Anteriormente, no Avito, era possível encontrar o produto certo usando a filtragem de palavras-chave ou a navegação em árvore de categorias. Esse método, embora parecesse familiar, nem sempre era conveniente - para encontrar um produto ou serviço, era necessário fazer um grande número de cliques. Mais de um ano atrás, ganhamos relevância, graças à qual a pesquisa se tornou melhor, e agora é mais fácil e conveniente encontrar um produto ou serviço, mesmo na página principal. Com essa inovação, mercadorias inadequadas e francamente “lixo” deixaram de cair na questão. E esta é apenas uma das etapas para melhorar sua pesquisa. Estamos mudando gradualmente a infraestrutura, o que nos permite trabalhar com mais intensidade na qualidade da pesquisa, melhorá-la mais rapidamente e lançar novos recursos que beneficiam vendedores e compradores no Avito.
No artigo, mostrarei como a pesquisa no Avito mudou: como começamos e agora estamos avançando no sentido de melhorar a vida de nossos usuários e compartilharemos nossas inovações tanto no produto quanto em seu preenchimento - a parte técnica. Não haverá carne hardcore aqui, mas espero que você goste.

Algumas notas introdutórias: Avito é o serviço de anúncios mais popular da Rússia. Temos mais de 450 mil anúncios por dia e o número mensal de visitantes únicos chega a 35 milhões, o que faz mais de 140 milhões de pesquisas por dia.
Cenário de pesquisa típico antes
Vejamos um exemplo simples de como uma pesquisa funcionou há mais de um ano. Suponha que você precise de um piano (bem, por que não?). Vamos para a página principal, digitamos "piano".
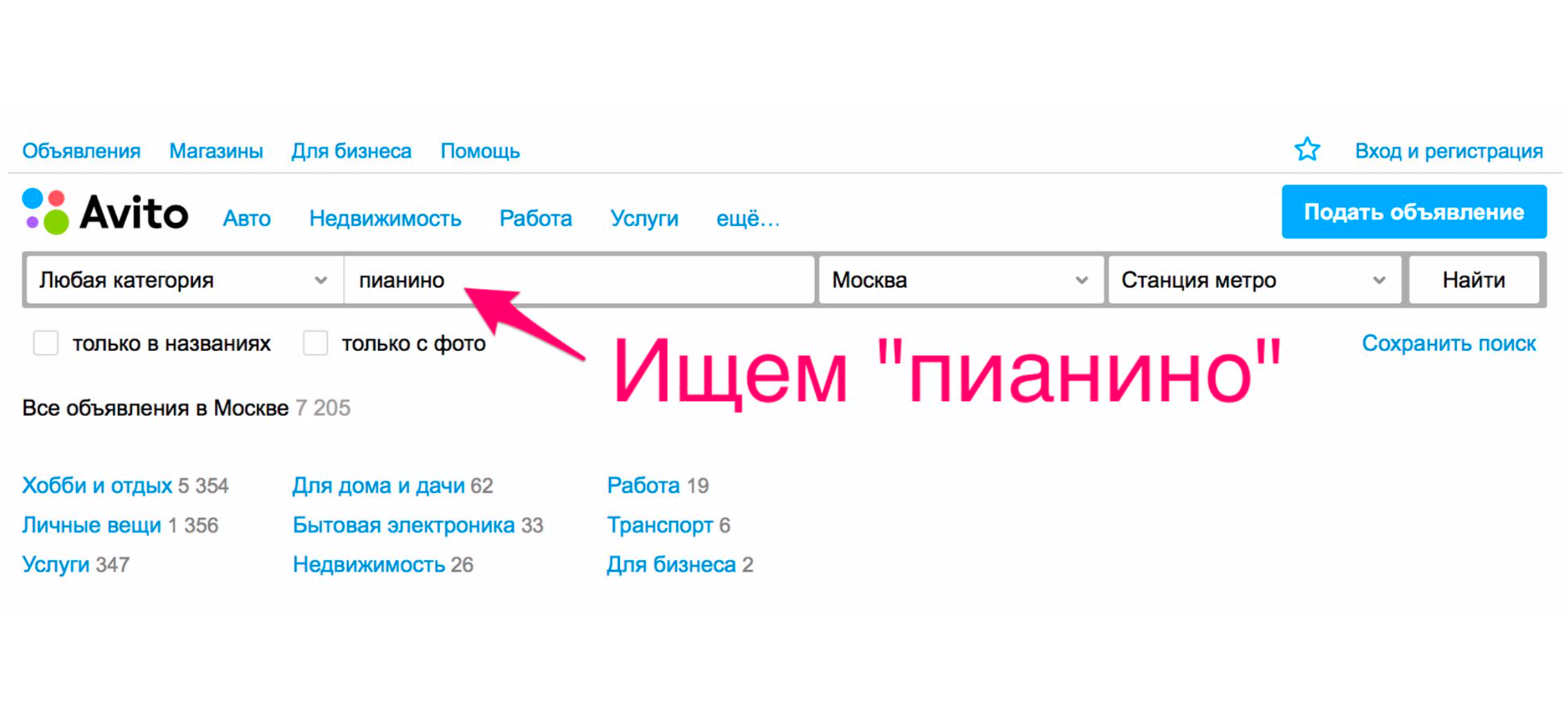
Na extradição, você provavelmente receberá motores, serviços de transporte para piano ou algo semelhante, mas não um instrumento musical.

Isso acontece porque teremos a classificação pela data da veiculação - e esses serviços são colocados com mais frequência.
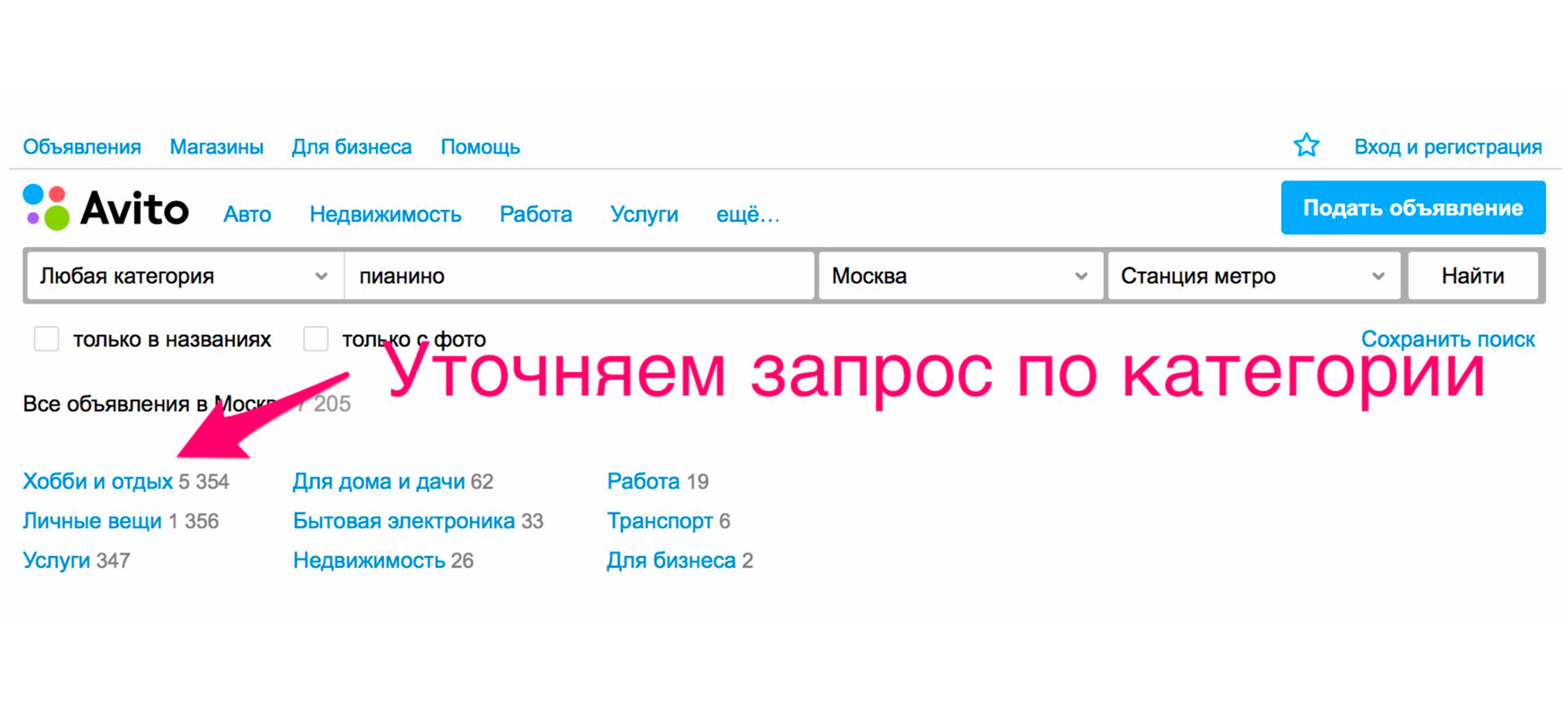
Para ver o piano, você precisa especificar a categoria. Clicamos no cabeçalho "Hobbies e lazer", descemos a árvore de categorias para "Instrumentos musicais" e, em seguida, "Instrumentos para teclado".
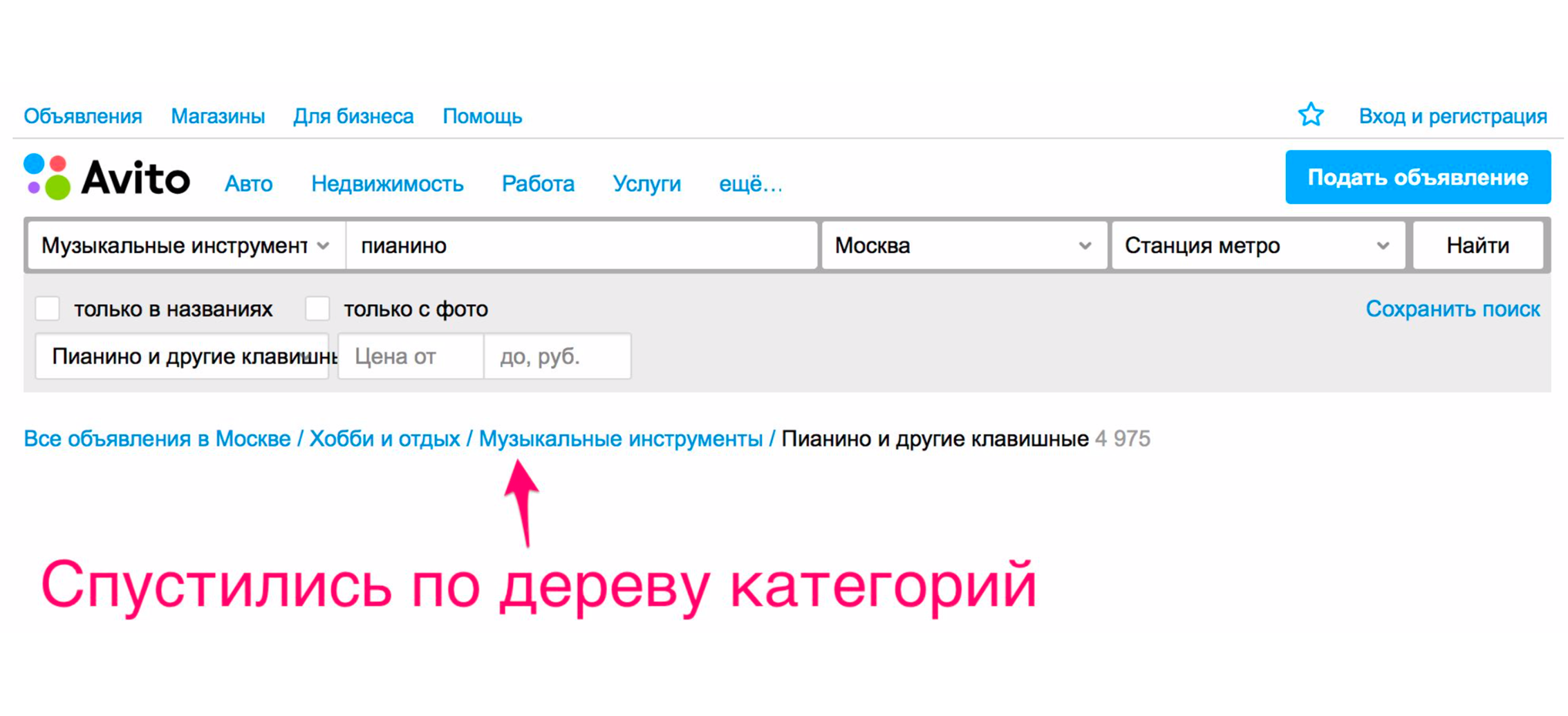
E somente depois disso vemos o piano que estávamos procurando.
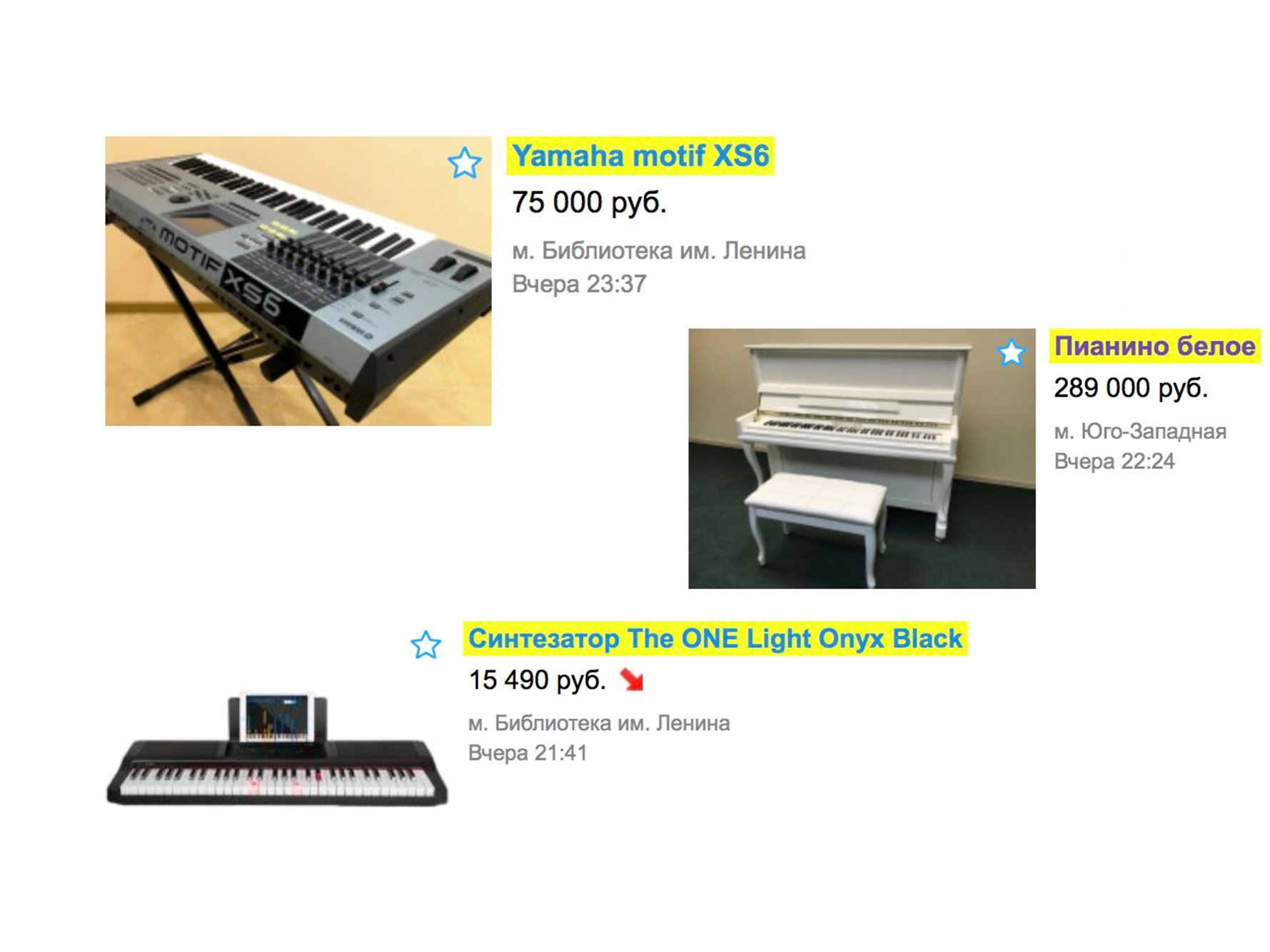
Acontece que, para encontrar o anúncio desejado, havia as seguintes opções:
- refinamento da categoria ao pesquisar por palavras-chave,
- classificação por frescura e preço,
- filtros
- pesquise apenas pelo nome.
O que mudou devido à relevância
Devido à relevância, os anúncios que não se encaixam deixaram de ser incluídos na emissão. Agora, se você estiver procurando um piano na página principal, provavelmente não verá os serviços de carregadores que o ajudam a transportá-lo, mas verá imediatamente o instrumento musical que deseja. Ao mesmo tempo, uma nova classificação foi adicionada - "Por padrão". É formado por dois indicadores: relevância do anúncio para a consulta de texto e atualização.

No topo, você vê os mais recentes dos relevantes.
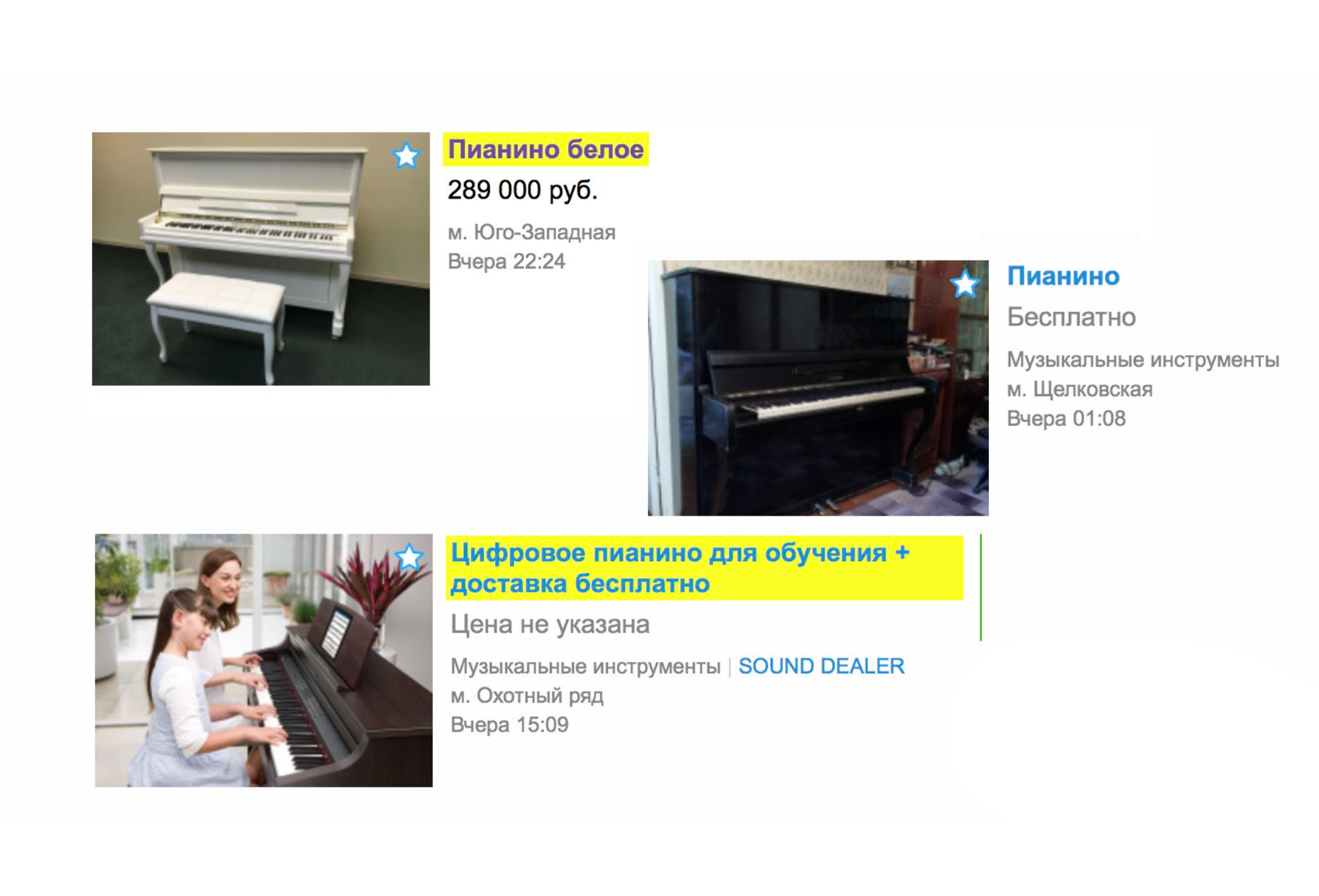
No Avito, por uma taxa adicional, você pode aumentar seu anúncio. E com a introdução da relevância, as melhorias pagas funcionam com mais eficiência. Antes de tudo, eles funcionarão se o seu anúncio for relevante para a consulta de texto.
A introdução da relevância não significa que abandonamos completamente as transições para a árvore de categorias. Apenas na maioria dos casos, reduzimos o número de cliques no anúncio desejado ao pesquisar na página principal. Se você ainda precisar de serviços de transporte, embora tenha digitado "piano" na pesquisa, acesse a árvore de categorias e encontrará esses anúncios. A pesquisa também começou a funcionar com mais eficiência e dentro da categoria, por exemplo, “Itens pessoais” e “Eletrodomésticos”.
Como encontrar o produto certo em três cliques
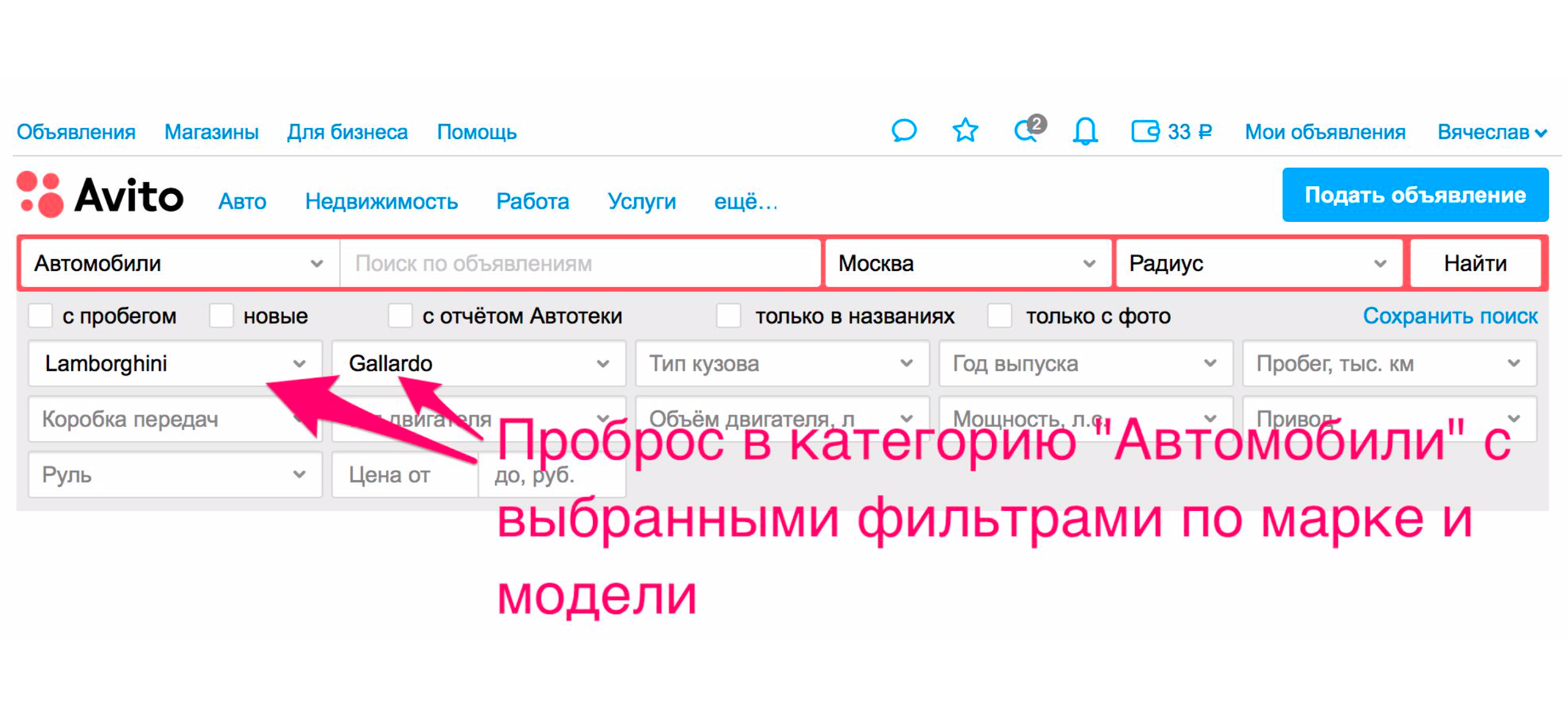
A pesquisa está se tornando mais conveniente para os usuários, não apenas devido à qualidade dos resultados da pesquisa. Existem outras maneiras de melhorar isso. Um deles está encaminhando para a categoria. Por exemplo, estamos procurando Lamborghini Gayardo (sim, você gosta de tocar piano e quer tocar Lamborghini). Para entrar na categoria de um carro de um modelo específico, é necessário fazer dois cliques extras. Com relevância, provavelmente você conseguirá o que deseja.
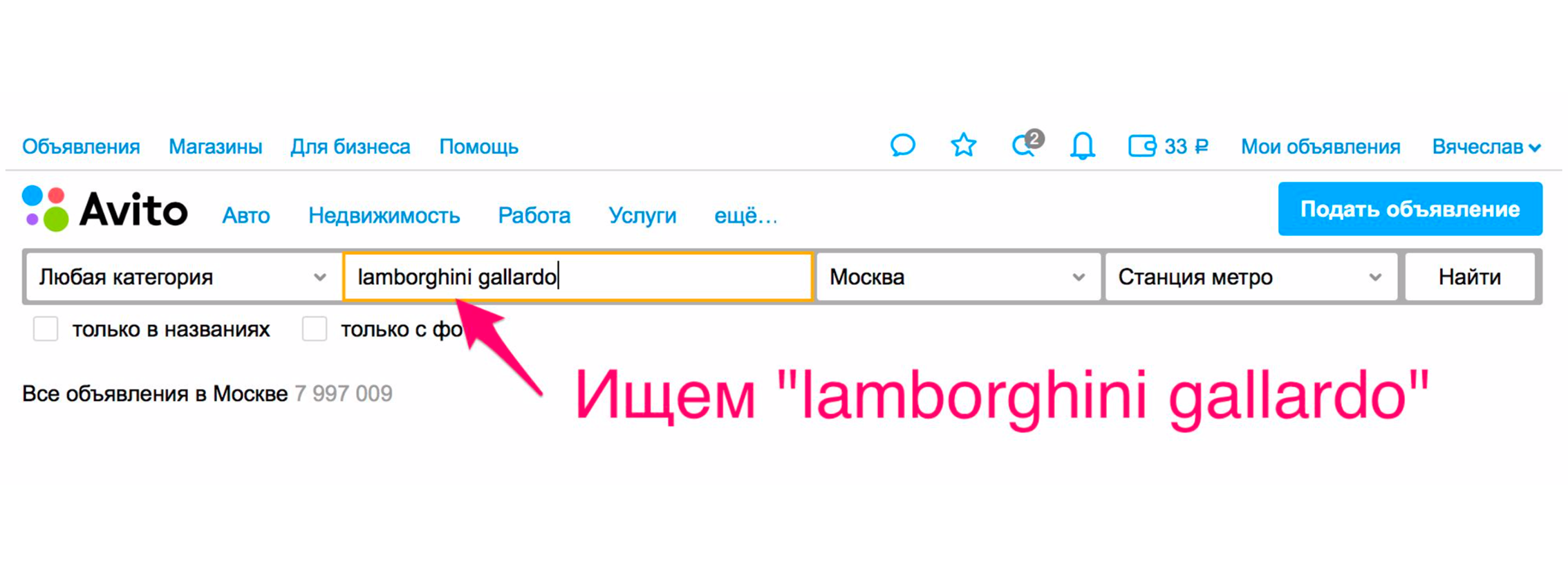
Mas há um método adicional que o jogará imediatamente em carros. A emissão será reduzida, o carro certo será selecionado nos filtros e você realmente receberá carros na emissão.

Outra maneira é expandir as tags. Por exemplo, quando você digita a palavra "paletó", recebe dicas.
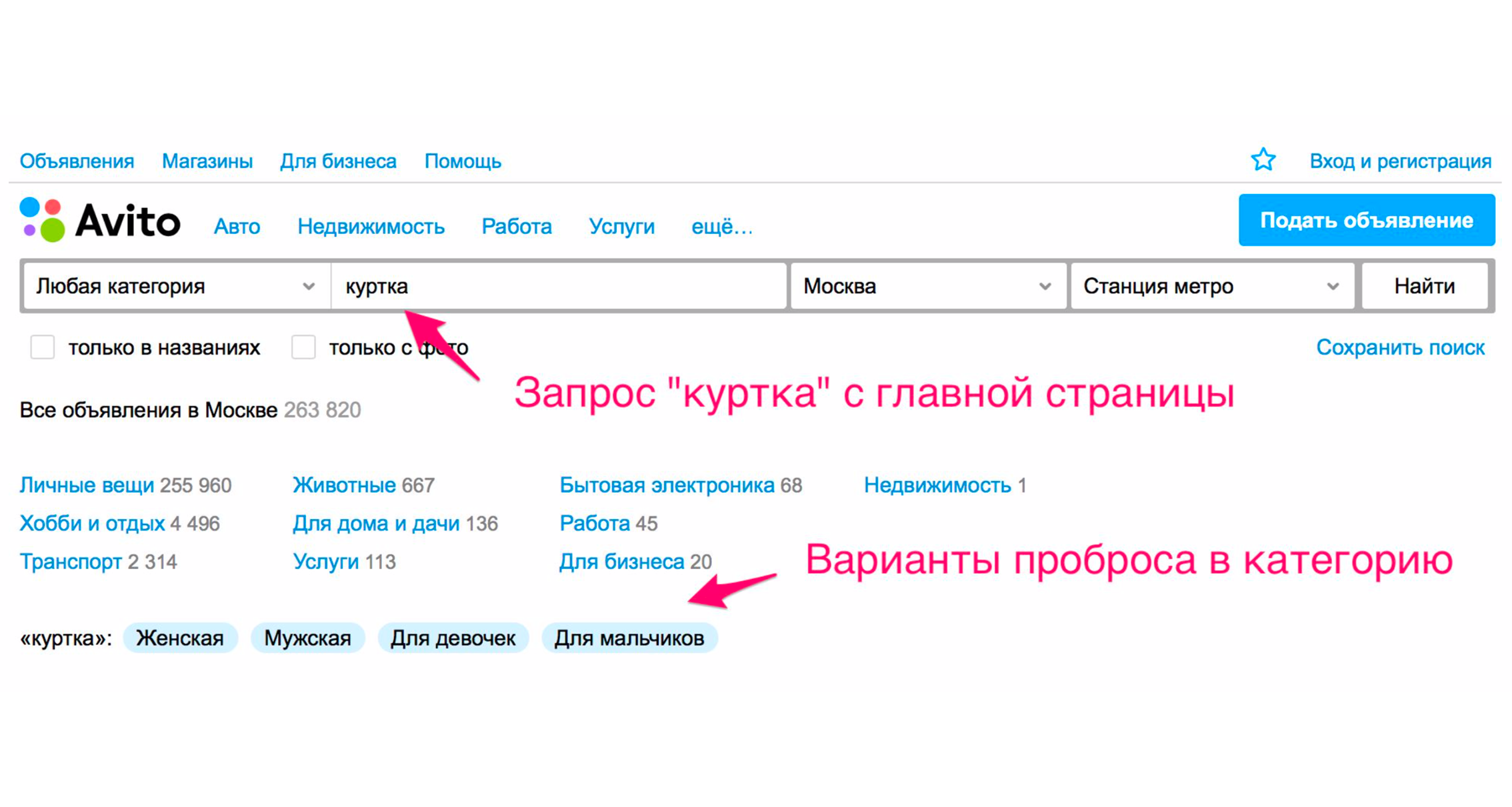
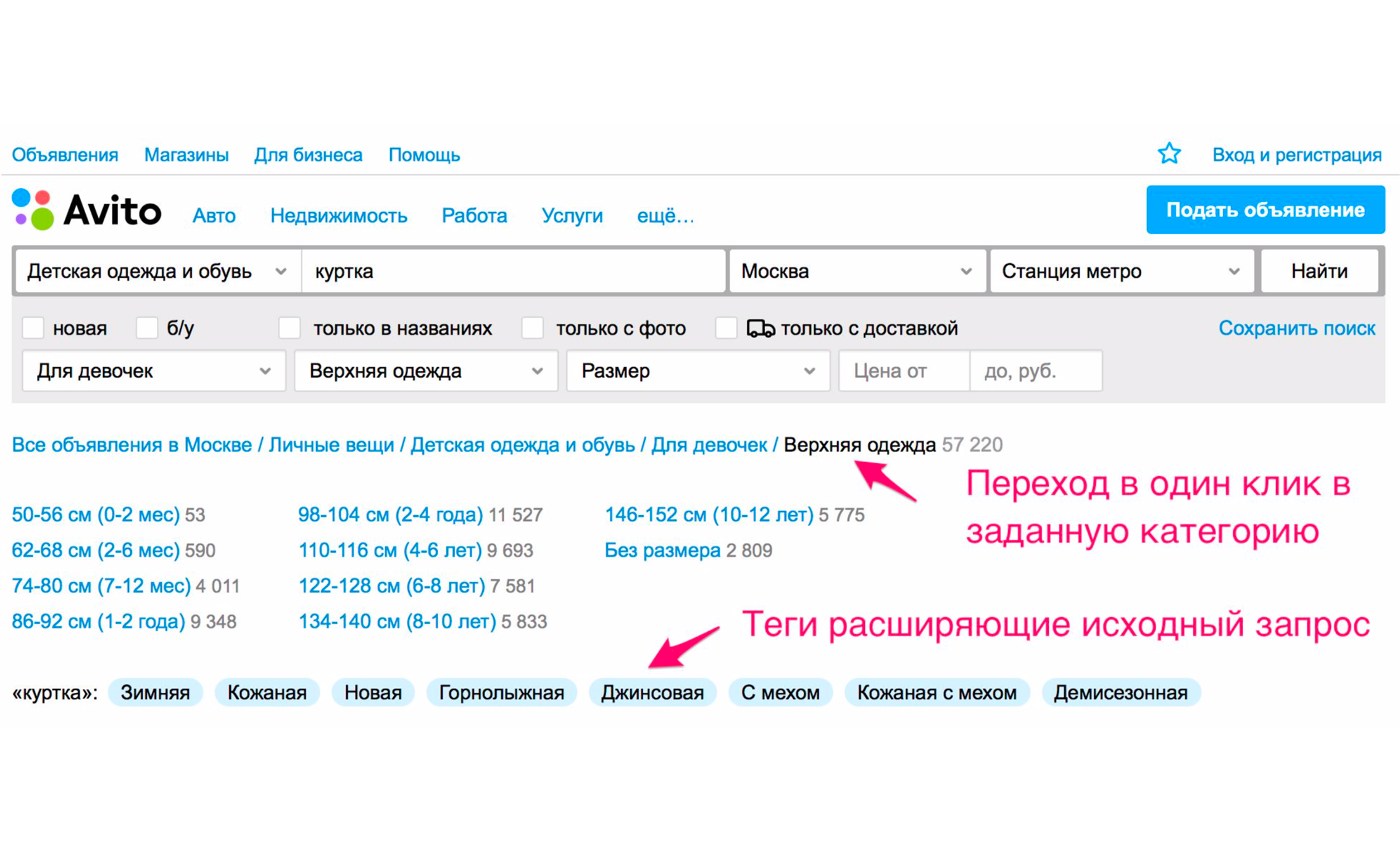
A captura de tela acima mostra as dicas: o tipo de jaqueta - feminina, masculina, para meninas, para meninos. Se você clicar em "Para meninas", você entrará imediatamente na categoria em que os filtros apropriados serão selecionados. Um conjunto de tags de expansão adicionais também aparecerá aqui: jaqueta de inverno, couro, nova e assim por diante. Se você descer manualmente a árvore de categorias até o produto desejado, precisará executar mais ações.
Qual é a diferença entre pesquisa e filtros
Quando falei no RIT ++ , o público fez uma pergunta: qual é a diferença entre a pesquisa de texto e os filtros? Tudo é bem simples. Você também pode encontrar o anúncio desejado sem uma solicitação de texto descendo a árvore de categorias. Nesse caso, a pesquisa ainda encontrará bens e serviços, não pelo texto fornecido, mas pelo conjunto de parâmetros passados dos filtros correspondentes da categoria selecionada.
Cada categoria tem seu próprio conjunto de filtros. Por exemplo, na categoria "Carros" - alguns filtros, na categoria "Coisas pessoais" - outros filtros. Ou seja, os filtros estão rigidamente vinculados a uma categoria.
Colocação do anúncio em dois minutos
Uma inovação importante apareceu para os vendedores que eles sentem ao enviar seu anúncio. Se o seu anúncio não contiver nenhum "proibido" ou não for uma duplicata - o bom anúncio habitual - você o verá na emissão quase que imediatamente. Na verdade, esse atraso dura cerca de dois minutos, mas, em casos raros, pode ser estendido até 30 minutos. Anteriormente, um anúncio sempre aparecia no site somente após meia hora.
Avito Assistant
O Avito Helper é uma extensão do Chrome que exibe o preço de um produto similar no Avito em sites de terceiros. Na extensão, você pode comparar preços em muitas lojas on-line com os preços do Avito ou simplesmente procurar os bens e serviços necessários em nosso serviço, sem ir diretamente ao site ou aplicativo. Conseguimos implementar o "Assistente", inclusive graças a novas mudanças na infraestrutura.

Arquitetura
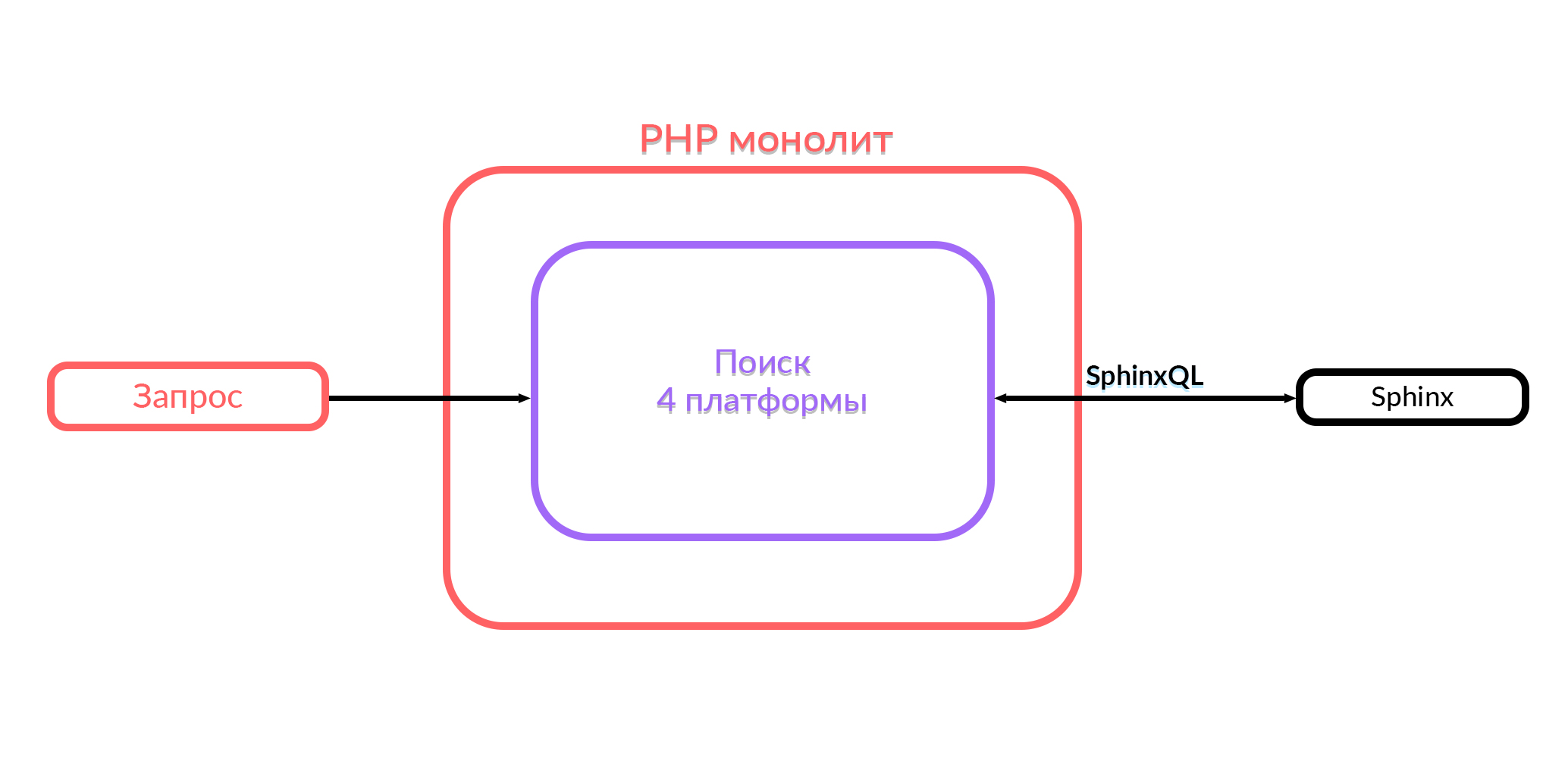
Serrar um monólito
Avito tem um monólito em PHP. Há um ano, toda a funcionalidade de pesquisa que funciona no Avito estava nesse monólito. A pesquisa no monólito funcionou com quatro plataformas: Android, iOS, a versão móvel no navegador e na área de trabalho. Para fornecer a saída, as consultas SQL correspondentes foram geradas no Sphinx dentro desse código, o processamento estava em andamento e a saída foi enviada no formato JSON ou HTML. Os usuários viram o que estavam procurando.
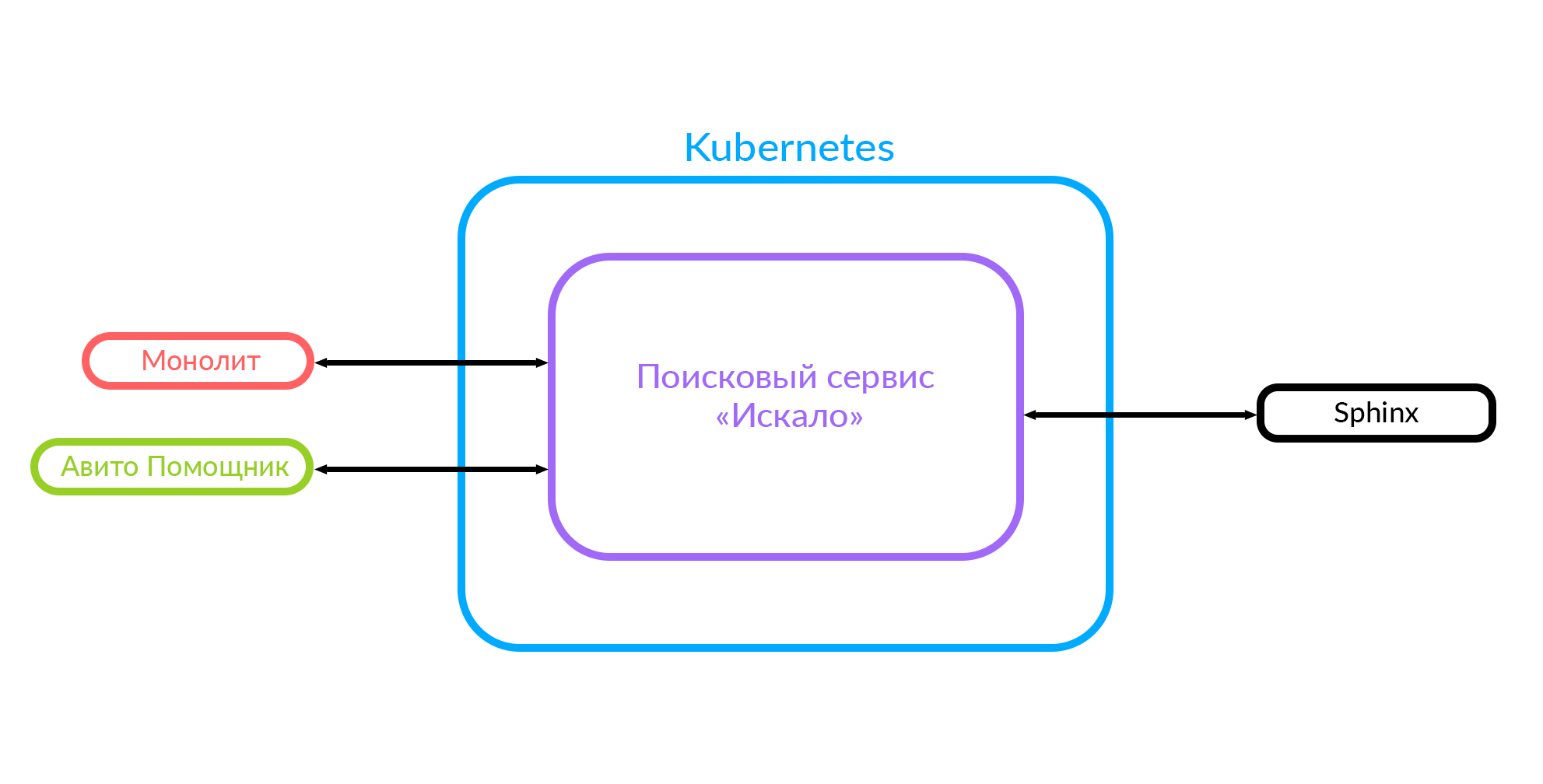
O que temos agora
Se você implementar novos recursos, será muito difícil integrar esse monólito. Portanto, decidimos desenvolver um serviço de pesquisa, que chamamos de "Pesquisado". Agora o monólito vai para esse serviço de pesquisa e o serviço vai para o Sphinx.

Razões para criar um serviço de pesquisa
Ao desenvolver serviços, você sempre precisa entender por que está fazendo isso. A primeira vantagem óbvia é a remoção da lógica de baixo nível. No nosso caso, isso está ocultando a cozinha para o processamento de consultas SphinxQL. Além disso, podemos fornecer mais facilmente a funcionalidade de pesquisa para sistemas de terceiros.
Execução de consulta assíncrona. Essa vantagem é bastante óbvia e, dependendo da implementação, um ou outro sucesso pode ser alcançado. Nosso serviço foi implementado no Golang e havia funcionalidades que podiam ser paralelizadas - três solicitações no Sphinx, que resultaram em bons resultados.
Implantação rápida. Identificamos uma funcionalidade separada com menos código, testes extras (o monólito tem muitos testes, não apenas a funcionalidade de pesquisa), e é mais fácil implementá-la. Mais importante ainda, devido a uma abordagem bem-sucedida da implementação desse serviço, fomos capazes de reduzir coisas interessantes e implementar algoritmos avançados de classificação - para fazer um processamento bastante complicado que não poderíamos fazer em um monólito. Isso nos fornece uma base muito boa para experimentar a qualidade da pesquisa.
Como bônus, temos a oportunidade de mudar de Sphinx para Elastic, porque a lógica de baixo nível agora está oculta.
Este diagrama já mostra o caso em que há um monólito, o serviço "Pesquisado" e o serviço de terceiros "Avito Assistant".
Como funciona um serviço de pesquisa?
Possui um conjunto de agregadores. Cada agregador executa uma certa lógica de negócios relacionada ao processamento da emissão. Ele pode formar esse problema de uma certa maneira.
A solicitação chega no agendador. O planejador seleciona o agregador de acordo com os critérios de consulta em termos de seus parâmetros (ou se o agregador desejado for especificado na própria solicitação). O agregador vai para a Sphinx. Após receber uma resposta do Sphinx, ele gera uma saída e fornece a resposta ao cliente.

Nesse caso, a solicitação estava fora, não na nuvem em que nosso serviço de pesquisa funciona. Mas outra opção também é possível: alguns de nossos serviços, dentro da nuvem, por exemplo, o Avito Assistant, se voltam para um serviço de pesquisa. Essa solicitação já vai para outro agregador - há outra lógica de negócios. Veja como funciona:
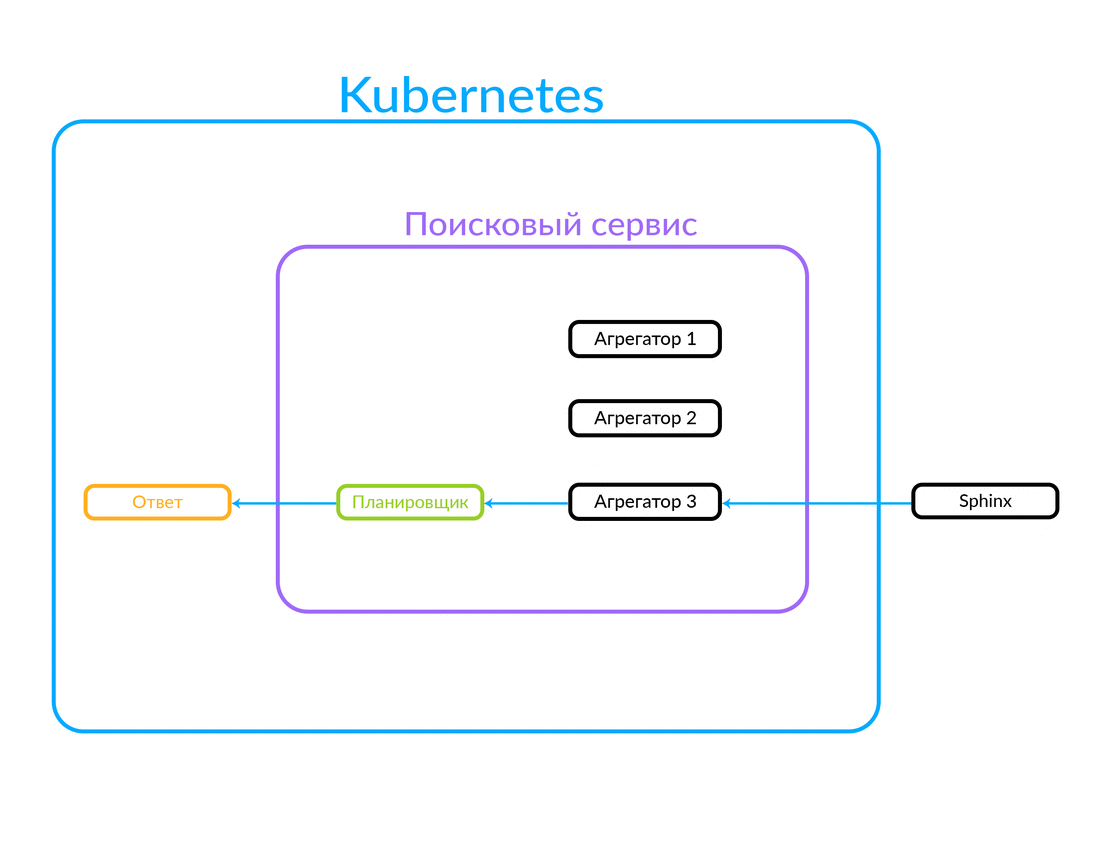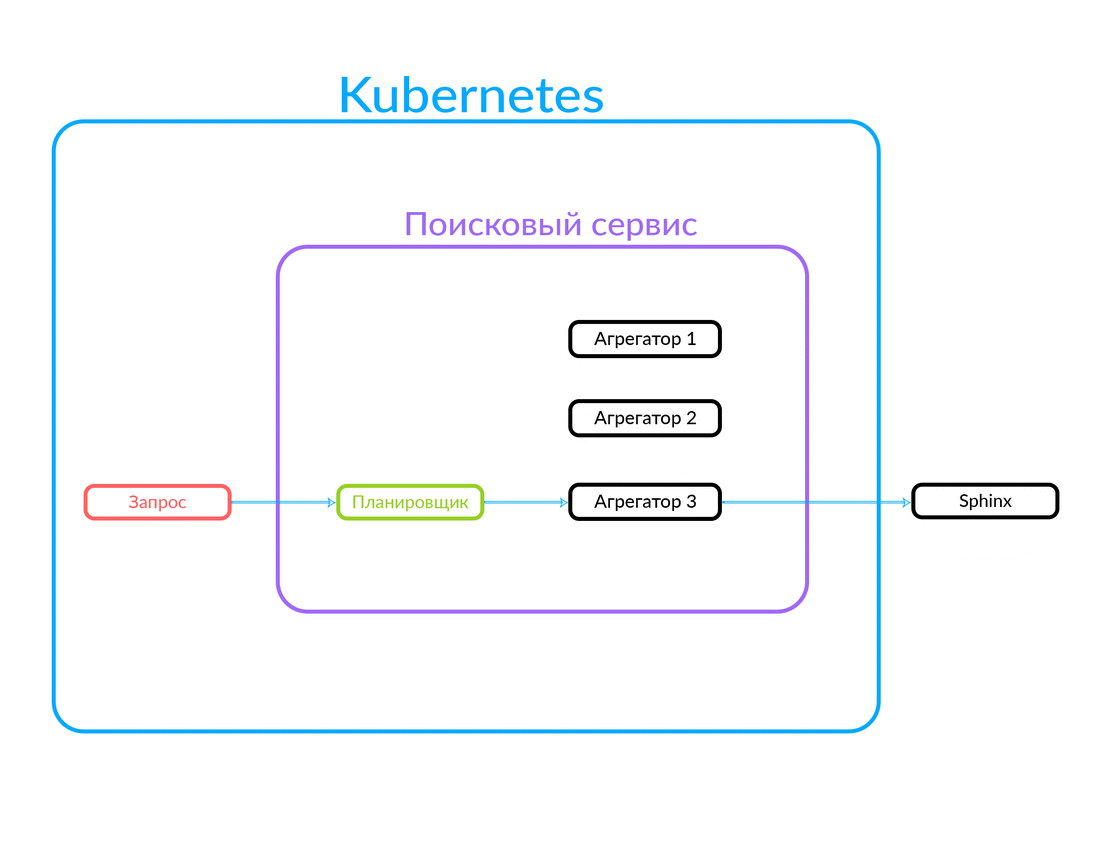
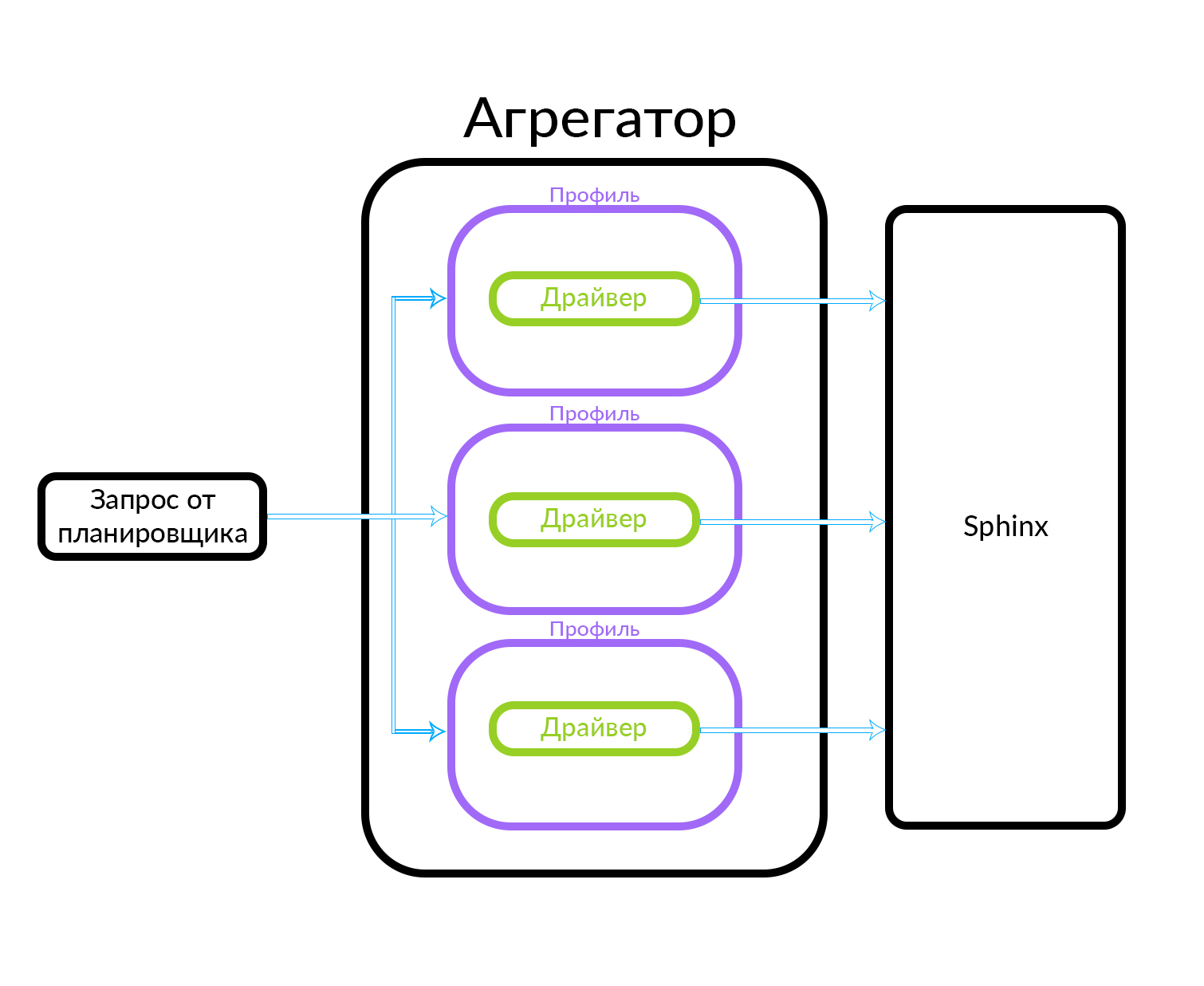
Como funciona a execução assíncrona de consulta no agregador
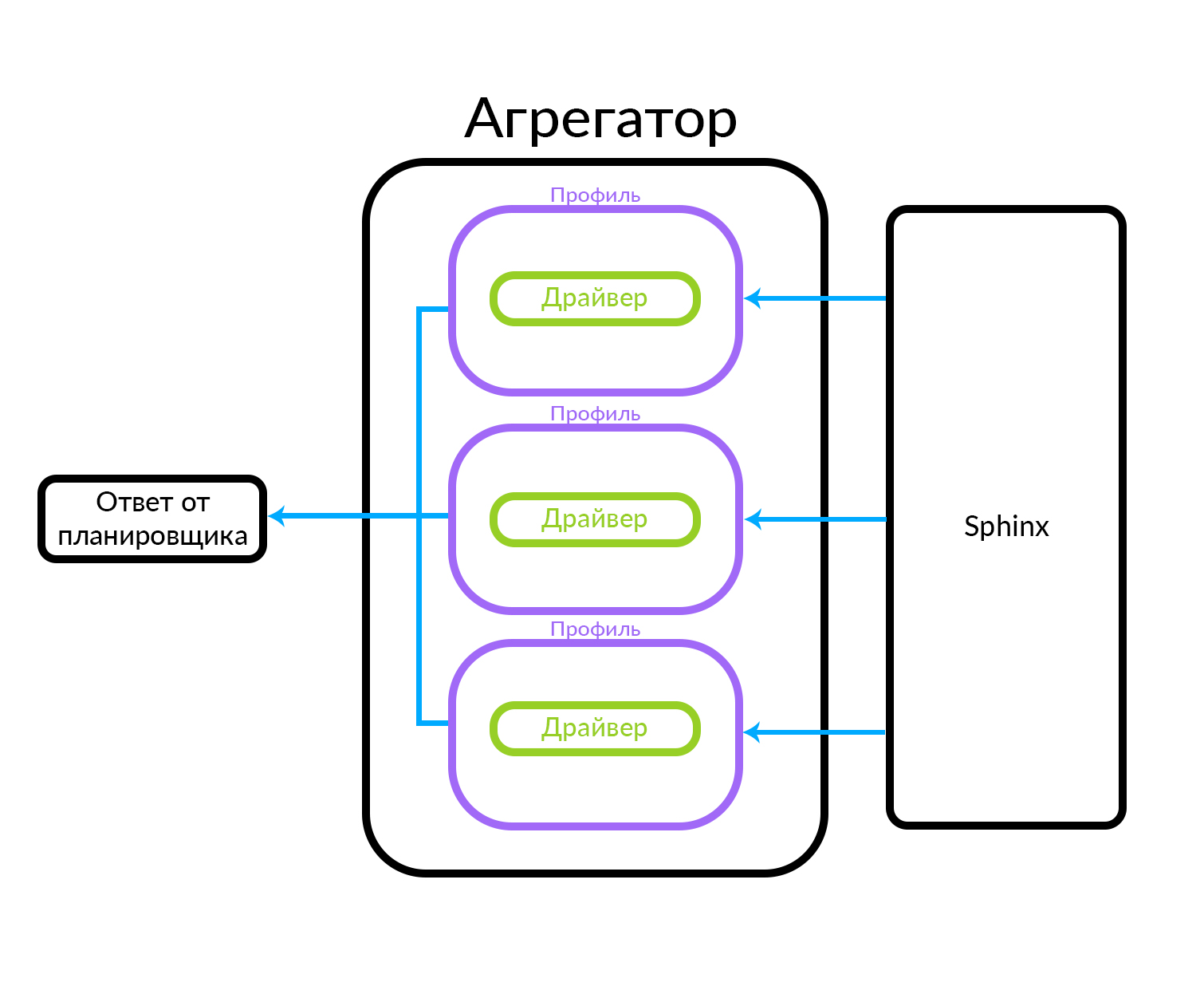
O agregador consiste em vários perfis. Um perfil é, grosso modo, uma entidade na qual você pode obter um anúncio de algum tipo ou de uma maneira específica. Por exemplo, isso pode ser explicado através de uma analogia: existem anúncios "Premium", "VIP" e regulares no Avito. O agregador recebe uma solicitação do planejador, enquanto solicitações paralelas são executadas para o conjunto de perfis conhecidos no agregador. O perfil possui um driver que acessa fisicamente o nível subjacente, neste caso no Sphinx, mas pode ser qualquer outra fonte de dados
O agregador pode simplesmente fornecer ao planejador os resultados das consultas aos perfis e também pode executar ações mais complexas, por exemplo, misturar esses resultados usando um ou outro algoritmo.
Armazenamento de índice de pesquisa
Devido ao fato de usarmos o Kubernetes na arquitetura, no RIT ++ me perguntaram sobre o armazenamento do índice de pesquisa - ele é armazenado no Kubernetes? Não, temos a Sphinx vivendo em máquinas físicas. No Kubernetes, estamos implantando um serviço de pesquisa que processa a lógica de pesquisa. A nuvem também contém um índice de pesquisa de amostra para o ambiente de desenvolvimento no qual os testes são executados, mas é indesejável colocar um índice de combate lá, porque os serviços que funcionam no Kubernetes são, antes de tudo, serviços sem estado.
Carga do serviço de pesquisa
Agora, este serviço está em batalha, serve 100% da carga, com algumas exceções. A carga que ele suporta é de aproximadamente 200 krpm. Atraso: mediana - até 17 ms, percentil 95 - até 120 ms, percentil 99 - até 320 ms.
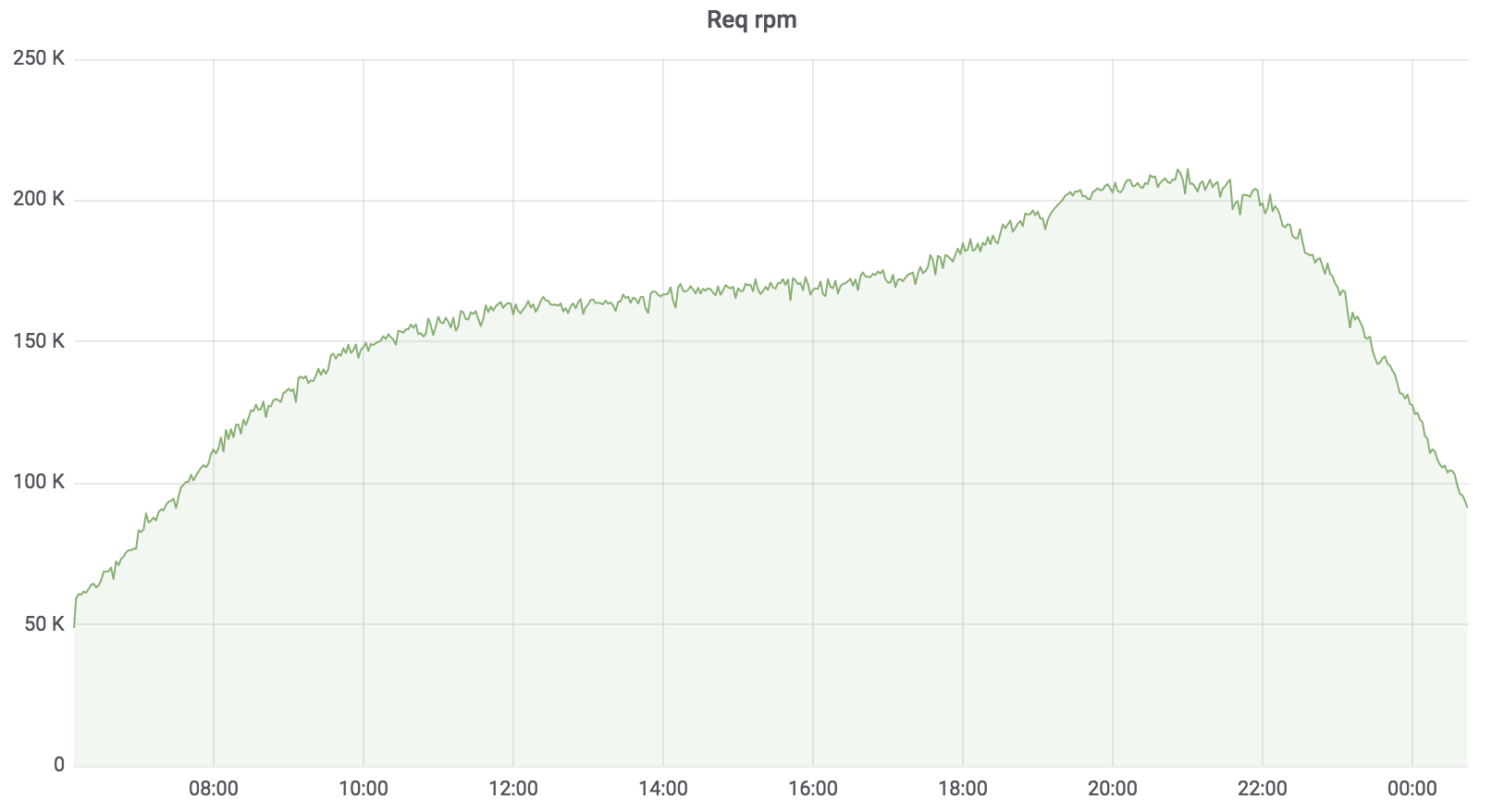
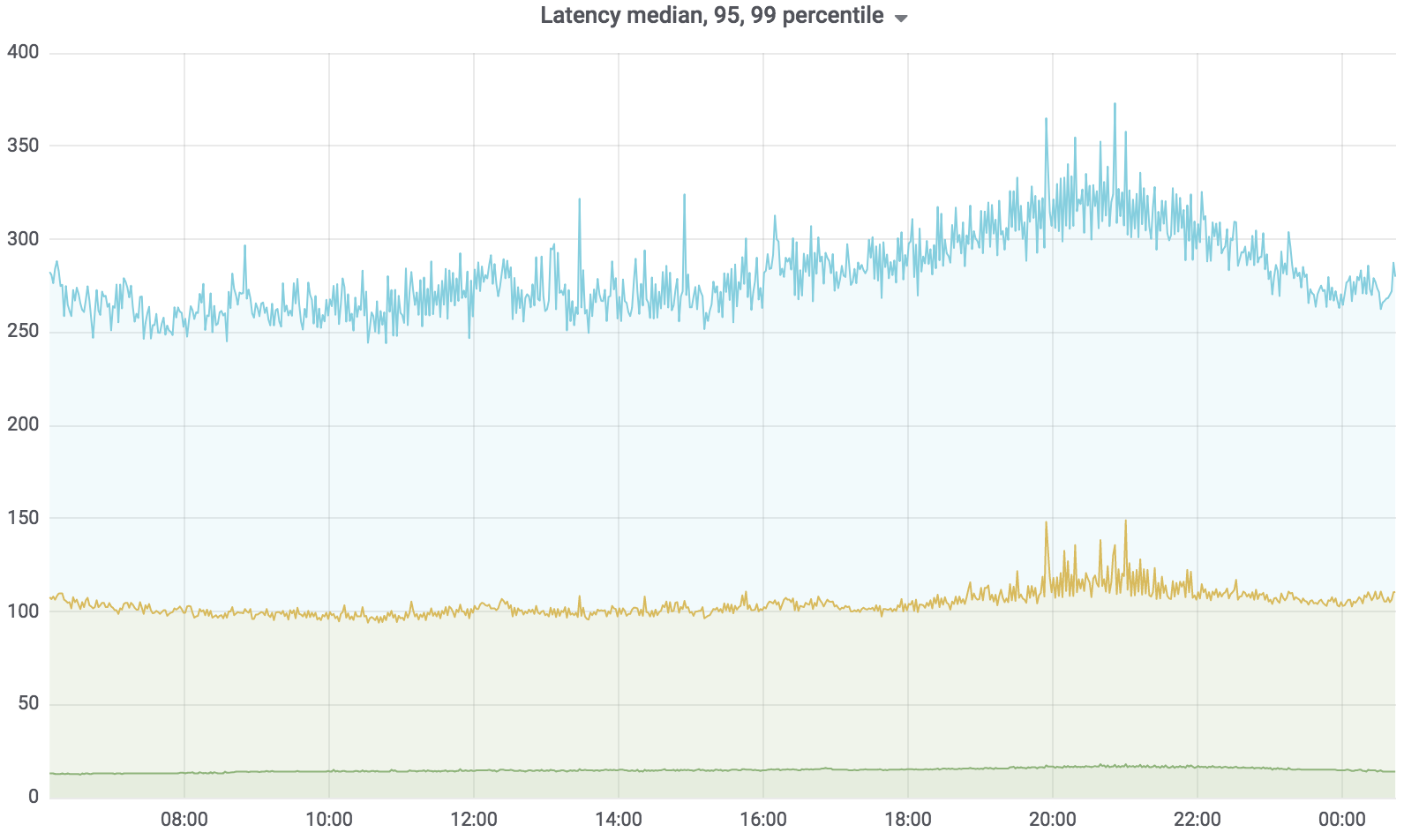
Serviço total de pesquisa
O serviço de pesquisa é escrito em Golang, implantado no Kubernetes, o agregador trabalha de forma assíncrona com vários perfis. O perfil funciona com o driver especificado, o driver acessa a fonte de dados especificada, por exemplo, Sphinx. O número de solicitações que nosso serviço atende é de até 200 krpm no momento. Atraso: mediana - até 17 ms, percentil 95 - até 120 ms, percentil 99 - até 320 ms.
Implementação do serviço em um sistema de trabalho
O problema da dupla funcionalidade é bastante óbvio, temos que suportar duas bases de código que devem executar a mesma tarefa. Precisamos de um retorno. Nós o chamamos de “canudos” - lembramos de “canudos leigos”. Além disso, precisamos de controle de tráfego, é desejável que seja rápido, através de um painel.
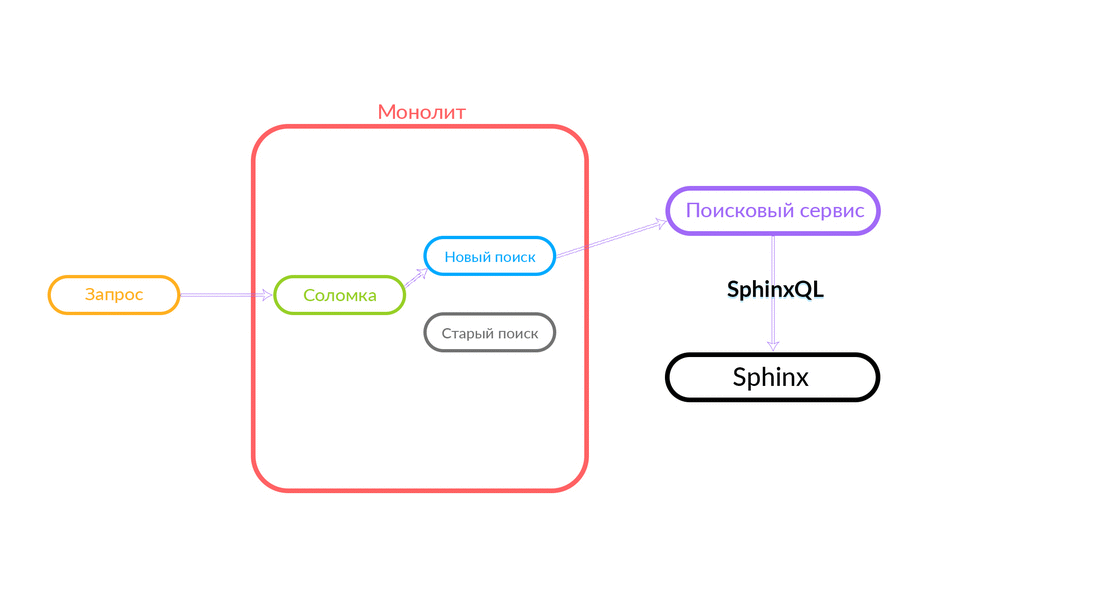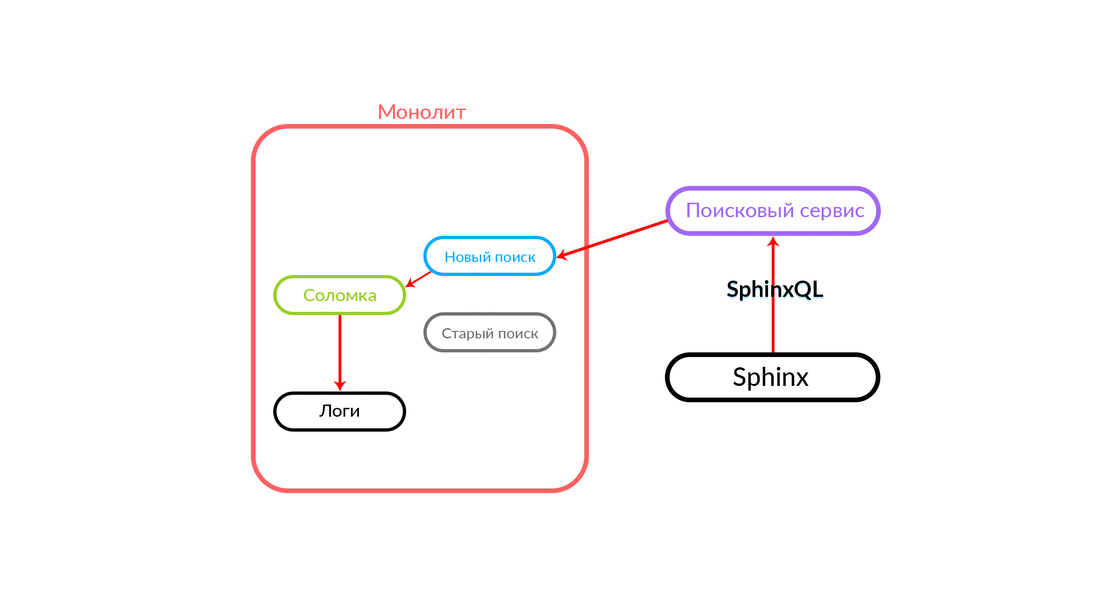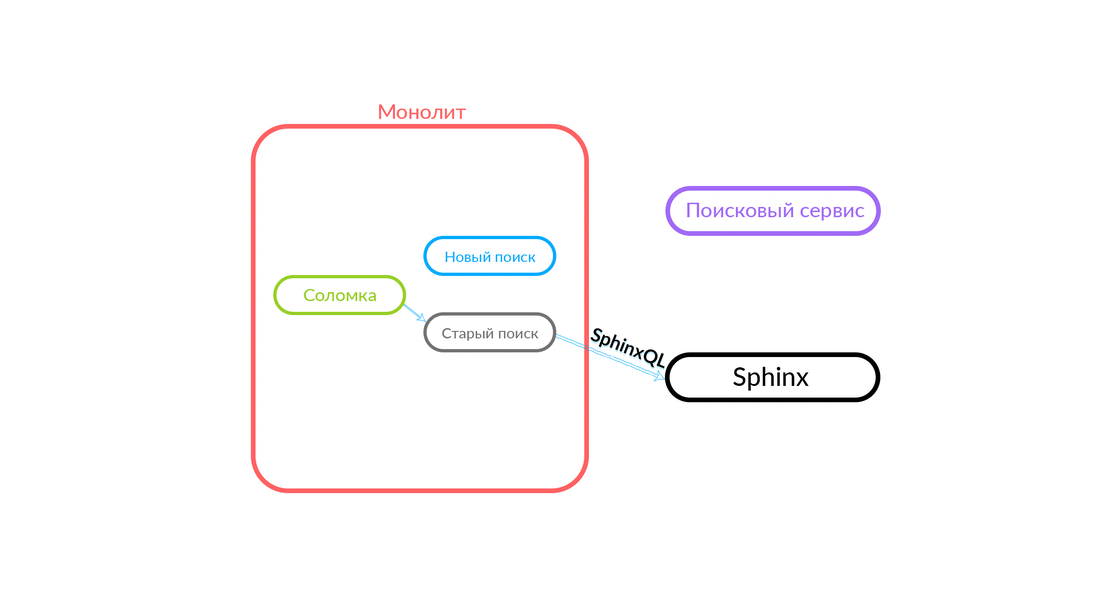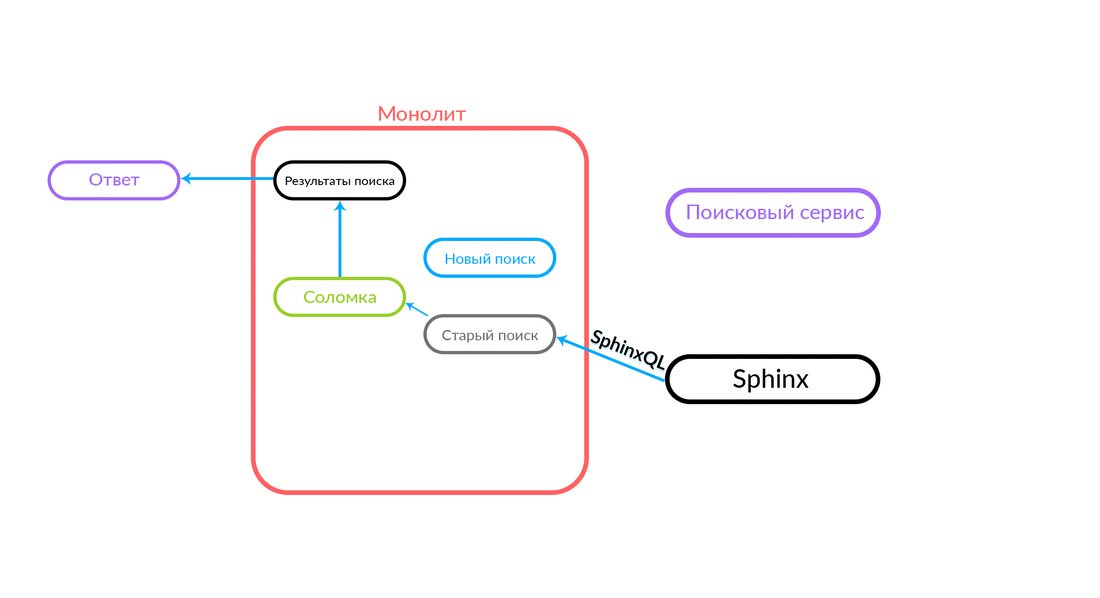
Como é que o "canudo"
A consulta de pesquisa chega ao "Straw", que funciona dentro do monólito e pode fazer uma chamada adicional para uma nova pesquisa ou uma antiga. Ela faz uma chamada para uma nova pesquisa, ele a realiza e, se for bem-sucedida, obtemos o resultado de uma nova pesquisa.
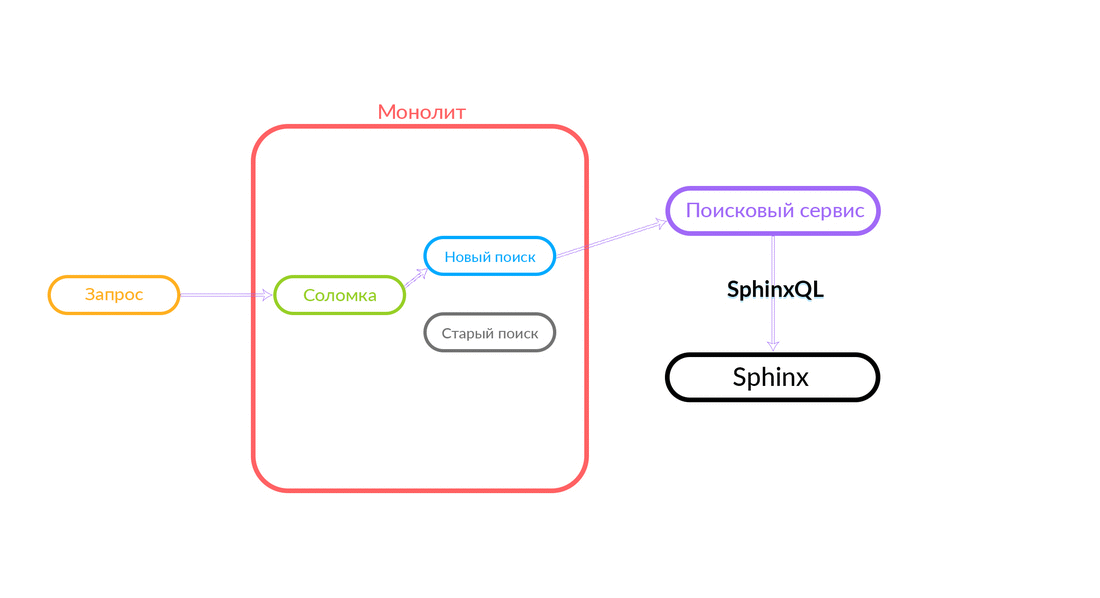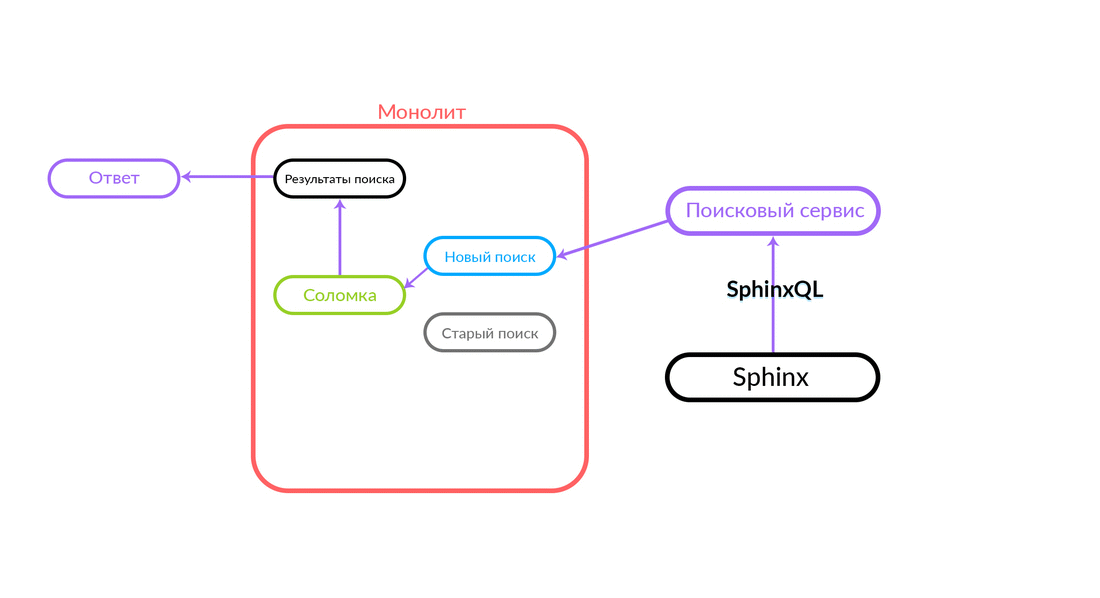
Há situações em que alguma consulta ao serviço de pesquisa está falhando: por exemplo, e até que algum tipo de funcionalidade seja implementada dentro do serviço de pesquisa. Então, necessariamente, prometemos esse pedido - "The Straw" o executará na busca antiga. A pesquisa antiga do monólito será direcionada para o Sphinx e a resposta será enviada para o cliente. O cliente não sentirá nada.
Um esquema razoavelmente confiável, e é sempre interessante ver o que acontece na prática. O Departamento de Arquitetura da Avito aprimora constantemente nossa nuvem, ajustando-a, tornando-a mais confiável e produtiva. Em algum momento, houve problemas que, ao atender um dos nós com uma intensidade suficientemente alta, os erros vieram do monólito (100 erros por segundo).

Ao mesmo tempo, o atraso do serviço aumentou acentuadamente - na imagem abaixo, você pode ver picos.
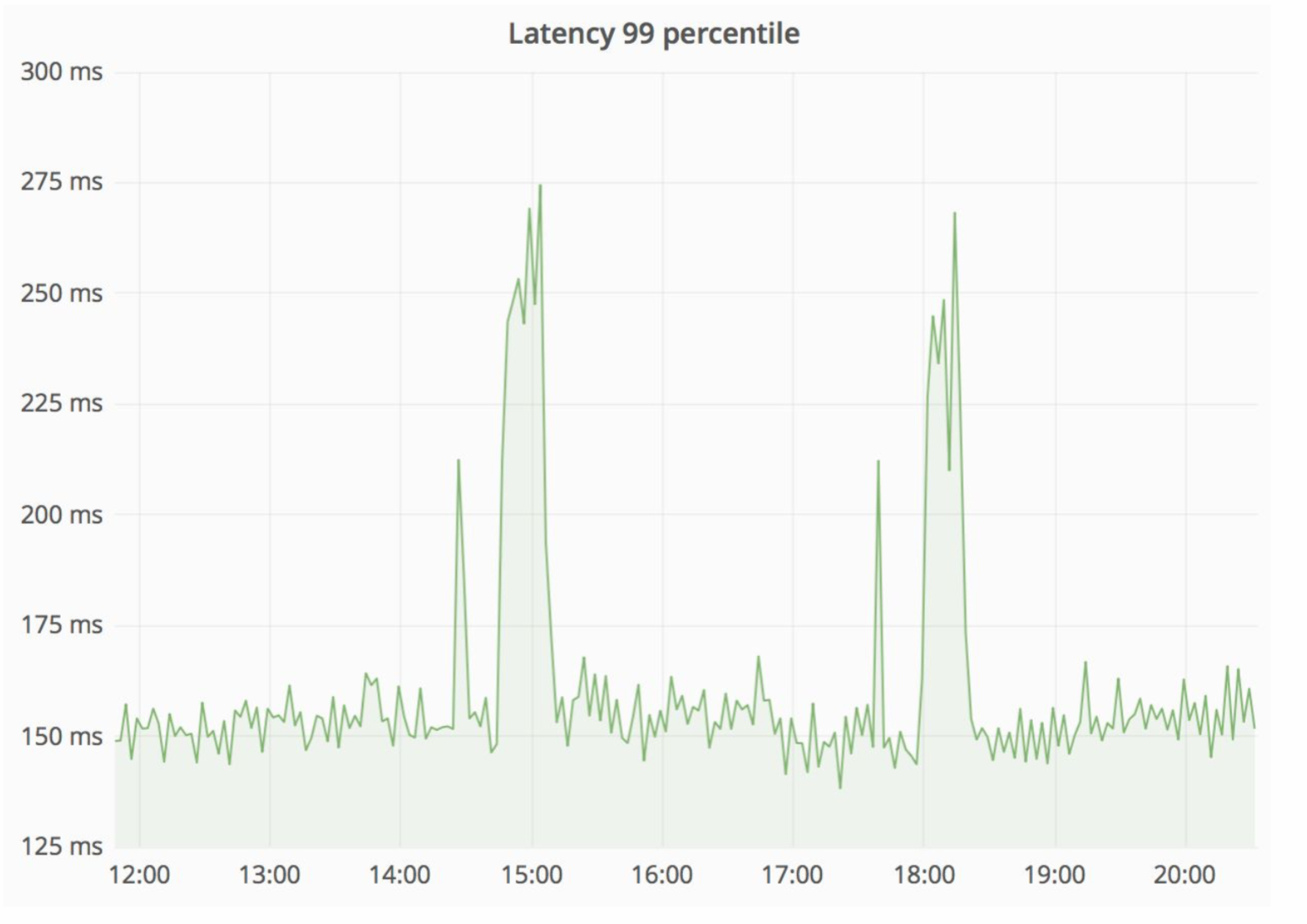
O "canudo" resolveu essa situação notavelmente, e os erros HTTP resultantes estavam no mesmo nível - uma unidade de erros para todo o Avito. Nossos visitantes não perceberam nada.
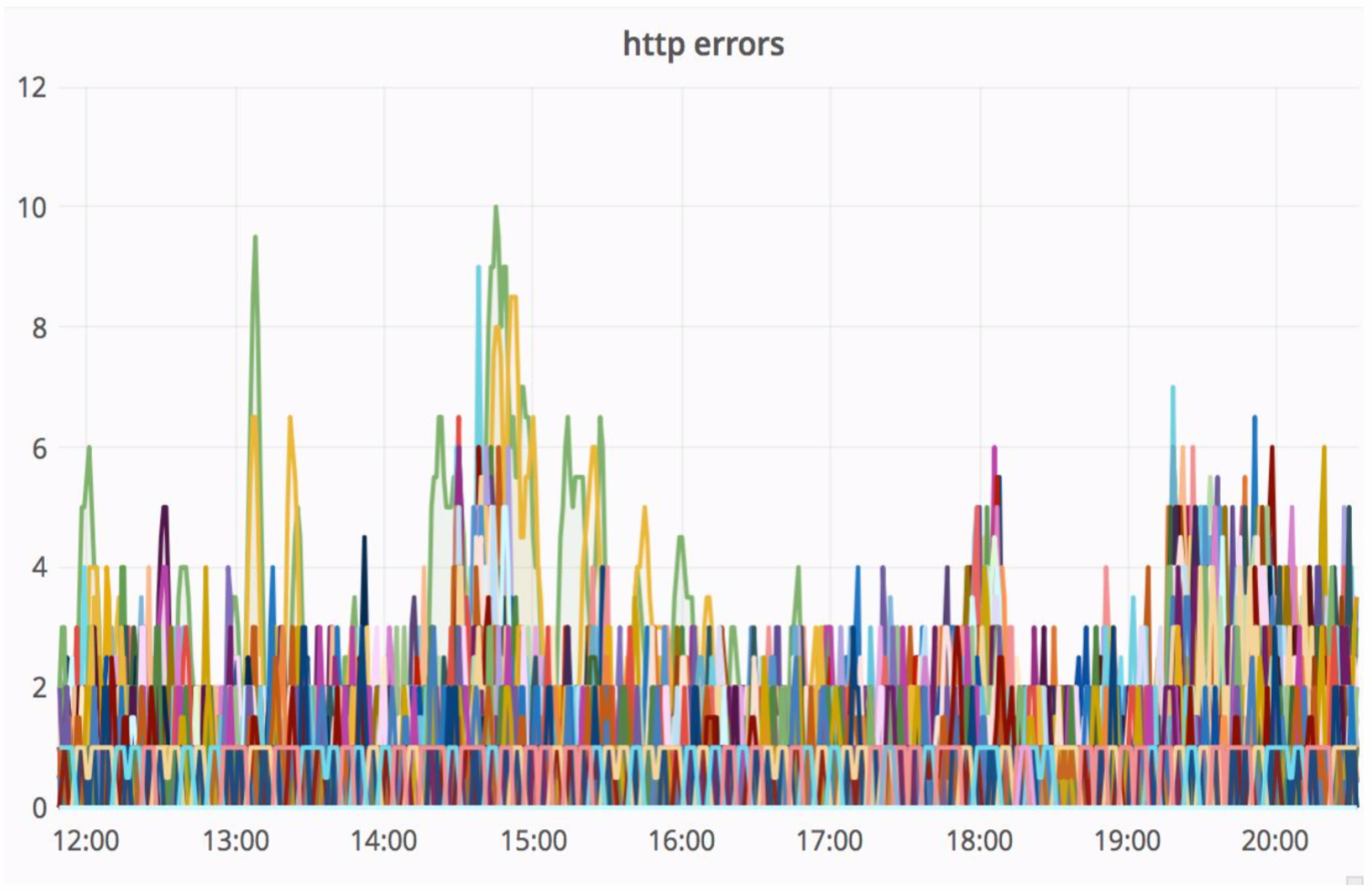
Automação de experimentos
Queremos que a pesquisa se desenvolva rapidamente e implantar novos recursos nela foi mais fácil. Para isso, é necessária infraestrutura adequada. Configuramos a automação dos testes A / B. Usando o painel, podemos iniciar novos experimentos, configurá-los com base nas inovações adicionadas e, portanto, executar experimentos sem rolar o monólito.
No estado inicial, quando nenhuma experiência foi iniciada, todos os visitantes veem a funcionalidade de pesquisa usual.
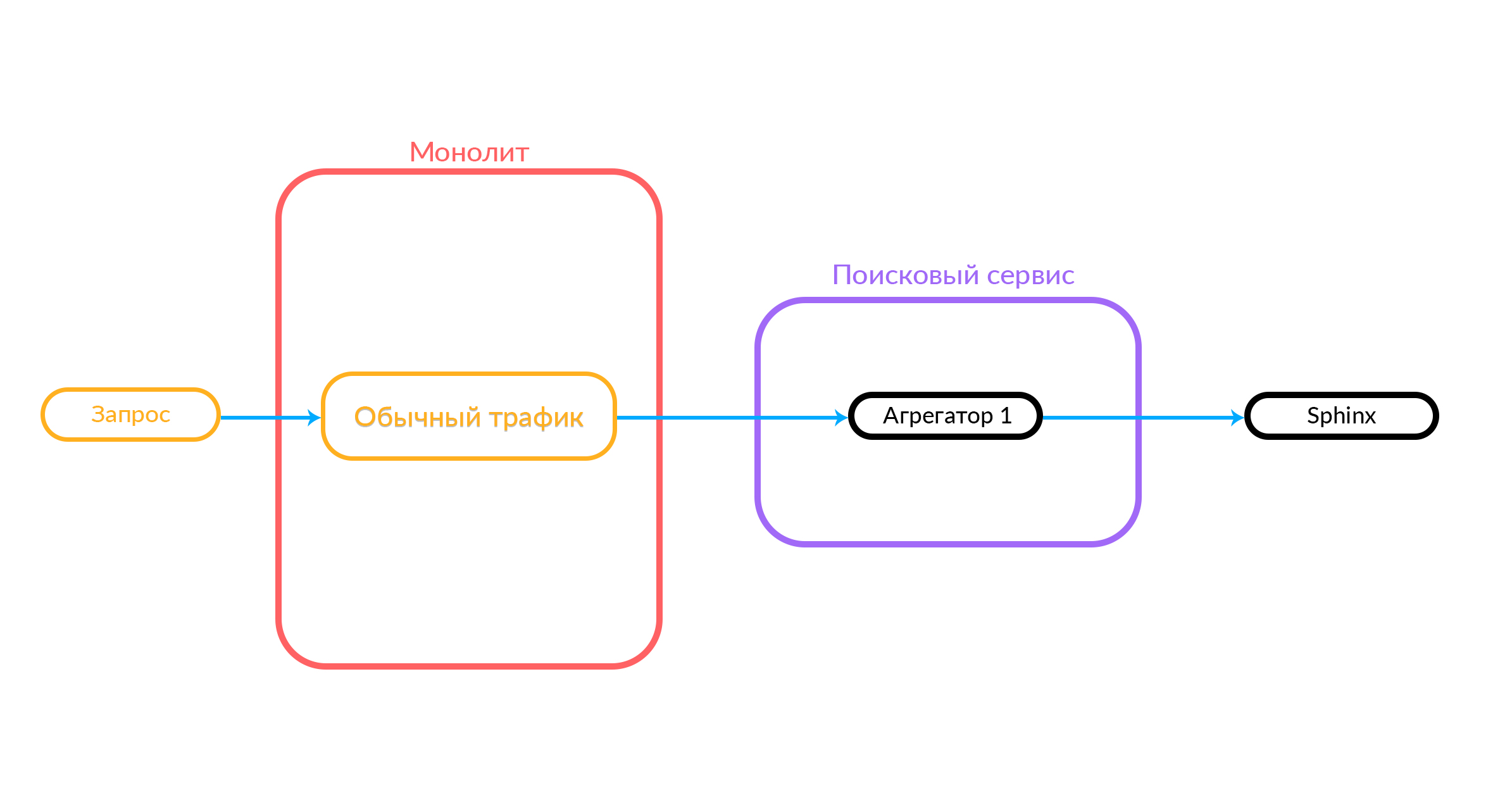
Em um experimento típico, os usuários são divididos em grupos. O grupo de controle - com a funcionalidade usual para nossos visitantes. Existem vários grupos de teste - com inovações. Quando precisamos criar um novo experimento, no serviço de pesquisa, implementamos uma nova funcionalidade de pesquisa (adicionamos novos agregadores) e, por meio do painel, configuramos o experimento com os grupos necessários, vinculando-os a novos agregadores.
Ao analisar experimentos, comparamos o comportamento dos visitantes no grupo de controle com os testes e, com base nisso, tiramos conclusões sobre o sucesso do experimento.

Suponha que tenhamos desenvolvido uma nova fórmula de classificação. O que precisamos fazer para experimentar com ela?
- No serviço de pesquisa, implante o agregador apropriado (seja "Agregador 2").
- Crie uma experiência por meio de um painel e conecte um dos grupos dessa experiência a esse agregador.
- Agora, se uma consulta chegar na pesquisa que se enquadra no grupo de teste, ela será direcionada para o serviço de pesquisa no "Agregador 2".
Podemos continuar criando novas experiências e associando seus grupos de teste a novos agregadores.
Infraestrutura total de pesquisa
Há um cluster de servidores Sphinx 3. Ele contém 13 krps de consultas SphinxQL e possui mais de 45 milhões de anúncios ativos.
Sphinx 3.0 é estável e agrada com seu desempenho. A propósito, os binários são de domínio público . Além disso, graças ao Avito, novos recursos são filmados no Sphinx 3, por exemplo, a operação do produto escalar de vetores e os erros encontrados são corrigidos.
Nós usamos a arquitetura de serviço. Temos o serviço de busca "Iskalo" e o serviço "Avito Assistant". Parte da funcionalidade permaneceu no monólito, mas continuamos trabalhando no seu corte.
Conclusões
No ano passado, um sistema avançado de desenvolvimento de funcionalidades de pesquisa foi recebido. Tivemos a oportunidade de realizar experimentos rápidos e flexíveis. E agora a busca por usuários se tornou mais conveniente, mais rápida e melhor ajuda a resolver seus problemas.
O que vem a seguir
Além disso, continuaremos removendo do monólito o que resta: renderização, filtros. Vamos trabalhar para melhorar a qualidade da pesquisa, continuar a encantar nossos visitantes. Espero que você também.
Se você tiver dúvidas sobre o trabalho de nossa pesquisa, gostaríamos de saber mais detalhes técnicos, escreva nos comentários. Eu responderei com prazer. A propósito, recentemente, Andrey Drozdov falou no Highload ++ 2018 com um relatório sobre otimização de vários critérios dos resultados da pesquisa , aqui está sua apresentação .