 Este artigo faz parte do Chronicle of Software Architecture , uma série de artigos sobre arquitetura de software. Neles, escrevo sobre o que aprendi sobre arquitetura de software, o que penso e como uso o conhecimento. O conteúdo deste artigo pode fazer mais sentido se você ler os artigos anteriores da série.
Este artigo faz parte do Chronicle of Software Architecture , uma série de artigos sobre arquitetura de software. Neles, escrevo sobre o que aprendi sobre arquitetura de software, o que penso e como uso o conhecimento. O conteúdo deste artigo pode fazer mais sentido se você ler os artigos anteriores da série.Em um
artigo anterior da série, publiquei um mapa conceitual que mostra os relacionamentos entre os tipos de código.
Mas sempre me pareceu que nem tudo está muito bem refletido lá, eu simplesmente não sabia como fazê-lo melhor. É sobre um núcleo comum.
Além disso, surgiram mais alguns pensamentos que descreverei neste pequeno artigo.
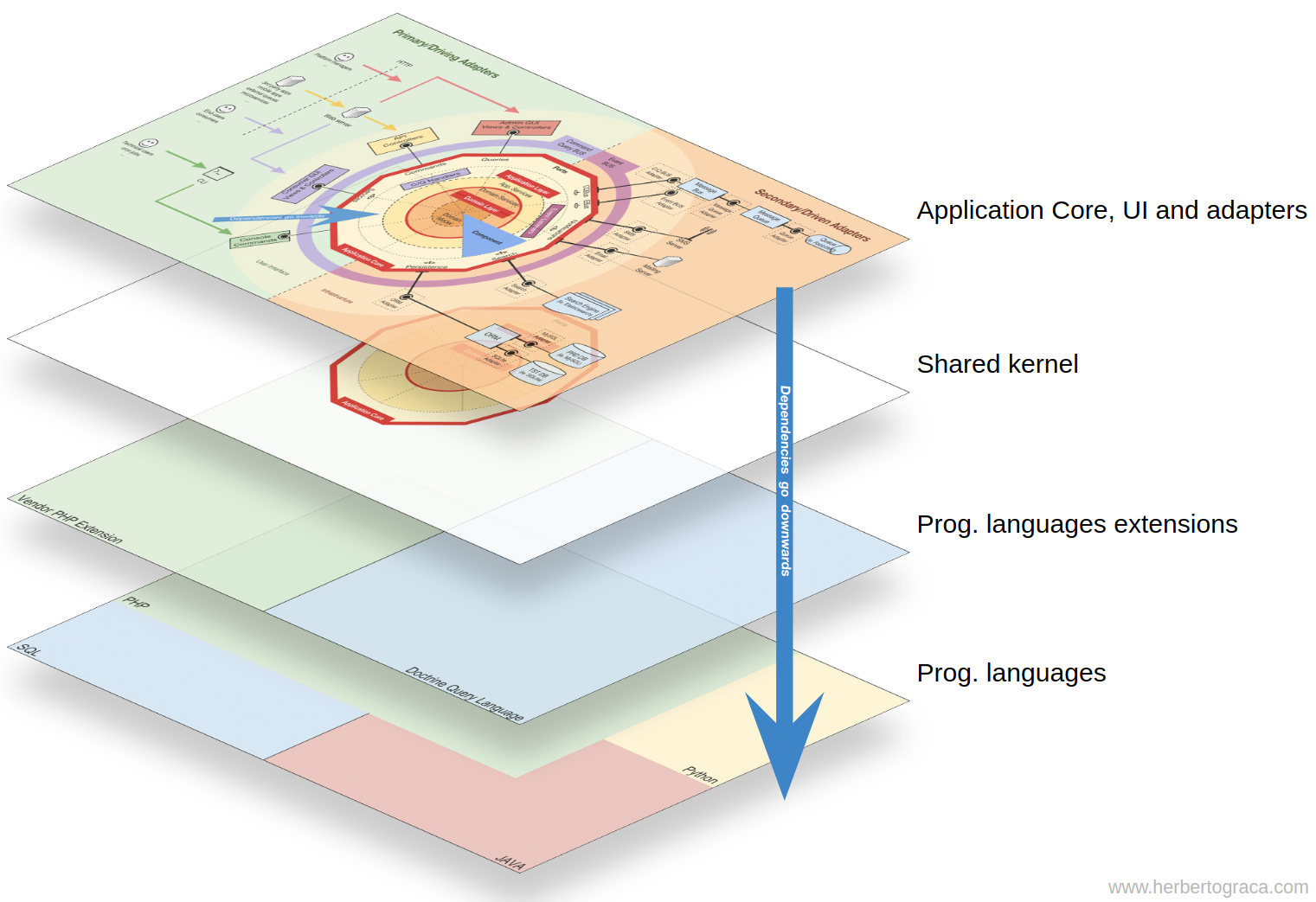
No infográfico do último artigo desta série, no centro do diagrama, vemos o núcleo comum. Parece estar localizado dentro da camada de domínio e acima das seções cônicas, que são contextos limitados.

Apesar da localização, não quis dizer que o núcleo comum depende do restante do código ou que o núcleo comum é outra camada dentro do nível do domínio.
O que é um núcleo comum ?!
O núcleo comum, conforme definido por Eric Evans, o
pai do DDD, é o código que a equipe de desenvolvimento decide dividir entre vários contextos limitados:
[...] um subconjunto do modelo de domínio que as duas equipes concordaram em usar juntas. Obviamente, junto com esse subconjunto do modelo, o núcleo comum inclui um subconjunto da arquitetura de código ou banco de dados associada a essa parte do modelo. Esse material claramente geral tem um status especial e não deve ser alterado sem consultar outra equipe.
- “Common Kernel” , DDD Wiki de Ward Cunningham
Assim, pode ser qualquer tipo de código: código no nível do domínio, código no nível do aplicativo, bibliotecas ... qualquer que seja.

No entanto, no contexto do nosso mapa conceitual, eu o apresento como um subconjunto, como um tipo específico de código. No meu mapa conceitual, o núcleo comum contém código para os níveis de domínio e aplicativo, que são compartilhados em contextos limitados, para que a comunicação entre contextos restritos seja possível.
Por exemplo, isso significa que os eventos são disparados em um ou mais contextos restritos e ouvidos em outros contextos restritos. Juntamente com esses eventos, precisamos compartilhar todos os tipos de dados usados por esses eventos, por exemplo: identificadores de entidade, objetos de valor, enumerações etc. Objetos complexos, como entidades, não devem ser usados diretamente pelos eventos, pois podem ser difíceis. serialize / desserialize de / para a fila, portanto, o código genérico não deve ser amplamente distribuído.
Obviamente, se tivermos um sistema multilíngue de microsserviços, o núcleo comum deverá ser descritivo, em JSON, XML, YAML etc., para que todos os microsserviços possam entendê-lo.
Como resultado, esse núcleo comum é completamente separado do restante da base de código, dos componentes. Isso é ótimo, porque os componentes, embora conectados ao núcleo comum, são separados um do outro. O código genérico é explicitamente identificado e facilmente recuperado em uma biblioteca separada.
Também é muito conveniente se decidirmos extrair um dos contextos limitados em um microsserviço, separado do monólito. Sabemos com certeza o que é comum e podemos simplesmente extrair o núcleo comum na biblioteca, que será instalada no monólito e no microsserviço.
Portanto, para resumir, no meu mapa conceitual, o núcleo do aplicativo depende de um kernel comum que contém código dos níveis de domínio e aplicativo compartilhados entre contextos limitados.
Quando a linguagem não é suficiente ...
Portanto, temos o código do aplicativo com todas as camadas concêntricas e o núcleo do aplicativo depende do núcleo comum, que está sob todo esse código.
Também podemos dizer que todo esse código depende da (s) linguagem (s) de programação usada (s), mas é um fato tão óbvio que tendemos a ignorá-lo completamente.
No entanto, surge a pergunta: "E se a construção da linguagem não for suficiente?!" Bem, obviamente, criamos essas construções de linguagem e compensamos as falhas da linguagem. Mas tenho importantes perguntas de acompanhamento: “Como e onde justificar a existência desse código? Como alguém pode indicar claramente quando e como usá-lo? ”
O que eu vi e fiz foi um pacote chamado Utils ou Commons, onde esse código está localizado. Mas no final, acabamos despejando todo o código lá, que não sabemos onde colocar! Todos os tipos de código para diferentes propósitos e facilidade de uso (envoltos em um adaptador usado diretamente ...) são finalmente descartados lá. O pacote não tem significado conceitual, coerência, coerência, clareza, muitas ambiguidades.
Quero abandonar os pacotes Utils e Commons!
Todos os pacotes devem ter coesão conceitual! Deve ficar claro quando e como usar o pacote! Sem ambiguidade!
Por exemplo, se um aplicativo interage com a interface da linha de comandos de alguma maneira especial, em vez de colocar 'Acme / Util / SpecialCli' no espaço para nome, você pode colocá-lo em 'Acme / App / Infraestrutura / Cli / SpecialCli'. Isso indica que este pacote está associado à CLI, faz parte da infraestrutura do aplicativo Acme App. A afiliação com a infraestrutura do aplicativo também diz que há uma porta no kernel do aplicativo à qual este pacote corresponde.
Como alternativa, se virmos este pacote como algo que não possui na linguagem, podemos colocá-lo no espaço de nomes apropriado, por exemplo, 'Acme / PhpExtension / SpecialCli'. Isso mostra que este pacote deve ser considerado como parte do próprio idioma e, portanto, seu código deve ser usado diretamente na base de código como qualquer construção de idioma. Obviamente, se outra empresa depender desse pacote, pode ser razoável não depender diretamente dele, mas é mais seguro criar uma porta / adaptador para que eles possam trocá-lo por outra coisa. Mas se possuirmos o pacote, podemos considerá-lo parte do idioma, pois o risco de substituí-lo por outra alternativa não é tão grande. Compromisso é sempre a coisa.
Outro exemplo do que pode ser considerado como parte da linguagem são os UUIDs exclusivos no PHP. É bem possível imaginá-los fora da linguagem, porque toda vez que há uma nova versão e é um pesadelo com suporte ao código, esse é um conceito muito geral, um conceito amplo e suficientemente consistente para fazer parte da linguagem.
Então, por que não criar uma implementação UUID e usá-la como parte do próprio PHP, como usamos um objeto DateTime ?! Enquanto controlamos a implementação, não vejo falhas.
E a Linguagem de Consulta da Doutrina (DQL)? (A doutrina é a porta do Hibernate no PHP) podemos ver o DQL como se fosse SQL, Elasticsearch QL ou Mongo QL?
Conclusão
Portanto, no nível macro, vejo quatro tipos básicos de código e acho importante mostrá-los claramente na organização da base de código, para não acabar com muita sujeira.
Para mim, a verdade inegável é que a
arquitetura sempre existe, a única questão é se a controlamos ou não ?!Então, vamos
organizar claramente o código de acordo com a arquitetura , no todo ou em parte, em um mapa conceitual - o meu ou outro. O principal é organizar o código logicamente para que o projeto comunique explicitamente sua arquitetura através da estrutura e organização do código.