
Este artigo faz parte do
Chronicle of Software Architecture , uma série de artigos sobre arquitetura de software. Neles, escrevo sobre o que aprendi sobre arquitetura de software, o que penso e como uso o conhecimento. O conteúdo deste artigo pode fazer mais sentido se você ler os artigos anteriores da série.
Depois de me formar na universidade, comecei a trabalhar como professor do ensino médio, mas há alguns anos desisti e fui para os desenvolvedores de software em tempo integral.
Desde então, sempre senti que precisava recuperar o tempo "perdido" e descobrir o máximo possível, o mais rápido possível. Portanto, comecei a me envolver um pouco nos experimentos, a ler e escrever bastante, prestando especial atenção ao design e arquitetura do software. É por isso que estou escrevendo esses artigos para me ajudar nos meus estudos.
Nos últimos artigos, falei sobre muitos conceitos e princípios que aprendi e um pouco sobre como raciocino sobre eles. Mas eu os imagino como fragmentos de um grande quebra-cabeça.
Este artigo é sobre como eu reuni todos esses fragmentos. Acho que devo dar um nome a eles, por isso vou chamá-los de
arquitetura explícita . Além disso, todos esses conceitos são
"testados em batalha" e são usados na produção em plataformas altamente confiáveis. Uma delas é uma plataforma de comércio eletrônico SaaS com milhares de lojas online em todo o mundo, a outra é uma plataforma de negociação que opera em dois países com um barramento de mensagens que processa mais de 20 milhões de mensagens por mês.
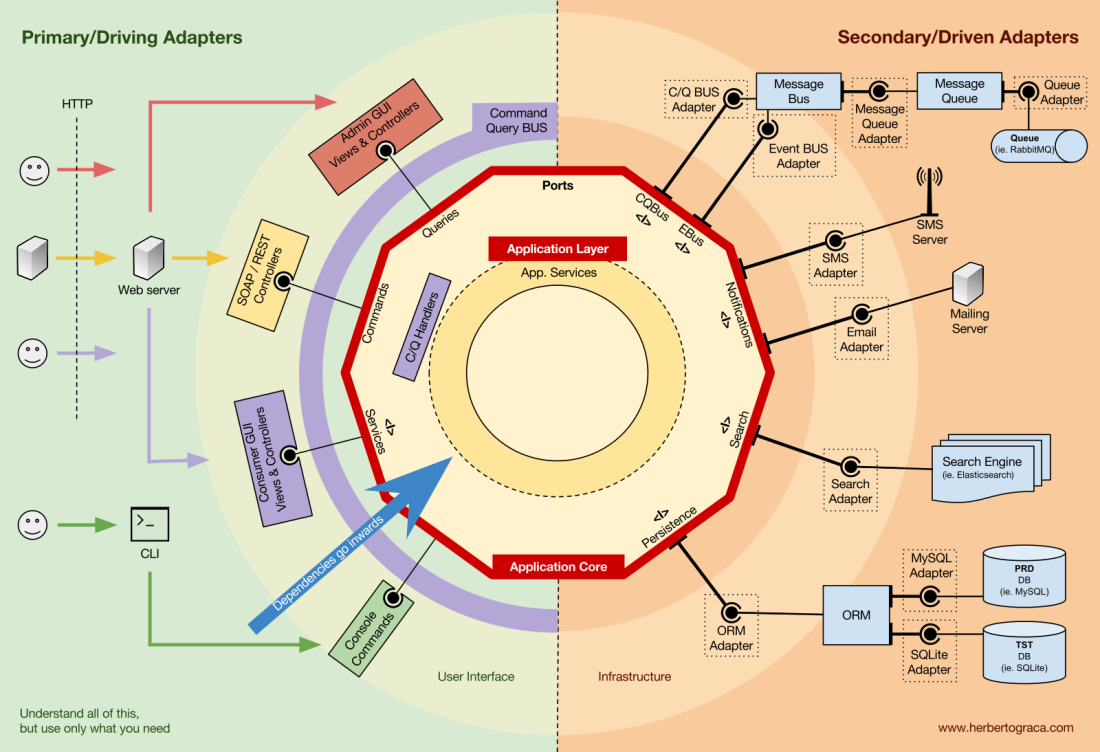
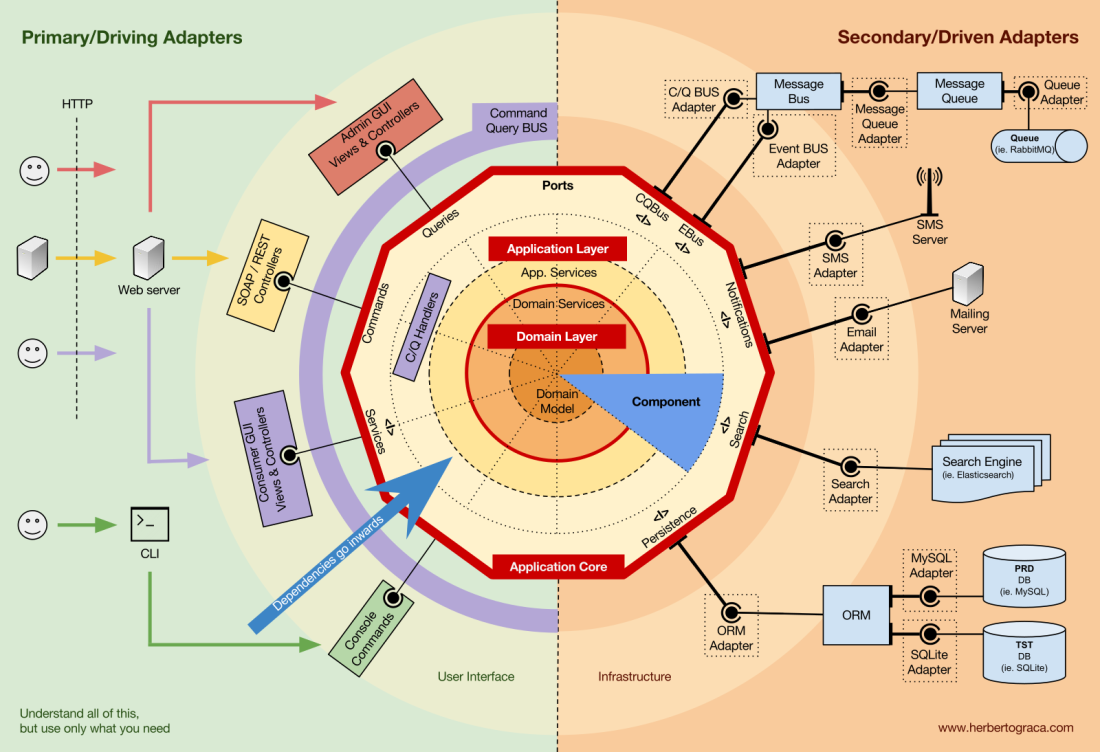
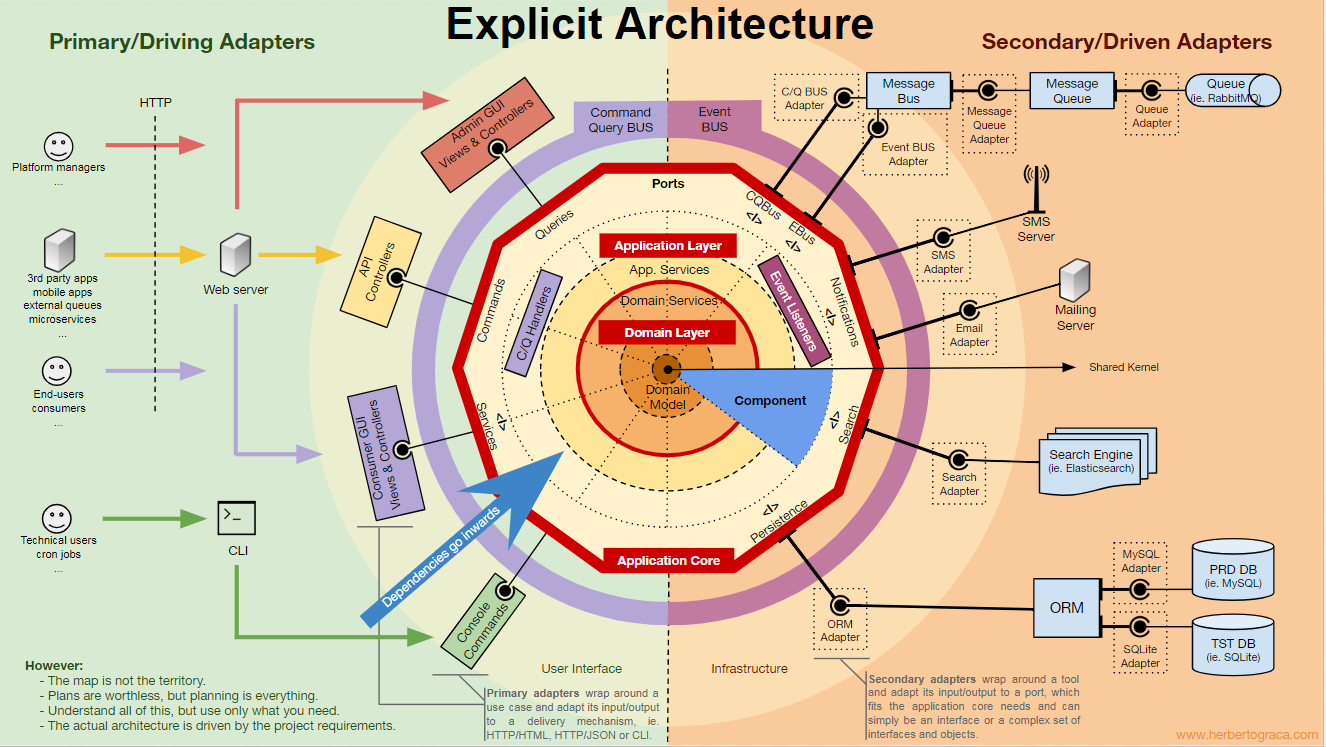
Blocos fundamentais do sistema
Vamos começar
lembrando as arquiteturas
EBI e
Ports & Adapters . Ambos separam claramente o código interno e externo do aplicativo, bem como os adaptadores para conectar o código interno e externo.
Além disso, a arquitetura de
portas e adaptadores define explicitamente os três blocos fundamentais de código no sistema:
- Isso permite que você execute a interface do usuário , independentemente do seu tipo.
- Lógica de negócios do sistema ou núcleo do aplicativo . É usado pela interface do usuário para fazer transações reais.
- O código de infraestrutura que conecta o núcleo do nosso aplicativo a ferramentas como banco de dados, mecanismo de pesquisa ou APIs de terceiros.
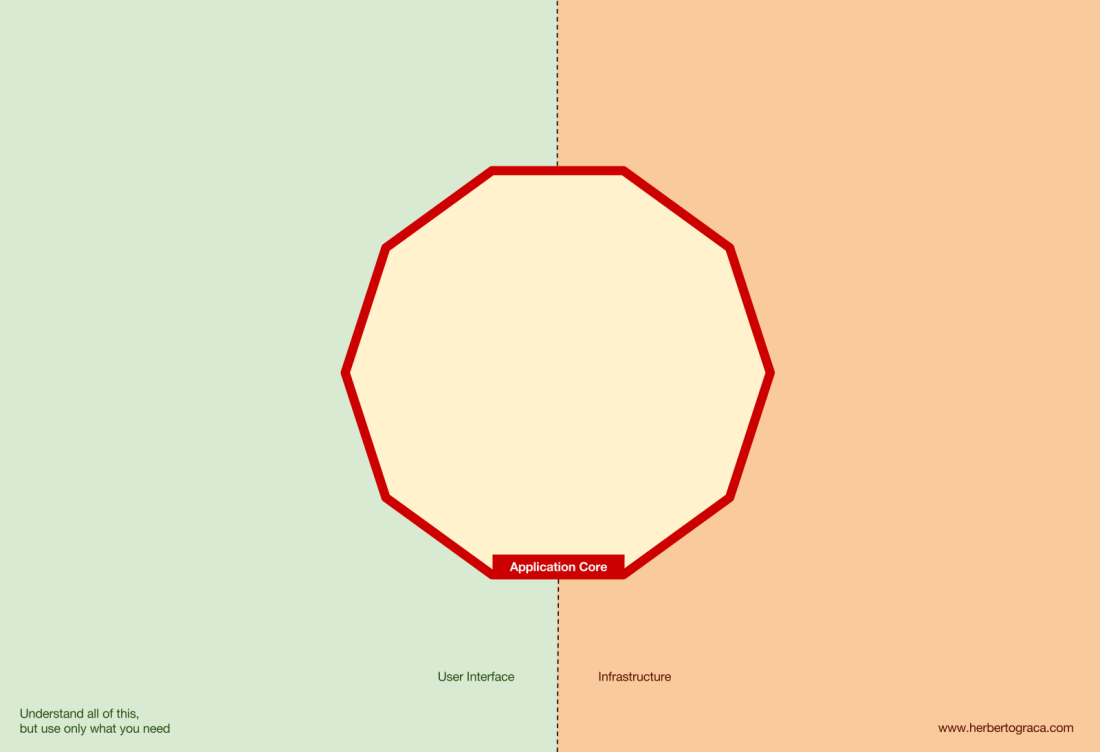
O núcleo do aplicativo é a coisa mais importante a se pensar. Este código permite que você execute ações reais no sistema, ou seja, este é o nosso aplicativo. Várias interfaces de usuário (um aplicativo da web progressivo, aplicativo móvel, CLI, API etc.) podem funcionar com ele, tudo é executado em um único núcleo.
Como você pode imaginar, um fluxo de execução típico vai do código na interface do usuário através do núcleo do aplicativo até o código da infraestrutura, volta ao núcleo do aplicativo e, finalmente, a resposta é entregue à interface do usuário.

As ferramentas
Longe do código do kernel mais importante, ainda existem ferramentas que o aplicativo usa. Por exemplo, o mecanismo de banco de dados, mecanismo de pesquisa, servidor da Web e console da CLI (embora os dois últimos também sejam mecanismos de entrega).
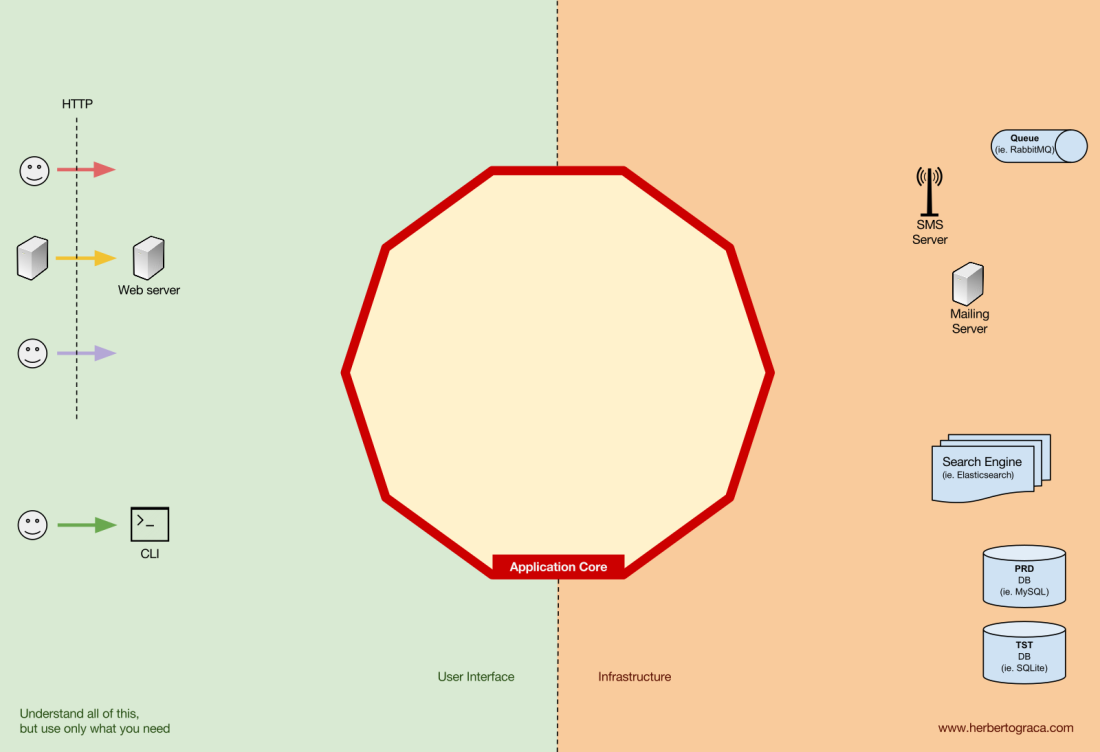
Parece estranho colocar o console da CLI na mesma seção temática do DBMS, porque eles têm uma finalidade diferente. Mas, de fato, ambos são ferramentas usadas pelo aplicativo. A principal diferença é que o console da CLI e o servidor da Web
instruem o aplicativo a fazer alguma coisa ; o kernel do DBMS, pelo contrário,
recebe comandos do aplicativo . Essa é uma diferença muito importante, pois afeta muito a maneira como escrevemos código para conectar essas ferramentas ao núcleo do aplicativo.
Conectando ferramentas e mecanismos de entrega ao núcleo do aplicativo
Blocos de ferramentas de conexão de código ao núcleo do aplicativo são chamados de adaptadores (
arquitetura de portas e adaptadores ). Eles permitem que a lógica de negócios interaja com uma ferramenta específica e vice-versa.
Os adaptadores que instruem o aplicativo a fazer algo são chamados de
adaptadores principais ou de controle , enquanto os adaptadores que instruem o aplicativo a fazer algo são chamados de
adaptadores secundários ou gerenciados .
Portas
No entanto, esses
adaptadores não são criados por acaso, mas correspondem a um ponto de entrada específico na
porta principal do aplicativo. Uma porta
nada mais é do que uma especificação de como a ferramenta pode usar o núcleo do aplicativo ou vice-versa. Na maioria dos idiomas e em sua forma mais simples, essa porta será uma interface, mas na verdade pode ser composta de várias interfaces e DTO.
É importante observar que as
portas (interfaces) estão dentro da lógica de negócios e os adaptadores estão fora. Para que esse modelo funcione corretamente, é extremamente importante criar portas de acordo com as necessidades do núcleo do aplicativo e não apenas imitar as APIs da ferramenta.
Adaptadores primários ou de controle
Adaptadores primários ou de controle
envolvem uma porta e a usam para informar ao kernel do aplicativo o que fazer.
Eles transformam todos os dados do mecanismo de entrega em chamadas de método no núcleo do aplicativo.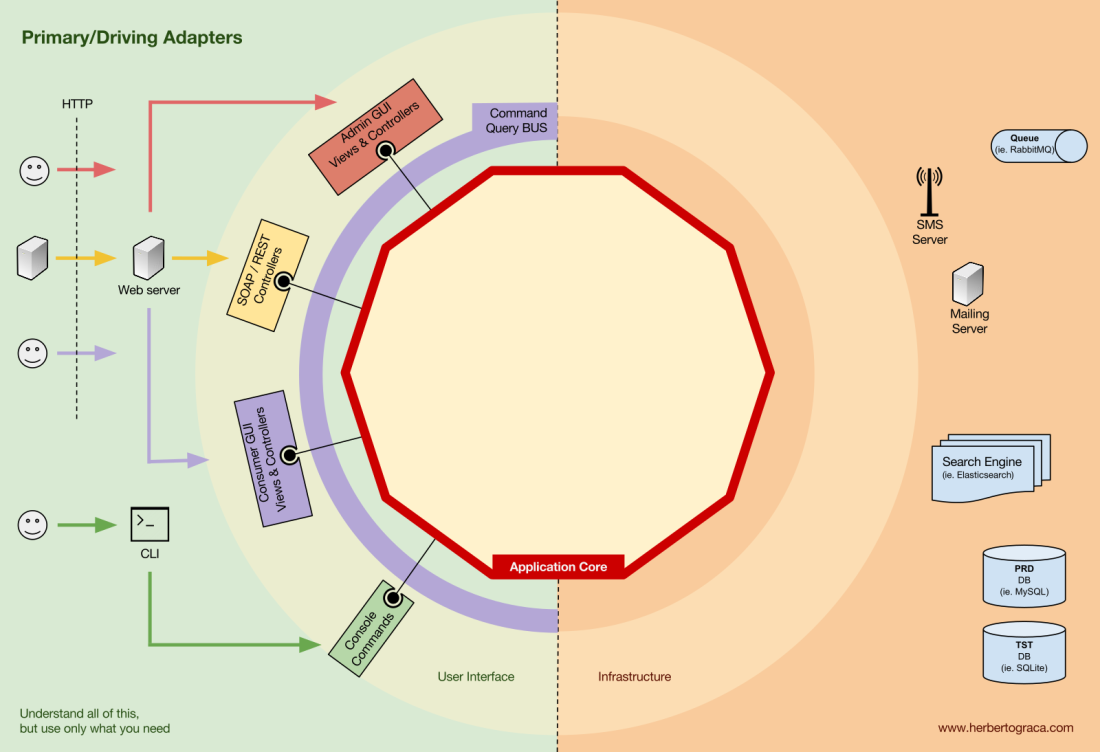
Em outras palavras, nossos adaptadores de controle são controladores ou comandos do console, eles são incorporados ao construtor com algum objeto cuja classe implementa a interface (porta) necessária para um controlador ou comando do console.
Em um exemplo mais específico, a porta pode ser a interface de serviço ou a interface do repositório que o controlador requer. Uma implementação específica de um serviço, repositório ou solicitação é então implementada e usada no controlador.
Além disso, a porta pode ser um barramento de comando ou uma interface de barramento de consulta. Nesse caso, uma implementação específica do barramento de comando ou solicitação é inserida no controlador, que cria um comando ou solicitação e o passa para o barramento correspondente.
Adaptadores secundários ou gerenciados
Ao contrário dos adaptadores de controle que envolvem uma porta, os
adaptadores gerenciados implementam uma porta, uma interface e entram no núcleo do aplicativo em que a porta é necessária (com tipo).

Por exemplo, temos um aplicativo nativo que precisa salvar dados. Criamos uma interface de persistência com um método para
salvar uma matriz de dados e um método para
excluir uma linha em uma tabela por seu ID. A partir de agora, sempre que o aplicativo precisar salvar ou excluir dados, solicitaremos no construtor um objeto que implemente a interface de persistência que definimos.
Agora crie um adaptador específico do MySQL que implementará essa interface. Ele terá métodos para salvar a matriz e excluir a linha da tabela, e a apresentaremos sempre que a interface de persistência for necessária.
Se, em algum momento, decidirmos mudar o provedor de banco de dados, por exemplo, para PostgreSQL ou MongoDB, precisamos criar um novo adaptador que implemente a interface de persistência específica para o PostgreSQL e introduzir um novo adaptador em vez do antigo.
Inversão de controle
Um recurso característico desse modelo é que os adaptadores dependem de uma ferramenta específica e de uma porta específica (implementando uma interface). Mas nossa lógica de negócios depende apenas da porta (interface), projetada para atender às necessidades da lógica de negócios e não depende de um adaptador ou ferramenta específica.
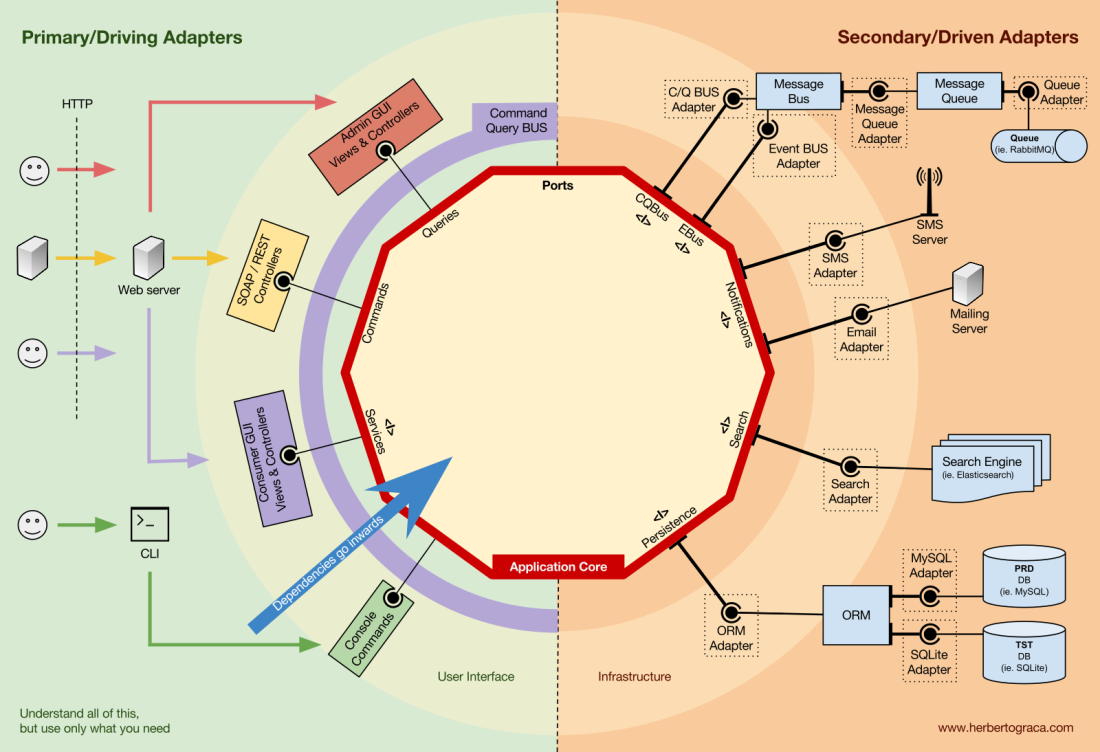
Isso significa que as dependências são direcionadas para o centro, ou seja, há uma
inversão do princípio de controle no nível arquitetural .
Embora, novamente,
seja imperativo que as portas sejam criadas de acordo com as necessidades do núcleo do aplicativo e não apenas imitem as APIs da ferramenta .
Organização do núcleo do aplicativo
A arquitetura Onion pega as camadas DDD e as incorpora na
arquitetura de porta e adaptador . Esses níveis foram projetados para trazer alguma ordem à lógica comercial, o interior do “hexágono” de portas e adaptadores. Como antes, a direção das dependências é em direção ao centro.
Camada de Aplicação (Camada de Aplicação)
Casos de uso são processos que podem ser iniciados no kernel por uma ou mais interfaces de usuário. Por exemplo, um CMS pode ter uma interface do usuário para usuários regulares, outra interface independente para administradores do CMS, outra CLI e uma API da web. Essas UIs (aplicativos) podem acionar casos de uso exclusivos ou comuns.
Os casos de uso são definidos no nível do aplicativo - o primeiro nível do DDD e a arquitetura Onion.
Essa camada contém serviços de aplicativos (e suas interfaces) como objetos de primeira classe e também interfaces de porta e adaptador (portas), que incluem interfaces ORM, interfaces de mecanismo de pesquisa, interfaces de mensagens, etc. No caso em que usamos o barramento de comando e / ou o barramento de solicitação, nesse nível, são os manipuladores de comando e solicitação correspondentes.
Os serviços de aplicativo e / ou manipuladores de comando contêm a lógica de implementação de um caso de uso, um processo de negócios. Como regra, seu papel é o seguinte:
- use o repositório para procurar uma ou mais entidades;
- peça a essas entidades que executem alguma lógica de domínio;
- e use o armazenamento para salvar novamente entidades, salvando efetivamente alterações de dados.
Os manipuladores de comando podem ser usados de duas maneiras:
- Eles podem conter lógica para executar um caso de uso;
- Eles podem ser usados como partes simples de uma conexão em nossa arquitetura que recebem um comando e simplesmente invocam a lógica existente no serviço de aplicativo.
Qual abordagem usar depende do contexto, por exemplo:
- Já temos serviços de aplicativos e agora o barramento de comando está sendo adicionado?
- O barramento de comando permite especificar uma classe / método como manipulador ou você precisa estender ou implementar classes ou interfaces existentes?
Essa camada também contém
eventos de aplicativos acionadores que representam algum resultado de um caso de uso. Esses eventos acionam a lógica que é um efeito colateral de um caso de uso, como enviar emails, notificar uma API de terceiros, enviar uma notificação por push ou até iniciar outro caso de uso que pertença a outro componente do aplicativo.
Nível de domínio
Mais para dentro, existe um nível de domínio. Os objetos nesse nível contêm dados e lógica para gerenciar esses dados, que são específicos ao próprio domínio e são independentes dos processos de negócios que acionam essa lógica. Eles são independentes e desconhecem completamente o nível do aplicativo.
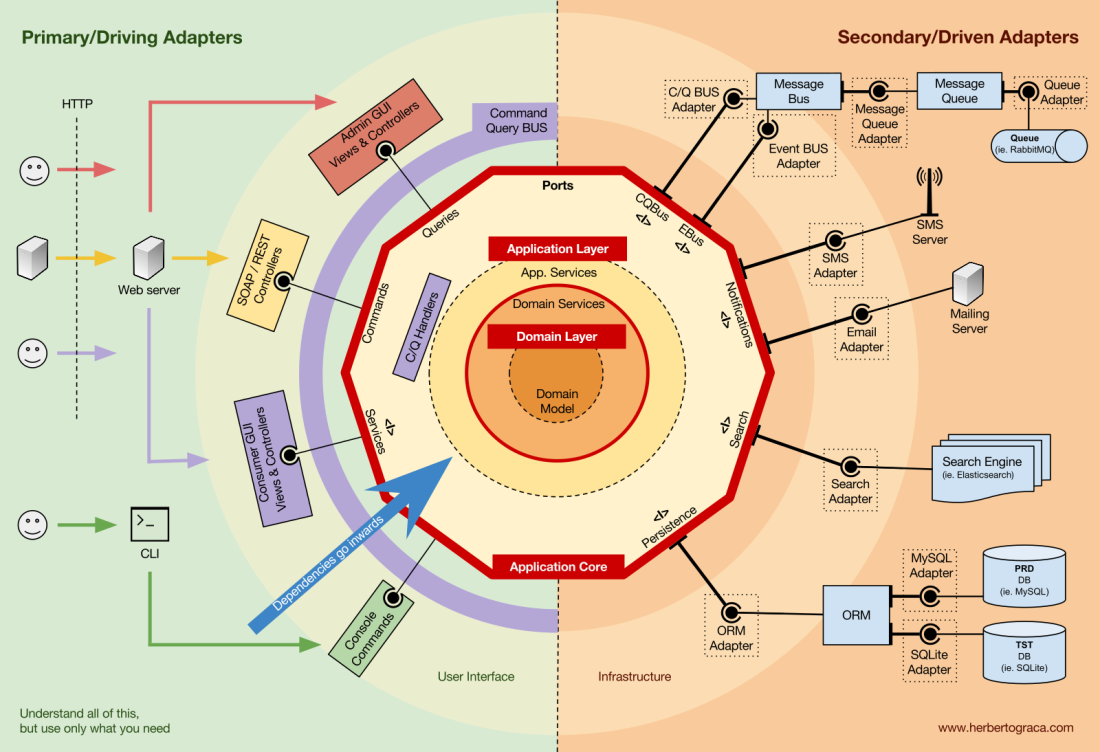
Serviços de Domínio
Como mencionei acima, o papel do serviço de aplicativo:
- use o repositório para procurar uma ou mais entidades;
- peça a essas entidades que executem alguma lógica de domínio;
- e use o armazenamento para salvar novamente entidades, salvando efetivamente alterações de dados.
Mas, às vezes, encontramos uma lógica de domínio, que inclui várias entidades do mesmo ou de tipos diferentes, e essa lógica de domínio não pertence às próprias entidades, ou seja, a lógica não é de sua responsabilidade direta.
Portanto, nossa primeira reação pode ser colocar essa lógica fora das entidades no serviço de aplicativo. No entanto, isso significa que, em outros casos, a lógica do domínio não será reutilizada: a lógica do domínio deve permanecer fora do nível do aplicativo!
A solução é criar um serviço de domínio, cuja função é obter um conjunto de entidades e executar alguma lógica de negócios nelas. Um serviço de domínio pertence a um nível de domínio e, portanto, não sabe nada sobre classes no nível do aplicativo, como serviços ou repositórios de aplicativos. Por outro lado, ele pode usar outros serviços de domínio e, é claro, objetos de modelo de domínio.
Modelo de domínio
No centro, está o modelo de domínio. Não depende de nada fora deste círculo e contém objetos de negócios que representam algo no domínio. Exemplos de tais objetos são, antes de tudo, entidades, bem como objetos de valor, enumerações e quaisquer objetos usados no modelo de domínio.
Eventos de domínio também vivem no modelo de domínio. Quando um conjunto de dados específico é alterado, esses eventos são acionados, os quais contêm novos valores das propriedades alteradas. Esses eventos são ideais, por exemplo, para uso no módulo de fornecimento de eventos.
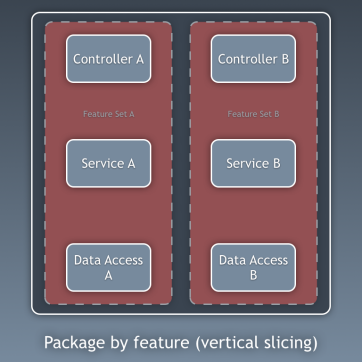
Componentes
Até agora, temos código isolado em camadas, mas isso é um isolamento de código muito detalhado. É igualmente importante olhar para a foto com uma aparência mais geral. Estamos falando de dividir o código em subdomínios e
contextos relacionados, de acordo com as idéias de Robert Martin expressas na
arquitetura gritante [isto é, a arquitetura deve "gritar" sobre o próprio aplicativo, e não sobre quais estruturas ele usa - aprox. trans.]. Eles falam sobre a organização de pacotes por função ou componente, e não por camada, e Simon Brown explicou muito bem em seu artigo
“Pacotes de componentes e testes de acordo com a arquitetura” em seu blog:
Sou um defensor da organização de pacotes de componentes e quero alterar descaradamente o diagrama de Simon Brown da seguinte maneira:
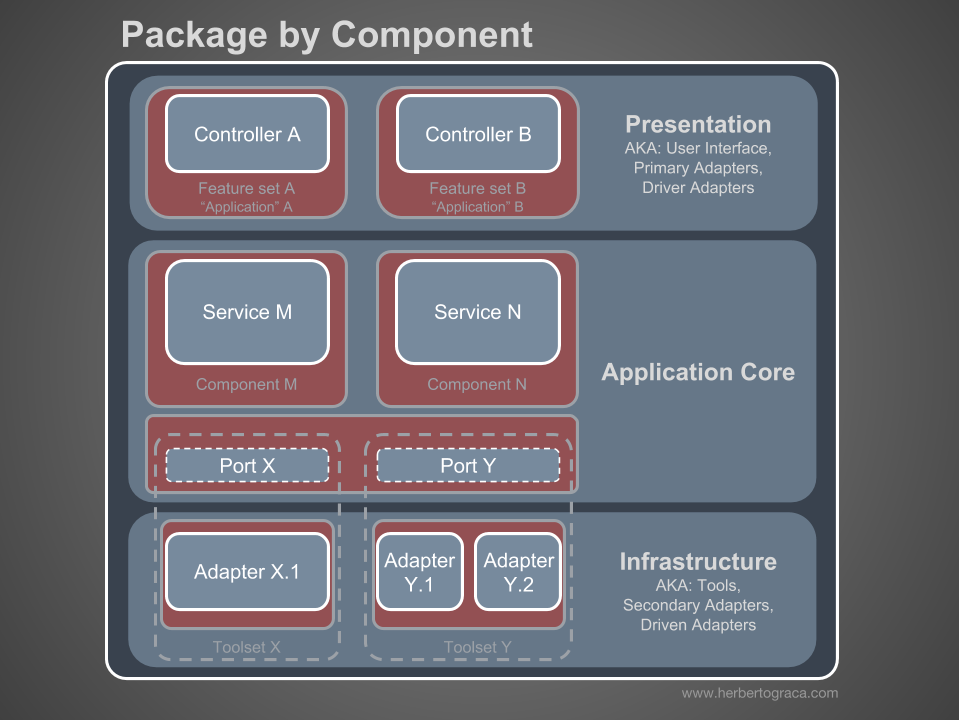
Essas seções do código são transversais para todas as camadas descritas anteriormente e esses são os
componentes de nosso aplicativo. Exemplos de componentes são cobrança, usuário, verificação ou conta, mas eles sempre estão associados a um domínio. Contextos limitados, como autorização e / ou autenticação, devem ser considerados como ferramentas externas para as quais criamos um adaptador e nos escondemos atrás de uma porta.
Desconexão de componentes
Assim como nas unidades de código refinadas (classes, interfaces, características, mixins, etc.), as unidades grandes (componentes) se beneficiam do acoplamento fraco e da conectividade rígida.
Para separar classes, usamos injeção de dependência, introduzindo dependências na classe, em vez de criá-las dentro da classe, e também invertendo as dependências, tornando a classe dependente de abstrações (interfaces e / ou classes abstratas) em vez de classes específicas. Isso significa que a classe dependente não sabe nada sobre a classe específica que usará, não possui uma referência ao nome completo das classes das quais depende.
Da mesma forma, em componentes completamente desconectados, cada componente não sabe nada sobre nenhum outro componente. Em outras palavras, ele não tem link para nenhum bloco de código refinado de outro componente, mesmo para a interface! Isso significa que a injeção de dependência e a inversão de dependência não são suficientes para separar os componentes; precisaremos de algum tipo de construção arquitetônica. Eventos, um núcleo comum, consistência eventual e até um serviço de descoberta podem ser necessários!
Disparando a lógica em outros componentes
Quando um de nossos componentes (componente B) precisa fazer algo sempre que algo acontece em outro componente (componente A), não podemos apenas fazer uma chamada direta do componente A para a classe / método do componente B, porque então A será conectado a B.
No entanto, podemos usar o gerenciador de eventos para despachar o evento do aplicativo, que será entregue a qualquer componente que o ouça, incluindo B, e o ouvinte de evento em B acionará a ação desejada. Isso significa que o componente A dependerá do gerenciador de eventos, mas será separado do componente B.
No entanto, se o evento em si "vive" em A, isso significa que B conhece a existência de A e está associado a ele. Para remover essa dependência, podemos criar uma biblioteca com um conjunto de funcionalidades do núcleo do aplicativo que serão compartilhadas por todos os componentes - um
núcleo comum . Isso significa que os dois componentes dependerão do núcleo comum, mas serão separados um do outro. Um núcleo comum contém funcionalidades como eventos de aplicativo e domínio, mas também pode conter objetos de especificação e qualquer coisa que faça sentido compartilhar. Ao mesmo tempo, deve ter um tamanho mínimo, pois qualquer alteração no kernel comum afetará todos os componentes do aplicativo. Além disso, se tivermos um sistema poliglota, digamos, um ecossistema de microsserviços em diferentes idiomas, o núcleo comum não deve depender do idioma para que todos os componentes o entendam. Por exemplo, em vez de um kernel comum com uma classe de eventos, ele conterá uma descrição do evento (ou seja, um nome, propriedades, talvez até métodos, embora sejam mais úteis no objeto de especificação) em uma linguagem universal como JSON, para que todos os componentes / microsserviços possam interpretá-lo e talvez até gere automaticamente suas próprias implementações específicas.
Essa abordagem funciona em aplicativos monolíticos e distribuídos, como ecossistemas de microsserviços. Mas se os eventos puderem ser entregues apenas de forma assíncrona, essa abordagem não será suficiente para contextos em que a lógica de acionamento em outros componentes deve funcionar imediatamente! Aqui, o componente A precisará fazer uma chamada HTTP direta para o componente B. Nesse caso, para desconectar os componentes, precisamos de um serviço de descoberta. O componente A perguntará para onde enviar a solicitação para iniciar a ação desejada. Como alternativa, faça uma solicitação ao serviço de descoberta, que o encaminhará para o serviço apropriado e, finalmente, retornará uma resposta ao solicitante.
Essa abordagem associa componentes a um serviço de descoberta, mas não os associa.Recuperando dados de outros componentes
A meu ver, o componente não tem permissão para modificar dados que não são "proprietários", mas pode solicitar e usar qualquer dado.Armazenamento de dados compartilhado para componentes
Se o componente precisar usar dados pertencentes a outro componente (por exemplo, o componente de cobrança deve usar o nome do cliente que pertence ao componente de contas), ele conterá o objeto de solicitação para o armazenamento de dados. Ou seja, o componente de cobrança pode saber sobre qualquer conjunto de dados, mas deve usar dados somente leitura de outros países.Armazenamento de dados separado para o componente
Nesse caso, o mesmo modelo é aplicado, mas o nível de armazenamento de dados se torna mais complicado. A presença de componentes com seu próprio data warehouse significa que cada data warehouse contém:- Um conjunto de dados que um componente possui e pode mudar, tornando-o a única fonte de verdade;
- Um conjunto de dados que é uma cópia dos dados de outros componentes que não podem ser alterados por si só, mas são necessários para a funcionalidade do componente. Esses dados devem ser atualizados sempre que forem alterados no componente proprietário.
Cada componente criará uma cópia local dos dados necessários de outros componentes, que serão usados conforme necessário. Quando os dados são alterados no componente ao qual pertencem, esse componente proprietário aciona um evento de domínio que carrega alterações de dados. Os componentes que contêm uma cópia desses dados ouvirão esse evento de domínio e atualizarão sua cópia local de acordo.Controle de fluxo
Como eu disse acima, o fluxo de controle vai do usuário ao núcleo do aplicativo, às ferramentas de infraestrutura, depois novamente ao núcleo do aplicativo - e de volta ao usuário. Mas como exatamente as aulas funcionam juntas? Quem depende de quem? Como os compomos?Como o tio Bob, em meu artigo sobre arquitetura limpa, tentarei explicar o fluxo do gerenciamento de esquema UMLish ...Sem barramento de comando / solicitação
Se não usarmos o barramento de comando, os controladores dependerão do serviço de aplicativo ou do objeto Query.[Suplemento 18/11/2017] Ignorei completamente o DTO, que utilizo para retornar dados da solicitação, então o adicionei agora. Agradecimentos a MorphineAdministered , que indicou um espaço. No diagrama acima, usamos a interface para o serviço de aplicativo, embora possamos dizer que ele não é realmente necessário, pois o serviço de aplicativo faz parte do nosso código de aplicativo. Mas não queremos alterar a implementação, embora possamos realizar uma refatoração completa. O objeto Query contém uma consulta otimizada que simplesmente retorna alguns dados brutos que serão mostrados ao usuário. Esses dados são retornados ao DTO, incorporado no ViewModel. Esse ViewModel pode ter algum tipo de lógica do View e será usado para preencher o View.Por outro lado, o serviço de aplicativo contém lógica de casos de uso que é acionada quando queremos fazer algo no sistema e não apenas exibir alguns dados. O serviço de aplicativo depende de repositórios que retornam entidades que contêm a lógica que precisa ser iniciada. Também pode depender do serviço de domínio para coordenar o processo de domínio entre várias entidades, mas esse é um caso raro.Depois de analisar o caso de uso, o serviço de aplicativo pode notificar todo o sistema que ocorreu um caso de uso e dependerá do distribuidor de eventos para acionar o evento.É interessante notar que hospedamos interfaces no mecanismo de persistência e nos repositórios. Isso pode parecer redundante, mas eles servem a propósitos diferentes:
O objeto Query contém uma consulta otimizada que simplesmente retorna alguns dados brutos que serão mostrados ao usuário. Esses dados são retornados ao DTO, incorporado no ViewModel. Esse ViewModel pode ter algum tipo de lógica do View e será usado para preencher o View.Por outro lado, o serviço de aplicativo contém lógica de casos de uso que é acionada quando queremos fazer algo no sistema e não apenas exibir alguns dados. O serviço de aplicativo depende de repositórios que retornam entidades que contêm a lógica que precisa ser iniciada. Também pode depender do serviço de domínio para coordenar o processo de domínio entre várias entidades, mas esse é um caso raro.Depois de analisar o caso de uso, o serviço de aplicativo pode notificar todo o sistema que ocorreu um caso de uso e dependerá do distribuidor de eventos para acionar o evento.É interessante notar que hospedamos interfaces no mecanismo de persistência e nos repositórios. Isso pode parecer redundante, mas eles servem a propósitos diferentes:- A interface Persistence é uma camada de abstração sobre o ORM, para que possamos trocar o ORM sem alterar o núcleo do aplicativo.
- persistence-. , MySQL MongoDB. persistence- , ORM, . , , , , , , MongoDB SQL.
C /
Se nosso aplicativo usa o barramento de comando / solicitação, o diagrama permanece quase o mesmo, exceto que o controlador agora depende do barramento, bem como de comandos ou solicitações. Uma instância de um comando ou solicitação é criada aqui e passada para o barramento, que encontrará o manipulador apropriado para receber e processar o comando.No diagrama abaixo, o manipulador de comandos usa o serviço de aplicativo. Mas isso nem sempre é necessário, porque na maioria dos casos o manipulador conterá toda a lógica do caso de uso. Tudo o que precisamos fazer é extrair a lógica do manipulador para um serviço de aplicativo separado, se precisarmos reutilizar a mesma lógica em outro manipulador.[Suplemento 18/11/2017] Ignorei completamente o DTO, que utilizo para retornar dados da solicitação, então o adicionei agora. ObrigadaMorphineAdministered , que indicava um espaço. Você deve ter notado que não há dependências entre o barramento, o comando, a solicitação e os manipuladores. De fato, eles não precisam se conhecer para garantir uma boa separação. O método de direcionar o barramento para um processador específico para processar um comando ou solicitação é configurado em uma configuração simples. Nos dois casos, todas as setas - dependências que cruzam o limite do kernel do aplicativo - apontam para dentro. Como explicado anteriormente, esta é a regra fundamental da arquitetura de portas e adaptadores, cebola e limpeza.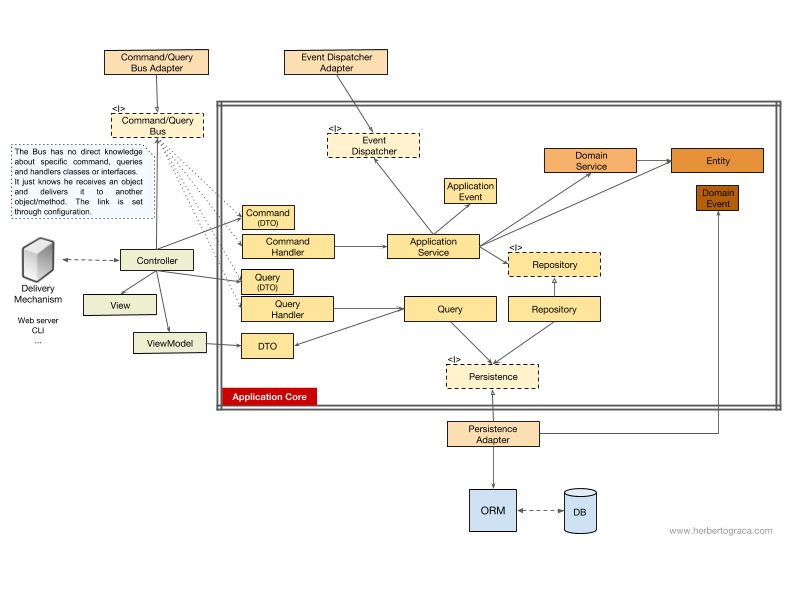

Conclusão
Como sempre, o objetivo é obter uma base de código desconectada com alta conectividade, na qual você pode fazer alterações com facilidade, rapidez e segurança.Os planos são inúteis, mas o planejamento é tudo. - Eisenhower
Este infográfico é um mapa conceitual. Conhecer e entender todos esses conceitos ajuda a planejar uma arquitetura saudável e um aplicativo viável.No entanto:Um mapa não é um território. - Alfred Korzybsky
Em outras palavras, essas são apenas recomendações! Um aplicativo é um território, uma realidade, um caso de uso específico em que precisamos aplicar nosso conhecimento e determina como será a arquitetura real!Precisamos entender todos esses padrões, mas também sempre precisamos pensar e entender o que nossa aplicação precisa, até onde podemos ir em prol da separação e conexão. Essa decisão depende de muitos fatores, desde os requisitos funcionais do projeto, até o momento do desenvolvimento do aplicativo, sua vida útil, a experiência da equipe de desenvolvimento e assim por diante.É assim que imagino tudo isso para mim.Essas idéias são discutidas em mais detalhes no próximo artigo: "Mais do que apenas camadas concêntricas" .