Por que algumas APIs são mais convenientes de usar do que outras? O que podemos fazer como fornecedores front-end do nosso lado para trabalhar com uma API de qualidade aceitável? Hoje vou contar aos leitores da Habr sobre opções técnicas e medidas organizacionais que ajudarão os provedores de front-end e back-end a encontrar uma linguagem comum e estabelecer um trabalho eficaz.

Neste outono, a Yandex.Market faz 18 anos. Todo esse tempo, a interface do mercado afiliado vem se desenvolvendo. Em resumo, este é o painel de administração com o qual as lojas podem fazer upload de catálogos, trabalhar com o sortimento, acompanhar estatísticas, responder a críticas etc. As especificidades do projeto são tais que você precisa interagir muito com vários back-ends. No entanto, os dados nem sempre podem ser obtidos em um local, a partir de um back-end específico.
Sintomas de um problema
Então, imagine, havia algum tipo de problema. O gerente vai com a tarefa para os designers - eles desenham o layout. Então ele vai para o back-end - eles fazem algumas
canetas e escrevem uma lista de parâmetros e o formato da resposta no wiki interno.
Em seguida, o gerente vai para o front-end com as palavras "Trouxe a API para você" e oferece um script rápido de tudo, porque, na opinião dele, quase todo o trabalho já foi feito.
Você olha a documentação e vê isso:
№ | ---------------------- 53 | feed_shoffed_id 54 | fesh 55 | filter-currency 56 | showVendors
Não percebe nada de estranho? Camel, Snake e Kebab Case em uma caneta. Eu não estou falando sobre o parâmetro fesh. O que é fesh? Tal palavra nem existe. Tente adivinhar antes de abrir o spoiler.
SpoilerFesh é um filtro por ID da loja. Você pode passar vários identificadores separados por vírgulas. Um ID pode ser precedido por um sinal de menos, o que significa que esse armazenamento deve ser excluído dos resultados.
Ao mesmo tempo, a partir do JavaSctipt, é claro, não consigo acessar as propriedades de um objeto por meio de notação pontilhada. Sem mencionar o fato de que, se você tiver mais de 50 parâmetros em um local, então, obviamente, na sua vida você se virou para outro lugar.
Existem muitas opções para uma API inconveniente. Um exemplo clássico - a API pesquisa e retorna resultados:
result: [ {id: 1, name: 'IPhone 8'}, {id: 2, name: 'IPhone 8 Plus'}, {id: 3, name: 'IPhone X'}, ] result: {id: 1, name: 'IPhone 8'} result: null
Se as mercadorias forem encontradas, obtemos uma matriz. Se um produto for encontrado, obteremos um objeto com esse produto. Se nada for encontrado, na melhor das hipóteses, ficaremos nulos. Na pior das hipóteses, o back-end responde com 404 ou mesmo 400 (Solicitação incorreta).
Situações são mais fáceis. Por exemplo, você precisa obter uma lista de lojas em um back-end e configurações de loja em outro. Em algumas canetas, não há dados suficientes, em alguns dados, há muitos. Filtrar tudo isso no cliente ou fazer várias solicitações de ajax é uma má idéia.
Então, quais podem ser as soluções para esse problema? O que podemos fazer como fornecedores front-end do nosso lado para trabalhar com uma API de qualidade aceitável?
Front-end back-end
Usamos o cliente React / Redux na interface do parceiro. Sob o cliente, encontra-se o Node.js, que faz muitas coisas auxiliares, por exemplo, lança-o na página InitialState para editores. Se você tiver uma renderização do lado do servidor, não importa com qual estrutura do cliente, provavelmente, ela será renderizada por um nó. Mas e se você der um passo adiante e não entrar em contato diretamente com o cliente no back-end, mas criar sua API de proxy no nó, adaptada ao máximo para as necessidades do cliente?
Essa técnica é chamada BFF (back-end para front-end). Este termo foi introduzido pela primeira vez pelo SoundCloud em 2015 e a ideia pode ser esquematicamente representada da seguinte maneira:
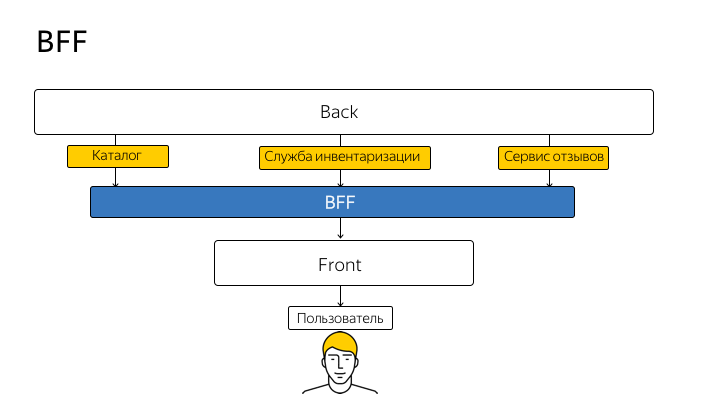
Portanto, você deixa de passar do código do cliente diretamente para a API. Cada identificador, cada método da API real que você duplica no nó e do cliente vai exclusivamente para o nó. E o nó já proxies a solicitação para a API real e retorna uma resposta para você.
Isso se aplica não apenas a solicitações de obtenção primitivas, mas geralmente a todas as solicitações, inclusive com dados de várias partes / formulário. Por exemplo, uma loja carrega um arquivo .xls com seu catálogo por meio de um formulário em um site. Portanto, nesta implementação, o diretório não é carregado diretamente na API, mas no identificador do Nod, que proxies transmitem para um back-end real.
Lembra-se do exemplo com resultado quando o back-end retornou nulo, uma matriz ou um objeto? Agora podemos voltar ao normal - algo como isto:
function getItems (response) { if (isNull(response)) return [] if (isObject(response)) return [response] return response }
Esse código parece horrível. Porque ele é terrível. Mas ainda precisamos fazer isso. Nós temos uma escolha: faça no servidor ou no cliente. Eu escolho um servidor.
Também podemos mapear todos esses casos de kebab e cobra em um estilo conveniente para nós e colocar imediatamente o valor padrão, se necessário.
query: { 'feed_shoffer_id': 'feedShofferId', 'pi-from': 'piFrom', 'show-urls': ({showUrls = 'offercard'}) => showUrls, }
Que outras vantagens temos?
- Filtragem . O cliente recebe apenas o que precisa, nem mais nem menos.
- Agregação Não é necessário desperdiçar a rede e a bateria do cliente para fazer várias solicitações de ajax. Um ganho de velocidade notável devido ao fato de abrir uma conexão ser uma operação cara.
- Armazenamento em cache Sua chamada agregada repetida não atrairá mais ninguém, mas simplesmente retornará 304 Não Modificado.
- Esconder dados. Por exemplo, você pode ter tokens necessários entre os back-ends e não deve ir para o cliente. O cliente pode não ter o direito de saber sobre a existência desses tokens, para não mencionar seu conteúdo.
- Microsserviços . Se você tiver um monólito nas costas, o BFF é o primeiro passo para os microsserviços.
Agora sobre os contras.
- Dificuldade crescente. Qualquer abstração é outra camada que precisa ser codificada, implantada e suportada. Outra parte móvel do mecanismo que pode falhar.
- Duplicação de alças. Por exemplo, vários pontos de extremidade podem executar o mesmo tipo de agregação.
- O BFF é uma camada de limite que deve suportar roteamento geral, restrições de direitos do usuário, registro de consultas, etc.
Para nivelar essas desvantagens, basta seguir regras simples. O primeiro é separar a lógica comercial e de front-end. Seu melhor amigo não deve alterar a lógica de negócios da API principal. Segundo, sua camada só deve converter dados se for absolutamente necessário. Não estamos falando de uma API abrangente e independente, mas apenas de um proxy que preenche essa lacuna, corrigindo as falhas de back-end.
GraphQL
Problemas semelhantes são resolvidos pelo GraphQL. Com o GraphQL, em vez de muitos pontos de extremidade "estúpidos", você tem uma caneta inteligente que pode trabalhar com consultas complexas e gerar dados na forma em que o cliente solicita.
Ao mesmo tempo, o GraphQL pode funcionar sobre o REST, ou seja, a fonte de dados não é o banco de dados, mas a API restante. Devido à natureza declarativa do GraphQL, devido ao fato de tudo isso ser amigo do React e Editors, seu cliente se torna mais fácil.
De fato, vejo o GraphQL como uma implementação do BFF com seu protocolo e uma linguagem de consulta estrita.
Essa é uma excelente solução, mas apresenta várias desvantagens, em particular com tipificação, diferenciação de direitos e, em geral, é uma abordagem relativamente nova. Portanto, ainda não mudamos, mas no futuro me parece a melhor maneira de criar uma API.
Melhores amigas para sempre
Nenhuma solução técnica funcionará corretamente sem alterações organizacionais. Você ainda precisa de documentação, garante que o formato da resposta não seja alterado repentinamente etc.
Deve-se entender que estamos todos no mesmo barco. Para um cliente abstrato, seja um gerente ou seu gerente, em geral, não faz diferença - você tem o GraphQL lá ou o BFF. É mais importante para ele que o problema seja resolvido e que os erros não apareçam no prod. Para ele, não há muita diferença devido a cuja falha ocorreu um erro no produto - pela falha da frente ou de trás. Portanto, você precisa negociar com os backders.
Além disso, as falhas nas quais eu falei no início do relatório nem sempre surgem devido a ações maliciosas de alguém. É possível que o parâmetro fesh também tenha algum significado.

Preste atenção na data do commit. Acontece que, recentemente, fesh comemorou seu décimo sétimo aniversário.
Vê alguns identificadores estranhos à esquerda? Este é o SVN, simplesmente porque não havia gita em 2001. Não é um github como serviço, mas um github como sistema de controle de versão. Ele apareceu apenas em 2005.
A documentação
Portanto, tudo o que precisamos não é brigar com o back-end, mas concordar. Isso só pode ser feito se encontrarmos uma única fonte de verdade. Essa fonte deve ser a documentação.
O mais importante aqui é escrever a documentação antes de começarmos a trabalhar na funcionalidade. Como em um acordo pré-nupcial, é melhor concordar com tudo na praia.
Como isso funciona? Relativamente falando, três vão para: gerente, front-end e back-end. Fronteder é bem versado na área de assunto, então sua participação é extremamente importante. Eles se reúnem e começam a pensar na API: de que maneira, quais respostas devem ser retornadas, até o nome e o formato dos campos.
Swagger
Uma boa opção para a documentação da API é o formato Swagger , agora chamado OpenAPI. É melhor usar o Swagger no formato YAML, porque, diferentemente do JSON, é melhor lido por humanos, mas não há diferença para a máquina.
Como resultado, todos os contratos são corrigidos no formato Swagger e publicados em um repositório comum. A documentação para o back-end de vendas deve estar no assistente.
O mestre está protegido contra confirmações, o código entra nele apenas através do pool de solicitações, e você não pode enviá-lo. O representante da equipe de frente é obrigado a realizar uma revisão do pool de solicitações, sem a atualização dele, o código não vai para o mestre. Isso protege você contra alterações inesperadas da API sem aviso prévio.
Então vocês se reuniram, escreveu Swagger, e assinaram o contrato. A partir deste momento, você como front-end pode iniciar seu trabalho sem esperar pela criação de uma API real. Afinal, qual era o ponto de separação entre cliente e servidor, se não podemos trabalhar em paralelo e os desenvolvedores de clientes precisam esperar pelos desenvolvedores de servidores? Se temos um "contrato", podemos paralisar com segurança esse assunto.
Faker.js
O Faker é ótimo para esses propósitos. Esta é uma biblioteca para gerar uma enorme quantidade de dados falsos. Pode gerar diferentes tipos de dados: datas, nomes, endereços, etc., tudo isso está bem localizado, há suporte para o idioma russo.
Ao mesmo tempo, o falsificador é amigo do arrogante, e você pode aumentar com calma o servidor Mock, que, com base no esquema do Swagger, irá gerar respostas falsas para você das formas necessárias.
Validação
O Swagger pode ser convertido em um esquema json e, com a ajuda de ferramentas como ajv, você pode validar respostas de back-end diretamente em tempo de execução, no seu BFF e reportar aos testadores, aos próprios back-ends, no caso de discrepâncias, etc.
Suponha que um testador encontre algum tipo de bug no site, por exemplo, quando um botão é clicado, nada acontece. O que o testador faz? Ele coloca um ingresso no front-end: "este é o seu botão, não está pressionado, repare".
Se houver um validador entre você e o back, o testador saberá que o botão está realmente pressionado, apenas o back-end envia a resposta errada. Errado - é uma resposta que a frente não espera, ou seja, não corresponde ao “contrato”. E aqui já é necessário reparar as costas ou alterar o contrato.
Conclusões
- Estamos ativamente envolvidos no design da API. Projetamos a API para que seja conveniente usá-la após 17 anos.
- Exigimos documentação do Swagger. Nenhuma documentação - a operação de back-end não foi concluída.
- Há documentação - nós a publicamos no git, e qualquer alteração na API deve ser atualizada pelo representante da equipe de frente.
- Aumentamos o servidor falso e começamos a trabalhar de frente sem esperar pela API real.
- Colocamos o nó no frontend e validamos todas as respostas. Além disso, temos a capacidade de agregar, normalizar e armazenar em cache dados.
Veja também
→ Como criar uma API semelhante a REST em um projeto grande
→ Back-end No front-end
→ Usando o GraphQL como implementação de padrão BFF