A primeira coisa que encontramos quando falamos em otimização proativa é que não se sabe o que precisa ser otimizado. "Faça isso, eu não sei o que."
- Não há algoritmo clássico.
- O problema ainda não surgiu (desconhecido), e só podemos adivinhar onde pode estar.
- Precisamos encontrar alguns pontos fracos em potencial no sistema.
- Tente otimizar o desempenho da consulta nesses locais.
Os principais objetivos da otimização proativa
As principais tarefas da otimização proativa diferem das tarefas da otimização reativa e são as seguintes:
- livrar-se de gargalos no banco de dados;
- diminuição no consumo de recursos do banco de dados.
O último momento é o mais fundamental. No caso de otimização reativa, não temos a tarefa de reduzir o consumo de recursos como um todo, mas apenas a tarefa de levar o tempo de resposta da funcionalidade para dentro dos limites aceitáveis.
Se você trabalha com servidores de batalha, tem uma boa idéia do que significam incidentes de desempenho. Você precisa sair de tudo e resolver rapidamente o problema. O RNKO Payment Center LLC trabalha com muitos agentes e é muito importante que eles tenham o mínimo de problemas possível. Alexander Makarov, da HighLoad ++ Siberia, contou o que foi feito para reduzir significativamente o número de incidentes de desempenho. A otimização proativa veio em socorro. E por que e como é produzido em um servidor de combate, leia abaixo.
 Sobre o Orador:
Sobre o Orador: Alexander Makarov (
AL_IG_Makarov ), Administrador Líder do Banco de Dados Oracle, LLC RNCO Payment Center. Apesar da posição, há muito pouca administração como tal, as principais tarefas estão relacionadas à manutenção do complexo e seu desenvolvimento, em particular, a solução de problemas de desempenho.
A otimização em um banco de dados de combate é proativa?
Primeiro, trataremos dos termos aos quais este relatório se refere como "otimização proativa de desempenho". Às vezes, você pode conhecer o ponto de vista de que a otimização proativa ocorre quando a análise das áreas problemáticas é realizada antes mesmo do lançamento do aplicativo. Por exemplo, descobrimos que algumas consultas não funcionam da melhor maneira, pois não há índice suficiente ou a consulta usa um algoritmo ineficiente, e esse trabalho é feito em servidores de teste.
No entanto, nós da RNCO fizemos esse projeto
em servidores de batalha . Muitas vezes ouvi: “Como assim? Você faz isso em um servidor de combate - isso significa que não é uma otimização proativa do desempenho! ” Aqui precisamos lembrar a abordagem cultivada no ITIL. Do ponto de vista da ITIL, temos:
- incidentes de desempenho são o que já aconteceu;
- as medidas que tomamos para impedir a ocorrência de incidentes de desempenho.
Nesse sentido, nossas ações são proativas. Apesar de estarmos resolvendo o problema em um servidor de combate, o problema em si ainda não surgiu: o incidente não ocorreu, não corremos e não tentamos resolvê-lo em pouco tempo.
Portanto, neste relatório, proatividade é entendida como
proatividade no sentido de ITIL , resolvemos o problema antes que ocorra um incidente de desempenho.
Ponto de referência
O "Centro de Pagamento" da RNKO atende a 2 grandes sistemas:
- RBS-Banco de varejo;
- Banco CFT.
A natureza da carga nesses sistemas é mista (DSS + OLTP): há algo que funciona muito rapidamente, há relatórios, há cargas médias.
Somos confrontados com o fato de que não com muita frequência, mas com uma certa frequência, ocorreram incidentes de desempenho. Quem trabalha com servidores de batalha imagina o que é. Isso significa que você precisa encerrar tudo e resolver rapidamente o problema, porque, nesse momento, o cliente não pode receber o serviço, algo ou não funciona, ou funciona muito devagar.
Como muitos agentes e clientes estão ligados à nossa organização, isso é muito importante para nós. Se não conseguirmos resolver rapidamente os incidentes de desempenho, nossos clientes sofrerão de uma maneira ou de outra. Por exemplo, eles não poderão reabastecer um cartão ou fazer uma transferência. Portanto, nos perguntamos o que poderia ser feito para eliminar até mesmo esses incidentes de desempenho pouco frequentes. Para trabalhar em um modo em que você precise largar tudo e resolver um problema - isso não está totalmente correto. Usamos sprints e elaboramos um plano de trabalho. A presença de incidentes de desempenho também é um desvio do plano de trabalho.
Algo deve ser feito com isso!
Abordagens de otimização
Pensamos e chegamos a entender a tecnologia da otimização proativa. Mas antes de falar sobre otimização proativa, devo dizer algumas palavras sobre a otimização reativa clássica.
Otimização reativa
O cenário é simples, existe um servidor de combate no qual algo aconteceu: eles lançaram um relatório, os clientes recebem instruções, neste momento há atividade em andamento no banco de dados e, de repente, alguém decidiu atualizar algum tipo de diretório volumoso. O sistema começa a desacelerar. Nesse momento, o cliente chega e diz: "Eu não posso fazer isso ou aquilo" - precisamos encontrar uma razão pela qual ele não pode fazer isso.
Algoritmo de ação clássico:- Reproduza o problema.
- Localize o ponto do problema.
- Otimize o local do problema.
Dentro da estrutura da abordagem reativa, a tarefa principal não é tanto encontrar a causa raiz e eliminá-la, mas fazer o sistema funcionar normalmente. A eliminação da causa raiz pode ser tratada mais tarde. O principal é restaurar rapidamente o servidor para que o cliente possa receber o serviço.
Os principais objetivos da otimização reativa
Na otimização reativa, dois objetivos principais podem ser distinguidos:
1.
Diminuir o tempo de resposta .
Uma ação, por exemplo, recebendo um relatório, extrato, transação, deve ser executada por algum tempo agendado. É necessário garantir que o tempo de recebimento do serviço retorne aos limites aceitáveis para o cliente. Talvez o serviço funcione um pouco mais devagar que o normal, mas para o cliente isso é aceitável. Então acreditamos que o incidente de desempenho foi eliminado e começamos a trabalhar na causa raiz.
2.
Um aumento no número de objetos processados por unidade de tempo durante o processamento em lote .
Quando o processamento em lote de transações está em andamento, é necessário reduzir o tempo de processamento de um objeto a partir de um lote.
Prós de uma abordagem reativa:●
Uma variedade de ferramentas e técnicas é a principal vantagem de uma abordagem reativa.
Usando ferramentas de monitoramento, podemos entender qual é o problema diretamente: não há CPU, threads, memória ou o sistema de disco escorregou ou os logs estão sendo processados lentamente. Existem muitas ferramentas e técnicas para estudar o problema de desempenho atual no banco de dados Oracle.
● O
tempo de resposta desejado é outra vantagem.
No processo desse trabalho, levamos a situação a um tempo de resposta aceitável, ou seja, não tentamos reduzi-la ao valor mínimo, mas atingimos um certo valor e, após essa ação, terminamos, porque acreditamos que atingimos limites aceitáveis.
Contras da abordagem reativa:- Os incidentes de desempenho permanecem - esse é o maior ponto negativo da abordagem reativa, porque nem sempre podemos alcançar a causa raiz. Ela poderia ficar em algum lugar fora do caminho e mentir em algum lugar mais profundo, apesar do fato de termos alcançado um desempenho aceitável.
E como lidar com incidentes de desempenho se eles ainda não aconteceram? Vamos tentar formular como a otimização proativa pode ser realizada para evitar tais situações.
Otimização proativa
A primeira coisa que encontramos é que não se sabe o que precisa ser otimizado. "Faça isso, eu não sei o que."
- Não há algoritmo clássico.
- O problema ainda não surgiu (desconhecido), e só podemos adivinhar onde pode estar.
- Precisamos encontrar alguns pontos fracos em potencial no sistema.
- Tente otimizar o desempenho da consulta nesses locais.
Os principais objetivos da otimização proativa
As principais tarefas da otimização proativa diferem das tarefas da otimização reativa e são as seguintes:
- livrar-se de gargalos no banco de dados;
- diminuição no consumo de recursos do banco de dados.
O último momento é o mais fundamental. No caso de otimização reativa, não temos a tarefa de reduzir o consumo de recursos como um todo, mas apenas a tarefa de levar o tempo de resposta da funcionalidade para dentro dos limites aceitáveis.
Como encontrar gargalos no banco de dados?
Quando começamos a pensar sobre esse problema, muitas subtarefas surgem imediatamente. É necessário executar:
- Teste de CPU
- teste de carga em leituras / registros;
- teste de estresse pelo número de sessões ativas;
- teste de carga em ... etc.
Se tentarmos simular esses problemas em um complexo de teste, podemos encontrar o fato de que o problema que surgiu no servidor de teste não tem nada a ver com o de combate. Há muitas razões para isso, começando com o fato de que os servidores de teste geralmente são mais fracos. Bem, se é possível tornar o servidor de teste uma cópia exata do combate, mas isso não garante que a carga seja reproduzida da mesma maneira, porque você precisa reproduzir com precisão a atividade do usuário e muitos outros fatores que afetam a carga final. Se você tentar simular essa situação, em geral, ninguém garante que exatamente a mesma coisa acontecerá no servidor de batalha.
Se, em um caso, o problema surgiu porque um novo registro chegou, no outro poderia surgir porque o usuário lançou um relatório enorme fazendo uma classificação grande, por causa do qual o espaço de tabela temporário foi preenchido e, como Como resultado, o sistema começou a desacelerar. Ou seja, os motivos podem ser diferentes e nem sempre é possível prever. Portanto,
abandonamos as tentativas de procurar gargalos nos servidores de teste quase desde o início. Confiamos apenas no servidor de combate e no que estava acontecendo nele.
O que fazer neste caso? Vamos tentar entender quais os recursos com maior probabilidade de faltar em primeiro lugar.
Diminuindo o consumo de recursos do banco de dados
Com base nos complexos industriais que temos à nossa disposição, a
falta mais frequente de recursos é observada nas leituras de disco e nas CPUs . Portanto, em primeiro lugar, procuraremos pontos fracos precisamente nessas áreas.
A segunda questão importante: como procurar algo?
A questão é muito trivial. Usamos o Oracle Enterprise Edition com a opção Diagnostic Pack e, por nós mesmos, encontramos essa ferramenta -
relatórios AWR (em outras edições do Oracle, você pode usar os
relatórios STATSPACK ). No PostgreSQL, há um analógico - pgstatspack, há
pg_profile de Andrey Zubkov. O último produto, como eu o entendo, apareceu e começou a se desenvolver apenas no ano passado. Para o MySQL, não consegui encontrar ferramentas semelhantes, mas não sou especialista em MySQL.
A abordagem em si não está vinculada a nenhum tipo específico de banco de dados. Se for possível obter informações sobre a carga do sistema em algum relatório, usando a técnica sobre a qual falarei agora, você poderá executar o trabalho de otimização proativa
em qualquer base .
Otimização das 5 principais operações
A tecnologia de otimização proativa que desenvolvemos e estamos usando no Payment Center RNCO consiste em quatro estágios.
Etapa 1. Recebemos o relatório AWR pelo maior período possível.O maior período de tempo possível é necessário para calcular a carga média em diferentes dias da semana, pois às vezes é muito diferente. Por exemplo, os registros da semana passada chegam ao RBS-Retail Bank na terça-feira, começam a ser processados e, durante todo o dia, temos uma carga média de cerca de 2 a 3 vezes. Nos outros dias, a carga é menor.
Se você souber que o sistema possui algumas especificidades - em alguns dias a carga é maior, em alguns dias - menos, será necessário receber relatórios para esses períodos separadamente e trabalhar com eles separadamente, se quisermos otimizar intervalos de tempo específicos . Se você precisar otimizar a situação geral no servidor, poderá obter um grande relatório para o mês e ver o que os recursos do servidor realmente consomem.
Às vezes, situações muito inesperadas aparecem. Por exemplo, no caso do CFT Bank, uma solicitação que verifique a fila do servidor de relatório pode estar entre os 10 primeiros. Além disso, essa solicitação é oficial e não executa nenhuma lógica comercial, mas apenas verifica se há ou não um relatório de execução.
Etapa 2. Observamos as seções:- SQL ordenado por tempo decorrido - consultas SQL classificadas por tempo de execução;
- SQL ordenado pelo CPU Time - para uso da CPU;
- SQL ordenado por Gets - por leituras lógicas;
- SQL ordenado por leituras - para leituras físicas.
As seções restantes do SQL ordenadas por são estudadas conforme necessário.
Etapa 3. Determinamos as operações e solicitações dos pais dependentes delas.O relatório AWR possui seções separadas em que, dependendo da versão do Oracle, 15 ou mais consultas principais são exibidas em cada uma dessas seções. Mas essas consultas da Oracle no relatório AWR mostram uma bagunça.
Por exemplo, há uma operação pai, nela podem haver três consultas principais. O Oracle no relatório AWR mostrará a operação pai e todas essas três consultas. Portanto, você precisa fazer uma análise dessa lista e ver a quais solicitações específicas de operação se referem, agrupá-las.
Etapa 4. Otimizamos as 5 principais operações.Após esse agrupamento, a saída é uma lista de operações das quais você pode selecionar as mais difíceis. Estamos limitados a 5 operações (não solicitações, ou seja, operações). Se o sistema for mais complexo, você poderá usar mais.
Erros comuns de design de consulta
Durante a aplicação desta técnica, compilamos uma pequena lista de erros típicos de design. Alguns erros são tão simples que parece que não podem ser.
●
Falta de índice → Verificação completaExistem casos muito incidentais, por exemplo, com a ausência de um índice no esquema de combate. Tivemos um exemplo concreto em que uma consulta por muito tempo funcionou rapidamente sem um índice. Mas houve uma varredura completa e, à medida que o tamanho da tabela aumentou gradualmente, a consulta começou a funcionar mais lentamente e, de um quarto para outro, demorou um pouco mais. No final, prestamos atenção a ele e constatamos que o índice não está lá.
●
Seleção ampla → Varredura completaO segundo erro comum é uma grande amostra de dados - o caso clássico de uma verificação completa. Todo mundo sabe que uma verificação completa deve ser usada apenas quando for realmente justificada. Às vezes, há momentos em que uma varredura completa aparece onde você poderia ficar sem ela, por exemplo, se você transferir as condições de filtragem do código pl / sql para a consulta.
●
Índice ineficaz → Longo INDEX RANGE SCANTalvez este seja até o erro mais comum, pelo qual, por algum motivo, eles dizem muito pouco - o chamado índice ineficiente (varredura longa de índice, varredura longa de INDEX RANGE). Por exemplo, temos uma tabela para registros. Na solicitação, tentamos encontrar todos os registros desse agente e, por fim, adicionamos algum tipo de condição de filtragem, por exemplo, por um determinado período, ou com um número específico ou um cliente específico. Nessas situações, o índice geralmente é criado apenas no campo "agente" por razões de universalidade de uso. O resultado é a seguinte imagem: no primeiro ano de trabalho, por exemplo, o agente teve 100 entradas nesta tabela, no próximo ano já 1.000, em outro ano pode haver 10.000 entradas. Com o passar do tempo, esses registros se tornam 100.000. Obviamente, a solicitação começa a funcionar lentamente, porque na solicitação você precisa adicionar não apenas o próprio identificador do agente, mas também algum filtro adicional, neste caso por data. Caso contrário, o tamanho da amostra aumentará de ano para ano, à medida que o número de registros desse agente estiver aumentando. Esse problema deve ser resolvido no nível do índice. Se houver muitos dados, já devemos pensar na direção do particionamento.
●
Ramos de código de distribuição desnecessáriosEste também é um caso curioso, mas, no entanto, acontece. Olhamos para as principais consultas e vemos algumas consultas estranhas lá. Chegamos aos desenvolvedores e dizemos: "Encontramos alguns pedidos, vamos descobrir e ver o que pode ser feito sobre isso". O desenvolvedor pensa, depois de um tempo e diz: “Este ramo de código não deve estar no seu sistema. Você não usa essa funcionalidade. ” Em seguida, o desenvolvedor recomenda que você ative alguma configuração especial para contornar esta seção do código.
Estudos de caso
Agora eu gostaria de considerar dois exemplos de nossa prática real. Quando lidamos com as principais consultas, é claro que antes de tudo pensamos no fato de que deve haver algo mega pesado, não trivial, com operações complexas. De fato, esse nem sempre é o caso. Às vezes, existem casos em que consultas muito simples se enquadram nas principais operações.
Exemplo 1
select * from (select o.* from rnko_dep_reestr_in_oper o where o.type_oper = 'proc' and o.ean_rnko in (select l.ean_rnko from rnko_dep_link l where l.s_rnko = :1) order by o.date_oper_bnk desc, o.date_reg desc) where ROWNUM = 1
Neste exemplo, uma consulta consiste em apenas duas tabelas, e essas não são tabelas pesadas - apenas alguns milhões de registros. Parece mais fácil? No entanto, a solicitação chegou ao topo.
Vamos tentar descobrir o que há de errado com ele.
Abaixo está uma imagem do Enterprise Manager Cloud Control - dados sobre as estatísticas desta solicitação (a Oracle possui uma ferramenta). Pode-se observar que há uma carga regular nessa solicitação (gráfico superior). O número 1 ao lado indica que, em média, não há mais de uma sessão em execução. O diagrama verde mostra que a
solicitação usa apenas a CPU , o que é duplamente interessante.

Vamos tentar descobrir o que está acontecendo aqui?

Acima está uma tabela com estatísticas a pedido. Quase 700 mil lançamentos - isso não surpreenderá ninguém. Mas o intervalo de tempo entre o Primeiro carregamento em 15 de dezembro e o Último carregamento em 22 de dezembro (veja a figura anterior) é de uma semana. Se você contar o número de partidas por segundo, a
consulta será executada em média a cada segundo .
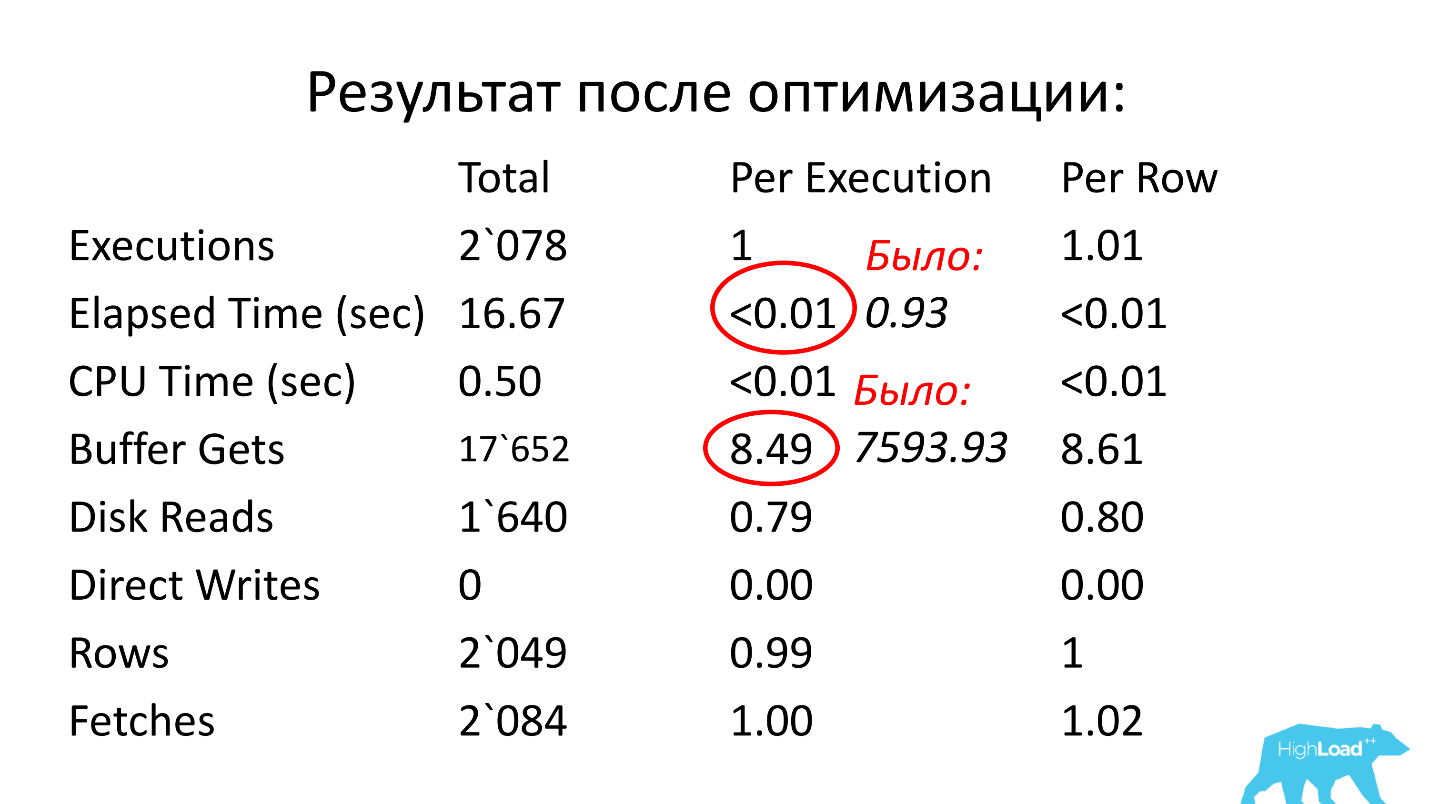
Nós olhamos mais longe. O tempo de execução da consulta é de 0,93 segundos, ou seja, menos de um segundo, isso é ótimo. Podemos nos alegrar - o pedido não é pesado. No entanto, ele chegou ao topo, o que significa que ele consome muitos recursos. Onde consome muitos recursos?
A tabela possui uma linha para leituras lógicas. Vemos que, para um lançamento, ele precisa de quase 8 mil blocos (normalmente 1 bloco tem 8 KB). Acontece que a solicitação, trabalhando uma vez por segundo, carrega cerca de 64 MB de dados da memória. Algo está errado aqui, precisamos entender.
Vamos ver o plano: há uma varredura completa. Bem, vamos seguir em frente.
Plan hash value: 634977963
Na tabela rnko_dep_reestr_in_oper, existem apenas 5 milhões de linhas e seu comprimento médio é de 150 bytes. Mas aconteceu que não há índice suficiente para o campo que está se conectando - a subconsulta é conectada à solicitação através do campo ean_rnko, para o qual não há índice!
Além disso, mesmo que ele apareça, de fato a situação não será muito boa. Essa verificação de índice longa (INDEX RANGE SCAN) ocorrerá. ean_rnko é o identificador interno do agente. Os registros do agente serão acumulados e, a cada ano, a quantidade de dados que essa solicitação selecionará aumentará e a solicitação diminuirá.
Solução: crie um índice para os campos ean_rnko e date_reg, solicite aos desenvolvedores que limitem a profundidade da verificação por data nesta solicitação. Em seguida, você pode pelo menos em certa medida garantir que o desempenho da consulta permanecerá aproximadamente nos mesmos limites, pois o tamanho da amostra será limitado a um intervalo de tempo fixo e a tabela inteira não precisará ser lida. Este é um ponto muito importante, veja o que aconteceu.
Após a otimização, o tempo de operação ficou menor que um centésimo de segundo (era 0,93), o número de blocos se tornou uma média de 8,5 a 1000 vezes menor que antes.
Exemplo 2
select count(1) from loy$barcodes t where t.id_processing = :b1 and t.id_rec_out is null and not t.barcode is null and t.status = 'u' and not t.id_card is null
Comecei a história dizendo que geralmente algo complicado é esperado no topo da consulta. Abaixo está um exemplo de uma consulta "complexa" que vai para uma tabela (!), E também entra nas principais consultas :) Há um índice no campo ID_PROCESSING!
Existem 3 condições IS NULL nesta consulta e, como sabemos, essas condições não são indexadas (você não pode usar o índice nesse caso). Além disso, existem apenas duas condições do tipo de igualdade (por ID_PROCESSING e STATUS).
Provavelmente, o desenvolvedor que examinaria essa consulta, antes de tudo, sugeriria criar um índice em ID_PROCESSING e STATUS. Mas, dada a quantidade de dados que serão escolhidos (haverá muitos deles), essa solução não funciona.
No entanto, a solicitação consome muitos recursos, o que significa que algo precisa ser feito para fazê-lo funcionar mais rapidamente. Vamos tentar descobrir os motivos.

As estatísticas acima são de 1 dia, a partir das quais é possível observar que a solicitação é iniciada a cada 5 minutos. O principal consumo de recursos é a CPU e a leitura do disco. Abaixo no gráfico com estatísticas do número de consultas iniciadas, é possível observar que tudo está em ordem - o número de partidas quase não muda ao longo do tempo - uma situação bastante estável.

E, se você procurar mais, pode ver que o tempo de consulta às vezes varia bastante - várias vezes, o que já é significativo.
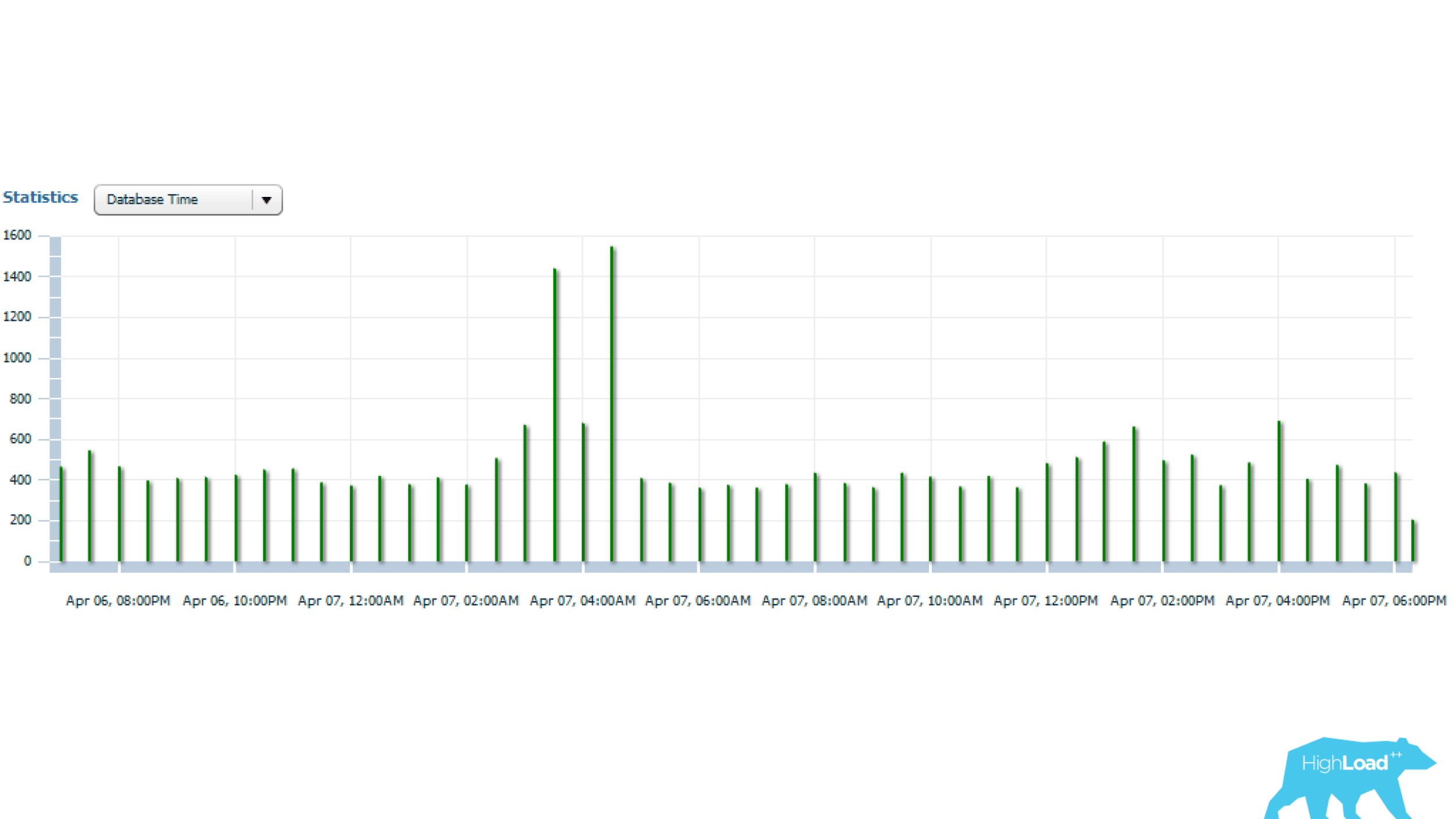
Vamos descobrir a seguir.
O Oracle Enterprise Manager possui um utilitário de monitoramento de SQL. Com este utilitário, você pode ver em tempo real o consumo de recursos por solicitação.

Relatório acima para solicitação problemática. Antes de tudo, devemos estar interessados no fato de que a INDEX RANGE SCAN (linha inferior) na coluna Linhas reais mostra 17 milhões de linhas. Provavelmente vale a pena considerar.
Se olharmos mais para o plano de implementação, verifica-se que, após o próximo item do plano, dessas 17 milhões de linhas, restam apenas 1705. A questão é: por que foram escolhidos 17 milhões? Cerca de 0,01% permaneceu na amostra final, ou seja
, obviamente ineficiente, foi realizado um trabalho desnecessário . Além disso, este trabalho é realizado a cada 5 minutos. Aqui está o problema! Portanto, essa solicitação atingiu as principais consultas.
Vamos tentar resolver esse problema não trivial. O índice que se implora em primeiro lugar é ineficiente, então você precisa criar algo complicado e derrotar as condições IS NULL.
Novo índice
Consultamos os desenvolvedores, pensamos e tomamos essa decisão: criamos um índice funcional no qual existe uma coluna ID_PROCESSING, que estava com a condição de igualdade na solicitação e incluímos todos os outros campos como argumentos dessa função:
create index gc.loy$barcod_unload_i on gc.loy$barcodes (gc.loy_barcodes_ic_unload(id_rec_out, barcode, id_card, status), id_processing); function loy_barcodes_ic_unload( pIdRecOut in loy$barcodes.id_rec_out%type, pBarcode in loy$barcodes.barcode%type, pIdCard in loy$barcodes.id_card%type, pStatus in loy$barcodes.status%type) return varchar2 deterministic is vRes varchar2(1) := ''; begin if pIdRecOut is null and pBarcode is not null and pIdCard is not null and pStatus = 'U' then vRes := pStatus; end if; return vRes; end loy_barcodes_ic_unload;
Essa função é do tipo determinística, ou seja, no mesmo conjunto de parâmetros, sempre fornece a mesma resposta. Garantimos que essa função sempre retornasse sempre um valor - neste caso, "U". Quando todas essas condições são cumpridas, "U" é emitido, quando não preenchido - NULL. Esse índice funcional torna possível filtrar efetivamente os dados.
A aplicação desse índice levou ao seguinte resultado:
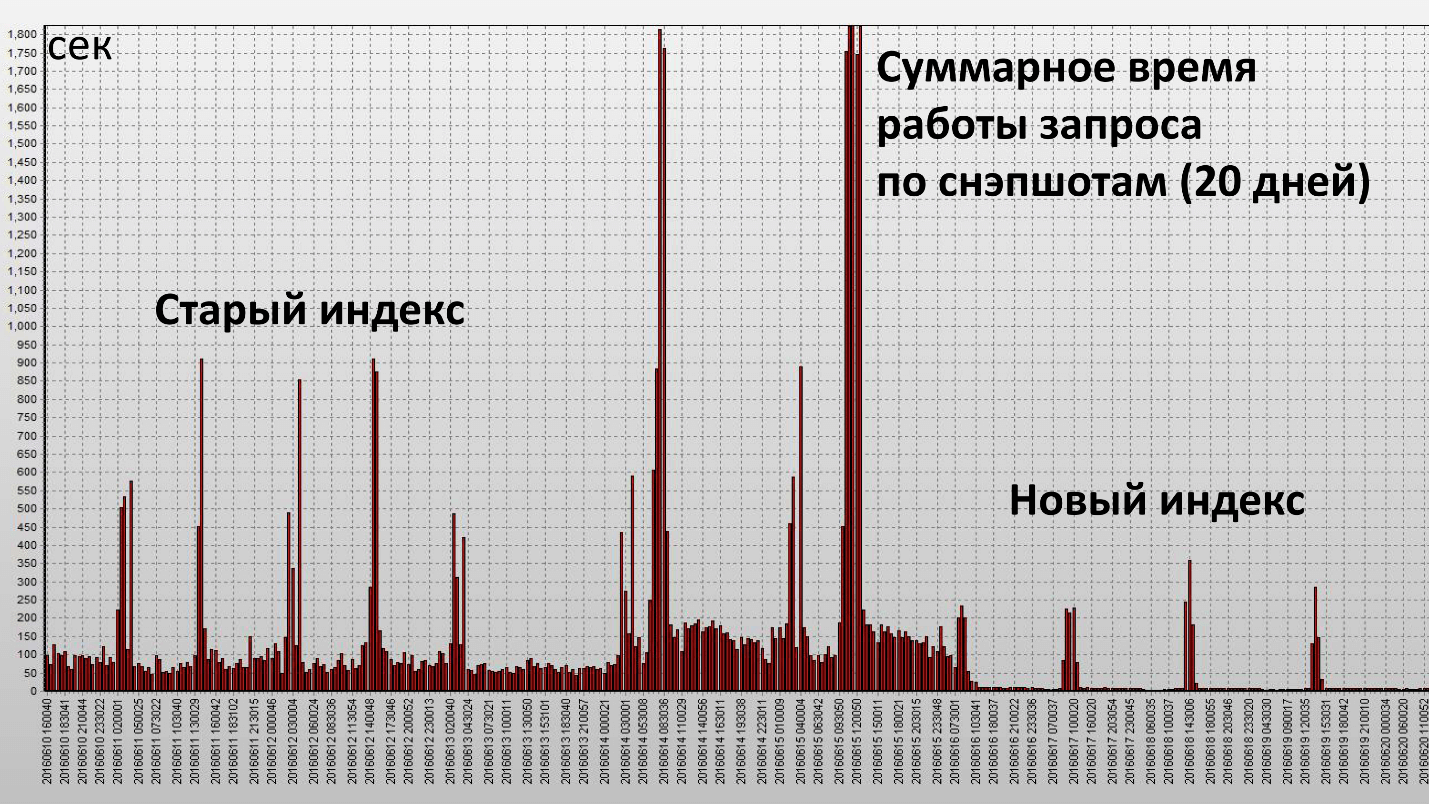
Aqui, uma coluna é uma captura instantânea, elas são feitas a cada meia hora do banco de dados. Atingimos nosso objetivo e esse índice foi realmente eficaz. Vamos ver as características quantitativas:
Estatísticas médias de solicitação
|
| Antes de
| DEPOIS
|
Tempo decorrido, seg
| 143,21
| 60,7
|
Tempo da CPU, seg
| 33,23
| 45,38
|
Buffer Obtém Bloco
| 6`288`237,67
| 1`589`836
|
Bloco de leitura de disco
| 266`600,33
| 2`680
|
O tempo operacional diminuiu 2,5 vezes e o consumo de recursos (Buffer Gets) - cerca de 4. O número de blocos de dados lidos no disco diminuiu significativamente.
Resultados de otimização proativa
Recebemos:
- reduzindo a carga no banco de dados;
- melhorar a estabilidade do banco de dados;
- uma redução significativa no número de incidentes de desempenho de software.
Os incidentes de desempenho diminuíram 10 vezes . É uma quantia subjetiva, antes dos incidentes ocorrerem no complexo RBS-Retail Bank, 1-2 vezes por mês, mas agora praticamente nos esquecemos deles.
Isso levanta a questão - e os incidentes de desempenho de software? Nós não lidamos com eles diretamente?
Voltar para a última agenda. Se você se lembra, havia uma varredura completa, era necessário armazenar um grande número de blocos na memória. Como a solicitação foi executada regularmente, todos esses blocos foram armazenados no cache do Oracle. Acontece que, se nesse momento ocorrer uma carga alta no banco de dados, por exemplo, alguém começar a usar a memória ativamente, será necessário um cache para armazenar os blocos de dados. Assim, parte dos dados de nossa solicitação será compactada, o que significa que teremos que fazer leituras físicas. Se você fizer leituras físicas, o tempo de execução da consulta aumentará tremendamente imediatamente.
A leitura lógica está funcionando com a memória, acontece rapidamente e qualquer acesso ao disco é lento (se você observar as horas, milissegundos). Se você tiver sorte e houver esses dados no cache do sistema operacional ou no cache da matriz, ainda serão dezenas de microssegundos. A leitura do cache do Oracle é muito mais rápida.
Quando nos livramos da verificação completa, a necessidade de armazenar um número tão grande de blocos no cache (Buffer Cache) desapareceu. Quando há falta desses recursos, a solicitação é mais ou menos estável. Não há mais picos tão grandes que estavam com o índice antigo.
Resumo da otimização proativa:- A otimização inicial da consulta deve ser realizada em servidores de teste, para ver como as consultas e sua lógica de negócios funcionam, para não fazer nada supérfluo. Estes trabalhos permanecem.
- Periodicamente, porém, a cada poucos meses, faz sentido remover relatórios com carga total do servidor, pesquisar as principais consultas e operações no banco de dados e otimizá-las.
Existem muitas ferramentas para obter estatísticas em um banco de dados Oracle:- Relatório AWR (DBMS_WORKLOAD_REPOSITORY.awr_report_html);
- Enterprise Manager Cloud Control 12c (Detalhes do SQL);
- Relatório ativo de detalhes do SQL (DBMS_PERF.report_sql);
- Monitoramento de SQL (guia EMCC);
- Relatório de monitoramento SQL (DBMS_SQLTUNE.report_sql_monitor *).
Algumas dessas ferramentas funcionam no console, ou seja, não estão vinculadas ao Enterprise Manager.
Exemplos de ferramentas Oracle para coletar estatísticas Bônus: os especialistas do “Centro de Pagamento” e CFT da RNCO estavam bem preparados para a conferência em Novosibirsk, fizeram alguns relatórios úteis e também organizaram um rádio de saída real. Durante dois dias, especialistas, palestrantes e organizadores conseguiram visitar a rádio CFT. Você pode voltar ao verão da Sibéria incluindo entradas. Aqui estão os links para os blocos:
Kubernetes: prós e contras ;
Ciência de dados e aprendizado de máquina ;
DevOps .
No HighLoad ++ em Moscou, que já é 8 e 9 de novembro, haverá coisas ainda mais interessantes. O programa inclui relatórios sobre todos os aspectos do trabalho em projetos altamente carregados, master classes, reuniões e eventos de parceiros que compartilharão conselhos de especialistas e encontrarão algo para surpreender. Não deixe de escrever sobre as mais interessantes e notificar no boletim informativo , fique conectado!