
Na Conferência da AI,
Vladimir Ivanov vivanov879 , Sr. falará sobre o uso da aprendizagem reforçada
Engenheiro de aprendizado profundo na Nvidia . O especialista está envolvido no aprendizado de máquina no departamento de testes: “Analiso os dados que coletamos durante o teste de jogos e hardware de vídeo. Para isso, uso aprendizado de máquina e visão computacional. A parte principal do trabalho é análise de imagens, limpeza de dados antes do treinamento, marcação de dados e visualização das soluções obtidas. ”
No artigo de hoje, Vladimir explica por que o aprendizado reforçado é usado em carros autônomos e fala sobre como um agente é treinado para agir em um ambiente em mudança - usando exemplos de videogame.
Nos últimos anos, a humanidade acumulou uma enorme quantidade de dados. Alguns conjuntos de dados são compartilhados e dispostos manualmente. Por exemplo, o conjunto de dados CIFAR, onde cada figura é assinada, a qual classe pertence.
Existem conjuntos de dados em que você precisa atribuir uma classe não apenas à imagem como um todo, mas a todos os pixels da imagem. Como, por exemplo, no CityScapes.

O que une essas tarefas é que uma rede neural de aprendizado precisa apenas lembrar os padrões nos dados. Portanto, com quantidades de dados suficientemente grandes e, no caso do CIFAR, são 80 milhões de imagens, a rede neural está aprendendo a generalizar. Como resultado, ela lida bem com a classificação de imagens que nunca havia visto antes.
Mas, atuando dentro da estrutura da técnica de ensino com o professor, que trabalha para marcar imagens, é impossível resolver problemas onde queremos não prever a marca, mas tomar decisões. Como, por exemplo, no caso de direção autônoma, em que a tarefa é alcançar com segurança e confiabilidade o ponto final da rota.
Nos problemas de classificação, usamos a técnica de ensino com o professor - quando cada figura recebe uma aula específica. Mas e se não tivermos essa marcação, mas houver um agente e um ambiente em que ele possa executar determinadas ações? Por exemplo, seja um videogame, e podemos clicar nas setas de controle.

Esse tipo de problema deve ser resolvido com o treinamento de reforço. Na declaração geral do problema, queremos aprender como executar a sequência correta de ações. É de fundamental importância que o agente tenha a capacidade de executar ações repetidas vezes, explorando o ambiente em que está. E, em vez da resposta correta, o que fazer em uma situação específica, ele recebe uma recompensa por uma tarefa concluída corretamente. Por exemplo, no caso de um táxi autônomo, o motorista receberá um bônus por cada viagem realizada.
Vamos voltar a um exemplo simples - um videogame. Pegue algo simples, como o jogo de tênis de mesa Atari.
Controlaremos o tablet à esquerda. Vamos jogar contra o jogador do computador programado de acordo com as regras à direita. Como trabalhamos com uma imagem e as redes neurais são as que obtêm mais sucesso na extração de informações, vamos aplicar uma imagem à entrada de uma rede neural de três camadas com um tamanho de núcleo 3x3. Na saída, ela terá que escolher uma das duas ações: mover o tabuleiro para cima ou para baixo.
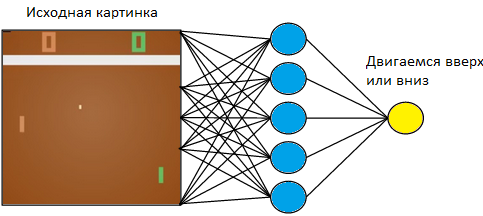
Treinamos a rede neural para executar ações que levam à vitória. A técnica de treinamento é a seguinte. Deixamos a rede neural jogar algumas rodadas de tênis de mesa. Então começamos a classificar os jogos disputados. Nos jogos em que ela venceu, marcamos as imagens “Up”, onde ela levantou a raquete, e “Down”, onde ela a abaixou. Nos jogos perdidos, fazemos o oposto. Marcamos as fotos em que ela abaixou o quadro com o rótulo "Para cima" e onde ela o levantou, "Para baixo". Assim, reduzimos o problema à abordagem que já conhecemos - treinando com um professor. Temos um conjunto de fotos com tags.
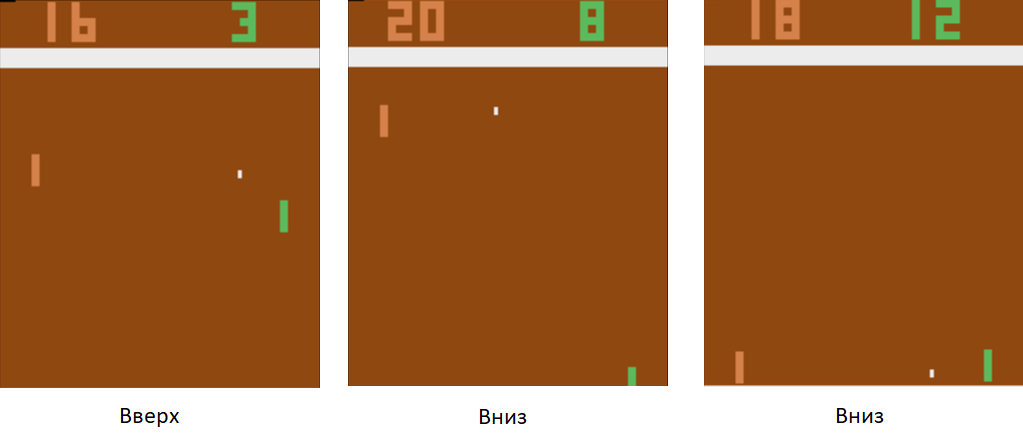
Usando essa técnica de treinamento, em algumas horas, nosso agente aprenderá a vencer um jogador de computador programado de acordo com as regras.
O que fazer com a condução autônoma? O fato é que o tênis de mesa é um jogo muito simples. E pode produzir milhares de quadros por segundo. Na nossa rede agora existem apenas 3 camadas. Portanto, o processo de aprendizado é extremamente rápido. O jogo gera uma enorme quantidade de dados e nós os processamos instantaneamente. No caso de direção autônoma, a coleta de dados é muito mais longa e mais cara. Os carros são caros e, com um carro, receberemos apenas 60 quadros por segundo. Além disso, o preço do erro aumenta. Em um videogame, poderíamos jogar um jogo após o outro no início do treinamento. Mas não podemos dar ao luxo de estragar o carro.
Nesse caso, vamos ajudar a rede neural no início do treinamento. Fixamos a câmera no carro, colocamos um motorista experiente e gravaremos fotos da câmera. Para cada imagem, assinamos o ângulo de direção do carro. Treinaremos a rede neural para copiar o comportamento de um motorista experiente. Assim, novamente reduzimos a tarefa ao ensino já conhecido com um professor.
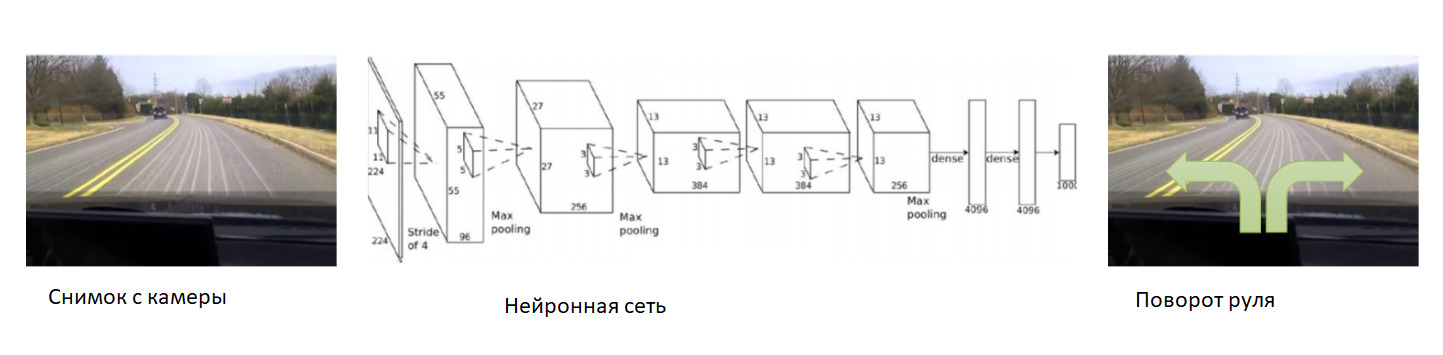
Com um conjunto de dados suficientemente amplo e diversificado, que incluirá diferentes paisagens, estações do ano e condições climáticas, a rede neural aprenderá como controlar com precisão o carro.
No entanto, houve um problema com os dados. Eles são muito longos e caros para colecionar. Vamos usar um simulador no qual toda a física do movimento do carro será implementada - por exemplo, o DeepDrive. Podemos aprender sem medo de perder um carro.

Neste simulador, temos acesso a todos os indicadores do carro e do mundo. Além disso, todas as pessoas, carros, suas velocidades e distâncias são marcadas.

Do ponto de vista do engenheiro, nesse simulador, você pode tentar com segurança novas técnicas de treinamento. O que um pesquisador deve fazer? Por exemplo, estudando diferentes opções para a descida do gradiente em problemas de aprendizagem com reforço. Para testar uma hipótese simples, não quero disparar pardais de um canhão e administrar um agente em um mundo virtual complexo e esperar dias seguidos pelos resultados da simulação. Nesse caso, vamos usar nosso poder de computação com mais eficiência. Deixe os agentes serem mais simples. Tomemos, por exemplo, um modelo de aranha quadrúpede. No simulador do Mujoco, é assim:

Estabelecemos a ele a tarefa de correr na velocidade mais alta possível em uma determinada direção - por exemplo, para a direita. O número de parâmetros observados para uma aranha é um vetor de 39 dimensões, que registra a posição e a velocidade de todos os seus membros. Ao contrário da rede neural para tênis de mesa, onde havia apenas um neurônio na saída, há oito na saída (já que a aranha neste modelo possui 8 articulações).
Em modelos tão simples, várias hipóteses sobre a técnica de ensino podem ser testadas. Por exemplo, vamos comparar a velocidade de aprender a correr, dependendo do tipo de rede neural. Seja uma rede neural de camada única, uma rede neural de três camadas, uma rede convolucional e uma rede recorrente:
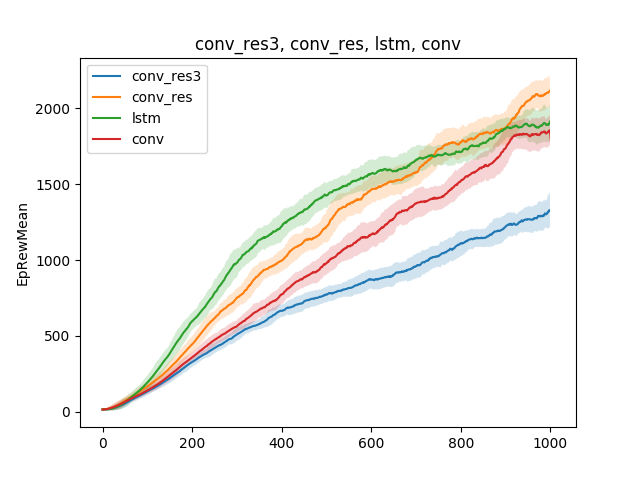
A conclusão pode ser tirada da seguinte forma: como o modelo de aranha e a tarefa são bastante simples, os resultados do treinamento são aproximadamente os mesmos para diferentes modelos. Uma rede de três camadas é muito complexa e, portanto, aprende pior.
Apesar de o simulador funcionar com um modelo simples de aranha, dependendo da tarefa colocada na aranha, o treinamento pode durar dias. Nesse caso, vamos animar várias centenas de aranhas em uma superfície ao mesmo tempo, em vez de uma, e aprender com os dados que receberemos de todos. Então, vamos acelerar o treinamento várias centenas de vezes. Aqui está um exemplo do mecanismo Flex.
A única coisa que mudou em termos de otimização de rede neural é a coleta de dados. Quando executamos apenas uma aranha, recebemos dados sequencialmente. Uma corrida atrás da outra.

Agora pode acontecer que algumas aranhas estejam apenas começando a corrida, enquanto outras já correm há muito tempo.
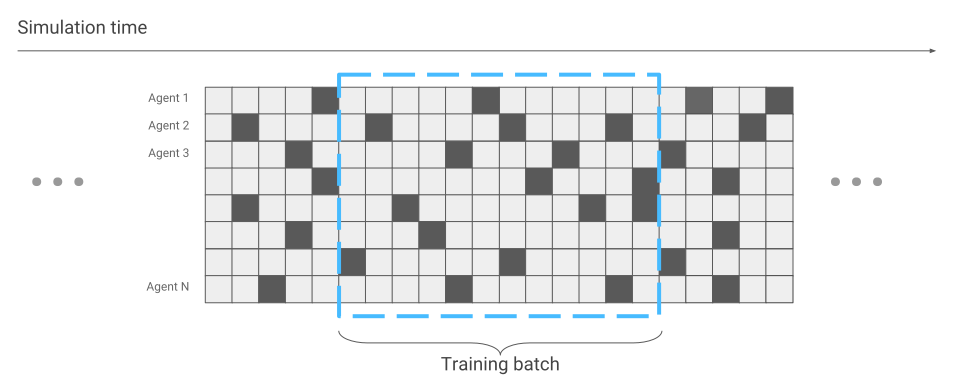
Isso será levado em consideração durante a otimização da rede neural. Caso contrário, tudo permanece o mesmo. Como resultado, temos aceleração no treinamento centenas de vezes, de acordo com o número de aranhas que estão simultaneamente na tela.
Como temos um simulador eficaz, vamos tentar resolver problemas mais complexos. Por exemplo, correndo sobre terrenos acidentados.

Como o ambiente nesse caso se tornou mais agressivo, vamos mudar e complicar tarefas durante o treinamento. É difícil de aprender, mas fácil na batalha. Por exemplo, a cada poucos minutos para mudar o terreno. Além disso, vamos direcionar agentes externos para o agente. Por exemplo, vamos jogar bolas nele e ligar e desligar o vento. Então o agente aprende a correr mesmo em superfícies que ele nunca conheceu. Por exemplo, suba escadas.

Como aprendemos com tanta eficácia a executar simulações, vamos verificar as técnicas de treinamento por reforço em disciplinas competitivas. Por exemplo, em jogos de tiro. A plataforma VizDoom oferece um mundo no qual você pode atirar, coletar armas e recuperar a saúde. Neste jogo também usaremos uma rede neural. Só agora ela terá cinco saídas: quatro para movimento e uma para fotografar.
Para que o treinamento seja eficaz, vamos levá-lo gradualmente. Do simples ao complexo. Na entrada, a rede neural recebe uma imagem e, antes de começar a fazer algo consciente, precisa aprender a entender em que consiste o mundo. Estudando em cenários simples, ela aprenderá a entender quais objetos habitam o mundo e como interagir com eles. Vamos começar com o traço:
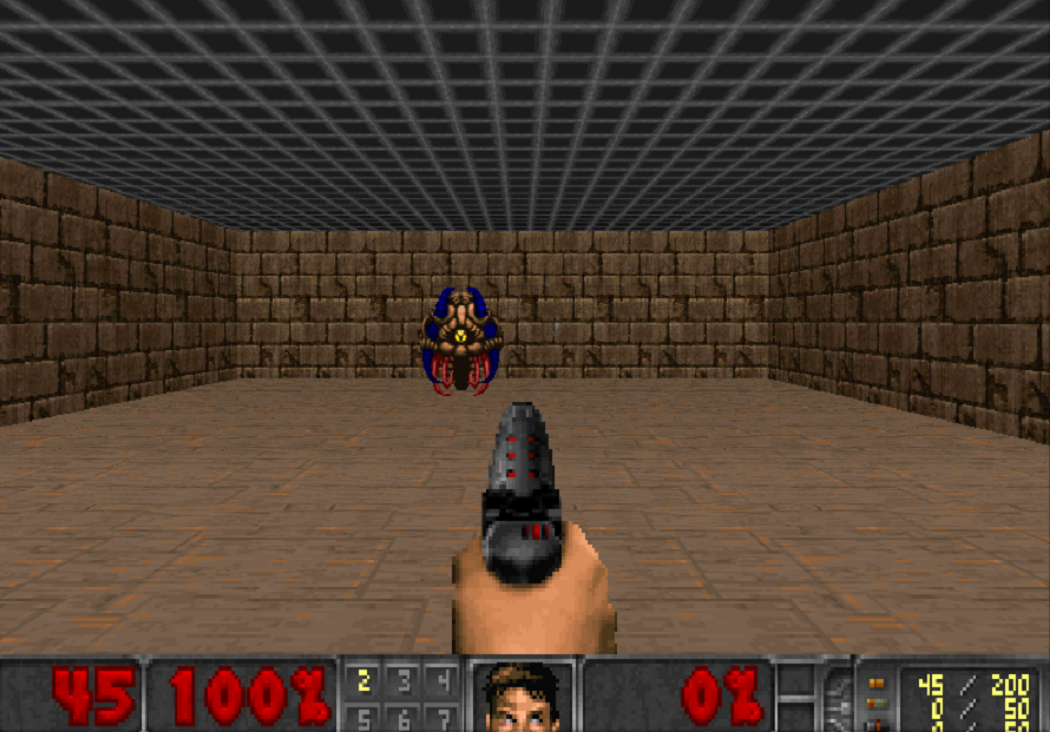
Tendo dominado esse cenário, o agente entenderá que existem inimigos e eles devem ser atingidos, porque você ganha pontos por eles. Em seguida, vamos treiná-lo em um cenário em que a saúde está constantemente diminuindo e você precisa reabastecer.

Aqui ele aprenderá que tem saúde e precisa ser reabastecido, porque, em caso de morte, o agente recebe uma recompensa negativa. Além disso, ele aprenderá que, se você se mover em direção ao sujeito, poderá coletá-lo. No primeiro cenário, o agente não pôde se mover.
E no terceiro cenário final, vamos deixá-lo para atirar com os bots programados nas regras do jogo para que ele possa aprimorar suas habilidades.

Durante o treinamento neste cenário, a seleção correta das recompensas que o agente recebe é muito importante. Por exemplo, se você der uma recompensa apenas aos rivais derrotados, o sinal será muito raro: se houver poucos jogadores por perto, receberemos pontos a cada poucos minutos. Portanto, vamos usar a combinação de recompensas que eram antes. O agente receberá uma recompensa por cada ação útil, seja para melhorar a saúde, selecionar cartuchos ou atingir um oponente.
Como resultado, um agente treinado com recompensas bem escolhidas é mais forte do que seus oponentes mais exigentes em termos computacionais. Em 2016, esse sistema venceu a competição VizDoom com uma margem de mais da metade dos pontos conquistados no segundo lugar. A equipe vice-campeã também usou uma rede neural, apenas com um grande número de camadas e informações adicionais do mecanismo de jogo durante o treinamento. Por exemplo, informações sobre se há inimigos no campo de visão do agente.
Examinamos abordagens para resolver problemas, onde é importante tomar decisões. Mas muitas tarefas com essa abordagem permanecerão sem solução. Por exemplo, o jogo de busca Montezuma Revenge.
Aqui você precisa procurar chaves para abrir as portas dos quartos vizinhos. Raramente recebemos chaves e abrimos salas com menos frequência. Também é importante não se distrair com objetos estranhos. Se você treinar o sistema, como fizemos nas tarefas anteriores, e recompensar os inimigos derrotados, ele simplesmente nocauteará o crânio rolante repetidamente e não examinará o mapa. Se você estiver interessado, posso falar sobre a solução desses problemas em outro artigo.
Você pode ouvir o discurso de Vladimir Ivanov na Conferência da AI em 22 de novembro . Um programa detalhado e ingressos estão disponíveis no
site oficial do evento.
Leia a entrevista com Vladimir
aqui .