Então, comunidade, peço que você me dê uma chance de surpreendê-lo pela terceira vez. Na decisão anterior , usei python, pensei em chamar a atenção dos especialistas aqui e eles imediatamente me diziam por que fazer isso, em geral existem expressões regulares - eu fiz e tudo está certo vai funcionar, isso nosso python pode dar e mais velocidade.
O próximo tópico do artigo deve ser outra tarefa, por sua vez, mas não, o primeiro não me deixou, o que pode ser feito para obter uma solução ainda mais rápida, uma vez que a vitória no site foi coroada com outra competição.
Eu escrevi uma implementação que, em média, era desse tipo de velocidade, o que significa que ainda existem 90% das soluções que eu não percebi que alguém sabe como resolvê-lo ainda mais rápido e ele fica em silêncio . Depois de examinar os dois artigos anteriores, eu não disse: ah, se problema de desempenho, tudo fica claro - aqui o prólogo não se encaixa. Mas agora tudo está normal com o desempenho, não é possível imaginar um programa que funcione com hardware fraco ", no final, por que pensar nisso?"
Desafio
Para resolver o problema ainda mais rápido, havia um python e houve tempo, e existe uma solução mais rápida no python?
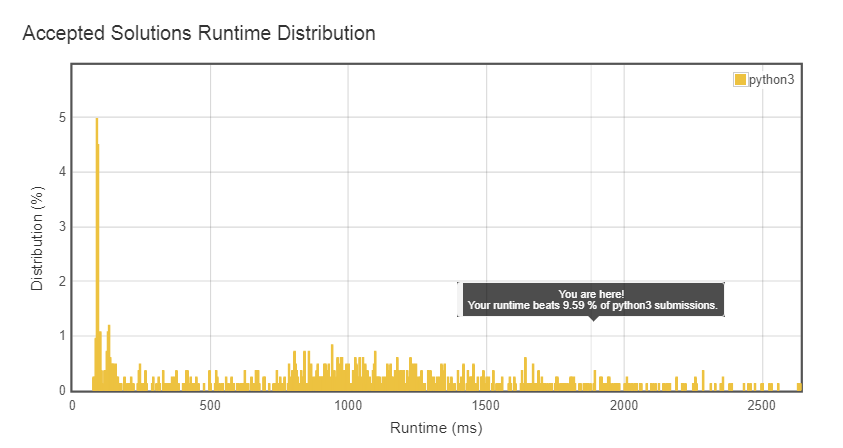
Fui informado "Tempo de execução: 2504 ms, mais rápido que 1,55% dos envios online do Python3 para correspondência de caracteres curinga".
Eu aviso, mais ainda há um fluxo de pensamentos on-line.
1 Regular?
Talvez aqui esteja a opção de escrever um programa mais rápido, simplesmente usando uma expressão regular.
Obviamente, o python pode criar um objeto de expressão regular que verificará a linha de entrada e funcionará exatamente na caixa de areia do site para testar programas.
Basta importar re , eu posso importar esse módulo, é interessante, eu tenho que tentar.
Não é fácil entender que criar uma solução rápida não é fácil. Teremos que pesquisar, tentar criar uma implementação semelhante a esta:
1. faça um objeto dessa regularidade,
2. entregar a ela um modelo corrigido pelas regras das regras da biblioteca selecionada,
3. Compare e a resposta está pronta
Voila:
import re def isMatch(s,p): return re.match(s,pat_format(p))!=None def pat_format(pat): res="" for ch in pat: if ch=='*':res+="(.)*" if ch=='?':res+="." else: res+=ch return res
Aqui está uma solução muito curta, como se estivesse correta.
Estou tentando executar, mas não estava aqui, não está totalmente certo, alguma opção não se encaixa. Você precisa testar a conversão no modelo.
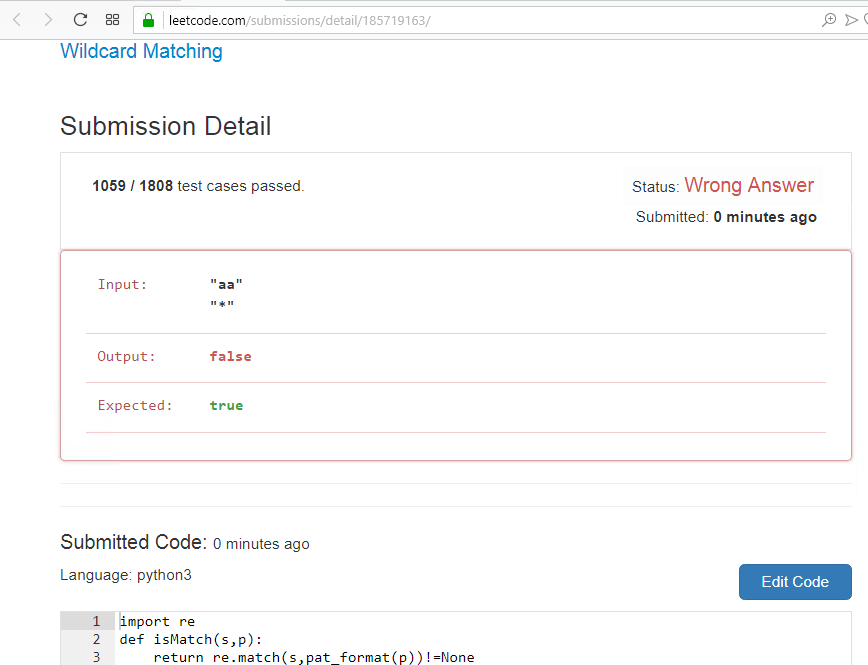
A verdade é engraçada, misturei o modelo e a string, mas a solução veio junto, passei em 1058 testes e falhei, só aqui.
Repito mais uma vez, neste site eles estão trabalhando com cuidado nos testes, como aconteceu, todos os anteriores são bons, mas aqui dois parâmetros principais são misturados e isso apareceu, aqui estão as vantagens do TDD ...
E em um texto tão maravilhoso, ainda recebo um erro
import re def isMatch(s,p): return re.match(pat_format(p),s)==None def pat_format(pat): res="" for ch in pat: if ch=='*':res+="(.)*" else: if ch=='?':res+="." else:res+=ch return res
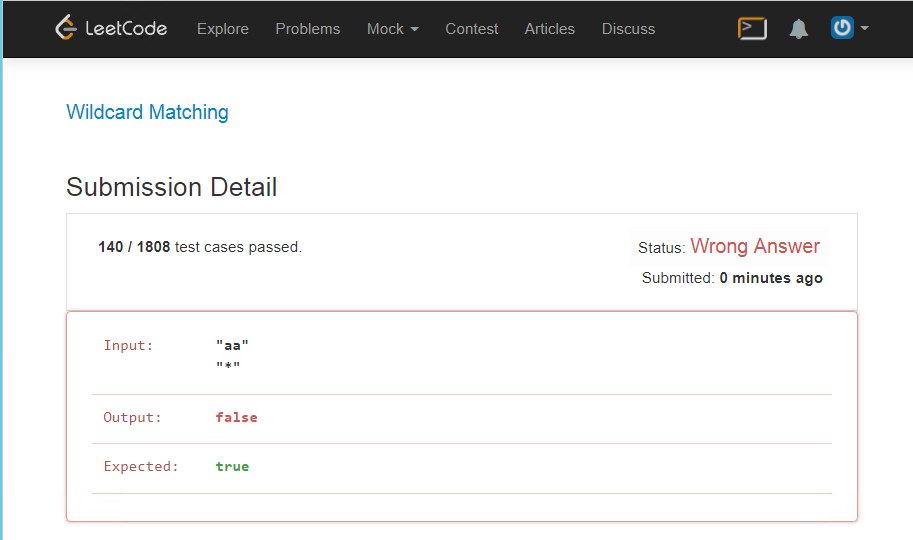
Difícil
Parece que esta tarefa foi especialmente sobreposta a testes, para que aqueles que desejam usar expressões regulares tenham mais dificuldades, eu tinha antes desta solução, não havia erros lógicos no programa, mas aqui temos que levar em consideração muitas coisas.
Portanto, a expressão regular corresponde e o primeiro resultado deve ser igual à nossa linha.
Vitória
Não foi fácil fazê-lo usar a expressão regular, mas a tentativa falhou, não é uma decisão tão simples de fazer quimicamente os regulares. A primeira solução de pesquisa funcionou mais rapidamente.
Aqui está essa implementação,
import re def isMatch(s,p): res=re.match(pat_format(p),s) if res is None: return False else: return res.group(0)==s def pat_format(pat): res="" for ch in pat: if ch=='*':res+="(.)*" else: if ch=='?':res+="." else:res+=ch return res
leva a isso:
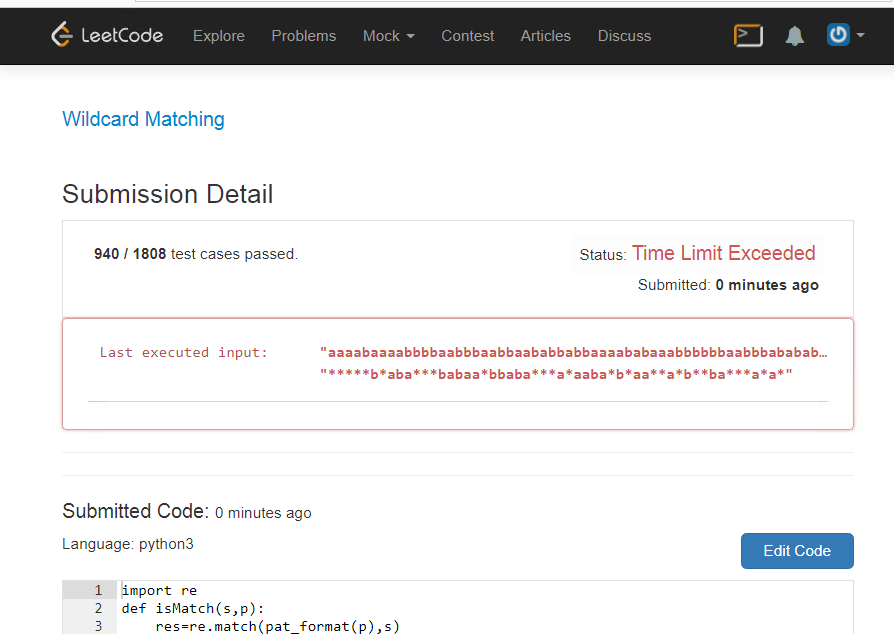
Recurso
Caros residentes, tente verificar isso, e ele faz do python três , ele não pode concluir rapidamente esta tarefa:
import re def isMatch(s,p): res=re.match(pat_format(p),s) if res is None: return False else: return res[0]==s def pat_format(pat): res="" for ch in pat: if ch=='*':res+="(.)*" else: if ch=='?':res+="." else:res+=ch return res "***** b * aba *** babaa * bbaba *** a * aaba * b * aa ** a * b ** ba *** a * a *") import re def isMatch(s,p): res=re.match(pat_format(p),s) if res is None: return False else: return res[0]==s def pat_format(pat): res="" for ch in pat: if ch=='*':res+="(.)*" else: if ch=='?':res+="." else:res+=ch return res
Você pode experimentá-lo em casa. Milagres, não demora muito para resolver, congela, oooh.
As expressões regulares são um subconjunto da aparência declarativa enfraquecida no desempenho?
A afirmação é estranha, eles estão presentes em todas as linguagens da moda; portanto, a produtividade deve ser impressionante, mas aqui não é realista que não exista uma máquina de estados finitos ?, o que acontece em um ciclo interminável?
Go
Eu li em um livro, mas foi há muito tempo ... A linguagem mais recente do Go funciona muito rapidamente, mas e a expressão regular?
Vou testá-lo:
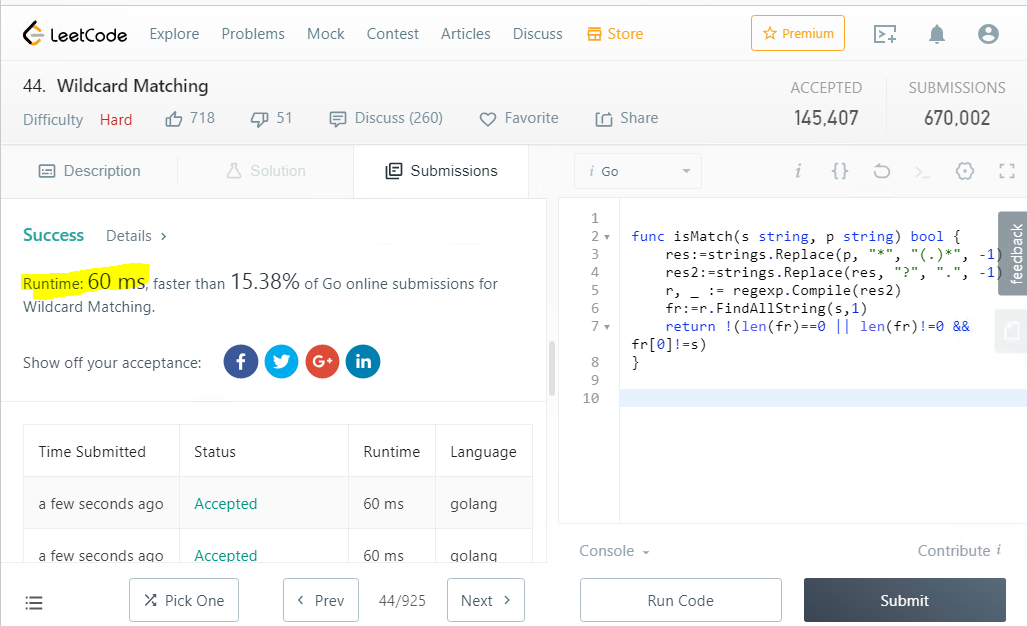
func isMatch(s string, p string) bool { res:=strings.Replace(p, "*", "(.)*", -1) res2:=strings.Replace(res, "?", ".", -1) r, _ := regexp.Compile(res2) fr:=r.FindAllString(s,1) return !(len(fr)==0 || len(fr)!=0 && fr[0]!=s) }
Eu admito, não foi fácil obter um texto tão conciso, a sintaxe não é trivial, mesmo com o conhecimento de si, não é fácil descobrir isso ...
Esse é um resultado maravilhoso, a velocidade realmente cai, totalizando ~ 60 milissegundos, mas é surpreendente que essa solução seja mais rápida que apenas 15% das respostas no mesmo site.
E onde está o prólogo
Acho que essa linguagem esquecida para trabalhar com expressões regulares nos fornece uma biblioteca baseada na Expressão Regular Compatível com Perl.
É assim que pode ser implementado, mas pré-processe a sequência de modelos com um predicado separado.
pat([],[]). pat(['*'|T],['.*'|Tpat]):-pat(T,Tpat),!. pat(['?'|T],['.'|Tpat]):-pat(T,Tpat),!. pat([Ch|T],[Ch|Tpat]):-pat(T,Tpat). isMatch(S,P):- atom_chars(P,Pstr),pat(Pstr,PatStr),!, atomics_to_string(PatStr,Pat), term_string(S,Str), re_matchsub(Pat, Str, re_match{0:Str},[bol(true),anchored(true)]).
E o tempo de execução é bom:
isMatch(aa,a)->ok:0.08794403076171875/sec isMatch(aa,*)->ok:0.0/sec isMatch(cb,?a)->ok:0.0/sec isMatch(adceb,*a*b)->ok:0.0/sec isMatch(acdcb,a*c?b)->ok:0.0/sec isMatch(aab,c*a*b)->ok:0.0/sec isMatch(mississippi,m??*ss*?i*pi)->ok:0.0/sec isMatch(abefcdgiescdfimde,ab*cd?i*de)->ok:0.0/sec isMatch(zacabz,*a?b*)->ok:0.0/sec isMatch(leetcode,*e*t?d*)->ok:0.0009980201721191406/sec isMatch(aaaa,***a)->ok:0.0/sec isMatch(b,*?*?*)->ok:0.0/sec isMatch(aaabababaaabaababbbaaaabbbbbbabbbbabbbabbaabbababab,*ab***ba**b*b*aaab*b)->ok:0.26383304595947266/sec isMatch(abbbbbbbaabbabaabaa,*****a*ab)->ok:0.0009961128234863281/sec isMatch(babaaababaabababbbbbbaabaabbabababbaababbaaabbbaaab,***bba**a*bbba**aab**b)->ok:0.20287489891052246/sec
MAS, existem algumas limitações, o próximo teste trouxe:
Not enough resources: match_limit Goal (directive) failed: user:assert_are_equal(isMatch(aaaabaaaabbbbaabbbaabbaababbabbaaaababaaabbbbbbaabbbabababbaaabaabaaaaaabbaabbbbaababbababaabbbaababbbba,'*****b*aba***babaa*bbaba***a*aaba*b*aa**a*b**ba***a*a*'),false)
Como conclusão
Restavam apenas perguntas. Tudo pode ser implementado, mas a velocidade é péssima.
Soluções transparentes não são eficazes?
Alguém implementou expressões regulares declarativas, que tipo de mecanismos existem?
E como você gosta desses desafios, existe um problema que pode ser resolvido, mas onde está a solução perfeita?