Antes que um cliente possa fazer transferências de dinheiro nos ePayments, ele precisará passar pela verificação. Ele nos fornece seus dados pessoais e carrega documentos para verificar sua identidade e endereço. E verificamos se eles atendem aos requisitos de nosso regulador. O fluxo de pedidos de verificação tornou-se cada vez mais difícil, para nós processar esse fluxo de documentos. Temíamos que o procedimento levasse muito tempo e excedesse todos os termos razoáveis para os clientes. Decidimos criar um sistema de verificação baseado em aprendizado profundo.

Programa educacional sobre reguladores e seus requisitos
Para emitir dinheiro eletrônico, você precisa obter uma licença do regulador. Se você abrir um sistema de pagamentos, por exemplo, na Rússia, o Banco Central da Federação Russa se tornará seu regulador. O ePayments é um sistema de pagamento em inglês, nosso regulador é a Financial Conduct Authority (FCA), uma autoridade que se reporta ao Tesouro do Reino Unido. A FCA garante que cumprimos a política de combate à lavagem de dinheiro (AML), que inclui o conjunto de procedimentos Conheça o seu cliente (KYC).
De acordo com a KYC, estamos comprometidos em verificar quem é nosso cliente e se ele está associado a grupos socialmente perigosos. Portanto, temos duas obrigações:
- Identificação e confirmação da identidade do cliente.
- Reconciliação de seus dados com várias listas: terroristas, pessoas sob sanções, membros do governo e muitos outros.
Todos os anos, os requisitos da KYC estão se tornando mais rigorosos e detalhados. No início de 2017, os clientes do ePayments ainda podiam receber pagamentos ou fazer transferências sem verificação. Agora isso não é possível até que eles confirmem sua identidade.
Verificação manual
Alguns anos atrás, lidamos sozinhos. Os russos enviaram uma varredura de certas páginas do passaporte para confirmar sua identidade, e uma varredura do contrato de locação, um recibo para pagamento de moradia e serviços comunitários para confirmar o endereço. Lembre-se do jogo Papers, por favor? Nele, atuando como funcionário da alfândega, você confere documentos em relação aos requisitos cada vez mais complexos do governo. Nosso departamento de atendimento ao cliente trabalhava todos os dias.

Os clientes são verificados remotamente, sem uma visita ao escritório. Para agilizar o processo, contratamos novos funcionários, mas esse é um beco sem saída. Então surgiu a idéia de confiar parte do trabalho da rede neural. Se ela lida bem com o reconhecimento facial, então lida com as nossas tarefas. Da perspectiva dos negócios, um sistema de verificação rápida deve ser capaz de:
- Classifique um documento. É-nos enviado um bilhete de identidade e confirmação do endereço de residência. O sistema deve responder ao que recebeu na entrada: o passaporte de um cidadão da Federação Russa, um contrato de locação ou algo mais.
- Compare o rosto na foto e no documento. Pedimos aos clientes que enviem selfies com um cartão de identidade para garantir que eles mesmos estejam registrados no sistema de pagamento.
- Extrair texto. Preencher dezenas de campos de um smartphone não é muito conveniente. É muito mais fácil se o aplicativo fez tudo por você.
- Verifique os arquivos de imagem para montagem de fotos. Não devemos esquecer os golpistas que desejam entrar no sistema de forma fraudulenta.
Na saída, o sistema deve indicar um certo nível de confiança no cliente: alto, médio ou baixo. Concentrando-se nessa classificação, verificaremos rapidamente e não irritaremos os clientes com períodos prolongados.
Classificador de documentos
A tarefa deste módulo é garantir que o usuário envie um documento válido e responda exatamente o que ele enviou: um passaporte de um cidadão do Cazaquistão, um contrato de locação ou um recibo para pagamento de moradia e serviços comunitários.
O classificador recebe os dados de entrada:
- Documento de foto ou digitalização
- País de residência
- Tipo de documento indicado pelo cliente (bilhete de identidade ou comprovante de endereço)
- Texto extraído (mais sobre isso abaixo)
Na saída, o classificador relata o que recebeu (passaporte, carteira de motorista etc.) e quão confiante está na resposta correta.

A solução agora é executada na arquitetura Wide Residual Network. Nós não a procuramos imediatamente. A primeira versão do sistema de verificação rápida funcionou com base na arquitetura que a VGG nos inspirou. Ela tinha dois problemas óbvios: um grande número de parâmetros (cerca de 130 milhões) e instabilidade na posição do documento. Quanto mais parâmetros, mais difícil é treinar uma rede neural - ela generaliza mal o conhecimento. O documento da fotografia deve ser centralizado, caso contrário, o classificador deverá ser treinado nas amostras em que está localizado em diferentes partes da fotografia. Como resultado, abandonamos o VGG e decidimos mudar para uma arquitetura diferente.
A rede residual (ResNet) foi mais fria que a VGG. Graças a
pular conexões, você pode criar um grande número de camadas e obter alta precisão. A ResNet possui apenas cerca de 1 milhão de parâmetros e ela era indiferente à posição do documento. Não importa onde esteja localizado na imagem, a solução nessa arquitetura lidou com a classificação.
Enquanto estávamos finalizando a solução com um arquivo, uma nova modificação de arquitetura, a Wide Residual Network (WRN), foi lançada. A principal diferença do ResNet é um passo atrás em termos de profundidade. O WRN tem menos camadas, mas mais filtros convolucionais. Agora, essa é a melhor arquitetura de rede neural para a maioria das tarefas e nossa solução funciona nela.
Algumas soluções úteis
Problema número 1. O classificador precisava ser treinado. Tivemos que baixar muitos passaportes e carteiras de motorista russas, cazaques e bielorrussas. Mas, é claro, você não pode levar documentos de clientes. Existem amostras na rede, mas há muito poucas para treinar com sucesso a rede neural.
Solução. Nosso departamento técnico gerou uma amostra de mais de 8000 amostras de cada tipo. Criamos um modelo de documento e multiplicamos por muitas amostras aleatórias. Em seguida, geramos uma posição aleatória do documento no espaço em relação à câmera, levando em consideração seu modelo matemático e características: distância focal, resolução da matriz e assim por diante. Ao gerar uma fotografia artificial, uma imagem aleatória do conjunto de dados final é selecionada como plano de fundo. Depois disso, um documento com distorções de perspectiva é colocado na imagem aleatoriamente. Em tal amostra, nossa rede neural foi bem treinada e definiu perfeitamente o documento "em batalha". Os resultados estão no final do artigo.
Problema número 2. Restrição banal aos recursos de computação e memória. Não faz sentido submeter uma rede neural profunda à entrada de imagens grandes. E as fotos dos smartphones modernos são exatamente isso.
Solução. Antes de aplicar a entrada, a foto é compactada para um tamanho de aproximadamente 300x300 pixels. A partir da imagem dessa permissão, é possível distinguir facilmente um documento de identificação de outro. Para resolver esse problema, podemos usar a arquitetura Wide ResNet padrão.
Problema número 3. Com documentos confirmando o endereço de residência, tudo fica mais complicado. O contrato de locação ou extrato bancário só pode ser distinguido pelo texto na planilha. Depois de reduzir o tamanho da imagem para os mesmos 300 x 300 pixels, qualquer um desses documentos parece o mesmo - como uma folha A4 com texto ilegível.
Solução. Para classificar documentos arbitrários, fizemos alterações na arquitetura da própria rede neural. Uma camada de entrada adicional de neurônios apareceu nela, que é conectada à camada de saída. Os neurônios dessa camada de entrada recebem uma entrada de vetor que descreve o texto reconhecido anteriormente usando o modelo
Bag-of-Words .
Primeiro, treinamos uma rede neural para classificar documentos de identidade. Usamos os pesos da rede treinada ao inicializar outra rede com uma camada adicional para classificar documentos arbitrários. Essa solução tinha alta precisão, mas o reconhecimento de texto levou algum tempo. A diferença na velocidade de processamento entre os diferentes módulos e a precisão da classificação pode ser vista na tabela No. 2.
Reconhecimento de rosto
Como enganar um sistema de pagamento que verifica documentos? Você pode emprestar o passaporte de outra pessoa e se registrar usando-o. Para garantir que o cliente esteja se registrando, solicitamos que você tire uma selfie com um cartão de identidade. E o módulo de reconhecimento deve comparar o rosto no documento e o rosto na selfie e responder, essa é uma pessoa ou duas diferentes.
Como comparar duas faces se você é um carro e pensa como um carro? Transforme uma foto em um conjunto de parâmetros e compare seus valores entre si. É assim que as redes neurais que reconhecem rostos funcionam. Eles pegam uma imagem e a transformam em um vetor de 128 dimensões (por exemplo). Quando você envia outra imagem de rosto para a entrada e pede para comparar, a rede neural transforma a segunda face em um vetor e calcula a distância entre eles.
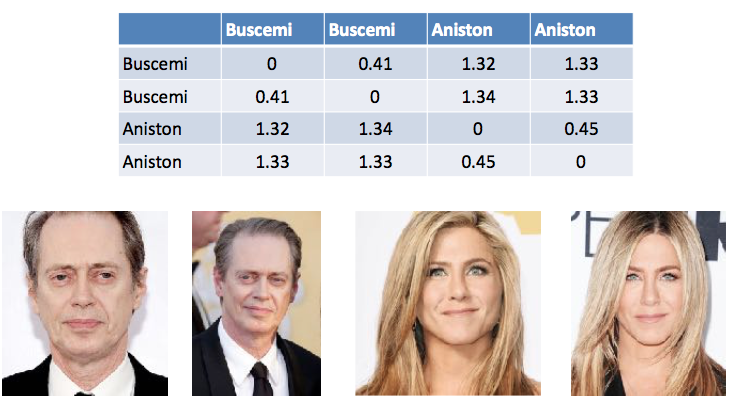 Tabela 1. Um exemplo de cálculo da diferença entre vetores no reconhecimento de face. Steve Buscemi difere de si mesmo em fotos diferentes em 0,44. E de Jennifer Aniston - uma média de 1,33.
Tabela 1. Um exemplo de cálculo da diferença entre vetores no reconhecimento de face. Steve Buscemi difere de si mesmo em fotos diferentes em 0,44. E de Jennifer Aniston - uma média de 1,33.Obviamente, existem diferenças entre a aparência de uma pessoa na vida e o passaporte. Também selecionamos a distância entre os vetores e testamos em pessoas reais para obter um resultado. De qualquer forma, a decisão final será agora tomada pela pessoa e um comentário do sistema será apenas uma recomendação.
Reconhecimento de texto
Existem campos de texto nos documentos que ajudam o classificador a entender o que está à sua frente. Será conveniente para o usuário se o texto do mesmo passaporte for transferido automaticamente e não precisar ser digitado manualmente, por quem e quando foi emitido. Para isso, criamos o seguinte módulo - reconhecimento e extração de texto.
Em alguns documentos, por exemplo, novos passaportes da Federação Russa, há zona de leitura automática (MRZ). Com sua ajuda, é fácil obter informações - é fácil ler texto em preto sobre fundo branco, fácil de reconhecer. Além disso, o MRZ possui um formato conhecido, graças ao qual é mais fácil obter os dados necessários.

Se a tarefa tiver documentos com MRZ, será mais fácil para nós. Todo o processo está no campo da visão computacional. Se essa zona não estiver lá, depois de reconhecer o texto, você precisará resolver um problema interessante - entender e quais informações reconhecemos? Por exemplo, "15 de maio de 1999" é a data de nascimento ou a data de emissão? Nesta fase, você também pode cometer um erro. O MRZ é bom porque é decodificado exclusivamente. Sempre sabemos quais informações e em que parte do MRZ procurar. É muito conveniente para nós. Mas a MRZ não estava no documento mais popular com o qual a rede funcionaria - o passaporte da Federação Russa.
Para o reconhecimento de texto, precisávamos de uma solução muito eficaz. O texto deverá ser removido da imagem tirada pela câmera do telefone e não pelos fotógrafos mais profissionais. Testamos o Google Tesseract e várias soluções pagas. Nada surgiu - ou funcionou mal ou foi excessivamente caro. Como resultado, começamos a desenvolver nossa própria solução. Agora estamos terminando seus testes. A solução mostra resultados decentes - você pode ler sobre eles abaixo. Falaremos sobre o módulo para verificar a montagem de fotos um pouco mais tarde, quando haverá resultados precisos de pesquisa em amostras de testes e na "batalha".
Resultado
Atualmente, o sistema está sendo testado no segmento de aplicativos para verificação da Rússia. O segmento é determinado por amostragem aleatória, os resultados são salvos e comparados com as decisões do operador do departamento do cliente para um cliente específico.
| País de origem | Tipo de classificador | Precisão | Tempo de trabalho, s |
| Rússia | Carteira de identidade | 99,96% | 0,41 |
| Rússia | Documento personalizado | 98,62% | 6,89 |
| Cazaquistão | Carteira de identidade | 99,51% | 0,47 |
| Cazaquistão | Documento personalizado | 97,25% | 7.66 |
| Bielorrússia | Carteira de identidade | 98,63% | 0,46 |
| Bielorrússia | Documento personalizado | 98,63% | 9,66 |
Tabela 2. A precisão do classificador de documentos (a classificação correta do documento em comparação com a avaliação do operador).Uma das grandes vantagens do aprendizado de máquina é que a rede neural realmente aprende e comete menos erros. Em breve, concluiremos os testes no segmento e iniciaremos o sistema de verificação no modo "combate". 30% dos pedidos de verificação são provenientes de pagamentos eletrônicos da Rússia, Cazaquistão e Bielorrússia. De acordo com nossas estimativas, o lançamento ajudará a reduzir a carga no departamento do cliente em 20 a 25%. No futuro, a solução poderá ser dimensionada para países europeus.
Procurando emprego?
Estamos à procura de funcionários para trabalhar em um escritório em São Petersburgo. Se você está interessado em um projeto internacional com um grande conjunto de tarefas ambiciosas, estamos esperando por você. Não temos pessoas suficientes que não tenham medo de percebê-las. Abaixo você encontrará links para vagas em hh.ru.