Em grandes serviços, resolver um problema usando o aprendizado de máquina significa fazer apenas parte do trabalho. A incorporação de modelos de ML não é tão fácil e a criação de processos de CI / CD em torno deles é ainda mais difícil. Na conferência Yandex
“Data & Science: the application program”, Adam Eldarov
, chefe de ciência de dados da YouDo, falou sobre como gerenciar o ciclo de vida dos modelos, configurar processos de reciclagem e reciclagem, desenvolver microsserviços escaláveis e muito mais.
- Vamos começar com a introdução. Há um cientista de dados, ele escreve algum código no Jupyter Notebook, faz engenharia de recursos, validação cruzada, treina modelos de modelos. A velocidade está crescendo.

Mas, em algum momento, ele entende: para agregar valor à empresa, ele deve anexar a solução em algum lugar da produção, a alguma produção mítica, o que nos causa muitos problemas. O laptop que vimos em produção na maioria dos casos não pode ser enviado. E surge a pergunta: como enviar esse código dentro do laptop para um determinado serviço. Na maioria dos casos, você precisa escrever um serviço que tenha uma API. Ou eles se comunicam através do PubSub, através de filas.

Quando fazemos recomendações, geralmente precisamos treinar modelos e treiná-los novamente. Esse processo deve ser monitorado. Nesse caso, é preciso sempre verificar com testes o próprio código e os modelos, para que em um momento nosso modelo não fique louco e nem sempre comece a prever zero. Também precisa ser verificado em usuários reais através de testes AB - o que fizemos melhor ou pelo menos não pior.
Como abordamos o código? Nós temos o GitLab. Todo o nosso código é dividido em muitas pequenas bibliotecas que resolvem um problema específico de domínio. Ao mesmo tempo, é um projeto GitLab separado, controle de versão Git e o modelo de ramificação GitFlow. Usamos coisas como ganchos de pré-confirmação, para que você não possa confirmar códigos que não atendam às nossas verificações de teste estatístico. E os próprios testes, testes de unidade. Usamos a abordagem de teste baseada em propriedades para eles.

Geralmente, quando você escreve testes, quer dizer que possui uma função de teste e os argumentos que cria com as mãos, alguns exemplos e quais valores sua função de teste retorna. Isso é inconveniente. O código é inflado, muitos em princípio são preguiçosos demais para escrevê-lo. Como resultado, temos um monte de código descoberto por testes. O teste baseado em propriedades implica que todos os seus argumentos têm uma certa distribuição. Vamos fazer a fase e, muitas vezes, provar todos os nossos argumentos dessas distribuições, chamar a função sob teste com esses argumentos e verificar se certas propriedades são o resultado dessa função. Como resultado, temos muito menos código e, ao mesmo tempo, existem muitos outros testes.
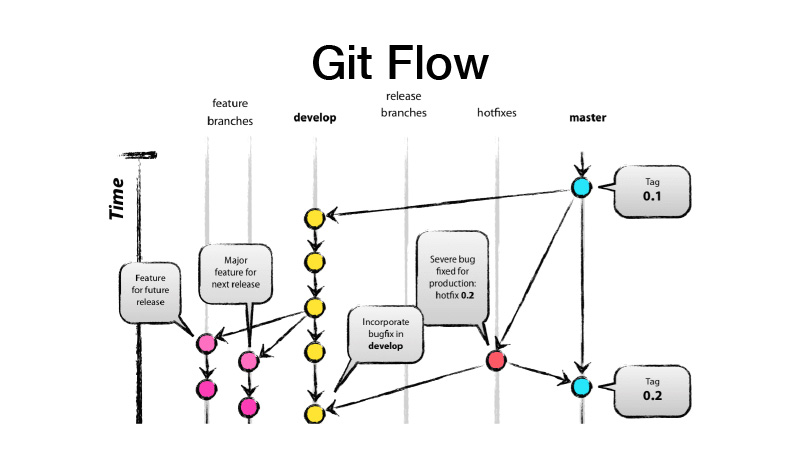
O que é o GitFlow? Este é um modelo de ramificação, o que implica que você tem duas ramificações principais - develop e master, onde o código de produção pronto está localizado, e todo o desenvolvimento é realizado na branch de desenvolvimento, na qual todos os novos recursos são extraídos de brunches de recursos. Ou seja, cada recurso é um novo brunch de recursos, enquanto o brunch de recursos deve durar pouco e para sempre - também coberto por alternância de recursos. Em seguida, fazemos um lançamento, do dev lançamos as alterações para o master e colocamos a tag de versão da nossa biblioteca ou serviço.
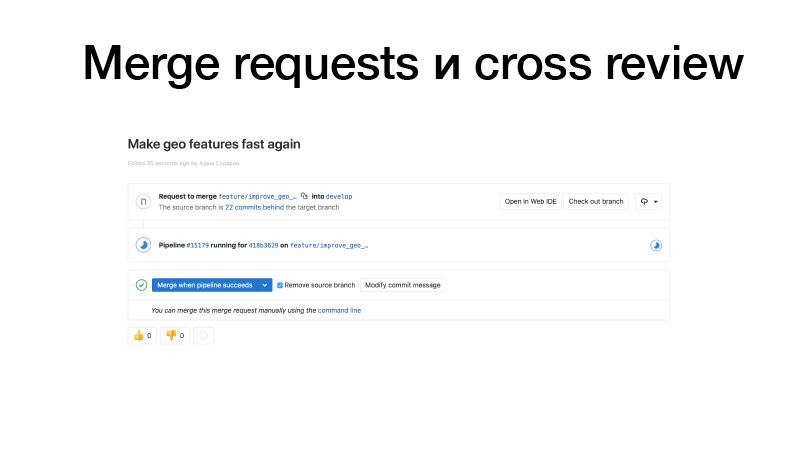
Estamos desenvolvendo, vendo algum recurso, enviando-o para o GitLab, criando uma solicitação de mesclagem do brunch de recursos para as donzelas. Os gatilhos funcionam, executam testes, se estiver tudo bem, podemos congelá-lo. Mas não somos nós que estamos segurando, mas alguém da equipe. Ele revisa o código e, assim, aumenta o fator de barramento. Esta seção de código já é conhecida por duas pessoas. Como resultado, se alguém é atropelado por um ônibus, alguém já sabe o que está fazendo.

A integração contínua para bibliotecas geralmente se parece com testes para alterações. E se o liberarmos, ele também será publicado no servidor PyPI privado do nosso pacote.
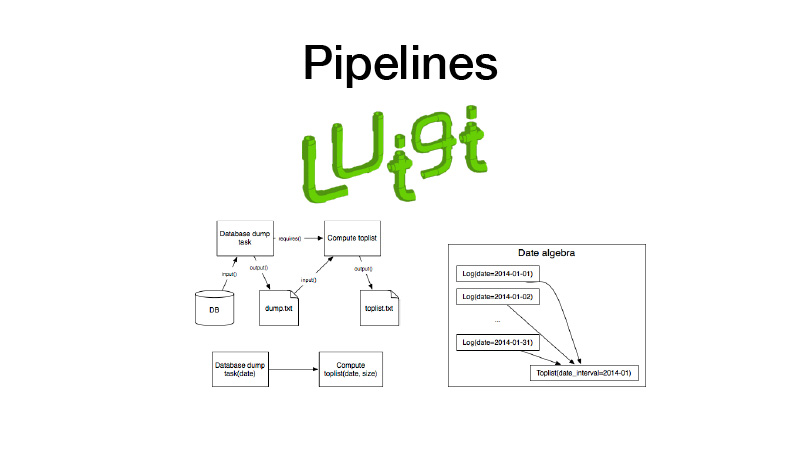
Além disso, podemos coletá-lo em gasodutos. Para isso, usamos a biblioteca Luigi. Ele trabalha com uma entidade como tarefa, que possui uma saída, na qual o artefato criado durante a execução da tarefa é salvo. Há um parâmetro de tarefa que parametriza a lógica de negócios que ele executa, identifica a tarefa e sua saída. Ao mesmo tempo, as tarefas sempre têm requisitos que outras tarefas apresentam. Quando executamos algum tipo de tarefa, todas as suas dependências são verificadas através da verificação de suas saídas. Se a saída existir, nossa dependência não será iniciada. Se o artefato estiver ausente em algum armazenamento, ele será iniciado. Isso forma um pipeline, um gráfico cíclico direcionado.
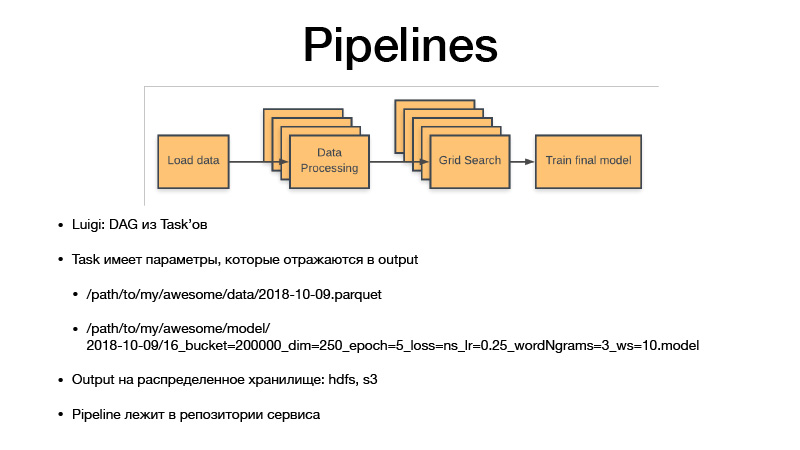
Todos os parâmetros identificam a lógica de negócios. Ao fazer isso, eles identificam o artefato. É sempre uma data com alguma granularidade, sensibilidade ou uma semana, dia, hora, três horas. Se treinamos algum modelo, Luigi Taska sempre tem hiperparâmetros dessa tarefa, eles vazam para o artefato que estamos produzindo, os hiperparâmetros são refletidos no nome do artefato. Portanto, essencialmente versão de todos os conjuntos de dados intermediários e artefatos finais, e eles nunca são substituídos, sempre aumentam apenas o armazenamento, e o armazenamento é HDFS e S3 privado, que vê artefatos finais de alguns pickles, modelos ou qualquer outra coisa . E todo o código do pipeline está no projeto de serviço no repositório ao qual se relaciona.

Ele precisa ser corrigido de alguma forma. A pilha HashiCorp vem em socorro, usamos o Terraform para declarar a infraestrutura na forma de código, o Vault para gerenciar segredos, todas as senhas, aparências no banco de dados. O Consul é um serviço de descoberta distribuído pelo armazenamento de valores-chave que você pode usar para configurar. E também o Consul faz verificações de saúde de seus nós e seus serviços, verificando sua disponibilidade.
E - Nomad. é um sistema de orquestração, distribuindo seus serviços e algum tipo de trabalho em lotes.
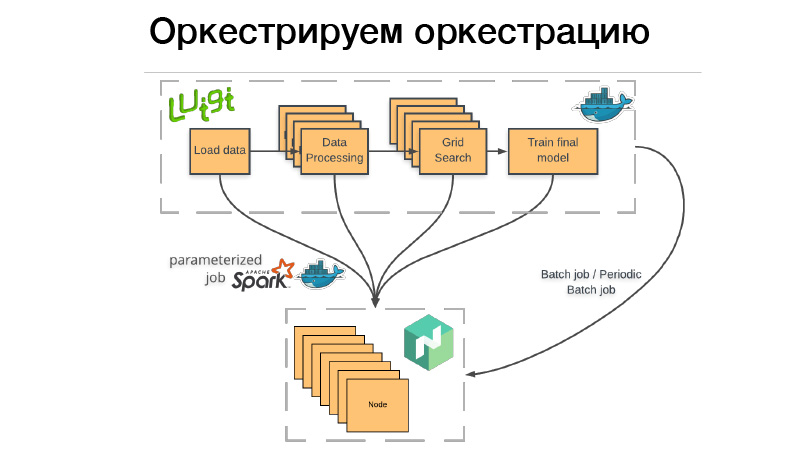
Como usamos isso? Há um pipeline Luigi, vamos empacotá-lo no contêiner do Docker, colocar o bastão ou o trabalho em lotes periódico no Nomad. Trabalho em lote - isso é algo concluído e encerrado e, se tudo der certo - tudo está bem, podemos iniciá-lo manualmente novamente. Mas se algo der errado, o Nomad tenta novamente até esgotar a tentativa ou não termina com sucesso.
Trabalho em lote periódico - é exatamente o mesmo, funciona apenas em uma programação.
Há um problema. Quando implantamos um contêiner em qualquer sistema de orquestração, precisamos indicar quanta memória esse contêiner, CPU ou memória precisa. Se tivermos um pipeline que funcione por três horas, duas horas disso consumirão 10 GB de RAM, 1 hora - 70 GB. Se excedermos o limite que lhe damos, o daemon do Docker chega e mata os Dockers e (nrzb.) [02:26:13] Não queremos ficar sem memória constantemente, portanto, precisamos especificar todos os 70 GB, o pico de carga de memória. Mas aqui está o problema: todos os 70 GB por três horas serão alocados e inacessíveis a qualquer outro trabalho.
Portanto, seguimos o outro caminho. Todo o nosso pipeline Luigi não inicia nenhum tipo de lógica de negócios, apenas lança um conjunto de dados no Nomad, o chamado trabalho parametrizado. De fato, este é um análogo das funções do Servidor (NRZB.) [02:26:39], AVS Lambda, quem sabe. Quando criamos uma biblioteca, implantamos por meio do CI todo o nosso código na forma de trabalhos parametrizados, ou seja, um contêiner com alguns parâmetros. Suponha, Lite JBM Classifier, que tenha um parâmetro para o caminho para os dados de entrada para treinamento, hiperparâmetros dos modelos e o caminho para os artefatos de saída. Tudo isso é registrado no Nomad e, a partir do pipeline do Luigi, podemos puxar todos esses trabalhos do Nomad por meio da API e, ao mesmo tempo, o Luigi garante que não execute a mesma tarefa muitas vezes.
Suponha que tenhamos o mesmo processamento de texto. Existem 10 modelos condicionais e não queremos reiniciar o processamento de texto sempre. Ele começará apenas uma vez e, ao mesmo tempo, haverá um resultado final sempre que for reutilizado. E, ao mesmo tempo, tudo isso funciona de maneira distribuída, podemos executar uma pesquisa de grade gigante em um grande aglomerado, apenas ter tempo para despejar o ferro.
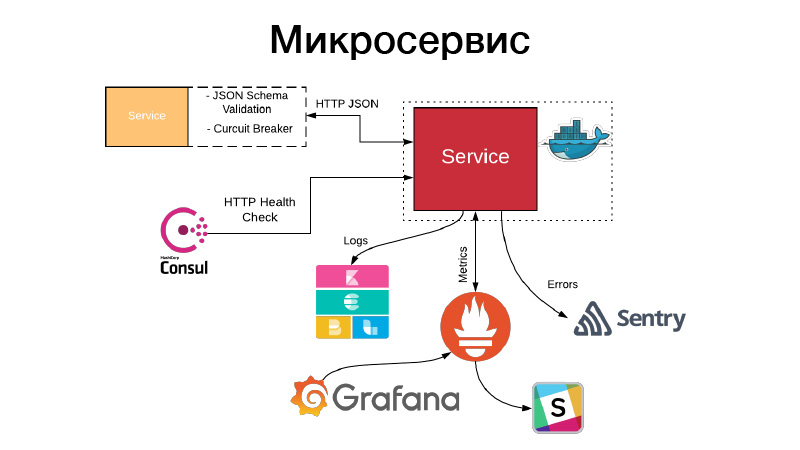
Temos um artefato, precisamos de alguma forma organizar isso na forma de um serviço. Os serviços expõem uma API HTTP ou se comunicam através de filas. Neste exemplo, esta é a API HTTP, o exemplo mais simples. Ao mesmo tempo, a comunicação com o serviço ou nosso serviço se comunica com outros serviços por meio da API HTTP JSON, valida o esquema JSON. O próprio serviço sempre descreve um objeto JSON na documentação para sua API e o esquema desse objeto. Mas nem todos os campos do objeto JSON são sempre necessários; portanto, os contratos orientados ao consumidor são validados; esse esquema é validado; a comunicação ocorre por meio de disjuntor padrão para impedir que nosso sistema distribuído falhe devido a falhas em cascata.
Ao mesmo tempo, o serviço deve definir uma verificação de integridade HTTP, para que o Consul possa entrar e verificar a disponibilidade desse serviço. Ao mesmo tempo, o Nomad pode fazer com que haja um serviço para três verificações de hello seguidas, e pode reiniciar o serviço para ajudá-lo. O serviço grava todos os seus logs no formato JSON. Usamos o driver de log JSON e a pilha Elastics, em cada momento o FileBit simplesmente pega todos os logs JSON, lança-os no cache de log, de onde eles chegam ao Elastic, podemos analisar o KBan. Ao mesmo tempo, não usamos logs para coleta de métricas e construção de painéis, é ineficiente, usamos o sistema de entrada do Prometheus para isso, temos um processo para criar modelos para cada serviço de painel e podemos analisar métricas técnicas produzidas pelo serviço.
Além disso, se algo der errado, chegam alertas, mas na maioria dos casos isso não é suficiente. Sentry vem em nosso auxílio, isso é uma coisa para análise de incidentes. De fato, capturamos todos os logs de nível de erro pelo manipulador do Sentry e os enviamos para o Sentry. E há um rastreamento detalhado, todas as informações sobre em que ambiente o serviço estava, qual versão, quais funções foram chamadas por quais argumentos e quais variáveis nesse escopo estavam com quais valores. Todas as configurações, tudo isso é visível, e ajuda muito a entender rapidamente o que aconteceu e corrigir o erro.
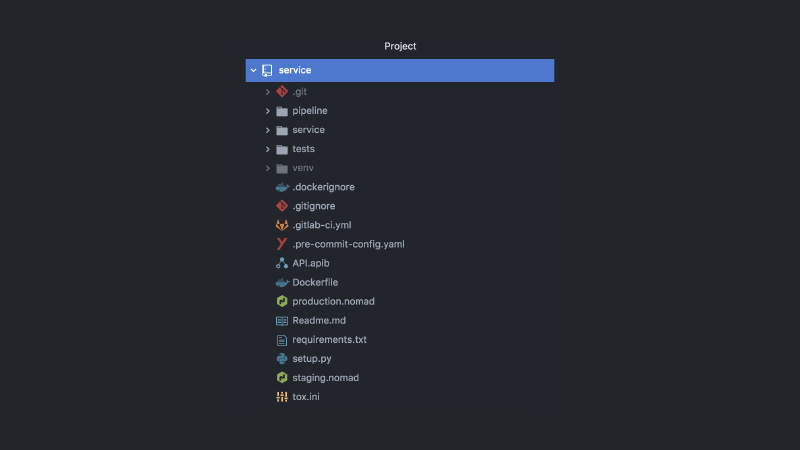
Como resultado, o serviço se parece com isso. Projeto GitLab separado, código de pipeline, código de teste, código de serviço em si, várias configurações diferentes, Nomad, configurações de CI, documentação de API, ganchos de confirmação e muito mais.
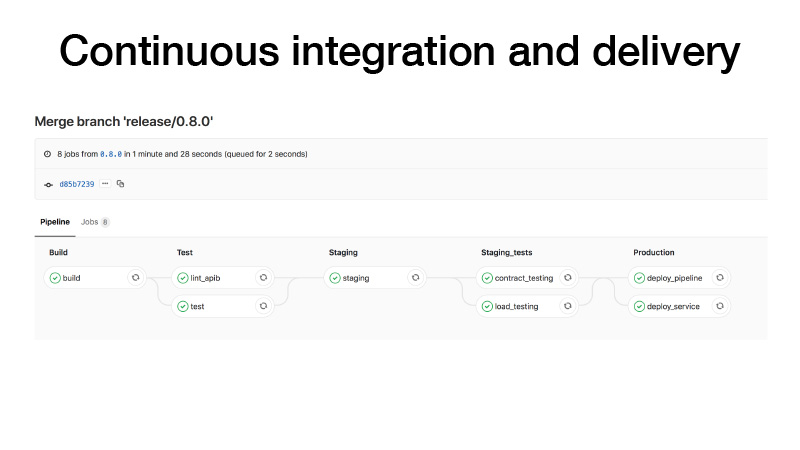
CI, quando fazemos um release, fazemos da seguinte maneira: construímos um contêiner, executamos testes, lançamos um cluster em um palco, executamos um contrato de teste para nosso serviço lá, conduzimos testes de estresse para garantir que nossa previsão não seja muito lenta e mantenha a carga que pensamos . Se tudo estiver correto, implantaremos esse serviço na produção. E existem duas maneiras: podemos implantar o pipeline, se o trabalho periódico em lote, ele trabalha em algum lugar em segundo plano e produz artefatos, ou com as canetas acionamos algum pipeline, ele treina algum modelo, depois entendemos que está tudo bem e implantar o serviço.

O que mais acontece neste caso? Eu disse que no desenvolvimento de brunches de recursos existe um paradigma que alterna recursos. De uma maneira boa, você precisa cobrir os recursos com algumas alternâncias, apenas para reduzir um recurso na batalha se algo der errado. Em seguida, podemos coletar todos os recursos nos trens de liberação e, mesmo que os recursos não estejam concluídos, podemos implantá-los. Apenas a alternância de recursos será desativada. Como somos todos cientistas de dados, também queremos fazer testes de AV. Digamos que substituímos o LightGBM pelo CatBoost. Queremos verificar isso, mas, ao mesmo tempo, o teste AV é gerenciado com referência a algum ID do usuário. A alternância de recurso está vinculada ao ID do usuário e, portanto, passa no teste AV. Precisamos verificar essas métricas aqui.
Todos os serviços são implantados no Nomad. Temos dois clusters de produção Nomad - um para trabalho em lote e outro para serviços.
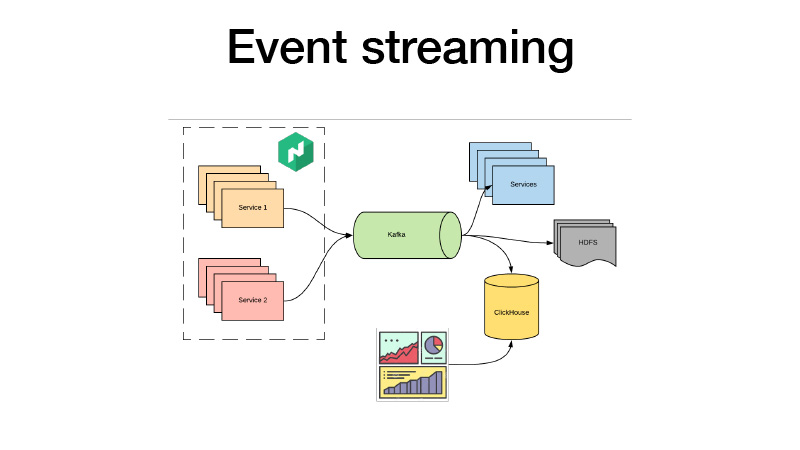
Eles enviam todos os seus eventos de negócios para Kafka. De lá, podemos buscá-los. Em essência, é uma arquitetura de cordeiro. Podemos assinar o HDFS com alguns serviços, fazer análises em tempo real e, ao mesmo tempo, todos utilizamos o ClickHouse e criamos painéis para analisar todos os eventos de negócios de nossos serviços. Podemos analisar testes AV, qualquer que seja.
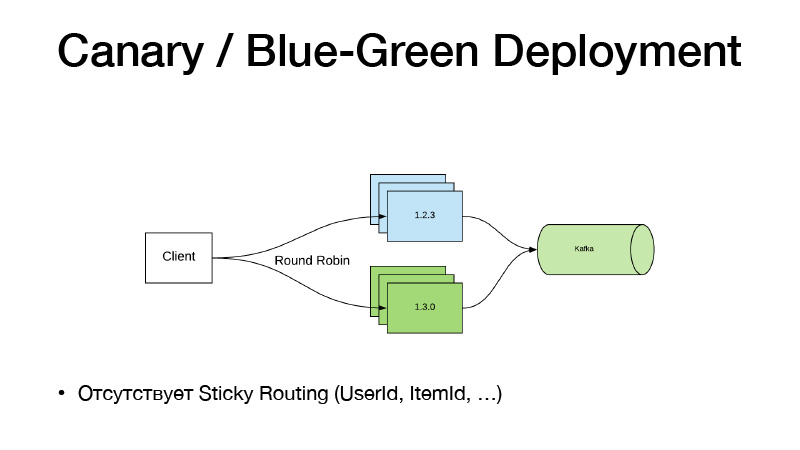
E se não alteramos o código, não use as alternâncias de recursos. Começamos a trabalhar com algumas canetas em algum oleoduto, ele nos ensinou um novo modelo. Temos um novo caminho para isso. Apenas mudamos o caminho do Nomad para o modelo na configuração, lançamos um novo serviço e aqui o paradigma Canary Deployment vem em nosso auxílio, está disponível no Nomad a partir da caixa.
Temos a versão atual do serviço em três instâncias. Dizemos que queremos três canários - mais três réplicas de novas versões são implantadas sem reduzir as antigas. Como resultado, o tráfego começa a se dividir em duas partes. Parte do tráfego cai em novas versões de serviços. Todos os serviços enviam todos os eventos de negócios para Kafka. Como resultado, podemos analisar métricas em tempo real.
Se estiver tudo bem, podemos dizer que está tudo bem. Ao implantar, o Nomad continuará, desligue suavemente todas as versões antigas e dimensione as novas.
Esse modelo é ruim, pois se precisarmos vincular o roteamento de versão por alguma entidade, Item de Usuário. Esse esquema não funciona, porque o tráfego é equilibrado através de round-robin. Portanto, seguimos o caminho a seguir e cortamos o serviço em duas partes.
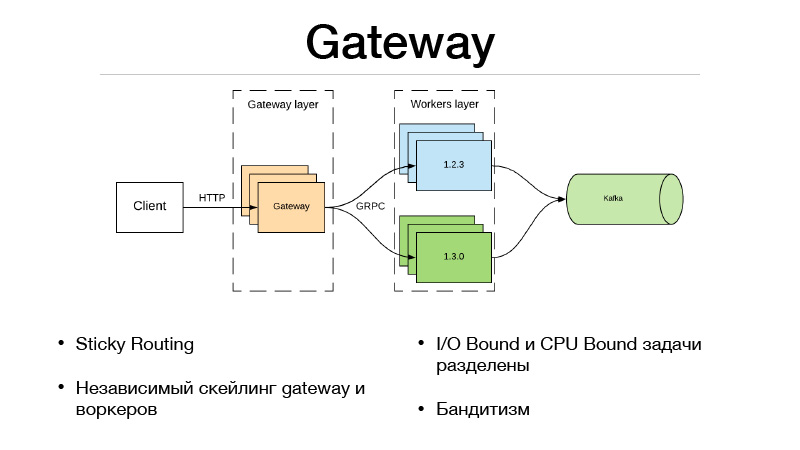
Essa é a camada Gateway e a camada Trabalhadores. O cliente se comunica via HTTP com a camada Gateway, toda a lógica de seleção de versão e balanceamento de tráfego está no Gateway. Ao mesmo tempo, todas as tarefas Limitadas de E / S necessárias para concluir o predicado também estão localizadas no Gateway. Suponha que obtivemos um ID do usuário no predicado na solicitação, que precisamos enriquecer com algumas informações. Devemos puxar outros microsserviços e coletar todas as informações, recursos ou bases. Como resultado, tudo isso acontece no gateway. Ele se comunica com os trabalhadores que estão apenas no modelo e faz uma coisa - uma previsão. Entrada e saída.
Porém, como dividimos nosso serviço em duas partes, a sobrecarga apareceu devido a uma chamada de rede remota. Como nivelá-lo? A estrutura JRPC do Google, a RPC do Google, que roda em cima do HTTP2, vem em socorro. Você pode usar multiplexação e compactação. JPRC usa protobuff. Este é um protocolo binário fortemente tipado que possui serialização e desserialização rápidas.
Como resultado, também temos a capacidade de escalar independentemente o Gateway e o trabalhador. Digamos que não possamos manter uma certa quantidade de conexões HTTP abertas. Ok, dimensionando o Gateway. Nossa previsão é muito lenta, não temos tempo para manter a carga - ok, dimensionamos trabalhadores. Essa abordagem se encaixa muito bem com bandidos com vários braços. No Gateway, como toda a lógica do balanceamento de tráfego é implementada, ele pode acessar microsserviços externos e obter todas as estatísticas de cada versão, além de tomar decisões sobre como equilibrar o tráfego. Digamos usando o Thompson Sampling.
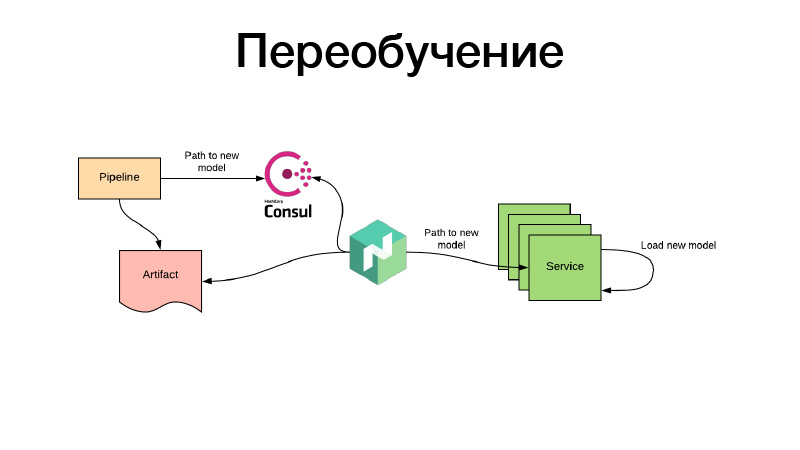
Tudo bem, os modelos foram de alguma forma treinados, nós os registramos na configuração do Nomad. Mas e se houver um modelo de recomendações que já tenha tempo para se tornar obsoleto durante o treinamento e precisarmos treiná-las constantemente? Tudo é feito da mesma maneira: por meio de trabalhos em lotes periódicos, algum artefato é produzido - digamos, a cada três horas. Ao mesmo tempo, no final de seu trabalho, o pipeline define o caminho para o novo modelo no Consul. Este é o armazenamento de valor-chave, usado para configuração. O Nomad pode configurar as configurações. Exista uma variável de ambiente com base nos valores do Consul de armazenamento de valores-chave. Ele monitora as alterações e, assim que um novo caminho aparece, decide que dois caminhos podem ser seguidos. Ele baixa o artefato por meio de um novo link, coloca o contêiner de serviço no Docker usando volume e reinicializa - e faz tudo isso para que não haja tempo de inatividade, ou seja, lentamente, individualmente. Ou ele renderiza uma nova configuração e relata o serviço para ele. Ou o próprio serviço o detecta - e dentro de si pode, independentemente, atualizar ao vivo sua modelka. Isso é tudo, obrigado.