O aprendizado de máquina permite tornar o serviço muito mais conveniente para os usuários. Não é tão difícil começar a implementar recomendações; os primeiros resultados podem ser obtidos mesmo sem uma infraestrutura estabelecida; o principal é começar. E só então para construir um sistema em grande escala. Foi assim que tudo começou na Booking.com. E o que resultou, quais abordagens estão sendo usadas agora, como os modelos estão sendo introduzidos na produção e quais monitorar, afirmou Viktor Bilyk ao HighLoad ++ Siberia. Possíveis erros e problemas não foram deixados para trás no relatório, ajudará alguém a contornar o raso e alguém terá novas idéias.
 Sobre o palestrante:
Sobre o palestrante: Victor Bilyk introduz produtos de aprendizado de máquina em operação comercial na Booking.com.
Primeiro, vamos ver onde a Booking.com usa o aprendizado de máquina em quais produtos.
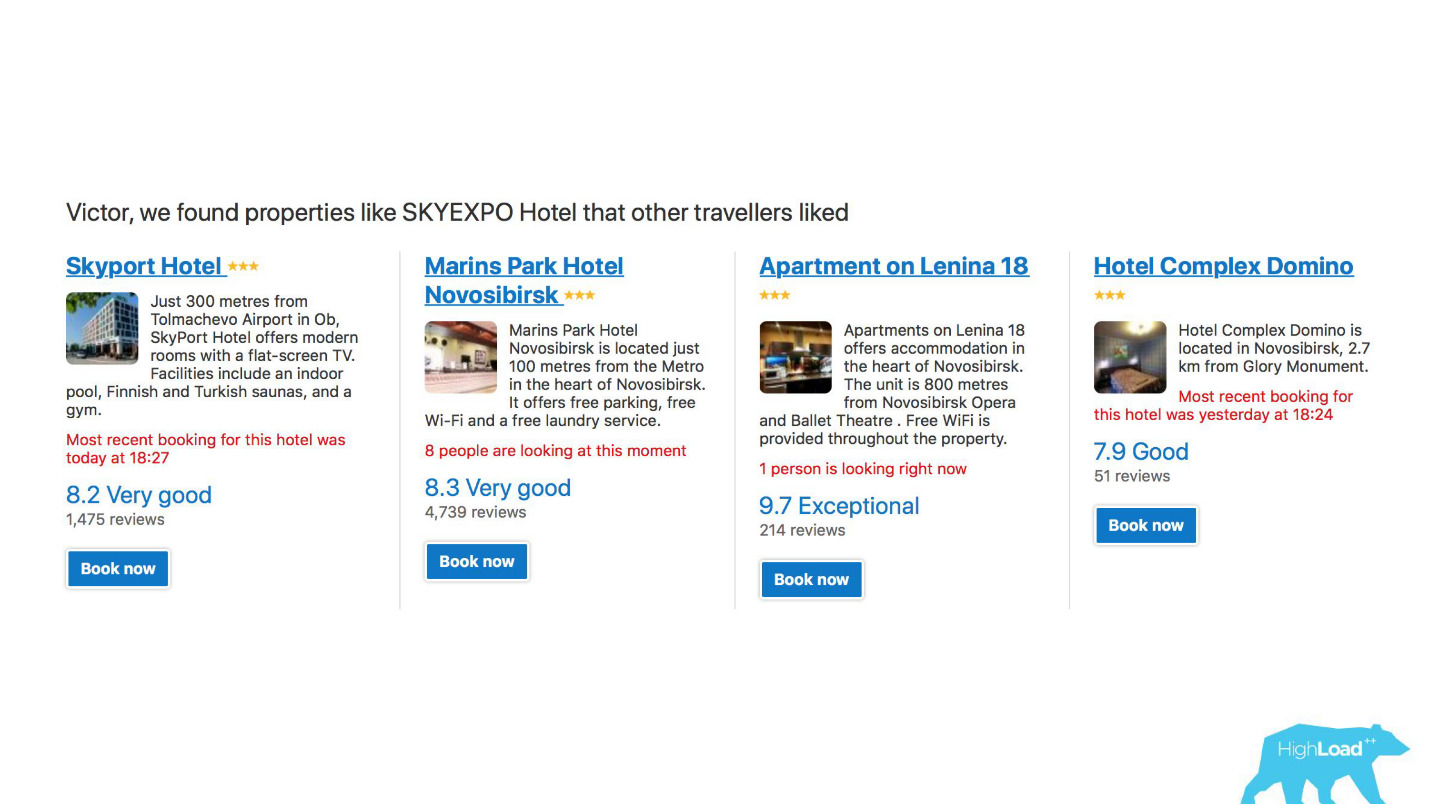
Em primeiro lugar, esse é um grande número de sistemas de recomendação para hotéis, destinos, datas e em diferentes pontos do funil de vendas e em diferentes contextos. Por exemplo, estamos tentando adivinhar para onde você vai quando não inseriu nada na linha de pesquisa.

Esta é uma captura de tela na minha conta e definitivamente visitarei duas dessas áreas este ano.
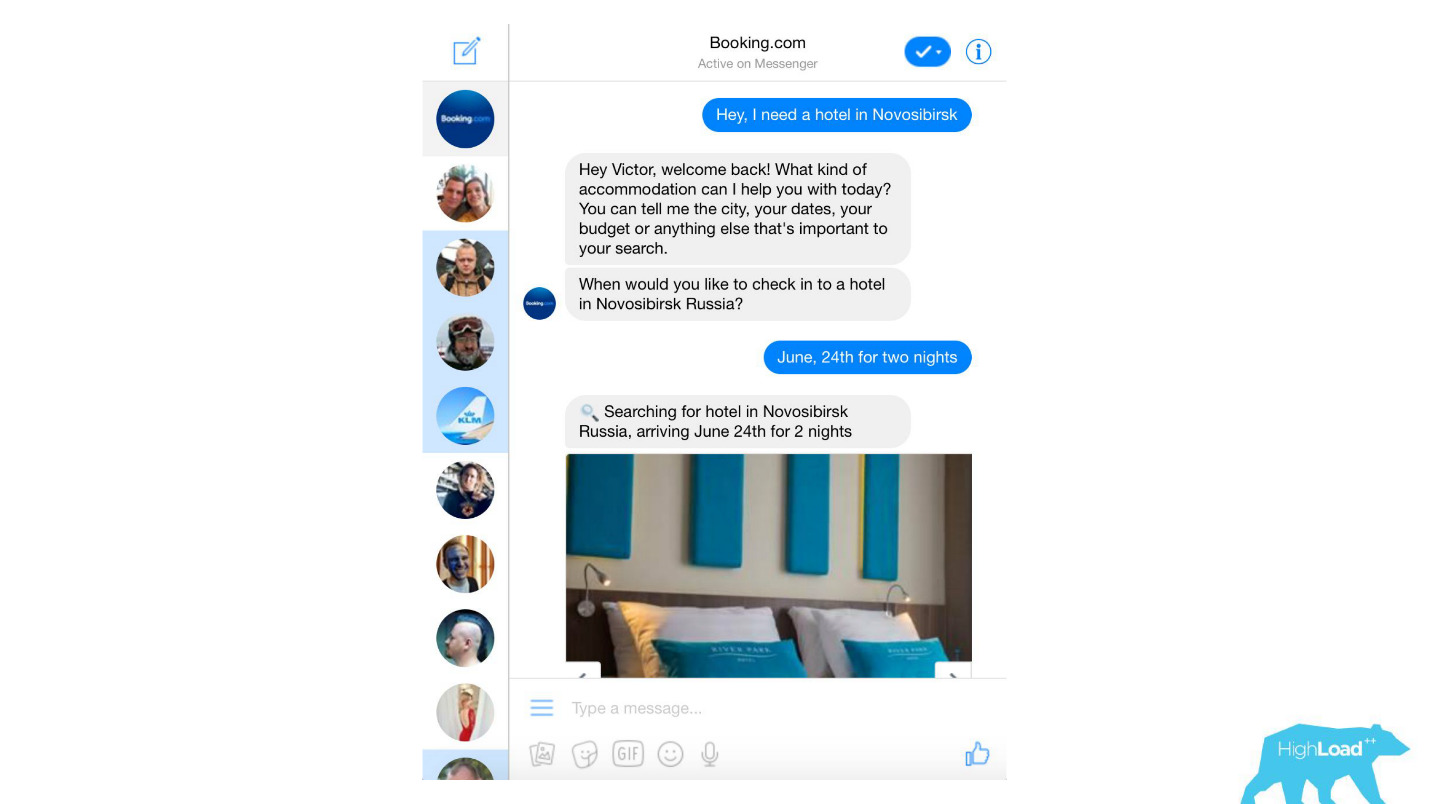
Processamos quase todas as mensagens de texto dos clientes, desde filtros de spam banais a produtos sofisticados, como o Assistant e o ChatToBook, que usam modelos para determinar intenções e reconhecer entidades. Além disso, existem modelos que não são tão perceptíveis, por exemplo, detecção de fraude.
Analisamos críticas. Modelos nos dizem por que as pessoas vão, digamos, para Berlim.
Com a ajuda de modelos de aprendizado de máquina, é analisado por que o hotel é elogiado para que você não precise ler milhares de comentários.
Em alguns lugares da nossa interface, quase todas as peças estão vinculadas às previsões de alguns modelos. Por exemplo, aqui estamos tentando prever quando o hotel estará esgotado.
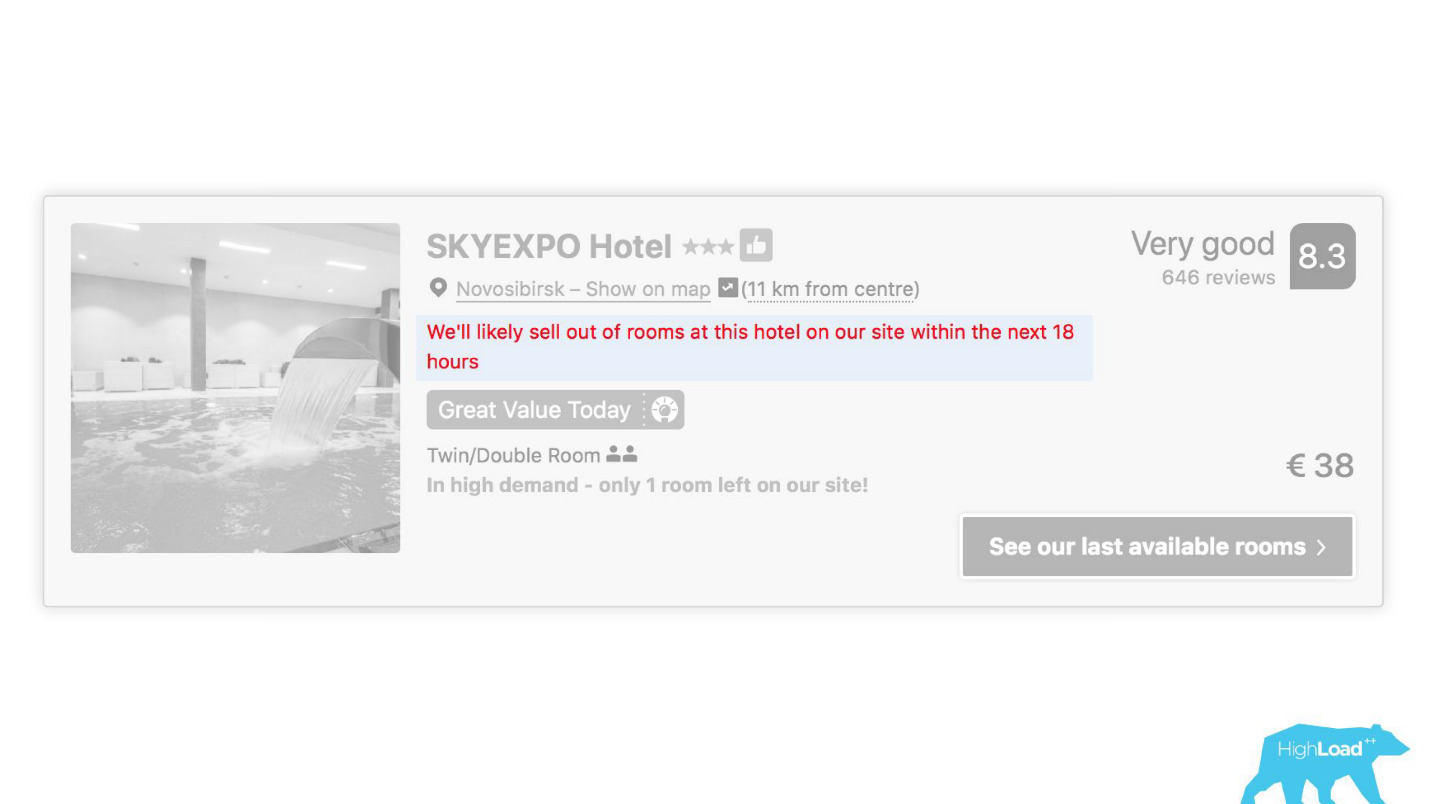
Muitas vezes, achamos que estamos certos - após 19 horas, o último quarto já está reservado.
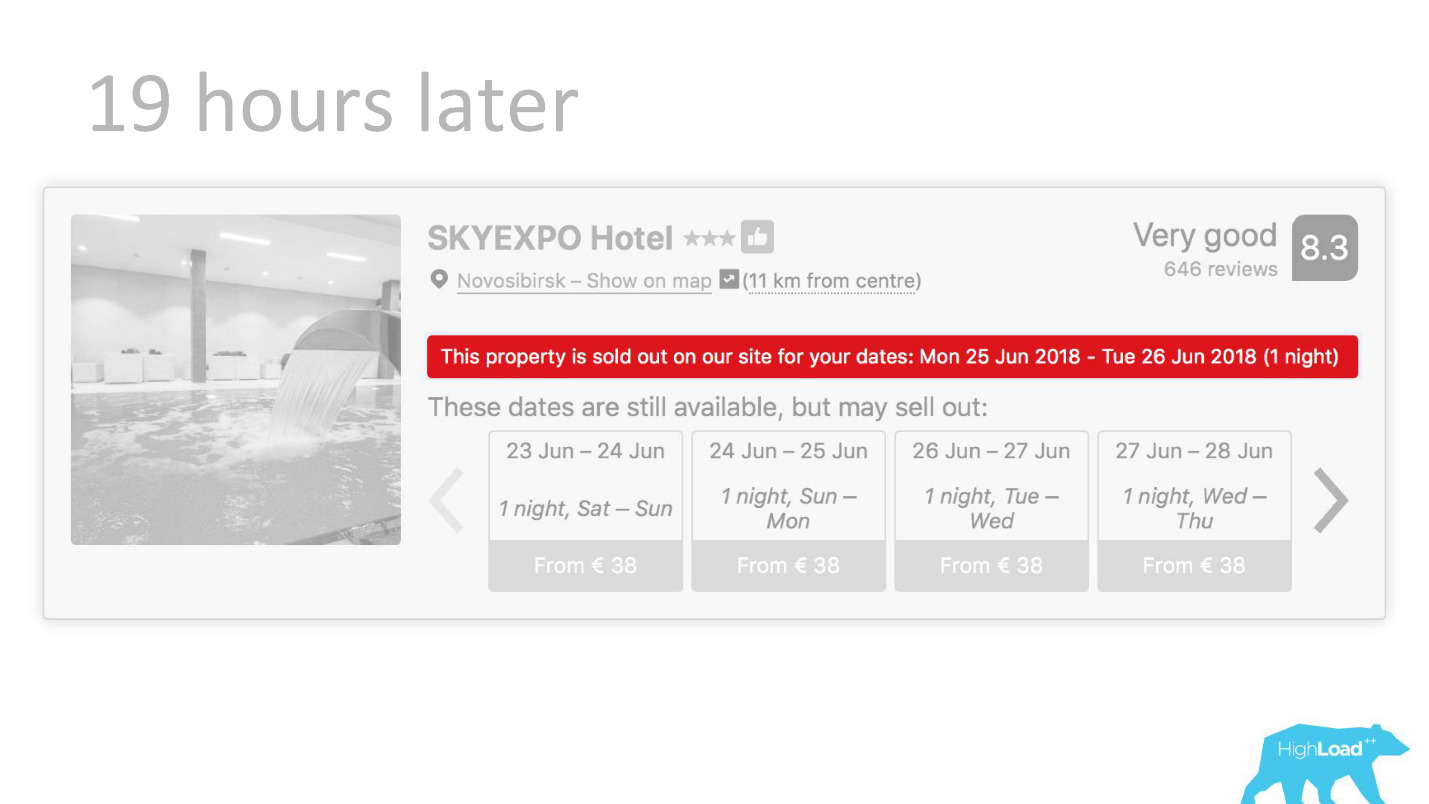
Ou, por exemplo, - o emblema "Oferta favorável". Aqui estamos tentando formalizar o subjetivo: o que é uma oferta tão vantajosa. Como entender que os preços estabelecidos pelo hotel para essas datas são bons? Afinal, isso, além do preço, depende de muitos fatores, como serviços adicionais e, muitas vezes, até de motivos externos, se, por exemplo, a Copa do Mundo ou uma grande conferência técnica estiver sendo realizada nesta cidade agora.
Início da implementação
Vamos retroceder alguns anos atrás, em 2015. Alguns dos produtos sobre os quais falei já existem. Além disso, o sistema sobre o qual falarei hoje ainda não é. Como a implementação ocorreu naquela época? Francamente, as coisas não eram muito. O fato é que tivemos um enorme problema, parte do qual é técnico e parte é organizacional.
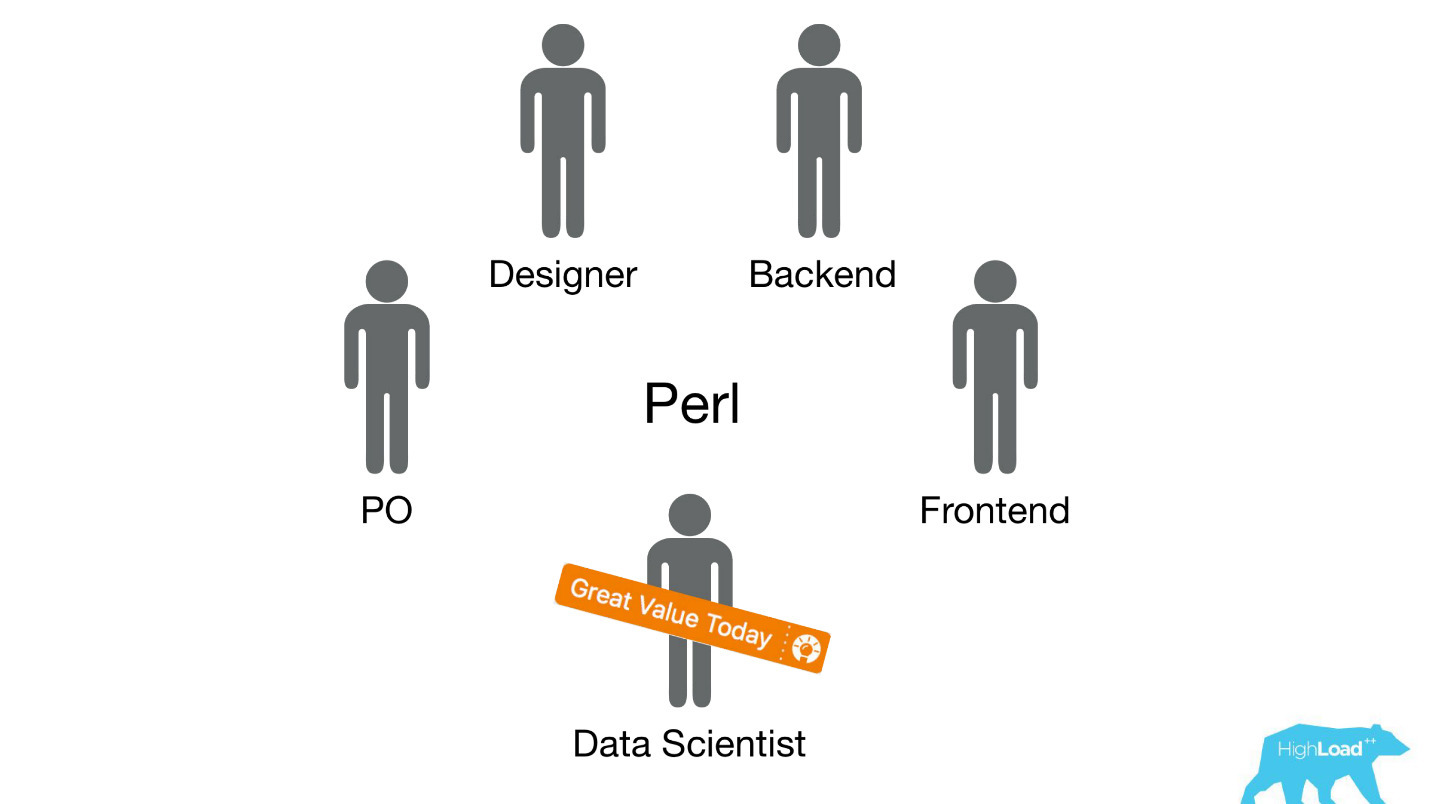
Enviamos cientistas de dados a equipes multifuncionais existentes que trabalham em um problema específico do usuário e esperavam que eles melhorassem o produto de alguma forma.
Na maioria das vezes, essas peças do produto foram construídas na pilha Perl. Há um problema óbvio com o Perl - ele não foi projetado para computação intensiva e nosso back-end já está carregado com outras coisas. Além disso, o desenvolvimento de sistemas sérios que resolveriam esse problema não poderia ser priorizado dentro da equipe, porque o foco da equipe é resolver um problema do usuário e não resolver um problema do usuário usando o aprendizado de máquina. Portanto, o Product Owner (PO) seria muito contrário a isso.
Vamos ver como aconteceu então.
Havia apenas duas opções - eu sei disso com certeza, porque naquela época eu estava apenas trabalhando em uma equipe e ajudou os Cientistas de Dados a trazer seus primeiros modelos para a batalha.
A primeira opção foi a
materialização de previsões . Suponha que exista um modelo muito simples com apenas dois recursos:
- país onde o visitante está localizado;
- a cidade em que ele está procurando um hotel.
Precisamos prever a probabilidade de algum evento. Acabamos de explodir todos os vetores de entrada: digamos, 100.000 cidades, 200 países - um total de 20 milhões de linhas no MySQL. Parece uma opção totalmente funcional para gerar alguns pequenos sistemas de classificação ou outros modelos simples para produção.

Outra opção é
incorporar as previsões diretamente no código de back-end . Existem grandes limitações - centenas, talvez milhares de coeficientes - é tudo o que podemos pagar.

Obviamente, nem uma nem a outra maneira permite que você exiba pelo menos algum tipo de modelo complexo na produção. Isso limitou o datacenter e os sucessos que eles poderiam alcançar melhorando os produtos. Obviamente, esse problema teve que ser resolvido de alguma forma.
Serviço de Previsão
A primeira coisa que fizemos foi um serviço de previsão. Provavelmente, a arquitetura mais simples já mostrada no Habré e no HighLoad ++ é menor.
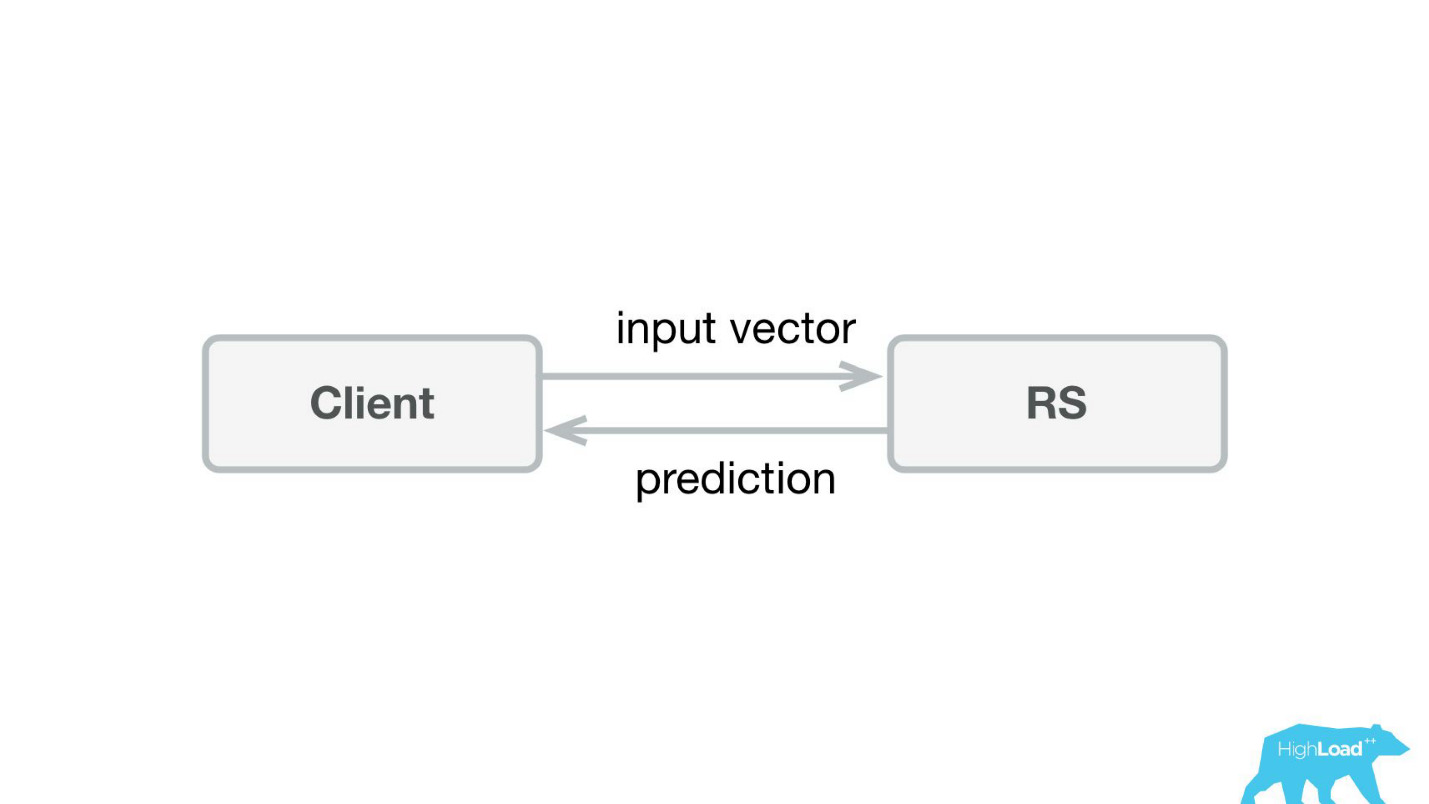
Escrevemos um pequeno aplicativo no Scala + Akka + Spray que simplesmente pegava os vetores recebidos e retornava a previsão. Na verdade, sou um pouco astuto - o sistema era um pouco mais complicado, porque precisávamos de alguma forma monitorar e implementá-lo. Na realidade, tudo parecia assim:
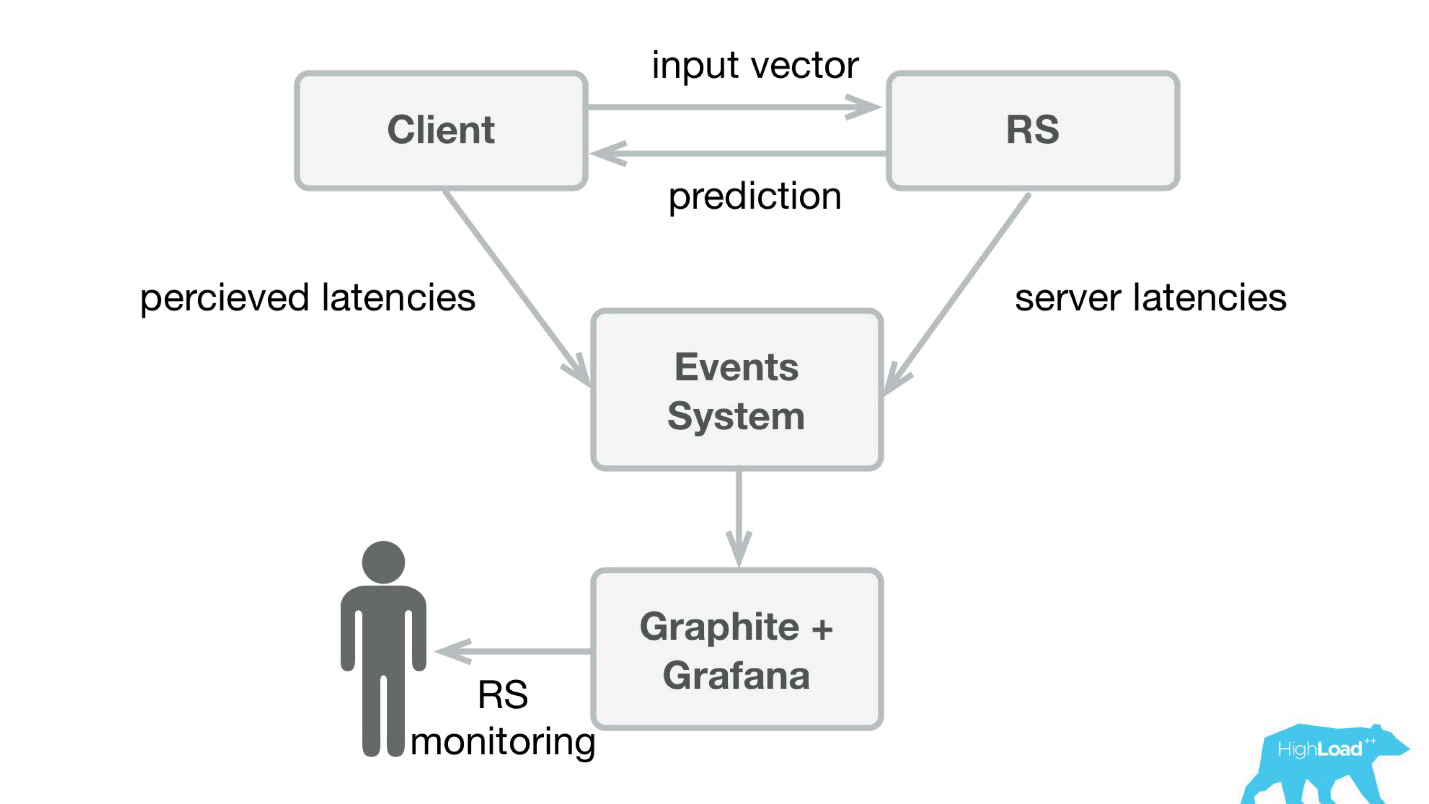
A Booking.com possui um sistema de eventos - algo como uma revista para todos os sistemas. É muito fácil escrever lá, e esse fluxo é muito simples de redirecionar. Inicialmente, precisamos enviar a telemetria do cliente para o Graphite e o Grafana com latências percebidas e informações detalhadas do lado do servidor.

Criamos bibliotecas de cliente simples para o Perl - ocultamos o RPC inteiro em uma chamada local, colocamos vários modelos lá e o serviço começou a decolar. Vender esse produto foi bastante simples, porque tivemos a oportunidade
de apresentar modelos mais complexos e gastar muito menos tempo .
Os cientistas de dados começaram a trabalhar com muito menos restrições e, em alguns casos, o trabalho dos back -ders se reduziu a uma única linha.
Previsões do produto
Mas vamos voltar brevemente à forma como usamos essas previsões no produto.
Existe um modelo que faz previsões com base em fatos conhecidos. Com base nessa previsão, estamos alterando a interface do usuário. Obviamente, esse não é o único cenário para o uso de aprendizado de máquina em nossa empresa, mas é bastante comum.
Qual é o problema de iniciar esses recursos? O fato é que essas são duas coisas em uma garrafa: um modelo e uma alteração na interface do usuário. É muito difícil separar os efeitos de ambos.
Imagine lançar o selo "Oferta favorável" como parte de um experimento da AB. Se não decolar - não há alterações estatisticamente significativas nas métricas de destino - não se sabe qual é o problema: um distintivo incompreensível, pequeno e discreto ou um modelo ruim.
Além disso, os modelos podem se degradar, e pode haver muitas razões para isso. O que funcionou ontem não necessariamente funciona hoje. Além disso, estamos constantemente no modo de partida a frio, conectando constantemente novas cidades e hotéis, pessoas de novas cidades vêm até nós. De alguma forma, precisamos entender que o modelo ainda generaliza bem nessas partes do espaço de entrada.

O caso provavelmente mais recentemente conhecido de degradação de modelo foi a história de Alex. Provavelmente, como resultado da reciclagem, ela começou a entender ruídos aleatórios, como um pedido de rir, e começou a rir à noite, assustando os proprietários.
Monitoramento de Previsão
Para monitorar as previsões, modificamos levemente nosso sistema (diagrama abaixo). Da mesma forma, no sistema de eventos, redirecionamos o fluxo para o Hadoop e começamos a salvar, além de tudo o que salvamos anteriormente, todos os vetores de entrada e todas as previsões feitas pelo nosso sistema. Em seguida, usando Oozie, os agregamos no MySQL e, a partir daí, mostramos a eles um pequeno aplicativo da web para aqueles que estão interessados em algum tipo de característica qualitativa dos modelos.
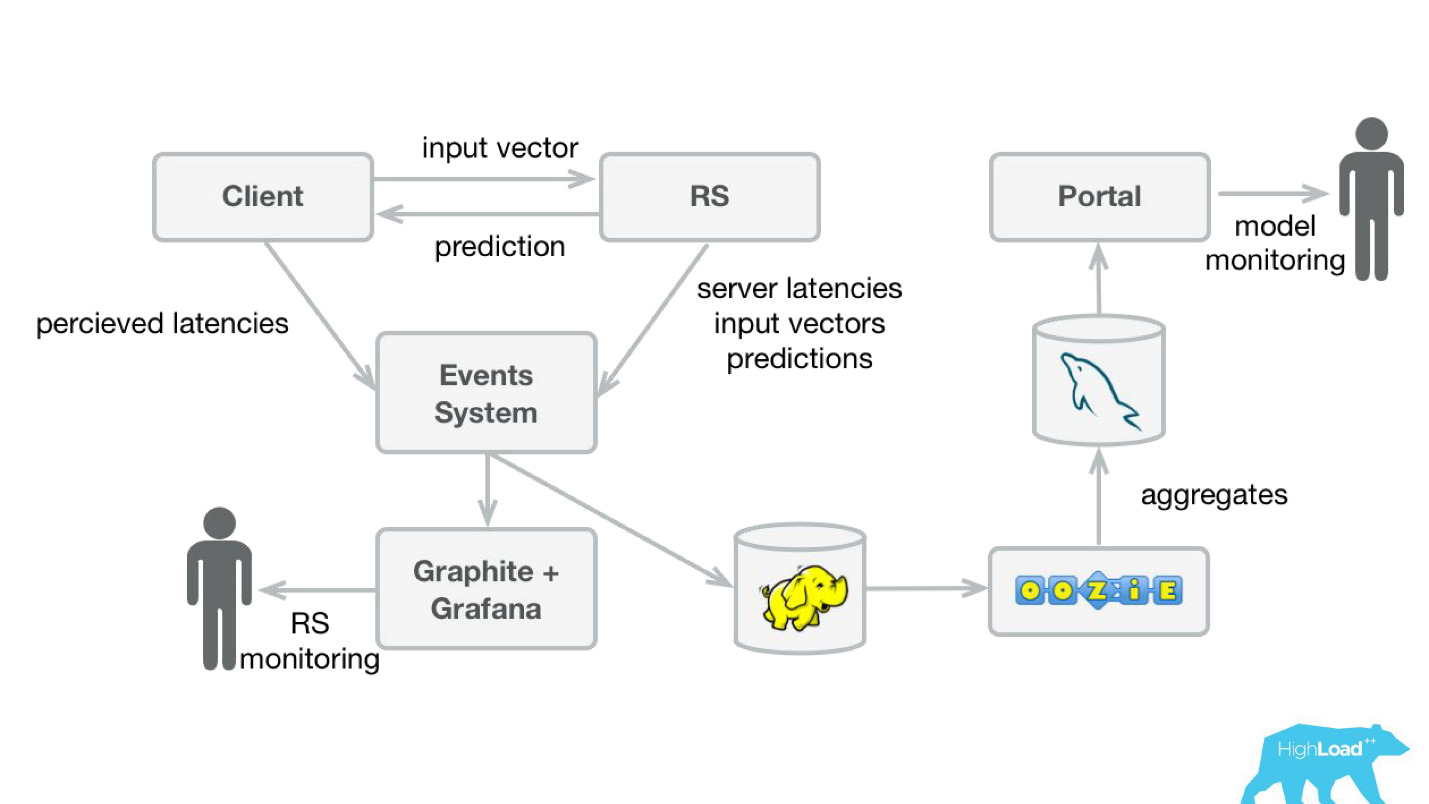
No entanto, é importante descobrir o que mostrar lá. O fato é que, no nosso caso, é muito difícil calcular as métricas usuais usadas no treinamento de modelos, porque geralmente temos um grande atraso nos rótulos.
Considere isso como um exemplo. Queremos prever se o usuário está saindo de férias sozinho ou com a família. Precisamos dessa previsão quando uma pessoa escolhe um hotel, mas só podemos descobrir a verdade em um ano. Depois de sair de férias, o usuário receberá um convite para deixar um comentário, onde, entre outras coisas, haverá uma pergunta se ele estava lá sozinho ou com sua família.
Ou seja, você precisa armazenar em algum lugar todas as previsões feitas ao longo do ano e ainda assim, para encontrar rapidamente correspondências com os rótulos recebidos. Parecia um investimento muito sério, talvez até pesado. Portanto, até resolvermos esse problema, decidimos fazer algo mais simples.
Esse "mais simples" acabou sendo apenas um
histograma de previsões feitas pelo modelo.
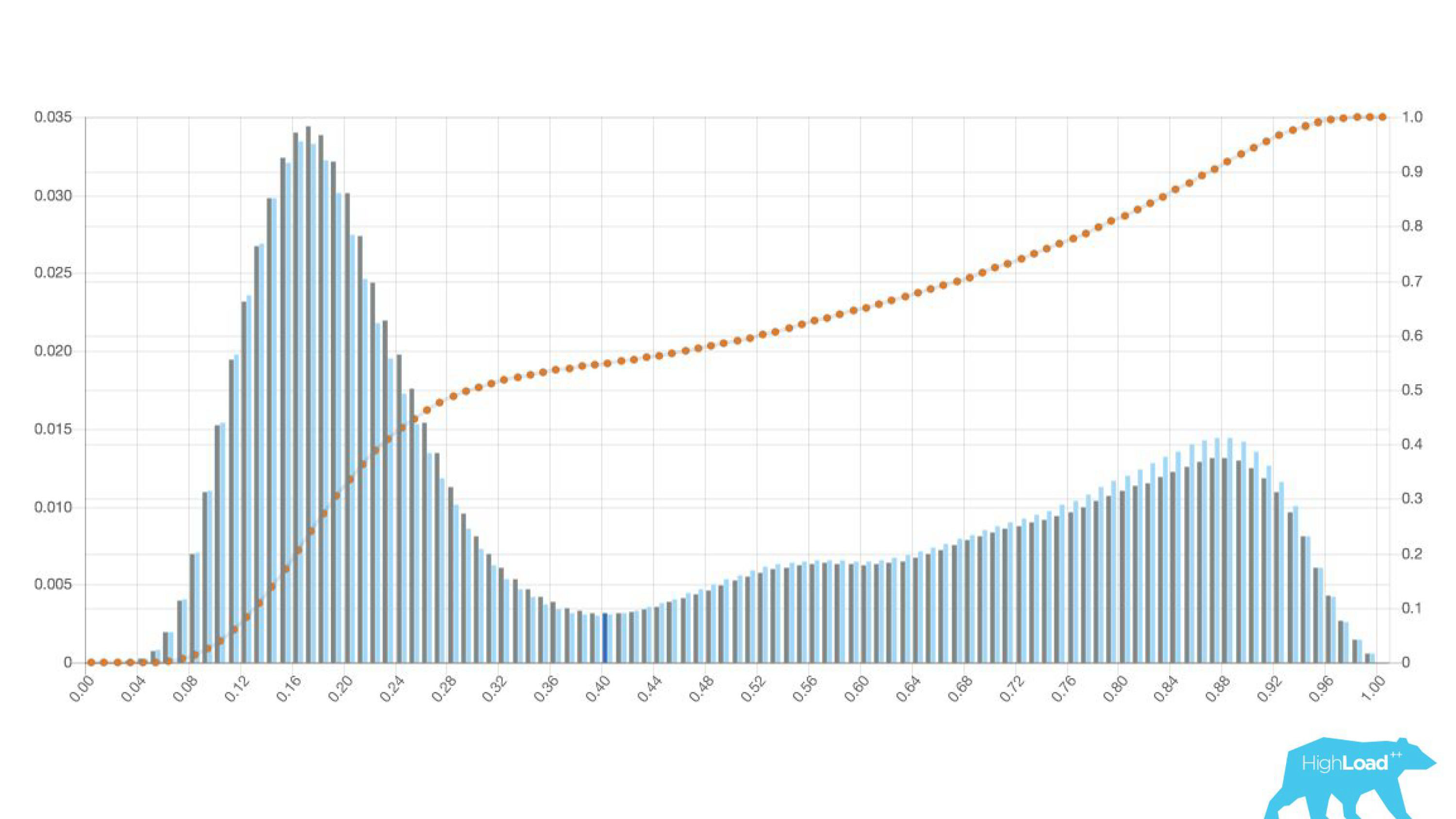
Acima no gráfico, há uma regressão logística que prevê se o usuário alterará ou não a data de sua viagem. Pode-se ver que ele divide os usuários em duas classes: à esquerda, o morro é aquele que não faz isso; a colina à direita é quem faz.
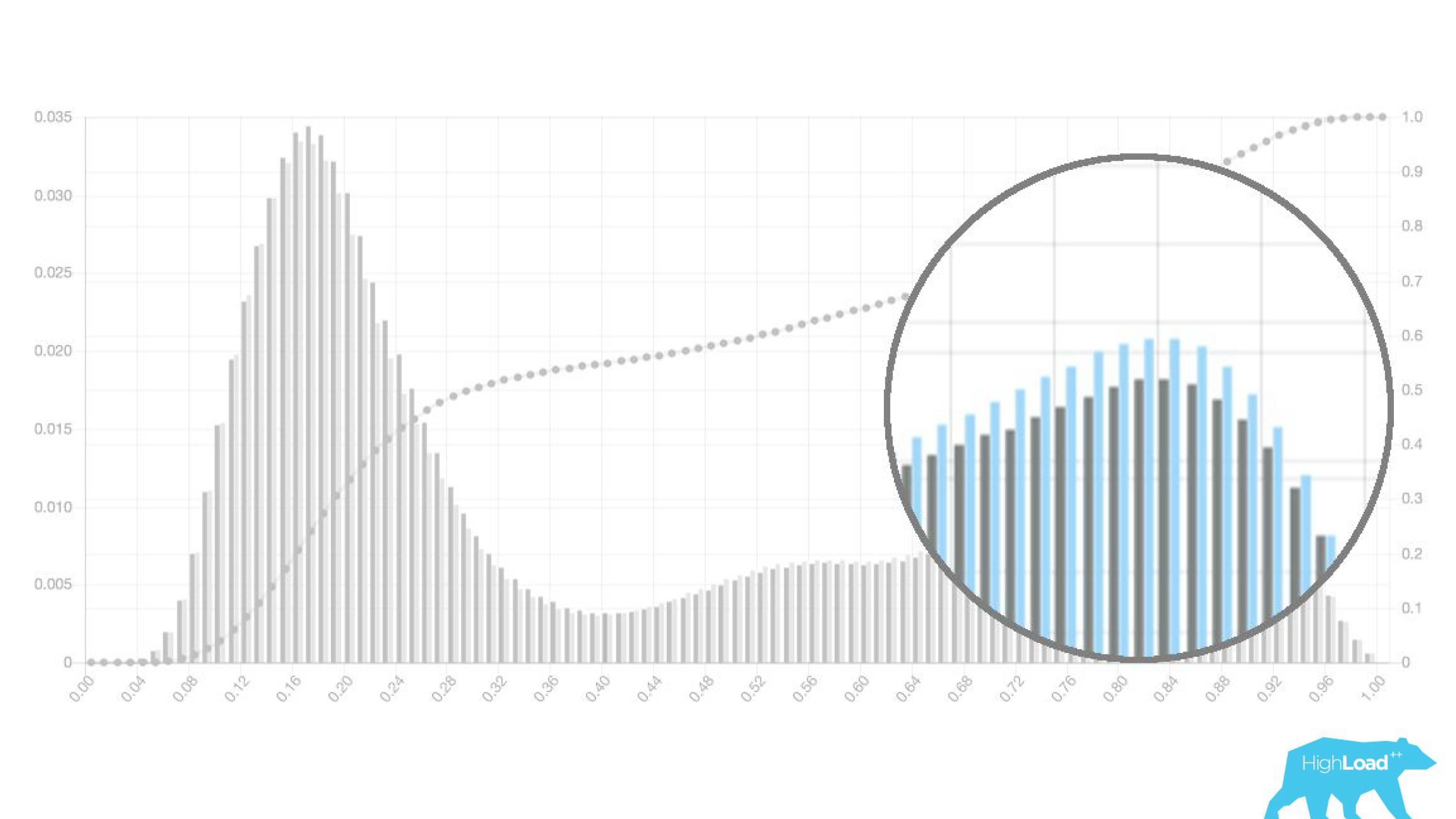
De fato, mostramos até dois gráficos: um para o período atual e outro para o período anterior. Vê-se claramente que nesta semana (este é um gráfico semanal) o modelo prevê uma mudança de datas com um pouco mais de frequência. É difícil dizer com certeza se é a sazonalidade ou a mesma degradação ao longo do tempo.
Isso levou a uma mudança no trabalho dos datacientes, que deixaram de envolver outras pessoas e começaram a iterar seus modelos mais rapidamente. Eles enviaram modelos para produção em funcionamento a seco, juntamente com os engenheiros de back-end. Ou seja, os vetores foram coletados, o modelo fez uma previsão, mas essas previsões não foram usadas de forma alguma.
No caso de um crachá, simplesmente não mostramos nada, como antes, mas coletamos estatísticas. Isso nos permitiu não perder tempo com projetos com falha antecipadamente. Liberamos tempo para o front-end e designers para outros experimentos.
Desde que o datacenter não tenha certeza de que o modelo funciona da maneira que deseja, ele simplesmente não envolve outras pessoas nesse processo.É interessante ver como os gráficos mudam em diferentes seções.
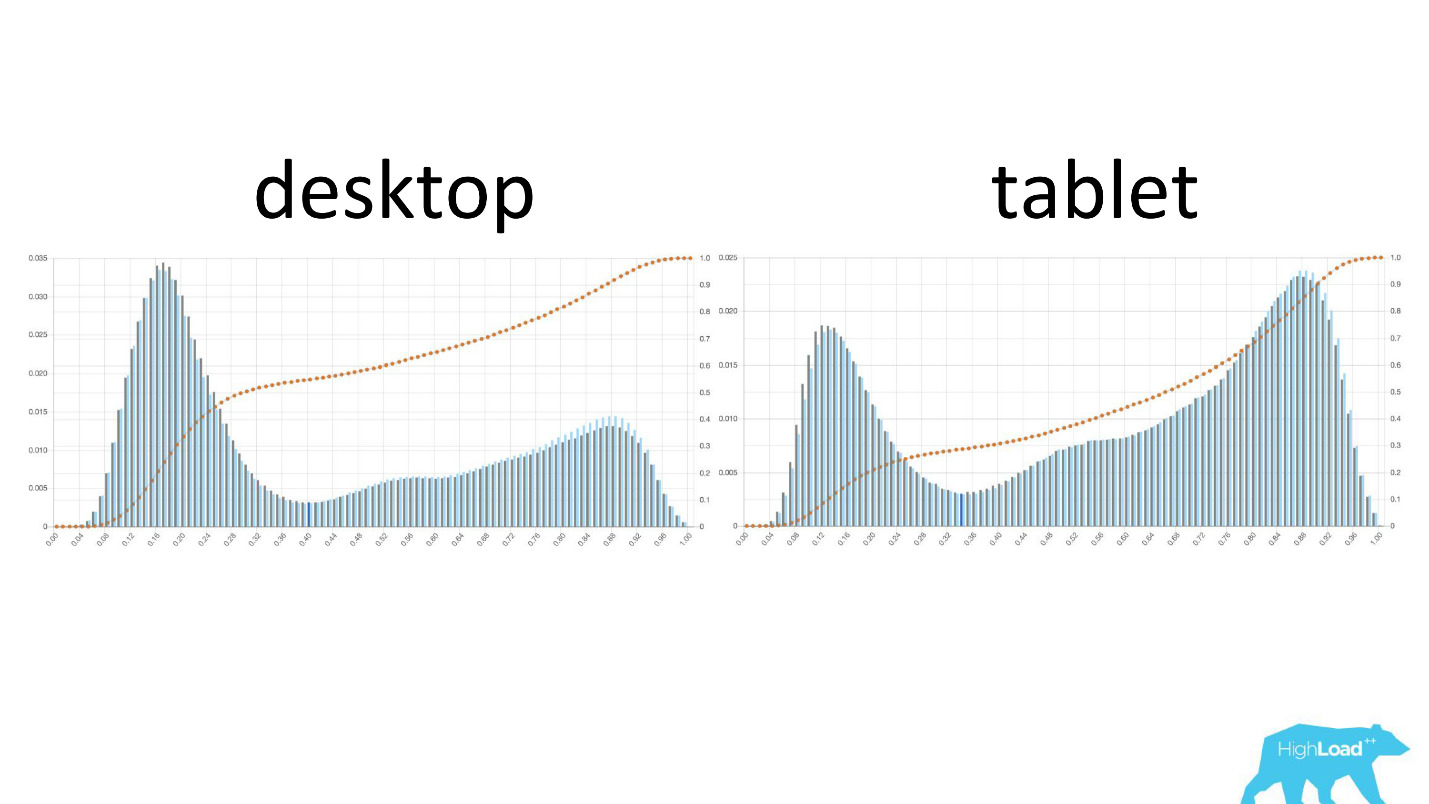
À esquerda, a probabilidade de alterar as datas na área de trabalho, à direita, nos tablets. É claramente visto que nos tablets o modelo prevê uma mudança de datas mais provável. Isso provavelmente ocorre devido ao fato de o tablet ser usado com frequência no planejamento de viagens e com menos frequência nas reservas.
Também é interessante ver como esses gráficos mudam à medida que os usuários se movem pelo funil de vendas.
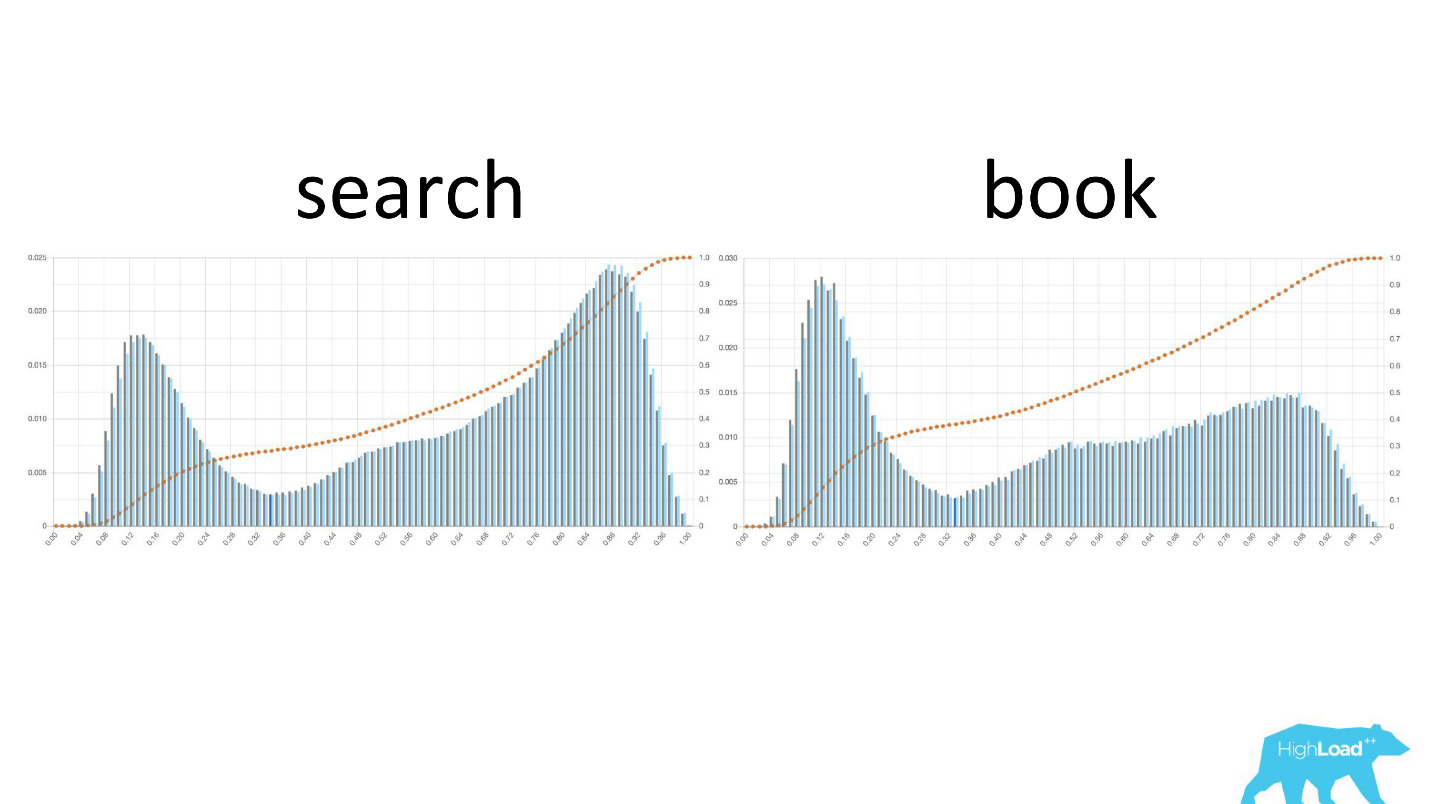
À esquerda, a probabilidade de alterar as datas na página de pesquisa, à direita, na primeira página de reserva. Pode-se observar que um número muito maior de pessoas que já decidiram suas datas acessam a página de reservas.
Mas esses eram bons gráficos. Como são os maus? De maneiras muito diferentes. Às vezes é apenas barulho, às vezes é uma colina enorme, o que significa que o modelo não pode separar efetivamente duas classes de previsões.

Às vezes, esses são enormes picos.
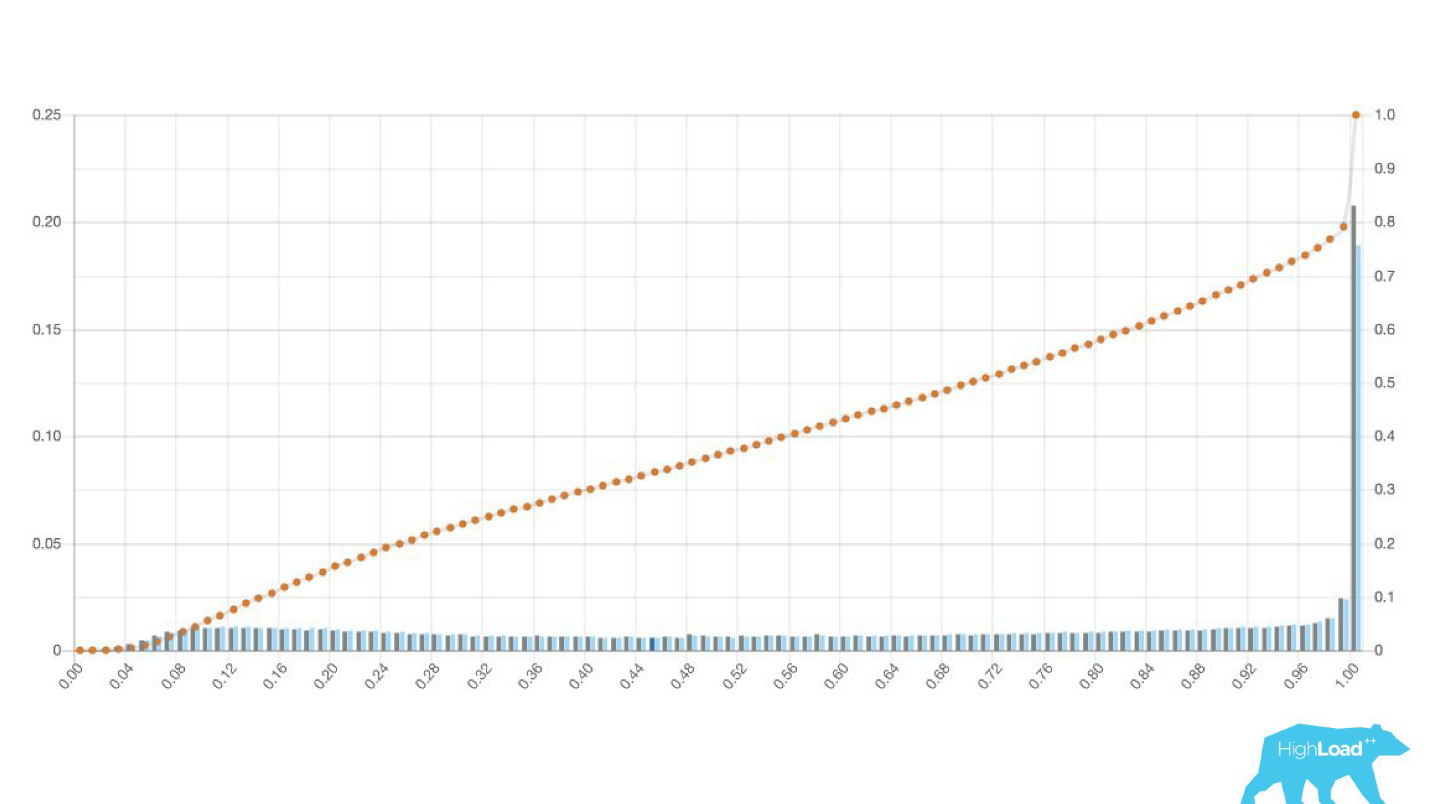
Essa também é uma regressão logística e, até certo ponto, mostrou uma bela foto com duas colinas, mas uma manhã ficou assim.
Para entender o que aconteceu lá dentro, você precisa entender como a regressão logística é calculada.
Referência rápida
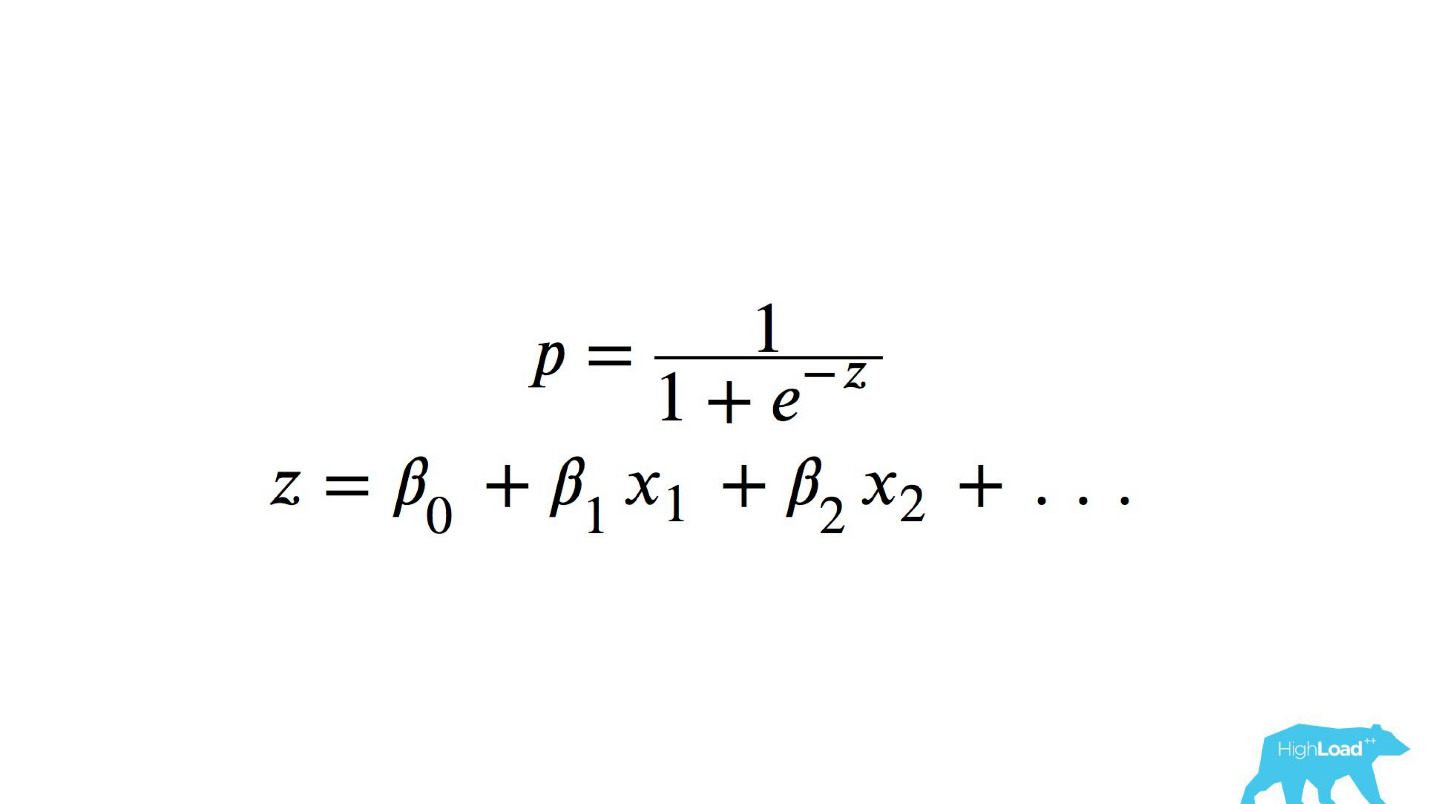
Essa é uma função logística do produto escalar, em que x
n são alguns recursos. Uma dessas características era o preço de uma noite em um hotel (em euros).
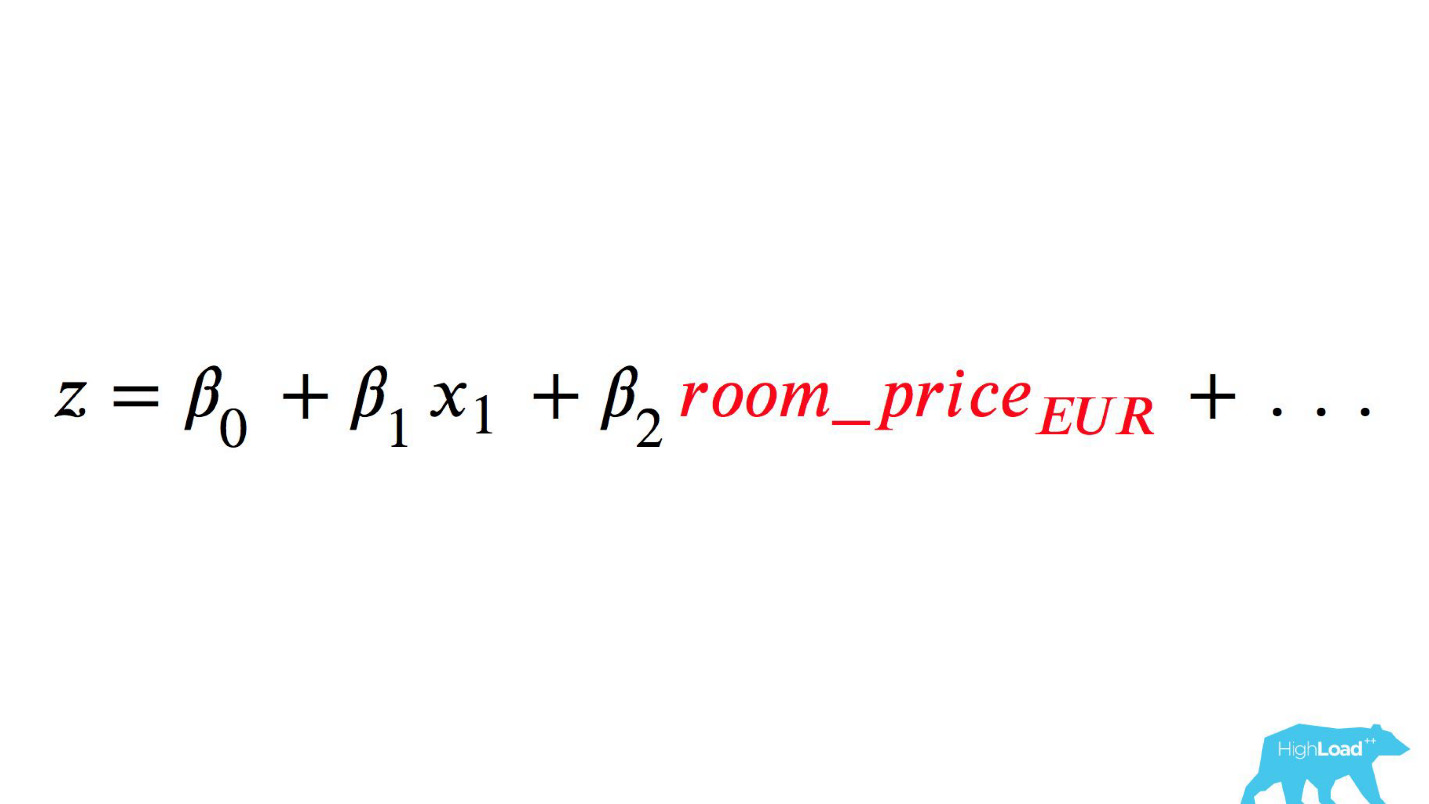
Chamar esse modelo seria algo assim:
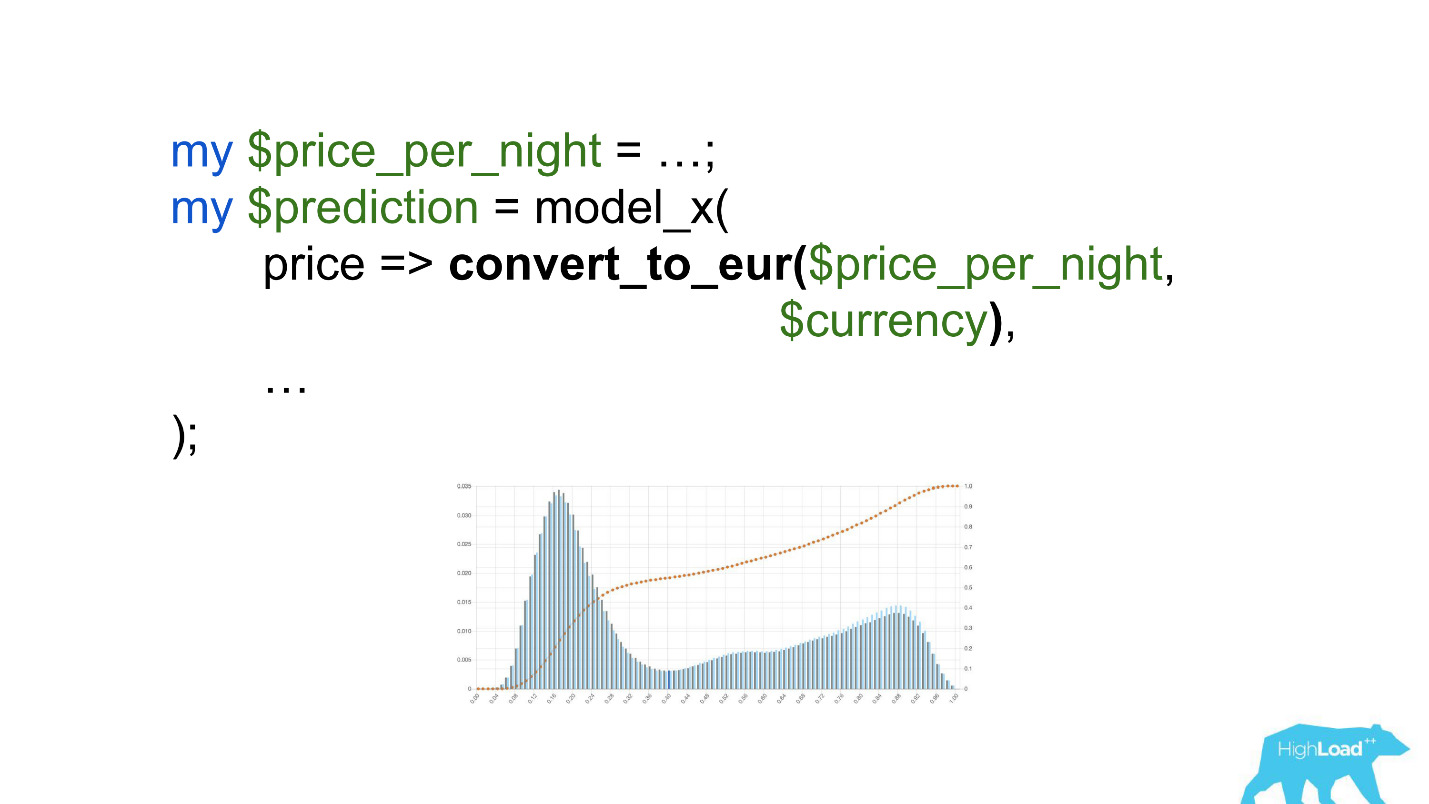
Preste atenção na seleção. Era necessário converter o preço em euros, mas o desenvolvedor esqueceu de fazê-lo.
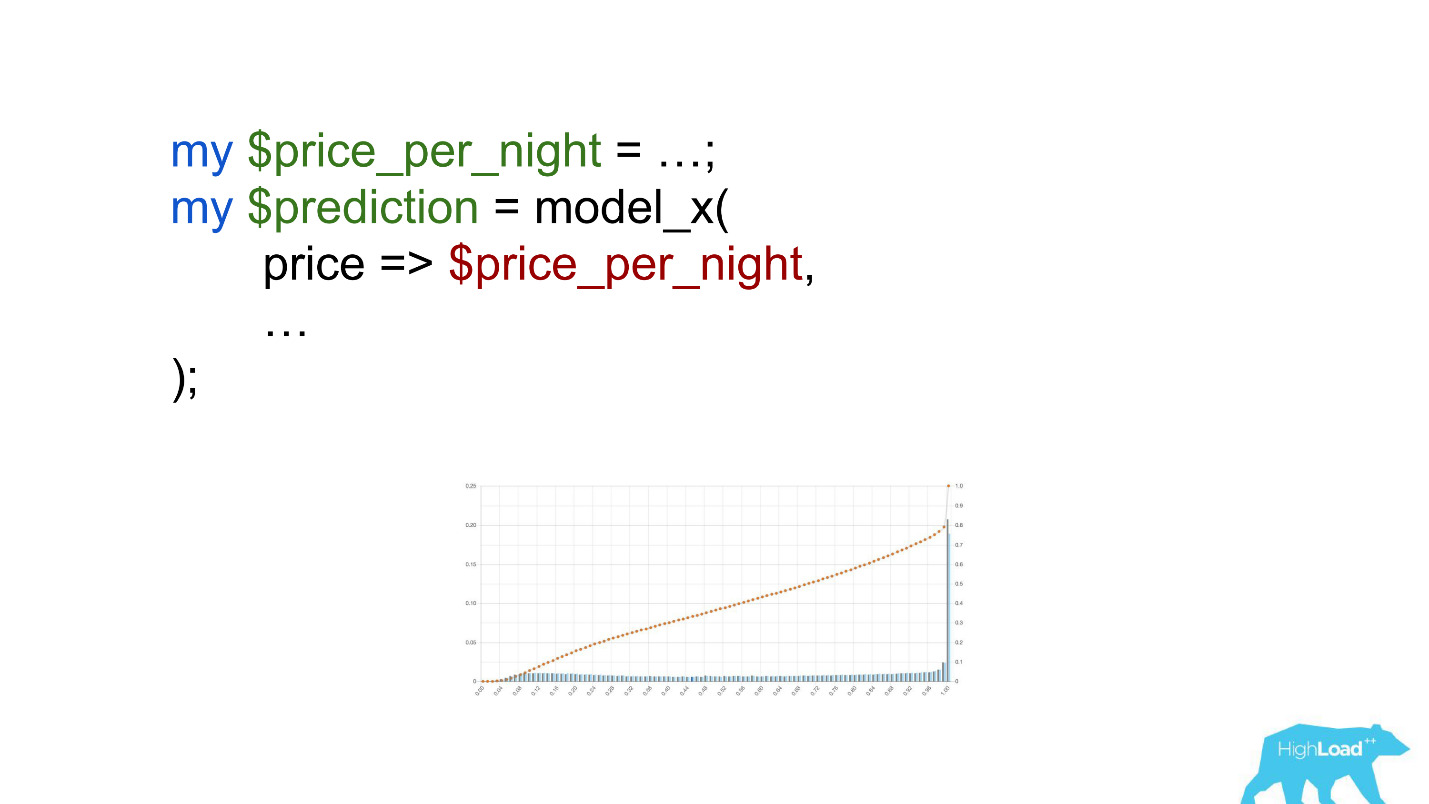
Moedas como rúpias ou rublos aumentaram o produto escalar muitas vezes e, portanto, forçaram esse modelo a produzir um valor próximo à unidade, com muito mais frequência, que vemos no gráfico.
Valores limite
Outra característica útil desses histogramas foi a possibilidade de uma escolha consciente e ideal dos valores-limite.
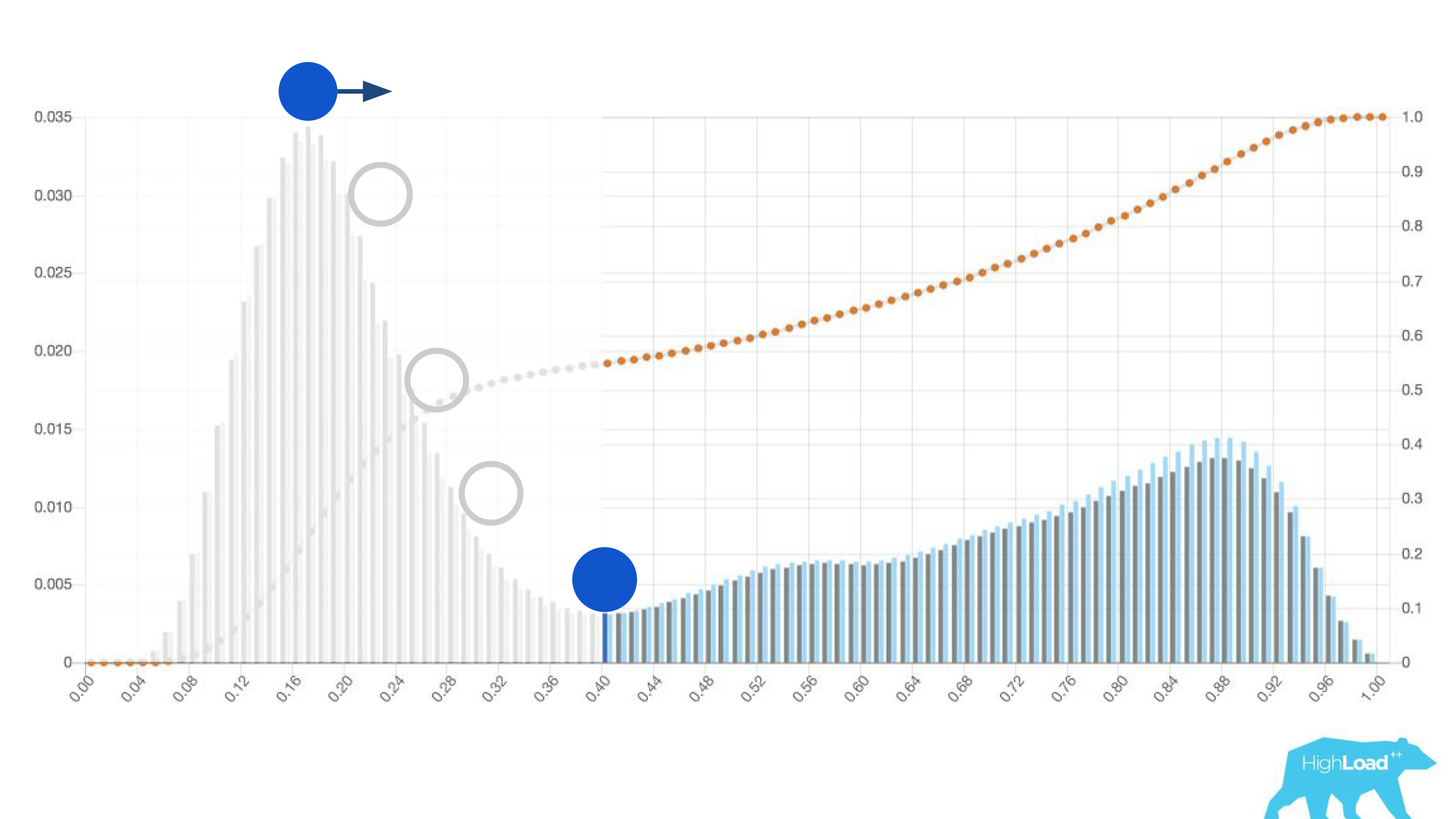
Se você colocar a bola na colina mais alta deste histograma, empurre-a e imagine onde ela irá parar, este será o ponto ideal para a separação de classes. Tudo à direita é uma classe, tudo à esquerda é outra.
No entanto, se você começar a mover esse ponto, poderá obter efeitos muito interessantes. Suponha que desejemos executar um experimento que, se o modelo disser sim, de alguma forma altere a interface do usuário. Se você mover esse ponto para a direita, o público de nosso experimento será reduzido. Afinal, o número de pessoas que receberam essa previsão é a área abaixo da curva. No entanto, na prática, a precisão das previsões é muito maior. Da mesma forma, se não houver energia estática suficiente, você poderá aumentar o público do seu experimento, mas diminuir a precisão das previsões.
Além das próprias previsões, começamos a monitorar os valores de entrada nos vetores.
Uma codificação quente
A maioria dos recursos em nossos modelos mais simples é categórica. Isso significa que não são números, mas certas categorias: a cidade da qual o usuário é ou a cidade em que ele está procurando um hotel. Usamos One Hot Encoding e transformamos cada um dos valores possíveis em uma unidade em um vetor binário. Como no início usamos apenas nosso próprio núcleo de computação, foi fácil identificar situações em que não há lugar para a categoria de entrada no vetor de entrada, ou seja, o modelo não viu esses dados durante o treinamento.
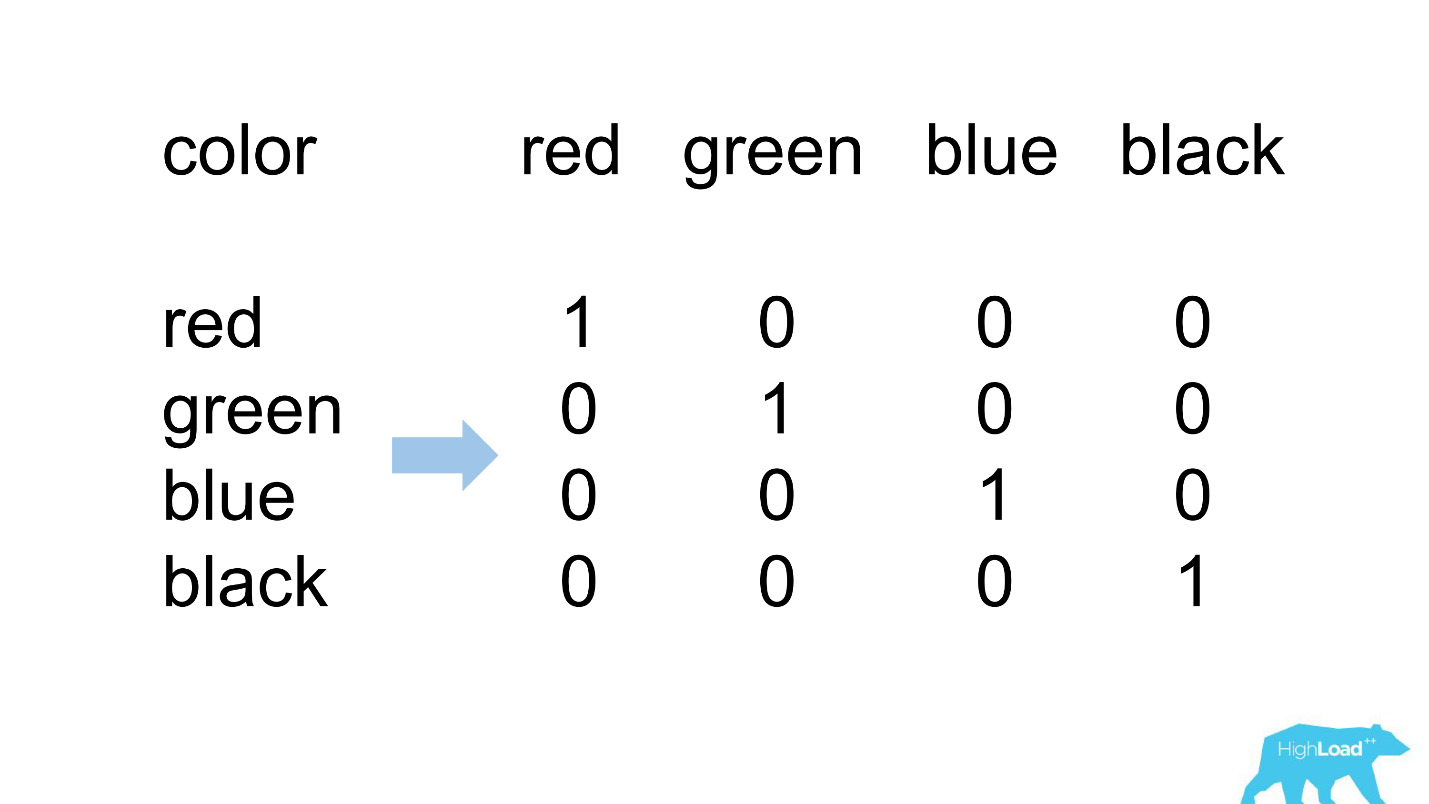
É assim que geralmente se parece.

destination_id - a cidade em que o usuário está procurando um hotel. Naturalmente, o modelo não obteve cerca de 5% dos valores, pois estamos constantemente conectando novas cidades. visitor_cty_id = 23.32%, porque os datacientistas às vezes omitem conscientemente cidades menos comuns.
Em um caso ruim, pode ser assim:

Imediatamente 3 propriedades, 100% dos valores que o modelo nunca viu. Na maioria das vezes, isso ocorre devido ao uso de formatos diferentes dos usados no treinamento ou simplesmente erros banais.
Agora, com a ajuda dos painéis, detectamos e corrigimos essas situações muito rapidamente.
Vitrine de aprendizado de máquina
Vamos falar sobre outros problemas que resolvemos. Depois que criamos as bibliotecas e o monitoramento do cliente, o serviço começou a ganhar impulso muito rapidamente. Ficamos literalmente impressionados com aplicativos de diferentes partes da empresa: “Vamos conectar esse modelo também! Vamos atualizar o antigo! Acabamos de costurar, de fato, qualquer novo desenvolvimento parou.
Saímos da situação criando
um quiosque de autoatendimento para cientistas de dados . Agora você pode simplesmente acessar nosso portal, o mesmo que usamos inicialmente apenas para o monitoramento e, literalmente, clicando no botão para carregar o modelo em produção. Em alguns minutos, ela trabalhará e fará previsões.
Havia mais um problema.
A Booking.com possui aproximadamente 200 equipes de TI. Como deixar a equipe saber em alguma parte completamente diferente da empresa que existe um modelo que poderia ajudá-los? Você pode simplesmente não saber que essa equipe existe. Como descobrir quais modelos existem e como usá-los? Tradicionalmente, as comunicações externas em nossas equipes estão envolvidas no PO (Product Owner). Isso não significa que não temos outras conexões horizontais, apenas o PO faz isso mais do que outros. Mas é óbvio que, nessa escala, a comunicação individual não é dimensionada. Você precisa fazer algo sobre isso.
Como a comunicação pode ser facilitada?De repente, percebemos que o portal, que criamos exclusivamente para monitoramento, está gradualmente começando a se transformar em uma vitrine de aprendizado de máquina em nossa empresa.
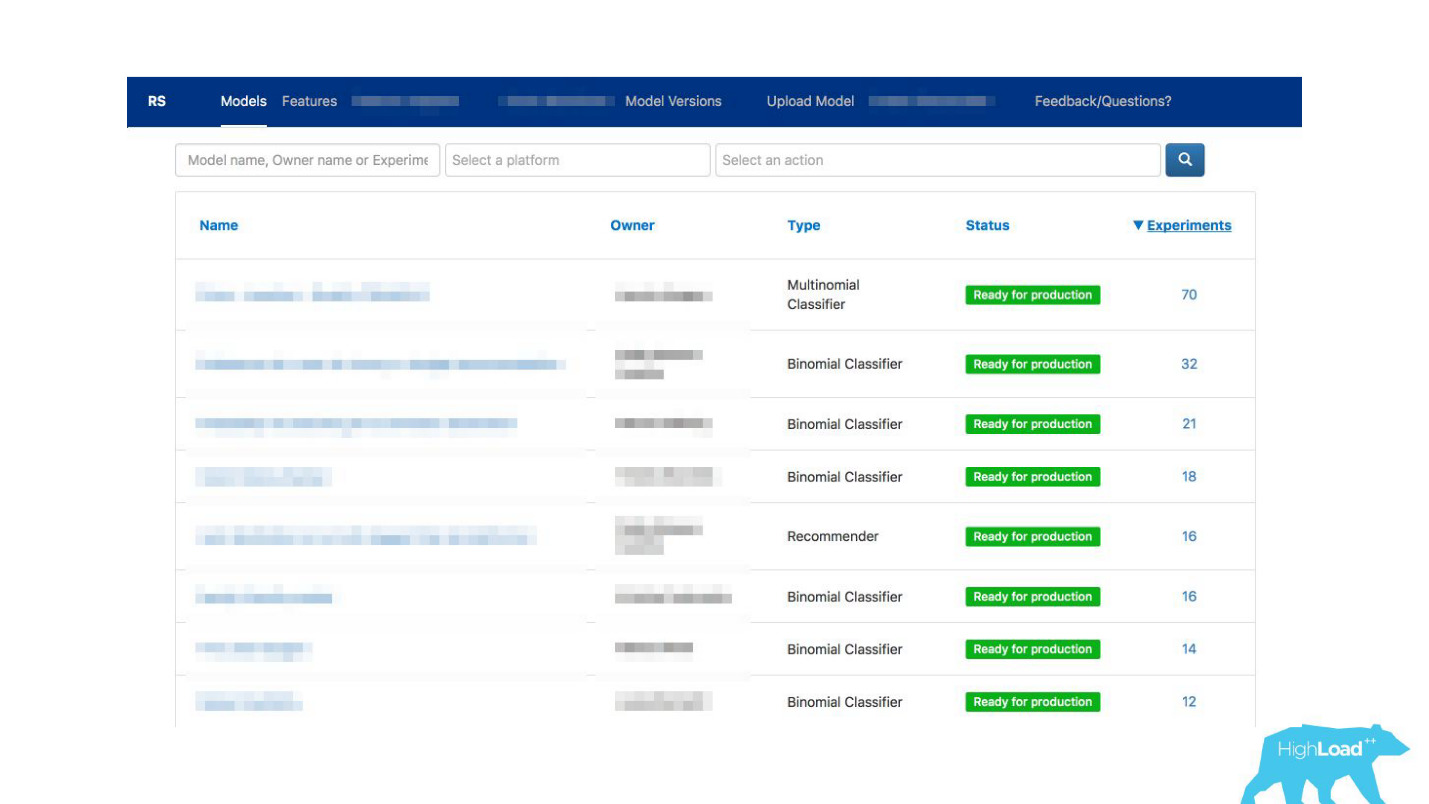
Permitimos que os datacientistas descrevessem seus modelos em detalhes. Quando havia muitos modelos, adicionamos rótulos de tópico e área para agrupamento conveniente.
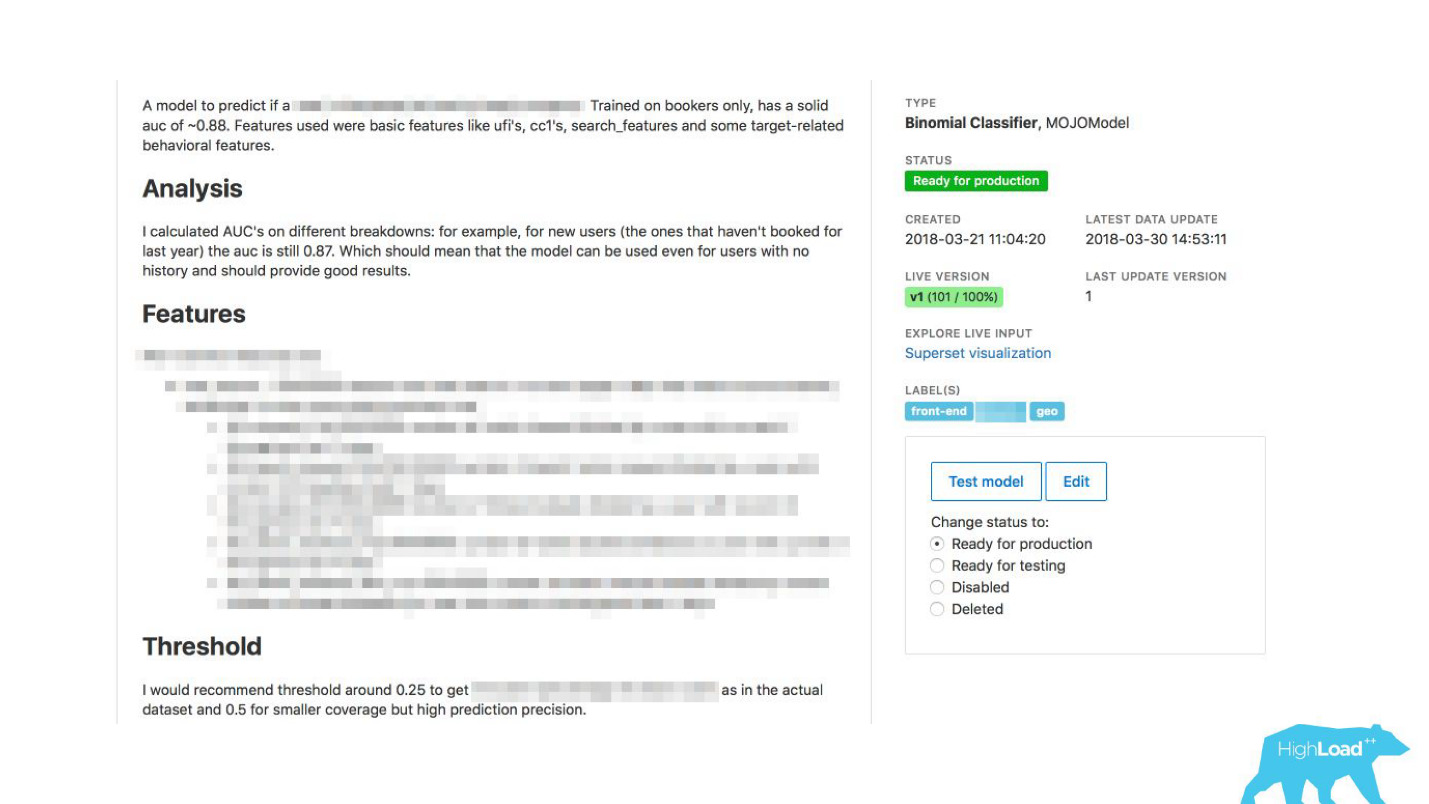
Vinculamos nossa ferramenta ao ExperimentTool. Este é um produto dentro de nossa empresa que fornece experimentos A / B e armazena todo o histórico de experimentos.

Agora, junto com a descrição do modelo, você também pode ver o que outras equipes fizeram com esse modelo antes e com que êxito. Isso mudou tudo.
Sério, isso mudou a maneira como a TI funciona, porque mesmo em situações em que não há cientista de dados na equipe, você pode usar o aprendizado de máquina.
Por exemplo, muitas equipes usam isso durante as sessões de brainstorming. Quando apresentam novas idéias de produtos, simplesmente selecionam os modelos que mais lhes agradam e os utilizam. Nada complicado é necessário para isso.
O que derramou para nós? No momento, no pico, entregamos cerca de 200 mil previsões por segundo, com latência menor que 20 a 30 ms, incluindo ida e volta HTTP e o posicionamento de mais de 200 modelos.
Pode parecer que foi uma caminhada tão fácil no parque: fizemos um trabalho maravilhoso, tudo funciona, todo mundo está feliz!
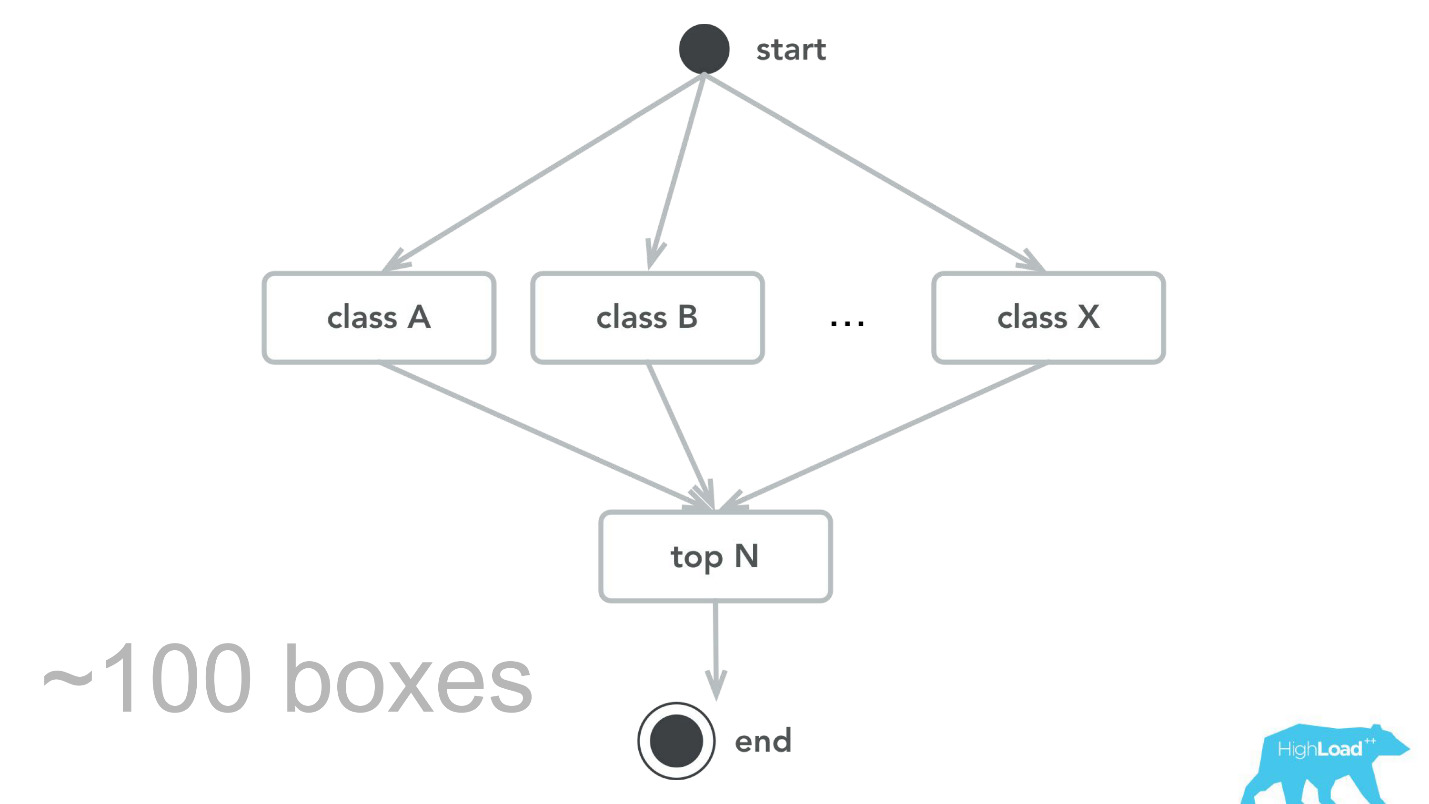
Isso, é claro, não acontece. Houve erros. No começo, por exemplo, plantamos uma pequena bomba-relógio. Por alguma razão, assumimos que a maioria dos nossos modelos será um sistema de recomendação com vetores de entrada pesados, e a pilha Scala + Akka foi escolhida precisamente porque é muito fácil organizar cálculos paralelos com sua ajuda. Mas, na realidade, a sobrecarga para toda essa paralelização, para se reunir, acabou sendo maior que o ganho possível. Em algum momento, nossas 100 máquinas processaram apenas 100.000 RPS e ocorreram falhas com sintomas bastante característicos: a utilização da CPU é baixa, mas os tempos limite são obtidos.
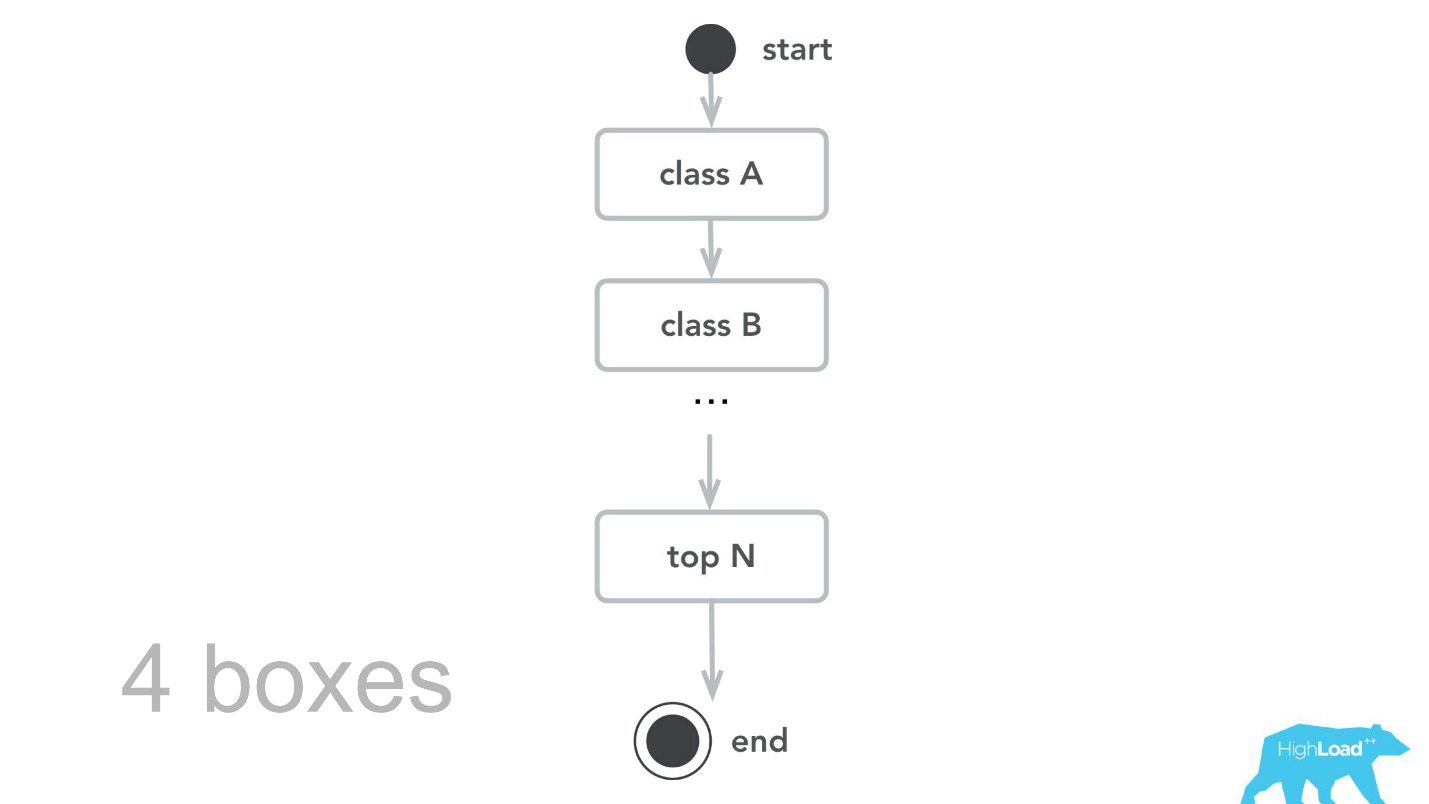
Em seguida, retornamos ao nosso núcleo de computação, revisamos, fizemos benchmarks e, como resultado do teste de capacidade, aprendemos que, para o mesmo tráfego, precisamos de apenas 4 máquinas. , , -, , , , 100 000 RPS 4 .
- , , . - , , , .
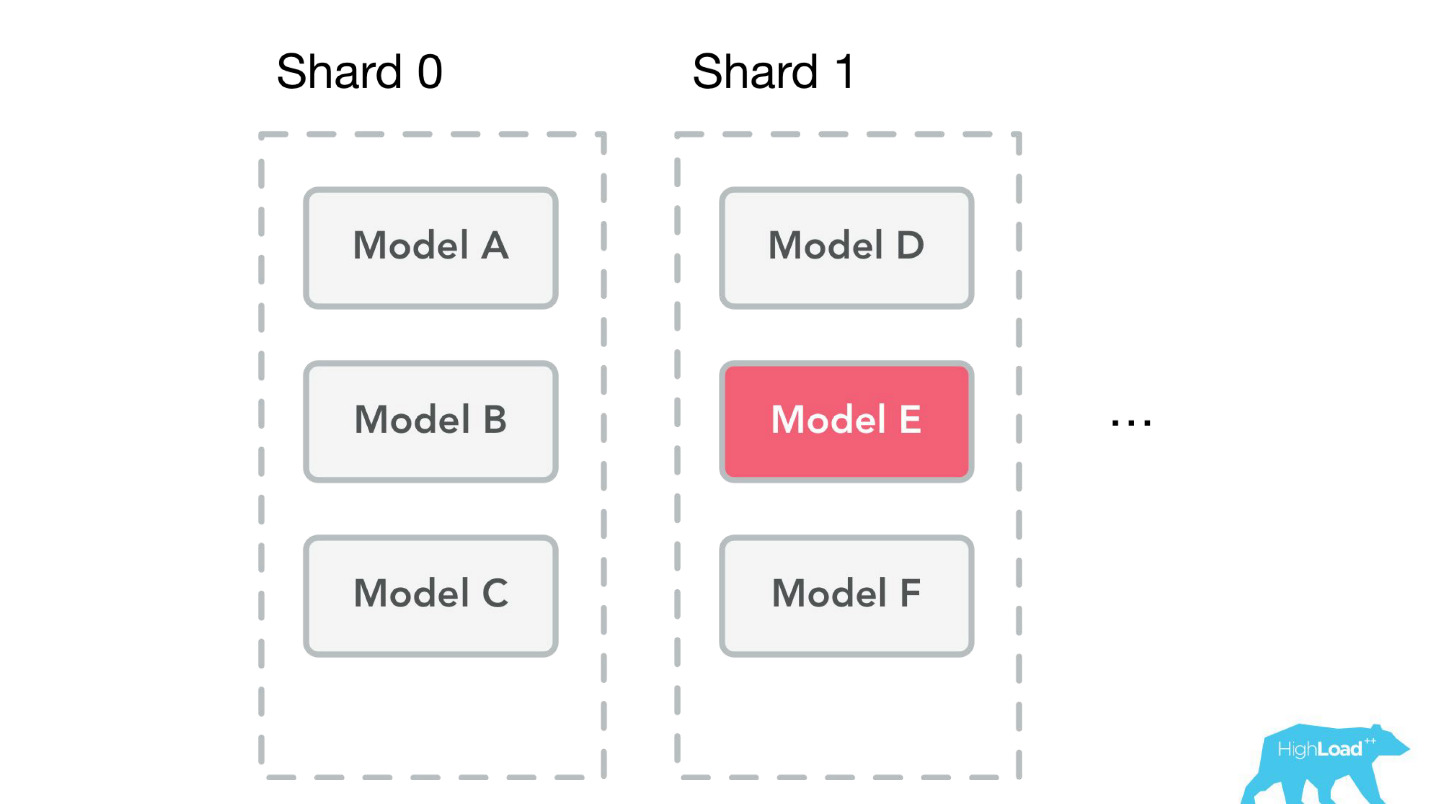
— , . , ID , . , 0.
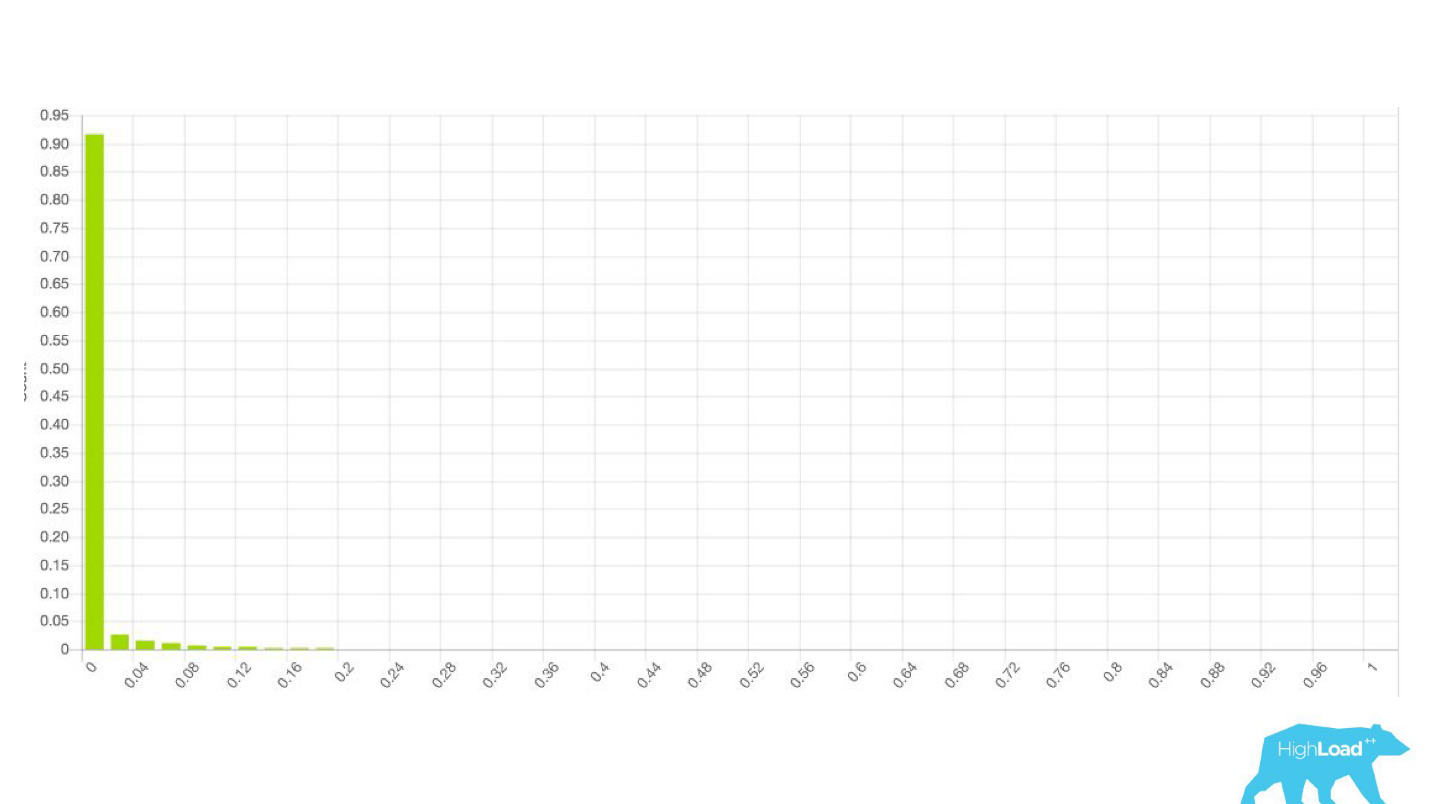
— , — .
, . , . , — , . , , , - .
, — ID . — 49-51%. , . , , . , .
Planos futuros
- , . Label based metrics, precision recall .
- More tools & integrations
, . , Perl Java, , , . Spark, .
- Reusable training pipelines
.
, -. , , , , ,
steaming — - , , .
. pipeline, , . , , .
. ,
, 50 , . , . , , .
Start small
, , Booking.com, , , — !
, , MySQL. , , . - . B . , , - — .
, ?
Monitor
— , -, .
— . — , . , , , . : , . , , , — !
Organization footprint
, . , . , .
(Don't) Follow our steps
- , , , . , - , . , . — , , ? , , , ?
, , !HighLoad++ 2018, 8 9 , 135 , . 9 - . , .