Instituto de Tecnologia de Massachusetts. Curso de Aula nº 6.858. "Segurança de sistemas de computador". Nikolai Zeldovich, James Mickens. 2014 ano
Computer Systems Security é um curso sobre o desenvolvimento e implementação de sistemas de computador seguros. As palestras abrangem modelos de ameaças, ataques que comprometem a segurança e técnicas de segurança baseadas em trabalhos científicos recentes. Os tópicos incluem segurança do sistema operacional (SO), recursos, gerenciamento de fluxo de informações, segurança de idiomas, protocolos de rede, segurança de hardware e segurança de aplicativos da web.
Palestra 1: “Introdução: modelos de ameaças”
Parte 1 /
Parte 2 /
Parte 3Palestra 2: “Controle de ataques de hackers”
Parte 1 /
Parte 2 /
Parte 3Aula 3: “Estouros de Buffer: Explorações e Proteção”
Parte 1 /
Parte 2 /
Parte 3Palestra 4: “Separação de Privilégios”
Parte 1 /
Parte 2 /
Parte 3Palestra 5: “De onde vêm os sistemas de segurança?”
Parte 1 /
Parte 2Palestra 6: “Oportunidades”
Parte 1 /
Parte 2 /
Parte 3Palestra 7: “Sandbox do Cliente Nativo”
Parte 1 /
Parte 2 /
Parte 3Aula 8: “Modelo de Segurança de Rede”
Parte 1 /
Parte 2 /
Parte 3Aula 9: “Segurança de aplicativos da Web”
Parte 1 /
Parte 2 /
Parte 3Palestra 10: “Execução Simbólica”
Parte 1 /
Parte 2 /
Parte 3Aula 11: “Linguagem de Programação Ur / Web”
Parte 1 /
Parte 2 /
Parte 3Aula 12: Segurança de rede
Parte 1 /
Parte 2 /
Parte 3Aula 13: “Protocolos de Rede”
Parte 1 /
Parte 2 /
Parte 3 Então, hoje falaremos sobre o Kerberos, um protocolo criptograficamente seguro projetado para autenticação mútua de computadores e aplicativos na rede. Este é um protocolo para autenticar o cliente e o servidor antes de estabelecer uma conexão entre eles.
Então agora, finalmente, usaremos criptografia, ao contrário da última palestra, na qual examinamos a segurança usando apenas números de sequência TCP SYN.

Então, vamos falar sobre o Kerberos. O que está tentando oferecer suporte a este protocolo? Foi criado em nosso instituto há 25 ou 30 anos como parte do projeto Athena para garantir a interação de vários computadores servidores e vários computadores clientes.
Imagine que você tem um servidor de arquivos em algum lugar. Talvez seja um servidor de correio conectado à rede ou outros serviços de rede, como impressoras. E tudo isso é simplesmente conectado a alguma rede, e não processos em um computador.

O pré-requisito para a criação do Athena e do Kerberos era que você tinha uma máquina para compartilhamento simultâneo, onde tudo era um processo separado, e todos podiam simplesmente entrar no mesmo sistema e armazenar seus arquivos lá. Portanto, os desenvolvedores queriam criar um sistema distribuído mais conveniente.
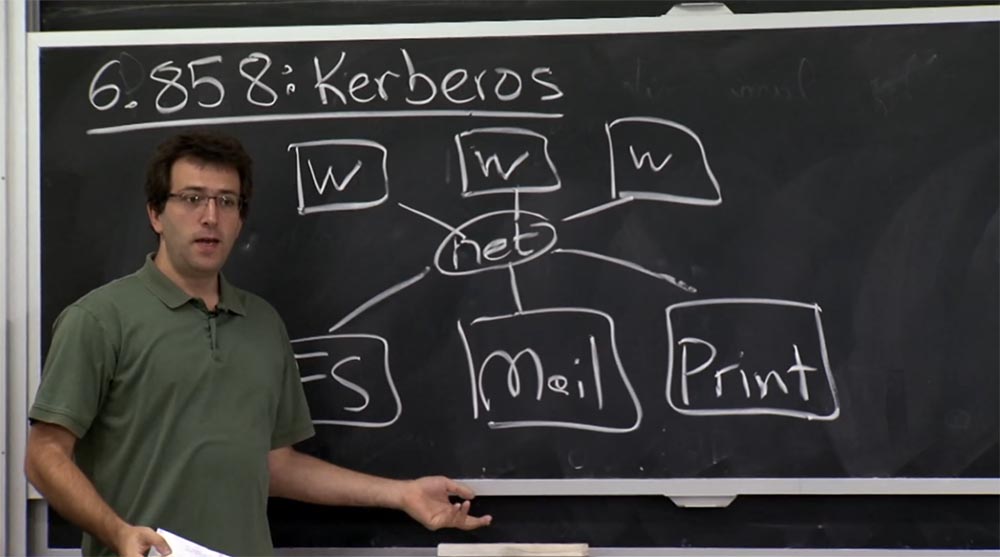
Portanto, isso significava que você teria esses servidores de um lado e várias estações de trabalho do outro lado que os usuários usariam a si mesmos e nas quais os aplicativos seriam executados. Essas estações de trabalho se conectam a esses servidores e armazenam arquivos do usuário, recebem seus emails e assim por diante.
O problema que eles queriam resolver era como autenticar usuários que usam essas estações de trabalho para todos esses computadores diferentes no lado do servidor, sem precisar confiar na rede e verificar sua correção. Isso era, sob todos os aspectos, um requisito de design razoável. Devo mencionar que, na época, a alternativa ao Kerberos era a equipe de logon R, discutida na última palestra, que parecia um plano ruim, pois eles simplesmente usam seus endereços IP para autenticar usuários.
O Kerberos foi bem-sucedido, ainda é usado na rede MIT e é a espinha dorsal do servidor Active Directory da Microsoft. Quase todos os produtos baseados no Microsoft Windows Server usam Kerberos de uma forma ou de outra.
Mas esse protocolo foi desenvolvido há 25 ou 30 anos e, desde então, são necessárias mudanças, pois hoje as pessoas entendem muito mais sobre segurança. Portanto, a versão atual do Kerberos é visivelmente diferente em muitos aspectos da versão descrita nos materiais desta palestra. Vamos considerar quais suposições específicas não são boas o suficiente hoje e o que estava errado na primeira versão. Isso é inevitável para o primeiro protocolo que realmente usou criptografia para autenticar os participantes da rede em um sistema completo.
De qualquer forma, o diagrama descrito no quadro é um tipo de instalação para a criação do Kerberos. É interessante descobrir qual é o modelo de confiança. Portanto, uma estrutura adicional é introduzida em nosso esquema - o servidor Kerberos, localizado aqui ao lado.
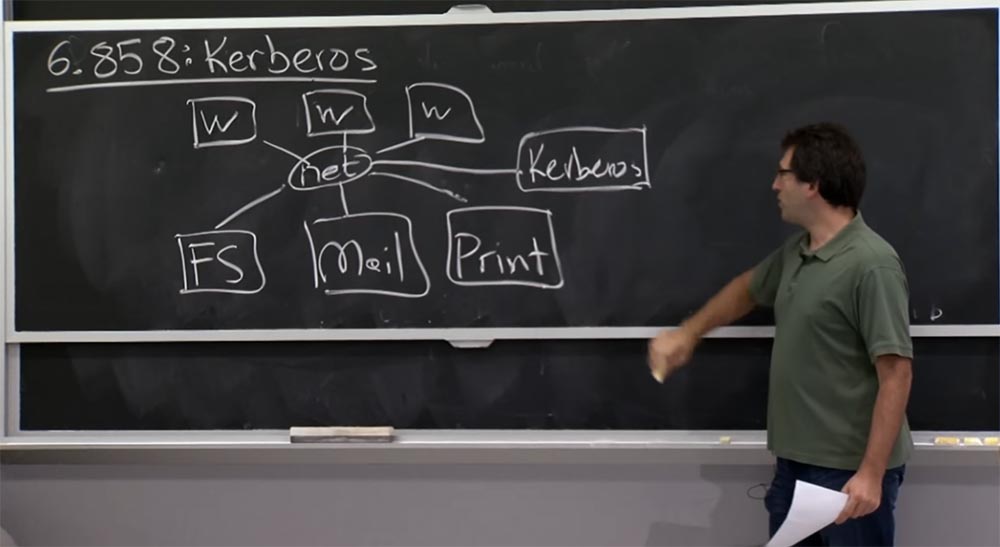
Assim, nosso terceiro modelo é, de certa forma, baseado no fato de que a rede não é confiável, como mencionamos na última palestra. Em quem devemos confiar nesse esquema Kerberos? Obviamente, todos os participantes da rede devem confiar no servidor Kerberos. Portanto, os criadores do sistema sugeriram que o servidor Kerberos seria responsável por todas as verificações de autenticação de rede de uma forma ou de outra. O que mais temos nesta rede em que você pode confiar?
Aluno: Os usuários podem confiar em suas próprias máquinas.
Professor: Sim, este é um bom argumento. Existem usuários aqui que não atraí. Mas esses caras usam algum tipo de estação de trabalho e, de fato, no Kerberos é muito importante que o usuário confie em sua estação de trabalho. O que acontece se você não confiar na sua estação de trabalho? Como se o usuário não confiar na estação de trabalho, você poderá simplesmente "descobrir" sua senha e agir em seu nome.
 Aluno:
Aluno: um invasor pode fazer muito mais, por exemplo, aprendendo seu ticket para o servidor Kerberos.
Professor: sim, exatamente. Ao fazer login, você digita sua senha, o que é ainda pior do que um ticket. Portanto, na verdade, há um pequeno problema com o Kerberos, se você não confia na estação de trabalho. Se você usa seu próprio laptop, não é tão assustador, mas a segurança de um computador público está em dúvida. Vamos considerar o que exatamente pode dar errado neste caso.
Aluno: você deve confiar nos administradores do servidor e garantir que eles possam ter acesso privilegiado aos servidores um do outro.
Professor: Eu acho que as próprias máquinas não precisam confiar umas nas outras, por exemplo, o servidor de email não precisa confiar no servidor de impressão ou no servidor de arquivos.
Aluno: não confie, mas tenha a capacidade de acessar um servidor ao qual o acesso por outro servidor não é suportado.
Professor: sim, é verdade. Se você estabelecer uma relação de confiança entre o servidor de correio e o servidor de impressão, mas apenas conceder ao servidor o acesso aos seus arquivos no servidor de arquivos por conveniência, isso poderá ser abusado. Portanto, você deve ter cuidado ao introduzir níveis adicionais de confiança ou trusts redundantes aqui.
O que mais importa aqui? Os servidores devem, de alguma forma, confiar em usuários ou estações de trabalho? Acho que não. O objetivo global do Kerberos era que o servidor a priori não conhecesse todos esses usuários ou estações de trabalho ou soubesse autenticá-los, até que esses usuários possam provar criptograficamente que são usuários legítimos e devem ter acesso aos dados ou algo assim. mais do que o servidor gerencia.
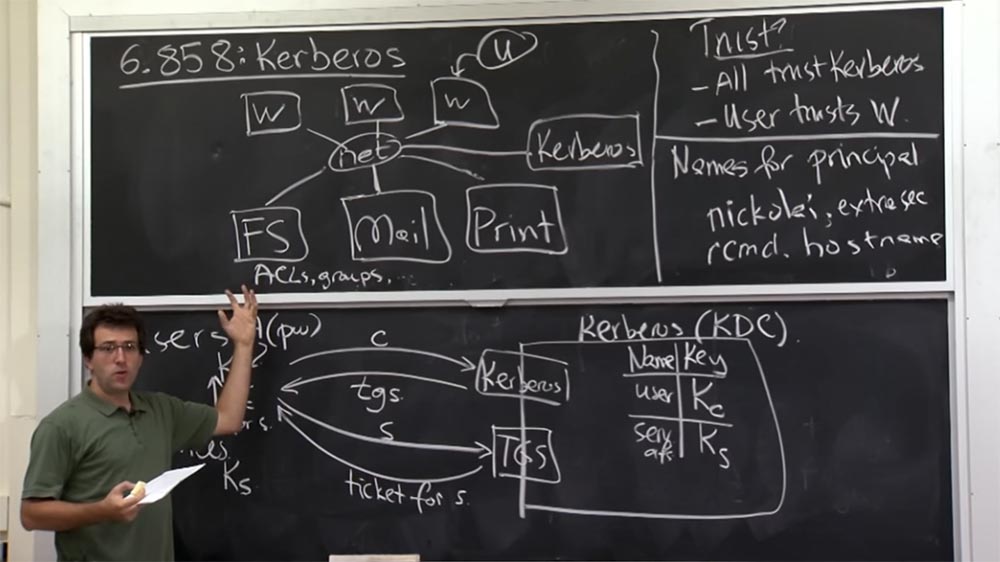
Vamos ver como o Kerberos funciona e qual é sua arquitetura geral. Vamos desenhar um servidor Kerberos em uma escala maior. Atualmente, é chamado KDC - Key Distribution Center, ou Key Providing Center. Em algum lugar, existem usuários e serviços aos quais você pode se conectar. O plano é que o servidor Kerberos seja responsável por armazenar a chave compartilhada para comunicação entre o servidor Kerberos e cada entidade de computador no mundo ao seu redor. Portanto, se o usuário tiver algum tipo de chave de cliente Kc, o servidor Kerberos se lembrará dessa chave e a armazenará em algum lugar dentro de si. Da mesma forma, a chave Ks de um serviço será conhecida apenas por esse serviço, pelo servidor Kerberos e por mais ninguém. Assim, você pode pensar nisso como um uso comum de senhas quando você conhece a senha e o Kerberos sabe, mas ninguém mais sabe.

É assim que vocês vão provar um para o outro que "eu sou o mesmo cara". Obviamente, o servidor Kerberos precisará acompanhar quem possui essa chave, portanto, deve haver uma tabela na qual nomes de usuário e nomes de serviço, por exemplo, serv afs (este é um servidor de arquivos), e as chaves correspondentes a eles serão armazenadas.
Ao mesmo tempo, o KDC é responsável por armazenar uma tabela gigante, não muito grande em termos de número de bytes, mas muito volumosa em número de registros, porque leva em consideração qualquer entidade de computador que viva na rede MIT que o servidor Kerberos deve conhecer. Assim, temos dois tipos de interface.

Os materiais das palestras não falam sobre isso com clareza suficiente, ou seja, a existência dessas 2 interfaces é simplesmente implícita. De fato, existem realmente duas interfaces para uma máquina. Um deles é chamado Kerberos e o segundo é TGS, Ticket Granting Service ou Ticket Service.
De fato, no final, essas são apenas duas maneiras de falar sobre a mesma coisa, e o protocolo é apenas ligeiramente diferente para essas duas coisas. Portanto, inicialmente, quando um usuário faz login, ele "fala" com a interface superior, Kerberos, e envia a ele seu nome de cliente C, este pode ser seu nome de usuário na rede da universidade Athena.
O servidor responde a essa solicitação com um tgs ticket ou informações do ticket; discutiremos os detalhes dessas informações um pouco mais tarde. Então, quando você quiser conversar com algum serviço, primeiro precisará acessar a interface TGS e informar: "Eu já efetuei login na interface Kerberos e agora quero conversar com o servidor S, que me fornecerá um determinado serviço".
Então você dirá ao TGS sobre o servidor com o qual deseja conversar, após o qual retornará algo como um ticket para conversar com o servidor S. Depois, você poderá finalmente conversar com o servidor de que precisa usando o ticket recebido para o servidor S.
Este é um tipo de plano de alto nível. Então, por que duas interfaces são usadas aqui? Muitas perguntas podem ser feitas sobre isso. No caso do servidor Ks, esse serviço provavelmente será armazenado em disco. E o que acontece com esse Kc no lado do usuário? De onde vem esse Kc no Kerberos?
 Aluno:
Aluno: esse Kc deve estar no banco de dados, na tabela do servidor KDC.
Professor: sim, bem, a tecla C está aqui na tabela, neste gigantesco banco de dados. Mas também deve ser conhecido pelo usuário, porque ele deve provar que é um usuário.
Aluno: é uma função unidirecional que requer uma senha?
Professor: sim, eles realmente têm um plano tão inteligente, onde o Kc é obtido através da hash da senha do usuário ou de algum tipo de função de geração de chave, pois existem vários métodos diferentes. Mas basicamente pegamos a senha, convertemos de alguma forma e obtemos essa chave Kc. Então, isso parece ser um bom caminho.
Mas por que precisamos de dois protocolos? Afinal, você pode imaginar que simplesmente solicita um ticket diretamente da primeira interface do Kerberos, dizendo a ele: “ei, eu quero um ticket para esse nome em particular!”, Ele enviará o ticket de volta e você poderá descriptografá-lo usando o Kc.
Aluno: talvez eles não desejem que o usuário digite novamente sua senha sempre que quiser acessar outro serviço?
Professor: verdade, a razão da diferença entre as duas interfaces é que, desde a primeira interface, todas as respostas são retornadas criptografadas com sua chave Kc, e os criadores do Kerberos estavam preocupados com a possibilidade de salvar esse Kc por um longo tempo. Porque você precisa pedir ao usuário para digitar a senha todas as vezes, o que é apenas irritante, ou ele fica "constantemente" na memória. Basicamente, isso é tão bom quanto apenas uma senha de usuário, porque alguém com acesso ao Kc pode manter o acesso aos arquivos do usuário até que o usuário talvez mude sua senha ou até mais. Mais tarde, consideraremos esse problema com mais detalhes.
Portanto, vazar essa chave Kc é uma coisa muito perigosa. Portanto, o objetivo de usar a primeira e a segunda interface para todas as solicitações subsequentes é que você pode realmente esquecer o Kc assim que descriptografar a resposta da interface TGS do servidor Kerberos. A partir de agora, mesmo no caso de um vazamento de chave, a funcionalidade dependerá do ticket recebido. Portanto, na pior das hipóteses, alguém terá acesso à sua conta por algumas horas e não por um período ilimitado de tempo. Esse é o motivo de um esquema com dois caminhos de acesso aos mesmos recursos.
Portanto, antes de nos aprofundarmos na mecânica de como esses protocolos realmente aparentam na rede, vamos falar um pouco sobre o aspecto dos nomes Kerberos. Em certo sentido, o Kerberos pode ser considerado um registro de nomes. Ele é responsável por exibir essas chaves criptográficas como nomes em minúsculas. Este é o tipo fundamental de operação que o Kerberos executa. Você verá na próxima aula por que precisamos de uma função semelhante. Ele pode ser implementado de forma diferente do Kerberos, mas é fundamentalmente muito importante ter uma coisa semelhante em quase qualquer sistema de segurança distribuído. Então, vamos ver como o Kerberos lida com nomes.
O Kerberos possui algo como chamadas de sistema para cada entidade do computador no banco de dados de membros da rede, e a forma principal desses dados é apenas uma string. Assim, você pode ter alguns nomes básicos em um formato como nickolai, por exemplo. Esta é a cadeia de nomes.

É o parâmetro principal em alguma área do Kerberos; na verdade, é isso que está na coluna esquerda da tabela KDC. E também existem alguns parâmetros adicionais que o protocolo suporta. Eu poderia, por exemplo, inserir outro nome como nickolai.extra sec, que seria usado além do nome nickolai para acessar recursos que precisam de segurança adicional. Talvez eu tenha uma senha para coisas realmente seguras e outra para minha conta normal.
Kerberos mencionou esse aspecto. Portanto, pode-se perguntar - de onde vem o impacto? O serviço Kerberos mapeia nomes para determinadas chaves, mas como você sabe qual nome perguntar ou qual nome esperar em resposta quando estiver conversando com algum computador? Ou seja, pergunto quais nomes aparecem fora do servidor Kerberos ou onde exatamente esses nomes de usuário aparecem? Você tem alguma ideia?
Aluno: presumivelmente, você pode solicitar nomes de usuários no servidor MIT.
Professor: sim, claro. É assim que você pode listar essas coisas. Além disso, os usuários simplesmente os inserem quando fazem login, e é daí que eles vêm. Os nomes de usuário aparecem em outro lugar? Eles deveriam aparecer em outro lugar?
Aluno: é possível que o acesso do usuário seja indicado nas listas em vários serviços.
Professor: sim, esse é um ponto muito importante, certo? O objetivo do Kerberos é simplesmente mapear chaves para nomes. Mas isso não diz a que nome esse nome deve ter acesso.
De fato, a maneira como os aplicativos normalmente usam o Kerberos é que um desses servidores usa o Kerberos para descobrir com qual nome em minúsculas está falando. Quando o servidor de email recebe uma conexão de alguma estação de trabalho, recebe um tíquete Kerberos, o que prova que esse usuário é Nikolai. Depois disso, o servidor de correio descobre internamente o que esse usuário tem acesso. O servidor de arquivos faz o mesmo.
Assim, dentro de todos esses servidores existem listas de controle de acesso, possivelmente listas de grupos ou outras coisas que realizam autorização. Portanto, o Kerberos fornece autenticação que mostra com quem essa pessoa está falando. O serviço em si é responsável pela implementação dessa parte da autorização, que decide qual nível de acesso você deve ter com base no seu nome de usuário. Então descobrimos onde os nomes de usuário aparecem. Existem outros nomes básicos que o Kerberos suporta para interagir com serviços.
De acordo com o material da palestra, os serviços são mais ou menos assim: rcmd.hostname. O motivo de você precisar de um nome para um desses serviços é porque deseja, por exemplo, ao conectar-se a um servidor de arquivos, executar autenticação mútua. Isso significa que, neste procedimento, não apenas o servidor de destino descobrirá quem eu sou, mas também eu, o usuário ou a estação de trabalho, verifique se estou falando com o servidor de arquivos correto, e não com um servidor de arquivos falso que falsificou o meu arquivos Porque, talvez, eu queira examinar o arquivo com minhas classificações e enviá-lo ao registrador. Portanto, seria muito ruim se algum outro servidor de arquivos pudesse atuar como o servidor correto e me fornecer o arquivo de classificações errado.
Portanto, os serviços também precisam de seu próprio nome e as estações de trabalho devem descobrir qual o nome que espero ver ao me conectar ao serviço.
Como regra, em algum nível, isso vem do usuário. Portanto, por exemplo, se eu digitar ssh.foo, isso significa que devo esperar que um nome principal do Kerberos como rcmd.foo apareça na outra extremidade dessa conexão. E se alguém estiver lá, o cliente SSH deve desconectar e não permitir que eu me conecte, pois serei enganado e começarei a conversar com outra máquina.
Isso levanta uma questão interessante. Quando podemos reutilizar nomes no Kerberos? Por exemplo, todos vocês têm contas no sistema do instituto Athena. Ao se formar, o MIT pode destruir sua entrada no banco de dados e permitir que outra pessoa registre o mesmo nome de usuário? Seria uma boa ideia?
Aluno: mas não apenas o banco de dados Kerberos, mas também os serviços têm uma lista de nomes de usuário?
Professor: sim, porque esses nomes são na verdade apenas representados por entradas de sequência em algum lugar da ACL em um arquivo ou servidor de email. Se apagarmos sua entrada no banco de dados do servidor Kerberos, isso não significa que sua entrada tenha desaparecido completamente. Essas entradas são independentes da versão.
Por exemplo, um registro diz que Alice tem acesso a um armário Athena. Em seguida, Alice se forma e seu registro é excluído, mas uma nova Alice entra no instituto, que passa pelo processo de registro no banco de dados Kerberos. Ao mesmo tempo, ela obtém o nome principal que é completamente idêntico ao nome da antiga Alice, para que o servidor de arquivos possa dar à nova Alice acesso aos arquivos da antiga Alice.
, Kerberos , Kerberos . , , , .
. , , , , , . , , , - . , . , , .
, . , , , TGS.

, , Kerberos, «». : s , IP – addr, time stump, life, , , Kc,s, . .

.
, Kerberos «». Ac , IP- , , . , . K,s, , Kerberos Ks. , .
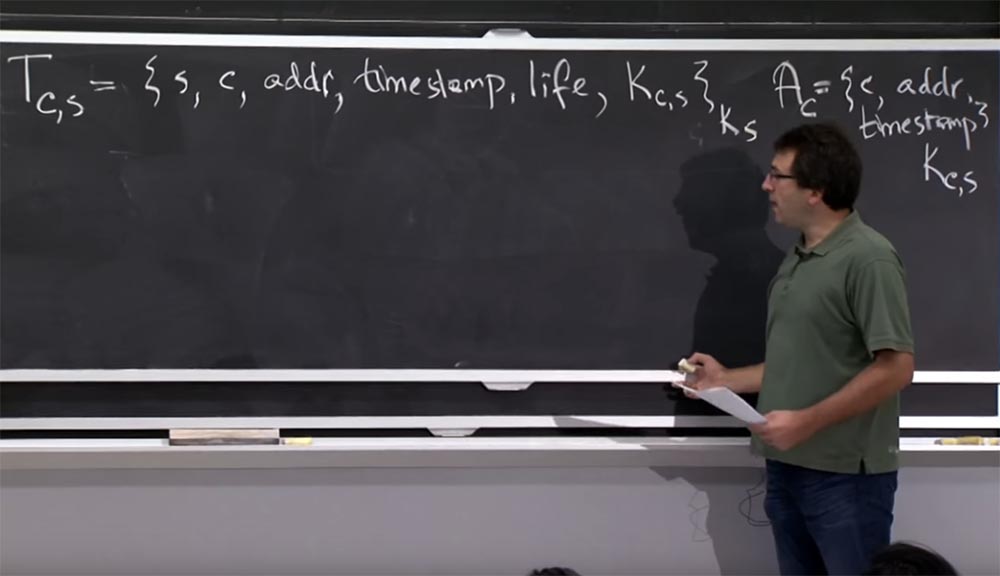
, , Kerberos TGS. , , Kerberos, , . : C, , S, TGS. .
Tc,s, Ks, , Ks, , Kc. .
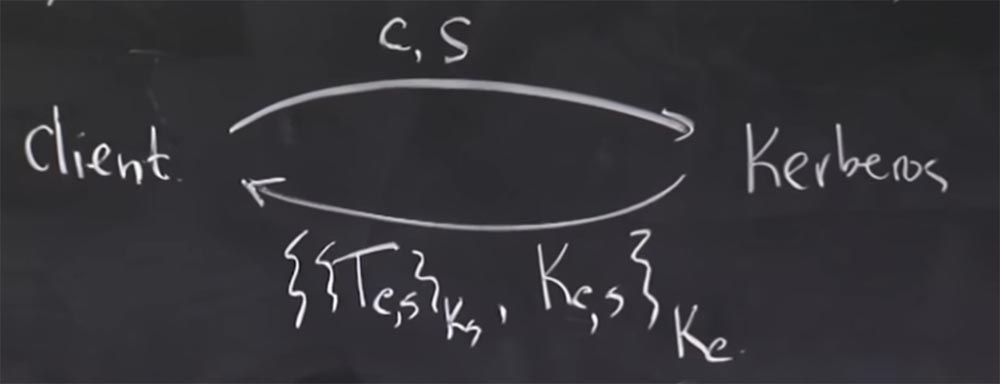
. , Kerberos ? , ?
: , , , Kc.
: , , Kerberos , . : «, , . , , , Kc». , .
, , , Kerberos, Kerberos , . , , - Kerberos, , .
: …
: , , Kerberos, ? , ? , , , , , , , , , .

«», , , , , . , , . . Kerberos, , . , , .
: ? , …
: , . , Kerberos , . , , - , , , . 30 , .
Kerberos 5 : , — . , , , , .
Kerberos 4 , , , . , . , , .
Portanto, este é o plano para informar ao cliente se seu ticket é válido. Eles estão apenas tentando decifrá-lo e ver como ele funciona. Outra pergunta interessante - por que essa chave Kc, s, de alguma forma, está incluída no ticket duas vezes? Está presente no ticket separadamente como a chave Kc, se está implicitamente presente no próprio ticket Tc, s. Por que temos duas cópias da chave Kc, s?27:10 min.Curso MIT "Computer Systems Security". Aula 13: Protocolos de Rede, Parte 2A versão completa do curso está disponível aqui .Obrigado por ficar conosco. Você gosta dos nossos artigos? Deseja ver materiais mais interessantes? Ajude-nos fazendo um pedido ou recomendando a seus amigos, um
desconto de 30% para os usuários da Habr em um análogo exclusivo de servidores básicos que inventamos para você: Toda a verdade sobre o VPS (KVM) E5-2650 v4 (6 núcleos) 10GB DDR4 240GB SSD 1Gbps da US $ 20 ou como dividir o servidor? (as opções estão disponíveis com RAID1 e RAID10, até 24 núcleos e até 40GB DDR4).
VPS (KVM) E5-2650 v4 (6 núcleos) 10GB DDR4 240GB SSD de 1Gbps até dezembro de graça quando pagar por um período de seis meses, você pode fazer o pedido
aqui .
Dell R730xd 2 vezes mais barato? Somente nós temos
2 TVs Intel Dodeca-Core Xeon E5-2650v4 128GB DDR4 6x480GB SSD 1Gbps 100 a partir de US $ 249 na Holanda e nos EUA! Leia sobre
Como criar um prédio de infraestrutura. classe usando servidores Dell R730xd E5-2650 v4 custando 9.000 euros por um centavo?