Criando roteamento de clientes / pesquisa semântica e agrupando corpúsculos externos arbitrários no Profi.ru
TLDR
Este é um resumo executivo muito curto (ou um teaser) sobre o que conseguimos fazer em aproximadamente 2 meses no departamento Profi.ru DS (estive lá por mais um tempo, mas integrar a mim e a minha equipe era algo a ser separado feito em primeiro lugar).
Objetivos projetados
- Entenda a entrada / intenção do cliente e direcione os clientes de acordo (optamos pelo classificador independente de qualidade de entrada no final, apesar de considerarmos também os modelos de nível de char tipo antecipado e modelos de linguagem. Regras de simplicidade);
- Encontre serviços e sinônimos totalmente novos para os serviços existentes;
- Como um subobjetivo de (2) - aprender a criar clusters apropriados em corpus externos arbitrários;
Objetivos alcançados
Obviamente, alguns desses resultados foram alcançados não apenas por nossa equipe, mas por várias equipes (ou seja, obviamente não fizemos a parte de raspagem para corpus de domínio e anotação manual, embora eu acredite que a raspagem também possa ser resolvida por nossa equipe - você só precisa proxies suficientes + provavelmente alguma experiência com selênio).
Objetivos de negócios:
- ~
88+% (vs ~ 60% com pesquisa elástica) na classificação de roteamento / intenção do cliente (~ 5k classes); - A pesquisa é independente da qualidade da entrada (impressões erradas / entrada parcial);
- O classificador generaliza, a estrutura morfológica da linguagem é explorada;
- O classificador supera severamente a pesquisa elástica em vários benchmarks (veja abaixo);
- Por uma questão de segurança - foram encontrados pelo menos
1,000 novos serviços + pelo menos 15,000 sinônimos (versus o estado atual de 5,000 + ~ 30,000 ). Espero que esse número duplique até o triplo;
A última bala é uma estimativa aproximada, mas conservadora.
Também serão realizados testes AB. Mas estou confiante nesses resultados.
Objetivos "científicos":
- Nós comparamos minuciosamente muitas técnicas modernas de incorporação de sentenças usando uma tarefa de classificação downstream + KNN com um banco de dados de sinônimos de serviço;
- Conseguimos superar a pesquisa elástica fracamente supervisionada (essencialmente o classificador deles é um saco de ngrams) nesse benchmark (veja detalhes abaixo) usando métodos UNSUPERVISED ;
- Desenvolvemos uma nova maneira de construir modelos de PNL aplicados (um pacote simples de baunilha bi-LSTM + de casamentos, essencialmente texto rápido atende à RNN) - isso leva em consideração a morfologia do idioma russo e generaliza bem;
- Demonstramos que nossa técnica final de incorporação (uma camada de gargalo do melhor classificador) combinada com algoritmos não supervisionados de última geração (UMAP + HDBSCAN) pode produzir aglomerados estelares;
- Demonstramos na prática a possibilidade, viabilidade e usabilidade de:
- Destilação do conhecimento;
- Aumentos para dados de texto (sic!);
- O treinamento de classificadores baseados em texto com aprimoramentos dinâmicos reduziu drasticamente o tempo de convergência (10x) em comparação com a geração de conjuntos de dados estáticos maiores (ou seja, a CNN aprende a generalizar o erro sendo mostrado frases drasticamente menos aumentadas);
Estrutura geral do projeto
Isso não inclui o classificador final.
No final, também abandonamos os modelos falsos de RNN e de perda tripla em favor do gargalo do classificador.

O que funciona na PNL agora?
Uma visão panorâmica:

Você também deve saber que a PNL pode estar enfrentando o momento da Imagenet agora .
Corte UMAP em grande escala
Ao criar clusters, deparamos com uma maneira / hack para aplicar essencialmente UMAP a conjuntos de dados com mais de 100m de ponto (ou talvez até 1 bilhão). Crie essencialmente um gráfico KNN com FAISS e, em seguida, apenas reescreva o loop UMAP principal no PyTorch usando sua GPU. Não precisávamos disso e abandonamos o conceito (tínhamos apenas 10 a 15m pontos), mas siga este tópico para obter detalhes.
O que funciona melhor
- Para classificação supervisionada, o texto rápido atende ao RNN (bi-LSTM) + conjunto de n-gramas cuidadosamente escolhido;
- Implementação - python simples para n-gramas + camada de bolsa PyTorch Embedding;
- Para clustering - a camada de gargalo deste modelo + UMAP + HDBSCAN;
Melhores referências de classificação
Conjunto de dev anotado manualmente
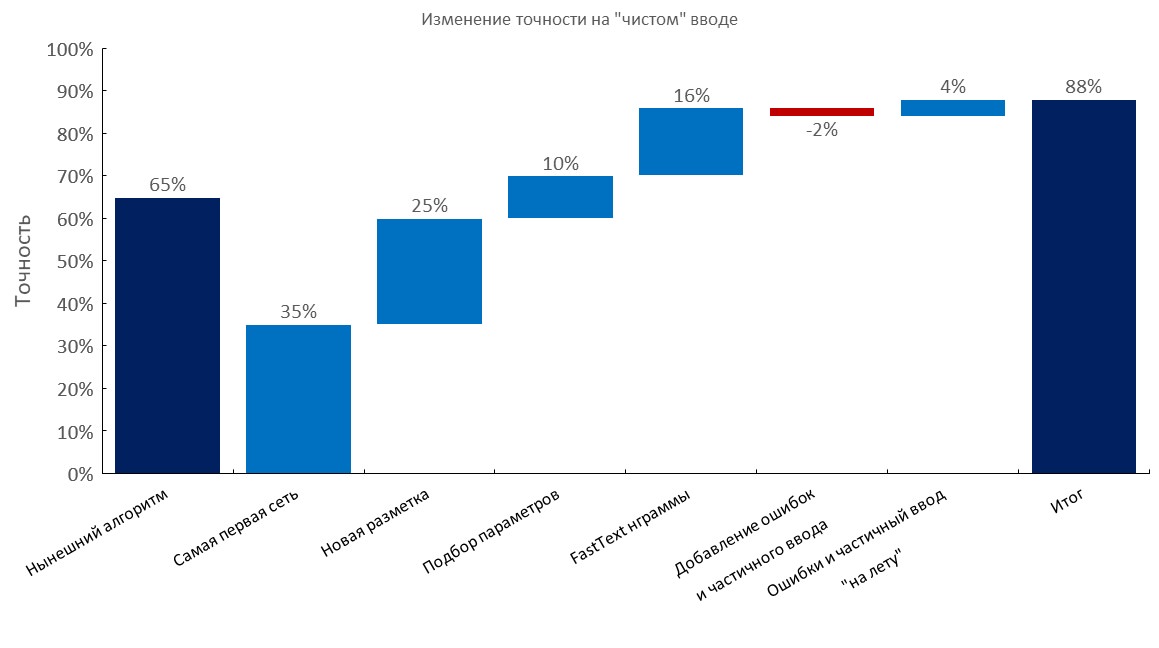
Da esquerda para a direita:
(Precisão Top1)
- Algoritmo atual (busca elástica);
- Primeiro RNN;
- Nova anotação;
- Tuning
- Camada de bolsa de incorporação de texto rápido;
- Adicionando erros de digitação e entrada parcial;
- Geração dinâmica de erros e entrada parcial ( tempo de treinamento reduzido em 10x );
- Pontuação final;
Conjunto de desenvolvedores anotado manualmente + 1-3 erros por consulta

Da esquerda para a direita:
(Precisão Top1)
- Algoritmo atual (busca elástica);
- Camada de bolsa de incorporação de texto rápido;
- Adicionando erros de digitação e entrada parcial;
- Geração dinâmica de erros e entrada parcial;
- Pontuação final;
Conjunto de dev anotado manualmente + entrada parcial
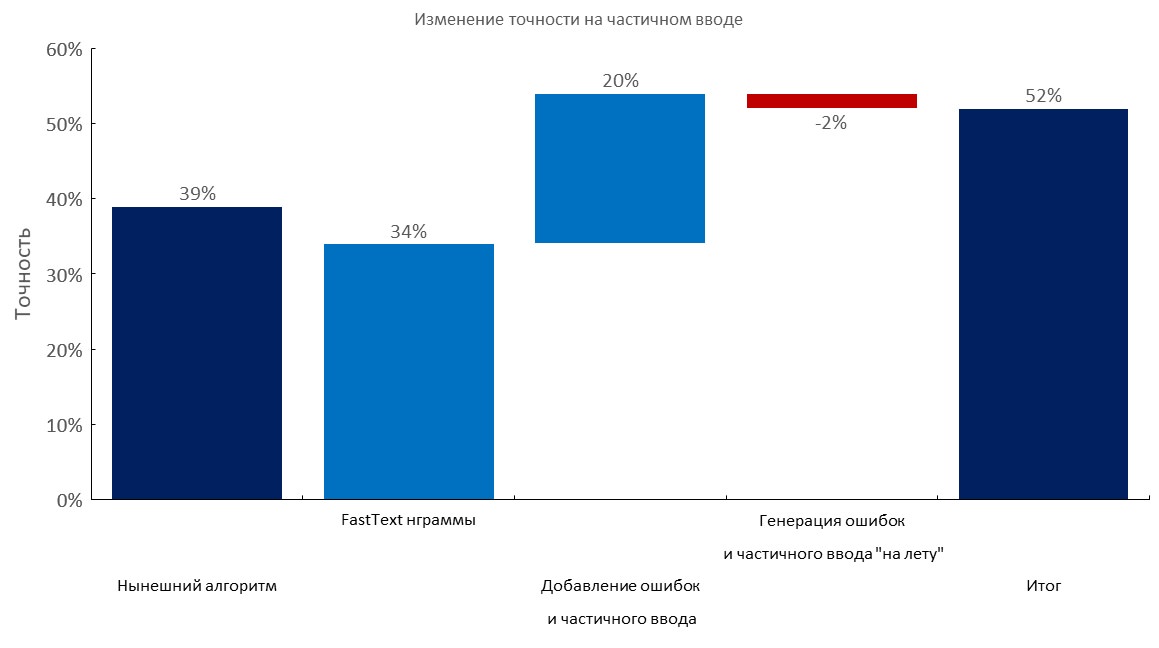
Da esquerda para a direita:
(Precisão Top1)
- Algoritmo atual (busca elástica);
- Camada de bolsa de incorporação de texto rápido;
- Adicionando erros de digitação e entrada parcial;
- Geração dinâmica de erros e entrada parcial;
- Pontuação final;
Seleção de corpus em grande escala / n-grama
- Reunimos os maiores corpus para o idioma russo:
- Coletamos um dicionário de palavras de
100m usando rastreamento de 1 TB ; - Também use esse truque para baixar esses arquivos mais rapidamente (durante a noite);
- Selecionamos um conjunto ideal de
1m n-gramas para o nosso classificador generalizar melhor ( 500k n-gramas mais populares de texto rápido treinado na Wikipedia russa + 500k n-gramas mais populares em nossos dados de domínio);
Teste de estresse de nossos 1M n-gramas no vocabulário 100M:

Aumentos de texto
Em poucas palavras:
- Faça um dicionário grande com erros (por exemplo, 10-100m de palavras únicas);
- Gere um erro (solte uma carta, troque uma carta usando probabilidades calculadas, insira uma letra aleatória, talvez use o layout do teclado etc.);
- Verifique se a nova palavra está no dicionário;
Nós forçamos muitas consultas a serviços como este (na tentativa de essencialmente fazer engenharia reversa de seus conjuntos de dados), e eles têm um dicionário muito pequeno (também esse serviço é alimentado por um classificador de árvore com recursos de n-grama). Foi meio engraçado ver que eles cobriam apenas 30-50% das palavras que tínhamos em alguns corpus .
Nossa abordagem é muito superior, se você tiver acesso a um vocabulário de domínio grande .
Melhores resultados não supervisionados / semi-supervisionados
KNN usado como referência para comparar diferentes métodos de incorporação.
(tamanho do vetor) Lista de modelos testados:
- (512) Detector de sentenças falsas em grande escala, treinado em 200 GB de dados de rastreamento comuns;
- (300) Detector de frases falsas treinado para distinguir uma frase aleatória da Wikipedia de um serviço;
- (300) Texto rápido obtido a partir daqui, pré-treinado em corpus araneum;
- (200) Texto rápido treinado em nossos dados de domínio;
- (300) Texto rápido treinado em 200 GB de dados de rastreamento comum;
- (300) Uma rede siamesa com perda de trigêmeos treinada com serviços / sinônimos / frases aleatórias da Wikipedia;
- (200) Primeira iteração da camada de incorporação da RNN, uma frase é codificada como uma bolsa inteira de incorporação;
- (200) O mesmo, mas primeiro a frase é dividida em palavras, depois cada palavra é incorporada, depois a média é obtida;
- (300) O mesmo que acima, mas para o modelo final;
- (300) O mesmo que acima, mas para o modelo final;
- (250) camada de gargalo do modelo final (250 neurônios);
- Linha de base elástica de pesquisa fracamente supervisionada;
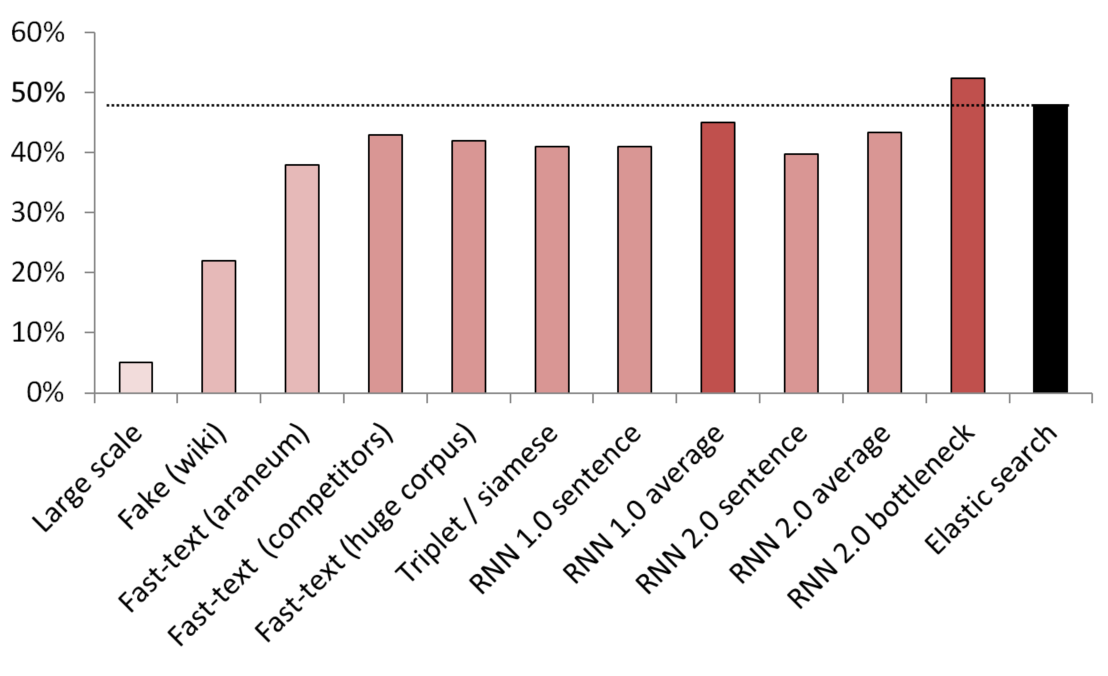
Para evitar vazamentos, todas as frases aleatórias foram amostradas aleatoriamente. O comprimento em palavras era o mesmo que o comprimento dos serviços / sinônimos com os quais foram comparados. Também foram tomadas medidas para garantir que os modelos não aprendessem apenas separando vocabulários (os casamentos foram congelados, a Wikipedia foi subamostrada para garantir que houvesse pelo menos uma palavra de domínio em cada frase da Wikipedia).
Visualização de cluster
3D

2D

Exploração de cluster "interface"
Verde - nova palavra / sinônimo.
Fundo cinza - provavelmente nova palavra.
Texto em cinza - sinônimo existente.

Testes de ablação e o que funciona, o que tentamos e o que não fizemos
- Veja os gráficos acima;
- Média simples / média tf-idf de incorporações de texto rápido - uma linha de base MUITO formidável ;
- Texto rápido> Word2Vec for Russian;
- A incorporação de sentenças por meio de detecção de sentenças falsas funciona, mas empalidece em comparação com outros métodos;
- O BPE (sentença) não mostrou melhora em nosso domínio;
- Os modelos de nível de caracteres lutaram para generalizar, apesar do artigo recente do google;
- Tentamos o transformador de várias cabeças (com cabeças classificadoras e de modelagem de linguagem), mas nas anotações disponíveis em mãos ele apresentou aproximadamente o mesmo que os modelos simples baseados em LSTM baunilha. Quando migramos para incorporar abordagens ruins, abandonamos essa linha de pesquisa devido à menor praticidade e impraticabilidade do transformador em ter uma cabeça linear, além de incorporar a camada de bolsa;
- BERT - parece ser um exagero, também algumas pessoas afirmam que os transformadores treinam literalmente por semanas;
- ELMO - usar uma biblioteca como AllenNLP parece contraproducente na minha opinião, tanto em ambientes de pesquisa / produção quanto em educação, por razões que não fornecerei aqui;
Implantar
Feito usando:
- Contêiner do Docker com um serviço da Web simples;
- Apenas CPU para inferência é suficiente;
- ~
2.5 ms por consulta na CPU, lote não é realmente necessário; - ~
1GB memória RAM; - Quase nenhuma dependência, além de
PyTorch , numpy e pandas (e servidor web ofc). - Imite a geração rápida de texto n-grama como esta ;
- Incorporar camada de bolsa + índices como recém-armazenados em um dicionário;