Meu nome é Andrey Polyakov, sou o chefe do grupo de documentação API e SDK da Yandex. Hoje, gostaria de compartilhar com você um relatório que eu e minha colega, desenvolvedora sênior de documentação Julia Pivovarova, lemos algumas semanas atrás no sexto Hyperbaton.
Svetlana Kayushina, chefe do departamento de documentação e localização:
- Os volumes de código de programa no mundo nos últimos anos cresceram significativamente, continuam a crescer, e isso afeta o trabalho de redatores técnicos, que enfrentam cada vez mais tarefas no desenvolvimento de documentação e código de documentação de programas. Não pudemos ignorar esse tópico, dedicamos uma seção inteira a ele. Estes são três relatórios relacionados à unificação do desenvolvimento de software. Convido nossos especialistas em documentação de interfaces e bibliotecas de software para Andrei Polyakov e Julia Pivovarova. Eu dou a eles a palavra.
- Olá pessoal! Hoje, Julia e eu contaremos como, no Yandex, tivemos uma nova visão da documentação da API e do SDK. O relatório será composto de quatro partes: o relatório de observação, discutiremos, conversaremos.
Vamos falar sobre a unificação da API e do SDK, como chegamos a isso, o que fizemos lá. Compartilharemos a experiência do uso de um gerador universal, um para todos os idiomas, e informaremos por que ele não nos convinha, quais foram as armadilhas e por que mudamos para a geração de documentação por geradores nativos.
No final, descreveremos como nossos processos foram construídos.
Vamos começar com a unificação. Todo mundo pensa em unificação quando há mais de duas pessoas em uma equipe: todo mundo escreve de maneira diferente, todo mundo tem suas próprias abordagens, e isso é lógico. É melhor discutir todas as regras na praia antes de começar a escrever a documentação, mas nem todos podem fazer isso.
Reunimos um grupo de especialistas para analisar nossa documentação. Fizemos isso para sistematizar nossas abordagens. Todo mundo escreve de maneiras diferentes, e vamos concordar em escrever no mesmo estilo. Esse é o segundo ponto, para o qual tentaríamos tornar a documentação uniforme, para que o usuário tivesse uma experiência em toda a documentação do Yandex, a saber, técnica.
O trabalho foi dividido em três etapas. Compilamos uma descrição das tecnologias que usamos no Yandex, tentamos destacar aquelas que podemos de alguma forma unificar. E também compôs a estrutura geral de documentos e modelos padrão.

Vamos seguir para a descrição das tecnologias. Começamos a estudar quais tecnologias são usadas no Yandex. Existem tantos que estamos cansados de anotá-los em algum tipo de caderno e, como resultado, selecionamos apenas os mais básicos mais usados, que os escritores técnicos costumam encontrar, e começamos a descrevê-los.
O que se entende por descrição da tecnologia? Identificamos os principais pontos e a essência de cada tecnologia. Se falamos sobre linguagens de programação, essa é uma descrição de entidades como classe, propriedade, interfaces etc. Se falamos de protocolos, descrevemos métodos HTTP, falamos sobre o formato do código de erro, código de resposta, etc. um glossário que contém os seguintes itens: termos em russo, termos em inglês, nuances de uso. Por exemplo, não estamos falando de nenhum método SDK, que permita que você faça algo. Ele faz alguma coisa, se o programador puxa uma caneta, ela dá alguma resposta.
Além das nuances, a descrição também continha estruturas padrão, rotações de fala padrão, que usamos na documentação para que o redator técnico possa usar uma redação específica e usá-la ainda mais.
Além disso, os escritores técnicos geralmente escrevem trechos de código, trechos, amostras e, para isso, também descrevemos nosso guia de estilo para cada tecnologia. Voltamos aos guias do desenvolvedor que estão no Yandex. Prestamos atenção ao código do design, descrição dos comentários, indentação e tudo mais. Fazemos isso para que, quando um escritor técnico forneça um pedaço de código ou uma amostra escrita a um programador, o programador analise a essência, e não a maneira como ela foi projetada, e isso reduz o tempo. E quando um escritor técnico pode escrever nos guias de estilo Yandex, é muito legal, talvez ele queira se tornar um programador mais tarde. O relatório anterior era sobre vários exames. Por exemplo, você pode mudar para programadores.
Também desenvolvemos um começo rápido para escritores de tecnologia: como configurar um ambiente de desenvolvimento quando ele se familiarizar com as novas tecnologias. Por exemplo, se o escritor técnico SDK é escrito em C #, ele vem, configura o ambiente de desenvolvimento, lê manuais, familiariza-se com a terminologia. Também deixamos links para a documentação oficial e a RFC, se houver. Criamos um ponto de entrada para escritores técnicos, e é algo parecido com isto.
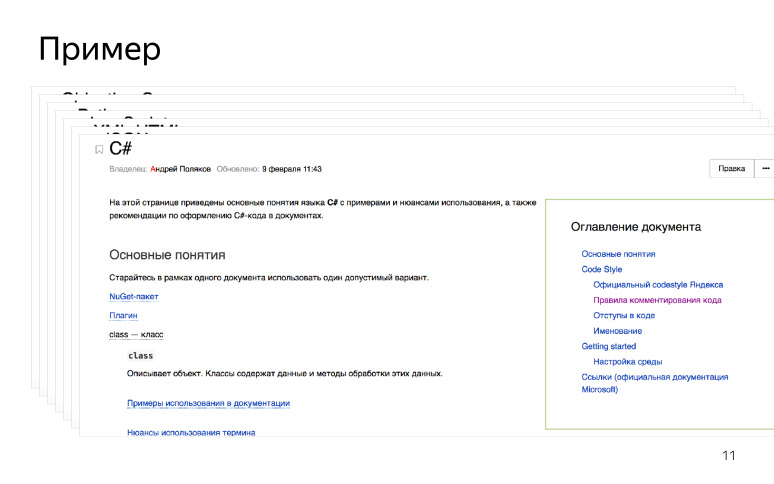
Quando um escritor técnico chega, ele aprende uma nova tecnologia e começa a documentá-la.
Depois de descrevermos as tecnologias, descrevemos a estrutura da API HTTP.
Temos muitas APIs HTTP diferentes e todas são descritas de maneira diferente. Vamos fazer um acordo e fazer o mesmo!
Identificamos as principais seções que estarão em cada API HTTP:

“Visão geral” ou “Introdução”: por que essa API é necessária, o que ela permite, qual host deve ser acessado para obter algum tipo de resposta.
"Início rápido" quando uma pessoa passa por algumas etapas e obtém um resultado bem-sucedido no final para entender como essa API funciona.
"Conexão / Autorização". Muitas APIs exigem um token de autorização ou chave de API. Este é um ponto importante, por isso decidimos que essa é uma parte obrigatória de todas as APIs.
"Limitações / limites" quando falamos de limites no número de solicitações ou no tamanho do corpo da solicitação, etc.
"Referência", referência. Uma parte muito grande, que contém todos os manipuladores HTTP que o usuário pode obter e obter algum tipo de resultado.
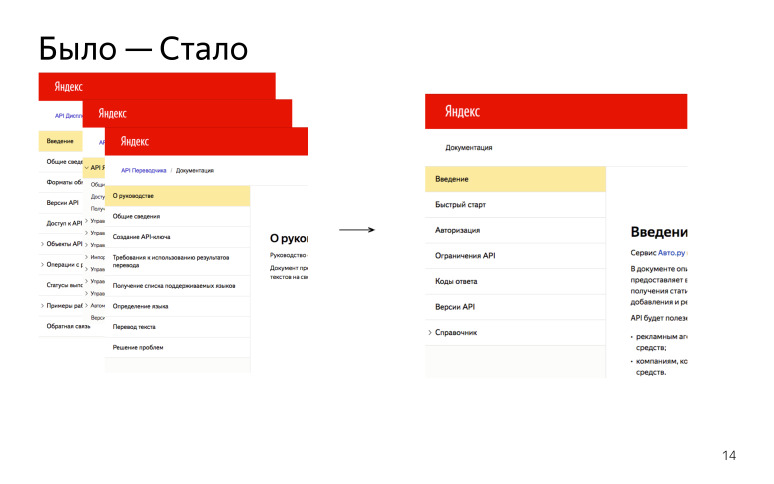
Como resultado, tínhamos muitas APIs diferentes, elas foram descritas de maneira diferente, agora tentamos escrever tudo da mesma maneira. Que lucro.
Indo profundamente nos diretórios, percebemos que o identificador HTTP é quase sempre o mesmo. Você puxa, ou seja, faz uma solicitação, o servidor retorna uma resposta - voila. Vamos tentar unificá-lo. Nós escrevemos um modelo que tentou cobrir todos os casos. O redator técnico pega o modelo e, se ele tiver uma solicitação PUT, ele deixa as partes necessárias no modelo. Se ele tiver uma solicitação GET, ele usará apenas as partes necessárias para a solicitação GET. Um modelo comum para todas as solicitações que podem ser reutilizadas. Agora você não precisa criar uma estrutura de documento a partir do zero, mas pode usar um modelo pronto.

Cada caneta descreve para que serve e para que serve. Há uma seção "Formato de solicitação", que contém parâmetros de caminho, parâmetros de consulta, tudo o que vem no corpo da solicitação, se for enviado. Também destacamos a seção “Formato da resposta”: escrevemos se houver um corpo de resposta. Como uma seção separada, destacamos “Códigos de resposta”, porque a resposta do servidor vem independentemente do corpo. E saiu da seção "Exemplo". Se fornecermos algum tipo de SDK com essa API, dizemos que use esse SDK assim, puxe essa alça, chame esse método. Geralmente deixamos algum tipo de exemplo cURL em que o usuário simplesmente insere seu token. E se tivermos uma bancada de testes, ela apenas pega a solicitação e a executa. E obtém algum tipo de resultado.

Acontece que havia muitas canetas, elas foram descritas de maneiras diferentes, e agora queremos trazer tudo para uma única forma.
Depois que terminamos com a API HTTP, passamos para o SDK móvel.
Existe uma estrutura geral de documentos, é aproximadamente a mesma:
- "Introdução", onde dizemos que, aqui, este SDK é usado para tais fins, integra-o para si mesmo para tais fins, é adequado para esses sistemas operacionais, temos tais e tais versões, etc.
- "Conexão". Ao contrário da API HTTP, não estamos falando apenas sobre como obter a chave para usar o SDK; se você precisar, estamos falando sobre como integrar a biblioteca ao nosso projeto.
- "Exemplos de uso". A maior seção de volume. Na maioria das vezes, os desenvolvedores querem acessar a documentação e não ler muitas informações, querem copiar um pedaço, colá-lo para si e tudo dará certo. Portanto, consideramos essa parte muito importante e a alocamos na seção obrigatória.

- “Diretório”, referência, mas, diferentemente da referência da API HTTP, não podemos unificar tudo aqui, pois geramos principalmente diretórios e falaremos sobre isso mais adiante no relatório.
- "Lançamentos" ou histórico de alterações, changelog. Os SDKs para dispositivos móveis geralmente têm um ciclo de lançamento curto, uma nova versão é lançada a cada duas semanas. E seria melhor para o usuário falar sobre o que mudou, vale a pena atualizar ou não.
Ao mesmo tempo, a API possui as seções necessárias que vemos e as seções que recomendamos usar. Se a API for atualizada com frequência, dizemos que você também deve inserir o histórico de alterações, que foi alterado na API. E muitas vezes nossas APIs raramente são atualizadas, e não faz sentido indicar isso como uma seção obrigatória.

Portanto, tínhamos muitos SDKs que foram descritos de maneiras diferentes, tentamos transformá-los aproximadamente no mesmo estilo. Naturalmente, existem diferenças adicionais inerentes apenas a este SDK ou a esta API HTTP. Aqui temos a liberdade de escolha. Não estamos dizendo que, além dessas seções, ninguém pode ser feito. Obviamente, é possível, simplesmente tentamos fazer as seções listadas em todos os lugares, para que fique claro que, se o usuário mudar para outro SDK na documentação, ele saberá o que será descrito na seção "Conexão".
Então, criamos modelos, guias elaborados, qual é o nosso plano de ação agora? Decidimos que, se escalarmos a API, mudarmos as canetas ou o SDK, adotamos novos modelos, adotamos uma nova estrutura e começamos a trabalhar nela.
Se escrevermos a documentação do zero, é claro que novamente adotamos uma nova estrutura, pegamos novos modelos e trabalhamos neles.
E se a API estiver desatualizada, raramente atualizada, ou ninguém a suportar, mas ela existir, refaça-a um pouco intensivamente em recursos. Apenas decidimos deixar como estava, mas quando os recursos aparecerem, definitivamente retornaremos a eles, faremos tudo isso de maneira bem e bonita.
Quais são os benefícios da unificação? Eles devem ser óbvios para todos:
"UX", estamos pensando em fazer o usuário se sentir em casa em nossa documentação. Ele veio e sabe o que está descrito nas seções onde pode encontrar autorização, exemplos de uso, descrição da caneta. Isso é ótimo.
Para os escritores de tecnologia, a descrição da tecnologia permite determinar um determinado ponto de entrada de onde ele vem e começa a se familiarizar com essa tecnologia, se ele não a conhecia, começa a entender a terminologia, mergulhando nela.
O próximo ponto é a intercambiabilidade. Se o redator de tecnologia saiu de férias ou simplesmente parou de escrever, outro redator de tecnologia, ao entrar no documento, sabe como ele funciona por dentro. Fica claro imediatamente o que está descrito na conexão, onde procurar informações sobre a integração do SDK. Compreender e fazer uma pequena revisão em um documento fica mais fácil. É claro que cada projeto tem suas próprias especificidades, você não pode simplesmente vir e documentar um projeto sem conhecê-lo completamente. Mas, ao mesmo tempo, a estrutura, isto é, a navegação de arquivos, será aproximadamente a mesma.
E, claro, terminologia geral. Essa terminologia que compilamos para idiomas, concordamos com os desenvolvedores e tradutores. Dizemos que temos C #, existe esse termo, usamos assim. Perguntamos aos desenvolvedores qual terminologia eles usavam e queriam alcançar a sincronização neste local. Temos acordos e, da próxima vez que apresentarmos a documentação, os desenvolvedores sabem que concordamos com os termos e guias com eles, usamos esses modelos e levamos em conta as nuances de seu uso. E os tradutores, por sua vez, sabem que descrevemos o SDK em C # ou Objective-C, portanto, essa terminologia corresponderá ao que está descrito no guia.
Os guias foram escritos em páginas wiki, portanto, se idiomas, tecnologias e protocolos forem atualizados, tudo isso será facilmente adicionado a um documento existente. Idílio.
Quanto mais cedo você começar a unificar e concordar, melhor. É melhor que não exista legado de documentação, escrita em um estilo diferente, que interrompa o fluxo do usuário na documentação. Melhor fazer tudo antes.
Atrair desenvolvedores. Essas são as pessoas para quem você está escrevendo a documentação. Se você mesmo escreveu algum tipo de guia, talvez eles não gostem. É melhor concordar com eles para que você tenha um entendimento comum da terminologia: o que você escreve na documentação, como a escreve.
E também negociar com tradutores, todos eles precisam traduzir. Se eles forem traduzidos de maneira diferente da que os desenvolvedores estão acostumados, haverá novamente conflitos. (
Aqui está um link para um fragmento de vídeo com perguntas e respostas - aprox. Ed.) Seguimos em frente.
Julia:
Olá, meu nome é Julia, trabalho na Yandex há cinco anos e estou documentando a API e o SDK no grupo de Andrey. Geralmente todo mundo fala sobre uma boa experiência, como é ótima. Vou lhe dizer como escolhemos uma estratégia não totalmente bem-sucedida. Naquela época, parecia bem-sucedido, mas então surgiu uma dura realidade, e tivemos um pouco de azar.
Inicialmente, tínhamos vários SDKs móveis, e eles eram escritos principalmente em duas linguagens: Objective-C e Java. Escrevemos a documentação para eles manualmente. Com o tempo, as classes, protocolos e interfaces aumentaram. Havia mais e mais deles, e percebemos que precisávamos automatizar esse negócio, analisamos o que são tecnologias.
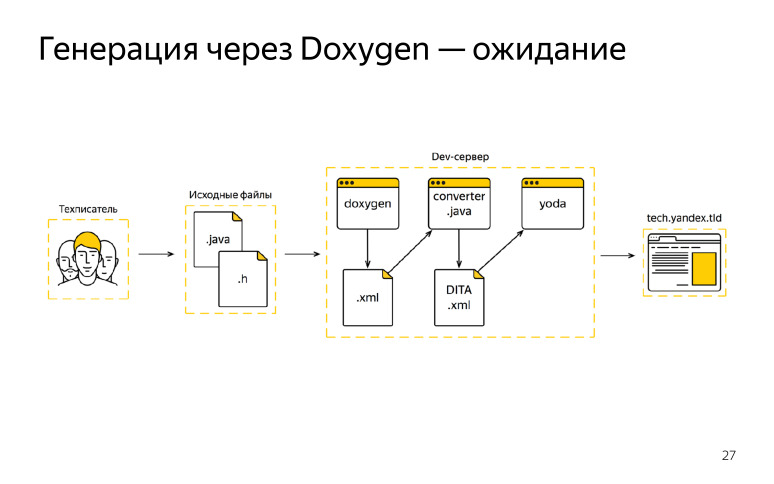
Naquela época, gostávamos do Doxygen, ele atendia às nossas necessidades, como nos parecia, e o escolhemos como um único gerador. E desenhámos esse esquema, que esperávamos obter, queríamos trabalhar de alguma forma.
O que nós tínhamos? O escritor técnico chegou ao trabalho, recebeu o código fonte do desenvolvedor, começou a escrever seus comentários, edições, depois que a documentação tinha que ser enviada ao nosso devserver, lá rodamos o Doxygen, recebemos o formato XML, mas não se encaixava no nosso padrão DITA XML. Sabíamos disso de antemão, escreveu um certo conversor.
Depois que obtivemos a saída do Doxygen, passamos tudo pelo conversor e já obtivemos nosso formato. Em seguida, o coletor de documentação foi conectado e publicamos tudo isso em um domínio externo. Tivemos até sorte em algumas iterações, tudo deu certo para nós, ficamos encantados. Mas então algo deu errado. O escritor técnico também foi trabalhar, recebeu tarefas e códigos-fonte do desenvolvedor e fez suas correções no local. Depois disso, ele foi ao devserver, lançou o Doxygen e houve um incêndio.
Decidimos descobrir qual era o problema. Então percebemos que o Doxygen não se encaixa perfeitamente em todos os idiomas. Tivemos que analisar o código, no qual ele tropeçou, encontramos construções que o Doxygen não suportava e não planejava suportar.
Decidimos que, como estamos trabalhando nesse esquema, escreveremos um script de pré-processamento e, de alguma forma, substituiremos essas construções pelo que o Doxygen aceita ou, de alguma forma, as ignoramos.

Nosso ciclo começou a ficar assim. Recebemos as fontes, as incluímos no devserver, conectamos o script de pré-processamento, cortamos todo o excesso do código e, em seguida, o Doxygen entrou no negócio, recebemos o formato de saída do Doxygen, também lançamos o conversor, também lançamos o conversor, recebemos nossos arquivos XML DITA finais e o coletor de documentação foi conectado, e Publicamos nossa documentação em um domínio externo. Parece que tudo parece bom. Adicionado um script, o que há por aí? Inicialmente, não havia nada. Havia três linhas no script, depois cinco, dez linhas, e tudo aumentou para centenas de linhas. Percebemos que começamos a gastar a maior parte do tempo não escrevendo documentação, mas analisando o código, procurando o que não é rastreado para onde e simplesmente adicionando o script a intermináveis regulares, sentando na loucura e pensando qual é o problema.
Percebemos que precisávamos mudar alguma coisa, de alguma forma parar, antes que fosse tarde demais, e até que nosso ciclo de lançamento caísse até o fim.
Como exemplo, o script de pré-processamento parecia algo assim no início e era inofensivo.

Por que escolhemos inicialmente esse caminho? Por que ele parecia bom?

Um gerador é ótimo, pegou, conectou uma vez, configurou e funcionou. Parecia uma boa abordagem. Além disso, você pode usar uma única sintaxe de comentário para todos os idiomas ao mesmo tempo. Você escreveu algum tipo de guia, use-o uma vez, insira imediatamente todas essas construções no código e faça seu trabalho, escreva comentários e de alguma forma não se fixe na sintaxe.

Mas isso acabou sendo um dos grandes desvios. Os desenvolvedores não suportam nossa sintaxe comum, estão acostumados a usar seus IDEs, já existem geradores nativos e sua sintaxe não corresponde à nossa. Este foi um obstáculo.
O Doxygen também não suportava novos recursos nos idiomas. , ++, - , . , Doxygen , .
. , Swift , Doxygen . , , - . , , . - , , . , , , . .
— , - , , , . , , , .
. . ? ( , ), , Objective-C Java, , .
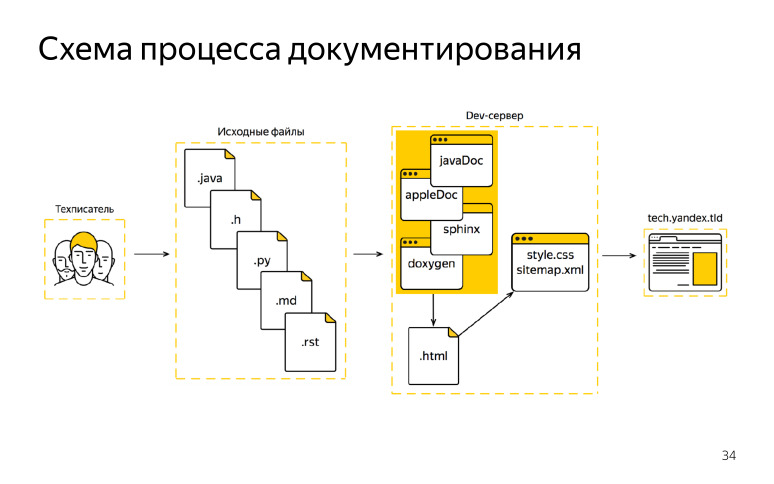
, DITA XML, , , , XML. HTML, . — JavaDoc, AppleDoc, Jazzy. HTML, . HTML, , . , HTML . , , , HTML, . XML , . .
.
— . Doxygen , , . Objective-C, , Java . . , , IDE , IntelliSense, , , , SDK, , . .
, , SDK , , , , HTML, . , , , , , .
. , - , . XML , XML . Doxygen , XML . HTML, XML . . — .
, , . 1500 , : HTML, CSS, .
, , .
. (
— . .)
, , .
— . , . -, . , . ? .
? -, , , , .
- , - , . .
? -, , , , .
. , , , , , , , .
, . , , , , , , .
? — , , , , , . . Bitbucket, - . , .

, . . - , - , , , , , , . , , , , .
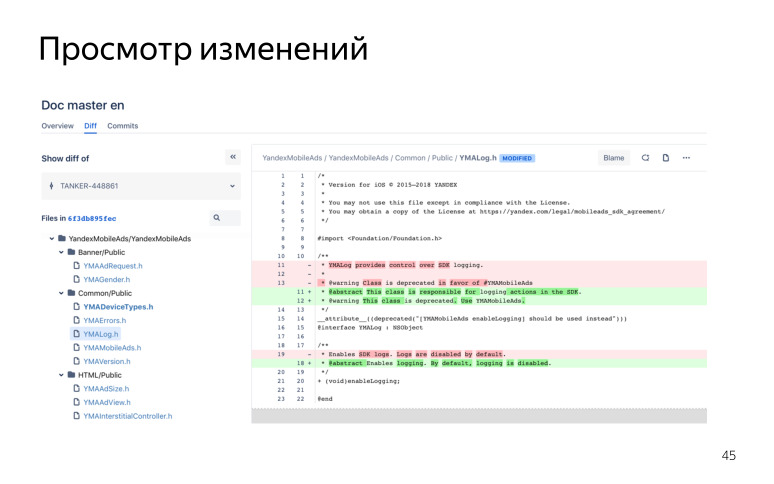
, , .
, SDK , - , , . -, , , , .
, . . — , , .
, . . .
, , , , , , .

, .
. - , . .

, , , , . . , , , - . , . , , .
, .
. , . , , .
, , , — . , , , .
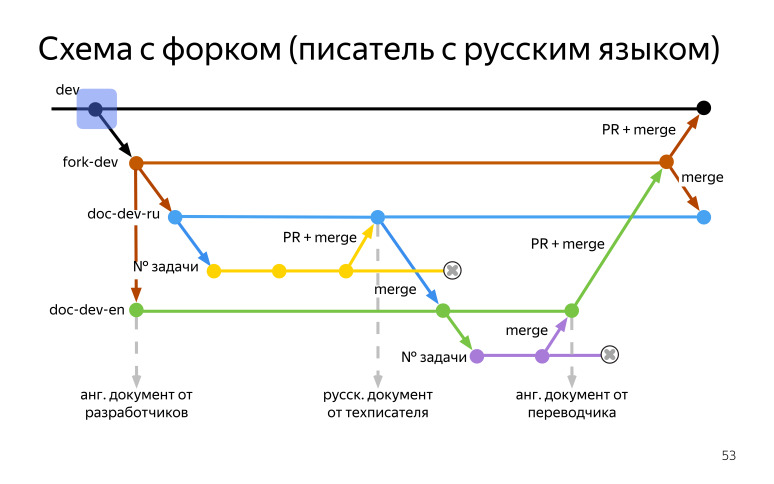
dev , (fork-dev) , . , doc-dev-en, . , , - , , .
(fork-dev) (doc-dev-ru) . , - . . , , doc-dev-ru, . , , - , .
, . (doc-dev-en). , , (doc-dev-en), , . , (fork-dev). , , , , . , , . , dev . , , , .
(fork-dev), , . (fork-dev), , (doc-dev-en), . , , , . , .

, , . dev, (fork-dev) , (doc-dev-ru) (doc-dev-en) . (doc-dev-en), (doc-dev-ru) . , .
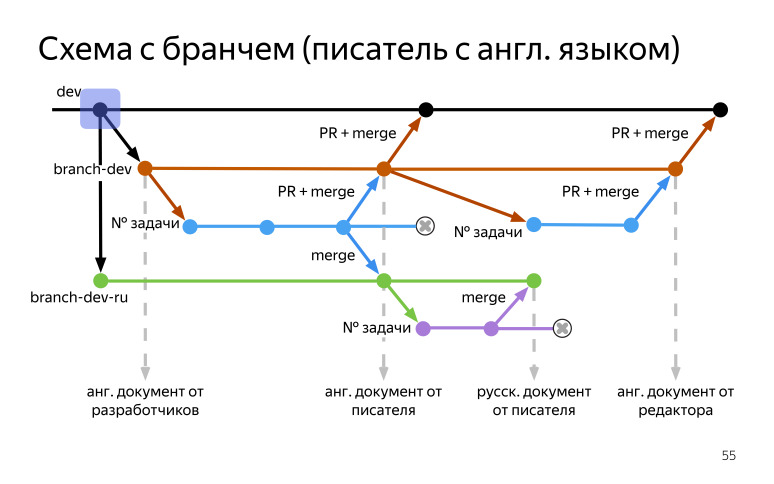
. dev , , (branch-dev). (branch-dev-ru), (branch-dev). , . , . — , — - , , , , .
, , . , , (branch-dev) . , , .
dev. , , , , . .
(branch-dev-ru), , (branch-dev-ru), . .
. (branch-dev), . , , , , , , , , . , , . , , .

, , , , . .
, ? , , . . . , - , . . , .
, , , , , .
, . . . . , , .
— — . — .
. . , . , , , , , , . .
, . . . . , . , . - , . — . .
Os processos devem ser igualmente convenientes para todos. Portanto, não temos uma ditadura, procuramos os desenvolvedores e dizemos: vamos trabalhar com o brunch. E eles dizem que trabalham com garfos. Dizemos: bem, mas vamos concordar que também trabalhamos com garfos. É necessário concordar para que todos os envolvidos nesse processo - na localização, escrevendo o código e a documentação no código - tenham uma posição acordada. É conveniente quando todos entendem sua área de responsabilidade - e não para que o redator técnico trabalhe de olhos fechados e não veja o código ou não tenha acesso ao repositório. Isso é tudo.