Oi habr.
Em um projeto em que era necessário armazenar e processar uma lista dinâmica bastante grande, os testadores começaram a reclamar por falta de memória. Uma maneira simples de corrigir o problema com "pouco sangue" adicionando apenas uma linha de código é descrita abaixo. O resultado na imagem:
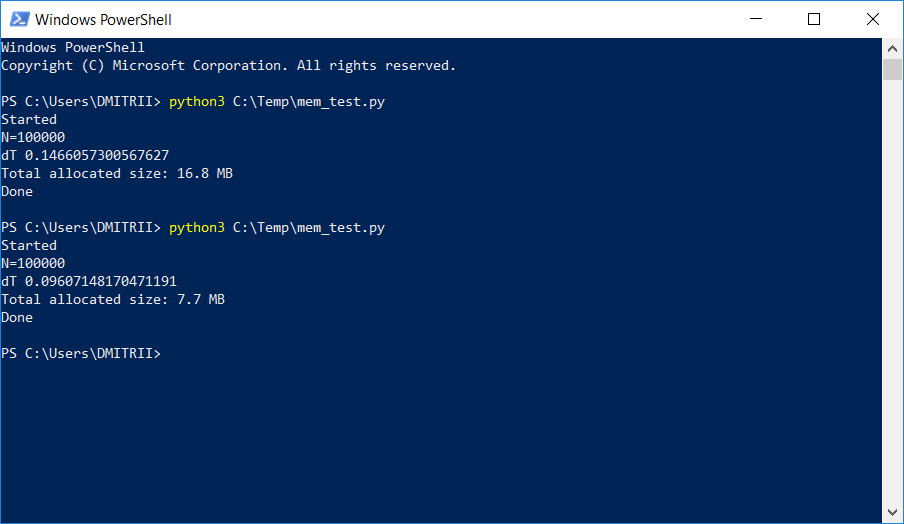
Como funciona, continuou sob o corte.
Considere um exemplo simples de "treinamento" - crie uma classe DataItem contendo dados
pessoais sobre uma pessoa, por exemplo, nome, idade e endereço.
class DataItem(object): def __init__(self, name, age, address): self.name = name self.age = age self.address = address
A questão das "crianças" é quanto esse objeto leva na memória?
Vamos tentar a solução na testa:
d1 = DataItem("Alex", 42, "-") print ("sys.getsizeof(d1):", sys.getsizeof(d1))
Nós obtemos uma resposta de 56 bytes. Parece um pouco, bastante satisfeito.
No entanto, verificamos outro objeto no qual há mais dados:
d2 = DataItem("Boris", 24, "In the middle of nowhere") print ("sys.getsizeof(d2):", sys.getsizeof(d2))
A resposta é novamente 56. Nesse ponto, entendemos que algo não está certo aqui e nem tudo é tão simples quanto parece à primeira vista.
A intuição não falha, e nem tudo é tão simples. Python é uma linguagem muito flexível com digitação dinâmica e, por seu trabalho, armazena muitos dados adicionais. Que por si só exigem muito. Apenas como exemplo, sys.getsizeof ("") retornará 33 - sim, até 33 bytes por linha vazia! E sys.getsizeof (1) retornará 24 - 24 bytes para um número inteiro (peço aos programadores C que se afastem da tela e não leiam mais, para não perder a fé no belo). Para elementos mais complexos, como um dicionário, sys.getsizeof (dict ()) retornará 272 bytes - e isso é para um dicionário
vazio . Não vou continuar, espero que o princípio esteja claro,
e os fabricantes de RAM também precisam vender seus chips .
Mas voltando à nossa classe DataItem e à pergunta "filho". Quanto tempo essa classe leva na memória? Para começar, exibimos todo o conteúdo da classe em um nível inferior:
def dump(obj): for attr in dir(obj): print(" obj.%s = %r" % (attr, getattr(obj, attr)))
Esta função mostrará o que está oculto "sob o capô", para que todas as funções do Python (digitação, herança e outros itens) possam funcionar.
O resultado é impressionante:
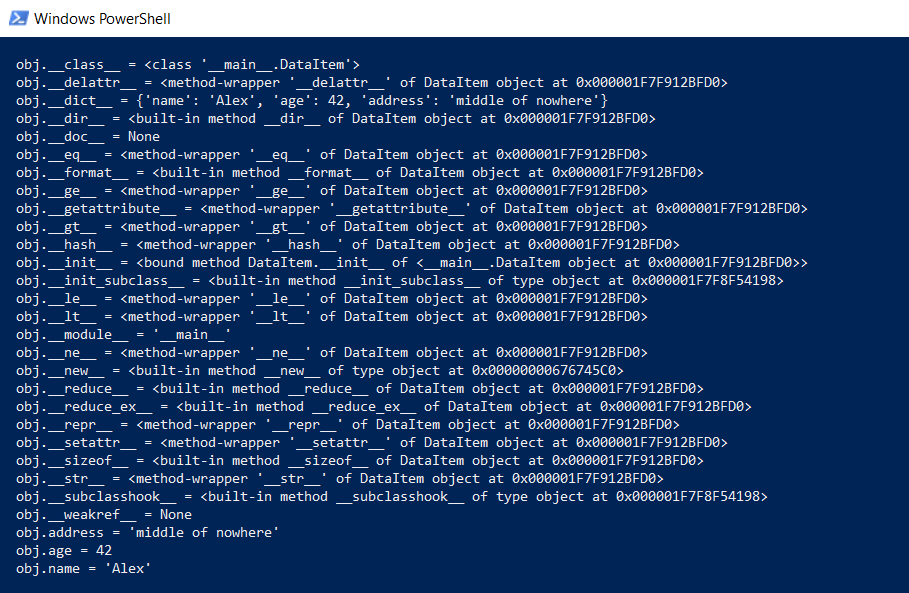
Quanto isso tudo leva? No github, havia uma função que calcula a quantidade real de dados, chamando recursivamente o tamanho de todos os objetos.
def get_size(obj, seen=None):
Tentamos:
d1 = DataItem("Alex", 42, "-") print ("get_size(d1):", get_size(d1)) d2 = DataItem("Boris", 24, "In the middle of nowhere") print ("get_size(d2):", get_size(d2))
Temos 460 e 484 bytes, respectivamente, o que é mais parecido com a verdade.
Tendo essa função, várias experiências podem ser realizadas. Por exemplo, gostaria de saber quantos dados serão necessários se você colocar as estruturas DataItem na lista. A função get_size ([d1]) retorna 532 bytes - aparentemente este é o "mesmo" 460 + alguma sobrecarga. Mas get_size ([d1, d2]) retornará 863 bytes - menos de 460 + 484 separadamente. Ainda mais interessante é o resultado para get_size ([d1, d2, d1]) - obtemos 871 bytes, um pouco mais, ou seja, O Python é inteligente o suficiente para não alocar memória para o mesmo objeto pela segunda vez.
Agora passamos à segunda parte da pergunta - é possível reduzir o consumo de memória? Sim você pode. Python é um intérprete, e podemos expandir nossa classe a qualquer momento, por exemplo, adicione um novo campo:
d1 = DataItem("Alex", 42, "-") print ("get_size(d1):", get_size(d1)) d1.weight = 66 print ("get_size(d1):", get_size(d1))
Isso é ótimo, mas se
não precisarmos dessa funcionalidade, podemos forçar o intérprete a listar os objetos da classe usando a diretiva __slots__:
class DataItem(object): __slots__ = ['name', 'age', 'address'] def __init__(self, name, age, address): self.name = name self.age = age self.address = address
Você pode ler mais na documentação (
RTFM ), que diz que "__slots__ nos permite declarar explicitamente membros de dados (como propriedades) e negar a criação de __dict__ e __weakref__. O espaço economizado usando __dict__
pode ser significativo ".
Verifique: sim, realmente significativo, get_size (d1) retorna ... 64 bytes em vez de 460, ou seja, 7 vezes menos. Como bônus, os objetos são criados cerca de 20% mais rápido (veja a primeira captura de tela do artigo).
Infelizmente, com o uso real, um ganho tão grande na memória não será devido a outras despesas gerais. Vamos criar uma matriz para 100.000 simplesmente adicionando elementos e ver o consumo de memória:
data = [] for p in range(100000): data.append(DataItem("Alex", 42, "middle of nowhere")) snapshot = tracemalloc.take_snapshot() top_stats = snapshot.statistics('lineno') total = sum(stat.size for stat in top_stats) print("Total allocated size: %.1f MB" % (total / (1024*1024)))
Temos 16,8 MB sem __slots__ e 6,9 MB com ele. Não sete vezes, é claro, mas muito bem, já que a alteração do código foi mínima.
Agora sobre as deficiências. A ativação de __slots__ proíbe a criação de todos os elementos, incluindo __dict__, o que significa, por exemplo, que um código para converter uma estrutura em json não funcionará:
def toJSON(self): return json.dumps(self.__dict__)
Mas é fácil de corrigir, basta gerar seu ditado programaticamente, classificando todos os elementos do loop:
def toJSON(self): data = dict() for var in self.__slots__: data[var] = getattr(self, var) return json.dumps(data)
Também será impossível adicionar dinamicamente novas variáveis à classe, mas no meu caso isso não foi necessário.
E o último teste de hoje. É interessante ver quanta memória o programa inteiro leva. Adicione um loop infinito no final do programa para que não feche e veja o consumo de memória no gerenciador de tarefas do Windows.
Sem __slots__:
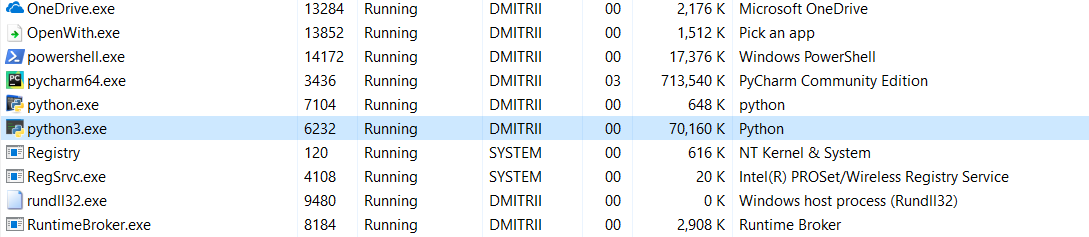
16,8 MB de alguma forma girou milagrosamente (edição - uma explicação do milagre abaixo) para 70 MB (espero que os programadores C ainda não tenham retornado à tela?).
Com __slots__ ativado:

6,9 MB se transformaram em 27 MB ... bem, afinal, economizamos memória, 27 MB em vez de 70 não é tão ruim pelo resultado da adição de uma linha de código.
Edit : nos comentários (graças a robert_ayrapetyan pelo teste), eles sugeriram que a biblioteca de depuração tracemalloc consome muita memória adicional. Aparentemente, ele adiciona elementos adicionais a
cada objeto criado. Se você desativá-lo, o consumo total de memória será muito menor, a captura de tela mostrará 2 opções:
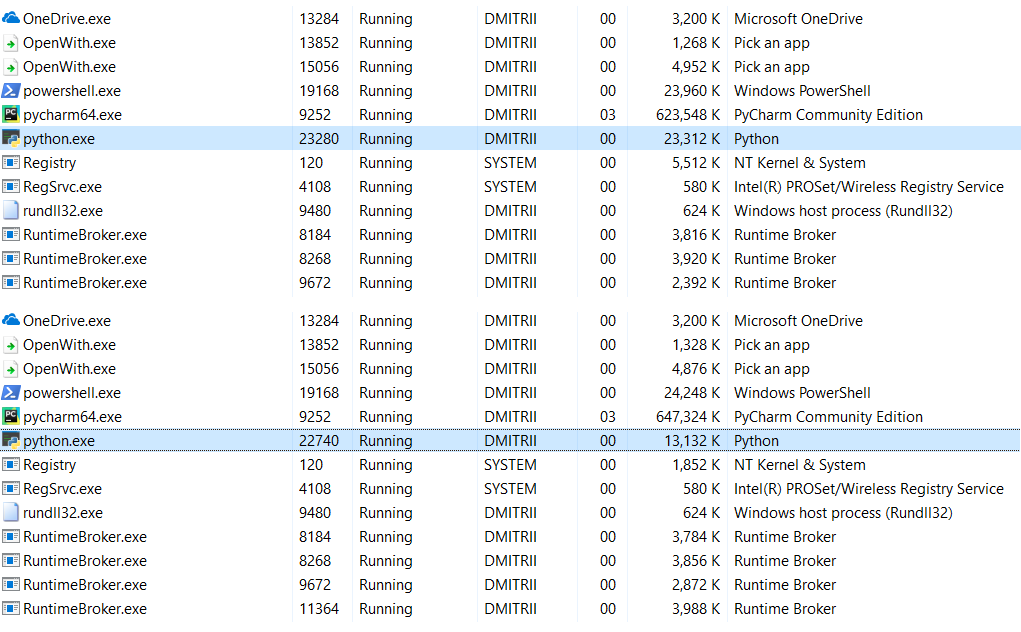
O que fazer se você precisar economizar ainda mais memória? Isso é possível usando a biblioteca
numpy , que permite criar estruturas no estilo C, mas no meu caso seria necessário um refinamento mais profundo do código, e o primeiro método acabou sendo suficiente.
É estranho que o uso de __slots__ nunca tenha sido examinado em detalhes em Habré. Espero que este artigo preencha um pouco essa lacuna.
Em vez de uma conclusão.
Este artigo pode parecer antipublicidade do Python, mas não é de todo. O Python é muito confiável (você tem que se esforçar
muito para abandonar um programa Python), uma linguagem que é facilmente legível e fácil de escrever código. Essas vantagens superam os contras em muitos casos, mas se você precisar de desempenho e eficiência máximos, poderá usar bibliotecas como numpy escritas em C ++ que funcionam com dados de maneira rápida e eficiente.
Obrigado a todos pela atenção e bom código :)