de trabalho for reduzida, eles deverão ser reciclados ou demitidos.
Em muitos casos, especialmente se não for necessário treinamento especial, esse trabalho pode ser realizado pelos executores da plataforma de crowdsourcing de
Toloka , Yandex. Esse sistema é facilmente escalável: se houver menos tarefas de um cliente, os tolokers irão para outro; se o número de tarefas aumentar, eles ficarão felizes.
Sob o corte, há exemplos de como a Toloka ajuda a Yandex e outras empresas a desenvolver seus produtos. Todos os títulos são clicáveis - os links levam a relatórios.

O MIPT usou o Toloka para avaliar a qualidade dos bots de bate-papo como parte do hackathon DeepHack.Chat. Envolveu 6 equipes. A tarefa era desenvolver um chatbot que pudesse falar sobre si com base no perfil fornecido, com uma breve descrição das características pessoais.

Os tolokers e os bots receberam perfis e tiveram que fingir ser uma pessoa no diálogo, cuja descrição foi dada lá, falar sobre si mesmos e aprender mais sobre o interlocutor. Os participantes do diálogo não viram os perfis um do outro.
Somente usuários que passaram no teste de proficiência em inglês tiveram permissão para a tarefa, já que todos os bots de bate-papo do hackathon falavam inglês. Era impossível organizar um diálogo com o bot diretamente através do Toloka, portanto, na tarefa, foi fornecido um link para o canal do Telegram onde o bot de bate-papo foi lançado.
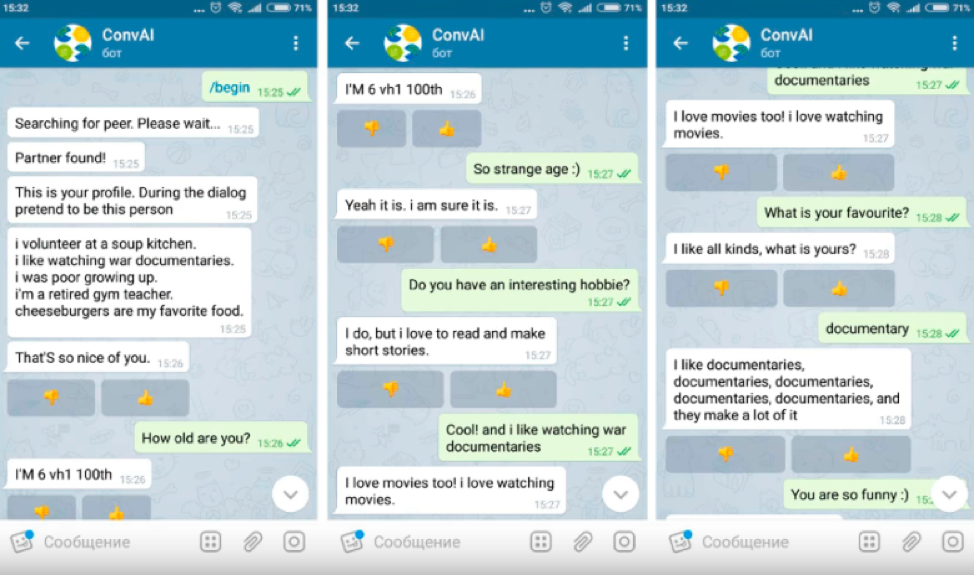
Após conversar com o bot, o usuário recebeu um ID de diálogo, que, juntamente com a avaliação do diálogo, foi inserido no Toloka como resposta.
Para excluir tolokers desonestos, era necessário verificar o quão bem o usuário falava com o bot. Para fazer isso, criamos uma tarefa separada, na qual os executantes lêem os diálogos e avaliamos o comportamento do usuário, ou seja, o atirador da tarefa anterior.
Durante o hackathon, as equipes enviaram seus bots de bate-papo. Durante o dia, os tolkers os testaram, contaram a qualidade e relataram a pontuação às equipes, após o que os desenvolvedores editaram o comportamento de seus sistemas.
Em quatro dias, os sistemas hackathon melhoraram significativamente. No primeiro dia, os bots tiveram respostas inadequadas e duplicadas; no quarto dia, as respostas se tornaram mais adequadas e detalhadas. Bots aprenderam não apenas a responder perguntas, mas também a fazer suas próprias.
Exemplo de diálogo no primeiro dia da hackathon:

No quarto dia:

Estatísticas: a avaliação durou 4 dias, participaram cerca de 200 tolkers e foram processados 1800 diálogos. Eles gastaram US $ 180 na primeira tarefa e US $ 15 na segunda. A porcentagem de diálogos válidos acabou sendo maior do que quando se trabalha com voluntários.
Uma tarefa importante do criador do drone é ensiná-lo a extrair informações sobre objetos ao redor dos dados que ele recebe dos sensores. Durante a viagem, o carro registra tudo o que vê ao redor. Esses dados são lançados na nuvem, onde as análises primárias são feitas e, em seguida, passam para o pós-processamento, que inclui a marcação. Os dados rotulados são enviados para algoritmos de aprendizado de máquina, o resultado é retornado à máquina e o ciclo se repete, melhorando a qualidade do reconhecimento de objetos.
Existem muitos objetos na cidade, todos eles precisam ser marcados. Essa tarefa requer certas habilidades e leva muito tempo, e dezenas de milhares de fotos são necessárias para treinar uma rede neural. Eles podem ser obtidos de conjuntos de dados abertos, mas são coletados no exterior, para que as imagens não correspondam à realidade russa. Você pode comprar imagens marcadas a partir de US $ 4, mas a marcação no Tolok foi cerca de 10 vezes mais barata.
Como no Tolok você pode incorporar qualquer interface e transferir dados via API, os desenvolvedores inseriram seu próprio editor visual, que possui camadas, transparência, seleção, ampliação e divisão em classes. Isso várias vezes aumentou a velocidade e a qualidade da marcação.
Além disso, a API permite que você divida automaticamente tarefas em tarefas mais simples e colete o resultado em partes. Por exemplo, antes de marcar uma imagem, você pode marcar quais objetos estão nela. Isso dará uma compreensão de quais classes marcar a imagem.
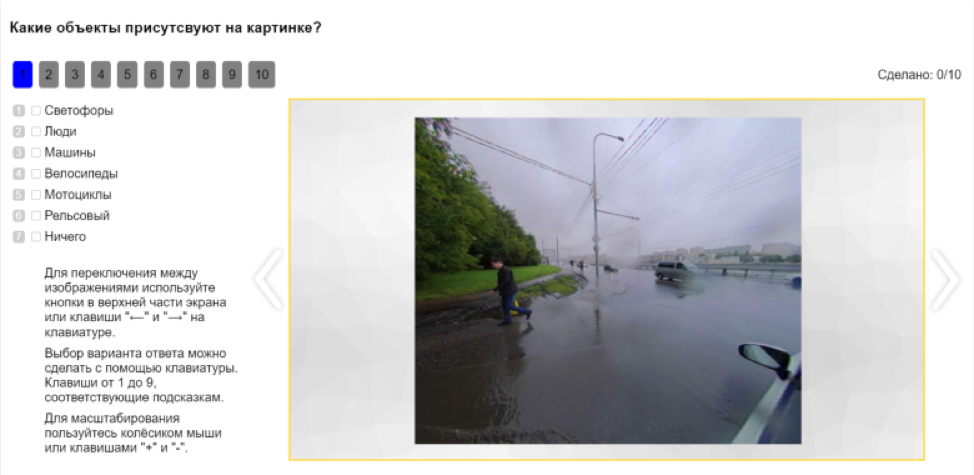
Depois disso, os objetos na imagem podem ser classificados. Por exemplo, para oferecer aos atiradores uma seleção de fotos onde há pessoas e pedir que eles esclareçam se são pedestres, ciclistas, motociclistas ou outra pessoa.

Quando o tolker tiver concluído a marcação, ele deverá ser verificado. Para fazer isso, são criadas tarefas de teste que são oferecidas a outros artistas.

Não apenas os tolokers, mas também as redes neurais estão envolvidas na marcação. Alguns deles já aprenderam a lidar com essa tarefa não pior que as pessoas. Mas a qualidade de seu trabalho também precisa ser avaliada. Portanto, nas tarefas, além das imagens marcadas com tolokers, também são marcadas com uma rede neural.
Portanto, Toloka se integra diretamente ao processo de aprendizado de redes neurais e se torna parte do pipeline de todo aprendizado de máquina.
Ozon usa Toloka para criar uma amostra de referência. Isso é para vários propósitos.
• Avaliação da qualidade do novo mecanismo de busca.
• Determinando o modelo de classificação mais eficaz.
• Melhorar a qualidade do algoritmo de pesquisa usando o aprendizado de máquina.
A primeira amostra de teste foi feita manualmente - recebemos 100 solicitações e as marcamos. Mesmo uma amostra tão pequena ajudou a identificar problemas de pesquisa e determinar os critérios de avaliação. A empresa queria criar sua própria ferramenta para avaliar a qualidade da pesquisa, contratar avaliadores e treiná-los, mas isso levaria muito tempo, por isso decidimos escolher uma plataforma de crowdsourcing pronta para uso.
O estágio mais difícil na preparação da tarefa para os tolokers foi o treinamento - mesmo os funcionários da empresa não puderam realizar a primeira tarefa de teste. Após receber o feedback da equipe, desenvolvemos um novo teste: desenvolvemos o treinamento de tarefas simples a complexas e compiladas, levando em consideração as importantes qualidades do artista para a empresa.
Para eliminar erros, Ozon realizou um teste. A tarefa consistiu em três blocos - treinamento, controle com um limite de 60% das respostas corretas e a tarefa principal com um limite de 80% das respostas corretas. Para melhorar a qualidade da amostra, uma tarefa foi oferecida a cinco artistas.
Estatísticas de execução de teste: 350 tarefas em 40 minutos. O orçamento era de US $ 12. A primeira etapa contou com a participação de 147 artistas, 77 foram treinados, 12 adquiriram a habilidade e realizaram a tarefa principal.
O cenário do lançamento principal se tornou mais complicado: participaram não apenas novos marcadores, mas também aqueles que receberam a habilidade necessária na fase de teste. O primeiro foi ao longo da cadeia padrão, o segundo foi imediatamente admitido nas principais tarefas. No lançamento principal, foram adicionadas habilidades adicionais - a porcentagem de respostas corretas na amostra principal e a opinião da maioria. A tarefa ainda foi oferecida a cinco artistas.
Principais estatísticas de lançamento: 40.000 empregos em um mês. O orçamento era de 1150 dólares. 1117 tolkers chegaram ao projeto, 18 adquiriram habilidades, 6 obtiveram acesso ao maior pool principal e o avaliaram.
Agora, o trabalho de Ozok em Tolok é assim:
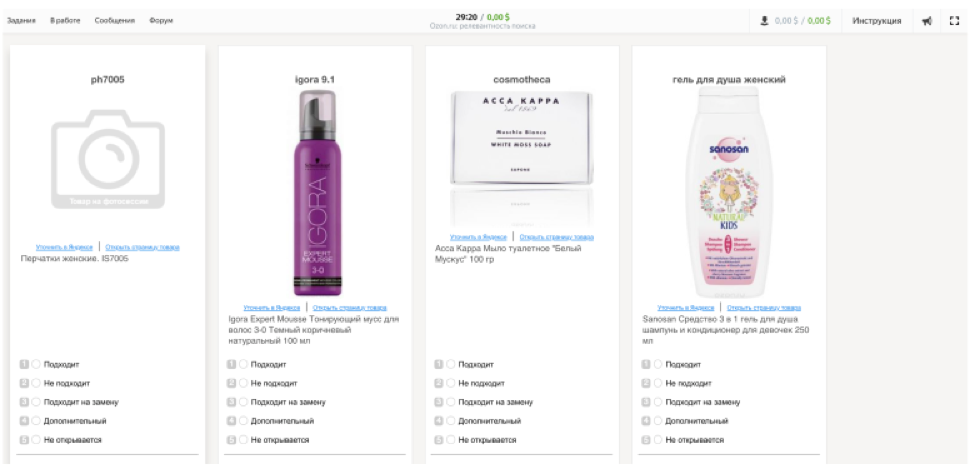
O contratante vê a consulta de pesquisa e 9 produtos dos resultados da pesquisa. Sua tarefa é escolher uma das classificações - “adequado”, “inadequado”, “adequado para substituição”, “adicional”, “não abre”. Uma classificação final ajuda a identificar problemas técnicos no site. Para simular o comportamento do usuário com a maior precisão possível, os desenvolvedores por meio do iframe recriaram a interface da loja online.
Paralelamente ao lançamento da tarefa no Toloka, a marcação das consultas de pesquisa foi realizada usando as regras. A ênfase estava nas consultas populares, a fim de melhorar principalmente a emissão delas.
A marcação pelas regras possibilitou a obtenção rápida de dados em um pequeno número de consultas e apresentou bons resultados nas consultas principais. Mas também havia contras: solicitações ambíguas não podem ser estimadas pelas regras, existem muitas situações controversas. Além disso, a longo prazo, esse método tem sido bastante caro.
A marcação com a ajuda de pessoas cobre essas desvantagens. No Tolok, você pode coletar as opiniões de um grande número de artistas, a avaliação é mais graduada, o que permite que você trabalhe mais profundamente com a extradição. Após a configuração inicial, a plataforma trabalha de forma estável e processa grandes quantidades de dados.
O trabalho manual e os mecanismos de inteligência artificial não se opõem. Quanto mais a inteligência artificial se desenvolve, mais trabalho manual é necessário para seu treinamento. Por outro lado, quanto mais treinadas as redes neurais, mais tarefas de rotina podem ser automatizadas, salvando uma pessoa delas.
Quase qualquer tarefa, mesmo volumosa, pode ser dividida em muitas pequenas e construída com base no crowdsourcing. A maioria das tarefas resolvidas no
Tolok é o primeiro passo para o treinamento de modelos e a automação de processos nos dados coletados pelas pessoas.
Na próxima publicação sobre este tópico, falaremos sobre como o crowdsourcing é usado para treinar Alice, moderar comentários e monitorar a conformidade com as regras do Yandex.Buses.