
Há um pequeno data center perto de uma empresa de manufatura em uma pequena cidade bem longe de Moscou. Ele é necessário o tempo todo. Aconteceu que há apenas uma entrada da rede elétrica, mas não há grupo gerador a diesel. Como a empresa não é de TI, mas de produção, eles não foram projetados corretamente. Porque uma vez tudo funcionou.
O raio do poder começou a fazer brincadeiras. A cada semana, a luz era cortada por várias horas e de uma maneira lotérica: elas podiam durar uma hora ou mais. Não há padrões.
O administrador sugeriu a compra de um diesel, mas a empresa disse que este não era um negócio administrativo. Seu trabalho é fornecer tempo de inatividade por não mais de uma hora. Eles investiram muito dinheiro no equipamento, para que você não possa partir para a nuvem, e não há data centers comerciais para transportar o equipamento para lá.
E o que fazer?
É com essa tarefa que o cliente veio até nós. Não há muito orçamento, você precisa procurar uma solução válida.
O caso normal (exceto a aparência da segunda entrada, a transferência de equipamento ou a aparência de um gerador a diesel) é implantar a segunda exatamente a mesma instância na nuvem e mudar para ela se algo cair repentinamente. É chamado de recuperação de desastres. Alguns estão construindo um segundo data center para si mesmos, está frio e aguardando a queda do principal, ou funciona no modo ativo-ativo, ocupando 50% da carga.
Mas não há dinheiro para um segundo data center completo.
Eles vieram com isso:

Há um servidor físico pesado com um banco de dados no datacenter do cliente. E há aplicativos trabalhando com esse banco de dados, que são um conjunto de máquinas virtuais no ESXi.
Para replicar o banco de dados, eles instalaram o software Carbonite Availability (anteriormente conhecido como Double-Take Availability) na nuvem, que funciona no nível do SO. E para a replicação das máquinas virtuais que instalaram o Zerto, esse software funciona no nível do hipervisor. Ambas as soluções funcionam aproximadamente da mesma maneira: primeiro, elas replicam todo o volume de dados do servidor na nuvem e interceptam todos os registros em discos no site principal e os duplicam em discos na nuvem. O atraso neste caso é especificamente de 10 segundos, ou seja, sempre temos uma cópia nova dos dados 10 segundos atrás.
Máquinas virtuais não estão incluídas. Usando o botão do painel de controle Zerto, podemos iniciar todas as VMs de uma só vez. Isso acontece em cerca de 28 minutos (as máquinas iniciam em paralelo), SLA por 1 hora conosco ociosos. O lançamento é feito chamando o administrador de serviço. O cliente decide quando é necessário.
VMs pegam a base e começam a trabalhar.
Quando a energia é ligada na instalação, o próprio cliente entende sua infraestrutura. Lida com falhas e, em seguida, habilita manualmente a replicação reversa. A quantidade de alterações no banco de dados acumuladas durante a operação dos aplicativos é devolvida. Replicado - interruptor. Neste exemplo específico, o tráfego acumula cerca de 5 minutos de recarga para cada hora de máquinas virtuais. Quanto maior o tempo de operação da instância de emergência, menor o compartilhamento de tráfego, porque os registros costumam ir para as mesmas tabelas do banco de dados e enviamos apenas a diferença.
Depois de voltar à nuvem, as máquinas virtuais são encerradas. O cliente não paga pelos recursos desativados. Quantizamos pelo relógio.
O pagamento é apenas pela quantidade de dados armazenados, canal e licença de software para replicação (Zerto e Carbonite). Trabalhamos com o princípio "Recuperação de desastres como um serviço", fornecendo SLA para isso. E responsável financeiramente por este SLA.
O cliente replica tudo, uma máquina virtual com os mesmos parâmetros de sua física, todas as unidades de disco são espelhadas.
É isso que Zerto faz:
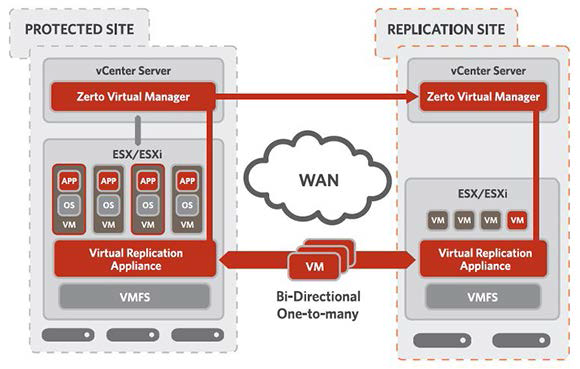
Possui replicação sem agente, modo assíncrono, VMs na plataforma DR desativadas, replicação de diário, otimização de WAN, replicação de hipervisor, licenciamento de máquinas virtuais protegidas.
O Carbonite é uma replicação de agente; portanto, independentemente do hipervisor, existe um modo de operação assíncrono, há suporte para instantâneos, compactação dos dados transmitidos, licenciamento para máquinas virtuais protegidas.
A instalação aplicou as duas soluções de uma só vez. Por isso, foi necessário devido a vários recursos. Geralmente eles oferecem uma coisa.
Você também pode resolver um problema semelhante com a solução doméstica do Veeam Cloud Connect (geralmente o usamos se você já possui um backup do Veeam).
Sumário
Todos entendemos que o problema poderia ser resolvido de maneira diferente bombeando a instalação do servidor de um gerador a diesel. No entanto, o negócio reduziu os requisitos para a organização da reserva. Prestamos um serviço e funcionou. Acabou sendo um bom exemplo de como você pode implantar uma plataforma de recuperação de desastres de maneira correta e barata.
Referências