O Aprendizado Reforçado (RL) é uma das técnicas de aprendizado de máquina mais promissoras que está sendo ativamente desenvolvida. Aqui, o agente de IA recebe uma recompensa positiva pelas ações corretas e uma recompensa negativa pelas ações erradas. Este método de
cenoura e palito é simples e universal. Com ele, o DeepMind ensinou o algoritmo
DQN a jogar videogames antigos da Atari e o
AlphaGoZero a jogar o antigo jogo Go. Então a OpenAI ensinou o algoritmo
OpenAI-Five a jogar o moderno videogame Dota, e o Google ensinou mãos robóticas para
capturar novos objetos . Apesar do sucesso da RL, ainda existem muitos problemas que reduzem a eficácia dessa técnica.
Os algoritmos de RL
acham difícil trabalhar em um ambiente em que o agente raramente recebe feedback. Mas isso é típico do mundo real. Como exemplo, imagine procurar seu queijo favorito em um labirinto grande, como um supermercado. Você está procurando e procurando um departamento com queijos, mas não consegue encontrá-lo. Se a cada passo você não recebe um "pau" ou uma "cenoura", é impossível dizer se você está se movendo na direção certa. Na ausência de uma recompensa, o que o impede de perambular para sempre? Nada além de sua curiosidade. Isso motiva a mudança para o departamento de compras, que parece desconhecido.
O trabalho científico,
"Curiosidade episódica através da acessibilidade", é o resultado de uma colaboração entre
a equipe do Google Brain ,
DeepMind, e
a Escola Técnica Superior Suíça de Zurique . Oferecemos um novo modelo de recompensa RL baseada em memória episódica. Ela parece uma curiosidade que permite explorar o meio ambiente. Como o agente não deve apenas estudar o ambiente, mas também resolver o problema inicial, nosso modelo adiciona um bônus à recompensa inicialmente esparsa. A recompensa combinada não é mais escassa, o que permite que os algoritmos RL padrão aprendam com ela. Assim, nosso método de curiosidade expande a gama de tarefas que podem ser resolvidas usando RL.
 Curiosidade ocasional através da acessibilidade: dados de observação são adicionados à memória, a recompensa é calculada com base na distância que a observação atual está de observações semelhantes na memória. O agente recebe uma recompensa maior por observações que ainda não são apresentadas na memória.
Curiosidade ocasional através da acessibilidade: dados de observação são adicionados à memória, a recompensa é calculada com base na distância que a observação atual está de observações semelhantes na memória. O agente recebe uma recompensa maior por observações que ainda não são apresentadas na memória.A idéia principal do método é armazenar as observações do ambiente do agente na memória episódica, além de recompensar o agente por visualizar as observações ainda não apresentadas na memória. "Falta de memória" é a definição de novidade em nosso método. A busca por tais observações significa a busca de um estranho. Tal desejo de procurar um estranho levará o agente da IA a novos locais, evitando assim vaguear em um círculo e, finalmente, ajudá-lo a tropeçar no alvo. Como discutiremos mais adiante, nossa redação pode impedir o agente de comportamentos indesejáveis aos quais outras palavras estão sujeitas. Para nossa grande surpresa, esse comportamento tem algumas semelhanças com o que um leigo chamaria de "procrastinação".
Curiosidade anterior
Embora tenha havido muitas tentativas de formular curiosidade no passado
[1] [2] [3] [4] , neste artigo, focaremos em uma abordagem natural e muito popular: curiosidade por surpresa com base em previsão. Essa técnica é descrita em um artigo recente,
“Investigando um ambiente usando a curiosidade, prevendo sob seu próprio controle” (geralmente chamado de ICM). Para ilustrar a conexão entre surpresa e curiosidade, usamos novamente a analogia de encontrar queijo em um supermercado.
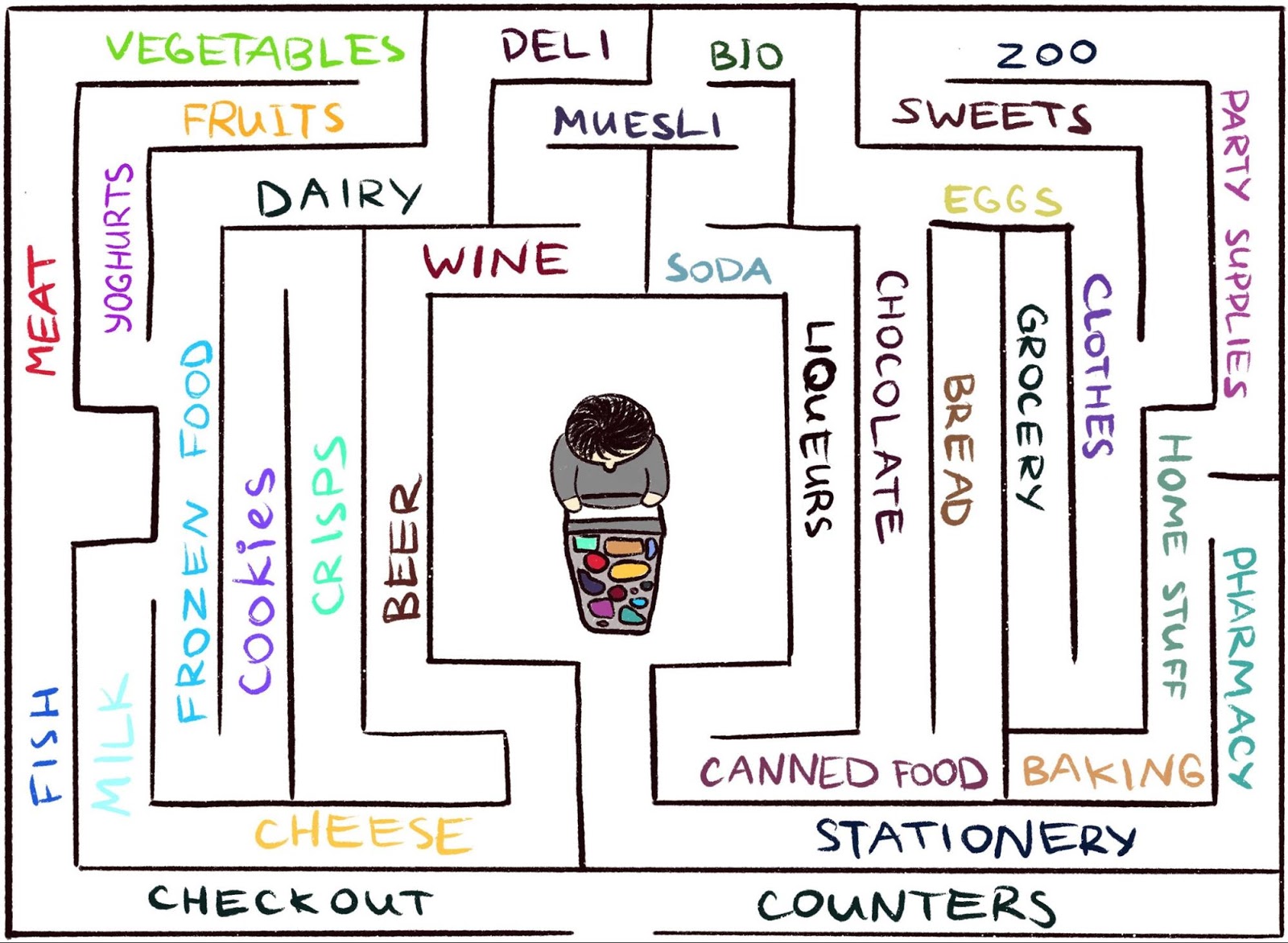 Ilustração de Indira Pasko , licenciada sob CC BY-NC-ND 4.0
Ilustração de Indira Pasko , licenciada sob CC BY-NC-ND 4.0Vagando pela loja, você está tentando prever o futuro (
"Agora estou no departamento de carnes, então acho que o departamento ao virar da esquina é o departamento de peixes, eles geralmente estão nas proximidades dessa cadeia de supermercados" ). Se a previsão estiver incorreta, você ficará surpreso (
"Na verdade, existe um departamento de vegetais. Eu não esperava isso!" ) - e dessa maneira você recebe uma recompensa. Isso aumenta a motivação no futuro para olhar ao virar da esquina novamente, explorando novos lugares apenas para verificar se suas expectativas são verdadeiras (e possivelmente tropeçam no queijo).
Da mesma forma, o método ICM constrói um modelo preditivo da dinâmica do mundo e recompensa o agente se o modelo falhar em fazer boas previsões - um marcador de surpresa ou novidade. Observe que explorar novos lugares não está diretamente articulado na curiosidade do ICM. Para o método ICM, comparecer a eles é apenas uma maneira de obter mais "surpresas" e, assim, maximizar sua recompensa geral. Como se vê, em alguns ambientes, pode haver outras maneiras de se surpreender, o que leva a resultados inesperados.
Um agente com um sistema de curiosidade baseado em surpresas congela ao se reunir com uma TV. Animação do vídeo de Deepak Patak , licenciado sob CC BY 2.0O perigo da procrastinação
No artigo,
“Um estudo em larga escala da aprendizagem baseada na curiosidade”, os autores do método ICM, juntamente com os pesquisadores da OpenAI, mostram um perigo oculto de maximizar a surpresa: os agentes podem aprender a se entregar à procrastinação, em vez de fazer algo útil para a tarefa. Para entender por que isso acontece, considere um experimento mental que os autores chamam de "problema de ruído na televisão". Aqui o agente é colocado em um labirinto com a tarefa de encontrar um item muito útil (como "queijo" em nosso exemplo). O ambiente possui uma TV e o agente possui um controle remoto. Há um número limitado de canais (cada canal possui uma transmissão separada) e cada pressão no controle remoto muda a TV para um canal aleatório. Como um agente atuará nesse ambiente?
Se a curiosidade for formada com base na surpresa, uma mudança de canal dará mais recompensas, pois cada mudança é imprevisível e inesperada. É importante observar que, mesmo após uma varredura cíclica de todos os canais disponíveis, uma seleção aleatória de um canal garante que cada nova alteração ainda seja inesperada - o agente faz uma previsão de que exibirá TV após alternar o canal e, muito provavelmente, a previsão ficará incorreta, o que causará surpresa. É importante observar que, mesmo que o agente já tenha visto cada transmissão em cada canal, a alteração ainda é imprevisível. Por isso, o agente, em vez de procurar um item muito útil, permanecerá na frente da TV - semelhante à procrastinação. Como mudar a expressão da curiosidade para evitar esse comportamento?
Curiosidade episódica
No artigo
“Curiosidade episódica através de alcançabilidade”, examinamos um modelo de curiosidade episódica baseada em memória que é menos propenso a prazer instantâneo. Porque Se tomarmos o exemplo acima, depois de algum tempo trocando de canal, todas as transmissões acabarão na memória. Assim, a TV perde seu apelo: mesmo que a ordem em que os programas apareçam na tela seja aleatória e imprevisível, eles estão todos na memória! Essa é a principal diferença do método baseado na surpresa: nosso método nem tenta prever o futuro, é difícil de prever (ou mesmo impossível). Em vez disso, o agente examina o passado e verifica se há alguma observação na memória
como a atual. Assim, nosso agente não é propenso a prazeres instantâneos, o que gera um "ruído na televisão". O agente precisará explorar o mundo fora da TV para obter mais recompensas.
Mas como decidimos se um agente vê a mesma coisa que é armazenada na memória? A verificação exata da correspondência é inútil: em um ambiente real, um agente raramente vê a mesma coisa duas vezes. Por exemplo, mesmo que o agente retorne à mesma sala, ele ainda a verá de um ângulo diferente.
Em vez de verificar se há correspondências exatas, usamos uma
rede neural profunda treinada para medir como duas experiências são semelhantes. Para treinar essa rede, devemos adivinhar o quanto as observações ocorreram no tempo. A proximidade no tempo é um bom indicador de se duas observações devem ser consideradas parte da mesma. Esse aprendizado leva a um conceito geral de novidade através da acessibilidade, que é ilustrado abaixo.
 O gráfico de alcançabilidade define a novidade. Na prática, este gráfico não está disponível - portanto, treinamos o aproximador da rede neural para estimar o número de etapas entre as observações
O gráfico de alcançabilidade define a novidade. Na prática, este gráfico não está disponível - portanto, treinamos o aproximador da rede neural para estimar o número de etapas entre as observaçõesResultados experimentais
Para comparar o desempenho de diferentes abordagens para descrever a curiosidade, as testamos em dois ambientes 3D visualmente ricos:
ViZDoom e
DMLab . Nessas condições, o agente recebeu várias tarefas, como encontrar um alvo no labirinto, colecionar objetos bons e evitar objetos ruins. No ambiente DMLab, o agente é equipado por padrão com um gadget fantástico como um laser, mas se o gadget não for necessário para uma tarefa específica, o agente não poderá usá-lo livremente. Curiosamente, com base na surpresa, o agente do ICM realmente usou o laser com muita frequência, mesmo que fosse inútil concluir a tarefa! Como no caso da TV, em vez de procurar um item valioso no labirinto, ele preferia passar um tempo atirando nas paredes, porque isso dava muitas recompensas na forma de surpresa. Teoricamente, o resultado de um tiro na parede deve ser previsível, mas na prática é muito difícil de prever. Provavelmente, isso requer um conhecimento mais profundo da física do que o disponível para o agente de IA padrão.
O agente ICM surpreso constantemente atira contra a parede em vez de explorar o labirintoAo contrário dele, nosso agente dominou um comportamento razoável para estudar o ambiente. Isso aconteceu porque ele não está tentando prever o resultado de suas ações, mas procura observações que estão "mais longe" daquelas que estão na memória episódica. Em outras palavras, o agente persegue implicitamente objetivos que exigem mais esforço do que um simples tiro na parede.
Nosso método demonstra um comportamento inteligente de exploração ambiental.É interessante observar como nossa abordagem de recompensa pune um agente que circula em círculo, porque após a conclusão do primeiro círculo, o agente não encontra novas observações e, portanto, não recebe nenhuma recompensa:
Visualização de recompensa: vermelho corresponde a recompensa negativa, verde a positivo. Da esquerda para a direita: cartão-prêmio, mapa com localizações na memória, visão em primeira pessoaAo mesmo tempo, nosso método contribui para um bom estudo do meio ambiente:
Visualização de recompensa: vermelho corresponde a recompensa negativa, verde a positivo. Da esquerda para a direita: cartão-prêmio, mapa com localizações na memória, visão em primeira pessoaEsperamos que nosso trabalho contribua para uma nova onda de pesquisa que vai além do escopo da técnica da surpresa, a fim de educar os agentes sobre comportamentos mais inteligentes. Para uma análise aprofundada do nosso método, consulte a
pré -
impressão do trabalho científico .
Agradecimentos:
Este projeto é o resultado de uma colaboração entre a equipe do Google Brain, DeepMind, e a Escola Técnica Superior Suíça de Zurique. Grupo principal de pesquisa: Nikolay Savinov, Anton Raichuk, Rafael Marinier, Damien Vincent, Mark Pollefeys, Timothy Lillirap e Sylvain Geli. Gostaríamos de agradecer a Olivier Pietkin, Carlos Riquelme, Charles Blundell e Sergey Levine pela discussão deste documento. Agradecemos a Indira Pasco pela ajuda com as ilustrações.
Referências à literatura:
[1]
“O estudo do meio ambiente baseado na contagem com modelos de densidade neural” , Georg Ostrovsky, Mark G. Bellemar, Aaron Van den Oord, Remy Munoz
[2]
“Ambientes de aprendizagem baseados em contagem
para aprendizado profundo com reforço” , Khaoran Tan, Rain Huthuft, Davis Foot, Adam Knock, Si Chen, Yan Duan, John Schulman, Philip de Turk, Peter Abbel
[3]
“Aprendendo sem um professor para localizar metas para pesquisas motivadas internamente”, Alexander Pere, Sebastien Forestier, Olivier Sigot, Pierre-Yves Udaye
[4]
“VIME: inteligência para maximizar as alterações de informações”, Rein Huthuft, Xi Chen, Yan Duan, John Schulman, Philippe de Turk, Peter Abbel