Uma das tarefas mais importantes no campo da ciência de dados não é apenas a construção de um modelo capaz de fazer previsões de alta qualidade, mas também a capacidade de interpretar essas previsões.
Se não apenas soubermos que o cliente está inclinado a comprar um produto, mas também entender o que influencia sua compra, poderemos construir uma estratégia da empresa no futuro, visando aumentar a eficiência das vendas.
Ou o modelo previu que o paciente adoeceria em breve. A precisão de tais previsões não é muito alta, porque Existem muitos fatores ocultos no modelo, mas uma explicação das razões pelas quais o modelo fez essa previsão pode ajudar o médico a prestar atenção a novos sintomas. Assim, é possível expandir os limites de aplicação do modelo se sua precisão em si não for muito alta.
Neste post, quero falar sobre a técnica
SHAP , que permite olhar sob o capô de uma variedade de modelos.
Se nos modelos lineares for cada vez menos claro, quanto maior o valor absoluto do coeficiente sob o preditor, mais importante é esse preditor e, em seguida, explicar a importância de características do mesmo aumento de gradiente é muito mais difícil.
Por que havia uma necessidade dessa biblioteca

Na pilha sklearn, nos pacotes xgboost, lightGBM, havia métodos internos para avaliar a importância dos recursos (importância dos recursos) para "modelos de madeira":
- Ganho
Essa medida mostra a contribuição relativa de cada recurso no modelo. Para o cálculo, examinamos cada árvore, observamos cada nó da árvore que recurso leva à partição do nó e quanto a incerteza do modelo diminui de acordo com a métrica (impureza de Gini, ganho de informações).
Para cada recurso, sua contribuição sobre todas as árvores é resumida.
- Cover
Mostra o número de observações para cada recurso. Por exemplo, você tem 4 recursos, 3 árvores. Suponha que o recurso 1 nos nós de uma árvore contenha 10, 5 e 2 observações nas árvores 1, 2 e 3. respectivamente.Então, para esse recurso, a importância será 17 (10 + 5 + 2).
- Frequência
Mostra com que frequência esse recurso ocorre nos nós da árvore, ou seja, o número total de árvores divididas em nós para cada recurso em cada árvore é considerado.
O principal problema em todas essas abordagens é que não está claro como exatamente esse recurso afeta a previsão do modelo. Por exemplo, aprendemos que o nível de renda é importante para avaliar a solvência de um cliente do banco para pagar um empréstimo. Mas como exatamente? Quanto os vieses de receita mais altos modelam previsões?
Obviamente, podemos fazer várias previsões alterando o nível de renda. Mas o que fazer com outros recursos? Afinal, nos encontramos em uma situação em que precisamos entender a influência da renda
independentemente de outras características, com seu valor médio.
Existe um tipo de cliente bancário médio "no vácuo". Como as previsões do modelo mudam com as mudanças na renda?
Aqui a biblioteca
SHAP vem em socorro.
Calculamos a importância dos recursos usando SHAP
Na biblioteca
SHAP , para avaliar a importância dos
recursos, os valores de Shapley são calculados (pelo nome de um matemático americano e a biblioteca é nomeada).
Para avaliar a importância de um recurso, as previsões do modelo são avaliadas
com e
sem esse recurso.
Um pouco de pré-história

Os significados de Shapley vêm da teoria dos jogos.
Considere o cenário: um grupo de pessoas joga cartas. Como distribuir o fundo do prêmio entre eles de acordo com sua contribuição?
São feitas várias suposições:
- A quantidade de recompensa para cada jogador é igual ao total do prêmio
- Se dois jogadores fizerem uma contribuição igual ao jogo, eles receberão uma recompensa igual.
- Se um jogador não fez nenhuma contribuição, ele não recebe uma recompensa.
- Se um jogador passou dois jogos, sua recompensa total consiste na quantidade de recompensas para cada um dos jogos
Apresentamos os recursos do modelo como jogadores e a premiação como a previsão final do modelo.
Vejamos um exemplo.
A fórmula para calcular o valor de Shapley para o i-ésimo recurso:
$$ display $$ \ begin {equação *} \ phi_ {i} (p) = \ sum_ {S \ subseteq N / \ {i \}} \ frac {| S |! (n - | S | -1) !} {n!} (p (S \ cup \ {i \}) - p (S)) \ end {equação *} $$ display $$
Aqui:
p (S \ cup \ {i \}) É uma previsão de um modelo com o i-ésimo recurso,
- esta é uma previsão do modelo sem o i-ésimo recurso,
- número de características,
- um conjunto arbitrário de recursos sem o i-ésimo recurso
O valor de Shapley para o i-ésimo recurso é calculado para cada amostra de dados (por exemplo, para cada cliente na amostra) em todas as combinações possíveis de recursos (incluindo a ausência de todos os recursos); em seguida, os valores obtidos são somados do módulo e a importância final do i-ésimo recurso é obtida.
Esses cálculos são extremamente caros, portanto, sob o capô, vários algoritmos para otimizar os cálculos são usados; para mais detalhes, consulte o link acima no github.
Veja o exemplo de baunilha da
documentação do
xgboost .
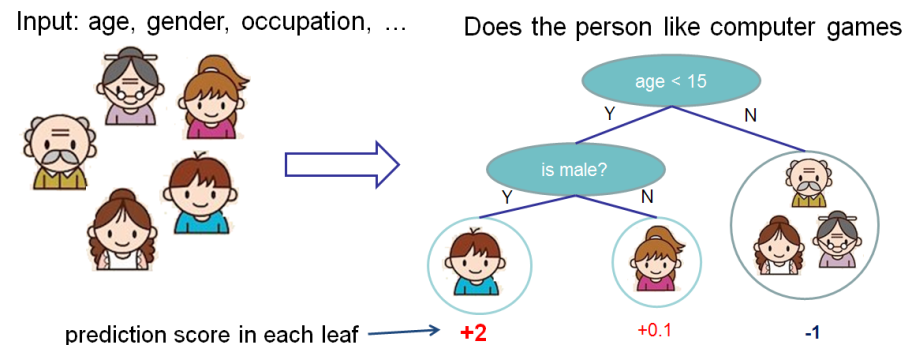
Queremos avaliar a importância dos recursos para prever se uma pessoa gosta de jogos de computador.
Neste exemplo, por simplicidade, temos dois recursos: idade (idade) e sexo (gênero). Gender (gender) assume os valores 0 e 1.
Pegue Bobby (o menino no nó mais à esquerda da árvore) e calcule o valor de Shapley para a característica idade (idade).
Temos dois conjuntos de recursos S:
\ {\} - sem recursos
\ {gender \} - existe apenas um gênero de recurso.
A situação em que não há valores de recurso
Modelos diferentes funcionam de maneira diferente com situações em que não há recursos para a amostra de dados, ou seja, para todos os recursos os valores são NULL.
Nesse caso, considerará que o modelo calcula a média das previsões sobre os galhos das árvores, ou seja, a previsão sem características será
.
Se adicionarmos conhecimento da idade, a previsão do modelo será
.
Como resultado, o valor de Shapley para o caso de recursos ausentes:
\ frac {| S |! (n - | S | -1)!} {n!} (p (S \ cup \ {i \}) - p (S)) = \ frac {1 (2-0 -1)!} {2!} (1,025) = 0,5125
A situação em que conhecemos o gênero
Para bobby para
previsão sem características idade, apenas com características sexo é igual
. Se conhecemos a idade, a previsão é a árvore mais à esquerda, ou seja, 2.
Como resultado, o valor de Shapley para este caso:
$$ display $$ \ begin {equação *} \ frac {| S |! (n - | S | -1)!} {n!} (p (S \ cup \ {i \}) - p (S) ) = \ frac {1 (2-1-1)!} {2!} (1,975) = 0,9875 \ end {equação *} $$ display $$
Resumir
O valor total de Shapley para os recursos idade (idade):
$$ display $$ \ begin {equação *} \ phi_ {Age Bobby} = 0,9875 + 0,5125 = 1,5 \ end {equation *} $$ display $$
Um exemplo real de negócios
A biblioteca SHAP possui uma rica funcionalidade de visualização que ajuda a explicar de maneira fácil e simples o modelo para os negócios e para o próprio analista, a fim de avaliar a adequação do modelo.
Em um dos projetos, analisei a saída de funcionários da empresa. Como modelo, o xgboost foi usado.
Código em python:
import shap shap_test = shap.TreeExplainer(best_model).shap_values(df) shap.summary_plot(shap_test, df, max_display=25, auto_size_plot=True)
O gráfico resultante da importância dos recursos:
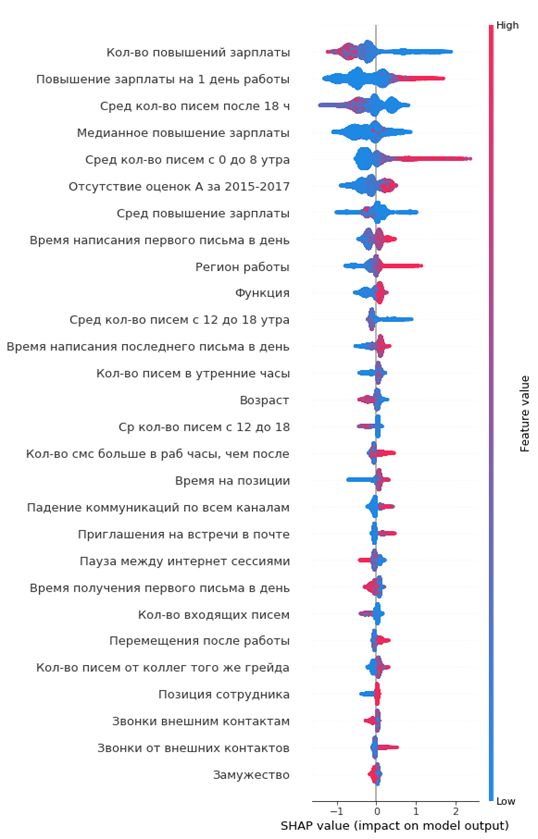
Como ler:
- os valores à esquerda da linha vertical central são da classe negativa (0) e à direita - positiva (1)
- quanto mais grossa a linha no gráfico, mais esses pontos de observação
- quanto mais vermelhos os pontos no gráfico, maior o valor dos recursos nele
No gráfico, você pode tirar conclusões interessantes e verificar sua adequação:
- quanto menor o aumento salarial do funcionário, maior a probabilidade de sua saída
- existem regiões de escritórios onde a saída é maior
- quanto mais jovem o empregado, maior a probabilidade de sua partida
- ...
Você pode imediatamente formar um retrato da funcionária de saída: ela não recebeu um aumento salarial, ele era jovem o suficiente, solteiro, por muito tempo na mesma posição, não houve aumento de notas, não houve altas classificações anuais, ele começou a se comunicar pouco com os colegas.
Simples e conveniente!
Você pode explicar a previsão para um funcionário específico:

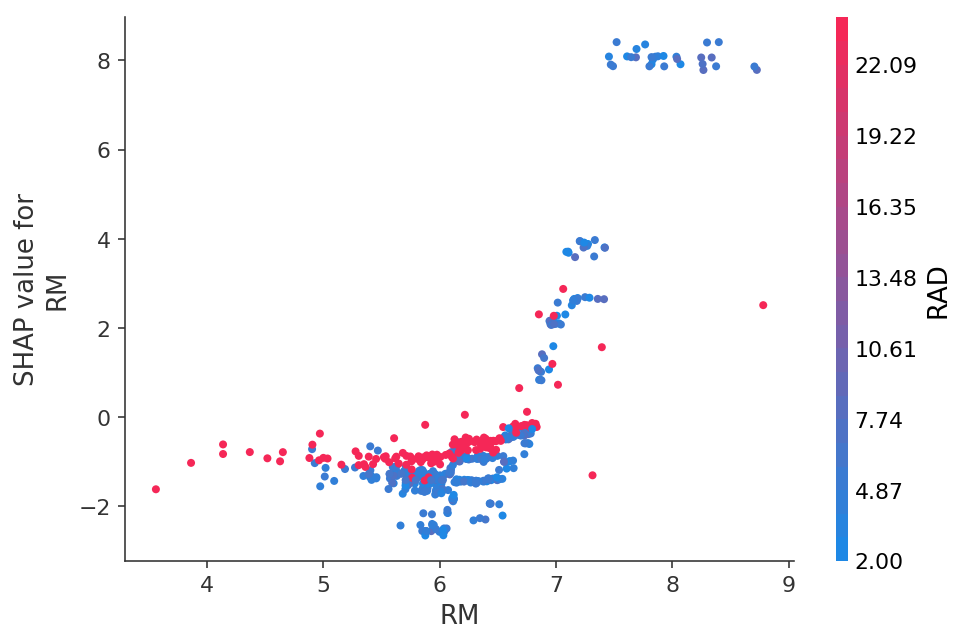
Ou veja a dependência de previsões em um recurso específico na forma de um gráfico 2D:
Você pode até visualizar as previsões de redes neurais em imagens:

Conclusão
Eu mesmo aprendi sobre os valores SHAP há cerca de seis meses e isso substituiu completamente outros métodos para avaliar a importância dos recursos.
As principais vantagens:
- visualização e interpretação convenientes
- cálculo honesto da importância dos recursos
- a capacidade de avaliar recursos para uma subamostra de dados específica (por exemplo, como nossos clientes diferem de outros clientes na amostra) é feita por um filtro simples do conjunto de dados nos pandas e sua análise no shap, literalmente algumas linhas de código