Ao desenvolver e usar sistemas distribuídos, somos confrontados com a tarefa de monitorar a integridade e a identidade dos dados entre sistemas - a tarefa de reconciliação .
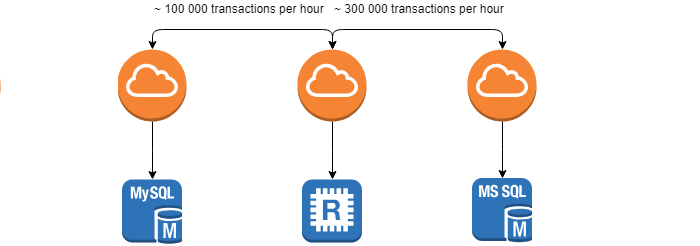
Os requisitos que o cliente define são o tempo mínimo para esta operação, pois, quanto mais cedo a discrepância for encontrada, mais fácil será eliminar suas conseqüências. A tarefa é significativamente complicada pelo fato de os sistemas estarem em movimento constante (~ 100.000 transações por hora) e 0% das discrepâncias não podem ser alcançadas.
Ideia principal
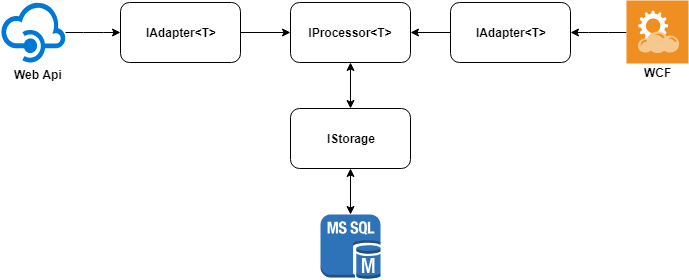
A idéia principal da solução pode ser descrita no diagrama a seguir.
Consideramos cada um dos elementos separadamente.
Adaptadores de dados
Cada um dos sistemas é projetado para sua própria área de assunto e, como conseqüência, as descrições de objetos podem variar significativamente. Precisamos comparar apenas um determinado conjunto de campos desses objetos.
Para simplificar o procedimento de comparação, levamos os objetos para um único formato, escrevendo um adaptador para cada fonte de dados. Trazer os objetos para um único formato pode reduzir significativamente a quantidade de memória usada, pois armazenaremos apenas os campos comparados.
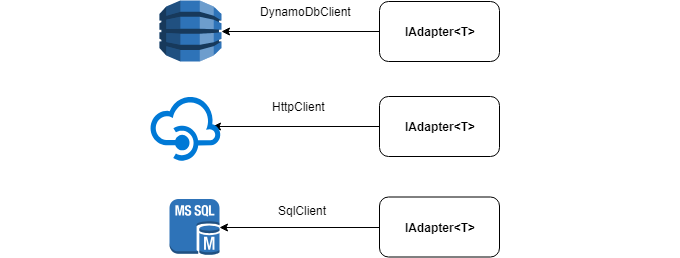
Sob o capô, o adaptador pode ter qualquer fonte de dados: HttpClient , SqlClient , DynamoDbClient etc.
A seguir, é a interface do IAdapter que você deseja implementar:
public interface IAdapter<T> where T : IModel { int Id { get; } Task<IEnumerable<T>> GetItemsAsync(ISearchModel searchModel); } public interface IModel { Guid Id { get; } int GetHash(); }
Armazenamento
A reconciliação de dados só pode começar depois que todos os dados foram lidos, pois os adaptadores podem retorná-los em ordem aleatória.
Nesse caso, a quantidade de RAM pode não ser suficiente, especialmente se você executar várias reconciliações ao mesmo tempo, indicando grandes intervalos de tempo.
Considere a interface IStorage
public interface IStorage { int SourceAdapterId { get; } int TargetAdapterId { get; } int MaxWriteCapacity { get; } Task InitializeAsync(); Task<int> WriteItemsAsync(IEnumerable<IModel> items, int adapterId); Task<IEnumerable<IResultModel>> GetDifferenceAsync(ISearchDifferenceModel model); } public interface ISearchDifferenceModel { int Offset { get; } int Limit { get; } }
Repositório. Implementação baseada em MS SQL
Implementamos o IStorage usando o MS SQL, o que nos permitiu realizar a comparação completamente no lado do servidor Db.
Para armazenar os valores solicitados, basta criar a seguinte tabela:
CREATE TABLE [dbo].[Storage_1540747667] ( [id] UNIQUEIDENTIFIER NOT NULL, [adapterid] INT NOT NULL, [qty] INT NOT NULL, [price] INT NOT NULL, CONSTRAINT [PK_Storage_1540747667] PRIMARY KEY ([id], [adapterid]) )
Cada entrada contém campos do sistema ( [id] , [adapterId] ) e campos para comparação ( [qty] , [price] ). Algumas palavras sobre os campos do sistema:
[id] - identificador exclusivo da entrada, o mesmo nos dois sistemas
[adapterId] - identificador do adaptador através do qual o registro foi recebido
Como os processos de reconciliação podem ser iniciados em paralelo e com intervalos de interseção, criamos uma tabela com um nome exclusivo para cada um deles. Se a reconciliação for bem-sucedida, essa tabela será excluída; caso contrário, um relatório será enviado com uma lista de registros nos quais existem discrepâncias.
Repositório. Comparação de Valor
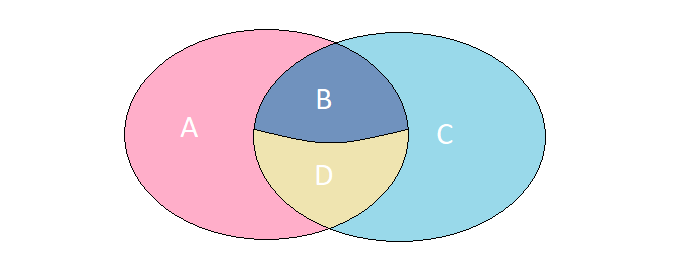
Imagine que temos 2 conjuntos cujos elementos têm um conjunto absolutamente idêntico de campos. Considere 4 casos possíveis de sua interseção:
A. Os elementos estão presentes apenas no conjunto esquerdo.
B. Os elementos estão presentes nos dois conjuntos, mas têm significados diferentes.
S Os elementos estão presentes apenas no conjunto certo.
D Os elementos estão presentes nos dois conjuntos e têm o mesmo significado.
Em um problema específico, precisamos encontrar os elementos descritos nos casos A, B, C. Você pode obter o resultado desejado em uma consulta para o MS SQL via FULL OUTER JOIN :
select [s1].[id], [s1].[adapterid] from [dbo].[Storage_1540758006] as [s1] full outer join [dbo].[Storage_1540758006] as [s2] on [s2].[id] = [s1].[id] and [s2].[adapterid] != [s1].[adapterid] and [s2].[qty] = [s1].[qty] and [s2].[price] = [s1].[price] where [s2].[id] is nul
A saída desta solicitação pode conter 4 tipos de registros que atendem aos requisitos iniciais
| # | id | adapterid | comentário |
|---|
| 1 | guid1 | adp1 | O registro está presente apenas no conjunto esquerdo. Caso A |
| 2 | guid2 | adp2 | O registro está presente apenas no conjunto correto. Caso C |
| 3 | guid3 | adp1 | Os registros estão presentes nos dois conjuntos, mas têm significados diferentes. Caso B |
| 4 | guid3 | adp2 | Os registros estão presentes nos dois conjuntos, mas têm significados diferentes. Caso B |
Repositório. Hashing
Usando hash em objetos comparados, você pode reduzir significativamente o custo das operações de gravação e comparação. Especialmente quando se trata de comparar dezenas de campos.
O método mais universal de hash de uma representação serializada de um objeto acabou por ser.
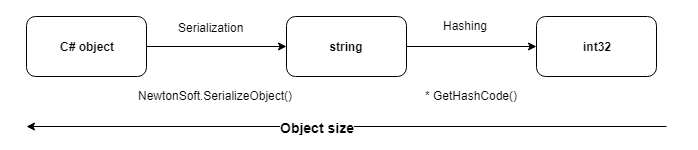
1. Para o hash, usamos o método GetHashCode () padrão, que retorna int32 e é substituído por todos os tipos primitivos.
2. Nesse caso, a probabilidade de colisões é improvável, pois apenas os registros com os mesmos identificadores são comparados.
Considere a estrutura da tabela usada nesta otimização:
CREATE TABLE [dbo].[Storage_1540758006] ( [id] UNIQUEIDENTIFIER NOT NULL, [adapterid] INT NOT NULL, [hash] INT NOT NULL, CONSTRAINT [PK_Storage_1540758006] PRIMARY KEY ([id], [adapterid], [hash]) )
A vantagem dessa estrutura é o custo constante de armazenar um registro (24 bytes), o que não dependerá do número de campos comparados.
Naturalmente, o procedimento de comparação sofre alterações e se torna muito mais simples.
select [s1].[id], [s1].[adapterid] from [dbo].[Storage_1540758006] as [s1] full outer join [dbo].[Storage_1540758006] as [s2] on [s2].[id] = [s1].[id] and [s2].[adapterid] != [s1].[adapterid] and [s2].[hash] = [s1].[hash] where [s2].[id] is null
CPU
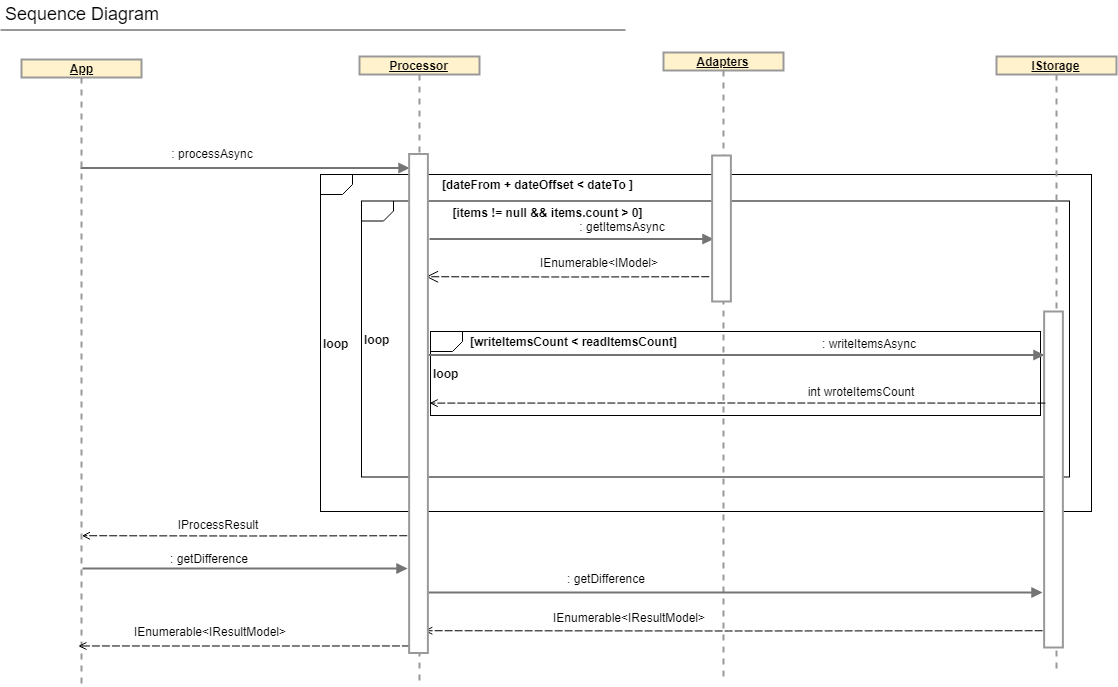
Nesta seção, falaremos sobre uma classe que contém toda a lógica comercial da reconciliação, a saber:
1. leitura paralela de dados de adaptadores
2. hash de dados
3. registro de valores no buffer
4. entrega de resultados
Uma descrição mais abrangente do processo de reconciliação pode ser obtida observando o diagrama de sequência e a interface do IProcessor.
public interface IProcessor<T> where T : IModel { IAdapter<T> SourceAdapter { get; } IAdapter<T> TargetAdapter { get; } IStorage Storage { get; } Task<IProcessResult> ProcessAsync(); Task<IEnumerable<IResultModel>> GetDifferenceAsync(ISearchDifferenceModel model); }
Agradecimentos
Muito obrigado aos meus colegas do MySale Group pelo feedback: AntonStrakhov , Nesstory , Barlog_5 , Kostya Krivtsun e VeterManve - o autor da idéia.