Qual é a linguagem de consulta do GraphQL? Quais vantagens essa tecnologia oferece e quais problemas os desenvolvedores enfrentarão ao usá-la? Como usar o GraphQL efetivamente? Sobre tudo isso sob o corte.

O artigo é baseado no relatório de nível introdutório de
Vladimir Tsukur (
volodymyrtsukur ) da conferência
Joker 2017 .
Meu nome é Vladimir, lidero o desenvolvimento de um dos departamentos do WIX. Mais de cem milhões de usuários do WIX criam sites de várias direções - de sites e lojas de cartões de visita a aplicativos web complexos, nos quais você pode escrever código e lógica arbitrária. Como exemplo vivo de um projeto no WIX, gostaria de mostrar a loja de sucesso
unicornadoptions.com , que oferece a oportunidade de comprar um kit para domar um unicórnio - um ótimo presente para uma criança.

Um visitante deste site pode escolher um kit que gosta de domar um unicórnio, digamos rosa, e ver o que exatamente está neste kit: brinquedo, certificado, crachá. Além disso, o comprador tem a oportunidade de adicionar mercadorias à cesta, visualizar seu conteúdo e fazer um pedido. Este é um exemplo simples de site de loja e temos muitas centenas de milhares desses sites. Todos eles são criados na mesma plataforma, com um back-end, com um conjunto de clientes que suportamos usando a API para isso. É sobre a API que será discutida mais adiante.
API simples e seus problemas
Vamos imaginar qual API de uso geral (ou seja, uma API para todas as lojas na parte superior da plataforma) poderíamos criar para fornecer a funcionalidade da loja. Vamos nos concentrar apenas na obtenção de dados.
Para uma página de produto em tal site, o nome do produto, preço, fotos, descrição, informações adicionais e muito mais devem ser retornados. Em uma solução completa para lojas no WIX, existem mais de duas dúzias desses campos de dados. A solução padrão para uma tarefa desse tipo na API HTTP é descrever o recurso
/products/:id , que retorna os dados do produto na solicitação
GET . A seguir, é apresentado um exemplo de dados de resposta:
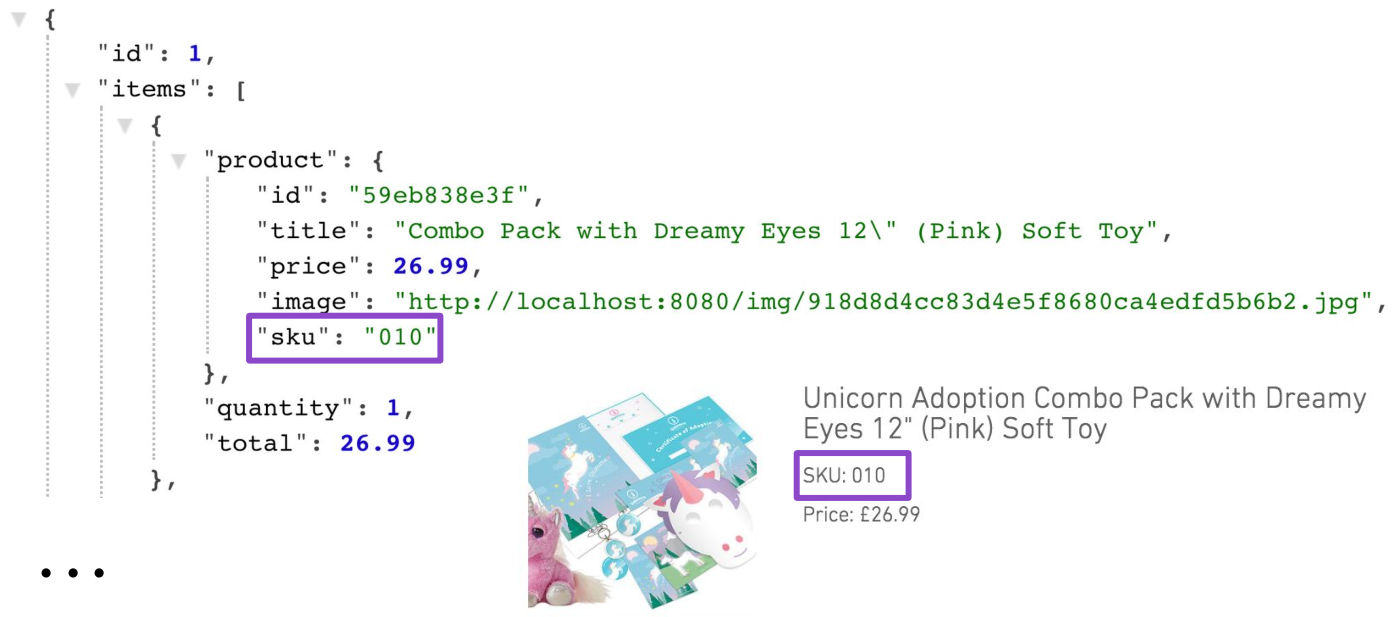
{ "id": "59eb83c0040fa80b29938e3f", "title": "Combo Pack with Dreamy Eyes 12\" (Pink) Soft Toy", "price": 26.99, "description": "Spread Unicorn love amongst your friends and family by purchasing a Unicorn adoption combo pack today. You'll receive your very own fabulous adoption pack and a 12\" Dreamy Eyes (Pink) cuddly toy. It makes the perfect gift for loved ones. Go on, you know you want to, adopt today!", "sku":"010", "images": [ "http://localhost:8080/img/918d8d4cc83d4e5f8680ca4edfd5b6b2.jpg", "http://localhost:8080/img/f343889c0bb94965845e65d3f39f8798.jpg", "http://localhost:8080/img/dd55129473e04f489806db0dc6468dd9.jpg", "http://localhost:8080/img/64eba4524a1f4d5d9f1687a815795643.jpg", "http://localhost:8080/img/5727549e9131440dbb3cd707dce45d0f.jpg", "http://localhost:8080/img/28ae9369ec3c442dbfe6901434ad15af.jpg" ] }

Vamos dar uma olhada na página do catálogo de produtos agora. Para esta página, você precisa da coleção de recursos
/ products . Mas apenas na exibição da coleção de produtos na página do catálogo, nem todos os dados do produto são necessários, mas apenas o preço, o nome e a imagem principal. Por exemplo, a descrição, informações adicionais, imagens de plano de fundo etc. não nos interessam.

Suponhamos, por simplicidade, que decidamos usar o mesmo modelo de dados do produto para os recursos
/products e
/products/:id . No caso de uma coleção desses produtos, haverá potencialmente vários. O esquema de resposta pode ser representado da seguinte maneira:
GET /products [ { title price images description info ... } ]
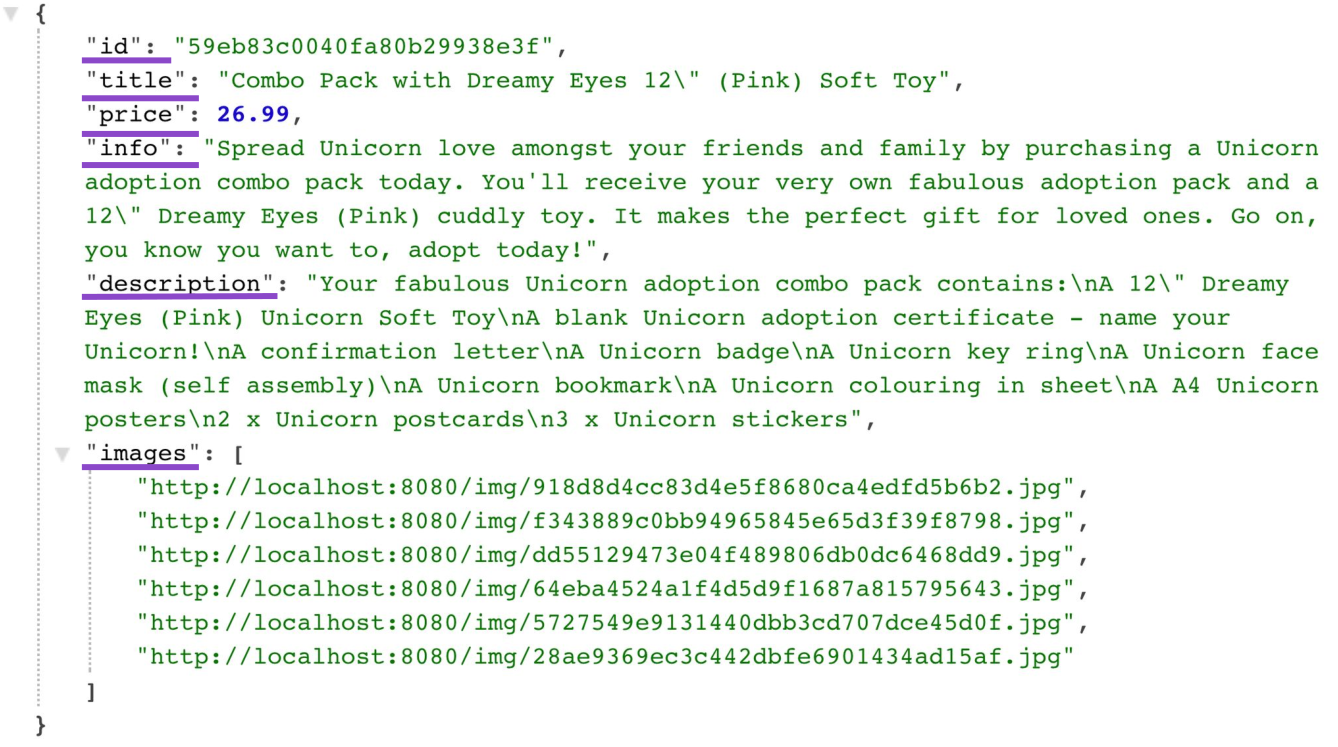
Agora, vejamos a "carga útil" da resposta do servidor para a coleção de produtos. Aqui está o que é realmente usado pelo cliente entre mais de duas dezenas de campos:
{
"id": "59eb83c0040fa80b29938e3f",
"title": "Combo Pack with Dreamy Eyes 12\" (Pink) Soft Toy",
"price": 26.99,
"info": "Spread Unicorn love amongst your friends and family by purchasing a Unicorn adoption combo pack today. You'll receive your very own fabulous adoption pack and a 12\" Dreamy Eyes (Pink) cuddly toy. It makes the perfect gift for loved ones. Go on, you know you want to, adopt todayl",
" description": "Your fabulous Unicorn adoption combo pack contains:\nA 12\" Dreamy Eyes (Pink) Unicorn Soft Toy\nA blank Unicorn adoption certificate — name your Unicorn!\nA confirmation letter\nA Unicorn badge\nA Unicorn key ring\nA Unicorn face mask (self assembly)\nA Unicorn bookmark\nA Unicorn colouring in sheet\nA A4 Unicorn posters\n2 x Unicorn postcards\n3 x Unicorn stickers",
"images": [
"http://localhost:8080/img/918d8d4cc83d4e5f8680ca4edfd5b6b2.jpg",
"http://localhost:8080/img/f343889c0bb94965845e65d3f39f8798.jpg",
"http://localhost:8080/img/dd55129473604f489806db0dC6468dd9.jpg",
"http://localhost:8080/img/64eba4524a1f4d5d9f1687a815795643.jpg",
"http://localhost:8080/img/5727549e9l3l440dbb3cd707dce45d0f.jpg",
"http://localhost:8080/img/28ae9369ec3c442dbfe6901434ad15af.jpg"
],
...
}Obviamente, se eu quiser manter o modelo do produto simples retornando os mesmos dados, acabo com um problema de busca excessiva, obtendo, em alguns casos, mais dados do que preciso. Nesse caso, isso apareceu na página de catálogo do produto, mas, em geral, qualquer tela de interface do usuário que esteja de alguma forma conectada ao produto exigirá dele apenas parte (e não todos) dos dados.
Vamos dar uma olhada na página do carrinho agora. Na cesta, além dos próprios produtos, há também a quantidade (nesta cesta), preço e o custo total de todo o pedido:

Se continuarmos a abordagem de modelagem simples da API HTTP, a cesta poderá ser representada através do recurso
/ carrinhos /: id , cuja apresentação se refere aos recursos dos produtos adicionados a esta cesta:
{ "id": 1, "items": [ { "product": "/products/59eb83c0040fa80b29938e3f", "quantity": 1, "total": 26.99 }, { "product": "/products/59eb83c0040fa80b29938e40", "quantity": 2, "total": 25.98 }, { "product": "/products/59eb88bd040fa8125aa9c400", "quantity": 1, "total": 26.99 } ], "subTotal": 79.96 }
Agora, por exemplo, para desenhar uma cesta com três produtos no front-end, você precisa fazer quatro solicitações: uma para carregar a própria cesta e três solicitações para carregar dados do produto (nome, preço e número de SKU).
O segundo problema que tivemos é a busca insuficiente. A diferenciação de responsabilidades entre a cesta e os recursos do produto levou à necessidade de fazer solicitações adicionais. Obviamente, há várias desvantagens aqui: devido
a um número maior de solicitações, pousamos a bateria do celular mais rapidamente e obtemos a resposta completa mais lentamente. E a escalabilidade da nossa solução também levanta questões.
Obviamente, esta solução não é adequada para produção. Uma maneira de se livrar do problema é adicionar suporte de projeção para a cesta. Uma dessas projeções poderia, além dos dados da própria cesta, retornar dados sobre produtos. Além disso, essa projeção será muito específica, pois é na página da cesta que você precisa do número de inventário (SKU) do produto. Em nenhum outro lugar o SKU era necessário em qualquer outro lugar.
GET /carts/1?projection=with-products
Esse "ajuste" de recursos para uma interface do usuário específica geralmente não termina, e começamos a gerar outras projeções: informações breves na cesta, a projeção da cesta para a web móvel e, depois disso, a projeção para unicórnios.

(Em geral, no WIX Designer, você como usuário pode configurar quais dados do produto você deseja exibir na página do produto e quais dados mostrar na cesta)
E aqui as dificuldades nos esperam: estamos emoldurando o jardim e procurando soluções complexas. Existem poucas soluções padrão do ponto de vista da API para essa tarefa e geralmente dependem muito da estrutura ou da biblioteca de descrição de recursos HTTP.
O que é ainda mais importante, agora está ficando mais difícil trabalhar, porque quando os requisitos do lado do cliente mudam, o back-end deve constantemente "acompanhar" e satisfazê-los.
Como uma “cereja no bolo”, vejamos outra questão importante. No caso de uma API HTTP simples, o desenvolvedor do servidor não tem idéia de que tipo de dados o cliente está usando. O preço é usado? Descrição? Uma ou todas as imagens?
Nesse sentido, várias questões surgem. Como trabalhar com dados obsoletos / obsoletos? Como sei quais dados não estão mais sendo usados? Como é relativamente seguro remover dados da resposta sem interromper a maioria dos clientes? Não há resposta para essas perguntas com a API HTTP usual. Apesar de estarmos otimistas e a API parecer simples, a situação não parece tão quente. Esse intervalo de problemas de API não é exclusivo do WIX. Um grande número de empresas teve que lidar com eles. Agora, é interessante procurar uma solução em potencial.
GraphQL. Iniciar
Em 2012, no processo de desenvolvimento de um aplicativo móvel, o Facebook enfrentou um problema semelhante. Os engenheiros queriam atingir o número mínimo de chamadas de aplicativos móveis para o servidor, enquanto em cada etapa eles recebiam apenas os dados necessários e nada além deles. O resultado de seus esforços foi o GraphQL, apresentado na conferência React Conf 2015. O GraphQL é uma linguagem de descrição de consulta, bem como um ambiente de tempo de execução para essas consultas.

Considere uma abordagem típica para trabalhar com servidores GraphQL.
Nós descrevemos o esquema
O esquema de dados no GraphQL define os tipos e relacionamentos entre eles e o faz de uma maneira fortemente tipada. Por exemplo, imagine um modelo simples de rede social.
User conhece amigos
friends . Os usuários moram na cidade e a cidade conhece seus habitantes através do campo de
citizens . Aqui está o gráfico de um modelo desse tipo no GraphQL:
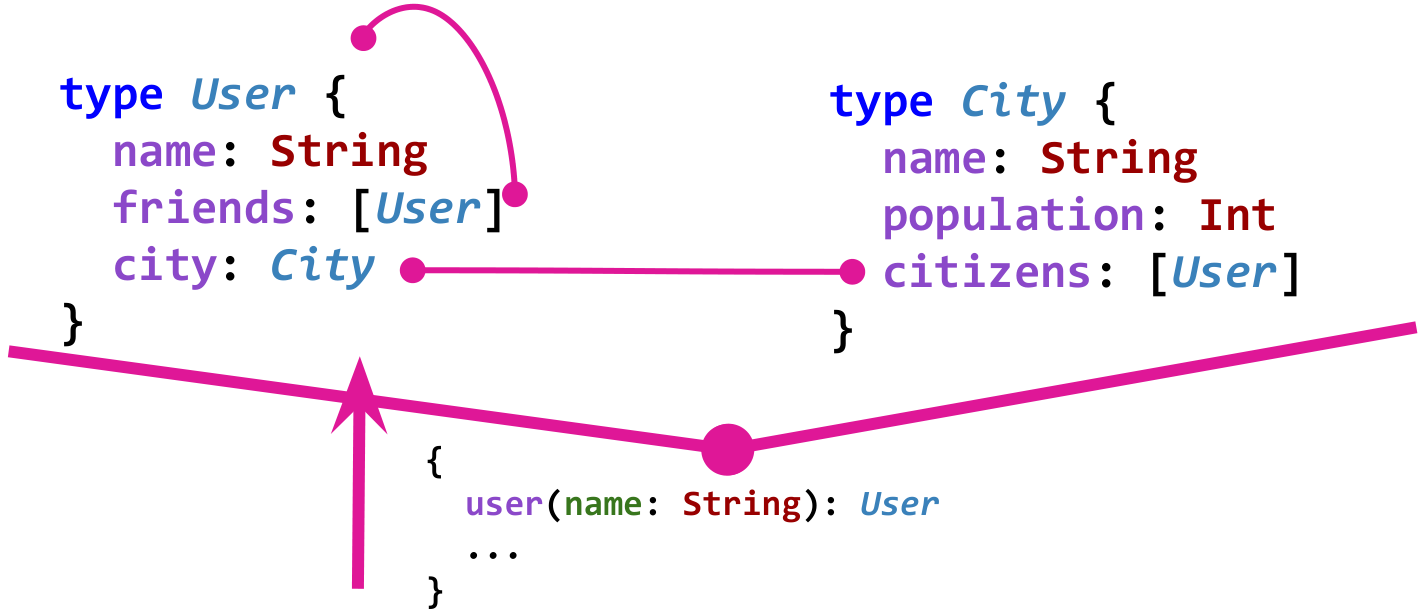
Obviamente, para que o gráfico seja útil, também são necessários os chamados "pontos de entrada". Por exemplo, esse ponto de entrada pode estar recebendo um usuário pelo nome.
Solicitar dados
Vamos ver qual é a essência da linguagem de consulta GraphQL. Vamos traduzir esta pergunta para este idioma:
“Para um usuário chamado Vanya Unicorn, quero saber os nomes de seus amigos, bem como o nome e a população da cidade em que Vanya vive” :
{ user(name: "Vanya Unicorn") { friends { name } city { name population } } }
E aqui vem a resposta do servidor GraphQL:
{ "data": { "user": { "friends": [ { "name": "Lena" }, { "name": "Stas" } ] "city": { "name": "Kyiv", "population": 2928087 } } } }
Observe como o formulário de solicitação é "consoante" com o formulário de resposta. Parece que essa linguagem de consulta foi criada para JSON. Com digitação forte. E tudo isso é feito em uma solicitação HTTP POST - não é necessário fazer várias chamadas para o servidor.
Vamos ver como fica na prática. Vamos abrir o console padrão para o servidor GraphQL, chamado Graph
i QL ("graph"). Para solicitar uma cesta, preencherei a seguinte solicitação:
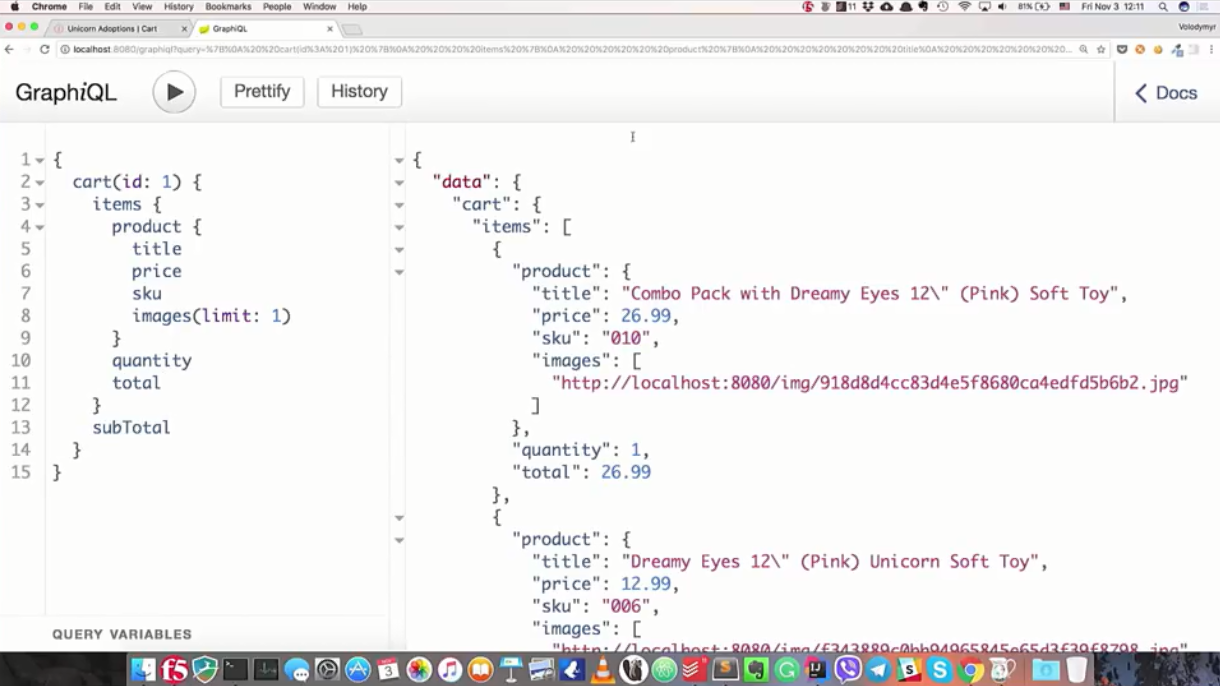
"Quero obter uma cesta pelo identificador 1, estou interessado em todas as posições dessa cesta e nas informações do produto. A partir das informações, o nome, o preço, o número do inventário e as imagens são importantes (e apenas o primeiro). Também estou interessado na quantidade desses produtos, qual é o preço e o custo total da cesta " .
{ cart(id: 1) { items { product { title price sku images(limit: 1) } quantity total } subTotal } }
Após a conclusão bem-sucedida da solicitação, obtemos exatamente o que foi solicitado:
Principais Benefícios
- Amostragem flexível. O cliente pode fazer uma solicitação de acordo com seus requisitos específicos.
- Amostragem eficaz. A resposta retorna apenas os dados solicitados.
- Desenvolvimento mais rápido. Muitas mudanças no cliente podem ocorrer sem a necessidade de alterar nada no lado do servidor. Por exemplo, com base em nosso exemplo, você pode mostrar facilmente uma visualização diferente da cesta da Web para dispositivos móveis.
- Análise útil. Como o cliente deve indicar os campos explicitamente na solicitação, o servidor sabe exatamente quais campos são realmente necessários. E essas são informações importantes para a política de descontinuação.
- Funciona sobre qualquer fonte de dados e transporte. É importante que o GraphQL permita que você trabalhe sobre qualquer fonte de dados e qualquer transporte. Nesse caso, o HTTP não é uma panacéia, o GraphQL também pode funcionar através do WebSocket e abordaremos esse ponto um pouco mais tarde.
Hoje, um servidor GraphQL pode ser fabricado em praticamente qualquer idioma. A versão mais completa do servidor
GraphQL é
GraphQL.js para a plataforma Node. Na comunidade Java, a implementação de referência é
GraphQL Java .
Crie a API GraphQL
Vamos ver como criar um servidor GraphQL em um exemplo de vida concreto.
Considere uma versão simplificada de uma loja online com base em uma arquitetura de microsserviço com dois componentes:
- Serviço de carrinho que fornece trabalho com uma cesta personalizada. Armazena dados em um banco de dados relacional e usa SQL para acessar dados. Serviço muito simples, sem muita magia :)
- Serviço de produto que fornece acesso ao catálogo de produtos, a partir do qual, de fato, a cesta está cheia. Fornece uma API HTTP para acessar dados do produto.
Ambos os serviços são implementados sobre o clássico Spring Boot e já contêm toda a lógica básica.
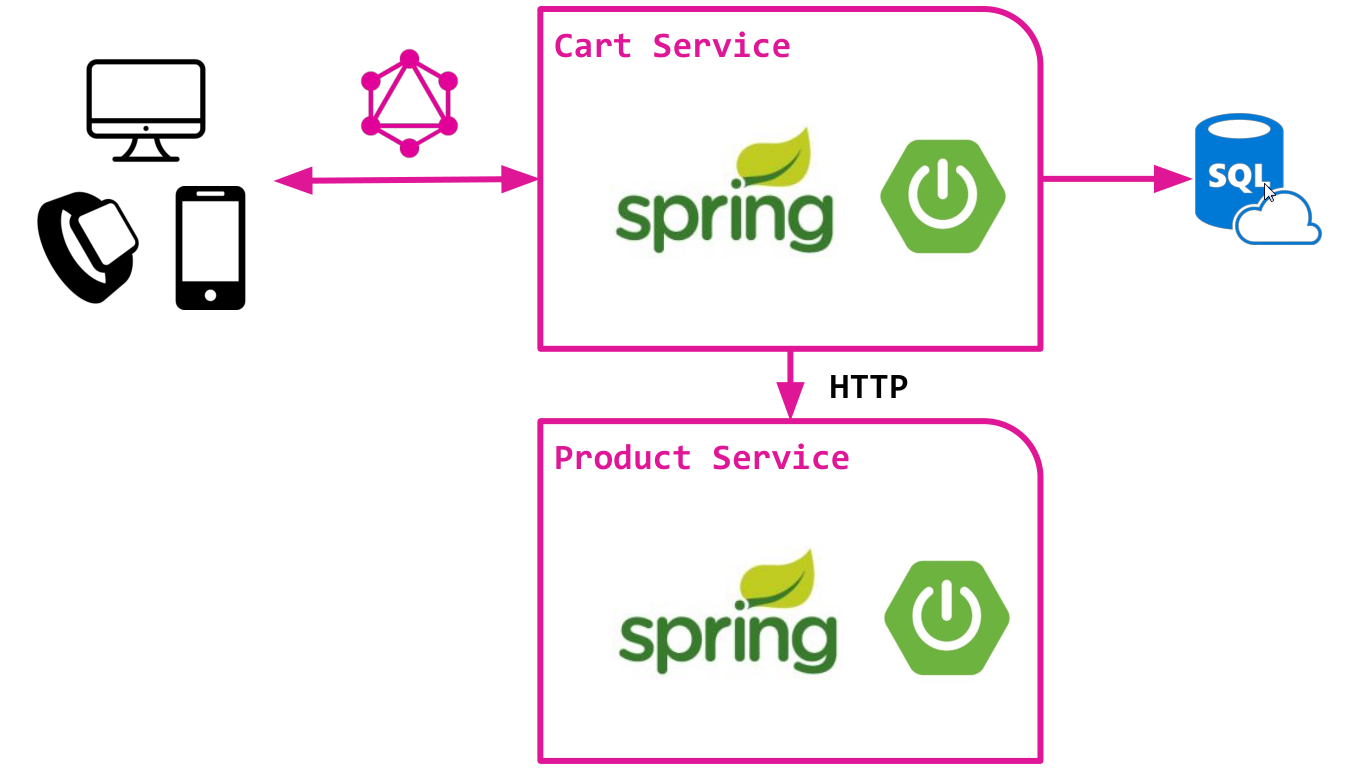
Pretendemos criar a API GraphQL sobre o serviço Cart. Essa API foi projetada para fornecer acesso aos dados da cesta e aos produtos adicionados a ela.
Primeira versão
A implementação de referência GraphQL para o ecossistema Java, que mencionamos anteriormente - GraphQL Java, nos ajudará.
Adicione algumas dependências ao
pom.xml: <dependency> <groupId>com.graphql-java</groupId> <artifactId>graphql-java</artifactId> <version>9.3</version> </dependency> <dependency> <groupId>com.graphql-java</groupId> <artifactId>graphql-java-tools</artifactId> <version>5.2.4</version> </dependency> <dependency> <groupId>com.graphql-java</groupId> <artifactId>graphql-spring-boot-starter</artifactId> <version>5.0.2</version> </dependency> <dependency> <groupId>com.graphql-java</groupId> <artifactId>graphiql-spring-boot-starter</artifactId> <version>5.0.2</version> </dependency>
Além do
graphql-java mencionado anteriormente
graphql-java precisaremos de uma biblioteca de
graphql-java-tools, bem como dos “iniciantes” do Spring Boot para GraphQL, que simplificarão bastante os primeiros passos para criar um servidor GraphQL:
- O graphql-spring-boot-starter fornece um mecanismo para conectar rapidamente o GraphQL Java ao Spring Boot;
- O graphiql-spring-boot-starter adiciona um console da web interativo Graph i QL para executar consultas GraphQL.
O próximo passo importante é determinar o esquema de serviço graphQL, nosso gráfico. Os nós deste gráfico são descritos usando
tipos e as arestas usando
campos . Uma definição de gráfico vazia é assim:
schema { }
Nesse mesmo esquema, como você se lembra, existem "pontos de entrada" ou consultas de nível superior. Eles são definidos através do campo de
consulta no esquema. Ligue para o nosso tipo de
pontos de entrada
EntryPoints :
schema { query: EntryPoints }
Definimos nela uma pesquisa de cesta por identificador como o primeiro ponto de entrada:
type EntryPoints { cart(id: Long!): Cart }
Cart nada mais é do que um
campo em termos do GraphQL.
id é um parâmetro desse campo com o tipo escalar
Long . Ponto de exclamação
! depois de especificar o tipo significa que o parâmetro é necessário.
É hora de identificar e digitar o
Cart :
type Cart { id: Long! items: [CartItem!]! subTotal: BigDecimal! }
Além da
id padrão, a cesta inclui seus elementos de itens e a quantia para todos os produtos
subTotal . Observe que os
itens são definidos como uma lista, conforme indicado entre colchetes
[] . Os elementos desta lista são os tipos
CartItem . A presença de um ponto de exclamação após o nome do tipo de campo
! indica que o campo é obrigatório. Isso significa que o servidor concorda em retornar um valor não vazio para esse campo, se um tiver sido solicitado.
Resta examinar a definição do tipo
CartItem , que inclui um link para o produto (
productId ), quantas vezes ele é adicionado à cesta (
quantity ) e a quantidade do produto, calculada no número (
total ):
type CartItem { productId: String! quantity: Int! total: BigDecimal! }
Tudo é simples aqui - todos os campos dos tipos escalares são obrigatórios.
Este esquema não foi escolhido por acaso. O serviço Cart já definiu a cesta do carrinho e seus elementos
CartItem com exatamente os mesmos nomes e tipos de campos do esquema GraphQL. O modelo de carrinho usa a biblioteca Lombok para gerar automaticamente getters / setters, construtores e outros métodos. O JPA é usado para persistência no banco de dados.
Classe do
Cart :
import lombok.Data; import javax.persistence.*; import java.math.BigDecimal; import java.util.ArrayList; import java.util.List; @Entity @Data public class Cart { @Id @GeneratedValue private Long id; @ElementCollection(fetch = FetchType.EAGER) private List<CartItem> items = new ArrayList<>(); public BigDecimal getSubTotal() { return getItems().stream() .map(Item::getTotal) .reduce(BigDecimal.ZERO, BigDecimal::add); } }
Classe
CartItem :
import lombok.AllArgsConstructor; import lombok.Data; import javax.persistence.Column; import javax.persistence.Embeddable; import java.math.BigDecimal; @Embeddable @Data @AllArgsConstructor public class CartItem { @Column(nullable = false) private String productId; @Column(nullable = false) private int quantity; @Column(nullable = false) private BigDecimal total; }
Portanto, os elementos basket (
Cart ) e basket (
CartItem ) são descritos no diagrama GraphQL e no código e são “compatíveis” entre si de acordo com o conjunto de campos e seus tipos. Mas isso ainda não é suficiente para o nosso serviço funcionar.
Precisamos esclarecer exatamente como o ponto de entrada "
cart(id: Long!): Cart " funcionará. Para fazer isso, crie uma configuração Java extremamente simples para o Spring com um bean do tipo GraphQLQueryResolver. GraphQLQueryResolver descreve apenas os "pontos de entrada" no esquema. Definimos um método com um nome idêntico ao campo no ponto de entrada (
cart ), o tornamos compatível com o tipo de parâmetros e usamos
cartService para encontrar o mesmo carrinho por identificador:
@Bean public GraphQLQueryResolver queryResolver() { return new GraphQLQueryResolver () { public Cart cart(Long id) { return cartService.findCart(id); } } }
Essas mudanças são suficientes para obtermos um aplicativo funcional. Após reiniciar o serviço Cart no console do GraphiQL, a seguinte consulta começará a ser executada com êxito:
{ cart(id: 1) { items { productId quantity total } subTotal } }
Nota
- Usamos os tipos escalares
Long e String como identificadores exclusivos para a cesta e o produto. O GraphQL possui um tipo especial para esses propósitos - ID . Semanticamente, essa é uma escolha melhor para uma API real. Valores do tipo ID podem ser usados como uma chave para armazenamento em cache.
- Nesta fase do desenvolvimento de nossa aplicação, os modelos de domínio interno e externo são completamente idênticos. Estamos falando das
CartItem Cart e CartItem e seu uso direto nos resolvedores do GraphQL. Em aplicações de combate, recomenda-se que esses modelos sejam separados. Para os resolvedores do GraphQL, um modelo separado da área de assunto interna deve existir.
Tornando a API útil
Então, obtivemos o primeiro resultado, e isso é maravilhoso. Mas agora nossa API é muito primitiva. Por exemplo, até o momento não há como solicitar dados úteis sobre um produto, como nome, preço, artigo, fotos e assim por diante. Em vez disso, existe apenas um
productId . Vamos tornar a API realmente útil e adicionar suporte completo ao conceito do produto. Aqui está a aparência de sua definição no diagrama:
type Product { id: String! title: String! price: BigDecimal! description: String sku: String! images: [String!]! }
Inclua o campo obrigatório em
CartItem e
productId campo productId como obsoleto:
type Item { quantity: Int! product: Product! productId: String! @deprecated(reason: "don't use it!") total: BigDecimal! }
Nós descobrimos o esquema. E agora é hora de descrever como a seleção para o campo do
product funcionará. Anteriormente,
CartItem com getters nas
CartItem Cart e
CartItem , o que permitia ao GraphQL Java vincular valores automaticamente. Mas aqui deve ser lembrado que apenas a propriedade do
product na classe
CartItem não
CartItem :
@Embeddable @Data @AllArgsConstructor public class CartItem { @Column(nullable = false) private String productId; @Column(nullable = false) private int quantity; @Column(nullable = false) private BigDecimal total; }
Temos uma escolha:
- Adicione a propriedade do produto ao CartItem e "ensine" como receber dados do produto;
- Determine como obter o produto sem alterar a classe CartItem .
A segunda maneira é preferível, porque o modelo da descrição do domínio interno (classe
CartItem ) nesse caso não será abordado com detalhes da implementação da API Graph
i QL.
Para atingir esse objetivo, a interface do marcador GraphQLResolver ajudará. Ao implementá-lo, você pode determinar (ou substituir) como obter os valores do campo para o tipo
T É assim que o bean correspondente se parece na configuração do Spring:
@Bean public GraphQLResolver<CartItem> cartItemResolver() { return new GraphQLResolver<CartItem>() { public Product product(CartItem item) { return http.getForObject("http://localhost:9090/products/{id}", Product.class, item.getProductId()); } }; }
O nome do método do
product não foi escolhido por acaso. O GraphQL Java está procurando métodos de download de dados pelo nome do campo, e nós apenas precisamos definir um carregador para o campo do
product ! Um objeto do tipo
CartItem passado como parâmetro define o contexto em que o produto é selecionado. Em seguida é uma questão de tecnologia. Usando um cliente
http , como
RestTemplate fazemos uma solicitação GET para o serviço Produto e convertemos o resultado em
Product , que se parece com isso:
@Data public class Product { private String id; private String title; private BigDecimal price; private String description; private String sku; private List<String> images; }
Essas alterações devem ser suficientes para implementar uma amostra mais interessante, que inclui o verdadeiro relacionamento entre a cesta e os produtos adicionados a ela.
Após reiniciar o aplicativo, você pode tentar uma nova consulta no console do Graph
i QL.
{ cart(id: 1) { items { product { title price sku images } quantity total } subTotal } }
E aqui está o resultado da execução da consulta:

Embora
productId sido marcado como
@deprecated , as consultas indicando esse campo continuarão funcionando. Mas o console do Graph
i QL não oferecerá preenchimento automático para esses campos e destacará seu uso de uma maneira especial:

É hora de mostrar o Document Explorer, parte do console do Graph
i QL, que é construído com base no esquema GraphQL e exibe informações sobre todos os tipos definidos. Aqui está a aparência do Document Explorer para o tipo
CartItem :

Mas voltando ao exemplo. Para obter a mesma funcionalidade da primeira demonstração, ainda não há limite suficiente para o número de imagens retornadas. De fato, para uma cesta, por exemplo, você precisa de apenas uma imagem para cada produto:
images(limit: 1)
Para fazer isso, altere o esquema e adicione um novo parâmetro para o campo
images ao tipo
Product :
type Product { id: ID! title: String! price: BigDecimal! description: String sku: String! images(limit: Int = 0): [String!]! }
E no código do aplicativo, vamos usá-lo novamente GraphQLResolver, apenas desta vez por tipo Product: @Bean public GraphQLResolver<Product> productResolver() { return new GraphQLResolver<Product>() { public List<String> images(Product product, int limit) { List<String> images = product.getImages(); int normalizedLimit = limit > 0 ? limit : images.size(); return images.subList(0, Math.min(normalizedLimit, images.size())); } }; }
Mais uma vez, chamo a atenção para o fato de o nome do método não ser acidental: ele coincide com o nome do campo images. O objeto de contexto Productfornece acesso às imagens e limité um parâmetro do próprio campo.Se o cliente não especificou nada como o valor limit, nosso serviço retornará todas as imagens do produto. Se o cliente especificou um valor específico, o serviço retornará exatamente o mesmo (mas não mais do que existe no produto).Compilamos o projeto e esperamos até o servidor reiniciar. Reiniciando o circuito no console e executando a solicitação, vemos que uma solicitação completa realmente funciona. { cart(id: 1) { items { product { title price sku images(limit: 1) } quantity total } subTotal } }
Concordo, tudo isso é muito legal. Em pouco tempo, aprendemos não apenas o que é o GraphQL, mas também transferimos um sistema simples de microsserviço para suportar essa API. E não nos importava de onde vinham os dados: as APIs SQL e HTTP se encaixavam bem sob o mesmo teto.Abordagem Code-First e GraphQL SPQR
Você deve ter notado que durante o processo de desenvolvimento houve alguns inconvenientes, como a necessidade de manter constantemente o esquema e o código do GraphQL em sincronia. As alterações de tipo sempre tinham que ser feitas em dois lugares. Em muitos casos, é mais conveniente usar a abordagem de primeiro código. Sua essência é que o esquema para o GraphQL é gerado automaticamente a partir do código. Nesse caso, você não precisa manter o circuito separadamente. Agora vou mostrar como fica.Apenas os recursos básicos do GraphQL Java não são suficientes para nós, também precisaremos da biblioteca GraphQL SPQR. A boa notícia é que o GraphQL SPQR é um complemento para o GraphQL Java, e não uma implementação alternativa do servidor GraphQL em Java.Adicione a dependência desejada a pom.xml: <dependency> <groupId>io.leangen.graphql</groupId> <artifactId>spqr</artifactId> <version>0.9.8</version> </dependency>
Aqui está o código que implementa a mesma funcionalidade baseada em GraphQL SPQR para a cesta: @Component public class CartGraph { private final CartService cartService; @Autowired public CartGraph(CartService cartService) { this.cartService = cartService; } @GraphQLQuery(name = "cart") public Cart cart(@GraphQLArgument(name = "id") Long id) { return cartService.findCart(id); } }
E para o produto: @Component public class ProductGraph { private final RestTemplate http; @Autowired public ProductGraph(RestTemplate http) { this.http = http; } @GraphQLQuery(name = "product") public Product product(@GraphQLContext CartItem cartItem) { return http.getForObject( "http://localhost:9090/products/{id}", Product.class, cartItem.getProductId() ); } @GraphQLQuery(name = "images") public List<String> images(@GraphQLContext Product product, @GraphQLArgument(name = "limit", defaultValue = "0") int limit) { List<String> images = product.getImages(); int normalizedLimit = limit > 0 ? limit : images.size(); return images.subList(0, Math.min(normalizedLimit, images.size())); } }
A anotação @GraphQLQuery é usada para sinalizar métodos do carregador de campo. A anotação @GraphQLContextdefine o tipo de seleção para o campo. E a anotação @GraphQLArgumentmarca claramente os parâmetros do argumento. Tudo isso faz parte de um mecanismo que ajuda o GraphQL SPQR a gerar um esquema automaticamente. Agora, se você excluir a configuração e o esquema Java antigos, reinicie o serviço Cart usando os novos chips do GraphQL SPQR, assegure-se de que tudo funcione funcionalmente da mesma maneira que antes.Resolvemos o problema de N + 1
É hora de olhar para b em detalhe lshih como a implementação de todo o pedido "sob a capa". Criamos rapidamente a API GraphQL, mas ela está funcionando com eficiência?Considere o seguinte exemplo: Obter a cesta
Obter a cesta cartacontece em uma consulta SQL ao banco de dados. Os dados itemssão subtotalretornados lá, porque os elementos da cesta são carregados com toda a coleção, com base na estratégia JPA de busca rápida: @Data public class Cart { @ElementCollection(fetch = FetchType.EAGER) private List<Item> items = new ArrayList<>(); ... }
 Quando se trata de baixar dados de produtos, as solicitações de serviço do Produto serão executadas exatamente da mesma forma que nesta cesta de produtos. Se houver três produtos diferentes na cesta, receberemos três solicitações para a API HTTP do serviço do produto e, se houver dez, o mesmo serviço terá que responder a dez solicitações.
Quando se trata de baixar dados de produtos, as solicitações de serviço do Produto serão executadas exatamente da mesma forma que nesta cesta de produtos. Se houver três produtos diferentes na cesta, receberemos três solicitações para a API HTTP do serviço do produto e, se houver dez, o mesmo serviço terá que responder a dez solicitações. Aqui está a comunicação entre o serviço Carrinho e o serviço Produto no Charles Proxy:
Aqui está a comunicação entre o serviço Carrinho e o serviço Produto no Charles Proxy: Portanto, voltamos ao problema clássico de N + 1. Exatamente aquele do qual eles tentaram tanto fugir no começo do relatório. Sem dúvida, temos progresso, porque exatamente uma solicitação é executada entre o cliente final e nosso sistema. Mas dentro do ecossistema de servidores, o desempenho claramente precisa ser aprimorado.Quero resolver esse problema obtendo todos os produtos certos em uma solicitação. Felizmente, o serviço Produto já suporta esse recurso por meio de um parâmetro
Portanto, voltamos ao problema clássico de N + 1. Exatamente aquele do qual eles tentaram tanto fugir no começo do relatório. Sem dúvida, temos progresso, porque exatamente uma solicitação é executada entre o cliente final e nosso sistema. Mas dentro do ecossistema de servidores, o desempenho claramente precisa ser aprimorado.Quero resolver esse problema obtendo todos os produtos certos em uma solicitação. Felizmente, o serviço Produto já suporta esse recurso por meio de um parâmetro idsno recurso de coleta: GET /products?ids=:id1,:id2,...,:idn
Vamos ver como você pode modificar o código do método de amostra para o campo do produto . Versão anterior: @GraphQLQuery(name = "product") public Product product(@GraphQLContext CartItem cartItem) { return http.getForObject( "http://localhost:9090/products/{id}", Product.class, cartItem.getProductId() ); }
Substitua por um mais eficaz: @GraphQLQuery(name = "product") @Batched public List<Product> products(@GraphQLContext List<Item> items) { String productIds = items.stream() .map(Item::getProductId) .collect(Collectors.joining(",")); return http.getForObject( "http://localhost:9090/products?ids={ids}", Products.class, productIds ).getProducts(); }
Fizemos exatamente três coisas:- marcou o método do carregador de inicialização com anotação @Batched , deixando claro para o GraphQL SPQR que o carregamento deve ocorrer com um lote;
- alterou o tipo de retorno e o parâmetro de contexto para uma lista, porque trabalhar com o lote pressupõe que vários objetos sejam aceitos e retornados;
- mudou o corpo do método, implementando uma seleção de todos os produtos necessários ao mesmo tempo.
Essas mudanças são suficientes para resolver o nosso problema de N + 1. A janela do aplicativo Charles Proxy agora mostra uma solicitação para o serviço Produto, que retorna três produtos ao mesmo tempo:
Amostras de campo eficazes
Resolvemos o problema principal, mas você pode tornar a seleção ainda mais rápida! Agora, o serviço do produto retorna todos os dados, independentemente do que o cliente final precisa. Poderíamos melhorar a consulta e retornar apenas os campos solicitados. Por exemplo, se o cliente final não solicitou a imagem, por que precisamos transferi-las para o serviço de carrinho?É ótimo que a API HTTP do serviço Produto já suporte esse recurso por meio do parâmetro include para o mesmo recurso de coleção: GET /products?ids=...?include=:field1,:field2,...,:fieldN
Para o método do carregador de inicialização, adicione um parâmetro do tipo Set com anotação @GraphQLEnvironment. O GraphQL SPQR entende que o código nesse caso "solicita" uma lista de nomes de campos solicitados para o produto e os preenche automaticamente: @GraphQLQuery(name = "product") @Batched public List<Product> products(@GraphQLContext List<Item> items, @GraphQLEnvironment Set<String> fields) { String productIds = items.stream() .map(Item::getProductId) .collect(Collectors.joining(",")); return http.getForObject( "http://localhost:9090/products?ids={ids}&include={fields}", Products.class, productIds, String.join(",", fields) ).getProducts(); }
Agora, nossa amostra é realmente eficaz, sem o problema N + 1 e usa apenas os dados necessários:
Consultas "pesadas"
Imagine trabalhar com um gráfico de usuário em uma rede social clássica como o Facebook. Se esse sistema fornecer a API GraphQL, nada impedirá o cliente de enviar uma solicitação da seguinte natureza: { user(name: "Vova Unicorn") { friends { name friends { name friends { name friends { name ... } } } } } }
No nível de aninhamento de 5 a 6, a implementação completa de uma solicitação desse tipo levará a uma seleção de todos os usuários no mundo. O servidor certamente não será capaz de lidar com essa tarefa de uma só vez e provavelmente irá "cair".Há várias medidas que devem ser tomadas para se proteger de tais situações:- Limite a profundidade da solicitação. Em outras palavras, os clientes não devem ter permissão para solicitar dados de aninhamento arbitrário.
- Limite a complexidade da solicitação. Atribuindo um peso a cada campo e calculando a soma dos pesos de todos os campos na solicitação, você pode aceitar ou rejeitar essas solicitações no servidor.
Por exemplo, considere a seguinte consulta: { cart(id: 1) { items { product { title } quantity } subTotal } }
Obviamente, a profundidade dessa solicitação é 4, porque o caminho mais longo está dentro dela cart -> items -> product -> title.Se assumirmos que o peso de cada campo é 1, levando em consideração 7 campos na consulta, sua complexidade também é 7.No GraphQL Java, a superposição de verificações é alcançada indicando instrumentação adicional ao criar o objeto GraphQL: GraphQL.newGraphQL(schema) .instrumentation(new ChainedInstrumentation(Arrays.asList( new MaxQueryComplexityInstrumentation(20), new MaxQueryDepthInstrumentation(3) ))) .build();
A instrumentação MaxQueryDepthInstrumentationverifica a profundidade da solicitação e não permite que solicitações muito "profundas" sejam iniciadas (nesse caso, com uma profundidade maior que 3).A instrumentação MaxQueryComplexityInstrumentationantes de executar uma consulta conta e verifica sua complexidade. Se esse número exceder o valor especificado (20), essa solicitação será rejeitada. Você pode redefinir o peso de cada campo, porque alguns deles obviamente ficam "mais difíceis" do que outros. Por exemplo, o campo do produto pode ser atribuído à complexidade 10 por meio da anotação @GraphQLComplexity,suportada no GraphQL SPQR: @GraphQLQuery(name = "product") @GraphQLComplexity("10") public List<Product> products(...)
Aqui está um exemplo de uma verificação de profundidade quando excede claramente o valor especificado: A propósito, o mecanismo de instrumentação não se limita a impor restrições. Também pode ser usado para outros fins, como registro ou rastreamento.Examinamos as medidas de “proteção” específicas do GraphQL. No entanto, há vários truques que vale a pena prestar atenção, independentemente do tipo de API:
A propósito, o mecanismo de instrumentação não se limita a impor restrições. Também pode ser usado para outros fins, como registro ou rastreamento.Examinamos as medidas de “proteção” específicas do GraphQL. No entanto, há vários truques que vale a pena prestar atenção, independentemente do tipo de API:- limitação / limitação de taxa - limite o número de solicitações por unidade de tempo
- timeouts - limite de tempo para operações com outros serviços, bancos de dados, etc;
- paginação - suporte à paginação.
Mutação de dados
Até agora, estamos considerando puramente a amostragem de dados. Mas o GraphQL permite que você organize organicamente não apenas o recebimento de dados, mas também suas alterações. Existe um mecanismo para isso mutation: schema { query: EntryPoints, mutation: Mutations }
Por exemplo, a adição de um produto a uma cesta pode ser organizada através da seguinte mutação: type Mutations { addProductToCart(cartId: Long!, productId: String!, count: Int = 1): Cart }
Isso é semelhante à definição de um campo, porque uma mutação também possui parâmetros e um valor de retorno.A implementação de uma mutação no código do servidor usando o GraphQL SPQR é a seguinte: @GraphQLMutation(name = "addProductToCart") public Cart addProductToCart( @GraphQLArgument(name = "cartId") Long cartId, @GraphQLArgument(name = "productId") String productId, @GraphQLArgument(name = "quantity", defaultValue = "1") int quantity) { return cartService.addProductToCart(cartId, productId, quantity); }
Obviamente, a maior parte do trabalho útil é feita internamente cartService. E a tarefa desse método intercalar é associá-lo à API. Como no caso da amostragem de dados, graças às anotações, é @GraphQL*muito fácil entender qual esquema do GraphQL é gerado a partir dessa definição de método.No console do GraphQL, agora você pode executar uma solicitação de mutação para adicionar um produto específico à nossa cesta em uma quantidade de 2: mutation { addProductToCart( cartId: 1, productId: "59eb83c0040fa80b29938e3f", quantity: 2) { items { product { title } quantity total } subTotal } }
Como a mutação tem um valor de retorno, é possível solicitar campos de acordo com as mesmas regras que fizemos para amostras comuns.Várias equipes de desenvolvimento do WIX estão usando ativamente o GraphQL com o Scala e a biblioteca Sangria, a principal implementação do GraphQL nessa linguagem.Uma das técnicas úteis usadas no WIX é o suporte para consultas GraphQL ao renderizar HTML. Fazemos isso para gerar JSON diretamente no código da página. Aqui está um exemplo de preenchimento de um modelo HTML: // Pre-rendered <html> <script data-embedded-graphiql> { product(productId: $productId) title description price ... } } </script> </html>
E aqui está a saída: // Rendered <html> <script> window.DATA = { product: { title: 'GraphQL Sticker', description: 'High quality sticker', price: '$2' ... } } </script> </html>
Essa combinação de renderizador HTML e servidor GraphQL nos permite reutilizar nossa API ao máximo e não criar uma camada adicional de controladores. Além disso, essa técnica geralmente se mostra vantajosa em termos de desempenho, porque após o carregamento da página, o aplicativo JavaScript não precisa ir para o back-end para os primeiros dados necessários - ele já está na página.Desvantagens do GraphQL
Hoje, o GraphQL usa um grande número de empresas, incluindo gigantes como GitHub, Yelp, Facebook e muitas outras. E se você decidir juntar o número deles, deve conhecer não apenas as vantagens do GraphQL, mas também suas desvantagens, e existem muitas delas:- -, GraphQL . GraphQL , HTTP API. Cache-Control Last-Modified HTTP GraphQL API. , proxy gateways (Varnish, Fastly ). , GraphQL , , .
- GraphQL — . , API, , .
- GraphQL . .
- . GraphQL — . JSON XML, , , GraphQL, .
- GraphQL . , HTTP PUT POST -. , . GraphQL . .
- . , -: «delete» «kill», «annihilate» «terminate», . GraphQL API . HTTP DELETE .
- Joker 2016 . GraphQL . API- , , , HATEOAS, , « REST». , , GraphQL .
Também vale lembrar que, se você não conseguiu desenvolver bem a API HTTP, provavelmente não poderá desenvolver a API GraphQL. Afinal, o que é mais importante no desenvolvimento de qualquer API? Separe o modelo de domínio interno do modelo de API externa. Crie uma API com base nos cenários de uso, não no dispositivo interno do aplicativo. Abra apenas as informações mínimas necessárias, e nem todas seguidas. Escolha os nomes certos. Descreva o gráfico corretamente. Há um gráfico de recurso na API HTTP e um gráfico de campo na API GraphQL. Nos dois casos, esse gráfico deve ser realizado qualitativamente.Existem alternativas no mundo da API HTTP, e você nem sempre precisa usar o GraphQL quando precisar de seleções complexas. Por exemplo, existe o padrão OData, que suporta seleções parciais e expansíveis, como GraphQL, e funciona sobre HTTP. Existe uma API JSON padrão que funciona com JSON e suporta recursos de busca hipermídia e complexos. Há também o LinkRest, sobre o qual você pode aprender mais no https://youtu.be/EsldBtrb1Qc "> relatório de Andrus Adamchik no Joker 2017.Para aqueles que desejam experimentar o GraphQL, recomendo vivamente a leitura de artigos de comparação de engenheiros versados em REST e GraphQL de um ponto de vista prático e filosófico:Finalmente, sobre assinaturas e adiar
O GraphQL tem uma vantagem interessante sobre as APIs padrão. No GraphQL, os casos de uso síncronos e assíncronos podem ficar sob o mesmo teto.Pensamos em receber dados através de você query, alterando o status do servidor mutation, mas há mais uma coisa boa. Por exemplo, a capacidade de organizar assinaturas subscriptions.Imagine que um cliente deseja receber notificações sobre como adicionar um produto à cesta de forma assíncrona. Através da API GraphQL, isso pode ser feito com base em um esquema: schema { query: Queries, mutation: Mutations, subscription: Subscriptions } type Subscriptions { productAdded(cartId: String!): Cart }
O cliente pode se inscrever através da seguinte solicitação: subscription { productAdded(cart: 1) { items { product ... } subTotal } }
Agora, toda vez que um produto for adicionado à cesta 1, o servidor enviará a cada cliente inscrito uma mensagem no WebSocket com os dados solicitados na cesta. Novamente, continuando a política do GraphQL, apenas os dados que o cliente solicitou ao se inscrever virão: { "data": { "productAdded": { "items": [ { "product": …, "subTotal": … }, { "product": …, "subTotal": … }, { "product": …, "subTotal": … }, { "product": …, "subTotal": … } ], "subTotal": 289.33 } } }
O cliente agora pode redesenhar a cesta, não necessariamente redesenhando a página inteira.Isso é conveniente porque a API síncrona (HTTP) e a API assíncrona (WebSocket) podem ser descritas através do GraphQL.Outro exemplo de uso da comunicação assíncrona é o mecanismo de adiamento . A idéia principal é que o cliente escolha quais dados ele deseja receber imediatamente (de forma síncrona) e aqueles que ele está pronto para receber posteriormente (de forma síncrona). Por exemplo, para tal solicitação: query { feedStories { author { name } message comments @defer { author { name } message } } }
O servidor retornará primeiro o autor e uma mensagem para cada história: { "data": { "feedStories": [ { "author": …, "message": … }, { "author": …, "message": … } ] } }
Depois disso, o servidor, após receber os dados nos comentários, os entregará ao cliente via WebSocket de forma assíncrona, indicando o caminho para o qual os comentários do histórico estão prontos: { "path": [ "feedStories", 0, "comments" ], "data": [ { "author": …, "message": … } ] }
Origem da amostra
O código usado para preparar este relatório pode ser encontrado no GitHub .Mais recentemente, anunciamos o JPoint 2019 , que será realizado de 5 a 6 de abril de 2019. Você pode aprender mais sobre o que esperar da conferência em nosso hub . Até o dia primeiro de dezembro, os ingressos para Early Bird ainda estão disponíveis pelo menor preço.