Olá pessoal!
Abrimos um novo fluxo para o curso
Machine Learning . Portanto, aguarde no futuro próximo artigos relacionados a essa disciplina, por assim dizer. Bem, é claro, seminários abertos. Agora, vejamos o que é aprendizado por reforço.
O aprendizado reforçado é uma forma importante de aprendizado de máquina, em que um agente aprende a se comportar em um ambiente executando ações e vendo resultados.
Nos últimos anos, vimos muitos sucessos nesse fascinante campo de pesquisa. Por exemplo,
DeepMind e Deep Q Learning Architecture em 2014,
vitória sobre o go go com AlphaGo em 2016,
OpenAI e PPO em 2017, entre outros.
 DeepMind DQN
DeepMind DQNNesta série de artigos, focaremos o estudo das diferentes arquiteturas usadas hoje para resolver o problema do aprendizado reforçado. Estes incluem Q-learning, Deep Q-learning, Gradientes de Política, Critic Actor e PPO.
Neste artigo, você aprenderá:
- O que é aprendizado por reforço e por que recompensas são uma ideia central
- Três abordagens de aprendizado por reforço
- O que "profundo" significa na aprendizagem por reforço profundo
É muito importante dominar esses aspectos antes de mergulhar na implementação de agentes de aprendizado por reforço.
A idéia do treinamento por reforço é que o agente aprenda com o ambiente interagindo com ele e recebendo recompensas por executar ações.

Aprender através da interação com o meio ambiente vem de nossa experiência natural. Imagine que você é uma criança na sala de estar. Você vê a lareira e vai até ela.
Perto quente, você se sente bem (recompensa positiva +1). Você entende que o fogo é uma coisa positiva.
Mas então você tenta tocar o fogo. Ai! Ele queimou a mão (recompensa negativa -1). Você acabou de perceber que o fogo é positivo quando você está a uma distância suficiente porque produz calor. Mas se você se aproximar dele, você se queimará.
É assim que as pessoas aprendem através da interação. O aprendizado reforçado é simplesmente uma abordagem computacional do aprendizado através da ação.
Processo de aprendizagem por reforço

Como exemplo, imagine um agente aprendendo a jogar Super Mario Bros. O processo de Aprendizagem por Reforço (RL) pode ser modelado como um ciclo que funciona da seguinte maneira:
- O agente recebe o estado S0 do ambiente (no nosso caso, obtemos o primeiro quadro do jogo (estado) de Super Mario Bros (ambiente))
- Com base nesse estado S0, o agente executa a ação A0 (o agente se moverá para a direita)
- O ambiente passa para um novo estado S1 (novo quadro)
- O ambiente dá alguma recompensa ao agente R1 (não está morto: +1)
Esse ciclo RL produz uma sequência de
estados, ações e recompensas.O objetivo do agente é maximizar as recompensas acumuladas esperadas.
Hipóteses de recompensa da ideia centralPor que o objetivo de um agente é maximizar as recompensas acumuladas esperadas? Bem, o aprendizado por reforço é baseado na idéia de uma hipótese de recompensa. Todas as metas podem ser descritas maximizando as recompensas acumuladas esperadas.
Portanto, no treinamento de reforço, para alcançar o melhor comportamento, precisamos maximizar as recompensas acumuladas esperadas.A recompensa acumulada em cada etapa t pode ser escrita como:

Isso é equivalente a:
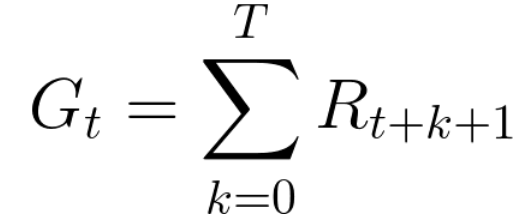
No entanto, na realidade, não podemos simplesmente adicionar essas recompensas. As recompensas que chegarem mais cedo (no início do jogo) são mais prováveis, pois são mais previsíveis do que as recompensas no futuro.

Suponha que seu agente seja um mouse pequeno e seu oponente seja um gato. Seu objetivo é comer a quantidade máxima de queijo antes que o gato coma você. Como podemos ver no diagrama, é mais provável que um rato coma queijo próximo a si mesmo do que queijo perto de um gato (quanto mais próximos estamos dele, mais perigoso é).
Como resultado, a recompensa de um gato, mesmo que seja maior (mais queijo), será reduzida. Não temos certeza de que podemos comê-lo. Para reduzir a remuneração, fazemos o seguinte:
- Determinamos a taxa de desconto chamada gama. Deve estar entre 0 e 1.
- Quanto maior a gama, menor o desconto. Isso significa que o agente de aprendizado está mais preocupado com recompensas de longo prazo.
- Por outro lado, quanto menor a gama, maior o desconto. Isso significa que é dada prioridade às recompensas de curto prazo (queijo mais próximo).
A contraprestação esperada acumulada, considerando o desconto, é a seguinte:
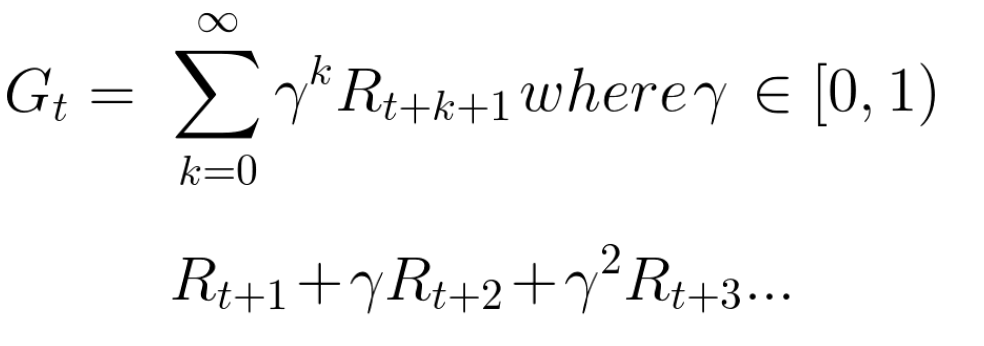
Grosso modo, cada recompensa será reduzida usando a gama no indicador de tempo. À medida que o tempo aumenta, o gato se aproxima de nós, e a recompensa futura se torna cada vez menos provável.
Tarefas ocasionais ou contínuasUma tarefa é uma instância do problema de aprendizagem com reforço. Podemos ter dois tipos de tarefas: episódica e contínua.
Tarefa episódicaNesse caso, temos um ponto inicial e um ponto final
(estado terminal). Isso cria um episódio : uma lista de estados, ações, recompensas e novos estados.
Veja o Super Mario Bros, por exemplo: o episódio começa com o lançamento do novo Mario e termina quando você é morto ou chega ao final do nível.
 O início de um novo episódioTarefas contínuasEssas são tarefas que duram para sempre (sem um estado terminal)
O início de um novo episódioTarefas contínuasEssas são tarefas que duram para sempre (sem um estado terminal) . Nesse caso, o agente deve aprender a escolher as melhores ações e ao mesmo tempo interagir com o ambiente.
Por exemplo, um agente que realiza negociação automatizada de ações. Não há ponto inicial nem estado terminal para esta tarefa.
O agente continua trabalhando até que decidimos detê-lo. Método Monte Carlo vs. Diferença de Tempo
Método Monte Carlo vs. Diferença de TempoExistem duas maneiras de aprender:
- Coletando recompensas no final do episódio e calculando as recompensas futuras máximas esperadas - abordagem Monte Carlo
- Avaliação das recompensas a cada passo - uma diferença temporária
Monte CarloQuando o episódio termina (o agente atinge um "estado terminal"), o agente analisa a recompensa acumulada total para ver o quão bem ele se saiu. Na abordagem de Monte Carlo, as recompensas são recebidas apenas no final do jogo.
Então começamos um novo jogo com conhecimento aumentado.
O agente toma as melhores decisões com cada iteração.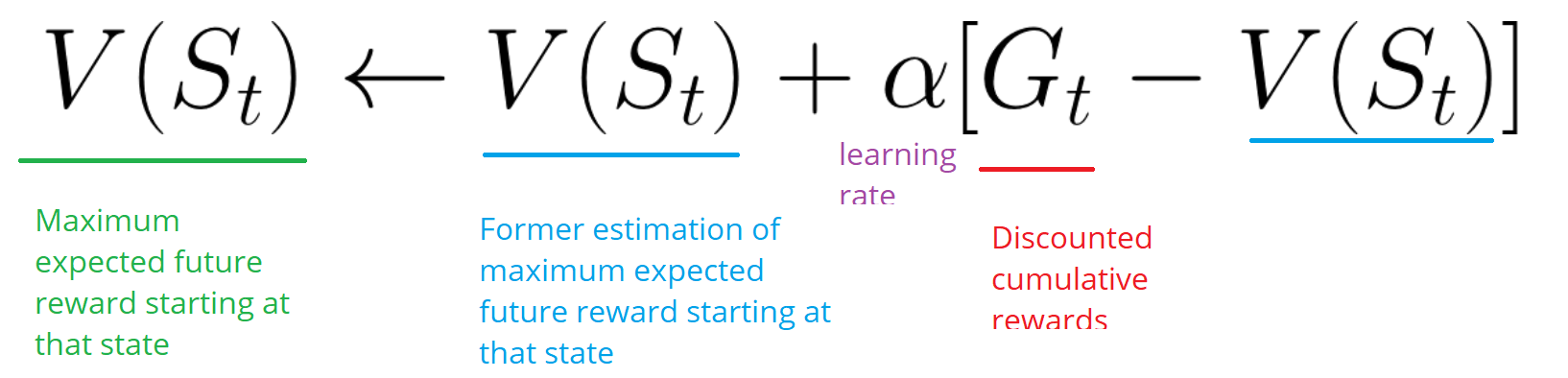
Aqui está um exemplo:
Se tomarmos o labirinto como um ambiente:
- Sempre começamos do mesmo ponto de partida.
- Paramos o episódio se o gato nos comer ou avançarmos> 20 passos.
- No final do episódio, temos uma lista de estados, ações, recompensas e novos estados.
- O agente resume a recompensa total de Gt (para ver como ele se saiu).
- Em seguida, ele atualiza V (st) de acordo com a fórmula acima.
- Então, um novo jogo começa com novos conhecimentos.
Executando mais e mais episódios, o
agente aprenderá a jogar cada vez melhor.Diferenças horárias: aprendendo a cada passoO método Temporal Difference Learning (TD) não aguardará o final do episódio para atualizar a maior recompensa possível. Ele atualizará o V dependendo da experiência adquirida.
Esse método é chamado de TD (0) ou
TD gradual (atualiza a função do utilitário após uma única etapa).
Os métodos TD esperam apenas que a próxima
etapa atualize os valores. No tempo t + 1
, um alvo TD é formado usando a recompensa Rt + 1 e a classificação atual V (St + 1).A meta de TD é uma estimativa do esperado: na verdade, você atualiza a pontuação V (St) anterior para a meta em uma etapa.
Exploração / Operação de CompromissoAntes de considerar várias estratégias para resolver problemas de treinamento de reforço, devemos considerar outro tópico muito importante: o compromisso entre exploração e exploração.
- A inteligência encontra mais informações sobre o ambiente.
- A exploração usa informações conhecidas para maximizar as recompensas.
Lembre-se de que o objetivo do nosso agente de RL é maximizar as recompensas acumuladas esperadas. No entanto, podemos cair em uma armadilha comum.
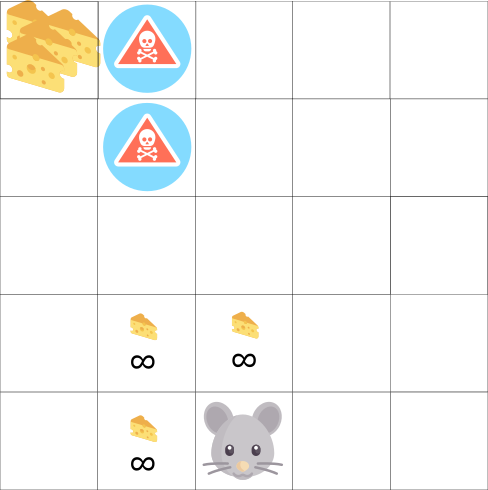
Neste jogo, nosso mouse pode ter um número infinito de pequenos pedaços de queijo (+1 cada). Mas no topo do labirinto há um pedaço gigante de queijo (+1000). No entanto, se focarmos apenas em recompensas, nosso agente nunca alcançará um pedaço gigantesco. Em vez disso, ele usará apenas a fonte de recompensas mais próxima, mesmo que essa fonte seja pequena (exploração). Mas se nosso agente reconhecer um pouco, ele será capaz de encontrar uma grande recompensa.
É o que chamamos de compromisso entre exploração e exploração. Devemos definir uma regra que ajude a lidar com esse compromisso. Nos próximos artigos, você aprenderá maneiras diferentes de fazer isso.
Três abordagens de aprendizado por reforçoAgora que identificamos os principais elementos do aprendizado por reforço, passemos a três abordagens para solucionar o aprendizado reforçado: baseado em custos, baseado em políticas e baseado em modelos.
Com base no custoNa RL baseada em custo, o objetivo é otimizar a função de utilidade V (s).
Uma função de utilitário é uma função que nos informa da recompensa máxima esperada que um agente receberá em cada estado.
O valor de cada estado é o valor total da recompensa que o agente pode esperar acumular no futuro, a partir desse estado.
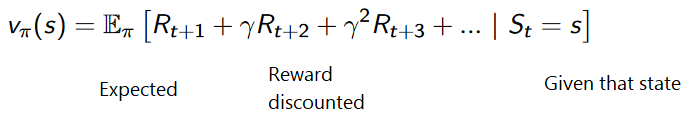
O agente usará essa função de utilitário para decidir qual estado escolher em cada etapa. O agente seleciona o estado com o valor mais alto.
No exemplo do labirinto, em cada etapa, obteremos o valor mais alto: -7, depois -6, depois -5 (etc.) para atingir a meta.
Baseado em políticasNa RL baseada em política, queremos otimizar diretamente a função de política π (s) sem usar a função de utilitário. Uma política é o que determina o comportamento de um agente em um determinado momento.
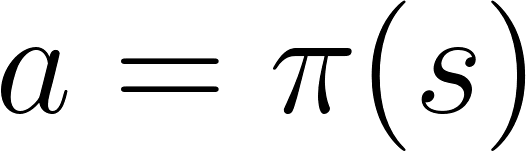 ação = política (estado)
ação = política (estado)Estudamos a função da política. Isso nos permite correlacionar cada estado com a melhor ação apropriada.
Existem dois tipos de políticas:
- Determinista: a política em um determinado estado sempre retornará a mesma ação.
- Estocástico: exibe a probabilidade de distribuição por ação.

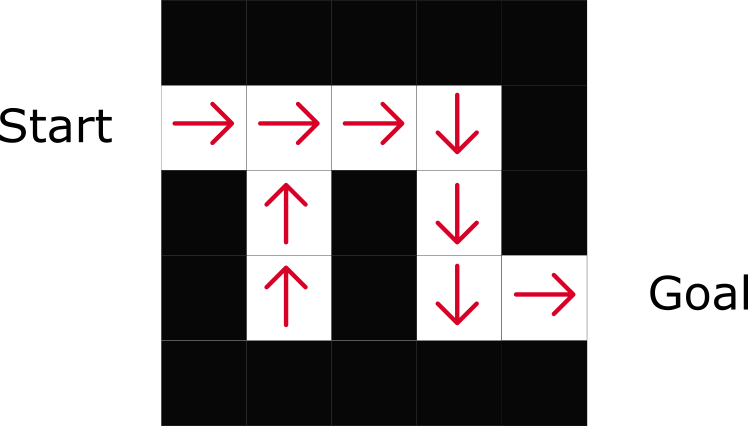
Como você pode ver, a política indica diretamente a melhor ação para cada etapa.
Baseado no modeloNa RL baseada em modelo, modelamos o ambiente. Isso significa que estamos criando um modelo de comportamento ambiental. O problema é que cada ambiente precisará de uma visão diferente do modelo. É por isso que não focaremos muito esse tipo de treinamento nos artigos a seguir.
Introdução ao aprendizado por reforço profundoO aprendizado profundo por reforço introduz redes neurais profundas para resolver os problemas do aprendizado reforçado - daí o nome "profundo".
Por exemplo, no próximo artigo, trabalharemos no Q-Learning (aprendizado de reforço clássico) e no Deep Q-Learning.
Você verá a diferença de que, na primeira abordagem, usamos o algoritmo tradicional para criar a tabela Q, o que nos ajuda a encontrar as ações a serem tomadas para cada estado.
Na segunda abordagem, usaremos uma rede neural (para aproximar as recompensas baseadas no estado: valor q).
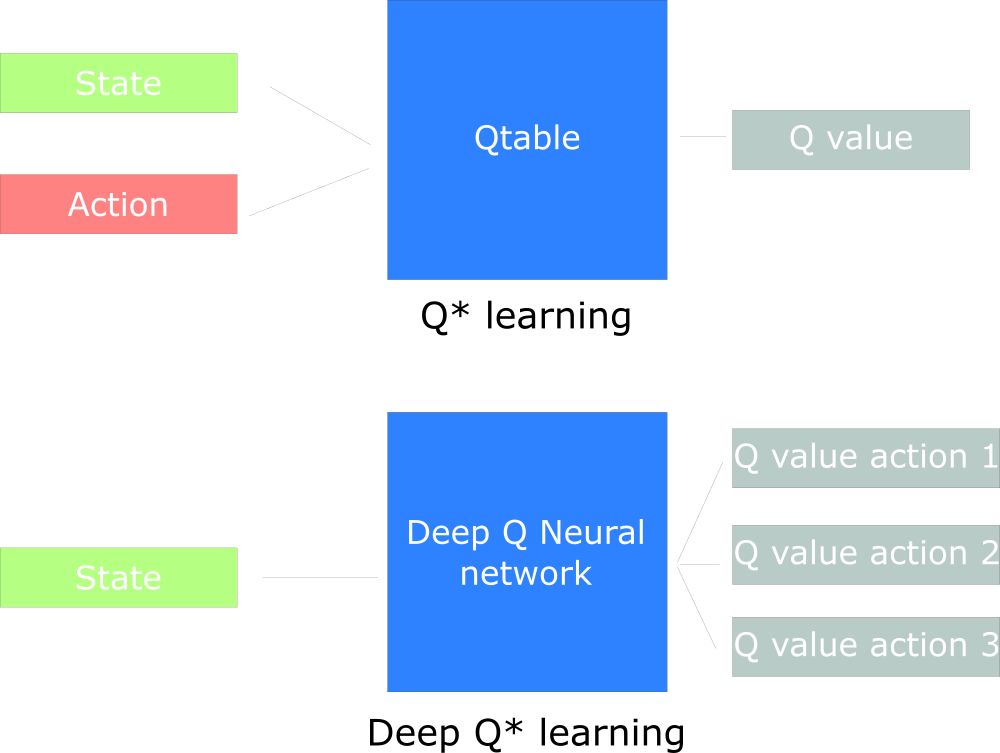 Udacity Inspired Q Design Chart
Udacity Inspired Q Design Chart
Isso é tudo. Como sempre, estamos aguardando seus comentários ou perguntas aqui, ou você pode pedir ao professor do curso
Arthur Kadurin em sua
lição aberta sobre networking.