As postagens anteriores no blog corporativo não continham uma única equipe de console e decidimos nos atualizar.
Nossa empresa possui uma métrica projetada para evitar grandes falhas na hospedagem compartilhada. Em cada servidor de hospedagem compartilhada, há um site de teste no WordPress, que é acessado periodicamente.
É assim que o site de teste fica em cada servidor de hospedagem compartilhado
A velocidade e o sucesso da resposta do site são medidos. Qualquer funcionário da empresa pode olhar para as estatísticas gerais e ver o desempenho da empresa. Pode ver a porcentagem de respostas bem-sucedidas de um site de teste para toda a hospedagem ou para um servidor específico. Não é necessário ser funcionário da empresa - no painel de controle, os clientes também veem estatísticas no servidor em que sua conta está localizada.
Chamamos essa métrica de tempo de atividade (a porcentagem de respostas bem-sucedidas do site de teste para todas as solicitações ao site de teste). Não é um nome muito bom, é fácil confundi-lo com tempo de atividade , que é o tempo total após a última reinicialização do servidor .
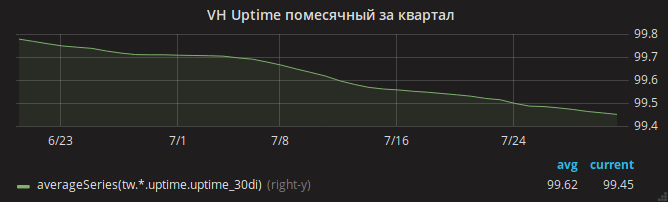
O verão passou e a programação do tempo de atividade diminuiu lentamente.
Os administradores identificaram imediatamente o motivo - falta de RAM. Era fácil ver casos de OOM nos logs quando o servidor ficou sem memória e o kernel eliminou o nginx.
O chefe do departamento, Andrei, pela mão de um assistente, divide uma tarefa em várias e as paralela a diferentes administradores. Vamos analisar as configurações do Apache - talvez as configurações não sejam ótimas e com muito tráfego, o Apache use toda a memória? Outro analisa o consumo de memória mysqld - de repente, existem configurações desatualizadas desde o momento em que a hospedagem compartilhada usou o Gentoo OS? O terceiro analisa as alterações recentes nas configurações do nginx.
Um por um, os administradores retornam com resultados. Cada um conseguiu reduzir o consumo de memória na área atribuída a ele. No caso do nginx, por exemplo, um mod_security incluído, mas não usado, foi detectado. OOM, enquanto isso, também é frequente.
Por fim, é possível notar que o consumo de memória principal (em particular, SUnreclaim) é muito grande em alguns servidores. Nem na saída ps nem no htop esse parâmetro é visível, então não o notamos imediatamente! Exemplo de servidor com SUnreclaim infernal:
root@vh28.timeweb.ru:~
24 gigabytes de RAM são dados ao kernel, eo kernel os gasta para que ninguém saiba o que!
O administrador (vamos chamá-lo de Gabriel) corre para a batalha. Remonta o kernel com as opções KMEMLEAK para detecção de vazamentos.
Opções para reconstruirPara ativar o KMEMLEAK, basta especificar as opções listadas abaixo e carregar o kernel com o parâmetro kmemleak = on.
CONFIG_HAVE_DEBUG_KMEMLEAK=y CONFIG_DEBUG_KMEMLEAK=y CONFIG_DEBUG_KMEMLEAK_DEFAULT_OFF=y CONFIG_DEBUG_KMEMLEAK_EARLY_LOG_SIZE=10000
O KMEMLEAK escreve (em /sys/kernel/debug/kmemleak ) estas linhas:
unreferenced object 0xffff88013a028228 (size 8): comm "apache2", pid 23254, jiffies 4346187846 (age 1436.284s) hex dump (first 8 bytes): 00 00 00 00 00 00 00 00 ........ backtrace: [<ffffffff818570c8>] kmemleak_alloc+0x28/0x50 [<ffffffff811d450a>] kmem_cache_alloc_trace+0xca/0x1d0 [<ffffffff8136dcc3>] apparmor_file_alloc_security+0x23/0x40 [<ffffffff81332d63>] security_file_alloc+0x33/0x50 [<ffffffff811f8013>] get_empty_filp+0x93/0x1c0 [<ffffffff811f815b>] alloc_file+0x1b/0xa0 [<ffffffff81728361>] sock_alloc_file+0x91/0x120 [<ffffffff8172b52e>] SyS_socket+0x7e/0xc0 [<ffffffff81003854>] do_syscall_64+0x54/0xc0 [<ffffffff818618ab>] return_from_SYSCALL_64+0x0/0x6a [<ffffffffffffffff>] 0xffffffffffffffff unreferenced object 0xffff880d67030280 (size 624): comm "hrrb", pid 23713, jiffies 4346190262 (age 1426.620s) hex dump (first 32 bytes): 01 00 00 00 03 00 ff ff 00 00 00 00 00 00 00 00 ................ 00 e7 1a 06 10 88 ff ff 00 81 76 6e 00 88 ff ff ..........vn.... backtrace: [<ffffffff818570c8>] kmemleak_alloc+0x28/0x50 [<ffffffff811d4337>] kmem_cache_alloc+0xc7/0x1d0 [<ffffffff8172a25d>] sock_alloc_inode+0x1d/0xc0 [<ffffffff8121082d>] alloc_inode+0x1d/0x90 [<ffffffff81212b01>] new_inode_pseudo+0x11/0x60 [<ffffffff8172952a>] sock_alloc+0x1a/0x80 [<ffffffff81729aef>] __sock_create+0x7f/0x220 [<ffffffff8172b502>] SyS_socket+0x52/0xc0 [<ffffffff81003854>] do_syscall_64+0x54/0xc0 [<ffffffff818618ab>] return_from_SYSCALL_64+0x0/0x6a [<ffffffffffffffff>] 0xffffffffffffffff
Gabriel não revelou todos os seus segredos para nós e não contou como, pelas linhas acima, descobriu a causa exata do vazamento de memória. Provavelmente, ele usou o addr2line /usr/lib/debug/lib/modules/`uname -r`/vmlinux ffffffff81722361 para encontrar a linha exata. Ou apenas abriu o net/socket.c e olhou para ele até que o arquivo se tornasse desconfortável.
O problema acabou sendo um patch no net/socket.c , que foi adicionado ao nosso repositório há muitos anos. Seu objetivo é proibir que os clientes usem a chamada de sistema bind (); essa é uma proteção simples contra o servidor proxy iniciando pelos clientes. O patch cumpriu seu objetivo, mas não limpou a memória depois de si próprio.
Talvez houvesse um novo malware na moda no PHP que tentasse executar um servidor proxy em loop - o que levou a centenas de milhares de chamadas de bind () bloqueadas e perda de gigabytes de RAM.
Então foi simples - Gabriel consertou o patch e reconstruiu o kernel. Adicionado monitoramento do valor de SUnreclaim em todos os servidores executando o Linux. Os engenheiros alertaram os clientes e reiniciaram a hospedagem no novo núcleo.
OOM desapareceu.
Mas o problema com a disponibilidade dos sites permaneceu
Em todos os servidores, o site de teste parou de responder várias vezes ao dia.
Aqui, o autor começaria a arrancar cabelos em diferentes partes do corpo. Mas Gabriel permaneceu calmo e ligou a gravação de tráfego para partes dos servidores de hospedagem.
No despejo de tráfego, observou-se que, na maioria das vezes, a solicitação para o site de teste cai após o recebimento repentino de um pacote TCP RST . Em outras palavras, a solicitação chegou ao servidor, mas a conexão acabou sendo interrompida pelo nginx.
Ainda mais interessante! O utilitário strace iniciado por Gabriel mostra que o daemon nginx não está enviando este pacote. Como pode ser isso, porque apenas o nginx está escutando na porta 80?
O motivo foi uma combinação de vários fatores:
- nas configurações nginx, a opção
reuseport é reuseport (incluindo a SO_REUSEPORT soquete SO_REUSEPORT ), que permite que diferentes processos aceitem conexões no mesmo endereço e porta - na versão (na época, a mais nova) do nginx 1.13.0, ocorreu um erro devido ao qual, ao iniciar o teste de configuração do nginx via
nginx -t e usando a SO_REUSEPORT esse processo de teste do nginx realmente começou a ouvir a porta 80 e a interceptar solicitações de clientes reais . E no final do processo de teste de configuração, os clientes receberam Connection reset by peer - finalmente, no monitoramento do zabbix, o monitoramento da correção da configuração do nginx foi configurado em todos os servidores com o nginx instalado: o comando
nginx -t foi chamado neles uma vez por minuto.
Somente após a atualização do nginx você pode expirar calmamente. O gráfico de tempo de atividade dos sites aumentou.
Qual é a moral de toda essa história? Seja otimista e evite usar kernels auto-montados.