O aprendizado de máquina está se tornando mais acessível, há mais oportunidades de aplicar essa tecnologia usando "componentes prontos para uso". Por exemplo, o Transfer Learning permite que você use a experiência adquirida na solução de um problema para resolver outro problema semelhante. A rede neural é treinada primeiro em uma grande quantidade de dados e depois no conjunto de destino.

Neste artigo, mostrarei como usar o método Transfer Learning usando o exemplo de reconhecimento de imagens com alimentos. Falarei sobre outras ferramentas de aprendizado de máquina no workshop de
Aprendizado de Máquina e Redes Neurais para Desenvolvedores .
Se formos confrontados com a tarefa de reconhecimento de imagem, você pode usar o serviço pronto. No entanto, se você precisar treinar o modelo em seu próprio conjunto de dados, precisará fazer isso sozinho.
Para tarefas típicas como a classificação de imagens, você pode usar a arquitetura pronta (AlexNet, VGG, Inception, ResNet etc.) e treinar a rede neural em seus dados. Já existem implementações dessas redes usando várias estruturas; portanto, nesse estágio, você pode usar uma delas como uma caixa preta, sem se aprofundar no princípio de sua operação.
No entanto, redes neurais profundas estão exigindo grandes quantidades de dados para a convergência da aprendizagem. E, freqüentemente, em nossa tarefa específica, não há dados suficientes para treinar adequadamente todas as camadas da rede neural. O Transfer Learning resolve esse problema.
Transferência de aprendizado para classificação de imagens
As redes neurais usadas para classificação geralmente contêm
N neurônios de saída na última camada, onde
N é o número de classes. Esse vetor de saída é tratado como um conjunto de probabilidades de pertencer a uma classe. Em nossa tarefa de reconhecer imagens de alimentos, o número de classes pode diferir daquele no conjunto de dados original. Nesse caso, teremos que jogar completamente fora essa última camada e colocar uma nova, com o número certo de neurônios de saída
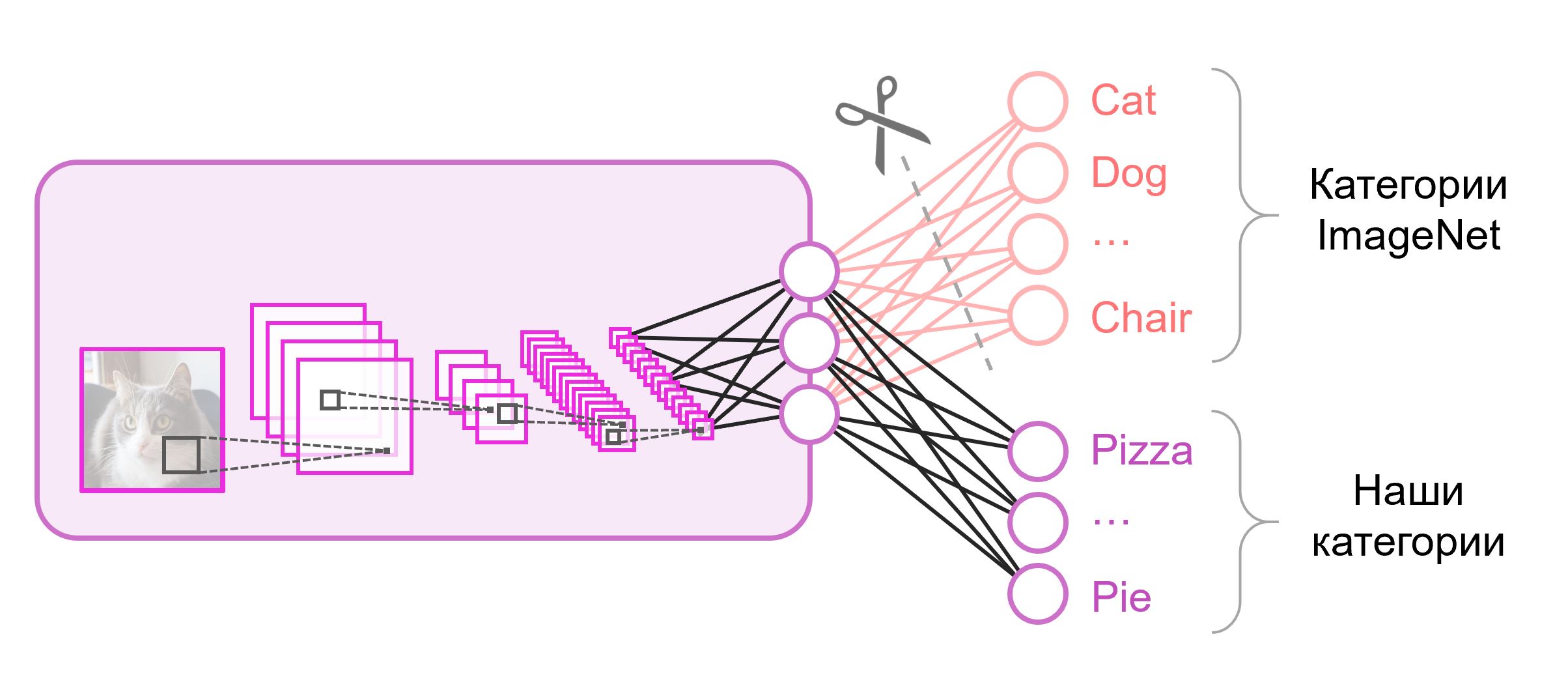
Freqüentemente, no final das redes de classificação, uma camada totalmente conectada é usada. Como substituímos essa camada, o uso de pesos pré-treinados não funcionará. Você terá que treiná-lo do zero, inicializando seus pesos com valores aleatórios. Carregamos pesos para todas as outras camadas a partir de um instantâneo pré-treinado.
Existem várias estratégias para continuar treinando o modelo. Usaremos o seguinte: treinaremos toda a rede de ponta a ponta (
ponta a ponta ) e não corrigiremos os pesos pré-treinados para permitir que eles se ajustem um pouco e se ajustem aos nossos dados. Esse processo é chamado
de ajuste fino .
Componentes estruturais
Para resolver o problema, precisamos dos seguintes componentes:
- Descrição do modelo de rede neural
- Pipeline de aprendizado
- Pipeline de interferência
- Pesos pré-treinados para este modelo
- Dados para treinamento e validação
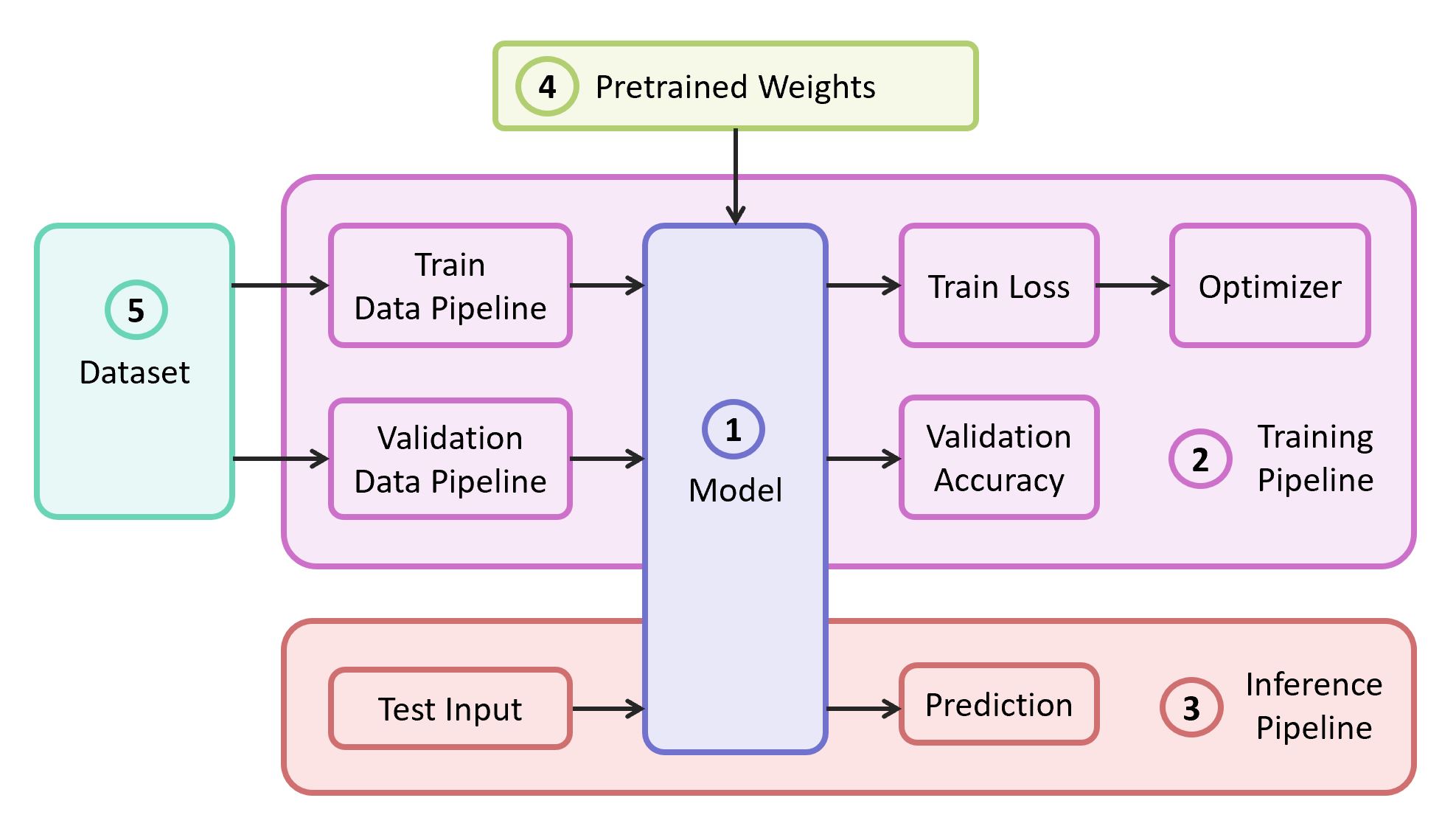
No nosso exemplo, pegarei os componentes (1), (2) e (3) do
meu próprio repositório , que contém o código mais leve - você pode facilmente descobrir se quiser. Nosso exemplo será implementado na popular estrutura
TensorFlow . Pesos pré-treinados (4) adequados para a estrutura selecionada podem ser encontrados se corresponderem a uma das arquiteturas clássicas. Como um conjunto de dados (5) para demonstração, tomarei o
Food-101 .
Modelo
Como modelo, usamos a rede neural
VGG clássica (mais precisamente,
VGG19 ). Apesar de algumas desvantagens, este modelo demonstra uma qualidade bastante alta. Além disso, é fácil de analisar. No TensorFlow Slim, a descrição do modelo é bastante compacta:
import tensorflow as tf import tensorflow.contrib.slim as slim def vgg_19(inputs, num_classes, is_training, scope='vgg_19', weight_decay=0.0005): with slim.arg_scope([slim.conv2d], activation_fn=tf.nn.relu, weights_regularizer=slim.l2_regularizer(weight_decay), biases_initializer=tf.zeros_initializer(), padding='SAME'): with tf.variable_scope(scope, 'vgg_19', [inputs]): net = slim.repeat(inputs, 2, slim.conv2d, 64, [3, 3], scope='conv1') net = slim.max_pool2d(net, [2, 2], scope='pool1') net = slim.repeat(net, 2, slim.conv2d, 128, [3, 3], scope='conv2') net = slim.max_pool2d(net, [2, 2], scope='pool2') net = slim.repeat(net, 4, slim.conv2d, 256, [3, 3], scope='conv3') net = slim.max_pool2d(net, [2, 2], scope='pool3') net = slim.repeat(net, 4, slim.conv2d, 512, [3, 3], scope='conv4') net = slim.max_pool2d(net, [2, 2], scope='pool4') net = slim.repeat(net, 4, slim.conv2d, 512, [3, 3], scope='conv5') net = slim.max_pool2d(net, [2, 2], scope='pool5')
Os pesos para o VGG19, treinados no ImageNet e compatíveis com o TensorFlow, são baixados do repositório no GitHub na seção
Modelos pré-treinados .
mkdir data && cd data wget http://download.tensorflow.org/models/vgg_19_2016_08_28.tar.gz tar -xzf vgg_19_2016_08_28.tar.gz
Datacet
Como amostra de treinamento e validação, usaremos o conjunto de dados público
Food-101 , que contém mais de 100 mil imagens de alimentos, divididas em 101 categorias.

Faça o download e descompacte o conjunto de dados:
cd data wget http://data.vision.ee.ethz.ch/cvl/food-101.tar.gz tar -xzf food-101.tar.gz
O pipeline de dados em nosso treinamento foi projetado para que, a partir do conjunto de dados, precisamos analisar o seguinte:
- Lista de aulas (categorias)
- Tutorial: uma lista de caminhos para imagens e uma lista de respostas corretas
- Conjunto de validação: lista de caminhos para imagens e lista de respostas corretas
Se o seu conjunto de dados, para
treinamento e
validação, você precisará quebrar os conjuntos por conta própria. O Food-101 já possui essa partição e essas informações são armazenadas no diretório
meta .
DATASET_ROOT = 'data/food-101/' train_data, val_data, classes = data.food101(DATASET_ROOT) num_classes = len(classes)
Todas as funções auxiliares responsáveis pelo processamento de dados são movidas para um arquivo
data.py separado:
data.py from os.path import join as opj import tensorflow as tf def parse_ds_subset(img_root, list_fpath, classes): ''' Parse a meta file with image paths and labels -> img_root: path to the root of image folders -> list_fpath: path to the file with the list (eg train.txt) -> classes: list of class names <- (list_of_img_paths, integer_labels) ''' fpaths = [] labels = [] with open(list_fpath, 'r') as f: for line in f: class_name, image_id = line.strip().split('/') fpaths.append(opj(img_root, class_name, image_id+'.jpg')) labels.append(classes.index(class_name)) return fpaths, labels def food101(dataset_root): ''' Get lists of train and validation examples for Food-101 dataset -> dataset_root: root of the Food-101 dataset <- ((train_fpaths, train_labels), (val_fpaths, val_labels), classes) ''' img_root = opj(dataset_root, 'images') train_list_fpath = opj(dataset_root, 'meta', 'train.txt') test_list_fpath = opj(dataset_root, 'meta', 'test.txt') classes_list_fpath = opj(dataset_root, 'meta', 'classes.txt') with open(classes_list_fpath, 'r') as f: classes = [line.strip() for line in f] train_data = parse_ds_subset(img_root, train_list_fpath, classes) val_data = parse_ds_subset(img_root, test_list_fpath, classes) return train_data, val_data, classes def imread_and_crop(fpath, inp_size, margin=0, random_crop=False): ''' Construct TF graph for image preparation: Read the file, crop and resize -> fpath: path to the JPEG image file (TF node) -> inp_size: size of the network input (eg 224) -> margin: cropping margin -> random_crop: perform random crop or central crop <- prepared image (TF node) ''' data = tf.read_file(fpath) img = tf.image.decode_jpeg(data, channels=3) img = tf.image.convert_image_dtype(img, dtype=tf.float32) shape = tf.shape(img) crop_size = tf.minimum(shape[0], shape[1]) - 2 * margin if random_crop: img = tf.random_crop(img, (crop_size, crop_size, 3)) else:
Modelo de treinamento
O código de treinamento do modelo consiste nas seguintes etapas:
- Construção de pipelines de dados de trem / validação
- Construção de gráficos de trem / validação (redes)
- Anexo da função de classificação de perdas ( perda de entropia cruzada ) sobre o gráfico de trens
- O código necessário para calcular a precisão das previsões na amostra de validação durante o treinamento
- Lógica para carregar balanças pré-treinadas a partir de uma captura instantânea
- Criação de várias estruturas para treinamento
- O próprio ciclo de aprendizado (otimização iterativa)
A última camada do gráfico é construída com o número necessário de neurônios e é excluída da lista de parâmetros carregados do instantâneo pré-treinado.
Código de treinamento modelo import numpy as np import tensorflow as tf import tensorflow.contrib.slim as slim tf.logging.set_verbosity(tf.logging.INFO) import model import data
Após iniciar o treinamento, você pode observar seu progresso usando o utilitário TensorBoard, fornecido com o TensorFlow e serve para visualizar várias métricas e outros parâmetros.
tensorboard --logdir checkpoints/
No final do treinamento no TensorBoard, vemos uma imagem quase perfeita: uma diminuição na
perda de trens e um aumento na
precisão da validação
Como resultado, obtemos o instantâneo salvo em
checkpoints/vgg19_food , que usaremos durante o teste do nosso modelo (
inferência ).
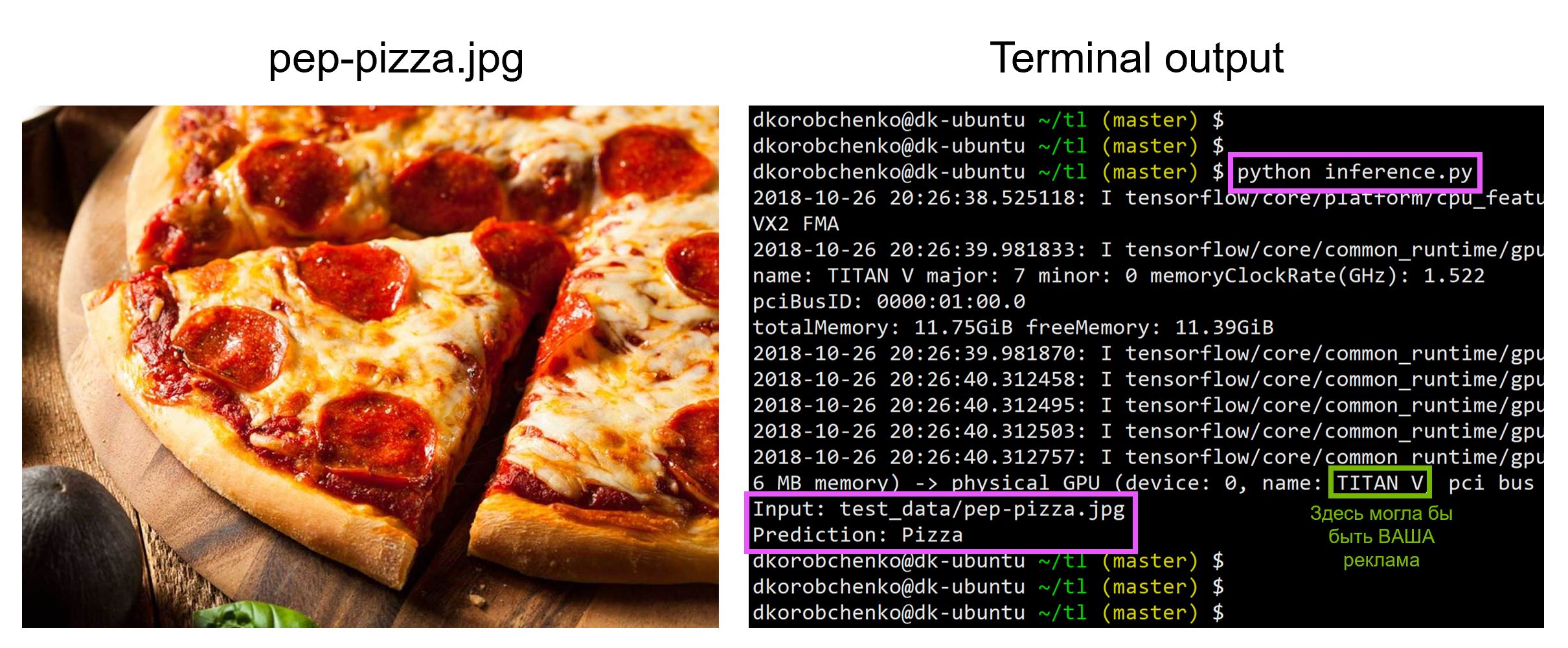
Teste de modelo
Agora teste nosso modelo. Para fazer isso:
- Construímos um novo gráfico projetado especificamente para inferência (
is_training=False ) - Carregar pesos treinados a partir de uma captura instantânea
- Faça o download e pré-processe a imagem de teste de entrada.
- Vamos conduzir a imagem através da rede neural e obter a previsão
inference.py import sys import numpy as np import imageio from skimage.transform import resize import tensorflow as tf import model
Todo o código, incluindo recursos para criar e executar um contêiner do Docker com todas as versões necessárias das bibliotecas, está
neste repositório - no momento da leitura do artigo, o código no repositório pode ter atualizações.
No workshop
“Aprendizado de máquina e redes neurais para desenvolvedores” , analisarei outras tarefas do aprendizado de máquina e os alunos apresentarão seus projetos até o final da sessão intensiva.