
Aqui está o primeiro livro originalmente em russo no qual os segredos do processamento de big data (Big Data) nas nuvens são examinados com exemplos reais.
O foco está nas soluções Microsoft Azure e AWS. Todas as etapas do trabalho são consideradas - obtenção de dados preparados para processamento na nuvem, usando armazenamento em nuvem, ferramentas de análise de dados em nuvem. É prestada atenção especial aos serviços SAAS; são demonstradas as vantagens das tecnologias em nuvem em comparação com as soluções implantadas em servidores dedicados ou máquinas virtuais.
O livro foi projetado para um amplo público e servirá como um excelente recurso para o desenvolvimento do Azure, Docker e outras tecnologias indispensáveis, sem as quais as empresas modernas são impensáveis.
Nós convidamos você a ler a passagem "Download direto de dados de streaming"
10.1 Arquitetura geral
No capítulo anterior, examinamos a situação em que muitos aplicativos clientes devem enviar um grande número de mensagens que precisam ser processadas dinamicamente, colocadas no repositório e processadas novamente nele. Ao mesmo tempo, você deve poder alterar a lógica do fluxo de processamento e armazenamento de dados sem recorrer à alteração do código do cliente. E, finalmente, do ponto de vista das razões de segurança, os clientes devem ter o direito de fazer apenas uma coisa: enviar mensagens ou recebê-las, mas de maneira alguma ler dados ou excluir bancos de dados, e eles não devem ter direitos diretos para gravar esses dados.
Essas tarefas são muito comuns em sistemas que trabalham com dispositivos IoT conectados por meio de uma conexão à Internet, bem como em sistemas de análise de log online. Além dos requisitos listados acima para o nosso serviço dedicado, há mais dois requisitos relacionados às especificidades da “Internet das Coisas” e para garantir o processamento confiável de mensagens. Antes de tudo, o protocolo de interação entre o cliente e o receptor de serviço deve ser muito simples, para que possa ser implementado em um dispositivo com recursos de computação limitados e memória muito limitada (por exemplo, Arduino, Intel Edison, STM32 Discovery e outras plataformas "inadequadas", como como antes de RaspberryPi). O próximo requisito é a entrega confiável de mensagens, independentemente de possíveis falhas nos serviços de processamento. Este é um requisito mais forte do que o requisito de alta confiabilidade. De fato, para garantir a confiabilidade geral de todo o sistema, é necessário que a confiabilidade de todos os seus componentes seja alta o suficiente e a adição de um novo componente não leve a um aumento perceptível no número de falhas. Além da falha na infraestrutura da nuvem, pode ocorrer um erro no serviço criado pelo usuário. E mesmo assim, a mensagem deve ser processada assim que o serviço do usuário for restaurado. Para fazer isso, o serviço de recebimento de fluxo de mensagens deve armazenar de forma confiável a mensagem até que seja processada ou até que sua vida útil expire (isso é necessário para evitar o estouro de memória durante um fluxo de mensagens contínuo). Um serviço com essas propriedades é chamado de Hub de Eventos. Para dispositivos IoT, existem hubs especializados (Hub IoT), que possuem várias outras propriedades que são muito importantes para uso em conjunto com os dispositivos Internet das Coisas (por exemplo, comunicação bidirecional a partir de um ponto, roteamento de mensagens interno, "dobras digitais" do dispositivo e várias outros). No entanto, esses serviços ainda são especializados e não os consideraremos em detalhes.
Antes de prosseguirmos para o conceito de concentração de mensagens, passemos às idéias subjacentes a ele.
Suponha que tenhamos uma fonte de mensagem (por exemplo, solicitações de um cliente) e um serviço que deve lidar com elas. O processamento de uma única solicitação leva tempo e requer recursos computacionais (CPU, memória, IOPS). Além disso, durante o processamento de uma solicitação, as solicitações restantes não podem ser processadas. Para que os aplicativos clientes não congelem enquanto aguardam o lançamento de um serviço, é necessário separá-los com a ajuda de um serviço adicional que será responsável por armazenar mensagens enquanto aguardam o processamento na fila. Essa separação também é necessária para aumentar a confiabilidade geral do sistema. De fato, o cliente envia uma mensagem ao sistema, mas o serviço de processamento pode "cair", mas a mensagem não deve ser perdida, deve ser armazenada em um serviço mais confiável que o serviço de processamento. A versão mais simples desse serviço é chamada de fila (Fig. 10.1).
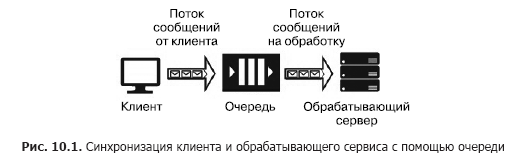
O serviço de fila funciona da seguinte maneira: o cliente conhece o URL da fila e possui chaves de acesso. Usando o SDK ou API da fila, o cliente coloca uma mensagem que contém o carimbo de data / hora, o identificador e o corpo da mensagem com uma carga útil no formato JSON, XML ou binário.
O código do programa do serviço inclui um ciclo que "escuta" a fila, recuperando a próxima mensagem a cada etapa e, se houver uma mensagem na fila, ela é extraída e processada. Se o serviço processar com êxito a mensagem, ela será removida da fila. Se ocorrer um erro durante o processamento, ele não será excluído e poderá ser processado novamente quando uma nova versão do serviço, com o código corrigido, for iniciada. A fila foi projetada para sincronizar um cliente (ou um grupo de clientes semelhantes) e exatamente um serviço de processamento (embora o último possa estar localizado em um cluster de servidores ou em um farm de servidores). Os Serviços de Enfileiramento em Nuvem incluem a Fila de Armazenamento do Azure, a Fila do Barramento de Serviço do Azure e o AWS SQS. Os serviços hospedados em máquinas virtuais incluem RabbitMQ, ZeroMQ, MSMQ, IBM MQ, etc.
Diferentes serviços de fila garantem diferentes tipos de entrega de mensagens:
- Entrega de mensagem pelo menos uma vez
- entrega estritamente única;
- entrega de mensagens enquanto mantém a ordem;
- entrega da mensagem sem manter a ordem.
A fila fornece entrega confiável de mensagens de uma fonte para um serviço de processamento, ou seja, interação um a um. Mas e se for necessário fornecer a entrega de mensagens a vários serviços? Nesse caso, você precisa usar um serviço chamado "tópico" (tópico) (Fig. 10.2).
Um elemento importante dessa arquitetura é "assinaturas". Este é o caminho registrado na seção em que a mensagem é enviada. As mensagens são publicadas no tópico pelo cliente e transferidas para uma das assinaturas, da qual são extraídas por um dos serviços e processadas por ele. Os tópicos fornecem uma arquitetura de interação um para muitos no atendimento ao cliente. Exemplos de tais serviços incluem o Tópico do Barramento de Serviço do Azure e o AWS SNS.
Agora, suponha que haja um grande número de clientes heterogêneos que precisem enviar muitas mensagens para vários serviços, ou seja, precisamos criar um sistema de interação muitos para muitos. Obviamente, essa arquitetura pode ser construída usando várias seções, mas essa construção não é escalável e requer esforço de administração e monitoramento. No entanto, existem serviços separados - concentradores de mensagens (Fig. 10.3).
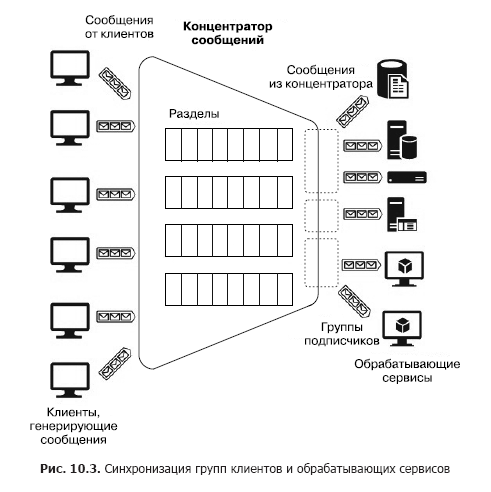
O hub aceita mensagens de muitos clientes. Todos os clientes podem enviar mensagens para um terminal em serviço comum ou conectar-se separadamente a terminais diferentes por meio de chaves especiais. Essas chaves permitem gerenciar clientes com flexibilidade: desconectar alguns, conectar novos, etc. Dentro do hub, também existem partições. Porém, nesse caso, eles podem ser distribuídos entre todos os clientes para aumentar a produtividade (round robin - “com adição cíclica”) ou o cliente pode publicar mensagens em uma das seções. Por outro lado, os serviços de processamento são combinados em grupos de consumidores. Um ou vários serviços podem ser conectados a um grupo. Portanto, um concentrador de mensagens é o serviço mais flexível que pode ser configurado como uma fila, seção ou grupo de filas ou um conjunto de seções. Em geral, um concentrador de mensagens fornece um relacionamento muitos para muitos entre clientes e serviços. Esses hubs incluem Apache Kafka, Azure Event Hub e AWS Kinesis Stream.
Antes de analisar os serviços PaaS baseados na nuvem, prestaremos atenção a um serviço muito poderoso e conhecido - Apache Kafka. Em ambientes em nuvem, ele pode ser acessado como uma distribuição implantada diretamente em um cluster de máquina virtual ou usando o serviço HDInsight. Portanto, o Apache Kafka é um serviço que fornece os seguintes recursos:
- Postando e assinando um fluxo de mensagens
- armazenamento confiável de mensagens;
- Aplicação de serviços de processamento de mensagens de streaming de terceiros.
Fisicamente, o Kafka é executado em um cluster de um ou mais servidores. Kafka fornece uma API para interagir com clientes externos (Fig. 10.4).
Considere essas APIs em ordem.
- As APIs do fornecedor permitem que os aplicativos clientes publiquem fluxos de mensagens em um ou mais tópicos Kafka.
- As APIs do consumidor oferecem aos aplicativos clientes a capacidade de assinar um ou mais tópicos e processar os fluxos de mensagens entregues pelos tópicos aos clientes.
- As APIs do processador de fluxo permitem que os aplicativos interajam com o cluster Kafka como um processador de fluxo. As fontes para um processador podem ser um ou mais tópicos. Nesse caso, as mensagens processadas também são colocadas em um ou mais tópicos.
- As APIs do conector ajudam a conectar fontes de dados externas (por exemplo, RDB) como fontes de mensagens (por exemplo, é possível interceptar eventos de alteração de dados no banco de dados) e como receptores.
No Kafka, a interação entre clientes e o cluster ocorre via TCP, o que é facilitado pelos SDKs existentes para várias linguagens de programação, incluindo .Net. Mas as linguagens básicas do SDK são Java e Scala.
Em um cluster, o armazenamento de fluxos de mensagens (na terminologia Kafka também chamada de entradas) ocorre logicamente em objetos chamados tópicos (Fig. 10.5). Cada registro consiste em uma chave, um valor e um carimbo de data / hora. Em essência, um tópico é uma sequência de registros (mensagens) que foram publicados pelos clientes. Os tópicos Kafka suportam de 0 a vários assinantes. Cada tópico é representado fisicamente como um log particionado. Cada seção é uma sequência ordenada de registros, à qual novos novos que chegam à entrada do Kafka são constantemente adicionados.
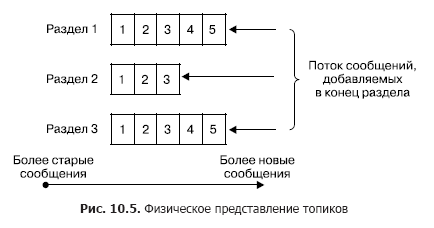
Cada entrada na seção corresponde a um número na sequência, também chamado de deslocamento, que identifica exclusivamente essa mensagem na sequência. Diferentemente da fila, o Kafka exclui a mensagem não após o processamento do serviço, mas após a vida útil das mensagens. Essa é uma propriedade muito importante, oferecendo a capacidade de ler de um tópico para diferentes consumidores. Além disso, um viés está associado a cada consumidor (Fig. 10.6). E cada ato de leitura leva apenas a um aumento no valor de cada cliente individualmente e é determinado precisamente pelo cliente.
No caso normal, esse deslocamento aumenta em um após a leitura bem-sucedida de uma mensagem do tópico. Mas, se necessário, o cliente pode mudar esse deslocamento e repetir a operação de leitura.
O uso do conceito de seções tem os seguintes objetivos.
Primeiramente, as seções fornecem a capacidade de escalar tópicos quando um tópico não se encaixa no mesmo nó. Ao mesmo tempo, cada seção possui um nó inicial (não o confunda com o nó principal de todo o cluster) e zero ou vários nós seguidores. O nó principal é responsável pelo processamento das operações de leitura / gravação, enquanto os seguidores são suas cópias passivas. Se o nó principal falhar, um dos nós sucessores se tornará automaticamente o nó principal. Cada nó do cluster é o principal para algumas seções e um seguidor para outras. Em segundo lugar, essa replicação aumenta o desempenho da leitura devido à possibilidade de operações de leitura paralela.
O produtor pode colocar a mensagem em qualquer tópico de sua escolha explicitamente ou no modo round robin implicitamente (ou seja, com preenchimento uniforme). Os consumidores estão unidos nos chamados grupos de consumidores, e cada mensagem publicada no tópico é entregue a um cliente em cada grupo de consumidores. Nesse caso, os clientes podem ser hospedados fisicamente em um ou mais servidores / máquinas virtuais. Em mais detalhes, a entrega da mensagem é a seguinte. Para todos os clientes pertencentes ao mesmo grupo de consumidores, as mensagens podem ser distribuídas entre os clientes para otimizar a carga. Se os clientes pertencerem a diferentes grupos de consumidores, cada mensagem será enviada para cada grupo. A separação das mensagens das seções por diferentes grupos de consumidores é mostrada na Fig. 10.7
Agora, descreverei brevemente os principais parâmetros de entrega e armazenamento de mensagens garantidos pelo Kafka.
- As mensagens enviadas pelo fabricante para um tópico específico serão adicionadas estritamente na ordem em que foram enviadas.
- O cliente vê a ordem das mensagens no tópico que foi recebido quando as mensagens foram salvas. Como resultado, as mensagens são entregues do produtor ao consumidor estritamente na ordem em que são recebidas.
- A replicação dobrada em N do tópico garante a estabilidade do tópico à falha de nós N - 1 sem perda de desempenho.
Portanto, o serviço Apache Kafka pode ser usado nos seguintes modos.
- Serviço - intermediário de mensagens (fila) ou serviço de publicação - assinatura de mensagens (tópico). De fato, o Kafka é baseado em um grupo de tópicos que podem ser convertidos em uma fila com um assinante. (Deve-se lembrar: em contraste com os serviços habituais de intermediários de mensagens, criados com base no princípio das filas, as mensagens Kafka são excluídas somente após o término de sua vida útil, enquanto os intermediários implementam o princípio Peek-Delete, ou seja, recuperação e exclusão após o processamento bem-sucedido. ) O princípio dos grupos de consumidores resume esses dois conceitos, e a capacidade de publicar mensagens em todos os tópicos com a distribuição de round robin faz do Kafka um intermediário universal de mensagens multimodo.
- Serviço para análise de mensagens de streaming. Isso é possível graças à API para processadores de streaming incluídos no Kafka, que permite criar sistemas complexos, criados com base no Event Driven, com serviços que filtram mensagens ou respondem a elas, além de serviços que agregam mensagens.
Todas essas propriedades possibilitam o uso do Kafka como um componente-chave de uma plataforma que trabalha com dados de streaming e possui ótimos recursos para criar sistemas complexos de processamento de mensagens. Mas, ao mesmo tempo, o Kafka é bastante complicado em termos de implantação e configuração de um cluster de vários nós, o que requer um esforço administrativo significativo. Mas, por outro lado, como as idéias subjacentes ao Kafka são muito adequadas para criar sistemas, transmitir mensagens e receber mensagens, os provedores de nuvem fornecem serviços de PaaS que implementam essas idéias e ocultam todas as dificuldades de criar e administrar um cluster Kafka. Porém, como esses serviços têm várias restrições em termos de personalização e expansão além dos limites alocados para os serviços, os provedores de nuvem fornecem serviços especiais de IaaS / PaaS para a implantação física do Kafka em um cluster de máquina virtual. Nesse caso, o usuário tem quase total liberdade de configuração e expansão. Esses serviços incluem o Azure HDInsight. Já foi mencionado acima. Foi criado para, por um lado, fornecer ao usuário serviços do ecossistema Hadoop por conta própria, sem invólucros externos e, por outro lado, para aliviar as dificuldades decorrentes da instalação, administração e configuração diretas do IaaS. A hospedagem no Docker é um pouco distante. Como esse é um tópico extremamente importante, vamos considerá-lo, mas primeiro familiarize-se com os serviços de PaaS implementados usando os conceitos básicos do Kafka.
10.2 Hub de eventos do Azure
Considere o serviço de hub de mensagens do Azure Event Hub. É um serviço criado no modelo PaaS. Vários grupos de clientes podem atuar como fontes de mensagens para o Hub de Eventos do Azure (Figura 10.8). Antes de tudo, esse é um grupo muito grande de serviços em nuvem cujas saídas ou gatilhos podem ser configurados para enviar mensagens diretamente para o Hub de Eventos. Estes podem ser Trabalho de Stream Analytics, Grade de Eventos e um grupo significativo de serviços que redirecionam eventos - logs no Hub de Eventos (principalmente, criados usando o AppService: App da API, aplicativo da Web, aplicativo móvel e aplicativo de funções).
As mensagens entregues ao hub podem ser capturadas diretamente e armazenadas no Blob Storage ou no Data Lake Store.
O próximo grupo de fontes são clientes ou dispositivos externos de software para os quais não há SDK do Azure Event Hub e que não podem ser integrados diretamente aos serviços do Azure. Esses clientes incluem principalmente dispositivos de IoT. Eles podem enviar mensagens para o Hub de Eventos via HTTPS ou AMQP. A consideração de como conectar esses dispositivos está além do escopo de nosso livro.
Por fim, os clientes de software que geram mensagens e as enviam para o Hub de Eventos usando o SDK do Hub de Eventos do Azure. Este grupo inclui o Azure PowerShell e a CLI do Azure.
Como receptores de mensagens (consumidores - “consumidores”) do Hub de Eventos, o Trabalho do Stream Analytics ou o serviço de integração de Grade de Eventos podem ser usados. Além disso, é possível receber mensagens de clientes de software usando o Azure Event Hub SDK. Os consumidores se conectam ao Hub de Eventos usando o protocolo AMQP 1.0.
Considere os conceitos básicos do Hub de Eventos do Azure necessários para entender como usá-lo e configurá-lo. Qualquer fonte (também chamada de publisher na documentação) que envia uma mensagem ao hub deve usar o protocolo HTTPS ou AMQP 1.0. A escolha de um protocolo é determinada pelo tipo de cliente, pela rede de comunicação e pelos requisitos da taxa de mensagens. O AMQP requer uma conexão permanente entre dois soquetes TCP bidirecionais. É protegido usando o protocolo de criptografia da camada de transporte TLS ou SSL / TLS. , , AMQP , HTTPS, . HTTPS.
, SAS (Shared Access Signature) tokens. SAS- SAS . SAS-, ( ).
256 . , .
, Event Hub. , , , -. EventHub (partitions). EventHub — , « — » (FIFO) (. 10.9).
— Event Hub. Event Hub 2 32 , Event Hub. , .
( ) , ( , — . ), (retention period), . . . , Azure Event Hub (offset). — , , , , . . Azure Event Hub SDK , , . -, .
, , , , . Azure Event Hub SDK , . , Storage Account. Azure, Event Hub, .
Event Hub (partition key), . — . , ( ) . , (round robin).
. , (consumer group) (. 10.11). . (view) ( ) , , . , . — 20, , .
. , . , (throughput unit). :
O valor da taxa de transferência específica é configurado para cada hub separadamente. Se as fontes excederem a taxa de transferência permitida, uma exceção será lançada nelas. Nesse caso, o receptor simplesmente não pode receber mensagens mais rapidamente que um determinado valor. As unidades de largura de banda também afetam o custo do uso do serviço. Cuidado!
Você deve estar ciente de que existem limites de largura de banda alocados para o espaço para nome e não para instâncias individuais do serviço Hub de Eventos.Os concentradores de mensagens são logicamente agrupados em espaços para nome (espaço para nome) (Fig. 10.12).»Mais informações sobre o livro podem ser encontradas no
site do editor»
Conteúdo»
TrechoCupom de 20% de desconto para
vendedores ambulantes -
BigData