Outra transcrição do relatório com
Pixonic DevGAMM Talks . Anton Kosyakin é gerente técnico de produtos e está trabalhando na plataforma ALICE (como Jira para hotéis). Ele contou como eles integraram as ferramentas de teste existentes no projeto, por que os testes de carga são necessários, quais ferramentas a comunidade oferece e como executar essas ferramentas na nuvem. Abaixo está uma apresentação e o texto do relatório.
Estamos criando um produto chamado ALICE Platform e agora vou lhe contar como eles resolveram o problema do teste de carga.

ALICE é Jira para hotéis. Estamos criando uma plataforma para ajudá-los a lidar com seu interior. Concierge, operador de recepção, faxineiros - eles também precisam de ingressos. Por exemplo: um convidado liga> diz que você precisa limpar a sala> o funcionário cria um ticket> os funcionários que limpam, sabem em quem a tarefa é executada> executar> alteram o status.
Como temos b2b, os números podem não ser impressionantes - apenas 1.000 hotéis, 5.000 DAUs. Para jogos, isso não é muito, mas para nós é muito legal, porque existem até 8 servidores de produtos e eles dificilmente conseguem lidar com esses 5 mil usuários ativos. Como coisas ligeiramente diferentes acontecem sob o capô - um monte de bancos de dados, transações, etc.

O mais importante: no ano passado, crescemos duas vezes, agora temos uma equipe de engenharia na região de 50 pessoas e planejamos dobrar a base de usuários em 2019. E este é o principal desafio que nos confronta.
Um exemplo da vida. Na sexta-feira à noite, depois de trabalhar uma semana de trabalho de 60 horas, às 23:00, terminei a última ligação, concluí rapidamente a apresentação, pulei no trem e vim para cá. E cerca de cinco minutos atrás, refiz um pouco minha apresentação. Então agora tudo funciona para nós, porque somos uma startup e é legal. Enquanto dirigia, parte da equipe técnica (chamamos de incêndio na produção) tentou garantir que o sistema não funcionasse e, ao mesmo tempo, os usuários não notassem isso. Eles tiveram sucesso e nós somos salvos.
Como você pode ver, até agora não dormimos muito bem à noite. Temos certeza de que nossa infraestrutura cairá. Enfrentamos a verdade e entendemos isso. Uma pergunta: quando? Foi assim que entendemos que o teste de carga é a chave da salvação. É com isso que precisamos nos preocupar.

Quais são nossos objetivos. Primeiro, precisamos entender agora exatamente a capacidade e o desempenho do nosso sistema, quão bem ele funciona para os usuários atuais. E isso deve acontecer antes que o usuário quebre o contrato conosco (e isso pode ser um cliente para 150 hotéis e muito dinheiro) devido ao fato de que algo não está funcionando ou é muito lento. Além disso, o departamento de vendas tem um plano: dobrar o crescimento no próximo ano. E aconteceu que compramos nosso principal concorrente e migramos seus usuários para nós mesmos.
E devemos saber que tudo isso pode suportar. Saiba com antecedência, antes que esses usuários cheguem e tudo caia.
Também fazemos lançamentos. Toda semana. Na segunda-feira. Obviamente, nem todas as versões estendem a funcionalidade, em algum lugar de manutenção, em algum lugar, mas é preciso entender que os usuários não perceberão isso e sua experiência não piorará.
Mas nós, como bons desenvolvedores, somos pessoas preguiçosas e não gostamos de trabalhar. Por isso, perguntaram à comunidade e ao Google quais serviços / soluções existem para teste de carga. Havia muitos deles. Existem algumas coisas simples, como o Apache Bench, que simplesmente chuta um site com centenas de threads em url. Existe uma versão maligna e estranha do Bees with Machine Guns, onde tudo é o mesmo, mas inicia as instâncias que voam e colocam seus aplicativos. Existe o JMeter, você pode escrever alguns scripts, rodar na nuvem.

Tudo parece estar bem, mas, depois de pensar, percebemos que realmente precisamos trabalhar e primeiro resolver vários problemas.

Primeiro, você precisa escrever cenários reais que simulem uma carga completa. Em alguns sistemas, é suficiente gerar chamadas aleatórias da API com dados aleatórios. No nosso caso, são cenários longos para o usuário: recebi uma ligação, abri uma tela, dirigi todos os dados (quem ligou para o que ele queria) e salvou. Em seguida, ele aparece no aplicativo móvel de outra pessoa que executará a solicitação. Não é a tarefa mais trivial.
E deixe-me lembrá-lo, lançamentos toda semana. A funcionalidade é atualizada, os scripts devem ser realmente relevantes. Primeiro você precisa escrevê-los e depois também apoiá-los.
Mas esse não era o maior problema. Veja flood.io por exemplo. Uma ferramenta legal, você pode executar o Selenium nele - é quando o Chrome é iniciado, você pode controlá-lo e ele executa algum tipo de script. Você pode executar scripts JMeter nele. Mas se quisermos executar o Selenium nos scripts do JMeter, tudo de repente se desfaz, porque os caras que o montaram tomaram várias decisões de arquitetura. Ou, por exemplo, alguns serviços podem executar o JUnit - é simples e direto, mas um desses serviços criou seu próprio JUnit e simplesmente ignora algumas coisas.

A questão da geração de carga é urgente, porque cada ferramenta pede à sua maneira de gerá-la. E mesmo quando você conseguiu garantir que os cenários fossem adequados, surge a pergunta: como executar 2-4 vezes mais? Parece ser: corra e está tudo bem. Mas não. Existem todos os tipos de IDs nessas solicitações - criamos algo, obtemos um novo ID, alteramos o ID antigo e o teste, que carrega a entidade por ID, altera seu campo para outro. E 10 testes que carregam a mesma entidade 10 vezes não são muito interessantes. Porque 10 vezes é necessário carregar entidades diferentes e dimensionar corretamente essa carga.
OK, queremos resolver o problema do teste de carga para entender exatamente quantos usuários o aplicativo suportará e que nossos planos são consistentes com os do departamento de vendas. Analisamos as soluções que estão no mercado e, em seguida, fizemos um inventário de nossas massas e palitos.
Como lançamos todas as semanas, naturalmente, automatizamos alguns testes - integração e outra coisa. Para isso, usamos pepino. Essa é uma estrutura de BDD para desenvolvimento orientado a comportamento. I.e. pedimos alguns scripts que consistem em etapas.

Nossa infraestrutura nos permitiu executar testes de integração e funcionais de dois modos: basta chutar o back-end, ajustar a API ou realmente executar o Chrome através do Selenium e gerenciá-lo.
Adoramos o NewRelic. Pode simplesmente monitorar o servidor, os principais indicadores. Ele se integra à JVM e intercepta todas as chamadas para os controladores e a API do Endpoint. Eles também têm uma solução para o navegador e, como temos a maioria das funcionalidades, ele também faz algo no navegador e fornece algum tipo de métrica.

Assim, você precisa juntar tudo. Já automatizamos os principais cenários. Nossos cenários (porque é como o BDD) imitam usuários reais e a carga é semelhante à produção real. Ao mesmo tempo, podemos escalá-lo. Como isso faz parte do processo de lançamento, ele é sempre atualizado.

Agora vamos usar qualquer ferramenta que esteja atualmente no mercado. Eles operam com as mesmas primitivas: http, API chama http, JSON, JUnit, só isso. Mas assim que tentamos aplicar nossos testes no pepino, eles fazem o mesmo, operam nas mesmas coisas, mas nada funciona. Começamos a pensar em como lidar com essa tarefa.
Uma pequena digressão, porque BDD não é um termo muito popular no desenvolvimento de jogos, é mais para soluções corporativas.

Todos os cenários realmente descrevem algum tipo de comportamento. O formato da descrição do cenário é muito simples: Dado, Quando, Então - em termos de BDD chamado Gherkin. Pepino para nós, usando anotações e atributos, mapeia isso para o código Java. Ele faz o que vê no cenário: você precisa dar uma maçã à pessoa, vamos encontrar um método no qual isso é implementado.
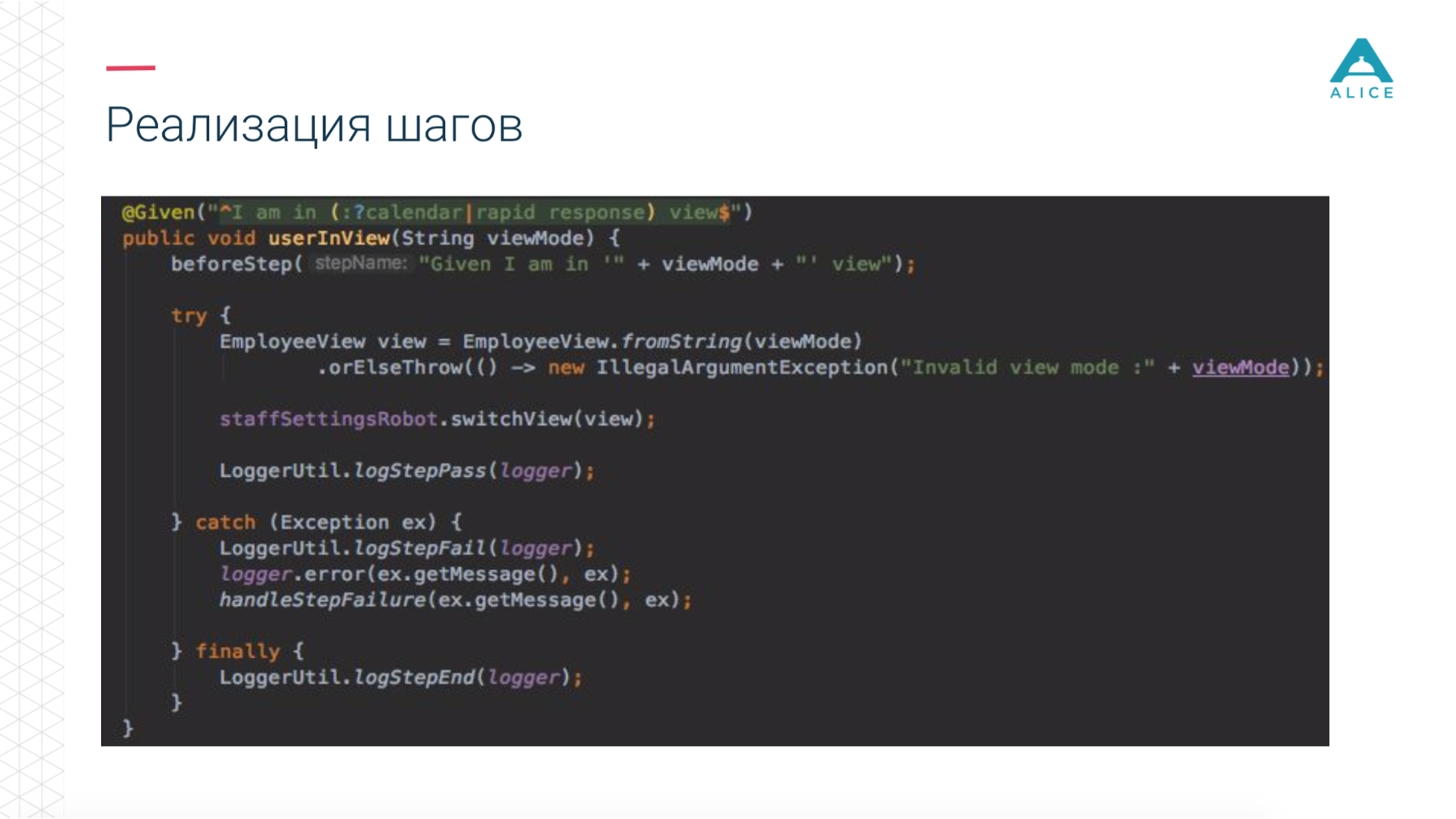
Em seguida, introduzimos um conceito como o Functional Robot. Este é um determinado cliente para a aplicação, possui métodos para efetuar login de um usuário, sair, criar um ticket, ver uma lista de tickets etc. E pode funcionar de três modos: com um aplicativo móvel, um aplicativo da Web e apenas faça chamadas de API.
Agora, em poucas palavras, a mesma coisa nos slides. Os arquivos de recursos são divididos em scripts, existem etapas e tudo isso está escrito em inglês.
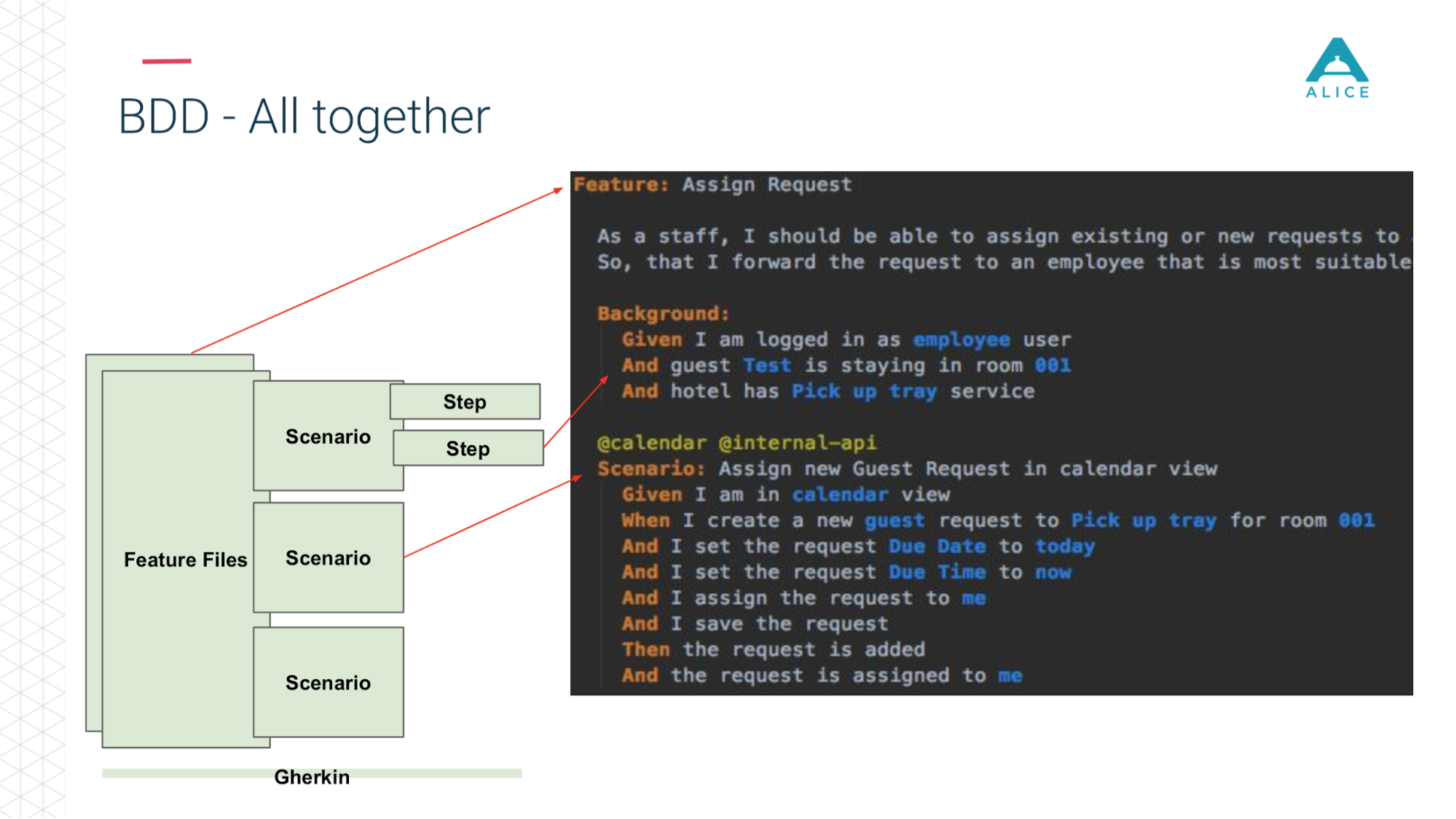
Em seguida, o Cucumber, o código Java, entra em ação, mapeia esses scripts para o código que está realmente em execução.
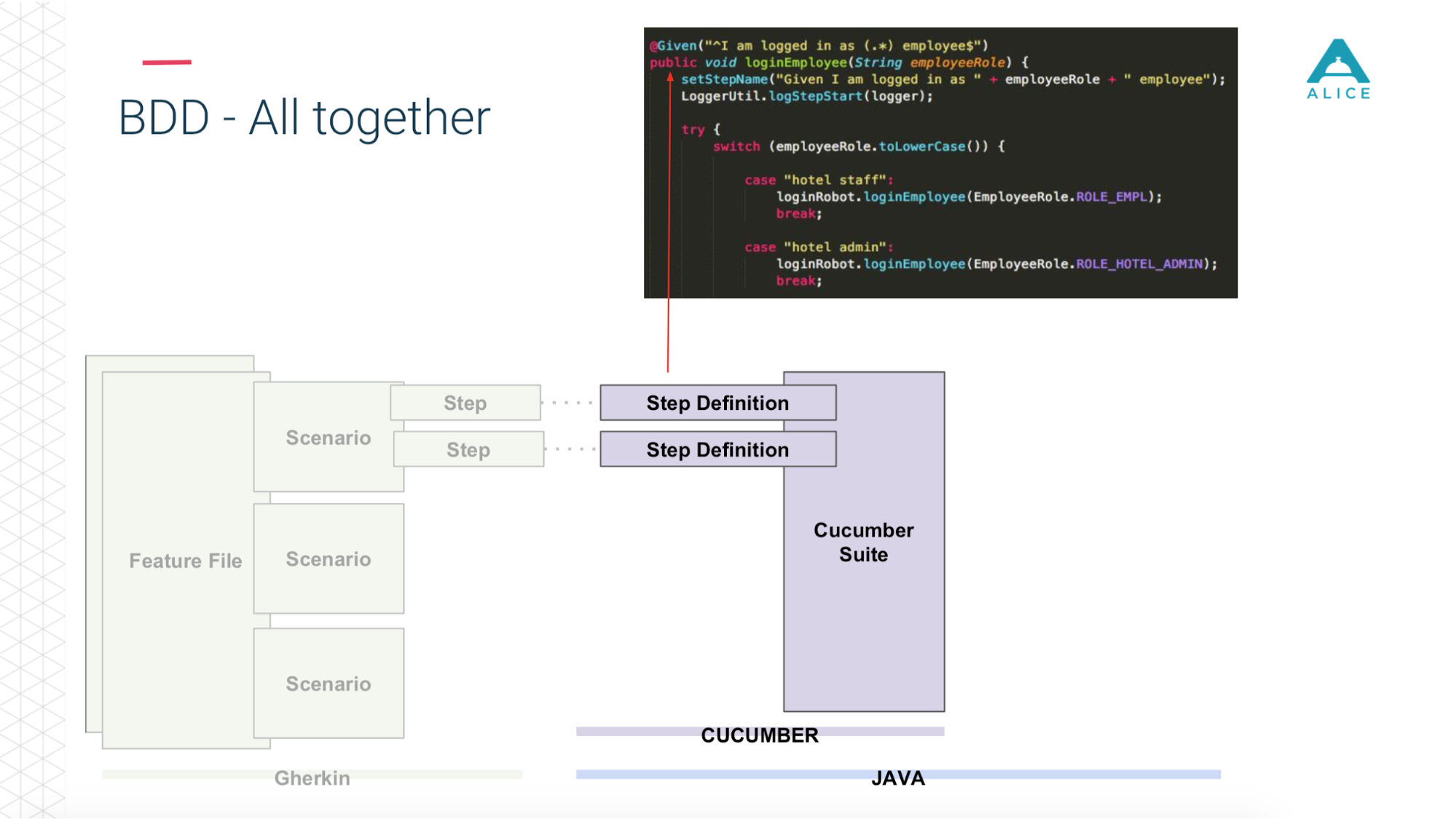
Este código usa nosso aplicativo.

E dependendo do que escolhemos: através do Selenium Chrome, acesse o aplicativo ALICE.

Ou a mesma coisa através da API http.
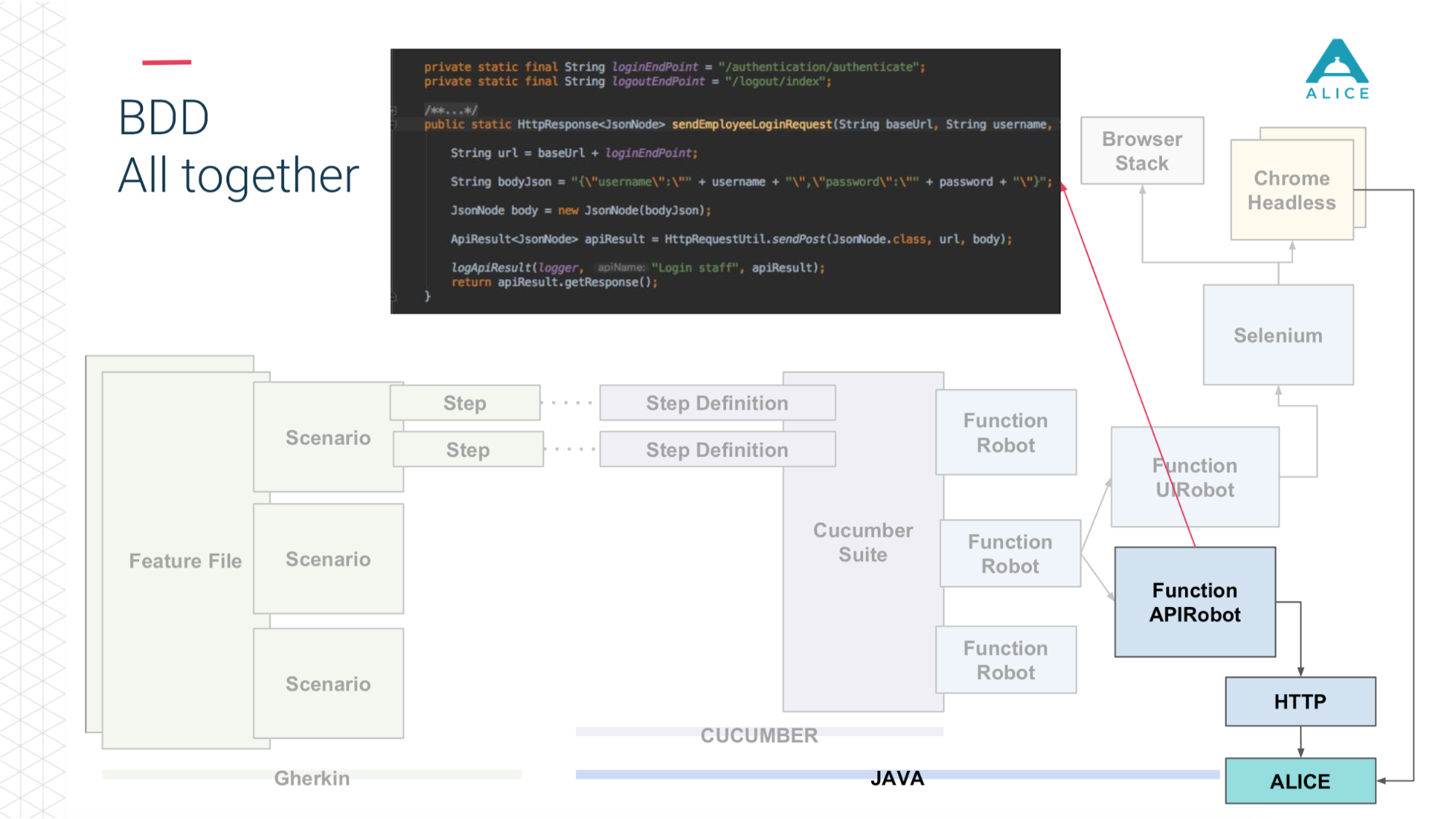
E então (graças aos caras da Yandex for Allure Reports) tudo isso é muito bem mostrado para nós - quanto tempo levou, quais testes foram executados, em que etapa e até aplicamos uma captura de tela se algo desse errado.
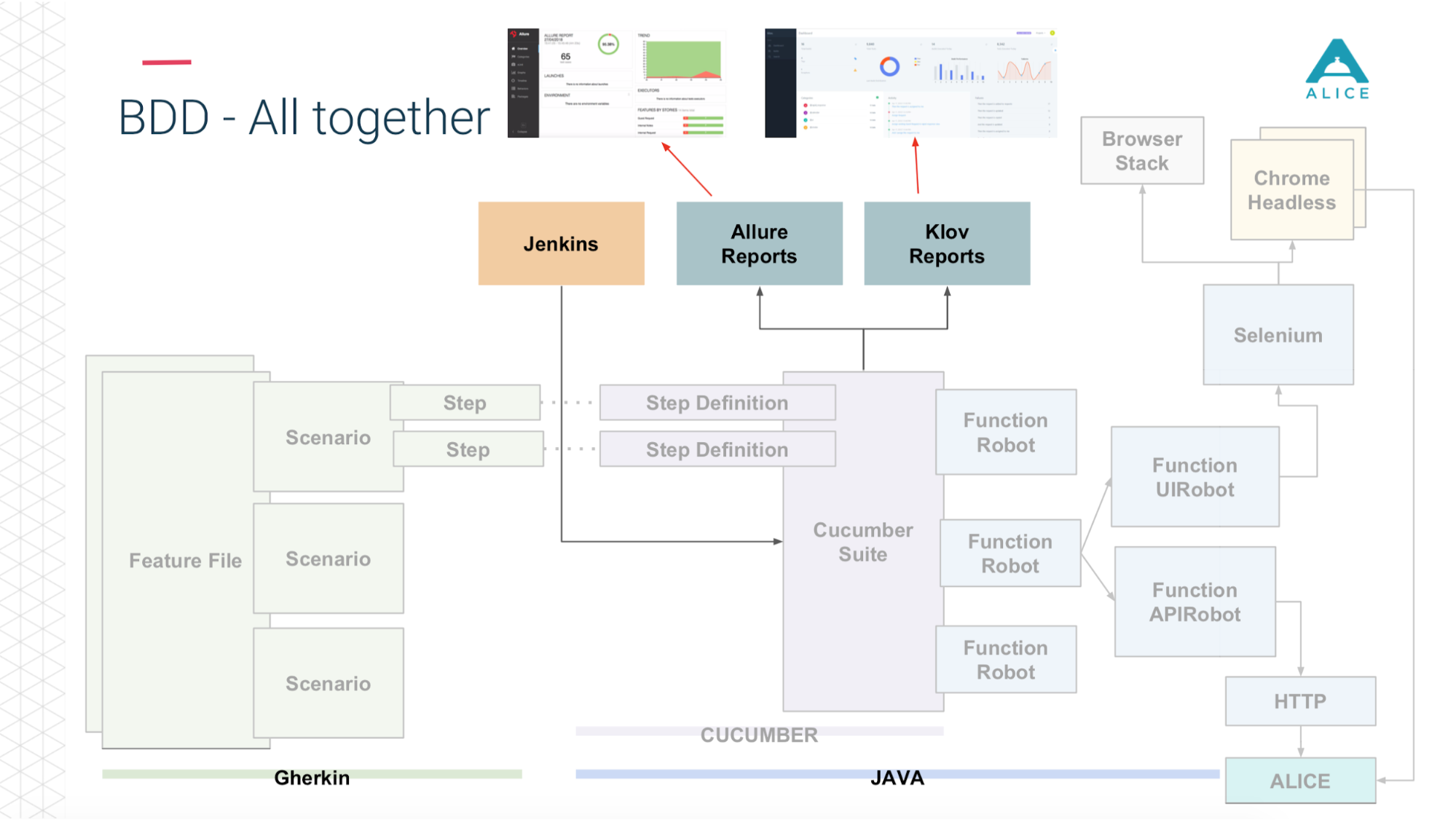
Aqui está um breve resumo do que já tínhamos.
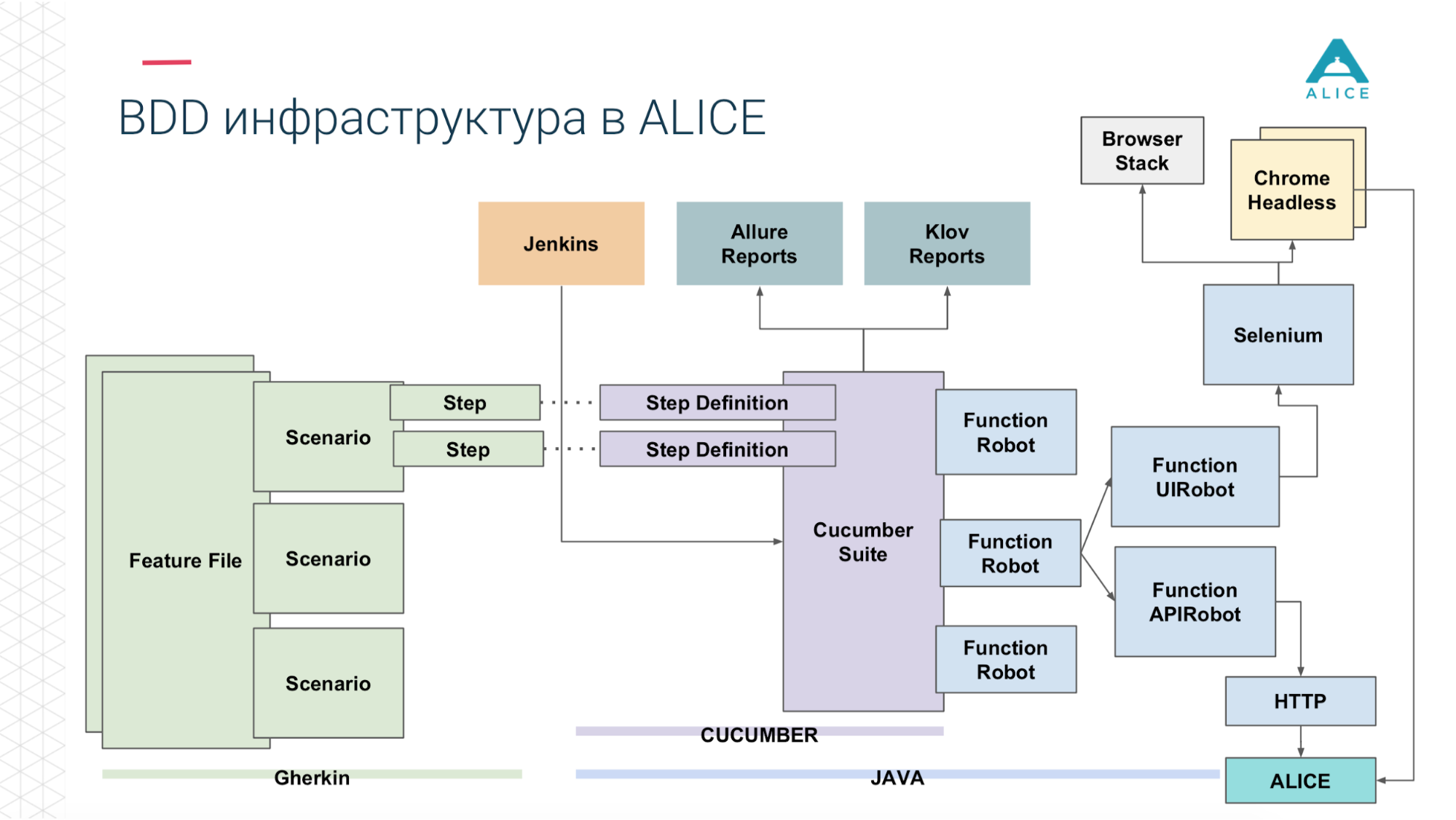
Como criar testes de carga a partir disso? Tínhamos Jenkins administrando a suíte Cucumber. Estes são os nossos testes e eles foram para o ALICE. Qual foi o principal problema? Jenkins executa testes localmente; não pode ser escalado para sempre. Sim, estamos hospedados na Amazon, na nuvem, podemos solicitar uma máquina extra-grande. De qualquer forma, em algum momento, entraremos, pelo menos, na rede. É necessário, de alguma forma, carregar essa carga. Obrigado Amazon, ele pensou por nós. Podemos empacotar nosso Cucumber Suite em um contêiner do Docker e usar o serviço da AWS (chamado Fargate) para dizer "e iniciá-los, por favor". O problema está resolvido, podemos executar nossos testes já na nuvem.

Então, como estamos na nuvem, execute o 5-10-20 Cucumber Suite. Mas há uma nuance: toda execução de todos os nossos testes funcionais gera um relatório. Uma vez executamos 400 testes e 400 relatórios foram gerados.
Obrigado novamente ao pessoal do Yandex pelo código-fonte aberto, lemos a documentação, o código-fonte e percebemos que existem maneiras de agregar todos os 400 relatórios em um. Corrigimos um pouco os dados, escrevemos algumas de nossas extensões e tudo deu certo.
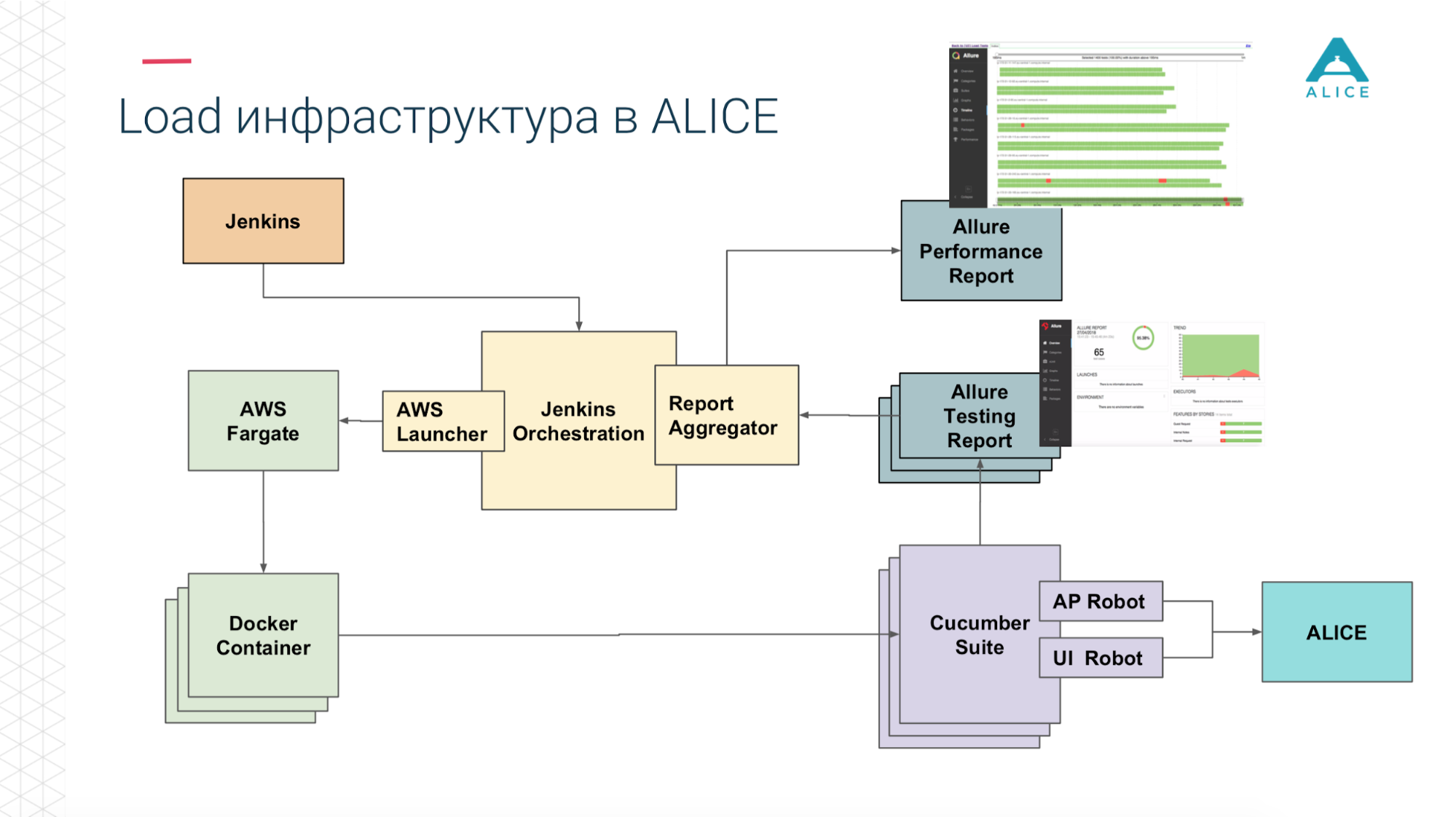
Agora, de Jenkins, dizemos "dê-nos 200 instâncias". Nosso script de orquestração certo vai para a Amazônia, diz "lançar 400 contêineres". Cada um deles contém nossos testes de integração, eles geram um relatório, o relatório é coletado através do Aggregator em uma única peça, colocada em Jenkins, aplicada ao trabalho, funciona super.
Mas
Tenho certeza de que muitos de vocês receberam coisas estranhas dos testadores, como "joguei um jogo, pulei 10 vezes; durante esse tempo, apertei o tiro e acidentalmente apertei o botão de desligar - o personagem começou a piscar, congelar no ar e depois o computador desligou, lidar com isso. " Você ainda pode concordar com uma pessoa e dizer, você sabe, é impossível se reproduzir. Mas temos máquinas sem alma, elas fazem tudo muito rapidamente e em algum lugar os dados não carregam, em algum lugar não são renderizados muito rapidamente, tentam pressionar um botão, mas ainda não há nenhum botão ou usam alguns dados que ainda não foram baixados do servidor . Tudo entra em colapso e o teste é falho. Embora (eu quero me concentrar nisso), temos o código Java que executa o Chrome, que se conecta a outro Java através de um wrapper e faz alguma coisa e ainda funciona com a velocidade da luz.
Bem, o problema óbvio resultante disso: temos 5 mil usuários e lançamos apenas 100 instâncias de nossos testes funcionais e criamos a mesma carga. Não é exatamente isso que queríamos, porque planejamos que no próximo mês teremos 6 mil usuários. É difícil entender essa carga, entender quantos threads iniciar.
OK, vamos humanizar nosso sistema. É assim que a interface do usuário se parece:

Alguém está ligando, o concierge quer pressionar o botão "criar um novo ticket", uma janela aparece para ele e ele precisa preencher todos os campos.
Mas isso não acontece instantaneamente. A pessoa real até que ele chegue ao mouse, até começar a digitar, até selecionar algo, enquanto clica em Salvar. Então, vamos desacelerar nossos testes.

Nós o chamamos de modo humano. Você só precisa medir quanto tempo dura o passo e dormir um pouco, se for muito rápido. Ao mesmo tempo, podemos medir quanto, em princípio, essa etapa levou - se 5 minutos, provavelmente a experiência do usuário está quebrada aqui.
Como tivemos alguns testes, não começamos a reescrever cada um deles. Eles pegaram o AspectJ, inseriram no nosso código, adicionaram mais 5 linhas de código, funciona muito bem.
Demonstração curta.


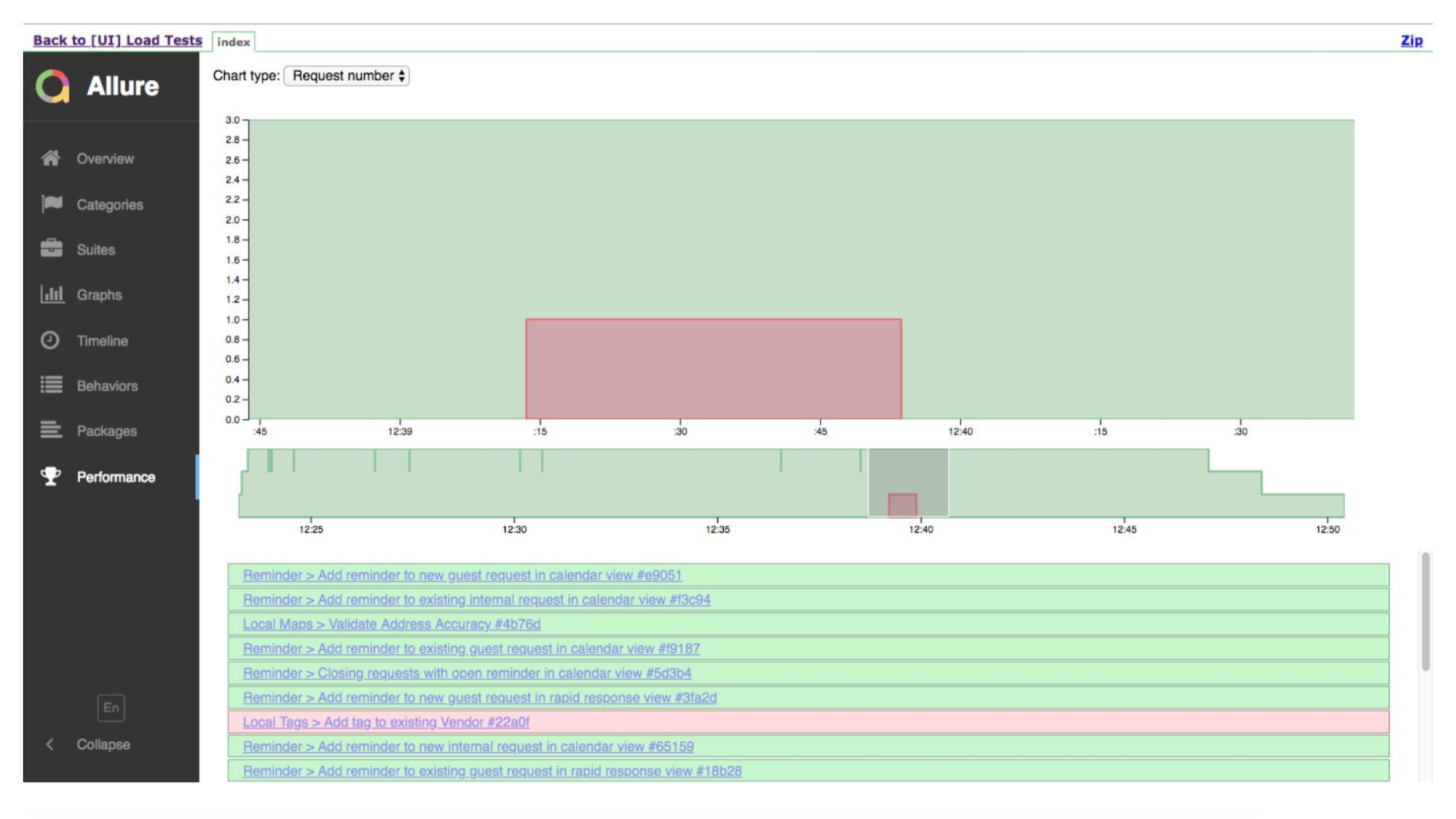
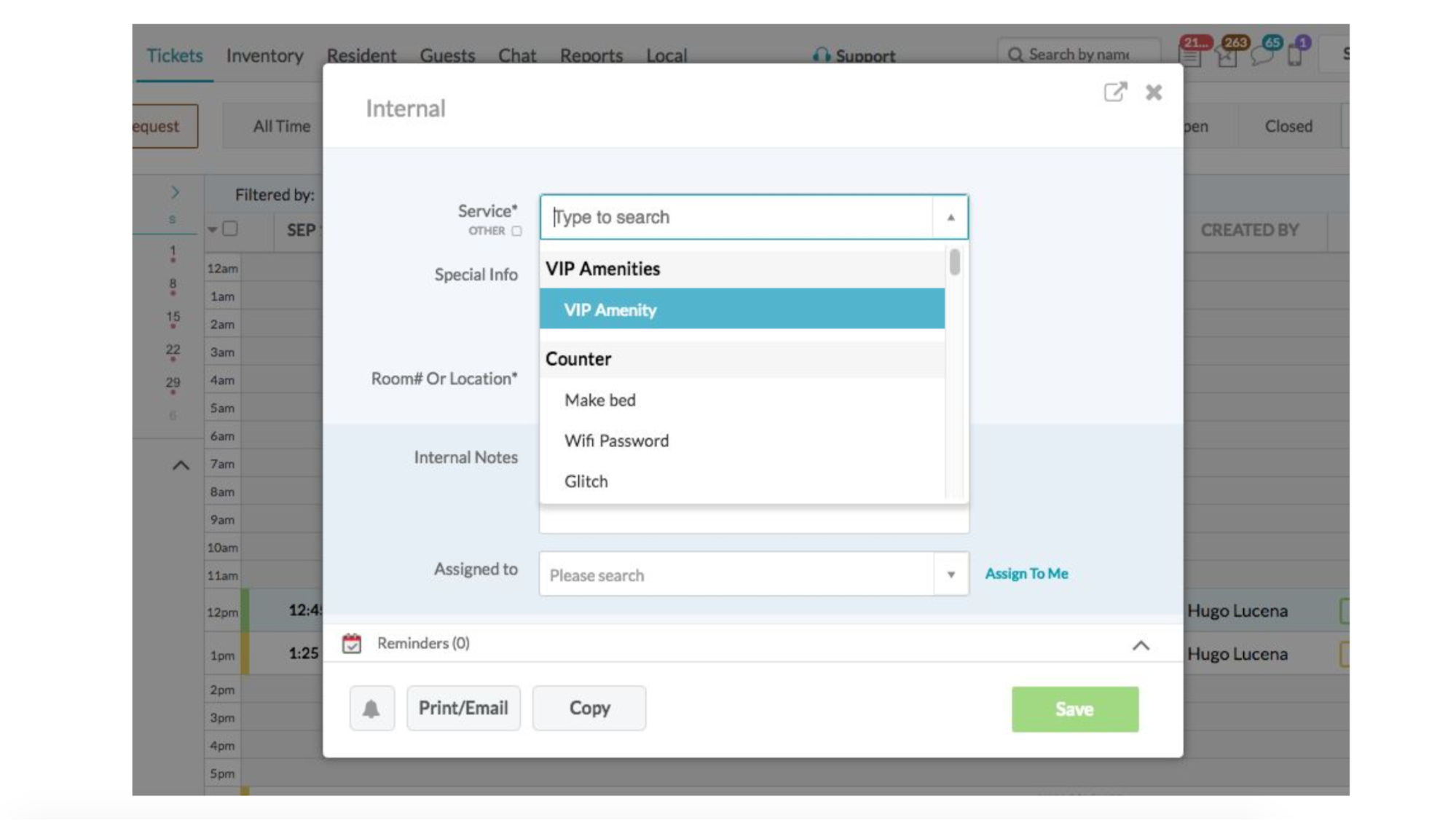
Esta é uma execução na linha do tempo. Testes verdes são bons, em algum lugar é ruim. Allure nos mostrará os detalhes de onde ele vira.
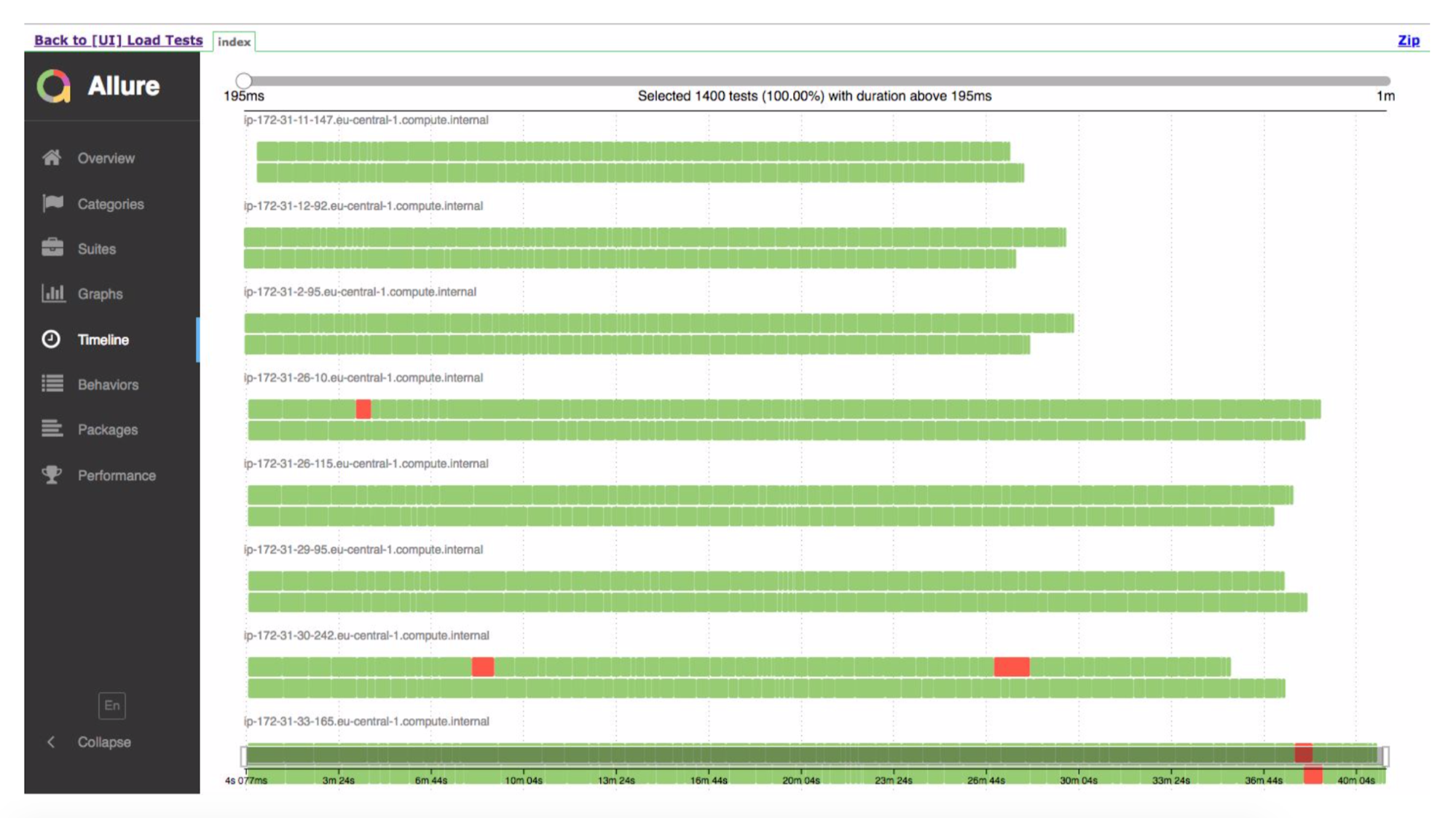
E aqui está a linha do tempo, mostrando que tivemos muitas instâncias. Eles fizeram um teste, em algum lugar algo caiu.
O sistema realmente funciona - na semana passada fizemos os primeiros testes na produção de combate.
Agora, sobre os próximos passos, como, acreditamos, pode ser aprimorado.

Mais importante, queremos que as pessoas tenham uma experiência legal do usuário. A idéia é que podemos gerar uma grande carga em nosso aplicativo e tudo parece simples - medimos trivialmente o desempenho de cada solicitação ao servidor, se ele continua a responder o mais rápido ou o início da redução de desempenho (o servidor começou a processar solicitações de entrada mais lentamente). Mas não. Na realidade, o cliente / aplicativo pode lançar várias solicitações ao servidor de uma só vez, em um monte. E espere até que todos sejam processados. E se uma das solicitações, a mais longa, como funcionou por 5 segundos e continuar a funcionar por 5 segundos, não nos importamos absolutamente com como todos os outros trabalham - com rapidez ou lentidão para 4 segundos. Afinal, ainda vamos esperar mais cinco segundos. Ou você criou um ticket, tudo funcionou em um milissegundo, mas o ticket apareceu no sistema tarde demais por causa dos caches internos do índice. A abordagem usual não resolverá esse problema; portanto, queremos tentar medir todos os cenários e ver o quanto o script de criação de tickets realmente piorou.
Porque temos todos os cenários baseados em chaves de acesso, podemos imitar executando uma pessoa na recepção e 10 produtos de limpeza. Então 20 ou 30 produtos de limpeza. Mas a frente do povo ainda é a mesma. I.e. podemos gerar uma carga real por padrões de comportamento, muito perto de uma carga realista.
Também testes multirregionais. Nosso sistema é usado em todo o mundo (embora tudo esteja hospedado na América) e, portanto, podemos gerar uma carga da Rússia e da América para ver qual deles começa a desacelerar mais rapidamente.
Perguntas da platéia
- Você é forçado a escrever uma grande quantidade de lógica e, quando algo muda um pouco, você quebra muitas coisas nos testes funcionais. Acontece que você leva quase mais tempo para apoiar os testes do que para desenvolver?"Sim, mas não." Este é o BDD, não são testes funcionais, estão mais próximos dos testes de integração. E o que quer que mudemos, o cenário continua o mesmo. Pressiono um botão, vejo uma janela, nele digito o número da sala com a qual o pedido foi recebido, o nome da pessoa e a data em que reservar uma mesa. Se o layout mudou, os campos mudaram de lugar, se algo acontecer no back-end, o teste será salvo, porque estamos em um nível muito alto, clicamos nos botões do navegador. Portanto, estamos protegidos de um grande número de alterações. Há momentos em que tudo pode quebrar. Portanto, no procedimento de lançamento, aqueles que escrevem um novo recurso - eles são responsáveis por ver que algo está quebrado e consertado. Mas até agora não houve tais problemas em grandes números.
- E você não teve uma situação em que, após uma mudança, todos os testes ficassem vermelhos.- Não foi. Teoricamente, isso pode acontecer se o script não tiver um botão, mas alguma outra maneira de abrir uma janela para inserir informações do ticket. Mas, como mostrei anteriormente, todos os nossos cenários consistem em etapas. As etapas são tudo, e se tivermos 100 scripts que clicam no mesmo botão, a etapa ainda será uma. E se tudo der errado por causa dessa etapa específica, nós a corrigimos, reescrevemos e todos os testes ficam verdes imediatamente.
Embora uma vez, quando quebramos algo acidentalmente, isso tenha acontecido conosco. Apenas 40% do verde permaneceu, embora antes disso fosse 99%. Essa foi uma pequena mudança. Corrigimos um passo (linha de código) e tudo ficou verde novamente.
- Embora você não tenha testes de integração, eles não são totalmente funcionais. De uma forma ou de outra, é algum tipo de interface gráfica em que os botões são pressionados, algum tipo de interação ocorre especificamente com o shell externo. Entendo que você tem testes neste formulário, basta iniciar muitos threads ao mesmo tempo. E por que eles não organizaram as solicitações geradas por ferramentas padrão: JMeter, Gatling, que não interagem com o shell externo de forma alguma, mas simplesmente enviam solicitações ao servidor?Tudo é muito simples. Qual é a arquitetura do nosso aplicativo? Temos um back-end, temos um front-end. Frontend é a web. Existe uma aplicação móvel. E quando eu crio um ticket, meu front-end é conectado, por exemplo, também aos servidores de eventos. Eu crio um ticket no back-end e todas as pessoas que estão sentadas no mesmo hotel observam os ingressos no mesmo hotel, elas chegam dos servidores de eventos: os caras atualizam, os dados mudam lá. E para juntar tudo, temos um único ponto - este é o cliente. Ele se conecta a um grande número de vários componentes e, se programamos com as mãos, criamos um ticket no back-end e, em seguida, nos conectamos ao servidor de eventos, registramos nele e aguardamos alguns eventos. Ou eles acabaram de lançar um navegador no qual tudo já foi montado, esse código já está escrito e fazemos tudo o que precisamos.
- Mas essas são abordagens diferentes? Ou trabalhamos especificamente com o servidor ou com a janela. Você pode simular solicitações para vários servidores ao mesmo tempo.- Foi por isso que eu disse que temos robôs funcionais chamados de testes. Há quem pega o Chrome e realiza cliques de alto nível. Existem aqueles que não clicam no botão, nada acontece, mas no momento da criação do ticket, ele envia uma solicitação ao servidor e podemos executar isso ou aquilo. Optamos por executar o Chrome por um motivo simples: queremos simular usuários reais, da maneira como eles realmente o usam. Enquanto sua página estava carregando, enquanto tudo era renderizado para ele, enquanto os scripts Java e assim por diante funcionavam. Queremos estar o mais próximo possível do usuário, e essa é a Web real.
- Mas muitas coisas dependerão de que tipo de usuário a Internet é, qual ambiente. Mas, especificamente, a operação do aplicativo dependerá de você e do seu lado. , : - ?— , - . , , , . , , . YouTube , . , . , .
— . - Selenium Grid ? - .— Cucumber': JAR, JAR Docker image Fargate' , image . flood.io grid Selenium , .
— ? , Chrome, . Internet Explorer 4 ( - ), ? - Android -.— , enterprise. enterprise , requirements. — , , web view. Android web view , .
— , , Load-? ?— .
Environment . . , Load, . 4- , , aliceapp.com. Load- , . , 504, , MySQL ElasticSearch.
— ( ), , ? .— Load- , . I.e. .
— , ?— , . , , , .
— , , .. html API?— Selenium DOM- : , , key down , — . .
— ? , ?— . , . QC, , QC. Smoke- -. « -, ». — , , , .
Pixonic DevGAMM Talks