Nota perev. R: O artigo original foi escrito por representantes da BlueData, uma empresa fundada por pessoas da VMware. Ela é especialista em tornar mais fácil (mais fácil, mais rápido e mais barato) implantar soluções para análise de Big Data e aprendizado de máquina em vários ambientes. A recente iniciativa da empresa chamada BlueK8s , na qual os autores desejam montar uma galáxia de ferramentas de código aberto "para implantar aplicativos com estado e gerenciá-los no Kubernetes", também é chamada a contribuir para isso. O artigo é dedicado ao primeiro deles - o KubeDirector, que, segundo os autores, ajuda um entusiasta do Big Data, que não possui treinamento especial em Kubernetes, a implantar aplicativos como Spark, Cassandra ou Hadoop no K8s. Breves instruções sobre como fazer isso são fornecidas no artigo. No entanto, lembre-se de que o projeto possui um status de prontidão antecipada - pré-alfa.
O KubeDirector é um projeto de código aberto criado para simplificar o lançamento de clusters a partir de aplicativos stateful escaláveis complexos no Kubernetes. O KubeDirector é implementado usando a estrutura CRD (
Custom Resource Definition ), usa os recursos nativos de extensão da API Kubernetes e depende de sua filosofia. Essa abordagem fornece integração transparente com o gerenciamento de usuários e recursos no Kubernetes, bem como com clientes e utilitários existentes.
O projeto KubeDirector
anunciado recentemente faz parte de uma iniciativa maior de código aberto para o Kubernetes chamada BlueK8s. Agora, tenho o prazer de anunciar a disponibilidade do código
KubeDirector inicial (pré-alfa). Esta postagem mostrará como funciona.
O KubeDirector oferece os seguintes recursos:
- Não é necessário modificar o código para executar aplicativos stateful que não sejam nativos da nuvem do Kubernetes. Em outras palavras, não há necessidade de decompor aplicativos existentes para corresponder ao padrão de arquitetura de microsserviço.
- Suporte nativo para armazenar configurações e estados específicos do aplicativo.
- Padrão de implantação independente de aplicativo que minimiza o tempo de inicialização de novos aplicativos com estado no Kubernetes.
O KubeDirector permite que cientistas de dados, acostumados a aplicativos distribuídos com processamento intensivo de dados, como Hadoop, Spark, Cassandra, TensorFlow, Caffe2 etc., os executem no Kubernetes com uma curva de aprendizado mínima e sem a necessidade de escrever código no Go. Quando esses aplicativos são controlados pelo KubeDirector, eles são definidos por metadados simples e pelo conjunto de configurações associado. Os metadados do aplicativo são definidos como um recurso
KubeDirectorApp .
Para entender os componentes do KubeDirector, clone o repositório no
GitHub com um comando como o seguinte:
git clone http://<userid>@github.com/bluek8s/kubedirector.
A definição
KubeDirectorApp para o aplicativo Spark 2.2.1 está localizada no
kubedirector/deploy/example_catalog/cr-app-spark221e2.json :
~> cat kubedirector/deploy/example_catalog/cr-app-spark221e2.json
{ "apiVersion": "kubedirector.bluedata.io/v1alpha1", "kind": "KubeDirectorApp", "metadata": { "name" : "spark221e2" }, "spec" : { "systemctlMounts": true, "config": { "node_services": [ { "service_ids": [ "ssh", "spark", "spark_master", "spark_worker" ], …
A configuração do cluster de aplicativos é definida como um recurso
KubeDirectorCluster .
A definição
KubeDirectorCluster para o exemplo de cluster Spark 2.2.1 está disponível em
kubedirector/deploy/example_clusters/cr-cluster-spark221.e1.yaml :
~> cat kubedirector/deploy/example_clusters/cr-cluster-spark221.e1.yaml
apiVersion: "kubedirector.bluedata.io/v1alpha1" kind: "KubeDirectorCluster" metadata: name: "spark221e2" spec: app: spark221e2 roles: - name: controller replicas: 1 resources: requests: memory: "4Gi" cpu: "2" limits: memory: "4Gi" cpu: "2" - name: worker replicas: 2 resources: requests: memory: "4Gi" cpu: "2" limits: memory: "4Gi" cpu: "2" - name: jupyter …
Inicie o Spark no Kubernetes com o KubeDirector
É fácil iniciar os clusters Spark no Kubernetes com o KubeDirector.
Primeiro, verifique se o Kubernetes está em execução (versão 1.9 ou superior) usando o comando
kubectl version :
~> kubectl version Client Version: version.Info{Major:"1", Minor:"11", GitVersion:"v1.11.3", GitCommit:"a4529464e4629c21224b3d52edfe0ea91b072862", GitTreeState:"clean", BuildDate:"2018-09-09T18:02:47Z", GoVersion:"go1.10.3", Compiler:"gc", Platform:"linux/amd64"} Server Version: version.Info{Major:"1", Minor:"11", GitVersion:"v1.11.3", GitCommit:"a4529464e4629c21224b3d52edfe0ea91b072862", GitTreeState:"clean", BuildDate:"2018-09-09T17:53:03Z", GoVersion:"go1.10.3", Compiler:"gc", Platform:"linux/amd64"}
Implemente o serviço KubeDirector e amostra as
KubeDirectorApp recursos do
KubeDirectorApp usando os seguintes comandos:
cd kubedirector make deploy
Como resultado, ele começará com o KubeDirector:
~> kubectl get pods NAME READY STATUS RESTARTS AGE kubedirector-58cf59869-qd9hb 1/1 Running 0 1m
Veja a lista de aplicativos instalados no KubeDirector executando o
kubectl get KubeDirectorApp :
~> kubectl get KubeDirectorApp NAME AGE cassandra311 30m spark211up 30m spark221e2 30m
Agora você pode iniciar o cluster Spark 2.2.1 usando o arquivo de amostra para
KubeDirectorCluster e o
kubectl create -f deploy/example_clusters/cr-cluster-spark211up.yaml . Verifique se ele começou:
~> kubectl get pods NAME READY STATUS RESTARTS AGE kubedirector-58cf59869-djdwl 1/1 Running 0 19m spark221e2-controller-zbg4d-0 1/1 Running 0 23m spark221e2-jupyter-2km7q-0 1/1 Running 0 23m spark221e2-worker-4gzbz-0 1/1 Running 0 23m spark221e2-worker-4gzbz-1 1/1 Running 0 23m
O Spark também apareceu na lista de serviços em execução:
~> kubectl get service NAME TYPE CLUSTER-IP EXTERNAL-IP PORT(S) AGE kubedirector ClusterIP 10.98.234.194 <none> 60000/TCP 1d kubernetes ClusterIP 10.96.0.1 <none> 443/TCP 1d svc-spark221e2-5tg48 ClusterIP None <none> 8888/TCP 21s svc-spark221e2-controller-tq8d6-0 NodePort 10.104.181.123 <none> 22:30534/TCP,8080:31533/TCP,7077:32506/TCP,8081:32099/TCP 20s svc-spark221e2-jupyter-6989v-0 NodePort 10.105.227.249 <none> 22:30632/TCP,8888:30355/TCP 20s svc-spark221e2-worker-d9892-0 NodePort 10.107.131.165 <none> 22:30358/TCP,8081:32144/TCP 20s svc-spark221e2-worker-d9892-1 NodePort 10.110.88.221 <none> 22:30294/TCP,8081:31436/TCP 20s
Se você acessar a porta 31533 no seu navegador, poderá ver a interface do usuário do Spark Master:
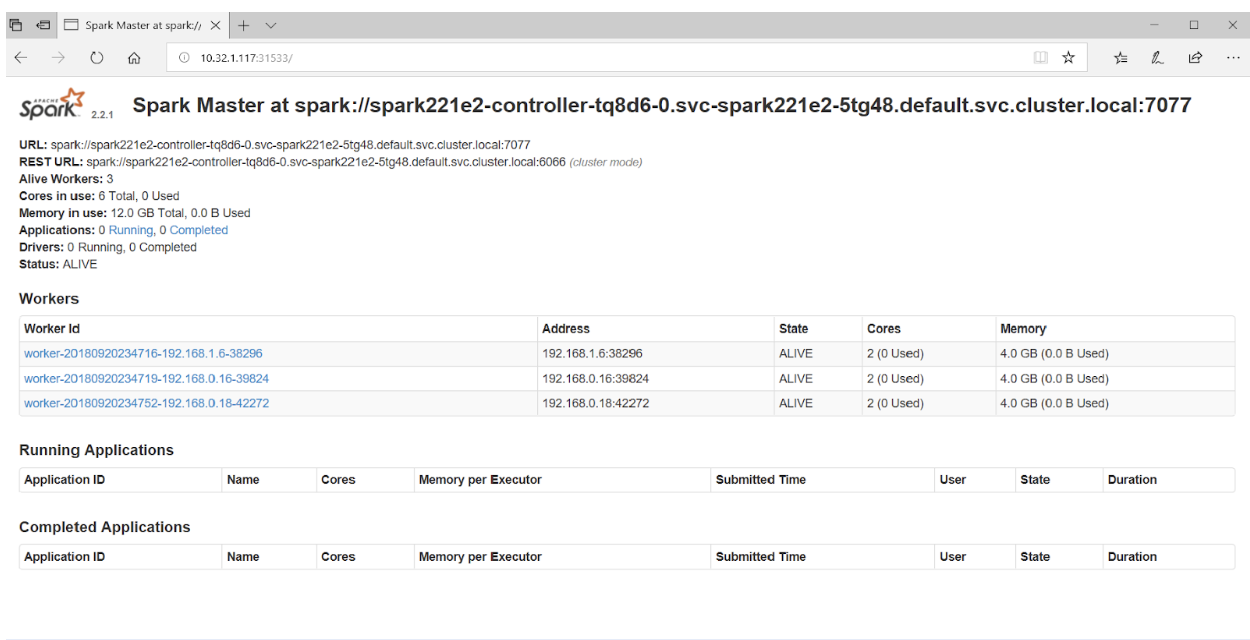
Isso é tudo! No exemplo acima, além do cluster Spark, também implantamos o
Jupyter Notebook .
Para iniciar outro aplicativo (por exemplo, Cassandra), basta especificar outro arquivo com o
KubeDirectorApp :
kubectl create -f deploy/example_clusters/cr-cluster-cassandra311.yaml
Verifique se o cluster Cassandra foi iniciado:
~> kubectl get pods NAME READY STATUS RESTARTS AGE cassandra311-seed-v24r6-0 1/1 Running 0 1m cassandra311-seed-v24r6-1 1/1 Running 0 1m cassandra311-worker-rqrhl-0 1/1 Running 0 1m cassandra311-worker-rqrhl-1 1/1 Running 0 1m kubedirector-58cf59869-djdwl 1/1 Running 0 1d spark221e2-controller-tq8d6-0 1/1 Running 0 22m spark221e2-jupyter-6989v-0 1/1 Running 0 22m spark221e2-worker-d9892-0 1/1 Running 0 22m spark221e2-worker-d9892-1 1/1 Running 0 22m
O Kubernetes agora executa o cluster Spark (com o Jupyter Notebook) e o cluster Cassandra. A lista de serviços pode ser vista com o comando
kubectl get service :
~> kubectl get service NAME TYPE CLUSTER-IP EXTERNAL-IP PORT(S) AGE kubedirector ClusterIP 10.98.234.194 <none> 60000/TCP 1d kubernetes ClusterIP 10.96.0.1 <none> 443/TCP 1d svc-cassandra311-seed-v24r6-0 NodePort 10.96.94.204 <none> 22:31131/TCP,9042:30739/TCP 3m svc-cassandra311-seed-v24r6-1 NodePort 10.106.144.52 <none> 22:30373/TCP,9042:32662/TCP 3m svc-cassandra311-vhh29 ClusterIP None <none> 8888/TCP 3m svc-cassandra311-worker-rqrhl-0 NodePort 10.109.61.194 <none> 22:31832/TCP,9042:31962/TCP 3m svc-cassandra311-worker-rqrhl-1 NodePort 10.97.147.131 <none> 22:31454/TCP,9042:31170/TCP 3m svc-spark221e2-5tg48 ClusterIP None <none> 8888/TCP 24m svc-spark221e2-controller-tq8d6-0 NodePort 10.104.181.123 <none> 22:30534/TCP,8080:31533/TCP,7077:32506/TCP,8081:32099/TCP 24m svc-spark221e2-jupyter-6989v-0 NodePort 10.105.227.249 <none> 22:30632/TCP,8888:30355/TCP 24m svc-spark221e2-worker-d9892-0 NodePort 10.107.131.165 <none> 22:30358/TCP,8081:32144/TCP 24m svc-spark221e2-worker-d9892-1 NodePort 10.110.88.221 <none> 22:30294/TCP,8081:31436/TCP 24m
PS do tradutor
Se você estiver interessado no projeto KubeDirector, você também deve prestar atenção ao
seu wiki . Infelizmente, não foi possível encontrar um roteiro público; no entanto,
problemas no GitHub lançaram luz sobre o andamento do projeto e as visões de seus principais desenvolvedores. Além disso, para os interessados no KubeDirector, os autores fornecem links para o
Slack chat e o
Twitter .
Leia também em nosso blog: