
Uma coisa romântica como um céu estrelado e uma coisa tão grave como otimizar o consumo de memória por um aplicativo iOS podem muito bem andar juntos: vale a pena tentar colocar esse céu estrelado em um aplicativo de recuperação de direitos autorais, e a pergunta sobre o mesmo consumo surgirá imediatamente.
Minimizar o uso da memória será útil em muitos outros casos. Portanto, este texto no exemplo de um projeto pequeno mostra métodos de otimização que podem ser úteis em aplicativos iOS completamente diferentes (e não apenas no iOS).
A publicação foi preparada com base em uma transcrição
do relatório de
Conrad Filer da conferência Mobius 2018 Piter. Anexamos o vídeo e, em seguida, uma versão em texto na primeira pessoa:
Fico feliz em receber todos! Meu nome é Conrad Filer e, com o nome espetacular de "Um milhão de estrelas em um iPhone", discutiremos como você pode minimizar o tamanho da memória ocupada pelo seu aplicativo iOS. Colorido e em exemplos.
Por que otimizar?
O que geralmente nos encoraja a fazer otimização, o que exatamente gostaríamos de alcançar? Nós não queremos isso:
Não queremos que o usuário espere. Ou seja, o primeiro motivo é
reduzir o tempo de inicialização .
Outra razão é
melhorar a qualidade .

Podemos falar sobre a qualidade das imagens, som e até AI. “IA otimizada” significa que você pode conseguir mais - por exemplo, calcule o jogo para um número maior de movimentos adiante.
A terceira razão é muito importante:
economizando energia da bateria . A otimização ajuda a drenar menos a bateria. Aqui está uma comparação interessante, embora do mundo Android. Aqui, comparamos o Vulkan e o OpenGL ES:

O segundo é pior otimizado para plataformas móveis. Observando a velocidade do consumo de energia da bateria, você pode ver que, para uma imagem semelhante, o OpenGL ES gastou muito mais recursos que o Vulkan.
Que tipo de otimização pode ajudar aqui? Por exemplo, em um jogo baseado em turnos, quando o usuário pensa em sua jogada, você pode reduzir o FPS a zero. Se você possui um mecanismo 3D, é totalmente sensato desligar tudo enquanto o usuário apenas olha para a tela.
Além disso, há momentos em que, sem uma abordagem otimizada, você não poderá implementar um ou outro recurso avançado: ele simplesmente não será puxado.
Sem fanatismo
Falando sobre otimização, não podemos deixar de lembrar a tese de Donald Knuth: “Devemos esquecer a baixa eficiência, digamos, em 97% dos casos: a otimização prematura é a raiz de todos os males. Embora não devamos desistir de nossas capacidades nesses 3% críticos ".
Em 97% dos casos, não devemos nos preocupar com eficiência, mas antes de tudo sobre como tornar nosso código compreensível, seguro e testável. Ainda estamos desenvolvendo para dispositivos móveis, e não para naves espaciais. As empresas em que trabalhamos não devem pagar a mais pelo suporte ao código que escrevemos. Além disso, o tempo de trabalho do desenvolvedor tem um custo e, se você o gasta na otimização de algo não essencial, gasta o dinheiro da empresa. Bem, o fato de que código bem otimizado tende a ser mais difícil de entender, você pode ver os exemplos que mostrarei hoje.
Em geral, priorize e otimize significativamente, conforme necessário.
As abordagens
Ao trabalhar na otimização, geralmente monitoramos o desempenho (leitura: carga do processador) ou a quantidade de memória usada. Freqüentemente, essas duas opções entram em conflito e você precisa encontrar um equilíbrio entre elas.
No caso do processador, podemos reduzir o número de ciclos do processador exigidos por nossas operações. Como você sabe, menos ciclos do processador nos proporcionam menos tempo de carregamento, menos consumo de bateria, capacidade de fornecer melhor qualidade etc.
Para desenvolvedores de iOS, o Xcode Instruments possui uma ferramenta útil, o Time Profiler. Ele permite que você acompanhe o número de ciclos da CPU gastos por diferentes partes do seu aplicativo. Este relatório não é sobre ferramentas, por isso não vou entrar em detalhes agora, houve um bom vídeo da WWDC sobre isso.
Você pode escolher outro objetivo - otimização em prol da memória. Vamos tentar garantir que, na inicialização, nosso aplicativo se encaixe no menor número possível de células RAM. Lembre-se de que as aplicações mais volumosas são os primeiros candidatos a um desligamento forçado durante a limpeza, que o sistema operacional é forçado a executar. Portanto, isso afeta por quanto tempo seu aplicativo permanece em segundo plano.
Também é importante que o recurso de RAM para dispositivos diferentes também seja diferente. Se você, por exemplo, decidiu desenvolver para o Apple Watch, não há memória suficiente e isso também o otimiza.
Finalmente, às vezes, uma pequena quantidade de memória também torna o programa muito rápido. Eu darei um exemplo Aqui estão as estruturas de vários tamanhos em bytes:

Element8 contém 8 bytes, Element16-16, e assim por diante.

Criaremos matrizes, uma para cada um dos nossos tipos de estruturas. A dimensão de todas as matrizes é a mesma - 10.000 elementos. Cada estrutura contém um número diferente de campos (crescente); o campo n é o primeiro e, portanto, está presente em todas as estruturas.
Agora vamos tentar o seguinte: para cada matriz, calcularemos a soma de todos os seus campos n. Ou seja, cada vez que somarmos o mesmo número de elementos (10.000 peças). A única diferença é que, para cada soma, a variável n será extraída de estruturas de tamanhos diferentes. Estamos interessados em saber se o somatório leva o mesmo tempo.
O resultado é o seguinte:
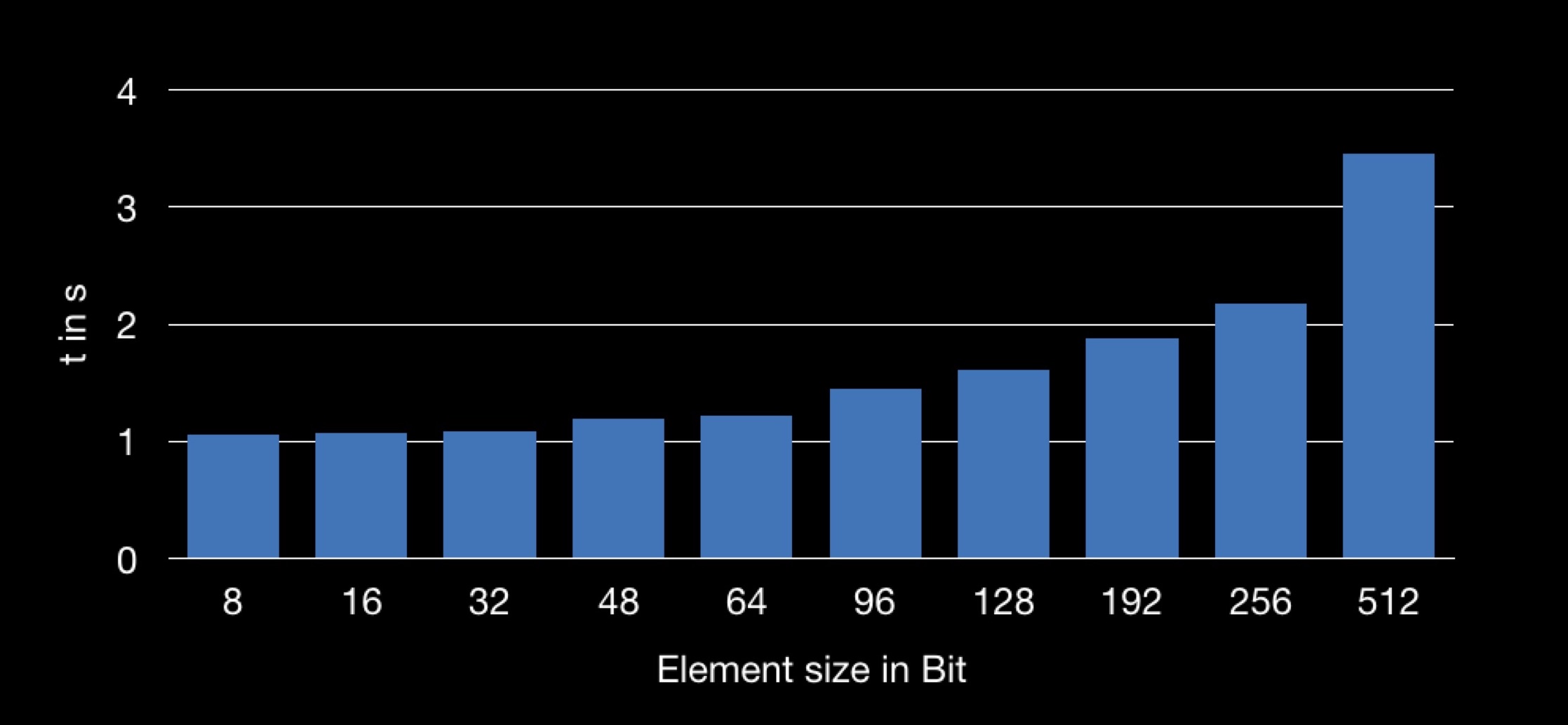
O gráfico mostra a dependência do tempo de soma no tamanho da estrutura usada na matriz. Acontece que obter o campo n de uma estrutura maior é mais longo e, portanto, a operação de soma leva mais tempo.
Muitos de vocês já entenderam por que isso está acontecendo.
O processador possui caches L1, L2 (às vezes até L3 e L4). O processador acessa esse tipo de memória direta e rapidamente.
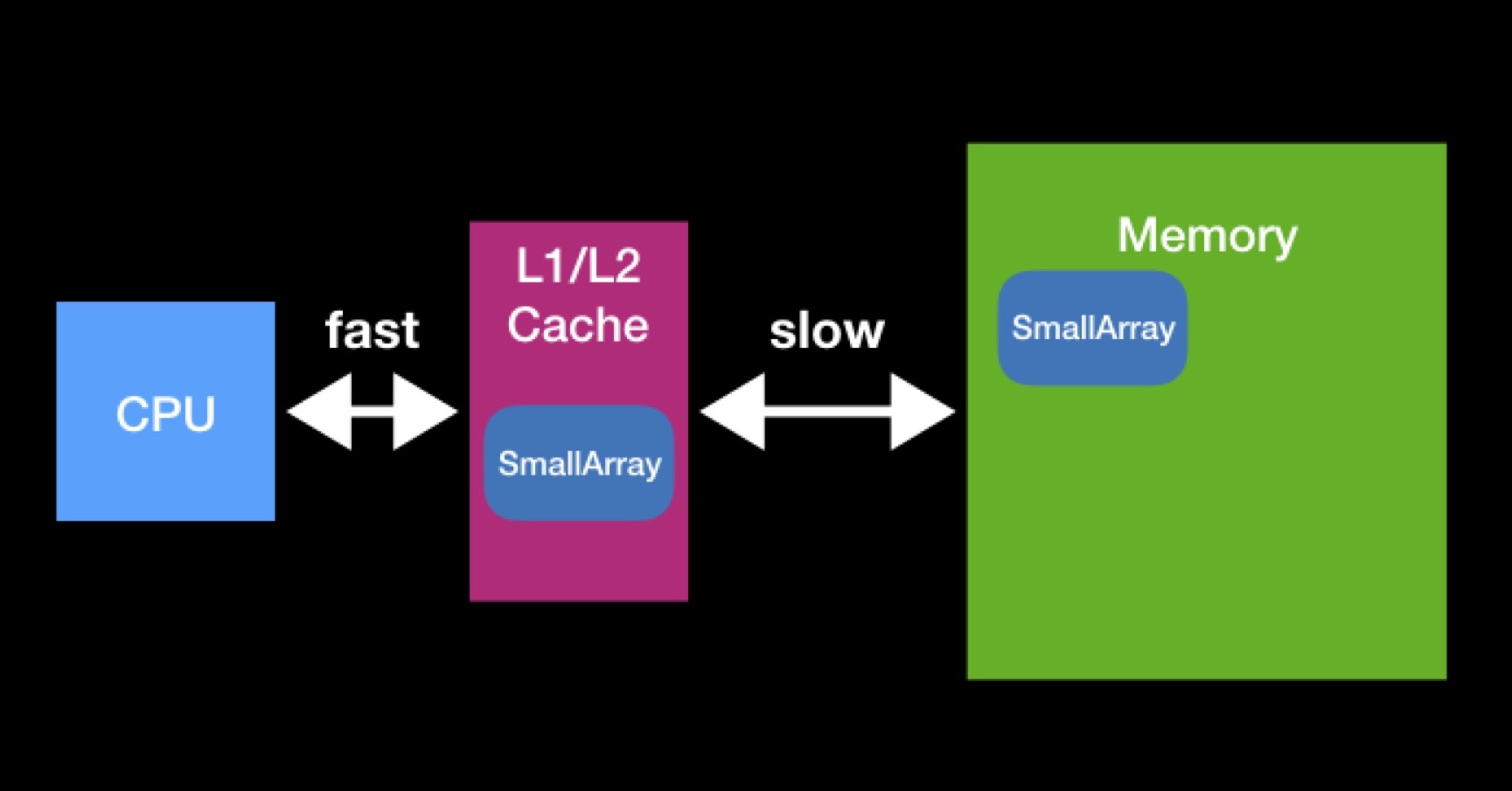
Existem caches para acelerar a reutilização de dados. Suponha que estamos trabalhando com matrizes. Se a matriz necessária para o processador já estiver presente em qualquer um dos caches, ela já foi solicitada anteriormente pelo processador. Naquele momento, ele os solicitou da memória principal, colocou-os no cache, executou todas as operações necessárias com eles, após o que esses dados permaneceram em repouso (não tiveram tempo de serem apagados por outros).
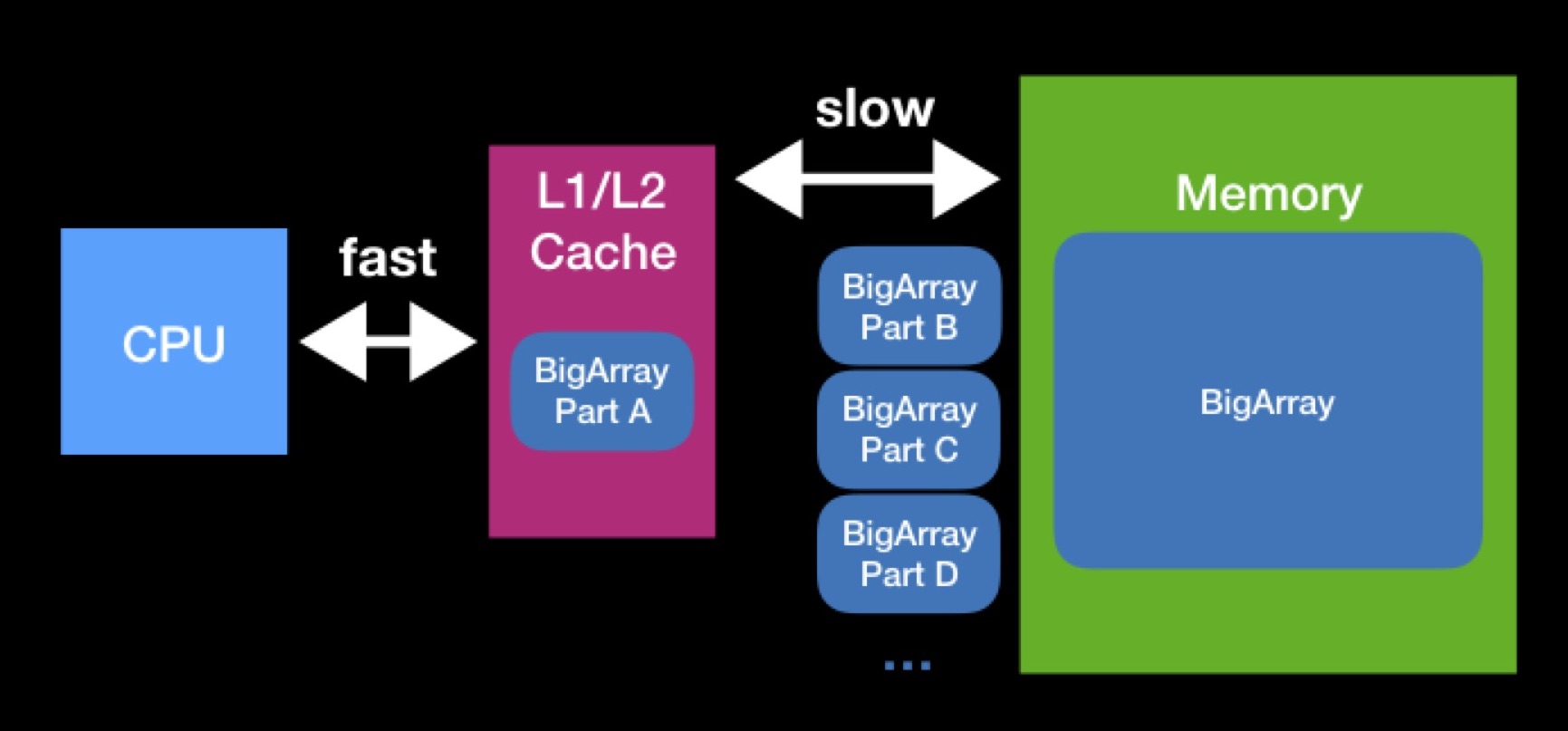
Os tamanhos dos caches L1, L2 não são tão grandes. A matriz necessária para o processador funcionar pode ser maior. Para executar totalmente a operação em uma matriz desse tipo, teremos que descarregá-la no cache em partes e operar essas partes uma a uma. Devido a constantes solicitações à memória principal, o processamento de nossa matriz levará muito mais tempo.
Ao programar estruturas de dados, tente manter os caches em mente. É possível que, ao reduzir o tamanho da sua estrutura de dados, você atinja a capacidade de cache bem-sucedida e acelere as operações que serão executadas no futuro. A interação com a memória principal sempre foi, é e provavelmente continuará sendo um fator significativo de produtividade - mesmo quando você escreve no Swift para dispositivos modernos de alto desempenho.
CPU vs RAM: inicialização lenta
Embora em alguns casos, quando a memória usada seja reduzida, o programa comece a funcionar mais rapidamente, há casos em que essas duas métricas, pelo contrário, entram em conflito. Vou dar um exemplo com o conceito de inicialização lenta.
Suponha que tenhamos um método makeHeavyObject () que retorna algum objeto grande. Este método inicializará a variável lazilyCalculated.

O modificador lento define a variável lazilyCalculated como inicialização lenta. Isso significa que um valor será atribuído a ele somente quando a primeira chamada ocorrer durante a execução. É então que o método makeHeavyObject () funcionará e o objeto resultante será atribuído à variável lazilyCalculated.
Qual é a vantagem aqui? A partir do momento da inicialização (ainda que mais tarde, mas será executado), temos um objeto localizado na memória. Seu valor é contado, está pronto para uso - basta fazer uma solicitação. Outra coisa é que nosso objeto é grande e, a partir do momento da inicialização, ocupará na memória a maior parte das células.
Você pode seguir o outro caminho - não armazene o valor do campo:

Com todos os links para o campo lazilyCalculated, o método makeHeavyObject () será executado novamente. O valor será retornado ao ponto de consulta, enquanto não será colocado na memória. Como você pode ver, o armazenamento de uma variável é opcional.
O que é mais caro - armazenar um objeto grande na memória, mas não perder tempo na CPU, ou chamar o método toda vez que precisarmos do nosso campo, economizando memória? Você deve ter um valor pronto em mãos ou calculá-lo em tempo real? Esse tipo de dilema surge com frequência, onde quer que você faça seus cálculos - em um servidor remoto ou em sua máquina local, independentemente do cache com o qual você tenha que trabalhar. Você precisa tomar uma decisão com base nas limitações do sistema nesse caso específico.
Ciclo de otimização

Tudo o que você otimizar, seu trabalho, em regra, será construído no mesmo algoritmo. Primeiro, você examina o código, perfil / medida (no Xcode usando as ferramentas apropriadas), tentando identificar seus gargalos. Essencialmente, organize os métodos por quanto tempo eles levam para serem executados. E, em seguida, observe as linhas principais para determinar o que otimizar.
Ao escolher um objeto, você define a tarefa (ou, falando cientificamente, propõe uma hipótese): aplicando esses ou outros métodos de otimização, você pode fazer o código selecionado trabalhar mais rápido.
Em seguida, você tenta otimizar. Após cada modificação, você analisa os indicadores de desempenho, avaliando a eficácia da modificação e o quanto conseguiu avançar.
Assim como em um trabalho científico: especulação, experimento, análise de resultados. Você passa por esse ciclo de ações repetidamente. A prática mostra que o trabalho construído dessa maneira realmente permite eliminar os botneks um por um.
Testes unitários

Resumidamente sobre testes de unidade: temos algumas funções que estamos testando, algumas entradas de dados de entrada e saída de dados de saída; recebendo entrada como entrada, nossa função sempre deve retornar a saída e nenhuma de nossas otimizações deve violar essa propriedade.
Os testes de unidade nos ajudam a rastrear o colapso. Se, em resposta à entrada, nossa função parou de retornar a saída, então, direta ou indiretamente, alteramos o curso antigo do trabalho de nossa função.
Nem tente iniciar a otimização se você não tiver escrito uma parte generosa dos testes de unidade no seu código. Você deve poder fazer o teste de regressão. Se você olhar no GitHub my commits no meu exemplo de aplicação, para o qual continuarei, você pode ver que algumas das minhas otimizações trouxeram bugs.
E agora a parte divertida, vamos para as estrelas.
Milhões de estrelas
Há um grande (enorme) banco de dados descrevendo um milhão de estrelas. Além disso, criei vários aplicativos. Um deles usa a realidade aumentada, em tempo real, desenhando estrelas em cima da imagem da câmera do telefone. Agora vou demonstrá-lo em ação:
Na ausência de luzes da cidade, uma pessoa pode distinguir até 8.000 estrelas no céu. Eu precisaria de 1,8 MB para armazenar 8.000 registros. Em princípio, aceitável. Mas eu queria adicionar aquelas estrelas que uma pessoa pode ver através de um telescópio - resultaram em cerca de 120.000 estrelas (de acordo com o chamado catálogo de Hipparcos, agora obsoleto). Isso já requer 27 MB. E entre os catálogos modernos de domínio público, você pode encontrar um que contará com cerca de 2.500.000 estrelas. Esse banco de dados já ocuparia cerca de 560 MB. Como você pode ver, muita memória já é necessária. Mas não queremos apenas um banco de dados, mas um aplicativo baseado nele, onde haverá ARKit, SceneKit e outras coisas que também exigem memória.
O que fazer?
Vamos otimizar as estrelas.
Ferramenta MemoryLayout
Você pode avaliar o tamanho do programa como um todo. Mas, para trabalhos de joalheria, como otimização, você precisará de ferramentas para estimar o tamanho de cada estrutura de dados individual.
Swift permite que você faça isso de maneira simples - usando objetos MemoryLayout <>. Você declara um MemoryLayout <>, especificando a estrutura de dados de seu interesse como o tipo genérico. Agora, referindo-se às propriedades do objeto recebido, você pode receber uma variedade de informações úteis sobre sua estrutura.

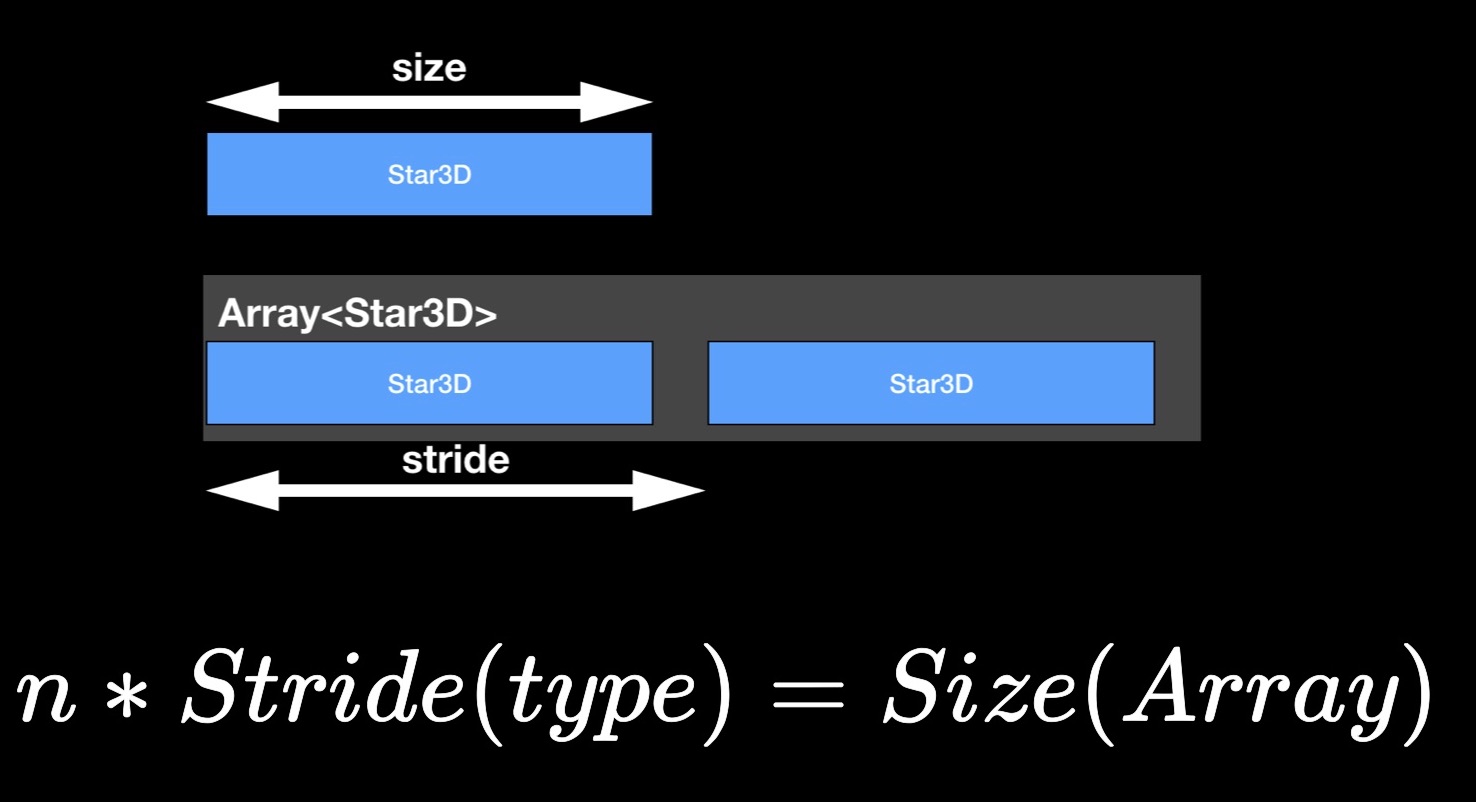
A propriedade size nos fornece o número de bytes ocupados por uma instância da estrutura.
Agora sobre a propriedade stride. Você deve ter notado que o tamanho da matriz, em regra, não é igual à soma dos tamanhos de seus elementos constituintes, mas excede-o. Obviamente, um pouco de "ar" é deixado entre os elementos na memória. Para estimar a distância entre elementos consecutivos em uma matriz adjacente, usamos a propriedade stride. Se você o multiplicar pelo número de elementos na matriz, obtém seu tamanho.
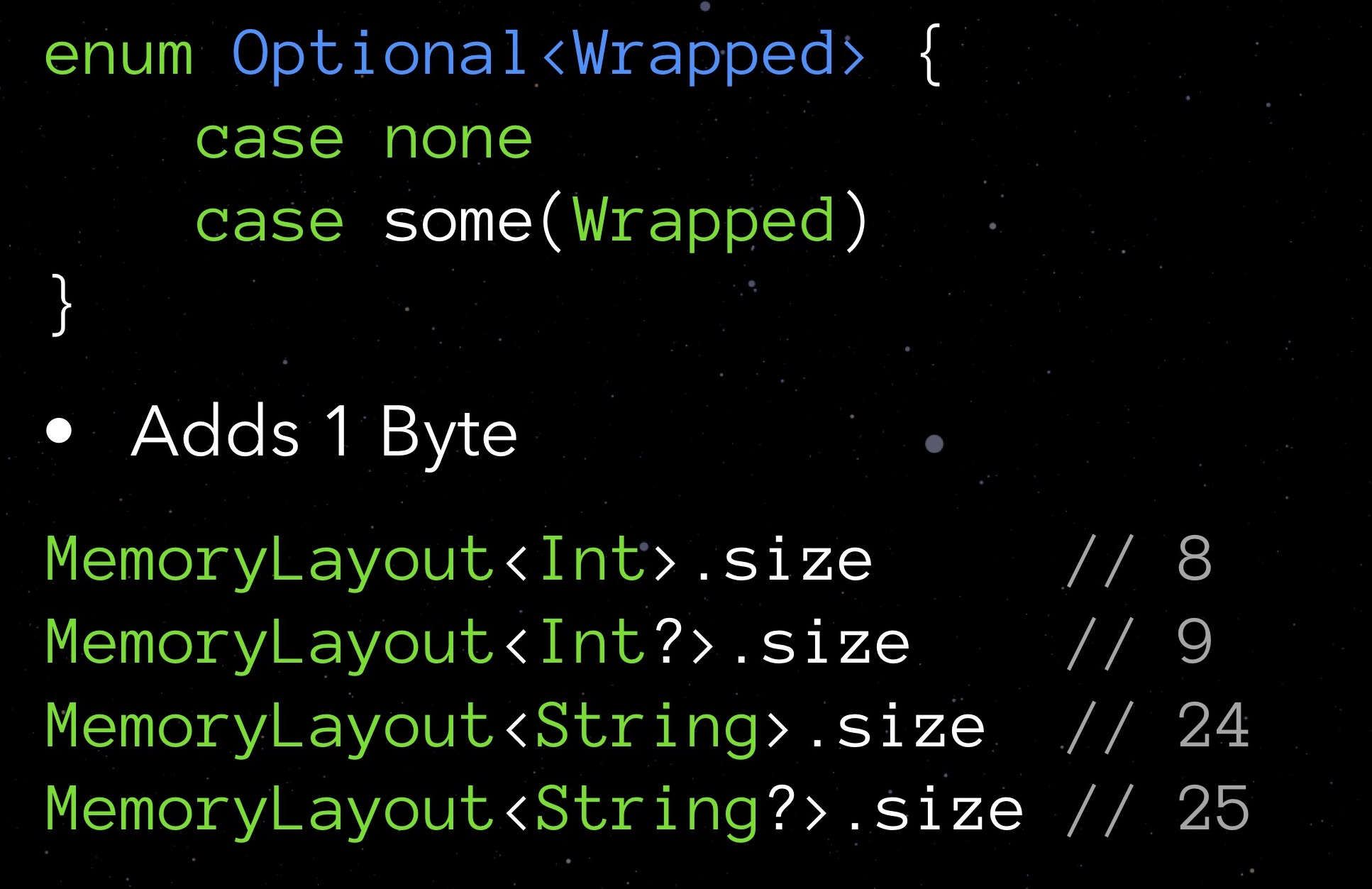
StarData, nossa estrutura experimental, em seu estado inicial não otimizado:
Aqui está uma estrutura de dados projetada para armazenar dados sobre uma estrela. Você não precisa se aprofundar no significado de cada um desses elementos. Agora é mais importante prestar atenção aos tipos: variáveis flutuantes que armazenam as coordenadas da estrela (de fato, latitude e longitude), vários Int32 para vários IDs, String para armazenar nomes e nomes de várias classificações; há distância, cor e outras quantidades necessárias para a exibição correta de uma estrela.
Solicitamos a propriedade stride:

No momento, nossa estrutura pesa 208 bytes. Um milhão dessas estruturas exigirá 250 MB - isso, como você sabe, é demais. Portanto, é necessário otimizar.
Int correto
O fato de existirem diferentes variedades de Int é relatado nas primeiras lições de programação. O Int mais familiar para nós no Swift é chamado Int8. Ocupa 8 bits (1 byte) e pode armazenar valores de -128 a 127 inclusive. Existem também outros Ints:
- Int16 no tamanho de 2 bytes, o intervalo de valores é de -32.768 a 32.767;
- Int32 no tamanho de 4 bytes, o intervalo de valores é de -2.147.483.648 a 2.147.483.647;
- Int64 (ou apenas Int) tem 8 bytes de tamanho, o intervalo de valores é de -9.223.372.036.854.775.808 a 9.223.372.036.854.775.807.
Provavelmente, aqueles que se envolveram no desenvolvimento da Web e lidaram com o SQL já estão pensando nisso. Mas sim, antes de tudo, escolha o Int ideal. Neste projeto, mesmo antes de pensar em otimização, entrei em um pouco de otimização prematura (que, como acabei de lhe dizer, não é necessário).
Vejamos, por exemplo, campos com ID. Sabemos que teremos cerca de um milhão de estrelas - não algumas dezenas de milhares, mas não um bilhão. Portanto, para esses campos, é melhor escolher Int32. Então percebi que 4 bytes são suficientes para o Float aqui. Double ocupará 8, String cada 24, adicione tudo - resulta 152 bytes. Se você se lembra, o MemoryLayout anterior nos disse que 208. Por quê? Nós devemos cavar mais fundo.
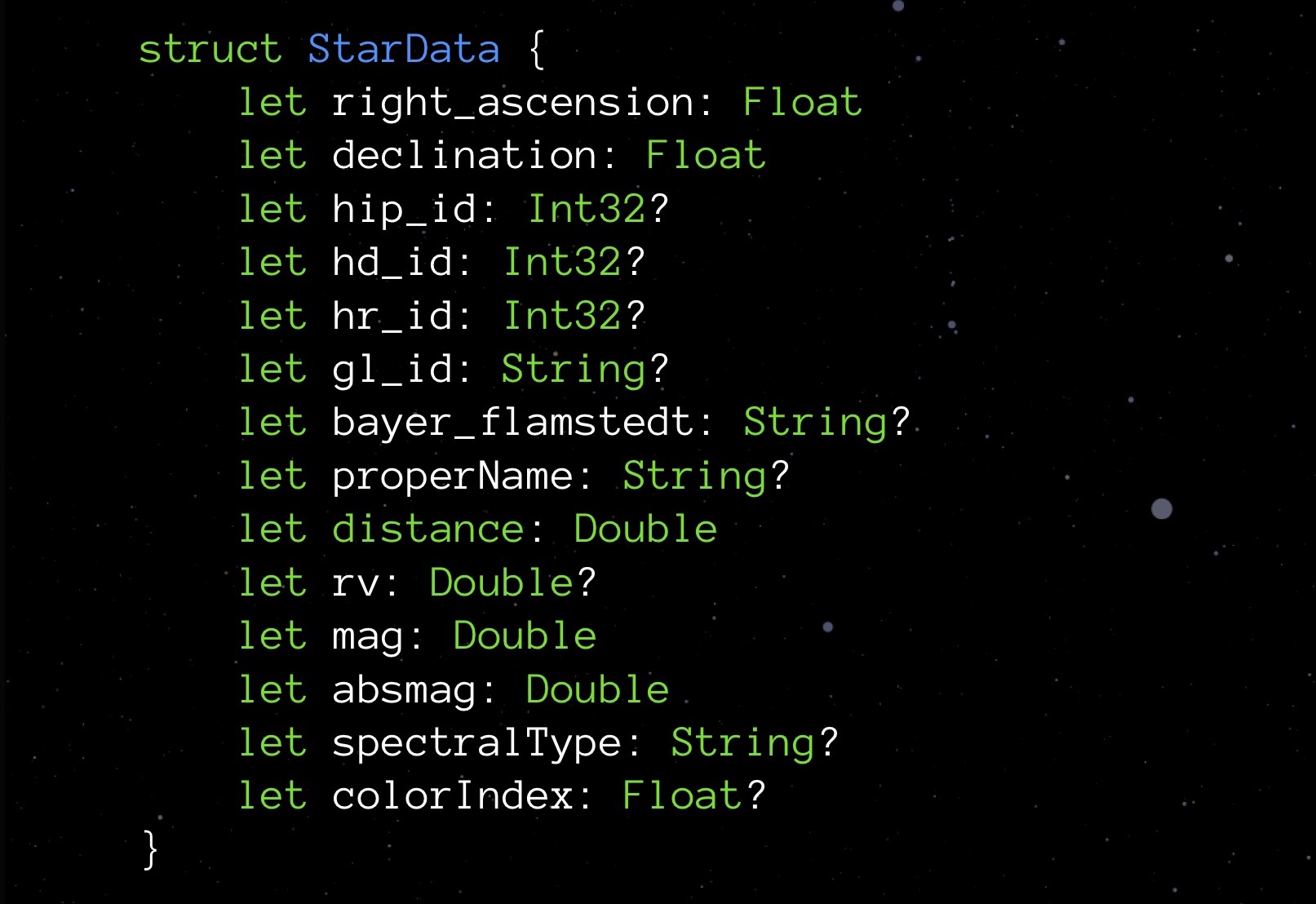
Primeiro, vejamos Opcional. Os tipos opcionais diferem no fato de que, se não houver valor atribuído, eles armazenam nulo. Isso garante segurança na interação com objetos. Mas, como você sabe, essa medida não custa de graça: ao solicitar a propriedade size de qualquer tipo opcional, você verá que esse tipo sempre leva um byte a mais. Pagamos pela capacidade de registrar-se no campo nulo.
Não gostaríamos de gastar um byte extra em uma variável. Ao mesmo tempo, gostamos muito da ideia incorporada em opcional. O que fazer? Vamos tentar implementar nossa estrutura.
Vamos escolher um valor que possa razoavelmente ser considerado "inválido" para um determinado campo, enquanto é adequado para o tipo declarado. Para getHipId (Int32), pode ser, por exemplo, o valor "-1". Isso significa que nosso campo não é inicializado. Aqui está uma bicicleta opcional, que dispensa um byte extra em nada.
Claramente, com esse truque, também temos uma potencial vulnerabilidade. Para nos proteger de erros, criaremos um getter para o campo, que gerenciará independentemente nossa nova lógica e verificará a validade do valor do campo.

Esse invasor abstrai completamente de nós a complexidade de uma solução inventada.
Vá para o nosso StarData. Substitua todos os tipos opcionais pelos tipos regulares e veja o que mostra a passada:
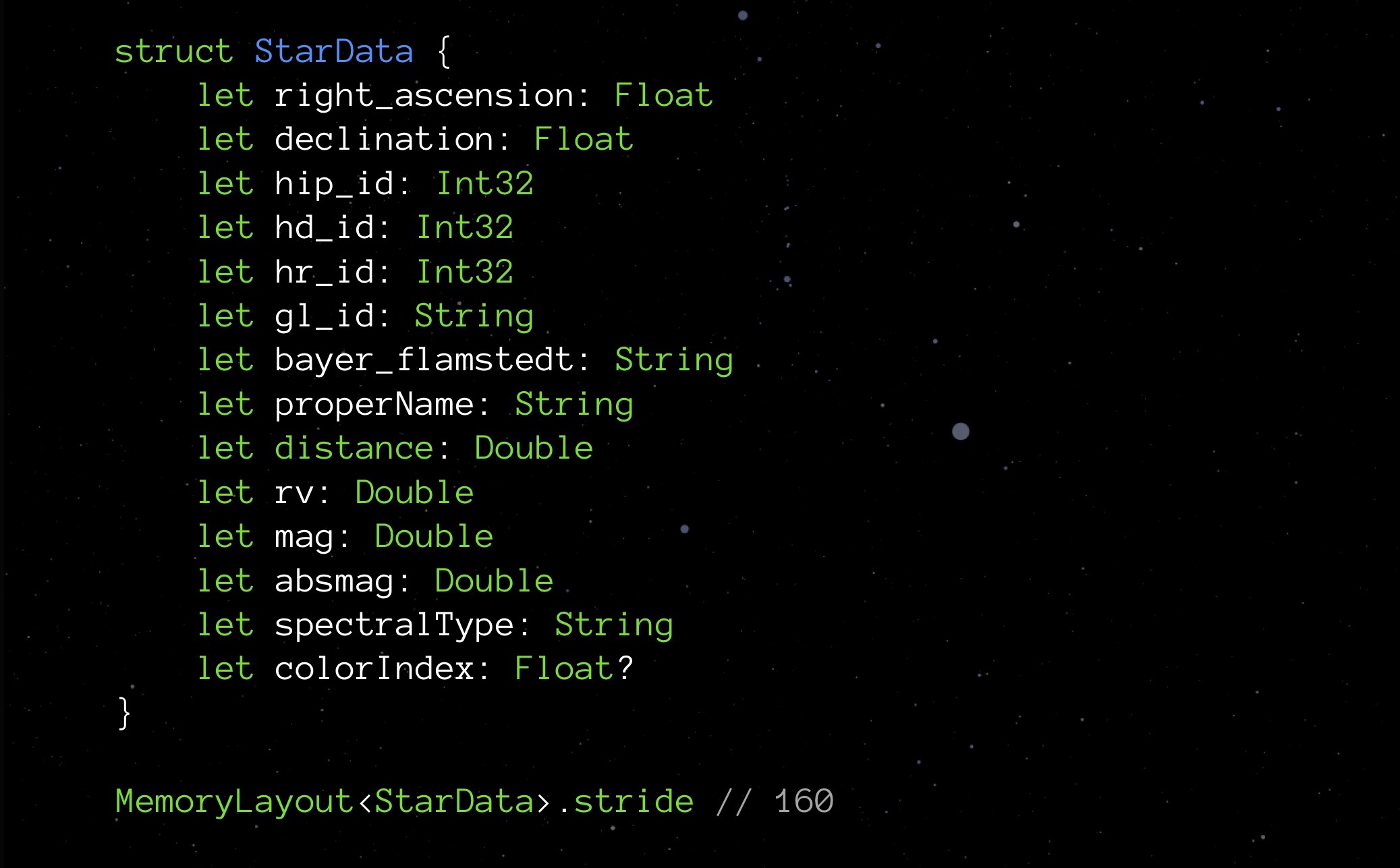
Acontece que, ao eliminar as opções, salvamos não 9 bytes (um byte para cada uma das nove opções), mas até 48. A surpresa é agradável, mas eu gostaria de saber por que isso aconteceu. E isso aconteceu por causa do alinhamento de dados na memória.
Alinhamento de dados
Lembre-se de que antes de Swift escrevíamos no Objective-C, e era baseado em C - e essa situação também remonta a C.
Ao colocar todas as estruturas na memória, os processadores modernos colocam seus elementos não em um fluxo contínuo (não "ombro a ombro"), mas em alguma grade reduzida de maneira homogênea pelos vazios. Este é o alinhamento de dados. Permite simplificar e acelerar o acesso aos elementos de dados necessários na memória.
As regras de alinhamento de dados se aplicam a cada variável, dependendo do seu tipo:
- uma variável do tipo char pode começar do 1º, 2º, 3º, 4º etc. bytes, pois leva apenas um byte em si;
- uma variável curta ocupa 2 bytes, para que possa começar do 2º, 4º, 6º, 8º etc. um byte (isto é, de cada byte par);
- uma variável do tipo float ocupa 4 bytes, o que significa que pode começar a cada 4, 8, 12, 16, etc. um byte (isto é, cada quarto byte);
- variáveis do tipo Double e String ocupam 8 bytes cada, para que possam começar com os dias 8, 16, 24, 32, etc. bytes
- etc.
Os objetos MemoryLayout <> têm uma propriedade de alinhamento que retorna a regra de alinhamento correspondente para o tipo especificado.
Poderíamos aplicar o conhecimento das regras de alinhamento para otimizar o código? Vejamos um exemplo. Existe uma estrutura de usuário: para firstName e lastName, usamos uma String regular, para middleName - uma String opcional (o usuário pode não ter esse nome). Na memória, uma instância dessa estrutura será colocada da seguinte maneira:

Como você pode ver, como o middleName opcional ocupa 25 bytes (em vez de múltiplos de 8 24 bytes), as regras de alinhamento obrigam você a pular os próximos 7 bytes e gastar 80 bytes em toda a estrutura. Aqui, não importa como você troque blocos com strings, é impossível contar com um número menor de bytes.
E agora um exemplo de falha no alinhamento:

BadAligned isHidden Bool (1 ), size Double (8 ), isInteractable bool (1 ) age Int ( 8 ). , , 32 .
— , .
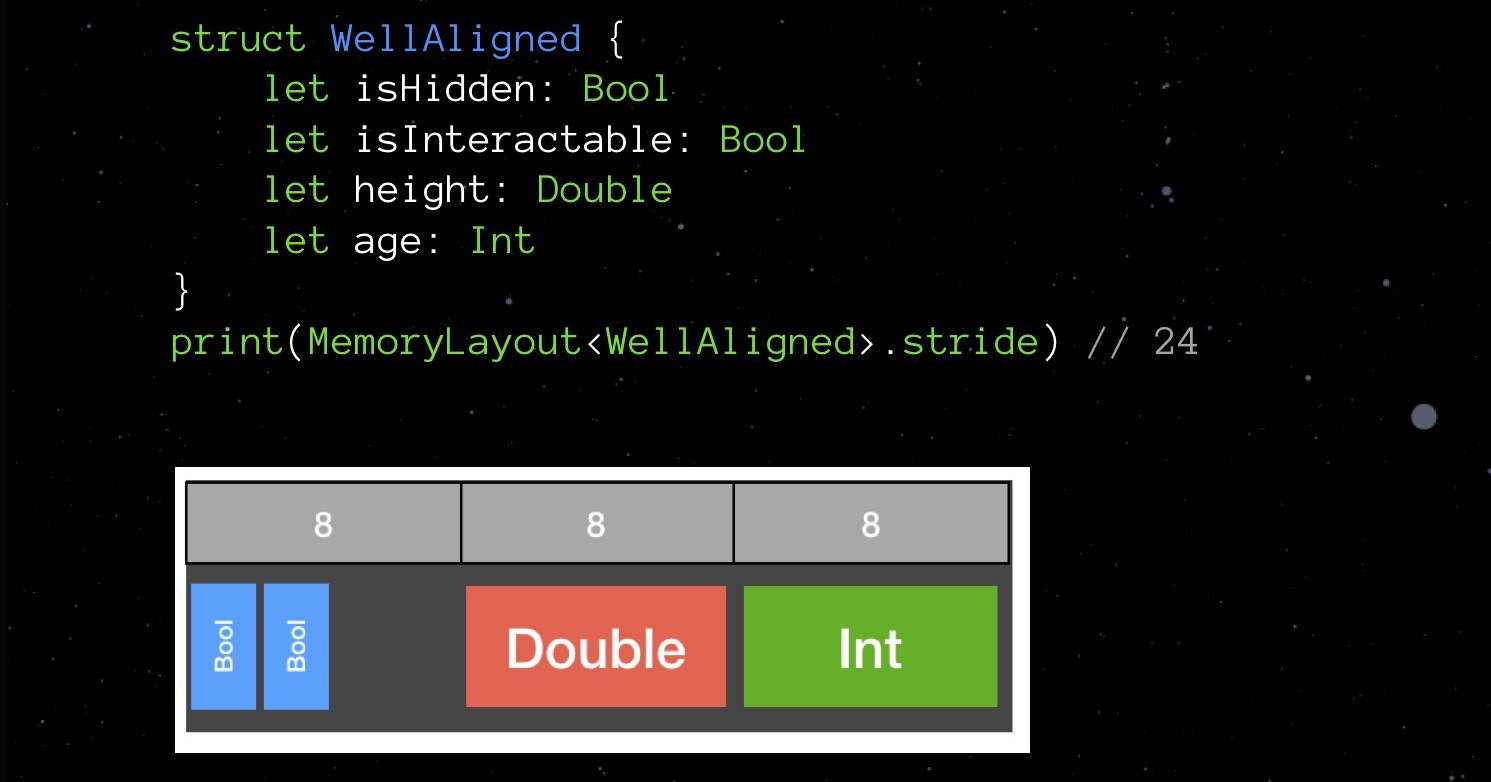
32 , 24. 25%.
Parece um jogo de Tetris, não é? Para coisas de baixo nível, Swift deve a linguagem C ao seu ancestral. Ao declarar campos em uma grande estrutura de dados aleatoriamente, é mais provável que você use mais memória do que poderia, dadas as regras de alinhamento. Portanto, tente lembrá-los e considere ao escrever código - isso não é tão difícil.Vamos voltar ao nosso StarData novamente. Vamos tentar organizar seus campos em ordem crescente de volume ocupado.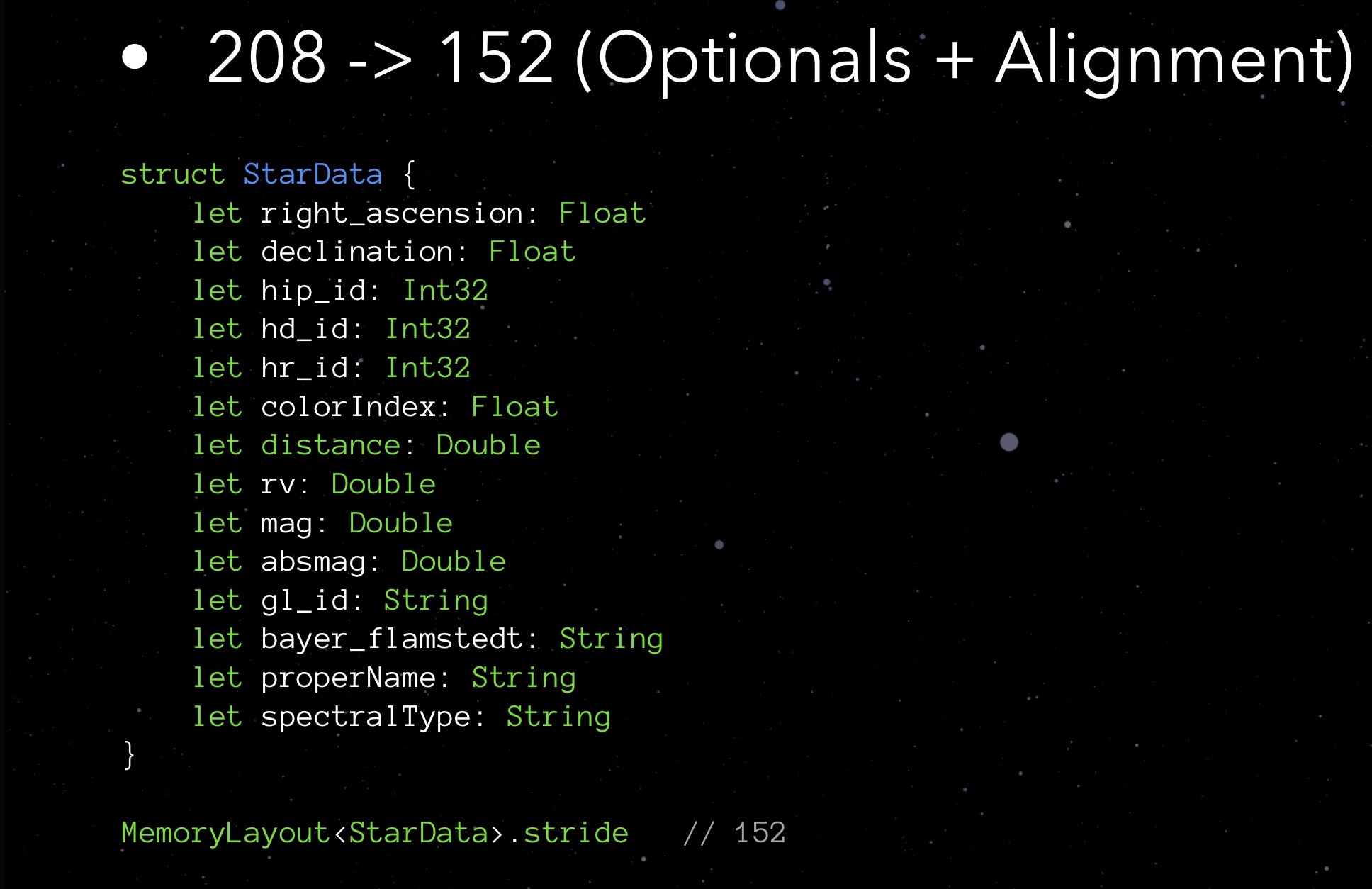 Primeiro, Float e Int32, depois Double e String. Não é tão complicado Tetris!O passo que recebemos é de 152 bytes. Ou seja, otimizando a implementação de opções e trabalhando com alinhamento, conseguimos reduzir o tamanho da estrutura de 208 para 152 bytes.Estamos nos aproximando do limite de nossos recursos de otimização? Provavelmente sim. No entanto, há algo mais que você e eu não tentamos - algo é uma ordem de magnitude mais complicada, mas às vezes pode surpreendê-lo com o resultado.
Primeiro, Float e Int32, depois Double e String. Não é tão complicado Tetris!O passo que recebemos é de 152 bytes. Ou seja, otimizando a implementação de opções e trabalhando com alinhamento, conseguimos reduzir o tamanho da estrutura de 208 para 152 bytes.Estamos nos aproximando do limite de nossos recursos de otimização? Provavelmente sim. No entanto, há algo mais que você e eu não tentamos - algo é uma ordem de magnitude mais complicada, mas às vezes pode surpreendê-lo com o resultado.Contabilidade da Lógica de Domínio
Tente se concentrar nas especificidades inerentes ao seu serviço. Lembre-se do meu exemplo com o xadrez: a idéia de variar o indicador FPS quando nada muda na tela é apenas uma otimização, levando em consideração a lógica de domínio do aplicativo.StarData. « » — String, . : ! 146 «» , properName. gl_id — ID , 3801 , . bayer_flamstedt — — 3064- . spectralType — 4307-. , , 24 .
. . — Int16, , - — , -1.
StarData properName, gl_id, bayer_flamstedt spectralType , . -, . — :

— . private, .
Obviamente, esta solução tem um sinal de menos. A economia de memória não pode deixar de afetar a carga do processador. Com esse esquema, somos forçados a acessar constantemente nossa matriz associativa; e na maioria dos casos - em vão, já que a maioria das linhas permanecerá vazia e as solicitações retornarão "-1".Portanto, tive que mudar um pouco o conceito do aplicativo. Foi decidido fornecer ao usuário informações sobre a estrela somente quando elas clicarem nela - somente então a consulta ao array associativo será executada e os dados recebidos serão exibidos na tela., , . . unit- — , .
: stride 64 !
? , : Int16 .

. , StarData 208 56 . 500 , 130. !
Não se esqueça dos perigos da otimização prematura. Se sua estrutura de dados de usuário for usada para cerca de 20 usuários, você não ganhará tanto assim que faz sentido fazê-lo. Mais importante, é conveniente para o próximo desenvolvedor depois que você manter o código. Por favor, não diga mais tarde "esse cara na conferência disse que a ordem deveria ser exatamente isso"! Não faça isso apenas por diversão. Bem, para mim, essas coisas são um bom entretenimento, não sei como fazer para você.Otimização rápida do compilador
( ) . , , .
- . , .
Xcode. :

, xCode culprits.txt. .
 Usando meu instrumento simples, eu pude observar coisas interessantes. Alguns métodos podem ser compilados por até 2 segundos, enquanto contêm apenas três linhas de código. Qual poderia ser o motivo?Por exemplo, algo como saída do compilador de tipo. Se você não especificar tipos explicitamente, o Swift será forçado a detectá-los. Essa operação (devo dizer, não trivial) requer tempo do processador; portanto, do ponto de vista do compilador, é sempre melhor indicar o tipo. Apenas escrevendo explicitamente os tipos, fui capaz de reduzir o tempo de compilação do aplicativo de 5 para 2 (!) Minutos.Mas existe um "mas": código sem tipos ainda é mais legível. E nós já conversamos sobre prioridades. Não otimize antecipadamente: a princípio, a legibilidade do código será mais cara.
Usando meu instrumento simples, eu pude observar coisas interessantes. Alguns métodos podem ser compilados por até 2 segundos, enquanto contêm apenas três linhas de código. Qual poderia ser o motivo?Por exemplo, algo como saída do compilador de tipo. Se você não especificar tipos explicitamente, o Swift será forçado a detectá-los. Essa operação (devo dizer, não trivial) requer tempo do processador; portanto, do ponto de vista do compilador, é sempre melhor indicar o tipo. Apenas escrevendo explicitamente os tipos, fui capaz de reduzir o tempo de compilação do aplicativo de 5 para 2 (!) Minutos.Mas existe um "mas": código sem tipos ainda é mais legível. E nós já conversamos sobre prioridades. Não otimize antecipadamente: a princípio, a legibilidade do código será mais cara.Opção de servidor
. Swift.
,
GitHub . API-, . , ARkit. : 500 , Bluemix. , .
, , :
- . . , , , ?
- , unit-. , unit-. , . Unit- , .
- . , . , : — .
- . . , — , «» .
- RAM vs. CPU. . , .
Mobius — , 8-9 Mobius 2018 Moscow , . 1 , !