Manter uma enorme base de código e garantir alta produtividade para um grande número de desenvolvedores é um sério desafio. Nos últimos 5 anos, a Yandex desenvolveu um sistema especial para integração contínua. Neste artigo, falaremos sobre a escala da base de código Yandex, sobre a transferência de desenvolvimento para um único repositório com uma abordagem de desenvolvimento baseada em tronco, sobre quais tarefas um sistema de integração contínua deve resolver para funcionar efetivamente nessas condições.

Muitos anos atrás, a Yandex não tinha regras especiais no desenvolvimento de serviços: cada departamento poderia usar qualquer idioma, tecnologia ou sistema de implantação. E, como a prática demonstrou, essa liberdade nem sempre ajudou a avançar mais rapidamente. Naquela época, para resolver os mesmos problemas, muitas vezes havia vários desenvolvimentos proprietários ou de código aberto. À medida que a empresa crescia, esse ecossistema funcionava pior. Ao mesmo tempo, queríamos continuar sendo um grande Yandex, e não dividir em muitas empresas independentes, porque isso oferece muitas vantagens: muitas pessoas fazem as mesmas tarefas, os resultados de seu trabalho podem ser reutilizados. Começando com uma variedade de estruturas de dados, como tabelas de hash distribuídas e filas sem bloqueio, e terminando com muitos códigos especializados diferentes que escrevemos ao longo de 20 anos.
Muitas das tarefas que resolvemos não resolvem no mundo de código aberto. Não há MapReduce que funcione bem em nossos volumes (mais de 5000 servidores) e em nossas tarefas; não há rastreador de tarefas que possa lidar com todas as dezenas de milhões de tickets. Isso é atraente no Yandex - você pode fazer grandes coisas.
Mas estamos seriamente perdendo eficiência quando resolvemos os mesmos problemas novamente, refazemos soluções prontas, dificultando a integração entre os componentes. É bom e conveniente fazer tudo apenas para você no seu próprio canto, você não pode pensar nos outros por enquanto. Mas assim que o serviço se tornar perceptível o suficiente, ele terá dependências. Parece que vários serviços são fracamente dependentes um do outro, de fato - existem muitas conexões entre diferentes partes da empresa. Muitos serviços estão disponíveis no aplicativo Yandex / Navegador / etc. ou são incorporados um ao outro. Por exemplo, Alice aparece no Navegador. Usando Alice, você pode pedir um táxi. Todos nós usamos componentes comuns: YT , YQL , Nirvana .
O antigo modelo de desenvolvimento apresentava problemas significativos. Devido à presença de muitos repositórios, é difícil para um desenvolvedor comum, especialmente um iniciante, descobrir:
- onde está o componente?
- como funciona: não há como "pegar e ler"
- Quem está desenvolvendo e apoiando isso agora?
- como começar a usá-lo?
Como resultado, surgiu o problema do uso mútuo de componentes. Os componentes quase não podiam usar outros componentes porque representavam "caixas pretas" um para o outro. Isso afetou negativamente a empresa, pois os componentes não foram apenas reutilizados, mas muitas vezes não melhoraram. Muitos componentes foram duplicados, a quantidade de código que precisava ser suportada estava crescendo significativamente. Geralmente, nos movíamos mais devagar do que podíamos.
Repositório e infraestrutura únicos
Há cinco anos, iniciamos um projeto para transferir o desenvolvimento para um único repositório, com sistemas comuns para montagem, teste, implantação e monitoramento.
O principal objetivo que queríamos alcançar era remover os obstáculos que impedem a integração do código de outra pessoa. O sistema deve fornecer acesso fácil ao código de trabalho finalizado, um esquema claro para sua conexão e uso, capacidade de coleta: os projetos são sempre coletados (e passam nos testes).
Como resultado do projeto, surgiu uma única pilha de tecnologias de infraestrutura para a empresa: armazenamento de código-fonte, sistema de revisão de código, sistema de compilação, sistema de integração contínua, implantação e monitoramento.
Agora, a maior parte do código fonte dos projetos Yandex está armazenada em um único repositório ou está em processo de mudança para ele:
- Mais de 2000 desenvolvedores trabalham em projetos.
- mais de 50.000 projetos e bibliotecas.
- O tamanho do repositório excede 25 GB.
- Mais de 3.000.000 de confirmações já foram confirmadas no repositório.
Vantagens para a empresa:
- qualquer projeto do repositório recebe uma infraestrutura pronta:
- um sistema para visualizar e navegar no código fonte e um sistema de revisão de código.
- sistema de montagem e montagem distribuída. Este é um grande tópico separado, e nós o abordaremos definitivamente nos seguintes artigos.
- sistema de integração contínua.
- implantação, integração com o sistema de monitoramento.
- compartilhamento de código, interação ativa da equipe.
- Como todo o código é comum, você pode acessar outro projeto e fazer as alterações necessárias lá. Isso é especialmente importante em uma empresa grande, porque outra equipe da qual você precisa de algo pode não ter os recursos. Com o código comum, você tem a oportunidade de fazer parte do trabalho e "ajudar a acontecer" as alterações necessárias.
- Há uma oportunidade de realizar refatoração global. Você não precisa oferecer suporte a versões antigas da sua API ou biblioteca, pode alterá-las e alterar os locais onde elas são usadas em outros projetos.
- o código se torna menos "diverso". Você tem um conjunto de maneiras de resolver problemas e não há necessidade de adicionar outra maneira que faça o mesmo, mas com pequenas diferenças.
- no projeto ao seu lado, provavelmente, não haverá linguagens e bibliotecas absolutamente exóticas.
Também deve ser entendido que esse modelo de desenvolvimento tem desvantagens que precisam ser consideradas:
- Um repositório compartilhado requer uma infraestrutura específica separada.
- a biblioteca que você precisa pode não estar no repositório, mas está em código aberto. Existem custos para adicionar e atualizar. Muito dependente da linguagem e da biblioteca, em algum lugar quase gratuito, em algum lugar muito caro.
- você precisa trabalhar constantemente na "saúde" do código. Isso inclui pelo menos a luta contra dependências desnecessárias e código morto.
Nossa abordagem para um repositório comum impõe regras gerais que todos precisam seguir. No caso de usar um único repositório, restrições são impostas aos idiomas usados, bibliotecas e métodos de implantação. Mas no projeto vizinho tudo será igual ou muito parecido com o seu, e você pode até consertar algo lá.
O modelo de um repositório comum gravita para todas as grandes empresas. O repositório monolítico é um tópico amplo e bem estudado e discutido; portanto, agora não vamos entrar muito nele. Se você quiser saber mais, no final do artigo você encontrará vários links úteis que revelam esse tópico com mais detalhes.
Condições em que o sistema de integração contínua opera
O desenvolvimento é realizado de acordo com o modelo de desenvolvimento baseado em tronco. A maioria dos usuários trabalha com HEAD, ou a cópia mais recente do repositório, obtida no ramo principal chamado tronco, no qual o desenvolvimento está em andamento. A confirmação de alterações no repositório é feita sequencialmente. Imediatamente após a confirmação, o novo código fica visível e pode ser usado por todos os desenvolvedores. O desenvolvimento em ramificações separadas não é incentivado, embora as ramificações possam ser usadas para liberações.
Os projetos dependem do código fonte. Projetos e bibliotecas formam um gráfico de dependência complexo. E isso significa que as alterações feitas em um projeto afetam potencialmente o restante do repositório.
Um grande fluxo de confirmações vai para o repositório:
- mais de 2000 confirmações por dia.
- até 10 alterações por minuto durante o horário de pico.
A base de código contém mais de 500.000 destinos e testes de construção.
Sem um sistema especial de integração contínua em tais condições, seria muito difícil avançar rapidamente.
Sistema de integração contínua
O sistema de integração contínua lança montagens e testes para cada alteração:
- Verificações preliminares. Eles permitem verificar o código antes de confirmar e evitar a quebra de testes no porta-malas. Montagens e testes são executados em cima do HEAD. No momento, as verificações pré-auditoria são iniciadas voluntariamente. Para projetos críticos, são necessárias verificações pré-auditoria.
- Verificações pós-confirmação após confirmação no repositório.
Construções e testes são executados em paralelo em grandes clusters de centenas de servidores. Construções e testes executados em plataformas diferentes. Sob a plataforma principal (linux), todos os projetos são montados e todos os testes são executados sob as outras plataformas - um subconjunto dos configuráveis pelo usuário.
Após receber e analisar os resultados de montagens e executar os testes, o usuário recebe feedback, por exemplo, se as alterações quebrarem os testes.

No caso de novas falhas ou testes de montagem, enviamos uma notificação aos proprietários do teste e ao autor das alterações. O sistema também armazena e exibe os resultados das verificações em uma interface especial. A interface da web do sistema de integração exibe o progresso e o resultado do teste, discriminados por tipo de teste. A tela com os resultados da verificação agora pode ter a seguinte aparência:
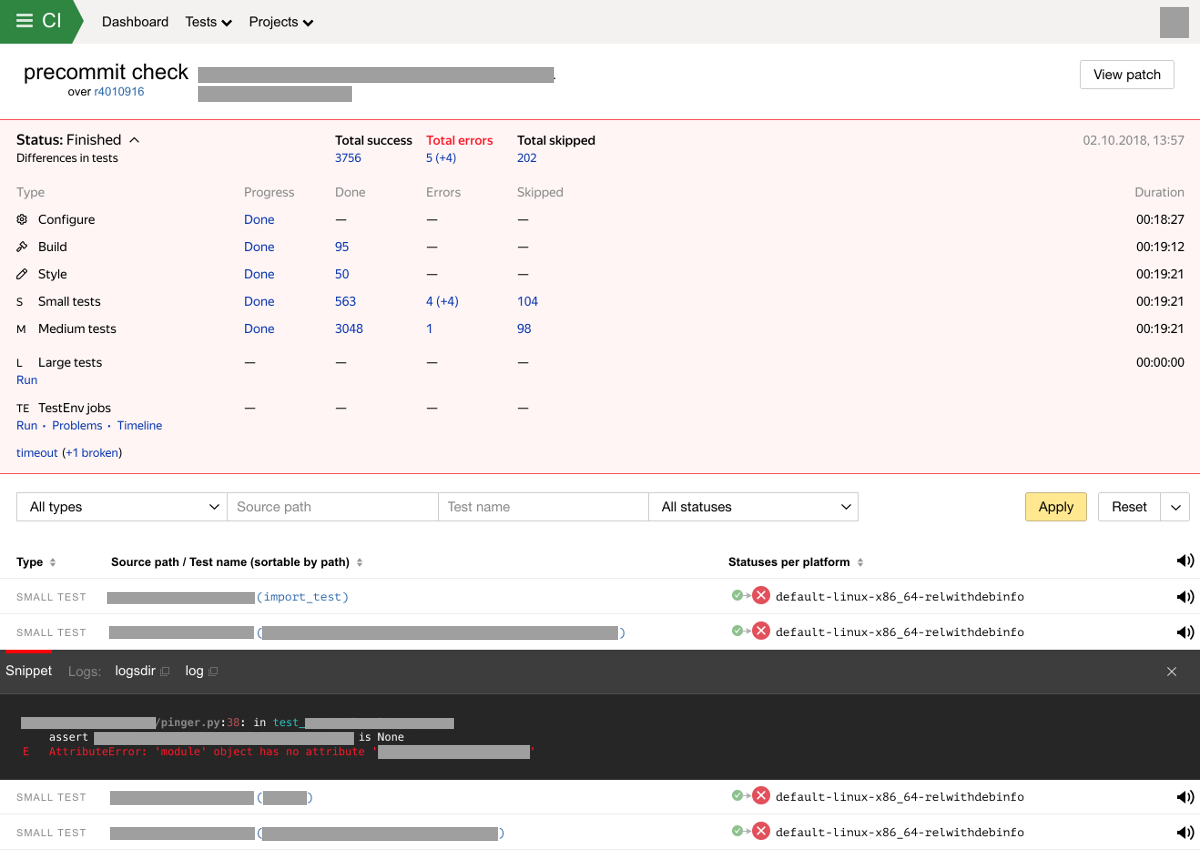
Recursos e capacidades do sistema de integração contínua
Resolvendo vários problemas enfrentados por desenvolvedores e testadores, desenvolvemos nosso sistema de integração contínua. O sistema já resolve muitos problemas, mas ainda há muito a melhorar.
Tipos e tamanhos de testes
Existem vários tipos de objetivos que um sistema de integração contínua pode desencadear:
- configurar. A fase de configuração executada pelo sistema de construção. A configuração inclui uma análise dos arquivos de configuração do sistema de montagem, determinando as dependências entre os projetos e os parâmetros da montagem e executando os testes.
- construir. Montagem de bibliotecas e projetos.
- estilo. Nesta fase, o estilo do código corresponde aos requisitos especificados.
- teste. Os testes são divididos em estágios de acordo com o tempo limite do tempo de trabalho e os requisitos de recursos de computação.
- pequeno. <1 min
- médio. <10 min
- grande. > 10 min Além disso, pode haver requisitos especiais para recursos de computação.
- extra grande. Este é um tipo especial de teste. Esses testes são caracterizados por um conjunto das seguintes características: um longo tempo de operação, um grande consumo de recursos, uma grande quantidade de dados de entrada, eles podem exigir acessos especiais e, o mais importante, suporte para os complexos cenários de teste descritos abaixo. Existem menos testes do que outros tipos de testes, mas são muito importantes.
Frequência de inicialização de teste e detecção de falhas binárias
Recursos enormes são alocados para teste no Yandex - centenas de servidores poderosos. Mas mesmo com um grande número de recursos, não podemos executar todos os testes para todas as alterações que os afetam. Mas, ao mesmo tempo, é muito importante para nós sempre ajudar o desenvolvedor a localizar o local onde o teste é interrompido, especialmente em um repositório tão grande.
O que estamos fazendo? Para cada alteração em todos os projetos afetados, são executadas montagens, verificações de estilo e testes com tamanhos pequenos e médios. O restante dos testes é executado não para todas as confirmações de influência, mas com uma certa periodicidade, se houver confirmações que afetem os testes. Em alguns casos, os usuários podem controlar a frequência de inicialização, em outros casos, a frequência de inicialização é definida pelo sistema. Quando uma falha de teste é detectada, o processo de procura por uma confirmação de quebra de teste é iniciado. Quanto menos vezes o teste é executado, mais procuramos uma confirmação de quebra após a detecção de uma falha.

Ao iniciar verificações pré-auditoria, também executamos apenas montagens e testes de luz. Em seguida, o usuário pode iniciar manualmente o lançamento de testes pesados, selecionando na lista de testes afetados pelas alterações fornecidas pelo sistema.
Detecção de teste intermitente
Testes intermitentes são testes cuja execução (Aprovada / Reprovada) no mesmo código pode depender de vários fatores. As causas dos testes intermitentes podem ser diferentes: suspensão no código de teste, erros ao trabalhar com multithreading, problemas de infraestrutura (indisponibilidade de qualquer sistema), etc. Os testes intermitentes apresentam um problema sério:
- Eles levam ao fato de que o sistema de integração contínua envia alertas falsos de spam sobre falhas de teste.
- Contaminar os resultados dos testes. Está se tornando mais difícil decidir sobre o sucesso dos resultados da verificação.
- Atraso nas versões do produto.
- Difícil de detectar. Os testes podem piscar muito raramente.
Os desenvolvedores podem ignorar testes intermitentes ao analisar os resultados. Às vezes incorreto.
É impossível eliminar completamente os testes intermitentes, isso deve ser levado em consideração em um sistema de integração contínua.
Atualmente, para cada teste, executamos todos os testes duas vezes para detectar testes intermitentes. Também levamos em conta as reclamações dos usuários (destinatários das notificações). Se detectarmos um piscar, marcamos o teste com uma bandeira especial (silenciado) e informamos o proprietário do teste. Depois disso, apenas os proprietários do teste receberão notificações de falhas no teste. Em seguida, continuamos a executar o teste no modo normal, enquanto analisamos o histórico de seus lançamentos. Se o teste não piscar em uma determinada janela de tempo, a automação pode decidir que o teste parou de piscar e você pode limpar o sinalizador.
Nosso algoritmo atual é bastante simples e muitas melhorias estão planejadas neste local. Antes de tudo, queremos usar sinais muito mais úteis.
Atualização automática da entrada de teste
Ao testar os sistemas Yandex mais complexos, além de outros métodos de teste, geralmente é usado o teste de estratégia de caixa preta + o teste orientado a dados . Para garantir uma boa cobertura, esses testes exigem um grande conjunto de dados de entrada. Os dados podem ser selecionados a partir de clusters de produção. Mas há um problema com o fato de os dados ficarem desatualizados rapidamente. O mundo não pára, nossos sistemas estão em constante evolução. Os dados de teste desatualizados ao longo do tempo não fornecerão uma boa cobertura de teste e, em seguida, levarão a uma falha no teste devido ao fato de os programas começarem a usar novos dados que não estão disponíveis nos dados de teste desatualizados.
Para que os dados não fiquem desatualizados, o sistema de integração contínua pode atualizá-los automaticamente. Como isso funciona?
- Os dados de teste são armazenados em um armazenamento especial de recursos.
- O teste contém metadados que descrevem a entrada necessária.
- A correspondência entre a entrada e os recursos de teste necessários é armazenada em um sistema de integração contínua.
- O desenvolvedor fornece entrega regular de dados atualizados para o armazenamento de recursos.
- O sistema de integração contínua procura novas versões dos dados de teste no repositório de recursos e alterna os dados de entrada.
É importante atualizar os dados para que o teste falso não ocorra. Você não pode simplesmente pegar e, a partir de uma certa confirmação, começar a usar novos dados, porque no caso de uma falha no teste, não ficará claro quem é o culpado - confirmar ou novos dados. Também tornará os testes diff (descritos abaixo) inoperantes.

Portanto, fazemos com que haja um pequeno intervalo de confirmações, no qual o teste é iniciado tanto com as versões antigas quanto com as novas versões dos dados de entrada.

Testes de diferença
Diff-tests chamamos de um tipo especial de testes orientados a dados , que diferem da abordagem geralmente aceita, na medida em que o teste não tem um resultado de referência, mas, ao mesmo tempo, precisamos descobrir no que confirma o teste que mudou seu comportamento.
A abordagem padrão no teste orientado a dados é a seguinte. O teste tem um resultado de referência obtido quando o teste foi executado pela primeira vez. O resultado da referência pode ser armazenado no repositório ao lado do teste. Execuções subsequentes do teste devem produzir o mesmo resultado.

Se o resultado diferir da referência, o desenvolvedor deve decidir se essa alteração ou erro esperado. Se a mudança for esperada, o desenvolvedor deve atualizar o resultado de referência ao mesmo tempo em que confirma as alterações no repositório.
Existem dificuldades ao usar essa abordagem em um repositório grande com grandes fluxos de confirmação:
- Pode haver muitos testes e os testes podem ser muito difíceis. O desenvolvedor não tem a capacidade de executar todos os testes afetados em um ambiente de trabalho.
- Após fazer as alterações, o teste poderá ser interrompido se o resultado de referência não tiver sido atualizado simultaneamente com as alterações no código. Em seguida, outro desenvolvedor pode fazer alterações no mesmo componente e o resultado do teste será alterado novamente. Temos a imposição de um erro em outro. É muito difícil lidar com esses problemas, leva tempo dos desenvolvedores.
O que estamos fazendo? Os testes de diferenças consistem em 2 partes:
- Verifique o componente.
- Iniciamos o teste e salvamos o resultado no armazenamento de recursos.
- Não compare o resultado com a referência.
- Podemos pegar alguns erros, por exemplo, o programa não inicia / não termina, trava, o programa não responde. A validação do resultado também pode ser realizada: a presença de qualquer campo na resposta, etc.
- Componente Diff.
- Compare os resultados obtidos em diferentes lançamentos e crie diferenças. No caso mais simples, esta é uma função que pega 2 parâmetros e retorna diff.
- A aparência do diff depende do teste, mas deve ser algo compreensível para alguém que examinará o diff. Normalmente, diff é um arquivo html.
O lançamento dos componentes check e diff é controlado por um sistema de integração contínua.

Se o sistema de integração contínua detectar diff, primeiro uma pesquisa binária será executada para a confirmação que causou a alteração. Após receber uma notificação do desenvolvedor, torna-se possível estudar o diff e decidir o que fazer a seguir: reconheça o diff como esperado (para isso, é necessário executar uma ação especial) ou repare / "reverta" suas alterações.
Para ser continuado
No próximo artigo , falaremos sobre como o sistema de integração contínua funciona.
Referências
Repositório monolítico, desenvolvimento baseado em tronco
Teste orientado a dados