Síntese e edição de imagens controladas usando o novo TL-GAN Exemplo de síntese controlada no meu modelo TL-GAN (GAN de espaço latente transparente, rede de conteúdo generativo com espaço oculto transparente)
Exemplo de síntese controlada no meu modelo TL-GAN (GAN de espaço latente transparente, rede de conteúdo generativo com espaço oculto transparente)Todo o código e demonstrações online estão disponíveis na
página do projeto .
Treinamos o computador para tirar fotos como descrito
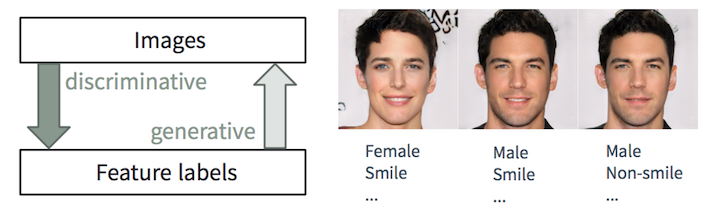 Tarefas Discriminantes e Geradoras
Tarefas Discriminantes e GeradorasÉ fácil para uma pessoa
descrever uma imagem, aprendemos a fazê-lo desde muito jovem. No aprendizado de máquina, essa é a tarefa de classificação / regressão
discriminante , ou seja, previsão de recursos a partir de imagens de entrada. Avanços recentes nos métodos de ML / AI, especialmente em modelos de aprendizado profundo, começam a se destacar nessas tarefas, às vezes atingindo ou superando as habilidades humanas, como mostrado em tarefas como reconhecimento visual de objetos (por exemplo, do AlexNet ao ResNet de acordo com a classificação do ImageNet) e detecção / segmentação objetos (por exemplo, de RCNN a YOLO no conjunto de dados COCO), etc.
No entanto, a tarefa inversa de
criar imagens realistas a partir da descrição é muito mais complicada e requer muitos anos de treinamento em design gráfico. No aprendizado de máquina, essa é uma tarefa
generativa , muito mais complicada do que tarefas discriminatórias, pois o modelo generativo deve gerar muito mais informações (por exemplo, uma imagem completa em um determinado nível de detalhe e variação) com base em dados iniciais menores.
Apesar da complexidade de criar esses aplicativos,
modelos generativos (com algum controle) são extremamente úteis em muitos casos:
- Criação de conteúdo : imagine que uma empresa de publicidade crie automaticamente imagens atraentes que correspondam ao conteúdo e estilo da página da web em que essas imagens são inseridas. O designer busca inspiração, ordenando o algoritmo para gerar 20 padrões de sapatos associados aos sinais "descanso", "verão" e "apaixonado". O novo jogo permite gerar avatares realistas a partir de uma descrição simples.
- Edição inteligente com base no conteúdo : o fotógrafo altera a expressão facial, o número de rugas e penteados na foto em apenas alguns cliques. Um artista em um estúdio de Hollywood converte as fotos tiradas em uma noite nublada, como se fossem tiradas em uma manhã clara, com a luz do sol no lado esquerdo da tela.
- Aumento de Dados : Um desenvolvedor de drones pode sintetizar vídeos realistas para um cenário de acidente específico, a fim de aumentar o conjunto de dados de treinamento. Um banco pode sintetizar certos tipos de dados de fraude mal apresentados no conjunto de dados existente para melhorar o sistema antifraude.
Neste artigo, falaremos sobre nosso trabalho recente chamado
GAN de espaço latente transparente (TL-GAN) , que estende a funcionalidade dos modelos mais modernos, fornecendo uma nova interface. No momento, estamos trabalhando em um documento que terá mais detalhes técnicos.
Visão geral de modelos generativos
A comunidade de aprendizagem profunda está melhorando rapidamente os modelos generativos. Três tipos promissores podem ser distinguidos entre eles:
modelos auto -
regressivos ,
auto- codificadores variacionais (VAE) e
redes adversárias generativas (GAN) , mostrados na figura abaixo. Se você estiver interessado nos detalhes, leia o excelente
artigo do OpenAI.
 Comparação de redes generativas. Imagem do curso STAT946F17 da Universidade de Waterloo
Comparação de redes generativas. Imagem do curso STAT946F17 da Universidade de WaterlooNo momento, as imagens da
mais alta qualidade são geradas pelas redes GAN (fotorrealistas e diversas, com detalhes convincentes em alta resolução). Veja a impressionante rede pg-GAN (
GAN que cresce progressivamente ) da Nvidia. Portanto, neste artigo, focaremos nos modelos GAN.
 Pg -GAN sintético gerado pela Nvidia. Nenhuma das imagens está relacionada à realidade.
Pg -GAN sintético gerado pela Nvidia. Nenhuma das imagens está relacionada à realidade.Gerenciamento de problemas do modelo GAN
 Geração de imagem aleatória e controladaA versão original do GAN
Geração de imagem aleatória e controladaA versão original do GAN e muitos modelos populares baseados nele (como
DC-GAN e
pg-GAN ) são modelos de ensino
sem um professor . Após o treinamento, a rede neural generativa recebe o ruído aleatório como entrada e cria uma imagem fotorrealista que mal se distingue do conjunto de dados de treinamento. No entanto, não podemos controlar adicionalmente os recursos das imagens geradas. Na maioria dos aplicativos (por exemplo, nos cenários descritos na primeira seção), os usuários gostariam de criar padrões com
atributos arbitrários (por exemplo, idade, cor do cabelo, expressão facial etc.). Idealmente, configure suavemente cada função.
Inúmeras variantes de GAN foram criadas para essa síntese controlada. Eles podem ser divididos condicionalmente em dois tipos: redes de transferência de estilo e geradores condicionais.
Redes de transferência de estilo
As redes de transferência no estilo
CycleGAN e
pix2pix são treinadas para transferir uma imagem de uma área (domínio) para outra: por exemplo, de um cavalo para uma zebra, de um esboço para imagens coloridas. Como resultado, não podemos alterar suavemente um sinal específico entre dois estados distintos (por exemplo, adicione um pouco de barba no rosto). Além disso, uma rede é projetada para um tipo de transmissão, portanto, dez redes neurais diferentes serão necessárias para configurar dez funções.
Geradores de condições
Geradores
condicionais -
GAN condicional ,
AC-GAN e Stack-GAN - no processo de treinamento, estudam simultaneamente imagens e rótulos de objetos, o que permite gerar imagens com a configuração de atributos. Quando você deseja adicionar novos recursos ao processo de geração, é necessário treinar novamente todo o modelo GAN, o que requer enormes recursos e tempo computacionais (por exemplo, de vários dias a semanas na mesma GPU K80 com um conjunto ideal de hiperparâmetros). Além disso, para concluir o treinamento, é necessário confiar em um conjunto de dados contendo todos os rótulos de objetos definidos pelo usuário e não usar rótulos diferentes de vários conjuntos de dados.
Nossa rede competitiva de geração com espaço oculto transparente (
GAN de espaço latente transparente , TL-GAN) usa uma abordagem diferente para geração controlada - e resolve esses problemas. Ele oferece a capacidade de
configurar perfeitamente um ou mais recursos usando uma única rede . Além disso, você pode efetivamente adicionar novos recursos personalizados em menos de uma hora.
TL-GAN: Uma Abordagem Nova e Eficaz para Síntese e Edição Controladas
Tornando este misterioso espaço escondido transparente
Pegue o modelo pvGAN da Nvidia, que gera imagens fotorrealistas de alta resolução de rostos, como mostrado na seção anterior. Todos os recursos da imagem 1024 × 1024px gerada são determinados exclusivamente pelo vetor de ruído de 512 dimensões no espaço oculto (como uma representação de baixa dimensão do conteúdo da imagem). Portanto,
se entendermos o que constitui um espaço oculto (ou seja, torná-lo transparente), poderemos controlar completamente o processo de geração .
 Motivação do TL-GAN: Compreendendo o espaço oculto para gerenciar o processo de geração
Motivação do TL-GAN: Compreendendo o espaço oculto para gerenciar o processo de geraçãoExperimentando a rede pg-GAN pré-treinada, descobri que o espaço oculto realmente tem duas boas propriedades:
- É bem preenchido, ou seja, a maioria dos pontos no espaço gera imagens razoáveis.
- É bastante contínua, ou seja, a interpolação entre dois pontos em um espaço oculto geralmente leva a uma transição suave das imagens correspondentes.
A intuição diz que no espaço oculto existem orientações que preveem os atributos que precisamos (por exemplo, um homem / mulher). Nesse caso, os vetores unitários dessas direções se tornarão eixos para controlar o processo de geração (face mais masculina ou mais feminina).
Abordagem: Expansão do eixo do recurso
Para encontrar esses eixos de atributos em um espaço oculto,
construímos uma conexão entre o vetor oculto e etiquetas usando treinamento de professores em pares
. Agora, o problema é como obter esses pares, já que os conjuntos de dados existentes contêm apenas imagens
e rótulos de objetos correspondentes
.
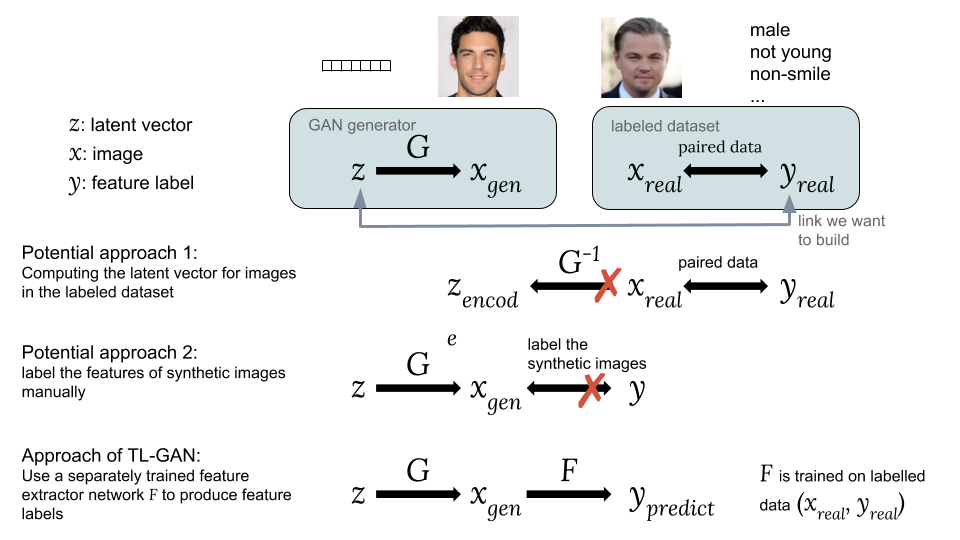 Maneiras de associar um vetor oculto z a um rótulo yPossíveis abordagens:Uma opção é calcular os vetores ocultos correspondentes imagens de um conjunto de dados existente com rótulos de seu interesse . No entanto, o GAN não fornece uma maneira fácil de calcular , o que dificulta a implementação dessa ideia.
Maneiras de associar um vetor oculto z a um rótulo yPossíveis abordagens:Uma opção é calcular os vetores ocultos correspondentes imagens de um conjunto de dados existente com rótulos de seu interesse . No entanto, o GAN não fornece uma maneira fácil de calcular , o que dificulta a implementação dessa ideia.
A segunda opção é gerar imagens sintéticas usando um GAN de um vetor oculto aleatório como . O problema é que as imagens sintéticas não são marcadas, por isso é difícil usar um conjunto acessível de dados marcados.A principal inovação do nosso modelo TL-GAN é o
treinamento de um extrator separado (classificador para etiquetas discretas ou regressor para contínuo) com o modelo
usando um conjunto existente de dados marcados (
,
) e, em seguida, inicie um monte de geradores GAN treinados
com rede de extração de recursos
. Isso permite prever os rótulos dos recursos.
imagens sintéticas
usando uma rede de extração de recursos treinada (extrator). Assim, através de imagens sintéticas, é estabelecida uma conexão entre
e
como
e
.
Agora, temos um vetor e recursos ocultos emparelhados. Você pode treinar o modelo de regressor
para abrir todo o eixo dos recursos para controlar o processo de geração de imagens.
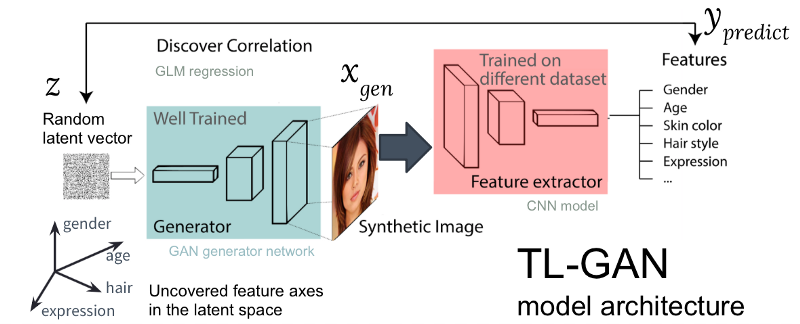 Figura: A arquitetura do nosso modelo TL-GAN
Figura: A arquitetura do nosso modelo TL-GANA figura acima mostra a arquitetura do modelo TL-GAN, que contém cinco etapas:
- O estudo da distribuição . Selecionamos um modelo GAN bem treinado e uma rede generativa. Peguei o pg-GAN bem treinado (da Nvidia), que fornece a melhor geração de rosto de qualidade.
- Classificação . Selecionamos um modelo pré-treinado para extrair traços (o extrator pode ser uma rede neural convolucional ou outros modelos de visão computacional) ou treinamos nosso próprio extrator usando um conjunto de dados marcados. Treinei uma rede neural convolucional simples usando o kit CelebA (mais de 30.000 rostos com 40 tags).
- Geração . Criamos vários vetores ocultos aleatórios, passamos pelo gerador GAN treinado para criar imagens sintéticas e usamos o extrator de recursos treinado para gerar recursos em cada imagem.
- Correlação . Utilizamos o modelo linear generalizado (GLM) para implementar a regressão entre vetores e características ocultas. A inclinação da linha de regressão se torna o eixo das características .
- Pesquisa . Começamos com um vetor oculto, movemos-o ao longo de um ou vários eixos dos sinais e estudamos como isso afeta a geração de imagens.
Otimizei bastante o processo: em um modelo GAN pré-treinado, a identificação de eixos de recursos
leva apenas uma hora em uma máquina com uma GPU. Isso é conseguido através de vários truques de engenharia, incluindo a transferência de treinamento, a redução do tamanho das imagens, o cache preliminar de imagens sintéticas etc.
Resultados
Vamos ver como essa idéia simples funciona.
Movendo um vetor oculto ao longo dos eixos dos objetos
Primeiro, verifiquei se os eixos de recurso detectados podem ser usados para controlar o recurso correspondente da imagem gerada. Para fazer isso, crie um vetor aleatório
no espaço oculto do GAN e gerar uma imagem sintética
passando por uma rede generativa
. Em seguida, movemos o vetor oculto ao longo de um eixo de recursos
(um vetor unitário no espaço oculto, digamos, correspondente ao sexo da face) à distância
para uma nova posição
e gerar uma nova imagem
. Idealmente, o recurso correspondente da nova imagem deve mudar na direção esperada.
Os resultados da movimentação de um vetor ao longo de vários eixos de atributos (sexo, idade etc.) são apresentados abaixo. Funciona surpreendentemente bem! Você pode
transformar suavemente a imagem entre um homem / mulher, um jovem / velho, etc.
 Os primeiros resultados da movimentação de um vetor oculto ao longo de eixos de recurso emaranhados
Os primeiros resultados da movimentação de um vetor oculto ao longo de eixos de recurso emaranhadosDesvendando os eixos de recurso correlacionados
Nos exemplos acima, a desvantagem do método original é visível, a saber, o eixo confuso dos atributos. Por exemplo, quando você precisa reduzir os pêlos faciais, os rostos gerados se tornam mais femininos, o que não é o resultado esperado. O problema é que gênero e barba são inerentemente
correlacionados . Uma mudança em uma característica leva a uma mudança em outra. Coisas semelhantes aconteceram com outros recursos, como cabelos e cabelos encaracolados. Conforme mostrado na figura abaixo, o eixo original do atributo "barba" no espaço oculto não é perpendicular ao eixo "piso".
Para resolver o problema, usei as técnicas da álgebra linear simples. Em particular, ele projetou o eixo da barba em uma nova direção, ortogonal ao eixo do piso, o que elimina efetivamente a correlação e, portanto, pode potencialmente desvendar esses dois sinais nas faces geradas.
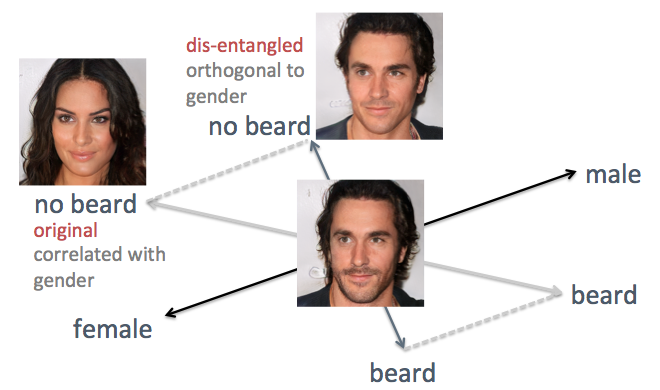 Desvendando os eixos de recurso correlacionados com técnicas de álgebra linear
Desvendando os eixos de recurso correlacionados com técnicas de álgebra linearEu apliquei esse método para a mesma pessoa. Desta vez, os eixos de gênero e idade são escolhidos como de apoio, projetando todos os outros eixos para que se tornem ortogonais a gênero e idade. As faces são geradas movendo o vetor oculto ao longo dos eixos de recursos recém-gerados (mostrados na figura abaixo). Como esperado, agora sinais como penteados e barbas não afetam o chão.
 Resultado aprimorado da movimentação de um vetor oculto ao longo de eixos de recurso desembaraçados
Resultado aprimorado da movimentação de um vetor oculto ao longo de eixos de recurso desembaraçadosEdição interativa flexível
Para ver com que flexibilidade nosso modelo TL-GAN é capaz de controlar o processo de geração de imagens, criei uma interface gráfica interativa com uma mudança suave nos valores dos objetos ao longo de diferentes eixos, como mostrado abaixo.
Edição interativa com TL-GANE, novamente, o modelo funciona surpreendentemente bem se você alterar a imagem ao longo do eixo dos sinais!
Sumário
Este projeto demonstra um novo método para gerenciar um modelo generativo sem professor, como o GAN (rede adversária generativa). Usando um gerador GAN pré-treinado (pg-GAN da Nvidia), tornei transparente seu espaço oculto, mostrando os eixos de recursos significativos. Quando um vetor se move ao longo desse eixo em um espaço oculto, a imagem correspondente é transformada ao longo desse recurso, fornecendo síntese e edição controladas.
Este método tem vantagens claras:
- Eficiência: para adicionar um novo sintonizador de recursos ao gerador, você não precisa treinar novamente o modelo GAN; portanto, adicionar sintonizadores para 40 recursos leva menos de uma hora.
- Flexibilidade: você pode usar qualquer extrator de recursos treinado em qualquer conjunto de dados, adicionando mais recursos a um GAN bem treinado.
Algumas palavras sobre ética
Este trabalho permite controlar a geração de imagens em detalhes, mas ainda depende muito das características do conjunto de dados. O treinamento em fotos de estrelas de Hollywood significa que o modelo irá gerar muito bem fotos de pessoas na sua maioria brancas e atraentes. Isso levará ao fato de que os usuários poderão criar rostos representando apenas uma pequena parte da humanidade. Se você implantar esse serviço como um aplicativo real, é recomendável expandir o conjunto de dados original para levar em consideração a diversidade de nossos usuários.
Embora a ferramenta possa ajudar muito no processo criativo, você precisa se lembrar das possibilidades de usá-la para fins impróprios. Se criarmos rostos realistas de qualquer tipo, em que medida podemos confiar na pessoa que vemos na tela? Hoje é importante discutir questões desse tipo. Como vimos em exemplos recentes da tecnologia
Deepfake , a IA está progredindo rapidamente, por isso é vital para a humanidade iniciar uma discussão sobre a melhor maneira de implantar esses aplicativos.
Demo e código online
Todo o código e demonstrações online deste trabalho estão disponíveis na
página do GitHub .
Se você quiser brincar com o modelo no navegador
Você não precisa fazer o download de código, modelo ou dados. Basta seguir as instruções
nesta seção Leia-me. Você pode alterar os rostos no navegador, como mostrado no vídeo.
Se você quiser experimentar o código
Basta ir para a página Leia-me do repositório GitHub. Código compilado no Anaconda Python 3.6 com Tensorflow e Keras.
Se você quer contribuir
Bem-vindo Sinta-se à vontade para enviar uma solicitação de pool ou relatar um problema no GitHub.
Sobre mim
Recentemente, recebi um doutorado em neurobiologia computacional e cognitiva pela Brown University e um mestrado em ciência da computação, com especialização em aprendizado de máquina. No passado, estudei como os neurônios do cérebro processam coletivamente as informações para obter funções de alto nível, como a percepção visual. Gosto da abordagem algorítmica da análise, simulação e implementação da inteligência, bem como do uso da IA para resolver problemas complexos do mundo real. Estou ativamente procurando um emprego como pesquisador de ML / AI no setor de tecnologia.
Agradecimentos
Este trabalho foi realizado em três semanas como um projeto para
o programa de bolsas InSight AI . Agradeço ao diretor do programa
Emmanuel Amaisen e
Matt Rubashkin pela liderança geral, especialmente a Emmanuel por suas sugestões e pela edição do artigo. Agradeço também a todos os funcionários do Insight pelo excelente ambiente de aprendizado e por outros participantes do programa Insight AI, dos quais aprendi muito.
Um agradecimento especial a Rubin Xia pelas muitas dicas e inspiração quando decidi em que direção desenvolver o projeto e pela enorme ajuda na estruturação e edição deste artigo.