
Me deparei com material interessante sobre inteligência artificial em jogos. Com uma explicação das coisas básicas sobre IA usando exemplos simples, e por dentro existem muitas ferramentas e métodos úteis para seu desenvolvimento e design convenientes. Como, onde e quando usá-los - também está lá.
A maioria dos exemplos é escrita em pseudocódigo, portanto, não é necessário conhecimento aprofundado de programação. Sob o corte de 35 folhas de texto com fotos e gifs, prepare-se.
UPD Sinto
muito , mas o
PatientZero já fez a tradução deste artigo em Habré. Você pode ler sua versão
aqui , mas por algum motivo o artigo passou por mim (usei a pesquisa, mas algo deu errado). E como estou escrevendo um blog de desenvolvedores de jogos, decidi deixar minha opção de tradução para assinantes (alguns momentos são diferentes para mim, outros são intencionalmente ignorados pelos conselhos dos desenvolvedores).
O que é IA?
A IA do jogo se concentra em quais ações um objeto deve executar com base nas condições em que está localizado. Isso geralmente é chamado de gerenciamento de "agentes inteligentes", onde o agente é um personagem do jogo, veículo, bot e, às vezes, algo mais abstrato: um grupo inteiro de entidades ou mesmo civilização. Em cada caso, é algo que deve ver seu entorno, tomar decisões com base e agir de acordo com eles. Isso é chamado de ciclo Sense / Think / Act:
- Sentido: o agente encontra ou recebe informações sobre coisas em seu ambiente que podem afetar seu comportamento (ameaças próximas, itens a coletar, locais interessantes para pesquisar).
- Pense: o agente decide como reagir (considera se é seguro coletar itens ou se deve lutar / se esconder primeiro).
- Ato: o agente executa ações para implementar a decisão anterior (começa a se mover em direção ao oponente ou objeto).
- ... agora a situação mudou devido às ações dos personagens, então o ciclo se repete com novos dados.
A IA tende a se concentrar na parte sensorial do loop. Por exemplo, carros autônomos tiram fotos da estrada, combinam-nos com dados de radar e lidar e interpretam. Geralmente, isso é feito pelo aprendizado de máquina, que processa os dados recebidos e lhes dá significado, extraindo informações semânticas como "existe outro carro 20 metros à sua frente". Estes são os chamados problemas de classificação.
Os jogos não precisam de um sistema complexo para extrair informações, pois a maioria dos dados já é parte integrante deles. Não é necessário executar algoritmos de reconhecimento de imagem para determinar se há um inimigo à frente - o jogo já sabe e transfere informações diretamente no processo de tomada de decisão. Portanto, parte do ciclo do Sentido é muitas vezes muito mais simples que o Pense e aja.
Limitações da IA do jogo
A IA possui várias restrições que devem ser observadas:
- A IA não precisa ser treinada com antecedência, como se fosse um algoritmo de aprendizado de máquina. Não faz sentido escrever uma rede neural durante o desenvolvimento para assistir a dezenas de milhares de jogadores e aprender a melhor maneira de jogar contra eles. Porque Porque o jogo não é lançado, mas não há jogadores.
- O jogo deve ser divertido e desafiador, portanto, os agentes não devem encontrar a melhor abordagem contra as pessoas.
- Os agentes precisam parecer realistas para que os jogadores sintam que estão jogando contra pessoas reais. O AlphaGo superou os humanos, mas os passos dados estavam longe do entendimento tradicional do jogo. Se o jogo imitar um oponente humano, não deve haver esse sentimento. O algoritmo precisa ser alterado para que tome decisões plausíveis, e não ideais.
- A IA deve funcionar em tempo real. Isso significa que o algoritmo não pode monopolizar o uso do processador por um longo tempo para a tomada de decisão. Até 10 milissegundos para isso é muito longo, porque a maioria dos jogos tem apenas 16 a 33 milissegundos para concluir todo o processamento e passar para o próximo quadro do gráfico.
- Idealmente, pelo menos parte do sistema é orientada por dados, para que não codificadores possam fazer alterações e ajustes mais rápidos.
Considere abordagens de IA que abrangem todo o ciclo Sense / Think / Act.
Tomada de decisão básica
Vamos começar com o jogo mais simples - Pong. Objetivo: mover a plataforma (raquete) para que a bola salte fora dela, em vez de passar voando. É como o tênis, no qual você perde se não bate na bola. Aqui, a IA tem uma tarefa relativamente fácil - decidir em qual direção mover a plataforma.

Instruções condicionais
Para a IA, Pong tem a solução mais óbvia - sempre tente posicionar a plataforma embaixo da bola.
Um algoritmo simples para isso, escrito em pseudocódigo:
cada quadro / atualização enquanto o jogo está em execução:
se a bola estiver à esquerda da raquete:
mover remo para a esquerda
caso contrário, se a bola estiver à direita da raquete:
mover remo para a direitaSe a plataforma se mover na velocidade da bola, esse é o algoritmo perfeito para IA em Pong. Não há necessidade de complicar nada se não houver muitos dados e possíveis ações para o agente.
Essa abordagem é tão simples que quase todo o ciclo Sense / Think / Act é quase imperceptível. Mas ele é:
- A parte Sense está em duas instruções if. O jogo sabe onde está a bola e onde está a plataforma, então a IA recorre a ela para obter essas informações.
- A parte Think também vem em duas declarações if. Eles incorporam duas soluções, que neste caso são mutuamente exclusivas. Como resultado, uma das três ações é selecionada - mova a plataforma para a esquerda, mova para a direita ou não faça nada se já estiver posicionada corretamente.
- A parte Act está nas instruções Move Paddle Left e Move Paddle Right. Dependendo do design do jogo, eles podem mover a plataforma instantaneamente ou a uma certa velocidade.
Tais abordagens são chamadas de reativas - há um conjunto simples de regras (neste caso, se no código) que respondem ao estado atual do mundo e agem.
Árvore de decisão
O exemplo de Pong é realmente igual ao conceito formal de IA chamado árvore de decisão. O algoritmo o passa para chegar a uma “folha” - uma decisão sobre qual ação tomar.
Vamos fazer um diagrama de blocos da árvore de decisão para o algoritmo da nossa plataforma:
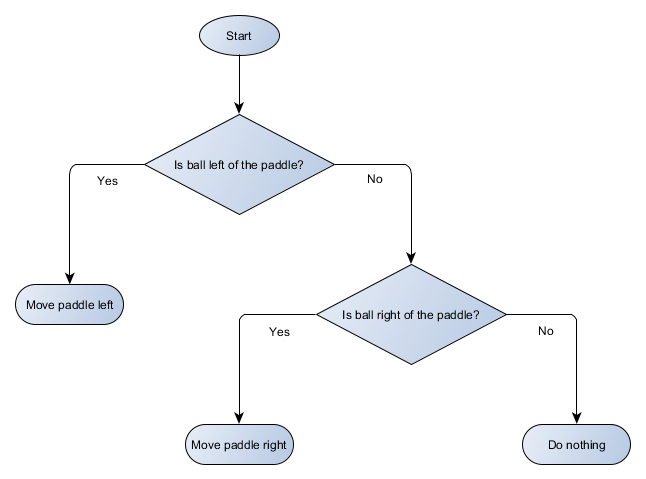
Cada parte da árvore é chamada de nó - a IA usa a teoria dos grafos para descrever essas estruturas. Existem dois tipos de nós:
- Nós de decisão: escolha entre duas alternativas com base na verificação de uma determinada condição em que cada alternativa é apresentada como um nó separado.
- Nós finais: uma ação a ser executada que representa a decisão final.
O algoritmo começa com o primeiro nó (a "raiz" da árvore). Ele decide para qual nó filho acessar ou executa uma ação armazenada no nó e é concluída.
Qual é a vantagem se a árvore de decisão faz o mesmo trabalho que as instruções if na seção anterior? Aqui existe um sistema comum em que cada solução tem apenas uma condição e dois resultados possíveis. Isso permite que o desenvolvedor crie AI a partir dos dados que representam as decisões na árvore, evitando sua codificação. Imagine na forma de uma tabela:
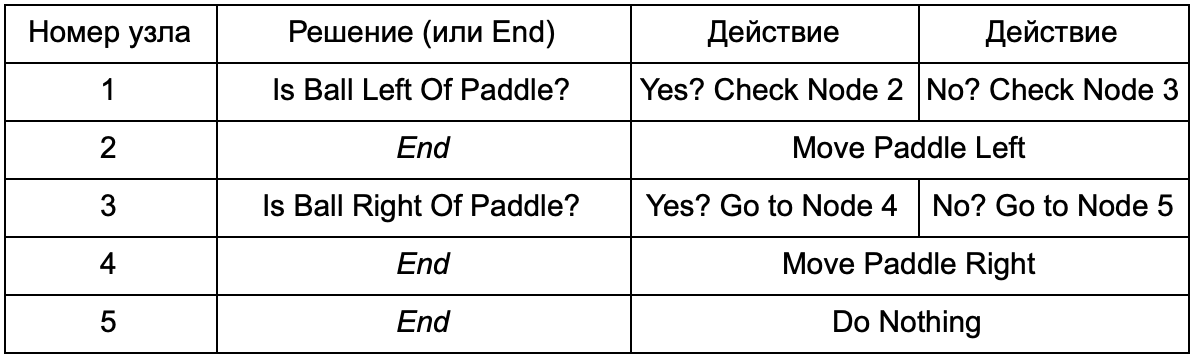
No lado do código, você obtém um sistema para leitura de strings. Crie um nó para cada um deles, conecte a lógica de decisão com base na segunda coluna e os nós filhos com base na terceira e quarta colunas. Você ainda precisa programar as condições e ações, mas agora a estrutura do jogo será mais complicada. Nele, você adiciona decisões e ações adicionais e, em seguida, configura toda a IA simplesmente editando um arquivo de texto com uma definição de árvore. Em seguida, transfira o arquivo para o designer do jogo, que pode alterar o comportamento sem recompilar o jogo e alterar o código.
As árvores de decisão são muito úteis quando construídas automaticamente com base em um grande conjunto de exemplos (por exemplo, usando o algoritmo ID3). Isso os torna uma ferramenta eficaz e de alto desempenho para classificar situações com base nos dados recebidos. No entanto, vamos além de um sistema simples para os agentes selecionarem ações.
Cenários
Desmontamos um sistema de árvore de decisão que usava condições e ações pré-criadas. O designer de IA pode organizar a árvore da maneira que quiser, mas ainda precisa confiar no codificador que programou tudo. E se pudéssemos fornecer ferramentas de designer para criar nossas próprias condições ou ações?
Para impedir que o programador escreva código para as condições Is Ball Left Paddle e Is Ball Right Paddle, ele pode criar um sistema no qual o designer registrará as condições para verificar esses valores. Em seguida, os dados da árvore de decisão terão a seguinte aparência:
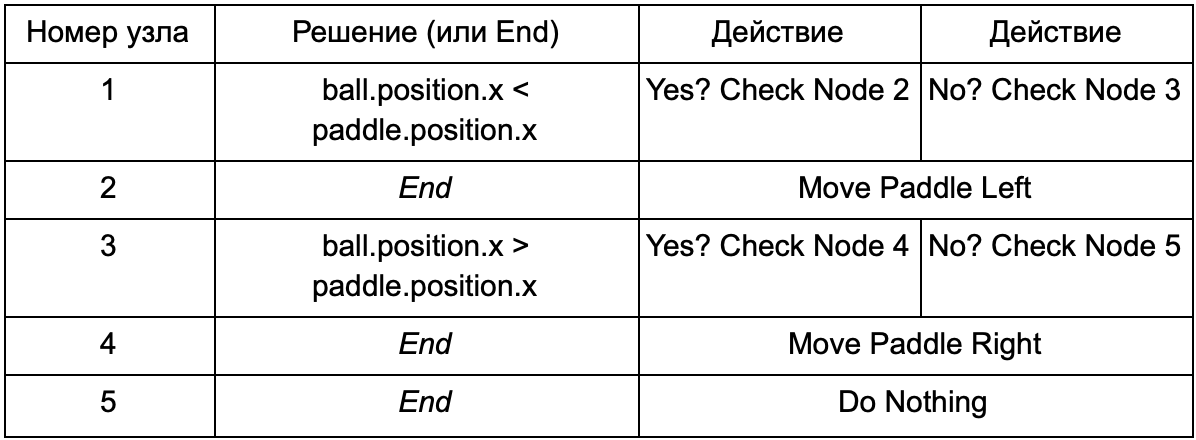
Em essência, é o mesmo que na primeira tabela, mas as soluções dentro de si têm seu próprio código, um pouco semelhante à parte condicional da instrução if. No lado do código, isso seria lido na segunda coluna para nós de decisão, mas, em vez de procurar uma condição específica a ser cumprida (Is Ball Left Of Paddle), ele avalia a expressão condicional e retorna verdadeiro ou falso, respectivamente. Isso é feito usando a linguagem de script Lua ou Angelscript. Utilizando-os, o desenvolvedor pode pegar objetos em seu jogo (bola e raquete) e criar variáveis que estarão disponíveis no script (ball.position). Além disso, a linguagem de script é mais simples que o C ++. Ele não requer um estágio completo de compilação, portanto, é ideal para o rápido ajuste da lógica do jogo e permite que “não codificadores” criem as funções necessárias.
No exemplo acima, a linguagem de script é usada apenas para avaliar uma expressão condicional, mas também pode ser usada para ações. Por exemplo, os dados Move Paddle Right podem se tornar uma instrução de script (ball.position.x + = 10). Para que a ação também seja definida no script, sem a necessidade de programar o Move Paddle Right.
Você pode ir ainda mais longe e escrever uma árvore de decisão completa em uma linguagem de script. Este será um código na forma de instruções condicionais codificadas, mas elas estarão localizadas em arquivos de script externos, ou seja, poderão ser alteradas sem recompilar o programa inteiro. Muitas vezes, você pode alterar o arquivo de script diretamente durante o jogo para testar rapidamente diferentes reações da IA.
Resposta do evento
Os exemplos acima são perfeitos para o Pong. Eles executam continuamente o ciclo Sense / Think / Act e agem com base no estado mais recente do mundo. Mas em jogos mais complexos, você precisa responder a eventos individuais e não avaliar tudo de uma vez. Pong já é um exemplo malsucedido. Escolha outro.
Imagine um atirador em que os inimigos ficam imóveis até encontrar o jogador, após o que agem dependendo da sua "especialização": alguém corre para "esmagar", alguém ataca de longe. Este ainda é o sistema responsivo básico - “se o jogador for notado, faça alguma coisa” - mas pode ser logicamente dividido no evento Visto pelo Jogador (o jogador é notado) e a reação (selecione a resposta e execute-a).
Isso nos leva de volta ao ciclo Sense / Think / Act. Podemos codificar a parte Sense, que cada quadro verificará se a IA do jogador está visível. Caso contrário, nada acontece, mas, se aparecer, o evento Jogador visto é gerado. O código terá uma seção separada que diz: "quando o evento Visto pelo Jogador ocorrer, faça-o", onde está a resposta que você precisa para se referir às partes Pensar e Agir. Assim, você configurará reações ao evento Player Seen: ChargeAndAttack para o personagem "crescente" e HideAndSnipe para o atirador de elite. Esses relacionamentos podem ser criados no arquivo de dados para edição rápida sem precisar recompilar. E aqui você também pode usar a linguagem de script.
Tomar decisões difíceis
Embora sistemas de reação simples sejam muito eficazes, existem muitas situações em que não são suficientes. Às vezes, é necessário tomar várias decisões com base no que o agente está fazendo no momento, mas é difícil imaginar isso como uma condição. Às vezes, existem muitas condições para representá-las efetivamente em uma árvore ou script de decisão. Às vezes, você precisa pré-avaliar como a situação vai mudar antes de decidir o próximo passo. Resolver esses problemas requer abordagens mais sofisticadas.
Máquina de estado finito
Máquina de estado finito ou FSM (máquina de estado) é uma maneira de dizer que nosso agente está atualmente em um dos vários estados possíveis e que ele pode passar de um estado para outro. Há um certo número desses estados - daí o nome. O melhor exemplo de vida é um semáforo. Em lugares diferentes, sequências diferentes de luzes, mas o princípio é o mesmo - cada estado representa algo (stand, go, etc.). Um semáforo fica apenas em um estado a qualquer momento e passa de um para outro com base em regras simples.
Com NPCs em jogos, uma história semelhante. Por exemplo, tome um guarda com as seguintes condições:
- Patrulhamento
- Atacar
- Fugindo
E essas condições para mudar sua condição:
- Se o guarda vê o inimigo, ele ataca.
- Se o guarda ataca, mas não vê mais o inimigo, ele volta a patrulhar.
- Se o guarda atacar, mas estiver gravemente ferido, ele foge.
Você também pode escrever declarações if com uma variável de estado de guarda e várias verificações: existe um inimigo por perto, qual é o nível de saúde do NPC, etc. Vamos adicionar mais alguns estados:
- Inação (inatividade) - entre patrulhas.
- Search (Searching) - quando o inimigo notado desapareceu.
- Peça ajuda (Finding Help) - quando o inimigo for visto, mas forte demais para lutar com ele sozinho.
A escolha para cada um deles é limitada - por exemplo, um guarda não procurará um inimigo escondido se estiver com a saúde debilitada.
No final, a enorme lista de "se <x e y, mas não z>, então <p>" pode se tornar muito complicada; portanto, devemos formalizar um método que nos permita ter em mente os estados e transições entre estados. Para fazer isso, levamos em conta todos os estados e, em cada estado, listamos todas as transições para outros estados, juntamente com as condições necessárias para eles.
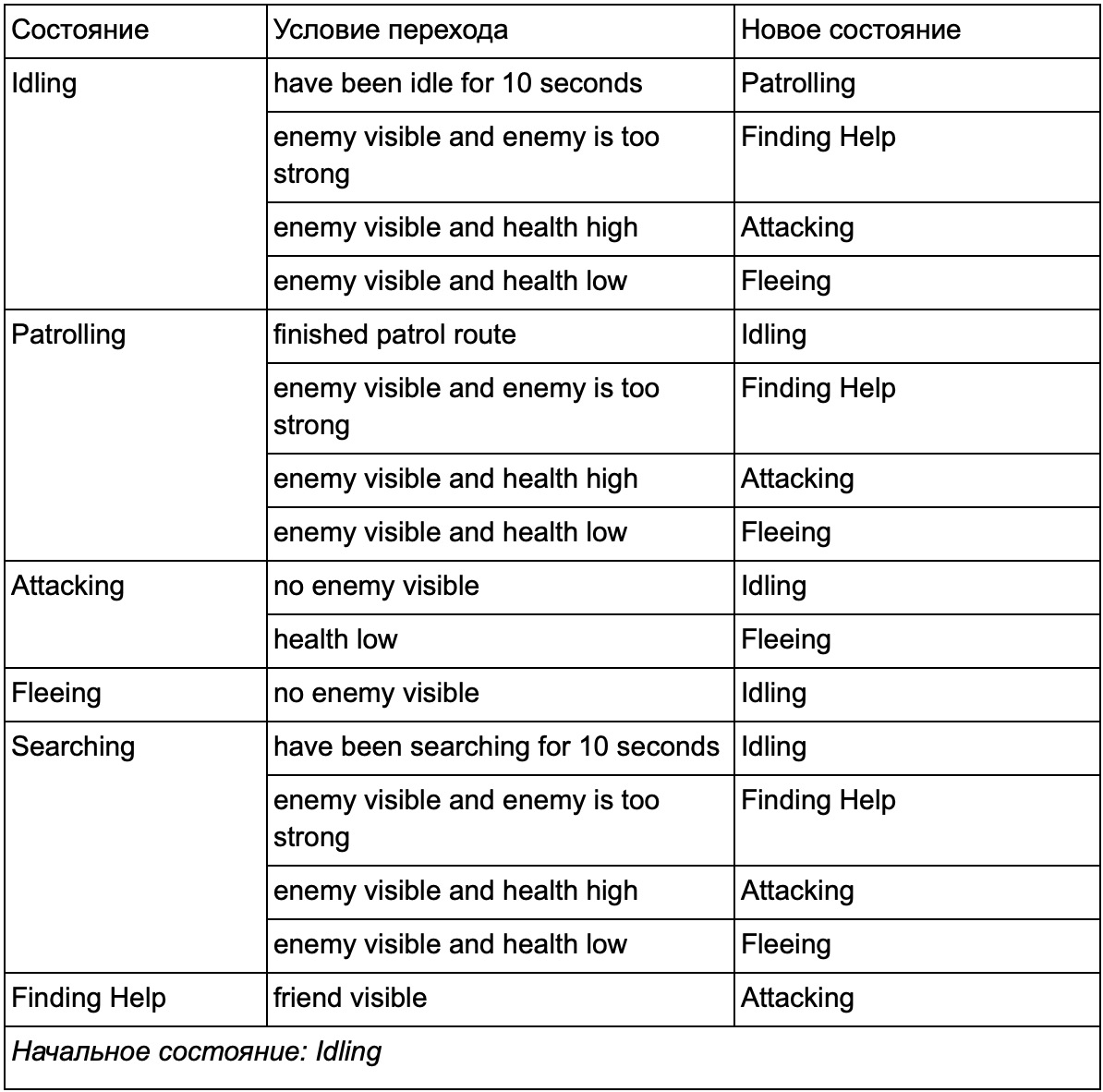
Esta tabela de transição de estado é uma maneira abrangente de representar o FSM. Vamos desenhar um diagrama e obter uma visão geral completa de como o comportamento dos NPCs muda.
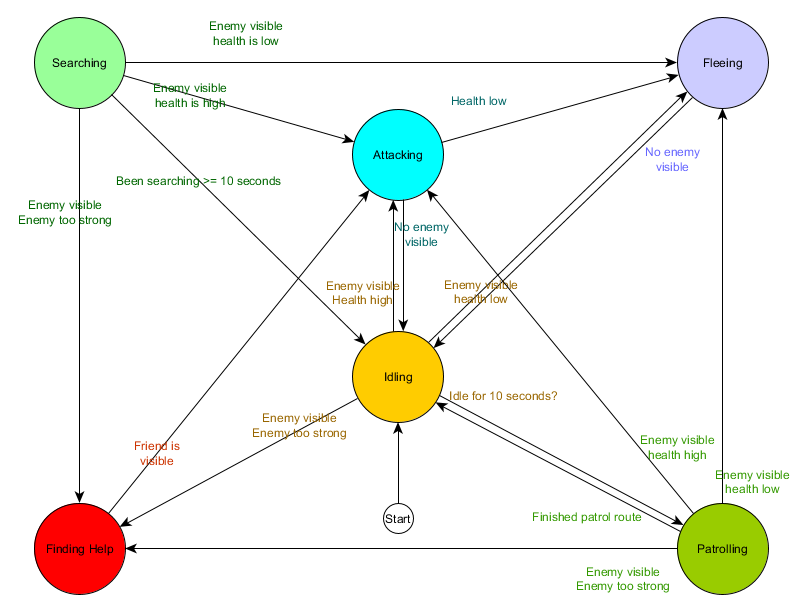
O gráfico reflete a essência da tomada de decisão para esse agente com base na situação atual. Além disso, cada seta mostra uma transição entre estados se a condição próxima a ela for verdadeira.
A cada atualização, verificamos o estado atual do agente, observamos a lista de transições e, se as condições para a transição forem atendidas, ele assumirá um novo estado. Por exemplo, cada quadro verifica se o temporizador de 10 segundos expirou e, em caso afirmativo, o guarda muda de Idling para Patrolling. Da mesma forma, o estado Atacante verifica a saúde do agente - se estiver baixo, entra no estado Fugindo.
Isso é lidar com transições de estado, mas e o comportamento associado aos próprios estados? Em relação à implementação do comportamento real de um estado específico, geralmente existem dois tipos de "ganchos" nos quais atribuímos ações ao FSM:
- Ações que realizamos periodicamente para o estado atual.
- As ações que tomamos ao passar de um estado para outro.
Exemplos para o primeiro tipo. Estado de patrulha Cada quadro moverá o agente ao longo da rota de patrulha. Estado de ataque Cada quadro tentará iniciar um ataque ou entrar em um estado quando possível.
Para o segundo tipo, considere a transição “se o inimigo estiver visível e for muito forte, vá para o estado Procurando ajuda. O agente deve escolher para onde procurar ajuda e salvar essas informações para que o status Procurando Ajuda saiba para onde ir. Assim que a ajuda é encontrada, o agente volta ao estado Atacante. Nesse momento, ele desejará informar o aliado sobre a ameaça, para que a ação NotifyFriendOfThreat possa ocorrer.
E, novamente, podemos olhar para esse sistema através do prisma do ciclo Sense / Think / Act. O Sense se traduz em dados usados pela lógica de transição. Pense - transições disponíveis em cada estado. E o ato é realizado por ações realizadas periodicamente dentro do estado ou em transições entre estados.
Às vezes, o polling contínuo das condições de transição pode ser caro. Por exemplo, se cada agente executar cálculos complexos em cada quadro para determinar se vê inimigos e entender se é possível alternar do estado Patrulhamento para Atacar, isso levará muito tempo do processador.
Mudanças importantes no estado do mundo podem ser consideradas eventos que serão processados à medida que ocorrerem. Em vez de o FSM verificar a condição de transição "meu agente pode ver o player?" Em cada quadro, você pode configurar um sistema separado para executar verificações com menos frequência (por exemplo, 5 vezes por segundo). E o resultado é dar ao jogador visto quando o cheque passa.
Isso é passado para o FSM, que agora precisa entrar na condição de jogador recebido do evento Visto e reagir de acordo. O comportamento resultante é o mesmo, exceto por um atraso quase imperceptível antes de responder. Mas o desempenho ficou melhor como resultado da separação de parte do Sense em uma parte separada do programa.
Máquina hierárquica de estados finitos
No entanto, trabalhar com FSMs grandes nem sempre é conveniente. Se quisermos expandir o estado do ataque, substituindo-o por MeleeAttacking (corpo a corpo) e RangedAttacking (à distância), teremos que alterar as transições de todos os outros estados que levam ao estado de ataque (atual e futuro).
Certamente você percebeu que em nosso exemplo existem muitas transições duplicadas. A maioria das transições no estado inativo é idêntica às transições no estado de patrulhamento. Seria bom não repetir, especialmente se adicionarmos mais estados semelhantes. Faz sentido agrupar Idling and Patrolling sob o rótulo comum "non-combat", onde existe apenas um conjunto comum de transições para combater estados. Se apresentarmos essa etiqueta como um estado, a marcha lenta e o patrulhamento se tornarão subestados. Um exemplo de uso de uma tabela de conversão separada para um novo subestado que não seja de combate:
As principais condições: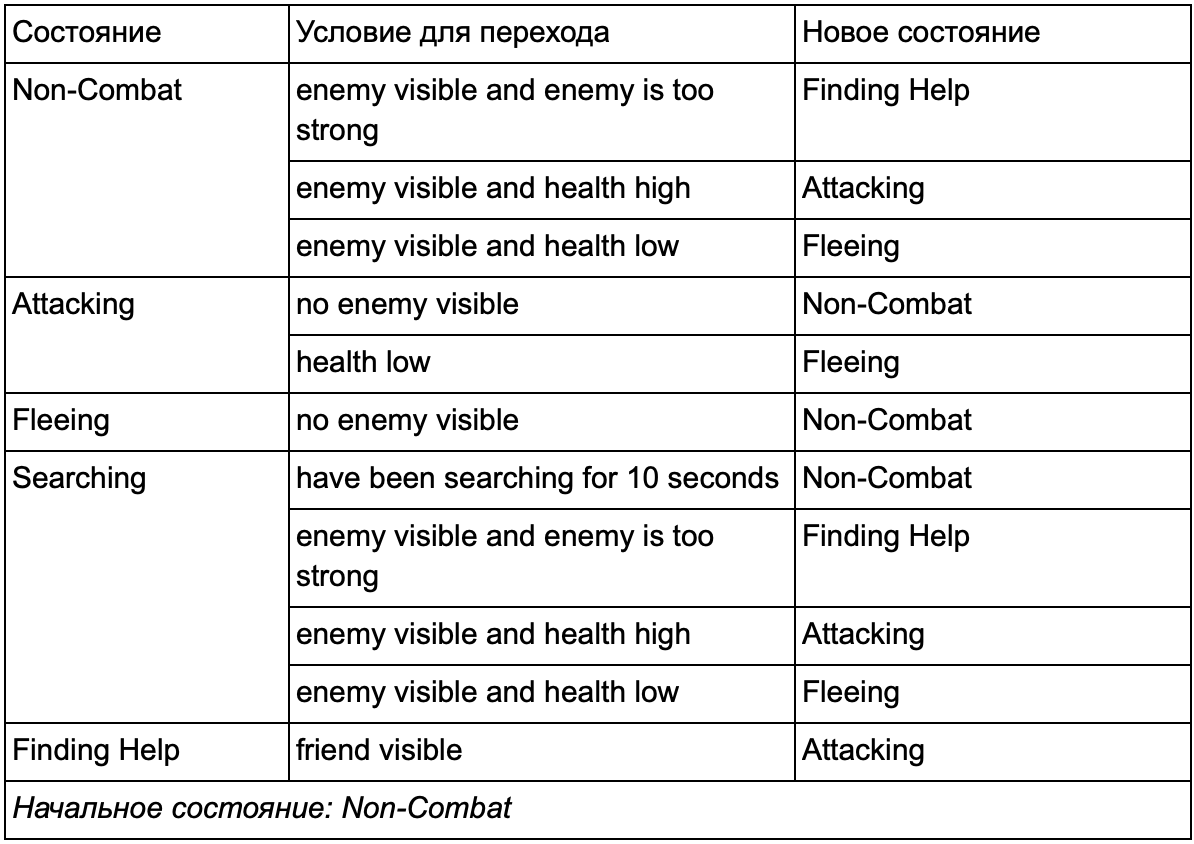 Status fora de combate:
Status fora de combate:
E em forma de gráfico:
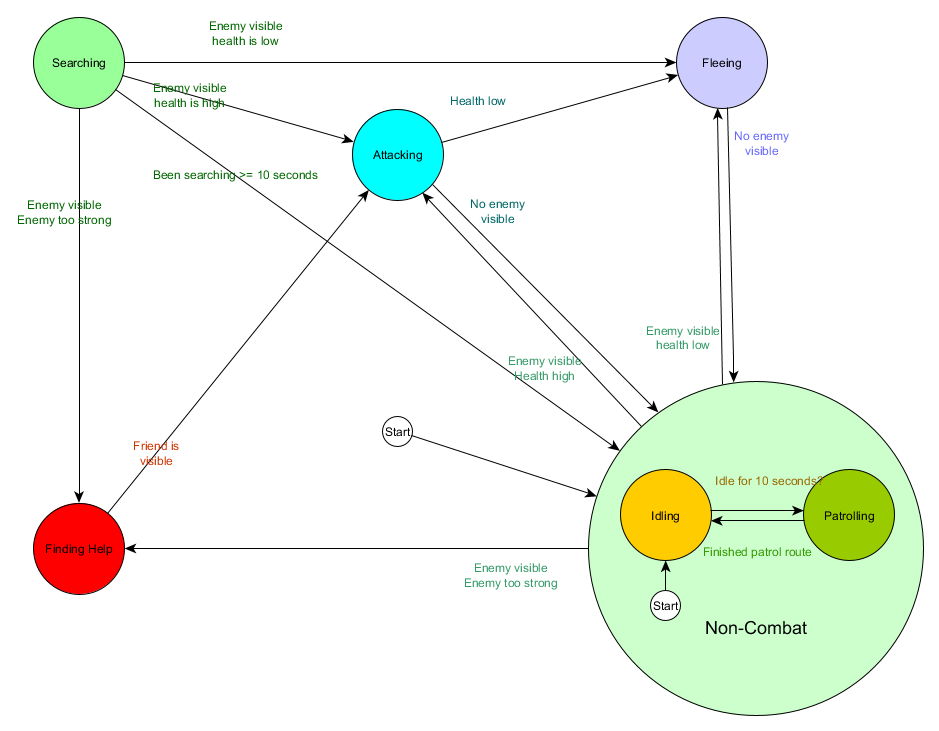
Este é o mesmo sistema, mas com um novo estado de não combate, que inclui Idling and Patrolling. Com cada estado que contém FSMs com subestados (e esses subestados, por sua vez, contêm seus próprios FSMs - e assim por diante, conforme necessário), obtemos uma Máquina de Estado Finito Hierárquico ou HFSM (máquina de estado hierárquico). Depois de agrupar um estado de não combate, cortamos várias transições redundantes. Podemos fazer o mesmo para quaisquer novos estados com transições comuns. Por exemplo, se no futuro estendermos o estado Ataque aos estados MeleeAttacking e MissileAttacking, eles serão subestados que se cruzam com base na distância do inimigo e na presença de munição. Como resultado, modelos complexos de comportamento e submodelos de comportamento podem ser representados com um mínimo de transições duplicadas.
HFSM . , , . , . . , , . , 25%, , , , — . 25% 10%, .
, « », , . .
, : «» , , , . :
- : Succeeded ( ), Failed ( ) Running ( ).
- . Decorator, . Succeed, .
- , , Running .
. HFSM :
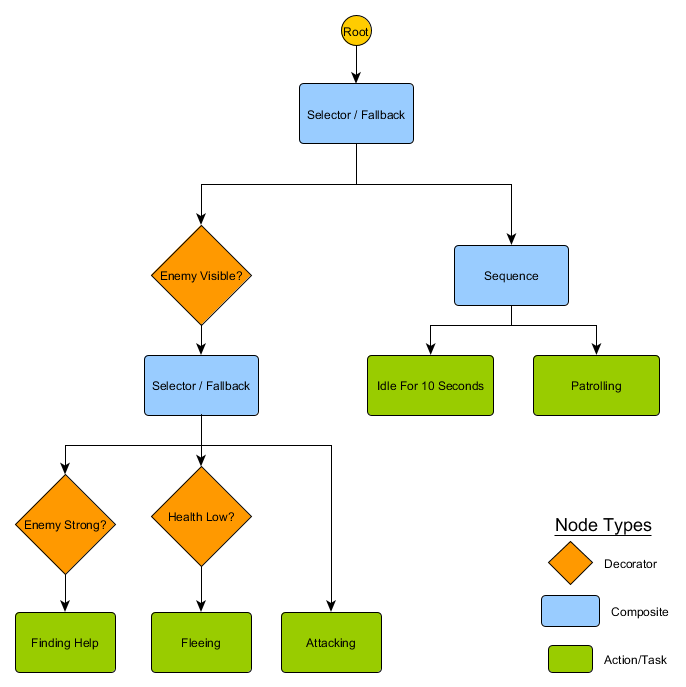
Idling/Patrolling Attacking . , , Fleeing, , — Patrolling, Idling, Attacking .
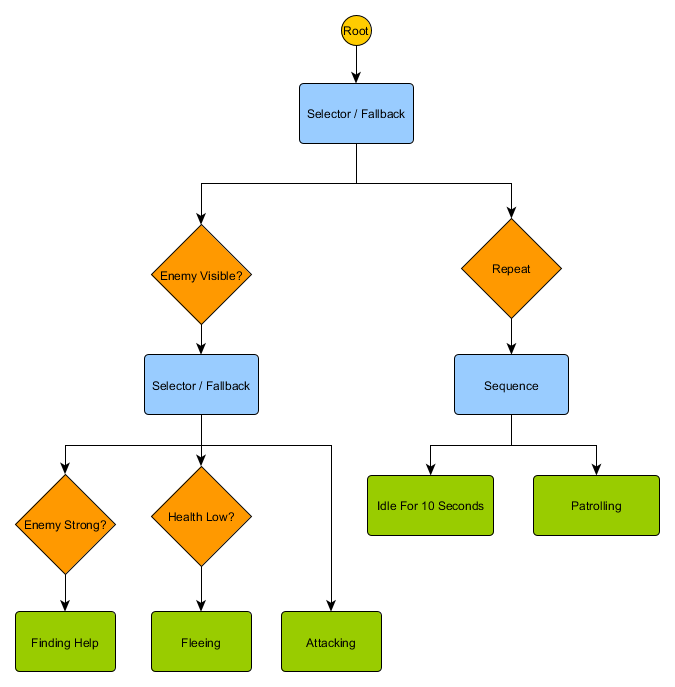
— , . , — , ? , — , Idling 10 , , ?
. , . , .
Utility-based system
. , , . , , .
Utility-based system (, ) . , , , . — , .
, . FSM, , , . , ( , ). , .
— , 0 ( ) 100 ( ). , . :

— . . , , , Fleeing, FindingHelp . FindingHelp . , 50, . .
, . . , Fleeing , , Attacking , . - Fleeing Attacking , , . , , FSM.
. . The Sims, , — «», . , , EatFood , , , EatFood .
, Utility-based system , . . , Utility , , .
, , , . ? , , , , ? .
Gerência
, , , . , , . . Sense/Think/Act, , Think , Act . , , . — , . , , . :
desired_travel = destination_position – agent_position2D-. (-2,-2), - - (30, 20), , — (32, 22). , — 5 , (4.12, 2.83). 8 .
. , , 5 / ( ), . , .
— , , , . . steering behaviours, : Seek (), Flee (), Arrival () . . , , , .
. Seek Arrival — . Obstacle Avoidance ( ) Separation () , . Alignment () Cohesion () . steering behaviours . , Arrival, Separation Obstacle Avoidance, . .
, — , - Arrival Obstacle Avoidance. , , . : , .
, , - .
Steering behaviours ( ), — . pathfinding ( ), .
— . - , , . . , ( , ). , Breadth-First Search BFS ( ). ( breadth, «»). , , — , , .
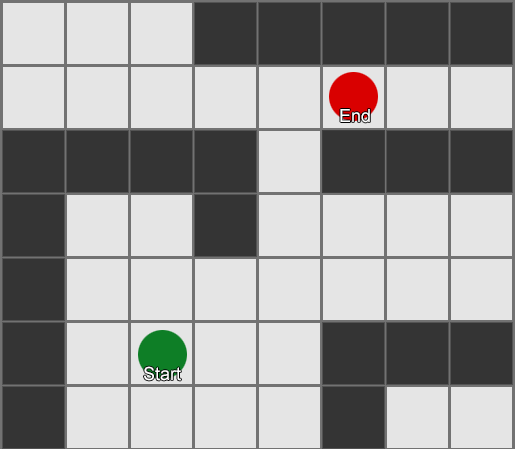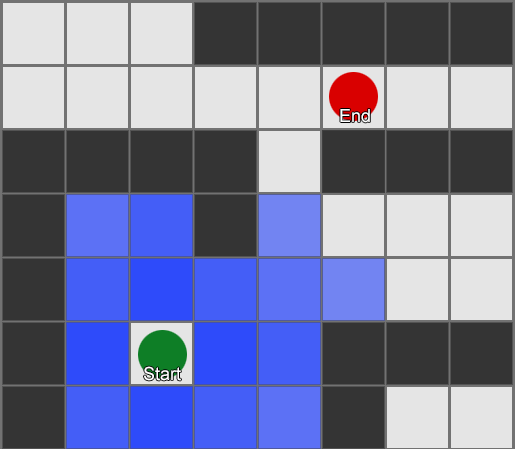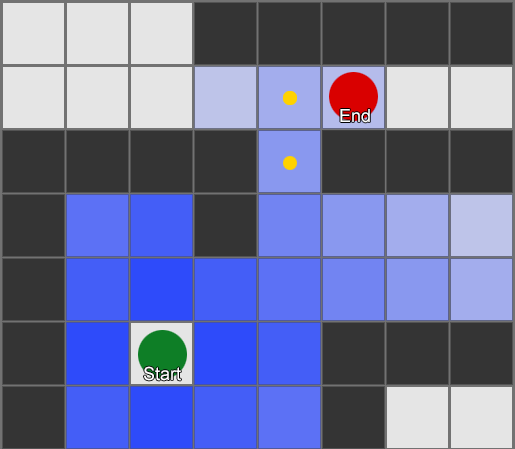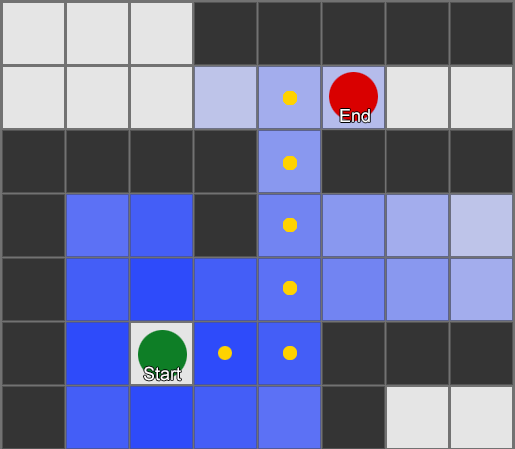
, . (, pathfinding) — , , .
, , steering behaviours, — 1 2, 2 3 . — , — . - .
BFS — «» , «». A* (A star). , - ( , ), , , . , — «» ( ) , ( ).
, , , . , BFS, — .
Mas a maioria dos jogos não é apresentada na grade, e muitas vezes isso não pode ser feito sem comprometer o realismo. São necessários compromissos. Qual o tamanho dos quadrados? Grande demais - e eles não conseguirão imaginar corretamente corredores ou curvas pequenos demais - haverá muitos quadrados a serem pesquisados, o que no final levará muito tempo.
A primeira coisa a entender é que a grade nos fornece um gráfico de nós conectados. Os algoritmos A * e BFS realmente funcionam em gráficos e não se importam com nossa grade. Poderíamos colocar os nós em qualquer lugar do mundo do jogo: se houver uma conexão entre dois nós conectados, bem como entre os pontos inicial e final e pelo menos um dos nós, o algoritmo funcionará tão bem quanto antes. Isso costuma ser chamado de sistema de waypoint, já que cada nó representa uma posição significativa no mundo, que pode fazer parte de qualquer número de caminhos hipotéticos.
 Exemplo 1: um nó em cada quadrado. A pesquisa começa no nó em que o agente está localizado e termina no nó do quadrado desejado.
Exemplo 1: um nó em cada quadrado. A pesquisa começa no nó em que o agente está localizado e termina no nó do quadrado desejado.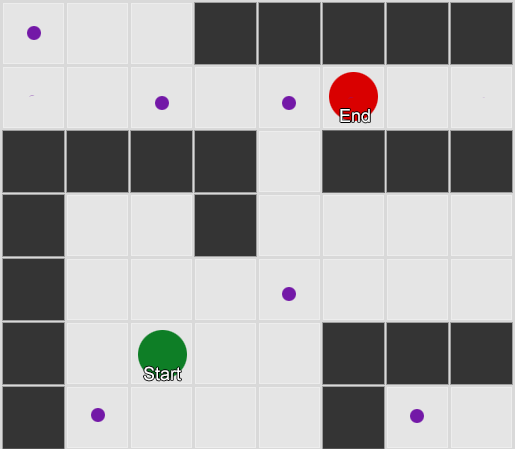 Exemplo 2: um conjunto menor de nós (pontos de referência). A pesquisa começa ao quadrado com o agente, passa pelo número necessário de nós e depois continua para o destino.
Exemplo 2: um conjunto menor de nós (pontos de referência). A pesquisa começa ao quadrado com o agente, passa pelo número necessário de nós e depois continua para o destino.Este é um sistema completamente flexível e poderoso. Mas você precisa de cautela ao decidir onde e como posicionar o waypoint; caso contrário, os agentes podem simplesmente não ver o ponto mais próximo e não poderão iniciar o caminho. Seria mais fácil se pudéssemos definir automaticamente waypoints com base na geometria do mundo.
Em seguida, uma malha de navegação ou navmesh aparece. Geralmente, é uma malha 2D de triângulos que se sobrepõe à geometria do mundo - onde quer que o agente possa andar. Cada um dos triângulos na grade se torna um nó no gráfico e tem até três triângulos adjacentes que se tornam nós adjacentes no gráfico.
Esta imagem é um exemplo do mecanismo do Unity - ele analisou a geometria no mundo e criou a navmesh (azul claro na captura de tela). Cada polígono na navmesh é uma área na qual um agente pode permanecer ou mover-se de um polígono para outro polígono. Neste exemplo, os polígonos são menores que os pisos em que estão localizados - feitos para levar em consideração as dimensões do agente, que vão além da sua posição nominal.

Podemos pesquisar a rota através dessa grade, novamente usando o algoritmo A *. Isso nos dará uma rota quase perfeita no mundo, que leva em consideração toda a geometria e não requer nós e pontos de referência extras.
A busca de caminhos é um tópico muito extenso sobre o qual uma seção do artigo não é suficiente. Se você quiser estudá-lo com mais detalhes, o
site de Amit Patel ajudará nisso.
Planejamento
Asseguramos com a busca de caminhos que, às vezes, não basta escolher uma direção e se mover - precisamos escolher uma rota e fazer várias curvas para chegar ao destino desejado. Podemos resumir esta idéia: alcançar o objetivo não é apenas o próximo passo, mas uma sequência inteira, onde às vezes você precisa olhar adiante alguns passos para descobrir qual deve ser o primeiro. Isso é chamado de planejamento. A busca de caminhos pode ser considerada uma das várias adições de planejamento. Da perspectiva do nosso ciclo Sense / Think / Act, é aqui que a parte Think planeja várias partes do Act para o futuro.
Vejamos o exemplo do jogo de tabuleiro Magic: The Gathering. Vamos primeiro com esse conjunto de cartas em mãos:
- Pântano - dá 1 mana preto (mapa da terra).
- Floresta - dá 1 mana verde (mapa da terra).
- Mago Fugitivo - Requer 1 de mana azul para evocar.
- Élfico Místico - Requer 1 mana verde para evocar.
Ignoramos os três cartões restantes para facilitar. De acordo com as regras, é permitido ao jogador jogar 1 carta de terreno por turno, ele pode "tocar" esta carta para extrair mana dela e, em seguida, usar magias (incluindo convocar criaturas) de acordo com a quantidade de mana. Nesta situação, o jogador humano sabe que você precisa jogar Forest, "toque" em 1 mana verde e depois chame Elvish Mystic. Mas como você adivinha o jogo AI?
Planejamento fácil
A abordagem trivial é tentar cada ação sucessivamente até que existam. Olhando para as cartas, a IA vê o que o Swamp pode jogar. E toca. Ainda existem outras ações neste turno? Ele não pode convocar Elfish Mystic ou Fugitive Wizard, já que a convocação deles requer mana verde e azul, respectivamente, e Swamp dá apenas mana negra. E ele não será capaz de jogar Forest, porque ele já jogou Swamp. Assim, o jogo AI seguiu as regras, mas fez mal. Pode ser melhorado.
O planejamento pode encontrar uma lista de ações que levam o jogo ao estado desejado. Assim como cada quadrado no caminho tinha vizinhos (na busca de caminhos), cada ação no plano também tem vizinhos ou sucessores. Podemos procurar essas ações e ações subseqüentes até atingirmos o estado desejado.
Em nosso exemplo, o resultado desejado é "convocar uma criatura, se possível". No início da jogada, vemos apenas duas ações possíveis permitidas pelas regras do jogo:
1. Jogue Pântano (resultado: Pântano no jogo)
2. Jogue Floresta (resultado: Floresta no jogo)Cada ação tomada pode levar a outras ações e fechar outras, novamente, dependendo das regras do jogo. Imagine que jogamos Swamp - isso removerá o Swamp como o próximo passo (já o jogamos) e também excluirá Forest (porque pelas regras você pode jogar um mapa do terreno por turno). Depois disso, a IA é adicionada como o próximo passo - recebendo 1 mana preto, porque não há outras opções. Se ele for mais longe e escolher Tap the Swamp, ele receberá 1 unidade de mana negra e não pode fazer nada com isso.
1. Jogue Pântano (resultado: Pântano no jogo)
1.1 Pântano "Tap" (resultado: "tap" do pântano, +1 unidade de mana negra)
Nenhuma ação disponível - FIM
2. Jogue Floresta (resultado: Floresta no jogo)A lista de ações foi curta, estamos em um impasse. Repita o processo para a próxima etapa. Jogamos Forest, abrimos a ação "receba 1 mana verde", que por sua vez abrirá a terceira ação - o chamado de Elvish Mystic.
1. Jogue Pântano (resultado: Pântano no jogo)
1.1 Pântano "Tap" (resultado: "tap" do pântano, +1 unidade de mana negra)
Nenhuma ação disponível - FIM
2. Jogue Floresta (resultado: Floresta no jogo)
2.1 Floresta "Tap" (resultado: "tap" da floresta, +1 unidade de mana verde)
2.1.1 Evocar Élfico Místico (resultado: Élfico Místico no jogo, -1 unidade de mana verde)
Nenhuma ação disponível - FIMFinalmente, examinamos todas as ações possíveis e encontramos um plano chamando a criatura.
Este é um exemplo muito simplificado. É aconselhável escolher o melhor plano possível, e não um que atenda a alguns critérios. Como regra, você pode avaliar possíveis planos com base no resultado final ou nos benefícios totais de sua implementação. Você pode adicionar 1 ponto para jogar um mapa da terra e 3 pontos para desafiar uma criatura. Jogar Swamp seria um plano dando 1 ponto. E para jogar Forest → Tap the Forest → chame Elvish Mystic - ele imediatamente dará 4 pontos.
É assim que o planejamento funciona em Magic: The Gathering, mas pela mesma lógica que se aplica em outras situações. Por exemplo, mova um peão para dar espaço para o bispo se mover no xadrez. Ou se esconda atrás de uma parede para atirar com segurança no XCOM dessa maneira. Em geral, você entende o ponto.
Planejamento aprimorado
Às vezes, existem muitas ações em potencial para considerar todas as opções possíveis. Retornando ao exemplo com Magic: The Gathering: digamos que no jogo e em suas mãos existam várias cartas de terra e criaturas - o número de combinações possíveis de movimentos pode estar nas dezenas. Existem várias soluções para o problema.
A primeira maneira é encadear para trás. Em vez de classificar todas as combinações, é melhor começar com o resultado final e tentar encontrar uma rota direta. Em vez do caminho da raiz da árvore para uma folha específica, avançamos na direção oposta - da folha para a raiz. Este método é mais simples e rápido.
Se o oponente tiver 1 unidade de vida, você pode encontrar um plano para "causar 1 ou mais unidades de dano". Para conseguir isso, várias condições devem ser atendidas:
1. O dano pode ser causado por um feitiço - ele deve estar na mão.
2. Para lançar um feitiço, você precisa de mana.
3. Para obter mana, você precisa jogar uma carta de terreno.
4. Para jogar uma carta da terra - você precisa da sua mão.
Outra maneira é a melhor pesquisa em primeiro lugar. Em vez de percorrer todos os caminhos, escolhemos o mais adequado. Na maioria das vezes, esse método fornece um plano ideal sem custos desnecessários de pesquisa. A * é a forma da melhor primeira pesquisa - explorando as rotas mais promissoras desde o início, ele já pode encontrar o melhor caminho sem precisar verificar outras opções.
Uma opção interessante e cada vez mais popular para a melhor pesquisa pela primeira vez é a Pesquisa de Árvores em Monte Carlo. Em vez de adivinhar quais planos são melhores que outros ao escolher cada ação subsequente, o algoritmo seleciona sucessores aleatórios a cada passo até chegar ao fim (quando o plano levou à vitória ou derrota). Em seguida, o resultado final é usado para aumentar ou diminuir a classificação de peso das opções anteriores. Repetindo esse processo várias vezes seguidas, o algoritmo fornece uma boa estimativa de qual próximo passo é melhor, mesmo que a situação mude (se o oponente tomar medidas para impedir o jogador).
A história sobre o planejamento em jogos não ficará sem o Planejamento de ações orientadas a objetivos ou o GOAP (planejamento de ações orientadas a objetivos). Este é um método amplamente utilizado e discutido, mas, além de alguns detalhes distintos, é essencialmente o método de encadeamento reverso sobre o qual falamos anteriormente. Se a tarefa era "destruir o jogador", e o jogador está escondido, o plano pode ser o seguinte: destruir com uma granada → obter → largar.
Geralmente, existem vários objetivos, cada um com sua própria prioridade. Se o objetivo com a maior prioridade não puder ser completado (nenhuma combinação de ações cria um plano para "destruir o jogador" porque o jogador não está visível), a IA retornará aos alvos com uma prioridade mais baixa.
Treinamento e adaptação
Já dissemos que a IA de jogos geralmente não usa aprendizado de máquina porque não é adequada para gerenciar agentes em tempo real. Mas isso não significa que você não possa emprestar nada dessa área. Queremos um adversário assim em um jogo de tiro com o qual possamos aprender alguma coisa. Por exemplo, descubra as melhores posições no mapa. Ou um adversário em um jogo de luta que bloqueia truques de combinação frequentemente usados pelo jogador, motivando outros a usar. Portanto, o aprendizado de máquina nessas situações pode ser muito útil.
Estatística e Probabilidades
Antes de passarmos a exemplos complexos, estimaremos até onde podemos chegar, tomando algumas medidas simples e usando-as para tomar decisões. Por exemplo, uma estratégia em tempo real - como podemos determinar se um jogador pode lançar um ataque nos primeiros minutos de um jogo e que defesa deve ser preparada contra isso? Podemos estudar a experiência passada do jogador para entender qual será a reação futura. Para começar, não temos esses dados iniciais, mas podemos coletá-los - sempre que a IA é jogada contra uma pessoa, ele pode registrar a hora do primeiro ataque. Após várias sessões, obteremos o tempo médio pelo qual o jogador atacará no futuro.
Os valores médios têm um problema: se um jogador “decide” 20 vezes e joga lentamente 20 vezes, então os valores necessários estarão em algum lugar no meio, e isso não nos dará nada de útil. Uma solução é limitar a entrada - você pode considerar as últimas 20 partes.
Uma abordagem semelhante é usada para avaliar a probabilidade de certas ações, assumindo que as preferências passadas do jogador serão as mesmas no futuro. Se um jogador nos atacar cinco vezes com uma bola de fogo, duas vezes com raios e uma vez com combate corpo a corpo, é óbvio que ele prefere uma bola de fogo. Extrapolamos e vemos a probabilidade de usar várias armas: bola de fogo = 62,5%, raio = 25% e corpo a corpo = 12,5%. Nosso jogo AI precisa se preparar para proteção contra incêndio.
Outro método interessante é usar o Naive Bayes Classifier (classificador bayesiano ingênuo) para estudar grandes volumes de dados de entrada e classificar a situação para que a IA responda da maneira correta. Os classificadores bayesianos são mais conhecidos por usar filtros de spam de e-mail. Lá, eles pesquisam palavras, as comparam com o local onde essas palavras apareceram anteriormente (em spam ou não) e tiram conclusões sobre as cartas recebidas. Podemos fazer o mesmo, mesmo com menos entrada. Com base em todas as informações úteis que a IA vê (por exemplo, quais unidades inimigas são criadas, ou quais feitiços eles usam, ou que tecnologias exploraram) e o resultado final (guerra ou paz, "esmagar" ou defender etc.) - selecionaremos o comportamento de IA desejado.
Todos esses métodos de treinamento são suficientes, mas é aconselhável usá-los com base nos dados dos testes. A IA aprenderá como se adaptar às várias estratégias usadas pelos testadores de jogo. Uma IA que se adapta a um jogador após um lançamento pode se tornar muito previsível ou vice-versa, muito complexa para vencer.
Adaptação Baseada em Valor
Dado o conteúdo do nosso mundo de jogo e as regras, podemos alterar o conjunto de valores que afetam a tomada de decisão, e não apenas usar os dados de entrada. Fazemos isso:
- Deixe a IA coletar dados sobre o estado do mundo e os principais eventos durante o jogo (como indicado acima).
- Vamos mudar alguns valores importantes com base nesses dados.
- Realizamos nossas decisões com base no processamento ou avaliação desses valores.
Por exemplo, um agente tem várias salas para escolher um atirador em primeira pessoa no mapa. Cada quarto tem seu próprio valor, que determina o quanto é desejável visitar. A IA escolhe aleatoriamente qual o espaço a seguir, com base no valor do valor. Em seguida, o agente se lembra em qual quarto ele foi morto e reduz seu valor (a probabilidade de ele voltar para lá). Da mesma forma para a situação inversa - se o agente destruir muitos oponentes, o valor da sala aumentará.
Modelo de Markov
E se usarmos os dados coletados para previsão? Se lembrarmos de cada sala em que vemos o jogador por um determinado período de tempo, preveremos em qual sala o jogador poderá entrar. Ao rastrear e registrar o movimento do jogador nas salas (valores), podemos prever.
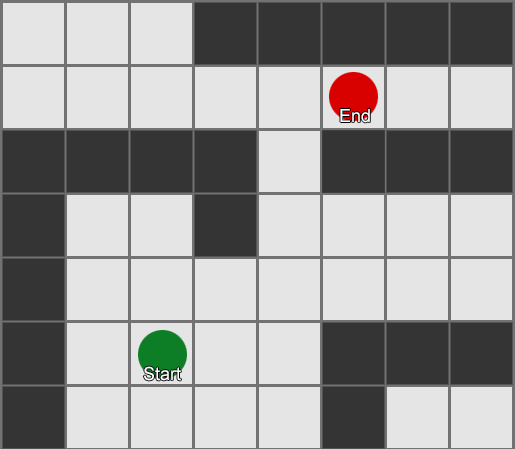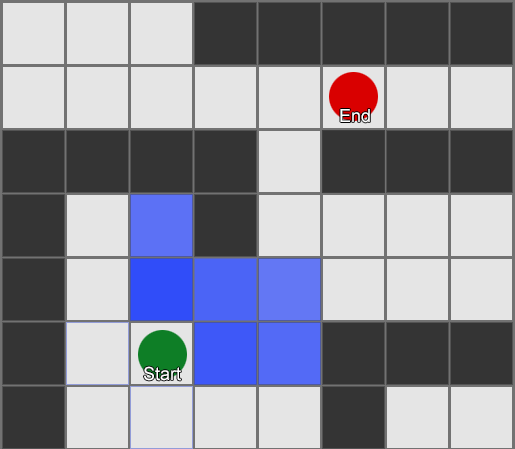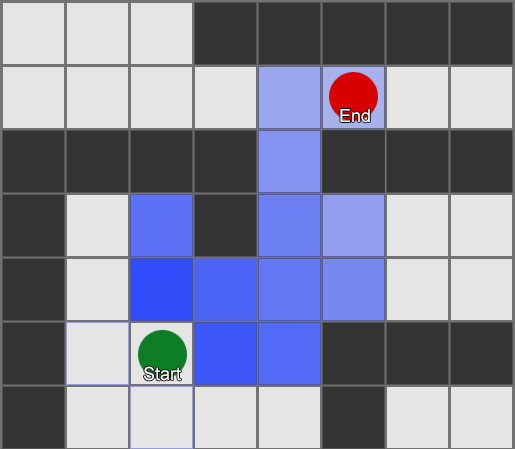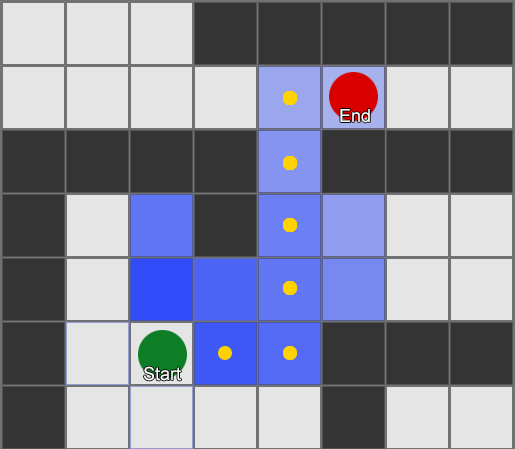
Vamos pegar três quartos: vermelho, verde e azul. Assim como as observações que registramos ao assistir a uma sessão de jogo:
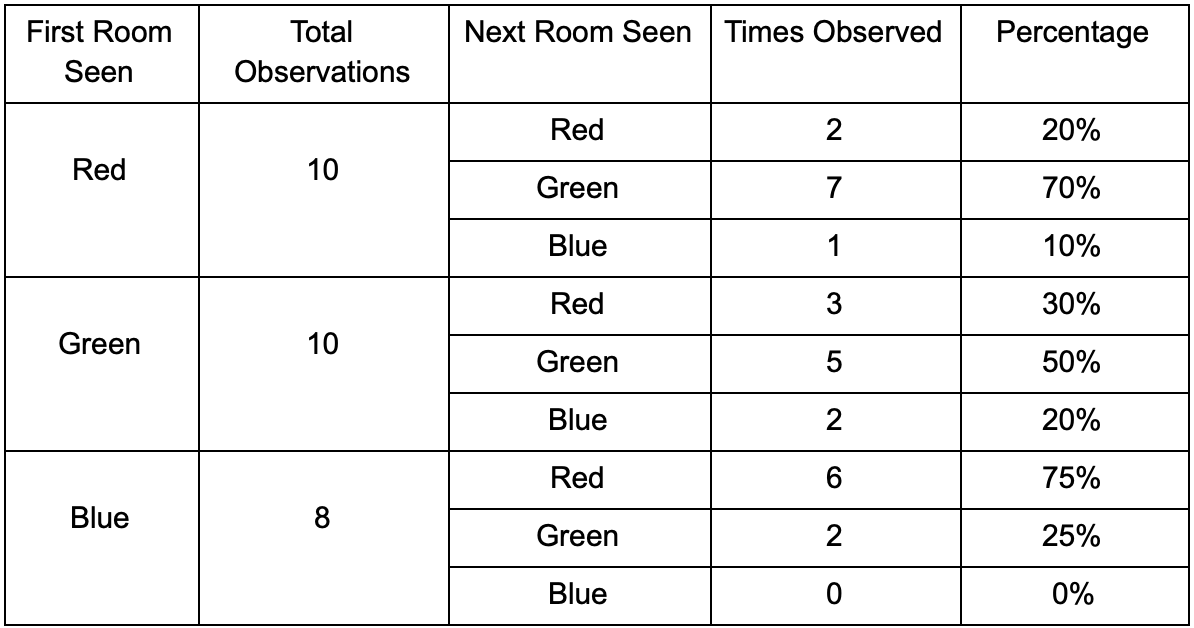
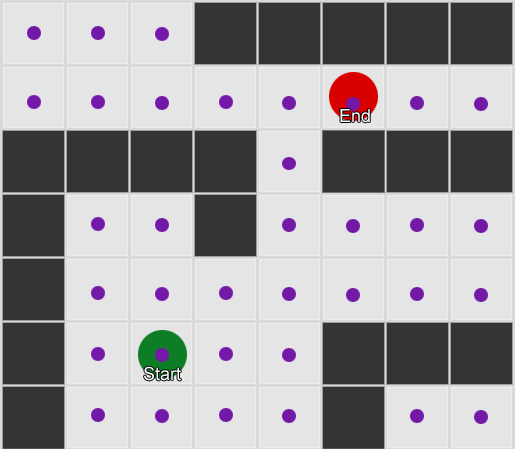
O número de observações para cada sala é quase igual - ainda não sabemos onde fazer um bom lugar para uma emboscada. A coleta de estatísticas também é complicada pelo reaparecimento de jogadores que aparecem uniformemente ao longo do mapa. Mas os dados na próxima sala, que eles inserem após aparecerem no mapa, já são úteis.
Pode-se ver que a sala verde combina com os jogadores - a maioria das pessoas de vermelho vai para ela, 50% das quais permanece lá e além. A sala azul, pelo contrário, não é popular, quase nunca é visitada e, se for, não permanece.
Mas os dados nos dizem algo mais importante - quando o jogador está na sala azul, a próxima sala em que provavelmente o veremos ficará vermelha, não verde. Apesar do fato de a sala verde ser mais popular que a vermelha, a situação muda se o jogador estiver em azul. O próximo estado (ou seja, a sala em que o jogador entrará) depende do estado anterior (ou seja, a sala em que o jogador está agora). Devido ao estudo das dependências, faremos previsões com mais precisão do que se simplesmente calculássemos as observações independentemente uma da outra.
A previsão de um estado futuro com base em dados de estados passados é chamada de modelo de Markov, e esses exemplos (com salas) são chamados de cadeias de Markov. Como os modelos representam a probabilidade de alterações entre estados sucessivos, eles são exibidos visualmente como FSMs com uma probabilidade próxima a cada transição. Anteriormente, usamos o FSM para representar o estado comportamental em que o agente estava localizado, mas esse conceito se aplica a qualquer estado, independentemente de estar ou não relacionado ao agente. Nesse caso, os estados representam a sala ocupada pelo agente:
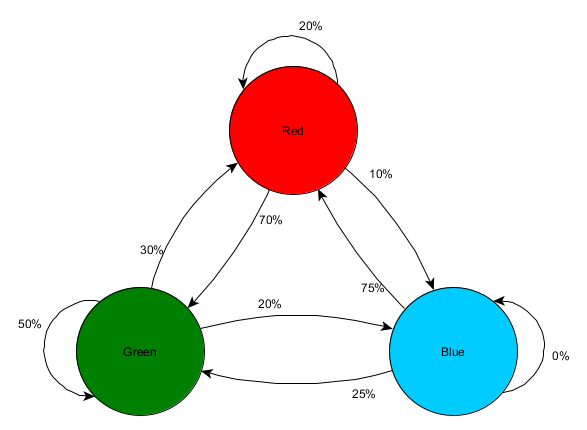
Esta é uma versão simples da representação da probabilidade relativa de alterações nos estados, dando à AI alguma oportunidade de prever o próximo estado. Você pode prever alguns passos à frente.
Se o jogador estiver na sala verde, há 50% de chance de ele permanecer lá durante a próxima observação. Mas qual é a probabilidade de ele ainda estar lá, mesmo depois? Não há apenas uma chance de o jogador permanecer na sala verde após duas observações, mas também a chance de ele sair e retornar. Aqui está a nova tabela com os novos dados:
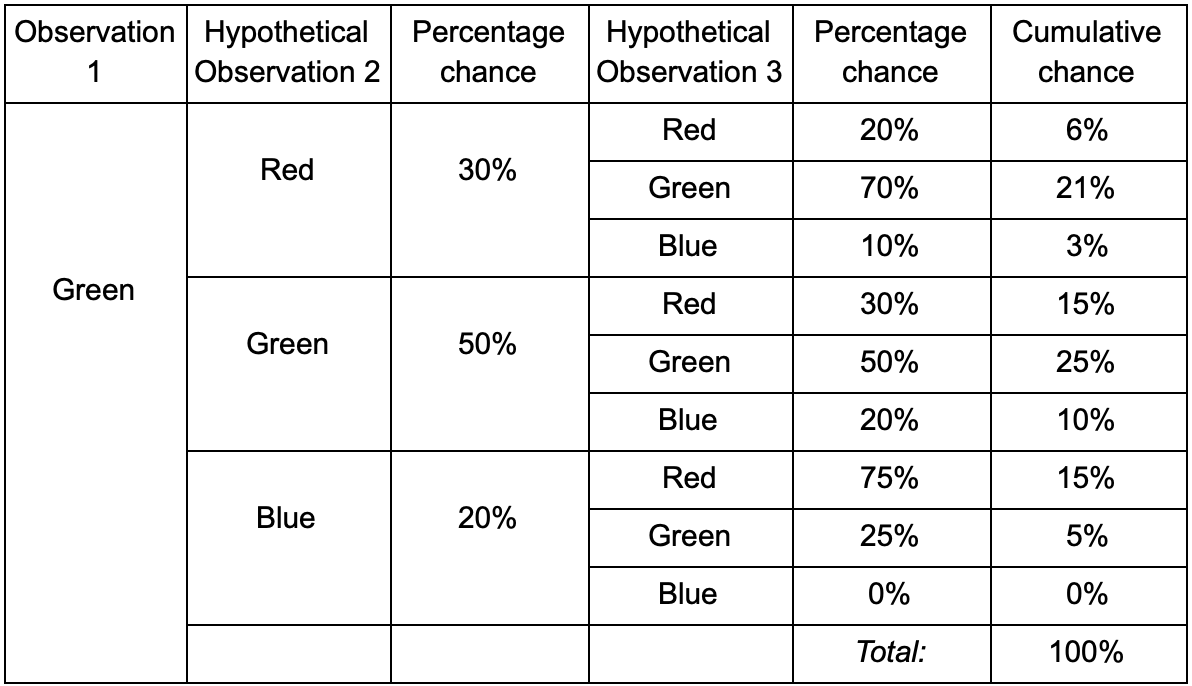
Isso mostra que a chance de ver um jogador na sala verde após duas observações será de 51% a 21%, de que ele virá da sala vermelha, 5% deles, que o jogador visitará a sala azul entre eles e 25%, que o jogador não vê vai sair da sala verde.
Uma tabela é apenas uma ferramenta visual - um procedimento requer apenas uma multiplicação de probabilidades em cada etapa. Isso significa que você pode olhar para o futuro com uma alteração: assumimos que a chance de entrar em uma sala depende completamente da sala atual. Isso é chamado de Propriedade Markov - o estado futuro depende apenas do presente. Mas isso não é completamente preciso. Os jogadores podem tomar decisões dependendo de outros fatores: nível de saúde ou quantidade de munição. Como não fixamos esses valores, nossas previsões serão menos precisas.
N-gramas
- ? ! , , -.
— (, Kick, Punch Block) . , Kick, Kick, Punch, SuperDeathFist, , .
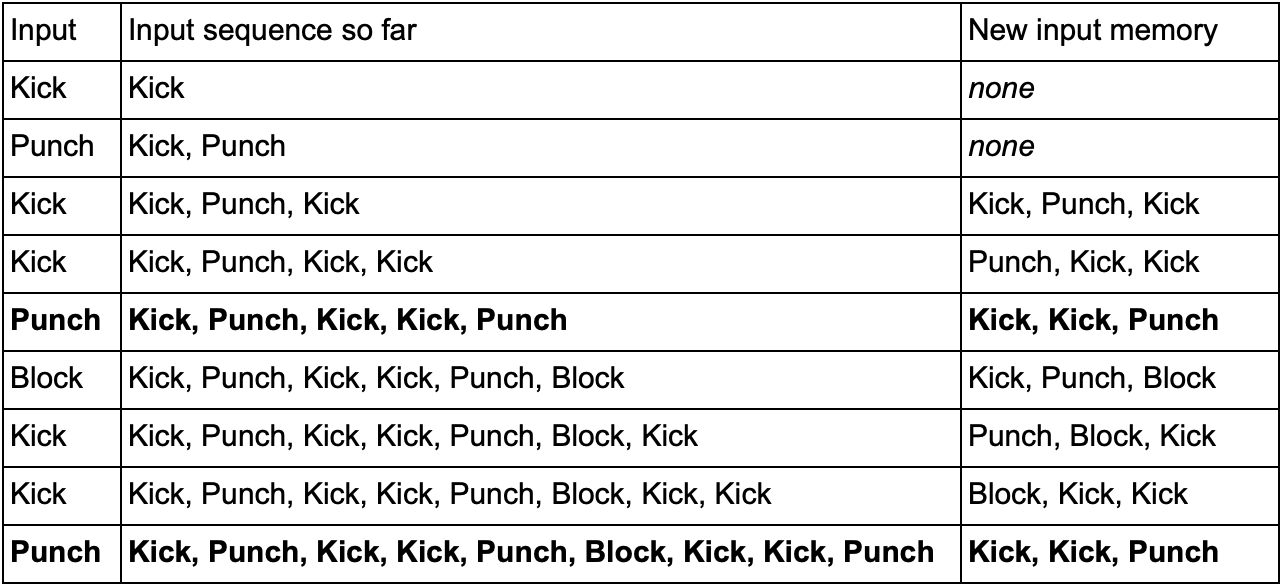
( , SuperDeathFist.)
, Kick, Kick, , Punch. - SuperDeathFist , .
N- (N-grams), N — . 3- (), : . 5- .
N-. N , . , 2- () Kick, Kick Kick, Punch, Kick, Kick, Punch, SuperDeathFist.
, , . Kick, Punch Block, 10-, 60 .
— « / » , . 3- N- , ( N-) , — . Kick Kick Kick Punch. , , , . , , - .
Conclusão
. , .
. , , . , :
- , ,
- / (minimax alpha-beta pruning)
- (, )
- ( , )
- ( )
- ( , anytime, timeslicing)
- :
1. GameDev.net
,
.
2.
AiGameDev.com .
3.
The GDC Vault GDC AI, .
4.
AI Game Programmers Guild .
5. , , YouTube-
AI and Games .
:
1. Game AI Pro , , .
Game AI Pro: Collected Wisdom of Game AI ProfessionalsGame AI Pro 2: Collected Wisdom of Game AI ProfessionalsGame AI Pro 3: Collected Wisdom of Game AI Professionals2. AI Game Programming Wisdom — Game AI Pro. , .
AI Game Programming Wisdom 1AI Game Programming Wisdom 2AI Game Programming Wisdom 3AI Game Programming Wisdom 43.
Artificial Intelligence: A Modern Approach — . — .