Fatal 43 segundos, o que causou a degradação diária do serviçoOcorreu um
incidente no GitHub na semana passada que degradou o serviço por 24 horas e 11 minutos. O incidente não afetou toda a plataforma, mas apenas alguns sistemas internos, o que levou à exibição de informações desatualizadas e inconsistentes. Por fim, os dados do usuário não foram perdidos, mas a reconciliação manual de vários segundos de gravação no banco de dados ainda está em andamento. Na maior parte do acidente, o GitHub também não conseguiu lidar com webhooks, criar e publicar páginas do GitHub.
Todos nós do GitHub queremos sinceramente pedir desculpas pelos problemas que todos vocês encontraram. Conhecemos sua confiança no GitHub e estamos orgulhosos de criar sistemas sustentáveis que suportam a alta disponibilidade de nossa plataforma. Nós o decepcionamos e lamentamos profundamente. Embora não possamos desfazer os problemas devido à degradação da plataforma GitHub por um longo tempo, podemos explicar as razões do que aconteceu, falar sobre as lições aprendidas e as medidas que permitirão à empresa se proteger melhor de tais falhas no futuro.
Antecedentes
A maioria dos serviços de usuário do GitHub funciona em nossos próprios
data centers . A topologia do datacenter foi projetada para fornecer uma rede de fronteira confiável e expansível na frente de vários datacenters regionais que fornecem o trabalho dos sistemas de computação e armazenamento de dados. Apesar dos níveis de redundância incorporados aos componentes físicos e lógicos do projeto, ainda é possível que os sites não consigam interagir por algum tempo.
Em 21 de outubro, às 22h52, UTC, os trabalhos de reparo programados para substituir o equipamento óptico 100G com defeito resultaram em perda de comunicação entre o nó da rede na costa leste (costa leste dos EUA) e o principal data center na costa leste. A conexão entre eles foi restaurada após 43 segundos, mas essa curta desconexão causou uma cadeia de eventos que levou a 24 horas e 11 minutos de degradação do serviço.
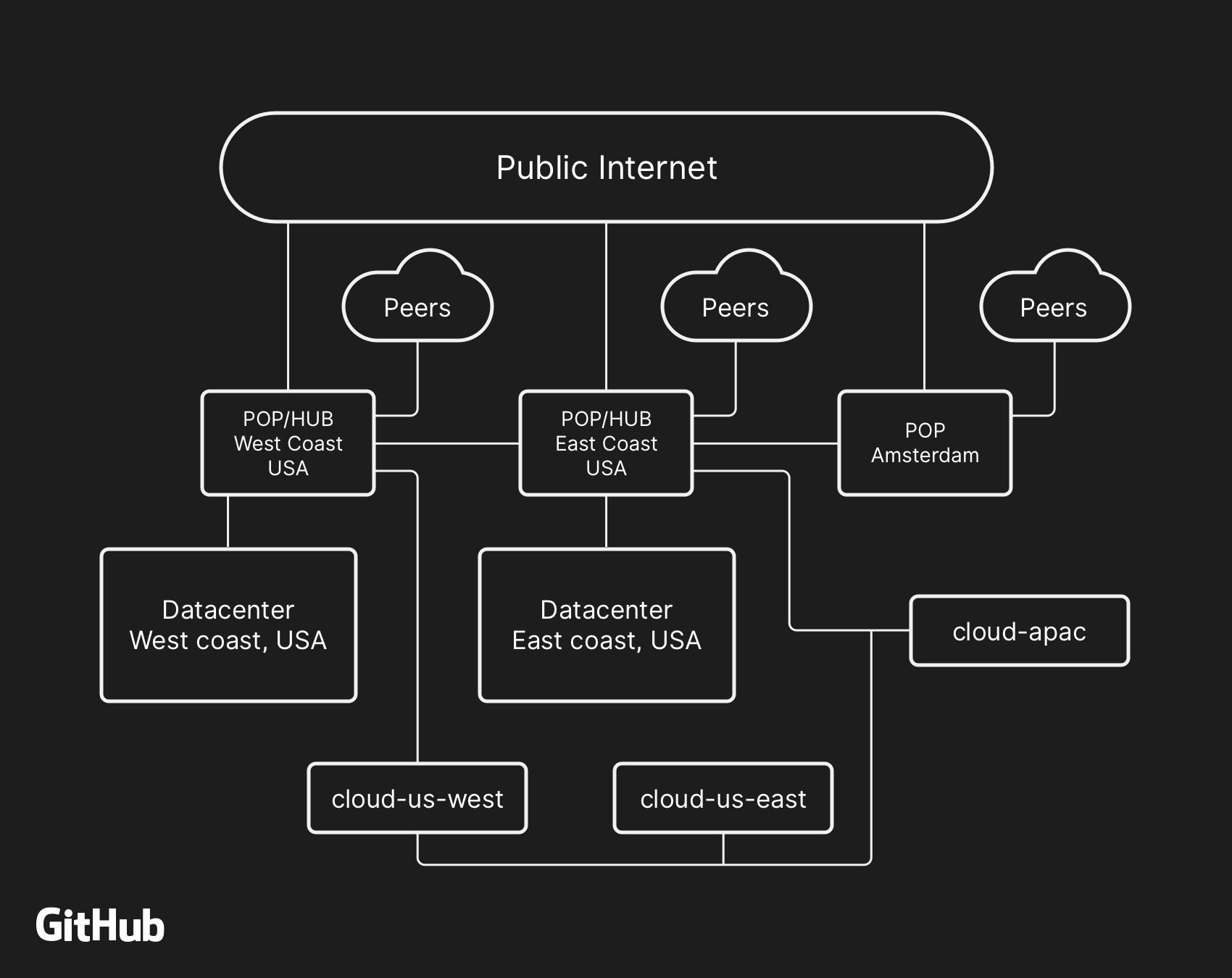 A arquitetura de rede de alto nível do GitHub, incluindo dois data centers físicos, 3 POPs e armazenamento em nuvem em várias regiões, conectados via peering
A arquitetura de rede de alto nível do GitHub, incluindo dois data centers físicos, 3 POPs e armazenamento em nuvem em várias regiões, conectados via peeringNo passado, discutimos como usamos o
MySQL para armazenar metadados do GitHub , bem como nossa abordagem para fornecer
alta disponibilidade para o MySQL . O GitHub gerencia vários clusters do MySQL, variando em tamanho, de centenas de gigabytes a quase cinco terabytes. Cada cluster possui dezenas de réplicas de leitura para armazenar outros metadados que não o Git; portanto, nossos aplicativos fornecem solicitações de pool, problemas, autenticação, processamento em segundo plano e recursos adicionais fora do repositório de objetos do Git. Dados diferentes em diferentes partes do aplicativo são armazenados em diferentes clusters usando segmentação funcional.
Para melhorar o desempenho em larga escala, os aplicativos gravam diretamente no servidor primário apropriado para cada cluster, mas na grande maioria dos casos delegam solicitações de leitura a um subconjunto de servidores de réplica. Usamos o
Orchestrator para gerenciar topologias de cluster do MySQL e efetuar failover automaticamente. Durante esse processo, o Orchestrator leva em consideração várias variáveis e é montado em cima do
Raft para obter consistência. O Orchestrator pode potencialmente implementar topologias que os aplicativos não suportam, portanto, você precisa garantir que a configuração do Orchestrator atenda às expectativas no nível do aplicativo.
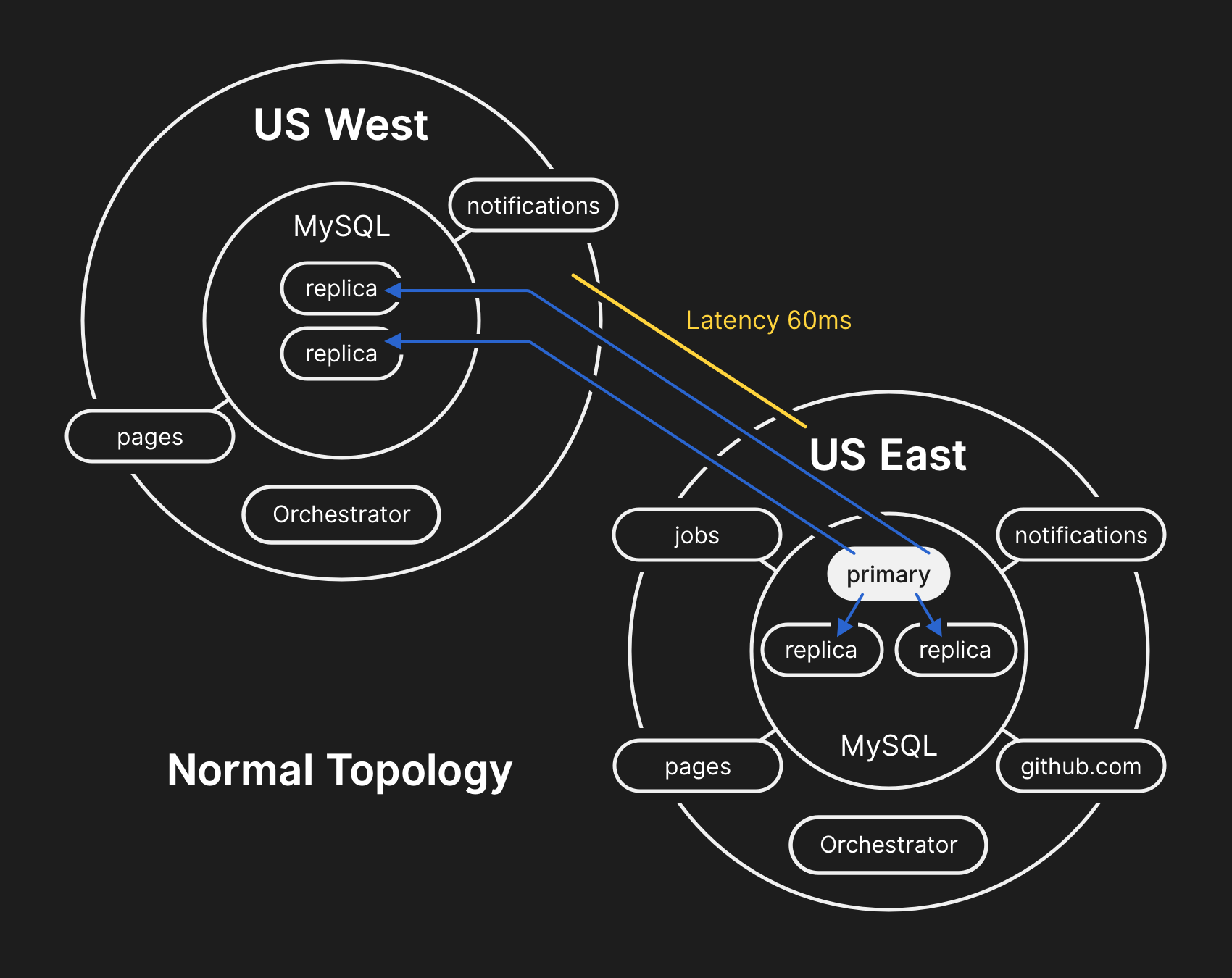 Em uma topologia típica, todos os aplicativos são lidos localmente com baixa latência.
Em uma topologia típica, todos os aplicativos são lidos localmente com baixa latência.Crônica do incidente
10.21.2018, 22:52 UTC
Durante a separação de rede acima mencionada, o Orchestrator no data center principal iniciou o processo de desmarcação da liderança de acordo com o algoritmo de consenso Raft. O data center da Costa Oeste e os nós de nuvem pública Orchestrator na Costa Leste conseguiram chegar a um consenso - e começaram a descobrir falhas de cluster para encaminhar registros para o data center ocidental. O Orchestrator começou a criar uma topologia de cluster de banco de dados no Ocidente. Após a reconexão, os aplicativos enviaram imediatamente o tráfego de gravação para os novos servidores principais no oeste dos EUA.
Nos servidores de banco de dados no data center oriental, houve registros por um curto período que não foram replicados no data center ocidental. Como os clusters de banco de dados nos dois datacenters agora continham registros que não estavam no outro datacenter, não conseguimos retornar com segurança o servidor principal de volta ao datacenter oriental.
10.21.2018, 22:54 UTC
Nossos sistemas de monitoramento interno começaram a gerar alertas indicando inúmeras falhas no sistema. No momento, vários engenheiros responderam e trabalharam na classificação das notificações recebidas. Às 23:02, os engenheiros do primeiro grupo de resposta determinaram que as topologias para vários clusters de banco de dados estavam em um estado inesperado. Ao consultar a API do Orchestrator, a topologia de replicação do banco de dados foi exibida, contendo apenas servidores do data center ocidental.
10.21.2018, 23:07 UTC
Nesse ponto, a equipe de resposta decidiu bloquear manualmente as ferramentas de implantação interna para evitar alterações adicionais. Às 23:09, o grupo colocou o site em
amarelo . Essa ação atribuiu automaticamente à situação o status de um incidente ativo e enviou um aviso ao coordenador do incidente. Às 23:11, o coordenador entrou no trabalho e dois minutos depois decidiu
mudar o status para vermelho .
10.21.2018, 23:13 UTC
Naquele momento, ficou claro que o problema afetava vários clusters de banco de dados. Desenvolvedores adicionais do grupo de engenharia do banco de dados estiveram envolvidos no trabalho. Eles começaram a examinar o estado atual para determinar quais ações precisavam ser executadas para configurar manualmente o banco de dados da Costa Leste dos EUA como principal para cada cluster e reconstruir a topologia de replicação. Isso não foi fácil, porque nesse momento o cluster de banco de dados ocidental estava recebendo registros da camada de aplicativos por quase 40 minutos. Além disso, no cluster leste, houve vários segundos de registros que não foram replicados para o oeste e não permitiram a replicação de novos registros de volta para o leste.
Proteger a privacidade e a integridade dos dados do usuário é a principal prioridade do GitHub. Portanto, decidimos que mais de 30 minutos de dados gravados no data center ocidental nos deixam com apenas uma solução para a situação, a fim de salvar esses dados: encaminhar para frente (encaminhar para frente). No entanto, aplicativos no leste, que dependem da gravação de informações no cluster ocidental do MySQL, atualmente não conseguem lidar com o atraso adicional devido à transferência da maioria de suas chamadas de banco de dados. Essa decisão levará ao fato de que nosso serviço se tornará inadequado para muitos usuários. Acreditamos que a degradação a longo prazo da qualidade do serviço valeu a pena garantir a consistência dos dados de nossos usuários.
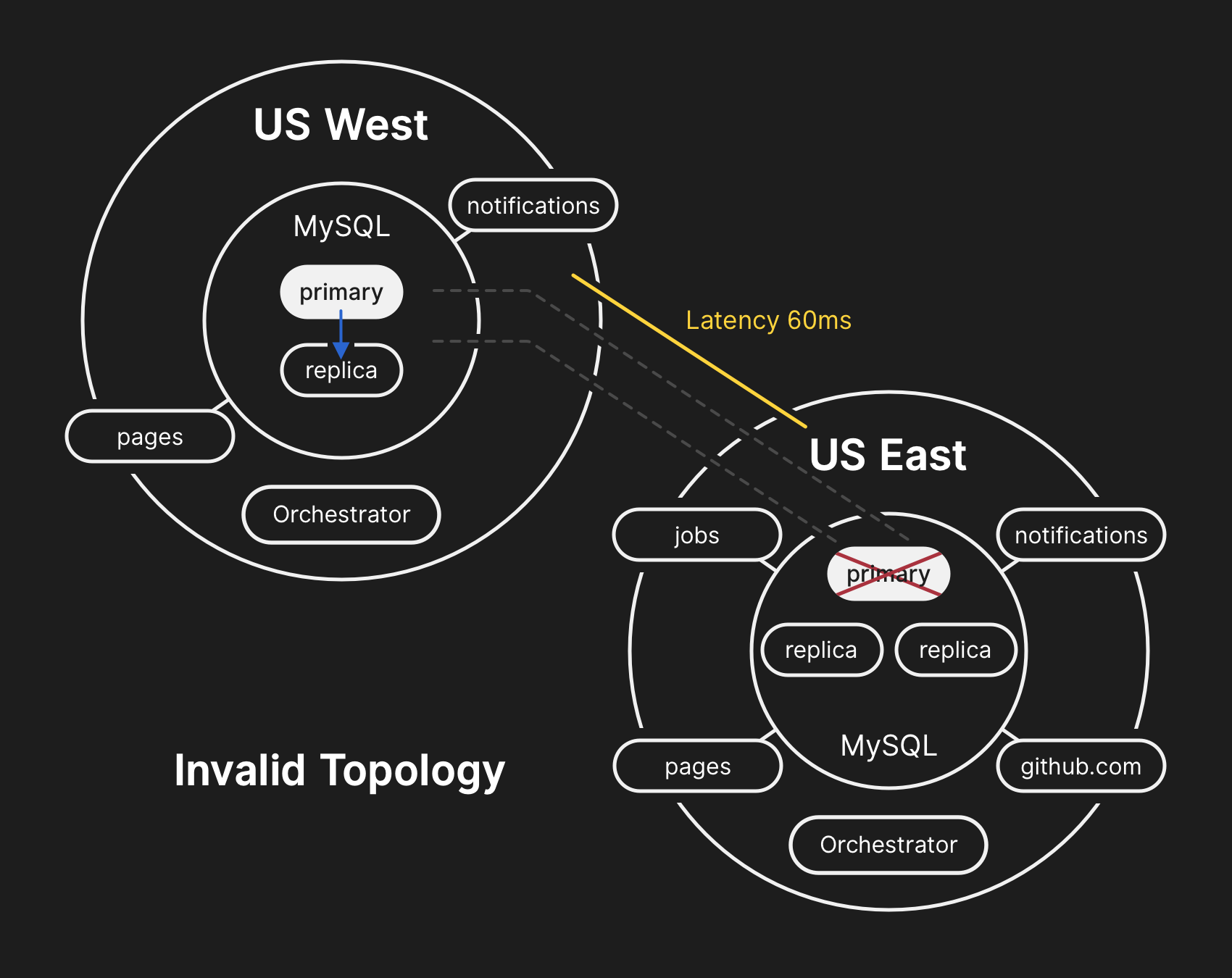 Na topologia incorreta, a replicação do oeste para o leste é violada e os aplicativos não podem ler dados das réplicas atuais, porque dependem de baixa latência para manter o desempenho da transação
Na topologia incorreta, a replicação do oeste para o leste é violada e os aplicativos não podem ler dados das réplicas atuais, porque dependem de baixa latência para manter o desempenho da transação10.21.2018, 23:19 UTC
As consultas sobre o estado dos clusters de banco de dados mostraram que é necessário interromper a execução de tarefas que gravam metadados, como solicitações push. Fizemos uma escolha e deliberadamente fizemos uma degradação parcial do serviço, suspendendo webhooks e a montagem das páginas do GitHub, para não comprometer os dados que já recebemos dos usuários. Em outras palavras, a estratégia era priorizar: integridade dos dados em vez da usabilidade do site e recuperação rápida.
22/10/2018, 00:05 UTC
Os engenheiros da equipe de resposta começaram a desenvolver um plano para resolver inconsistências de dados e lançaram procedimentos de failover para o MySQL. O plano era restaurar arquivos do backup, sincronizar réplicas nos dois sites, retornar a uma topologia de serviço estável e depois retomar o processamento de trabalhos na fila. Atualizamos o status para informar aos usuários que vamos executar um failover gerenciado do sistema de armazenamento interno.
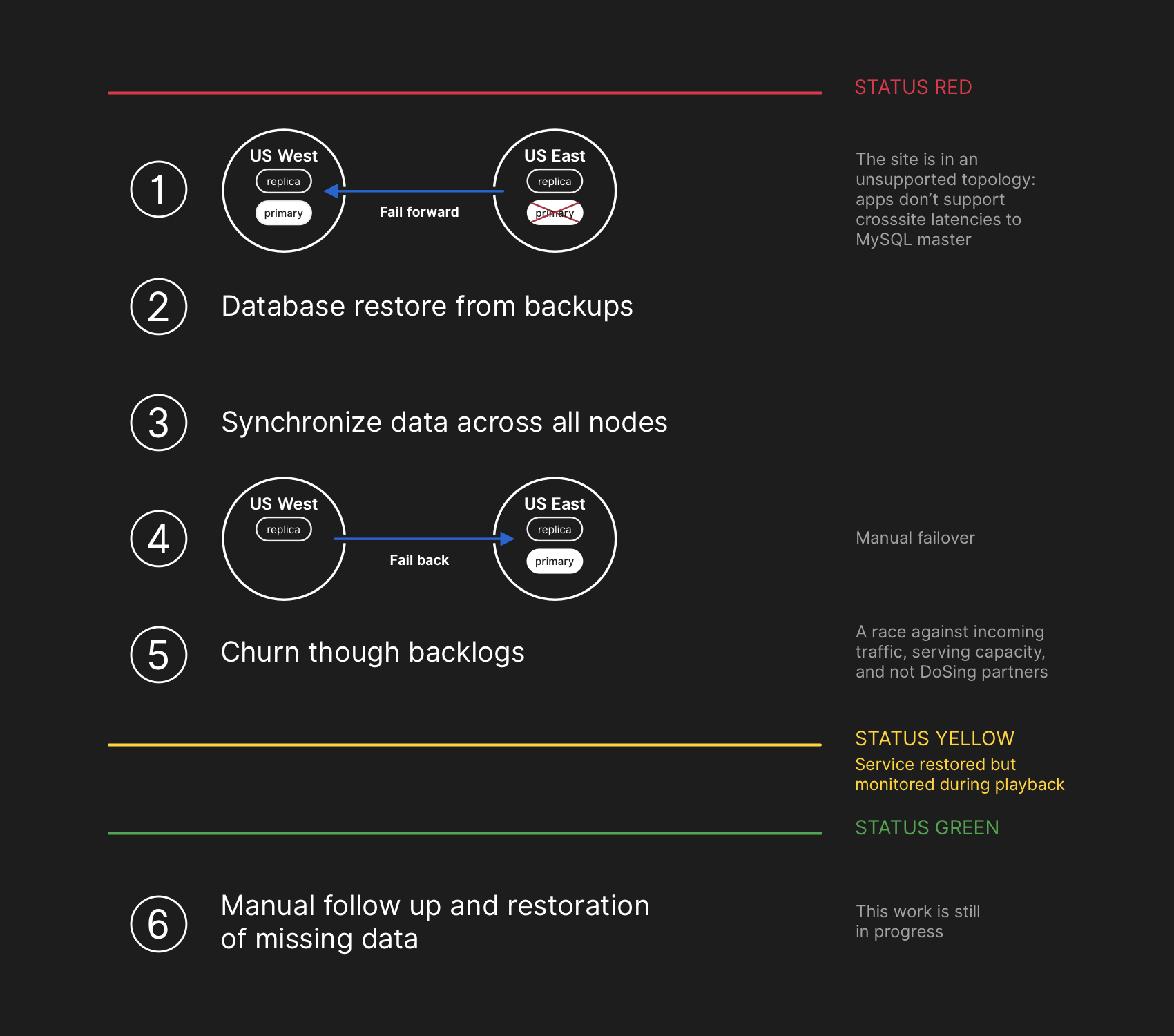 O plano de recuperação envolvia avançar, restaurar os backups, sincronizar, retroceder e resolver o atraso antes de retornar ao status verde
O plano de recuperação envolvia avançar, restaurar os backups, sincronizar, retroceder e resolver o atraso antes de retornar ao status verdeEmbora os backups do MySQL sejam feitos a cada quatro horas e armazenados por muitos anos, eles ficam em um armazenamento remoto na nuvem de objetos de blob. A recuperação de vários terabytes de um backup levou várias horas. Demorou muito tempo para transferir dados do serviço de backup remoto. Passava a maior parte do tempo descompactando, verificando a soma de verificação, preparando e carregando grandes arquivos de backup em servidores MySQL recém-preparados. Esse procedimento é testado diariamente, para que todos tenham uma boa idéia de quanto tempo a recuperação levaria. No entanto, antes desse incidente, nunca tivemos que reconstruir completamente o cluster inteiro a partir de um backup. Outras estratégias sempre funcionaram, como réplicas adiadas.
10/22/2018, 00:41 UTC
A essa altura, um processo de backup havia sido iniciado para todos os clusters do MySQL afetados, e os engenheiros acompanharam o progresso. Ao mesmo tempo, vários grupos de engenheiros estudaram maneiras de acelerar a transferência e a recuperação sem degradar ainda mais o site ou o risco de corrupção de dados.
10/22/2018, 06:51 UTC
Vários clusters no data center oriental concluíram a recuperação dos backups e começaram a replicar novos dados da costa oeste. Isso levou a uma desaceleração no carregamento de páginas que executaram uma operação de gravação em todo o país, mas a leitura de páginas desses clusters de banco de dados retornou resultados reais se a solicitação de leitura cair em uma réplica restaurada recentemente. Outros clusters de banco de dados maiores continuaram a se recuperar.
Nossas equipes identificaram um método de recuperação diretamente da costa oeste para superar as limitações de largura de banda causadas pela inicialização a partir do armazenamento externo. Tornou-se quase 100% claro que a recuperação será concluída com êxito, e o tempo para criar uma topologia de replicação íntegra depende de quanto demora a replicação de recuperação. Essa estimativa foi interpolada linearmente com base na replicação de telemetria disponível e a página de status foi
atualizada para definir a espera de duas horas como o tempo estimado de recuperação.
10/22/2018, 07:46 UTC
O GitHub postou um
post informativo no blog . Nós mesmos usamos as páginas do GitHub, e todas as assembléias foram pausadas algumas horas atrás, portanto a publicação exigiu um esforço adicional. Pedimos desculpas pelo atraso. Pretendemos enviar esta mensagem muito antes e, no futuro, forneceremos a publicação de atualizações nas condições de tais restrições.
10/22/2018, 11:12 UTC
Todos os bancos de dados primários são novamente transferidos para o leste. Isso fez com que o site se tornasse muito mais responsivo, pois os registros agora eram roteados para um servidor de banco de dados localizado no mesmo data center físico da nossa camada de aplicativos. Embora esse desempenho tenha melhorado significativamente, ainda havia dezenas de réplicas de leitura do banco de dados que estavam várias horas atrás da cópia principal. Essas réplicas atrasadas levaram os usuários a ver dados inconsistentes ao interagir com nossos serviços. Distribuímos a carga de leitura por um grande conjunto de réplicas de leitura, e cada solicitação para nossos serviços tem boas chances de entrar na réplica de leitura com um atraso de várias horas.
De fato, o tempo de recuperação de uma réplica atrasada é reduzido exponencialmente, não linearmente. Quando os usuários nos EUA e na Europa acordaram, devido ao aumento da carga nos registros nos clusters de bancos de dados, o processo de recuperação levou mais tempo do que o previsto.
22/10/2018, 13:15 UTC
Estávamos nos aproximando do pico de carga no GitHub.com. A equipe de resposta discutiu as próximas etapas. Ficou claro que o atraso na replicação para um estado consistente está aumentando, não diminuindo. Anteriormente, começamos a preparar réplicas adicionais de leitura do MySQL na nuvem pública da Costa Leste. Uma vez disponíveis, ficou mais fácil distribuir o fluxo de solicitações de leitura entre vários servidores. Reduzir a carga média nas réplicas de leitura acelerou a recuperação da replicação.
22/10/2018, 16:24 UTC
Após sincronizar as réplicas, retornamos à topologia original, eliminando os problemas de atraso e disponibilidade. Como parte de uma decisão consciente sobre a prioridade da integridade dos dados, em vez de uma rápida correção da situação,
mantivemos o status vermelho do site quando começamos a processar os dados acumulados.
22/10/2018, 16:45 UTC
No estágio de recuperação, era necessário equilibrar o aumento da carga associada ao backlog, sobrecarregando potencialmente nossos parceiros do ecossistema com notificações e retornando a cem por cento de eficiência o mais rápido possível. Mais de cinco milhões de eventos de gancho e 80 mil solicitações para criação de páginas da web permaneceram na fila.
Quando reativamos o processamento desses dados, processamos cerca de 200.000 tarefas úteis com webhooks que excederam o TTL interno e foram descartados. Ao saber disso, paramos de processar e começamos a aumentar o TTL.
Para evitar uma diminuição adicional na confiabilidade de nossas atualizações de status, deixamos o status de degradação até concluirmos o processamento de toda a quantidade acumulada de dados e garantir que os serviços retornem claramente ao nível normal de desempenho.
22/10/2018, 23:03 UTC
Todos os eventos incompletos da webhook e conjuntos de páginas são processados, e a integridade e a operação correta de todos os sistemas são confirmadas. O status do site foi
atualizado para verde .
Ações adicionais
Resolução de incompatibilidade de dados
Durante a recuperação, corrigimos logs binários do MySQL com entradas principalmente do data center, que não foram replicadas para o ocidental. O número total de tais entradas é relativamente pequeno. Por exemplo, em um dos clusters mais ocupados, existem apenas 954 registros nesses segundos. No momento, estamos analisando esses logs e determinando quais entradas podem ser reconciliadas automaticamente e quais requerem assistência ao usuário. Várias equipes participam desse trabalho, e nossa análise já determinou a categoria de registros que o usuário repetiu - e foram salvos com sucesso. Conforme declarado nesta análise, nosso principal objetivo é manter a integridade e a precisão dos dados armazenados no GitHub.
Comunicação
Tentando transmitir informações importantes para você durante o incidente, fizemos várias estimativas públicas do tempo de recuperação com base na velocidade de processamento dos dados acumulados. Olhando para trás, nossas estimativas não levaram em consideração todas as variáveis. Pedimos desculpas pela confusão e nos esforçaremos para fornecer informações mais precisas no futuro.
Medidas técnicas
Várias medidas técnicas foram identificadas durante esta análise. A análise continua, a lista pode ser complementada.
- Ajuste a configuração do Orchestrator para impedir que os bancos de dados principais se movam para fora da região. O orquestrador funcionou de acordo com as configurações, embora a camada de aplicativo não suporte essa alteração de topologia. A escolha de um líder em uma região geralmente é segura, mas o aparecimento repentino de um atraso devido ao fluxo de tráfego no continente se tornou a principal causa desse incidente. Este é um novo comportamento emergente do sistema, porque antes não encontramos a seção interna da rede dessa magnitude.
- Aceleramos a migração para o novo sistema de relatório de status, que fornecerá uma plataforma mais adequada para discutir incidentes ativos com linguagem cada vez mais clara. Embora muitas partes do GitHub estivessem disponíveis durante todo o incidente, só pudemos selecionar status verde, amarelo e vermelho para todo o site. Admitimos que isso não fornece uma imagem precisa: o que funciona e o que não funciona. O novo sistema exibirá os vários componentes da plataforma para que você saiba o status de cada serviço.
- Algumas semanas antes desse incidente, lançamos uma iniciativa de engenharia em toda a empresa para oferecer suporte ao tráfego do GitHub de vários data centers usando a arquitetura ativa / ativa / ativa. O objetivo deste projeto é oferecer suporte à redundância N + 1 no nível do datacenter para suportar a falha de um datacenter sem interferência externa. Isso é muito trabalhoso e levará algum tempo, mas acreditamos que vários datacenters bem conectados em diferentes regiões fornecerão um bom compromisso. O último incidente levou essa iniciativa ainda mais longe.
- Tomaremos uma posição mais ativa na verificação de nossas suposições. O GitHub está crescendo rapidamente e acumulou uma quantidade considerável de complexidade na última década. Está se tornando cada vez mais difícil capturar e transmitir à nova geração de funcionários o contexto histórico de compromissos e decisões tomadas.
Medidas organizacionais
Esse incidente influenciou bastante nosso entendimento da confiabilidade do site. Aprendemos que restringir o controle operacional ou melhorar os tempos de resposta não são garantias suficientes de confiabilidade em um sistema tão complexo de serviços como o nosso. Para apoiar esses esforços, também iniciaremos uma prática sistemática de testar cenários de falhas antes que eles realmente ocorram. Este trabalho inclui a solução de problemas deliberada e o uso de ferramentas de engenharia do caos.
Conclusão
Sabemos como você confia no GitHub em seus projetos e negócios. Preocupamo-nos mais do que ninguém com a disponibilidade do nosso serviço e a segurança dos seus dados. , .