Experimentando melhorias para o
modelo de previsão do
Guess.js. , comecei a examinar de perto o aprendizado profundo: redes neurais recorrentes (RNNs), em particular LSTMs, devido à sua
"eficácia irracional" na área em que o Guess.js. trabalha. Ao mesmo tempo, comecei a brincar com redes neurais convolucionais (CNNs), que também são frequentemente usadas para séries temporais. As CNNs são comumente usadas para classificar, reconhecer e detectar imagens.
 Gerenciando o MK.js com o TensorFlow.js
Gerenciando o MK.js com o TensorFlow.jsO código fonte deste artigo e do MK.js estão no meu GitHub . Não publiquei um conjunto de dados de treinamento, mas você pode criar seu próprio e treinar o modelo conforme descrito abaixo!
Depois de jogar na CNN, lembrei-me de um
experimento que conduzi há vários anos quando os desenvolvedores de navegadores lançaram a API
getUserMedia . Nele, a câmera do usuário serviu como um controlador para reproduzir o pequeno clone JavaScript do Mortal Kombat 3. Você pode encontrar esse jogo no
repositório do GitHub . Como parte do experimento, implementei um algoritmo de posicionamento básico que classifica a imagem nas seguintes classes:
- Soco esquerdo ou direito
- Chute esquerdo ou direito
- Passos à esquerda e à direita
- Agachamento
- Nenhuma das opções acima
O algoritmo é tão simples que eu posso explicar em algumas frases:
O algoritmo fotografa o plano de fundo. Assim que o usuário aparece no quadro, o algoritmo calcula a diferença entre o plano de fundo e o quadro atual com o usuário. Portanto, determina a posição da figura do usuário. O próximo passo é exibir o corpo do usuário em branco ou preto. Depois disso, são construídos histogramas verticais e horizontais, somando os valores para cada pixel. Com base nesse cálculo, o algoritmo determina a posição atual do corpo.
O vídeo mostra como o programa funciona. Código fonte do
GitHub .
Embora o pequeno clone MK tenha funcionado com sucesso, o algoritmo está longe de ser perfeito. É necessária uma moldura com fundo. Para uma operação adequada, o plano de fundo deve ter a mesma cor durante a execução do programa. Essa limitação significa que mudanças na luz, sombra e outras coisas interferem e dão um resultado impreciso. Finalmente, o algoritmo não reconhece a ação; ele apenas classifica o novo quadro como a posição do corpo a partir de um conjunto predefinido.
Agora, graças ao progresso na API da web, ou seja, WebGL, decidi voltar a esta tarefa aplicando o TensorFlow.js.
1. Introdução
Neste artigo, compartilharei minha experiência na criação de um algoritmo para classificar posições corporais usando o TensorFlow.js e o MobileNet. Considere os seguintes tópicos:
- Coleta de dados de treinamento para classificação de imagens
- Aumento de dados com imgaug
- Transfira o aprendizado com o MobileNet
- Classificação binária e classificação N-primária
- Treinando o modelo de classificação de imagem TensorFlow.js no Node.js e usando-o em um navegador
- Algumas palavras sobre a classificação de ações com LSTM
Neste artigo, reduziremos o problema para determinar a posição do corpo com base em um quadro, em contraste com o reconhecimento de ações por uma sequência de quadros. Desenvolveremos um modelo de aprendizado profundo com um professor que, com base na imagem da webcam do usuário, determina os movimentos de uma pessoa: chute, perna ou nada disso.
Até o final do artigo, poderemos criar um modelo para jogar o
MK.js :

Para uma melhor compreensão do artigo, o leitor deve estar familiarizado com os conceitos fundamentais de programação e JavaScript. Um entendimento básico da aprendizagem profunda também é útil, mas não necessário.
Coleta de dados
A precisão do modelo de aprendizado profundo depende muito da qualidade dos dados. Precisamos nos esforçar para coletar um extenso conjunto de dados, como na produção.
Nosso modelo deve ser capaz de reconhecer socos e chutes. Isso significa que devemos coletar imagens de três categorias:
Nesta experiência, dois voluntários (
@lili_vs e
@gsamokovarov ) me ajudaram a coletar fotos. Gravamos 5 vídeos do QuickTime no meu MacBook Pro, cada um contendo 2-4 chutes e 2-4 chutes.
Em seguida, usamos o ffmpeg para extrair quadros individuais dos vídeos e salvá-los como imagens
jpg :
ffmpeg -i video.mov $filename%03d.jpgPara executar o comando acima, você primeiro precisa
instalar o ffmpeg no computador.
Se quisermos treinar o modelo, devemos fornecer os dados de entrada e os dados de saída correspondentes, mas, neste estágio, temos apenas um monte de imagens de três pessoas em poses diferentes. Para estruturar os dados, você precisa classificar os quadros em três categorias: socos, chutes e outros. Para cada categoria, um diretório separado é criado onde todas as imagens correspondentes são movidas.
Assim, em cada diretório deve haver cerca de 200 imagens semelhantes às abaixo:

Observe que haverá muito mais imagens no diretório Outros, porque relativamente poucos quadros contêm fotos de socos e pontapés, e nos quadros restantes as pessoas andam, viram ou controlam o vídeo. Se tivermos muitas imagens de uma classe, corremos o risco de ensinar o modelo tendencioso a essa classe em particular. Nesse caso, ao classificar uma imagem com impacto, a rede neural ainda pode determinar a classe “Outro”. Para reduzir esse viés, você pode remover algumas fotos do diretório Outros e treinar o modelo em um número igual de imagens de cada categoria.
Por conveniência, atribuímos os números nos números de catálogos de
1 a
190 , para que a primeira imagem seja
1.jpg , a segunda
2.jpg , etc.
Se treinarmos o modelo em apenas 600 fotografias tiradas no mesmo ambiente e com as mesmas pessoas, não obteremos um nível muito alto de precisão. Para aproveitar ao máximo nossos dados, é melhor gerar algumas amostras extras usando o aumento de dados.
Aumento de Dados
O aumento de dados é uma técnica que aumenta o número de pontos de dados sintetizando novos pontos de um conjunto existente. Normalmente, o aumento é usado para aumentar o tamanho e a diversidade do conjunto de treinamento. Transferimos as imagens originais para o pipeline de transformações que criam novas imagens. Você não pode abordar as transformações com muita agressividade: apenas outros socos de mão devem ser gerados a partir de um soco.
As transformações aceitáveis são rotação, inversão de cores, desfoque, etc. Existem excelentes ferramentas de código aberto para aumento de dados. No momento em que escrevi este artigo em JavaScript, não havia muitas opções, então usei a biblioteca implementada no Python -
imgaug . Possui um conjunto de aumentadores que podem ser aplicados probabilisticamente.
Aqui está a lógica de aumento de dados para esta experiência:
np.random.seed(44) ia.seed(44) def main(): for i in range(1, 191): draw_single_sequential_images(str(i), "others", "others-aug") for i in range(1, 191): draw_single_sequential_images(str(i), "hits", "hits-aug") for i in range(1, 191): draw_single_sequential_images(str(i), "kicks", "kicks-aug") def draw_single_sequential_images(filename, path, aug_path): image = misc.imresize(ndimage.imread(path + "/" + filename + ".jpg"), (56, 100)) sometimes = lambda aug: iaa.Sometimes(0.5, aug) seq = iaa.Sequential( [ iaa.Fliplr(0.5),
Este script usa o método
main com três
for loops - um para cada categoria de imagem. Em cada iteração, em cada um dos loops, chamamos o método
draw_single_sequential_images : o primeiro argumento é o nome do arquivo, o segundo é o caminho, o terceiro é o diretório em que o resultado será salvo.
Depois disso, lemos a imagem do disco e aplicamos uma série de transformações. Eu documentei a maioria das transformações no trecho de código acima, portanto não o repetiremos.
Para cada imagem, outras 16 imagens são criadas. Aqui está um exemplo de como eles se parecem:

Observe que, no script acima, dimensionamos imagens para
100x56 pixels. Fazemos isso para reduzir a quantidade de dados e, consequentemente, o número de cálculos que nosso modelo executa durante o treinamento e a avaliação.
Construção de modelo
Agora construa um modelo para classificação!
Como estamos lidando com imagens, usamos uma rede neural convolucional (CNN). Essa arquitetura de rede é conhecida por ser adequada para reconhecimento de imagens, detecção de objetos e classificação.
Transferência de Aprendizado
A imagem abaixo mostra o popular CNN VGG-16, usado para classificar imagens.
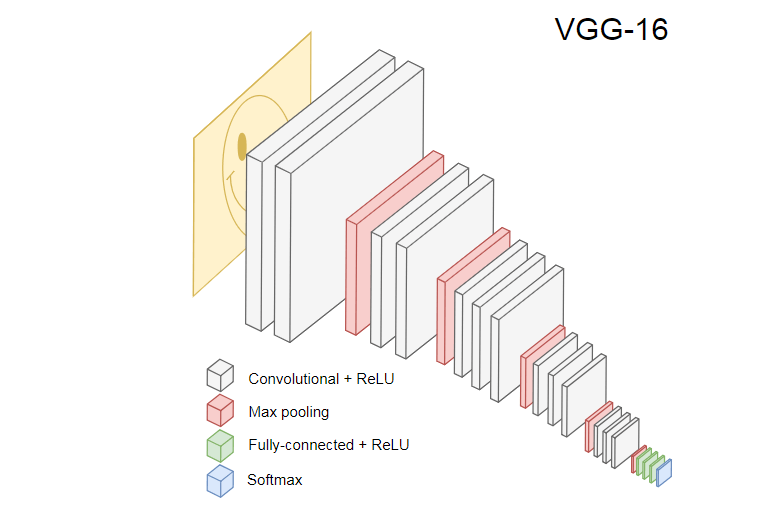
A Rede Neural VGG-16 reconhece 1000 classes de imagens. Possui 16 camadas (sem contar as camadas de pool e saída). Essa rede multicamada é difícil de treinar na prática. Isso exigirá um grande conjunto de dados e muitas horas de treinamento.
As camadas ocultas da CNN treinada reconhecem vários elementos das imagens do conjunto de treinamento, começando pelas bordas, passando para elementos mais complexos, como formas, objetos individuais e assim por diante. Uma CNN treinada no estilo do VGG-16 para reconhecer um grande conjunto de imagens deve ter camadas ocultas que aprenderam muitos recursos do conjunto de treinamento. Esses recursos serão comuns à maioria das imagens e, consequentemente, reutilizados em diferentes tarefas.
A transferência de aprendizado permite reutilizar uma rede existente e treinada. Podemos pegar a saída de qualquer uma das camadas da rede existente e transferi-la como entrada para a nova rede neural. Assim, ensinando a rede neural recém-criada, com o tempo, ela pode ser ensinada a reconhecer novos recursos de um nível superior e a classificar corretamente imagens de classes que o modelo original nunca havia visto antes.
Para nossos propósitos, use a rede neural
MobileNet do pacote @ tensorflow-models / mobilenet . O MobileNet é tão poderoso quanto o VGG-16, mas é muito menor, o que acelera a distribuição direta, ou seja, a propagação de rede (propagação direta) e reduz o tempo de download no navegador. A MobileNet treinou no
conjunto de dados de classificação de imagem
ILSVRC-2012-CLS .
Ao desenvolver um modelo com uma transferência de aprendizado, temos duas opções:
- A saída da qual camada do modelo de origem usar como entrada para o modelo de destino.
- Quantas camadas do modelo de destino vamos treinar, se houver.
O primeiro ponto é muito significativo. Dependendo da camada selecionada, obteremos recursos em um nível mais baixo ou mais alto de abstração como entrada para nossa rede neural.
Não vamos treinar nenhuma camada do MobileNet.
global_average_pooling2d_1 saída de
global_average_pooling2d_1 e a passamos como entrada para o nosso pequeno modelo. Por que eu escolhi essa camada em particular? Empiricamente. Fiz alguns testes e essa camada funciona muito bem.
Definição do modelo
A tarefa inicial era classificar a imagem em três classes: mão, pé e outros movimentos. Primeiro, vamos resolver o problema menor: determinaremos se há um golpe de mão no quadro ou não. Este é um problema típico de classificação binária. Para esse fim, podemos definir o seguinte modelo:
import * as tf from '@tensorflow/tfjs'; const model = tf.sequential(); model.add(tf.layers.inputLayer({ inputShape: [1024] })); model.add(tf.layers.dense({ units: 1024, activation: 'relu' })); model.add(tf.layers.dense({ units: 1, activation: 'sigmoid' })); model.compile({ optimizer: tf.train.adam(1e-6), loss: tf.losses.sigmoidCrossEntropy, metrics: ['accuracy'] });
Esse código define um modelo simples, uma camada com
1024 unidades e ativação da
ReLU , bem como uma unidade de saída que passa pela
sigmoid ativação
sigmoid . Este último fornece um número de
0 a
1 , dependendo da probabilidade de um golpe de mão nesse quadro.
Por que escolhi
1024 unidades para o segundo nível e uma velocidade de treinamento de
1e-6 ? Bem, tentei várias opções diferentes e vi que essas opções funcionam melhor. O método Spear não parece ser a melhor abordagem, mas, em grande parte, é assim que funcionam as configurações de hiperparâmetro no aprendizado profundo - com base em nossa compreensão do modelo, usamos a intuição para atualizar parâmetros ortogonais e verificar empiricamente como o modelo funciona.
O método de
compile compila as camadas juntas, preparando o modelo para treinamento e avaliação. Aqui anunciamos que queremos usar o algoritmo de otimização do
adam . Também declaramos que calcularemos a perda (perda) da entropia cruzada e indicamos que queremos avaliar a precisão do modelo. O TensorFlow.js calcula a precisão usando a fórmula:
Accuracy = (True Positives + True Negatives) / (Positives + Negatives)Se você transferir o treinamento do modelo MobileNet original, deverá primeiro fazer o download. Como não é prático treinar nosso modelo em mais de 3.000 imagens em um navegador, usaremos o Node.js e carregaremos a rede neural a partir do arquivo.
Faça o download do MobileNet
aqui . O catálogo contém o arquivo
model.json , que contém a arquitetura do modelo - camadas, ativações etc. Os arquivos restantes contêm parâmetros do modelo. Você pode carregar o modelo de um arquivo usando este código:
export const loadModel = async () => { const mn = new mobilenet.MobileNet(1, 1); mn.path = `file://PATH/TO/model.json`; await mn.load(); return (input): tf.Tensor1D => mn.infer(input, 'global_average_pooling2d_1') .reshape([1024]); };
Observe que no método
loadModel retornamos uma função que aceita um tensor unidimensional como entrada e retorna
mn.infer(input, Layer) . O método
infer leva um tensor e uma camada como argumentos. A camada determina de qual camada oculta queremos a saída. Se você abrir
model.json e
global_average_pooling2d_1 , encontrará esse nome em uma das camadas.
Agora você precisa criar um conjunto de dados para treinar o modelo. Para fazer isso, devemos passar todas as imagens pelo método
infer no MobileNet e atribuir-lhes rótulos:
1 para imagens com traços e
0 para imagens sem traços:
const punches = require('fs') .readdirSync(Punches) .filter(f => f.endsWith('.jpg')) .map(f => `${Punches}/${f}`); const others = require('fs') .readdirSync(Others) .filter(f => f.endsWith('.jpg')) .map(f => `${Others}/${f}`); const ys = tf.tensor1d( new Array(punches.length).fill(1) .concat(new Array(others.length).fill(0))); const xs: tf.Tensor2D = tf.stack( punches .map((path: string) => mobileNet(readInput(path))) .concat(others.map((path: string) => mobileNet(readInput(path)))) ) as tf.Tensor2D;
No código acima, primeiro lemos os arquivos em diretórios com e sem ocorrências. Em seguida, determinamos o tensor unidimensional que contém os rótulos de saída. Se tivermos
n imagens com traços e
m outras imagens, o tensor terá
n elementos com o valor 1 e
m elementos com o valor 0.
Em
xs infer resultados da chamada do método
infer para imagens individuais. Observe que, para cada imagem, chamamos o método
readInput . Aqui está a sua implementação:
export const readInput = img => imageToInput(readImage(img), TotalChannels); const readImage = path => jpeg.decode(fs.readFileSync(path), true); const imageToInput = image => { const values = serializeImage(image); return tf.tensor3d(values, [image.height, image.width, 3], 'int32'); }; const serializeImage = image => { const totalPixels = image.width * image.height; const result = new Int32Array(totalPixels * 3); for (let i = 0; i < totalPixels; i++) { result[i * 3 + 0] = image.data[i * 4 + 0]; result[i * 3 + 1] = image.data[i * 4 + 1]; result[i * 3 + 2] = image.data[i * 4 + 2]; } return result; };
readInput chama primeiro a função
readImage e depois delega sua chamada para
imageToInput . A função
readImage lê uma imagem do disco e decodifica jpg do buffer usando o pacote
jpeg-js . Em
imageToInput convertemos a imagem em um tensor tridimensional.
Como resultado, para cada
i de
0 a
TotalImages deve ser
ys[i] igual a
1 se
xs[i] corresponde à imagem com um hit e
0 caso contrário.
Modelo de treinamento
Agora o modelo está pronto para o treinamento! Chame o método de
fit :
await model.fit(xs, ys, { epochs: Epochs, batchSize: parseInt(((punches.length + others.length) * BatchSize).toFixed(0)), callbacks: { onBatchEnd: async (_, logs) => { console.log('Cost: %s, accuracy: %s', logs.loss.toFixed(5), logs.acc.toFixed(5)); await tf.nextFrame(); } } });
As chamadas de código acima se
fit em três argumentos:
xs , ys e o objeto de configuração. No objeto de configuração, definimos quantas Eras o modelo, o tamanho do pacote e o retorno de chamada que o TensorFlow.js gerará após o processamento de cada pacote serão treinados.
O tamanho do pacote determina
xs e
ys para treinar o modelo em uma era. Para cada era, o TensorFlow.js seleciona um subconjunto de
xs e os elementos correspondentes de
ys , executa uma distribuição direta, recebe a saída da camada com ativação
sigmoid e, com base na perda, executa a otimização usando o algoritmo
adam .
Após iniciar o script de treinamento, você verá um resultado semelhante ao abaixo:
Custo: 0,84212, precisão: 1,00000
eta = 0,3> ---------- acc = 1,00 perda = 0,84 Custo: 0,79740, precisão: 1,00000
eta = 0,2 => --------- acc = perda de 1,00 = 0,80 Custo: 0,81533, precisão: 1,00000
eta = 0,2 ==> -------- acc = 1,00 perda = 0,82 Custo: 0,64303, precisão: 0,50000
eta = 0,2 ===> ------- acc = 0,50 perda = 0,64 Custo: 0,51377, precisão: 0,00000
eta = 0,2 ====> ------ acc = 0,00 perda = 0,51 Custo: 0,46473, precisão: 0,50000
eta = 0,1 =====> ----- acc = 0,50 perda = 0,46 Custo: 0,50872, precisão: 0,00000
eta = 0,1 ======> ---- acc = 0,00 perda = 0,51 Custo: 0,62556, precisão: 1,00000
eta = 0,1 =======> --- acc = perda de 1,00 = 0,63 Custo: 0,65133, precisão: 0,50000
eta = 0,1 ========> - acc = 0,50 perda = 0,65 Custo: 0,63824, precisão: 0,50000
eta = 0,0 ===========>
293ms 14675us / etapa - acc = 0,60 perda = 0,65
Época 3/50
Custo: 0,44661, precisão: 1,00000
eta = 0,3> ---------- acc = 1,00 perda = 0,45 Custo: 0,78060, precisão: 1,00000
eta = 0,3 => --------- acc = perda de 1,00 = 0,78 Custo: 0,79208, precisão: 1,00000
eta = 0,3 ==> -------- acc = 1,00 perda = 0,79 Custo: 0,49072, precisão: 0,50000
eta = 0,2 ===> ------- acc = 0,50 perda = 0,49 Custo: 0,62232, precisão: 1,00000
eta = 0,2 ====> ------ acc = perda de 1,00 = 0,62 Custo: 0,82899, precisão: 1,00000
eta = 0,2 =====> ----- acc = 1,00 perda = 0,83 Custo: 0,67629, precisão: 0,50000
eta = 0,1 ======> ---- acc = 0,50 perda = 0,68 Custo: 0,62621, precisão: 0,50000
eta = 0,1 =======> --- acc = 0,50 perda = 0,63 Custo: 0,46077, precisão: 1,00000
eta = 0,1 ========> - acc = perda de 1,00 = 0,46 Custo: 0,62076, precisão: 1,00000
eta = 0,0 ===========>
304ms 15221us / etapa - acc = 0,85 perda = 0,63
Observe como a precisão aumenta com o tempo e a perda diminui.
No meu conjunto de dados, o modelo após o treinamento mostrou uma precisão de 92%. Lembre-se de que a precisão pode não ser muito alta devido ao pequeno conjunto de dados de treinamento.
Executando o Modelo em um Navegador
Na seção anterior, treinamos o modelo de classificação binária. Agora execute-o em um navegador e conecte-se ao
MK.js !
const video = document.getElementById('cam'); const Layer = 'global_average_pooling2d_1'; const mobilenetInfer = m => (p): tf.Tensor<tf.Rank> => m.infer(p, Layer); const canvas = document.getElementById('canvas'); const scale = document.getElementById('crop'); const ImageSize = { Width: 100, Height: 56 }; navigator.mediaDevices .getUserMedia({ video: true, audio: false }) .then(stream => { video.srcObject = stream; });
Existem várias declarações no código acima:
videocontém um link para um item HTML5 videona páginaLayer contém o nome da camada do MobileNet a partir da qual queremos obter a saída e passá-la como entrada para o nosso modelomobilenetInfer- uma função que pega uma instância do MobileNet e retorna outra função. A função retornada aceita entrada e retorna a saída correspondente da camada MobileNet especificada.canvasindica o elemento HTML5 canvasque usaremos para extrair quadros do vídeoscale- outro canvasque é usado para escalar quadros individuais
Depois disso, obtemos o fluxo de vídeo da câmera do usuário e o definimos como a fonte do elemento video.A próxima etapa é implementar um filtro em escala de cinza que aceite canvase converta seu conteúdo: const grayscale = (canvas: HTMLCanvasElement) => { const imageData = canvas.getContext('2d').getImageData(0, 0, canvas.width, canvas.height); const data = imageData.data; for (let i = 0; i < data.length; i += 4) { const avg = (data[i] + data[i + 1] + data[i + 2]) / 3; data[i] = avg; data[i + 1] = avg; data[i + 2] = avg; } canvas.getContext('2d').putImageData(imageData, 0, 0); };
Como próximo passo, conectaremos o modelo ao MK.js: let mobilenet: (p: any) => tf.Tensor<tf.Rank>; tf.loadModel('http://localhost:5000/model.json').then(model => { mobileNet .load() .then((mn: any) => mobilenet = mobilenetInfer(mn)) .then(startInterval(mobilenet, model)); });
No código acima, primeiro carregamos o modelo que treinamos acima e baixamos o MobileNet. Passamos o MobileNet para o método mobilenetInferpara calcular a saída da camada de rede oculta. Depois disso, chamamos o método startIntervalcom duas redes como argumentos. const startInterval = (mobilenet, model) => () => { setInterval(() => { canvas.getContext('2d').drawImage(video, 0, 0); grayscale(scale .getContext('2d') .drawImage( canvas, 0, 0, canvas.width, canvas.width / (ImageSize.Width / ImageSize.Height), 0, 0, ImageSize.Width, ImageSize.Height )); const [punching] = Array.from(( model.predict(mobilenet(tf.fromPixels(scale))) as tf.Tensor1D) .dataSync() as Float32Array); const detect = (window as any).Detect; if (punching >= 0.4) detect && detect.onPunch(); }, 100); };
A parte mais interessante começa no método startInterval! Primeiro, executamos um intervalo em que todos 100mschamam uma função anônima. Nele, o canvasvídeo com o quadro atual é renderizado primeiro em cima dele . Em seguida, reduzimos o tamanho do quadro 100x56e aplicamos um filtro em escala de cinza a ele.O próximo passo é transferir o quadro para o MobileNet, obter a saída da camada oculta desejada e transferi-la como entrada para o método do predictnosso modelo. Isso retorna um tensor com um elemento. Usando, dataSyncobtemos o valor do tensor e o atribuímos a uma constante punching.Finalmente, verificamos: se a probabilidade de um golpe de mão exceder 0.4, chamamos o método de onPunchobjeto global Detect. O MK.js fornece um objeto global com três métodos:onKick, onPunchE onStandque pode ser usado para controlar um dos personagens.Feito!
Aqui está o resultado!
Reconhecimento de chute e braço com classificação N
Na próxima seção, criaremos um modelo mais inteligente: uma rede neural que reconhece socos, chutes e outras imagens. Desta vez, vamos começar preparando o conjunto de treinamento: const punches = require('fs') .readdirSync(Punches) .filter(f => f.endsWith('.jpg')) .map(f => `${Punches}/${f}`); const kicks = require('fs') .readdirSync(Kicks) .filter(f => f.endsWith('.jpg')) .map(f => `${Kicks}/${f}`); const others = require('fs') .readdirSync(Others) .filter(f => f.endsWith('.jpg')) .map(f => `${Others}/${f}`); const ys = tf.tensor2d( new Array(punches.length) .fill([1, 0, 0]) .concat(new Array(kicks.length).fill([0, 1, 0])) .concat(new Array(others.length).fill([0, 0, 1])), [punches.length + kicks.length + others.length, 3] ); const xs: tf.Tensor2D = tf.stack( punches .map((path: string) => mobileNet(readInput(path))) .concat(kicks.map((path: string) => mobileNet(readInput(path)))) .concat(others.map((path: string) => mobileNet(readInput(path)))) ) as tf.Tensor2D;
Como antes, lemos primeiro os catálogos com imagens de socos à mão, pé e outras imagens. Depois disso, diferentemente da última vez, formamos o resultado esperado na forma de um tensor bidimensional, e não unidimensional. Se tivermos n imagens com um chute, m imagens com um chute ek outras imagens, o tensor ysterá nelementos com um valor [1, 0, 0], melementos com um valor [0, 1, 0]e kelementos com um valor [0, 0, 1].Um vetor de nelementos em que existem n - 1elementos com um valor 0e um elemento com um valor 1, chamamos de vetor unitário (vetor quente).Depois disso, formamos o tensor de entradaxsempilhamento da saída de cada imagem do MobileNet.Aqui você deve atualizar a definição do modelo: const model = tf.sequential(); model.add(tf.layers.inputLayer({ inputShape: [1024] })); model.add(tf.layers.dense({ units: 1024, activation: 'relu' })); model.add(tf.layers.dense({ units: 3, activation: 'softmax' })); await model.compile({ optimizer: tf.train.adam(1e-6), loss: tf.losses.sigmoidCrossEntropy, metrics: ['accuracy'] });
As únicas duas diferenças em relação ao modelo anterior são:- O número de unidades na camada de saída
- Ativações na camada de saída
Existem três unidades na camada de saída, porque temos três categorias diferentes de imagens:softmax , . ? :
00 ,
01 ,
10 . ,
softmax , 1, 00, .
500 92%! , , .
— ! , , :
const [punch, kick, nothing] = Array.from((model.predict( mobilenet(tf.fromPixels(scaled)) ) as tf.Tensor1D).dataSync() as Float32Array); const detect = (window as any).Detect; if (nothing >= 0.4) return; if (kick > punch && kick >= 0.35) { detect.onKick(); return; } if (punch > kick && punch >= 0.35) detect.onPunch();
Primeiro chamamos o MobileNet com uma moldura reduzida em tons de cinza, depois transferimos o resultado do nosso modelo treinado. O modelo retorna um tensor unidimensional, que convertemos em Float32Arrayc dataSync. Na próxima etapa, usamos Array.frompara converter uma matriz digitada em uma matriz JavaScript. Em seguida, extraímos as probabilidades de que um tiro com a mão, um chute ou nada esteja presente no quadro.Se a probabilidade do terceiro resultado exceder 0.4, retornamos. Caso contrário, se a probabilidade de um chute for maior 0.32, enviamos um comando de chute ao MK.js. Se a probabilidade de um chute for maior 0.32e maior que a probabilidade de um chute, enviaremos a ação de um chute.Em geral, é tudo! O resultado é mostrado abaixo:
Reconhecimento de ação
, , , . ? : (back kick).
, :


, :

, ?
, (RNN). , RNN :
- Processamento de linguagem natural (PNL), em que cada palavra depende de palavras anteriores e subsequentes
- Prever a próxima página com base no seu histórico de navegação
- Reconhecimento de quadros
A implementação desse modelo está além do escopo deste artigo, mas vamos examinar um exemplo de arquitetura para ter uma idéia de como tudo isso funcionará em conjunto.O poder da RNN
O diagrama abaixo mostra o modelo de reconhecimento de ações: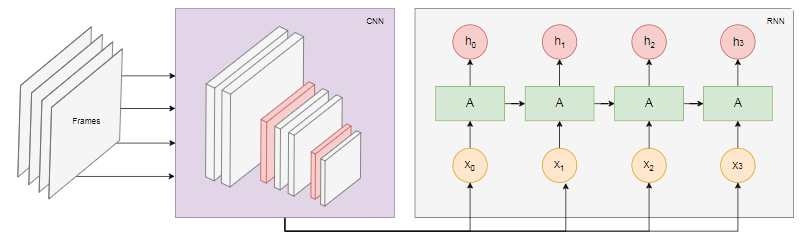 Pegamos os últimos
Pegamos os últimos nquadros do vídeo e os transferimos para a CNN. A saída CNN para cada quadro é transmitida como RNN de entrada. Uma rede neural recorrente determinará as relações entre quadros individuais e reconhecerá a que ação eles correspondem.Conclusão
Neste artigo, desenvolvemos um modelo de classificação de imagens. Para isso, coletamos um conjunto de dados: extraímos os quadros de vídeo e os dividimos manualmente em três categorias. Em seguida, os dados foram aumentados adicionando imagens usando o imgaug .Depois disso, explicamos o que é a transferência de aprendizado e usamos o modelo MobileNet treinado do pacote @ tensorflow-models / mobilenet para nossos propósitos . Carregamos o MobileNet a partir de um arquivo no processo Node.js e treinamos uma camada densa adicional na qual os dados foram alimentados a partir da camada oculta do MobileNet. Após o treinamento, alcançamos uma precisão de mais de 90%!Para usar esse modelo em um navegador, o baixamos junto com o MobileNet e começamos a categorizar os quadros da webcam do usuário a cada 100 ms. Conectamos o modelo ao jogoMK.js e usou a saída do modelo para controlar um dos caracteres.Finalmente, vimos como melhorar o modelo combinando-o com uma rede neural recorrente para reconhecer ações.Espero que você tenha gostado desse pequeno projeto, tanto quanto eu!