Não confiamos em software há muito tempo e, portanto, realizamos sua auditoria, realizamos engenharia reversa, executamos em um modo passo a passo, executamos na sandbox. E o processador no qual nosso software é executado? - Confiamos cegamente e de todo o coração neste pequeno pedaço de silício. No entanto, o hardware moderno tem os mesmos problemas que o software: funcionalidade secreta não documentada, bugs, vulnerabilidades, malware, cavalos de Troia, rootkits, backdoors.

O ISA (Arquitetura do conjunto de instruções) x86 é uma das “arquiteturas do conjunto de instruções” que mais mudam continuamente na história. Começando com o design do 8086 desenvolvido em 1976, o ISA está passando por mudanças e atualizações contínuas; mantendo a compatibilidade com as versões anteriores e o suporte para a especificação original. Ao longo de 40 anos, a arquitetura ISA cresceu e continua a crescer com muitos novos modos e conjuntos de instruções, cada um dos quais adiciona uma nova camada ao design anterior, que já está sobrecarregado. Devido à política de total compatibilidade com versões anteriores, os modernos processadores x86 ainda contêm instruções e modos que já estão completamente esquecidos. Como resultado, temos uma arquitetura de processador, que é um labirinto complexo de tecnologias novas e antigas. Um ambiente tão complexo - causa muitos problemas com a segurança cibernética do processador. Portanto, os processadores x86 não podem afirmar ser a raiz confiável da infraestrutura cibernética crítica.
Você ainda confia no seu processador?
Segurança de programas e sistema operacional - baseia-se na segurança do hardware no qual eles são implantados. Como regra, os desenvolvedores de software não levam em consideração o fato de que o hardware no qual o software é implantado pode ser não confiável, malicioso. Quando o hardware se comporta erroneamente (intencionalmente ou não), os mecanismos de segurança do software se tornam completamente inúteis. Por muitos anos, vários modelos de processadores seguros foram oferecidos: Intel SGX, AMD Pacifica, etc. No entanto, a regularidade invejável com a qual as informações são publicadas sobre falhas críticas (das mais recentes, por exemplo, Meltdown e Spectre) e detectadas funções não documentadas de "depuração" - levam a o pensamento de que nossa confiança total nos processadores não tem fundamento.
Os processadores x86 modernos são um entrelaçamento muito complexo e complicado das tecnologias mais recentes e antigas. 8086 tinha 29 mil transistores, Pentium 3 milhões, Broadwell 3,2 bilhões, Cannonlake mais de 10 bilhões.
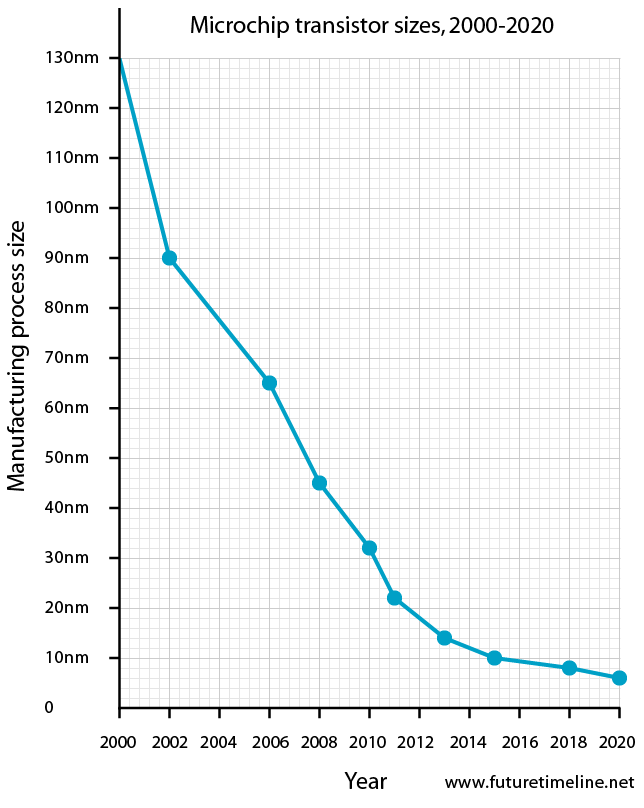
Com tantos transistores, não é surpreendente que os modernos processadores x86 estejam repletos de instruções não documentadas e vulnerabilidades de hardware. Entre os documentos não documentados, descobertos quase por acidente, estão as instruções: ICEBP (0xF1), LOADALL (0x0F07), apicall (0x0FFFF0) [1], que permitem o desbloqueio do processador para acesso não autorizado a áreas de memória protegidas.
Quanto às numerosas vulnerabilidades de hardware dos processadores (veja duas figuras abaixo), elas permitem que um ciberataqueiro tenha privilégios [3], extraia chaves criptográficas [4], crie novas instruções de montagem [2], altere a funcionalidade das instruções de montagem já existentes [2] , instale ganchos nas instruções do montador [2], assuma o controle da “virtualização acelerada por hardware” [7], intervenha nos “cálculos criptográficos atômicos” [7] e, finalmente, doce, entre no “modo deus”: ive-se um hardware legítimo Intel ME backdoor (que permite que você receba acesso remoto mesmo o computador desligado). [8] E tudo isso - sem deixar vestígios digitais.
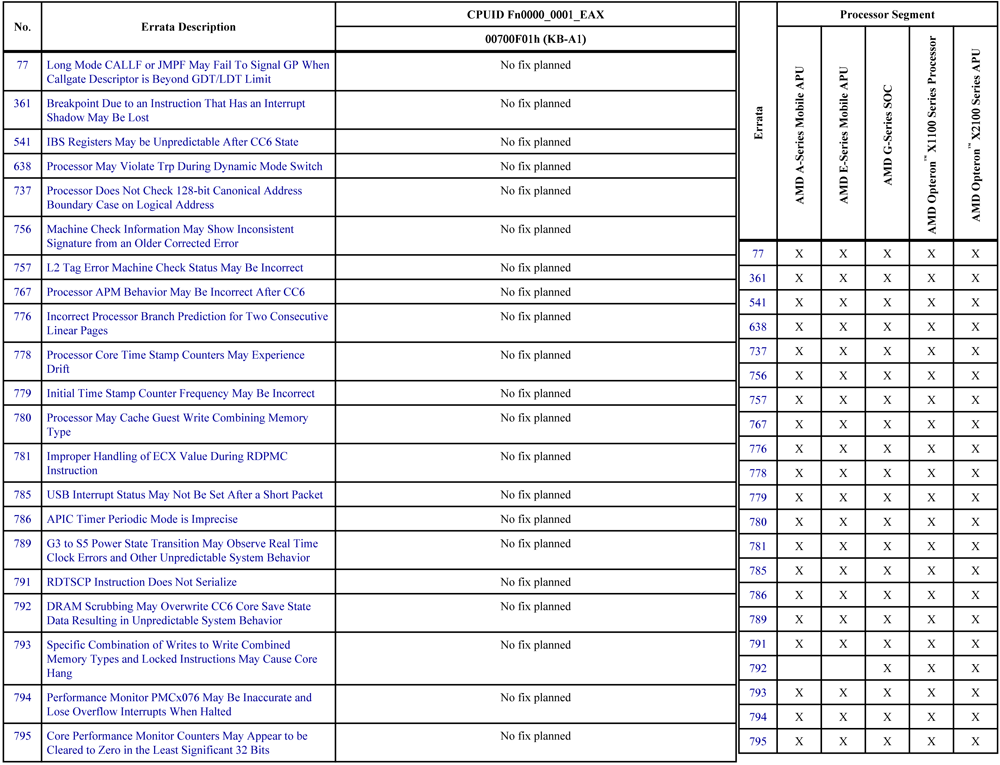
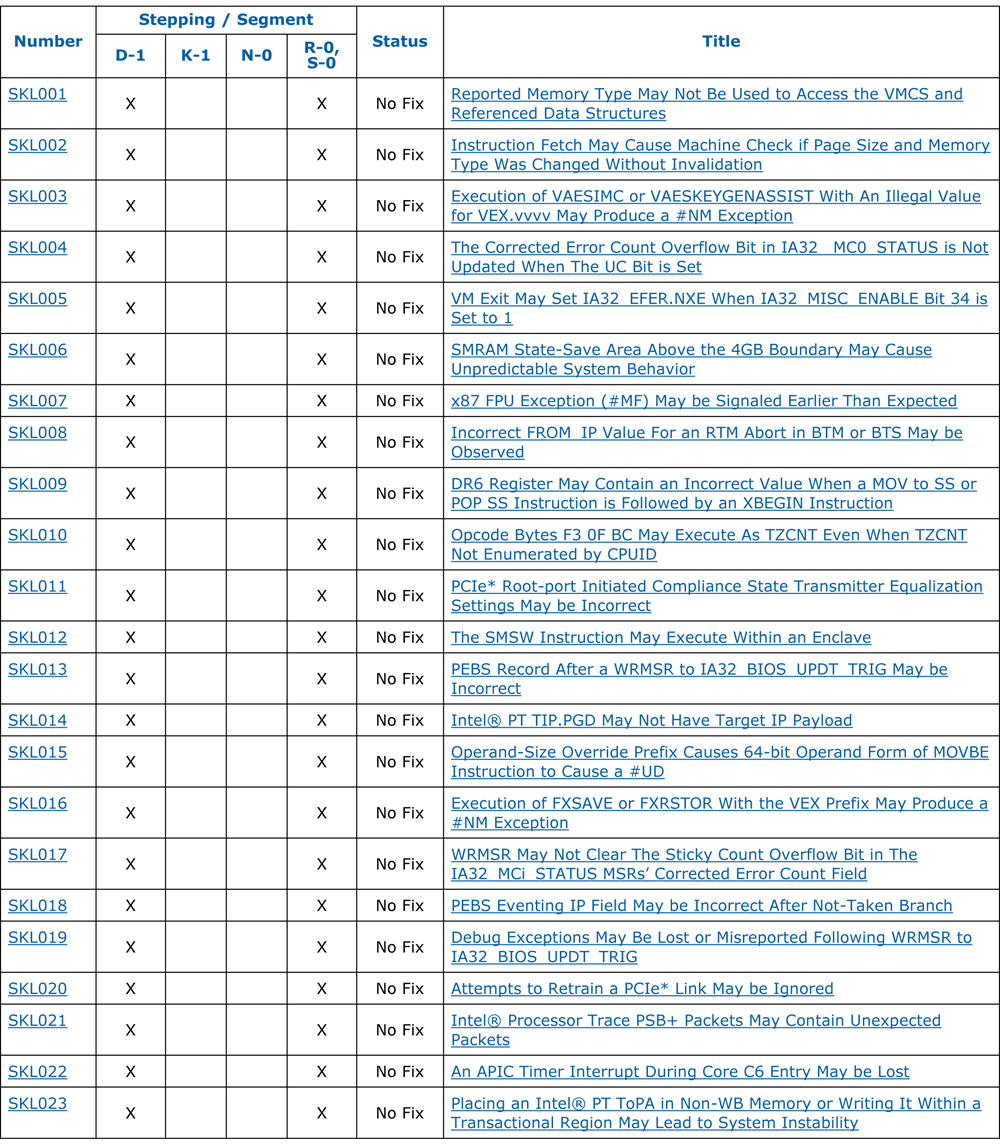
Processadores modernos são mais software que hardware
A rigor, os processadores modernos nem mesmo podem ser chamados de "hardware" no sentido pleno da palavra. Porque sua funcionalidade mais crítica (incluindo ISA) é fornecida piscando o microcódigo. Inicialmente, o microcódigo era o principal responsável pelo controle da decodificação e execução de instruções complexas do montador: operações de ponto flutuante, primitivas MMX, manipuladores de linha com o prefixo REP etc. No entanto, com o tempo, mais e mais responsabilidades são atribuídas ao microcódigo pelas operações de processamento dentro do processador. Por exemplo, extensões modernas de processadores Intel, como AVX (Advanced Vector Extensions) e VT-d (virtualização de hardware) são implementadas no microcódigo.
Além disso, hoje o microcódigo é responsável, entre outras coisas, por manter o estado do processador, gerenciar o cache e também gerenciar a economia de energia. Para economizar energia, o microcódigo possui um mecanismo de interrupção que processa os estados de energia: estado C (grau de sono de economia de energia: do estado ativo ao sono profundo) e estado P (diferentes combinações de tensão e frequência). Assim, por exemplo, o microcódigo é responsável por redefinir o cache L2 ao entrar no estado C4 e ao sair dele.
Por que os fabricantes de processadores usam microcódigo?
Os fabricantes de processadores x86 usam o microcódigo para decompor instruções de montagem complexas (que podem ter até 15 bytes de comprimento) em uma cadeia de micro-instruções simples, a fim de simplificar a arquitetura do hardware e facilitar o diagnóstico. De fato, o microcódigo é um intérprete entre a arquitetura CISC externa (visível ao usuário) e a arquitetura RISC interna (hardware).
Se forem detectados erros na arquitetura CISC (principalmente no ISA), os fabricantes publicam uma atualização de microcódigo que pode ser baixada no processador através do BIOS / UEFI da placa-mãe ou do sistema operacional (durante o processo de inicialização). Graças a esse sistema de atualização baseado em microcódigos, os fabricantes de processadores oferecem flexibilidade e redução de custos - enquanto corrigem erros em seus equipamentos. O erro sensacional com o fdiv, que derrubou severamente os processadores Intel Pentium em 1994, tornou o fato de que os erros de hardware de alta tecnologia propensos exatamente como o software o tornam ainda mais óbvio. Esse incidente deu aos fabricantes ainda mais interesse na arquitetura de processadores baseados em microcódigo. Portanto, Intel e AMD começaram a construir seus processadores usando a tecnologia de microcódigo. Intel - começando com o Pentium Pro (P6), lançado em 1995. AMD - começando com o K7, lançado em 1999.
Tudo segredo fica claro
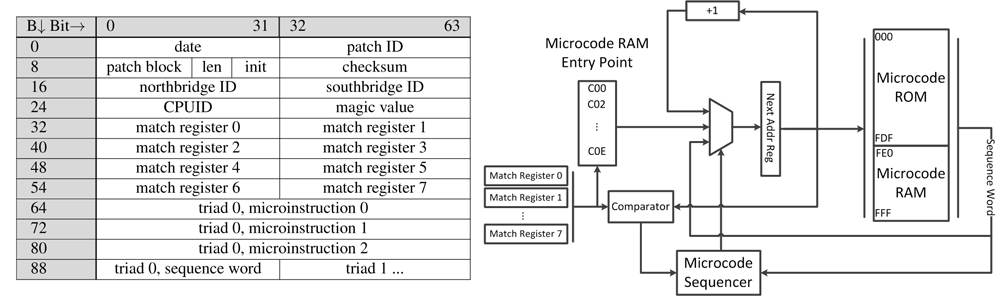
Apesar do fato de os fabricantes de processadores estarem tentando manter a arquitetura dos microcódigos e o mecanismo para atualizá-los com a maior confidencialidade, o inimigo não está dormindo. Pedaços de informações fragmentadas (principalmente de patentes, como AMD RISC86 [5]) e reversão ponderada das atualizações oficiais do BIOS (como aconteceu com o K8 [6]), gradualmente lançam luz sobre o segredo do microcódigo (veja, por exemplo, na figura abaixo " Mecanismo de atualização de microcódigo do processador AMD ”). E graças à constante evolução das ferramentas de engenharia reversa (software e hardware) [2], técnicas promissoras de difusão [1] e o advento de ferramentas OpenSource como Microparse [9] e Sandsifter [10] - um invasor cibernético pode aprender tudo sobre um microcódigo necessário para ter que escrever um malware de microcódigo nele.
Então, por exemplo, em [2] como "Olá, mundo!" (a primeira etapa para trojanizar o microcódigo), foi desenvolvido um “micro gancho” (programa de microcódigo que intercepta a instrução assembler), que conta quantas vezes o processador acessou o comando div. Este microhook é uma injeção no manipulador da instrução assembler div.

Ibid [2] apresenta um microhook mais avançado - que fica silenciosamente na instrução assembler do div ebx, sem dar presença, e é ativado apenas quando condições específicas são atendidas ao acessar o ebx div: o registrador ebx contém o valor B e o registrador eax contém o valor A. Quando ativado, este microhook aumenta em um o valor do registro eip (ponteiro de instrução atual). Como resultado, a execução do programa (que teve a coragem de se referir à instrução div ebx) continua com um deslocamento: não a partir do primeiro byte do comando após a div ebx, mas a partir do segundo byte. Se outros valores forem especificados nos registros eax e ebx, a div ebx funcionará normalmente. Qual é o valor prático disso? Por exemplo, para ativar silenciosamente uma cadeia oculta de instruções do montador ao usar técnicas de ofuscação com “instruções sobrepostas” [11].
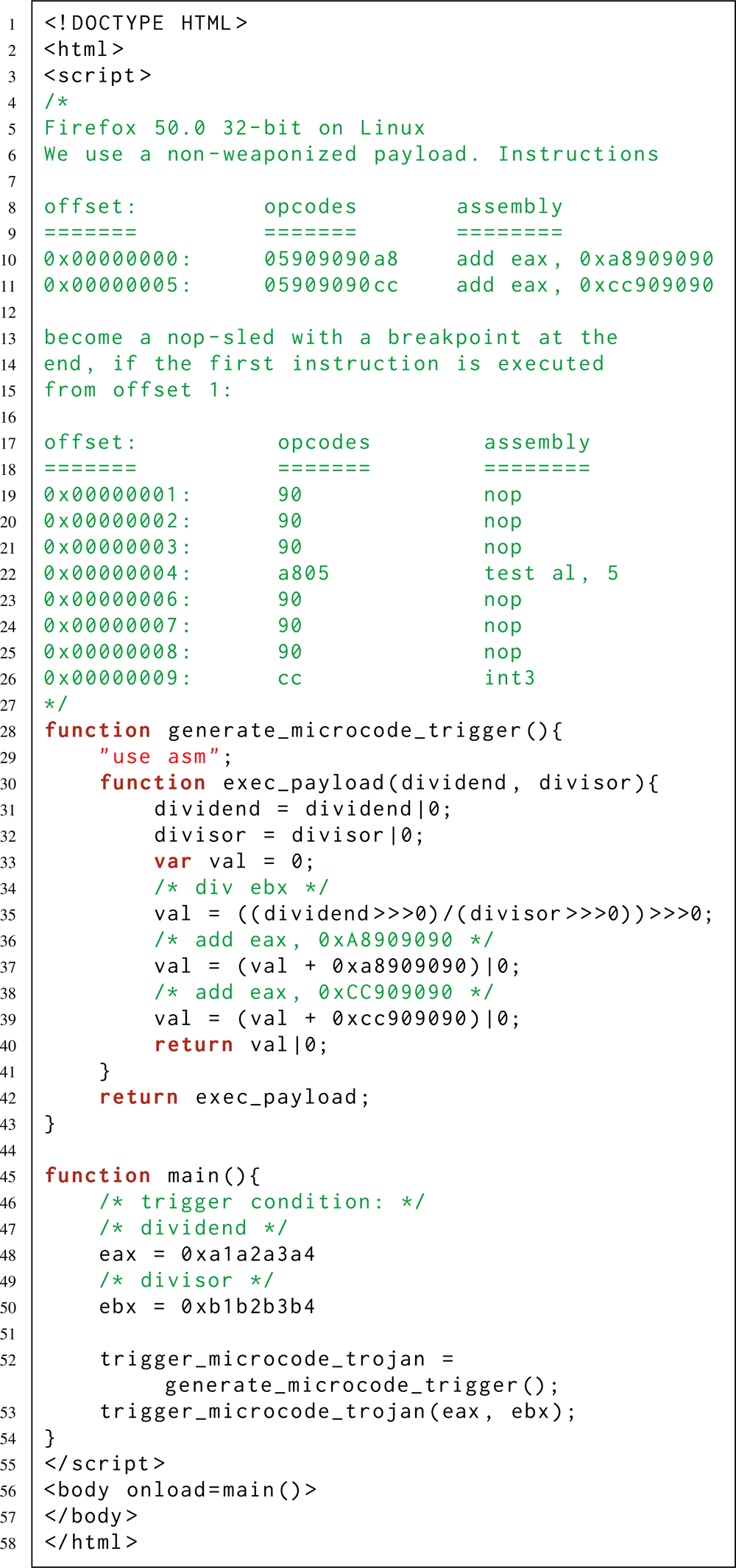
Estes dois exemplos demonstram como as instruções legítimas do assembler podem ser usadas para ocultar neles o código de Trojan
Ao mesmo tempo, um invasor cibernético pode ativar sua carga maliciosa - inclusive remotamente. Por exemplo, quando a condição necessária para a ativação é cumprida em uma página da web controlada por um invasor. Isso é possível graças aos compiladores Just-in-Time (JIT) e Ahead-of-Time (AOT) incorporados nos modernos navegadores da web. Esses compiladores permitem emitir um fluxo predefinido de instruções do assembler para código de máquina - mesmo se você escrever o programa exclusivamente em JavaScript de alto nível (consulte a última lista, logo acima).