
Como você sabe, o HTTP 1.1 é um protocolo de transferência de dados baseado em texto. As mensagens HTTP são codificadas usando a ISO-8859-1 (que pode ser considerada condicionalmente uma versão estendida do ASCII contendo tremas, diacríticos e outros caracteres usados nos idiomas da Europa Ocidental). Ao mesmo tempo, outra codificação pode ser usada no corpo da mensagem, que deve ser indicada no cabeçalho “Content-Type”. Mas e se precisarmos especificar caracteres não ASCII não no corpo da mensagem, mas nos próprios cabeçalhos? Provavelmente, o caso mais comum é colocar um nome de arquivo no cabeçalho "Disposição de conteúdo". Isso parece ser uma tarefa bastante comum, mas sua implementação não é tão óbvia.
TL; DR: Use a codificação descrita na
RFC 6266 para “Disposição de conteúdo” e converta o texto em latim (transliteração) em outros casos.
Uma pequena introdução às codificações
O artigo menciona e usa codificações US-ASCII (geralmente chamadas simplesmente de ASCII), ISO-8859-1 e UTF-8. Esta é uma pequena introdução a essas codificações. A seção é direcionada a desenvolvedores que raramente ou completamente não trabalham com codificações e conseguiram esquecê-las. Se você não pertence a eles, fique à vontade para pular a seção.
ASCII é uma codificação simples que contém 128 caracteres e inclui todo o alfabeto inglês, números, sinais de pontuação e caracteres de serviço.
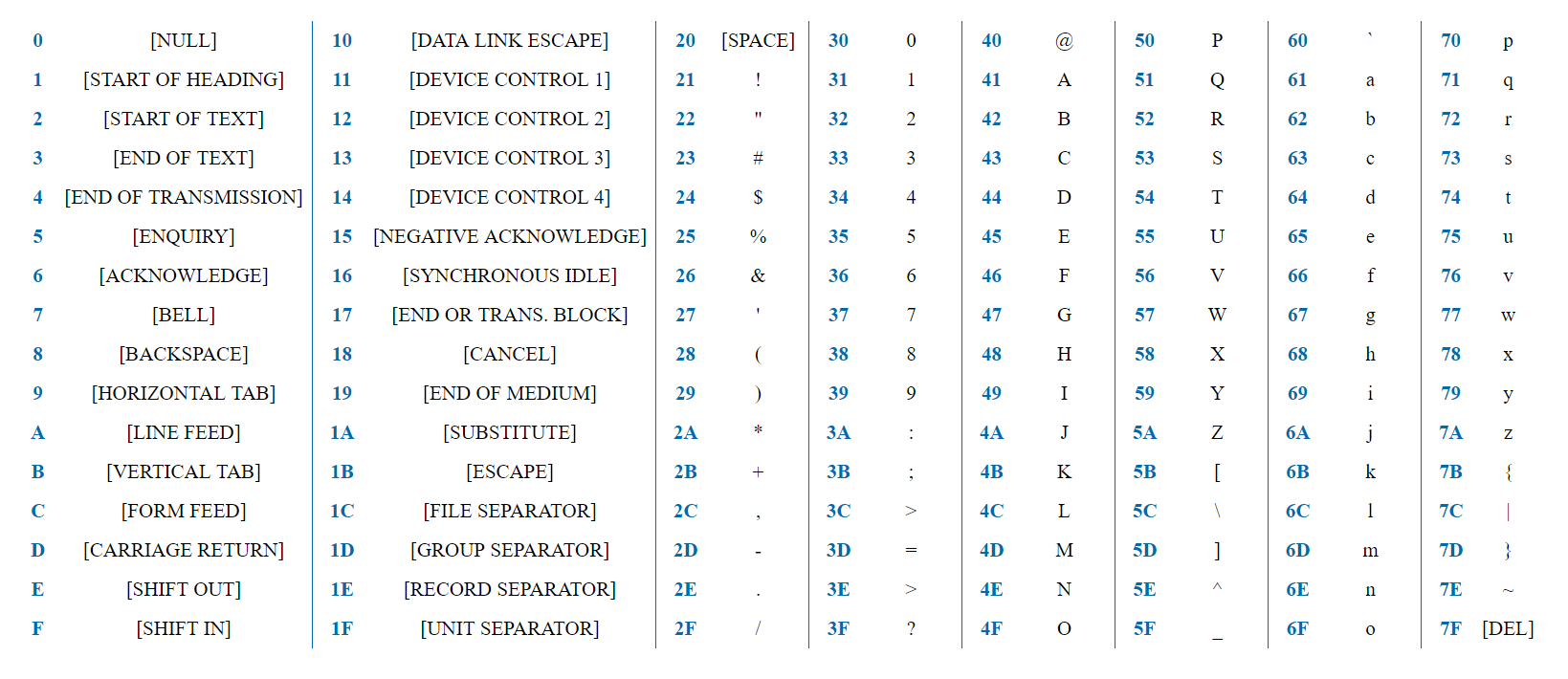
7 bits é suficiente para representar qualquer caractere ASCII. A palavra "teste" será representada na representação HEX como 0x74 0x65 0x73 0x74. O primeiro bit para todos os caracteres é sempre 0, porque os caracteres são codificados em 128 e o byte fornece 2 ^ 8 = 256 opções.
ISO-8859-1 é uma codificação destinada aos idiomas da Europa Ocidental. Contém diacríticos franceses, tremados alemães, etc.
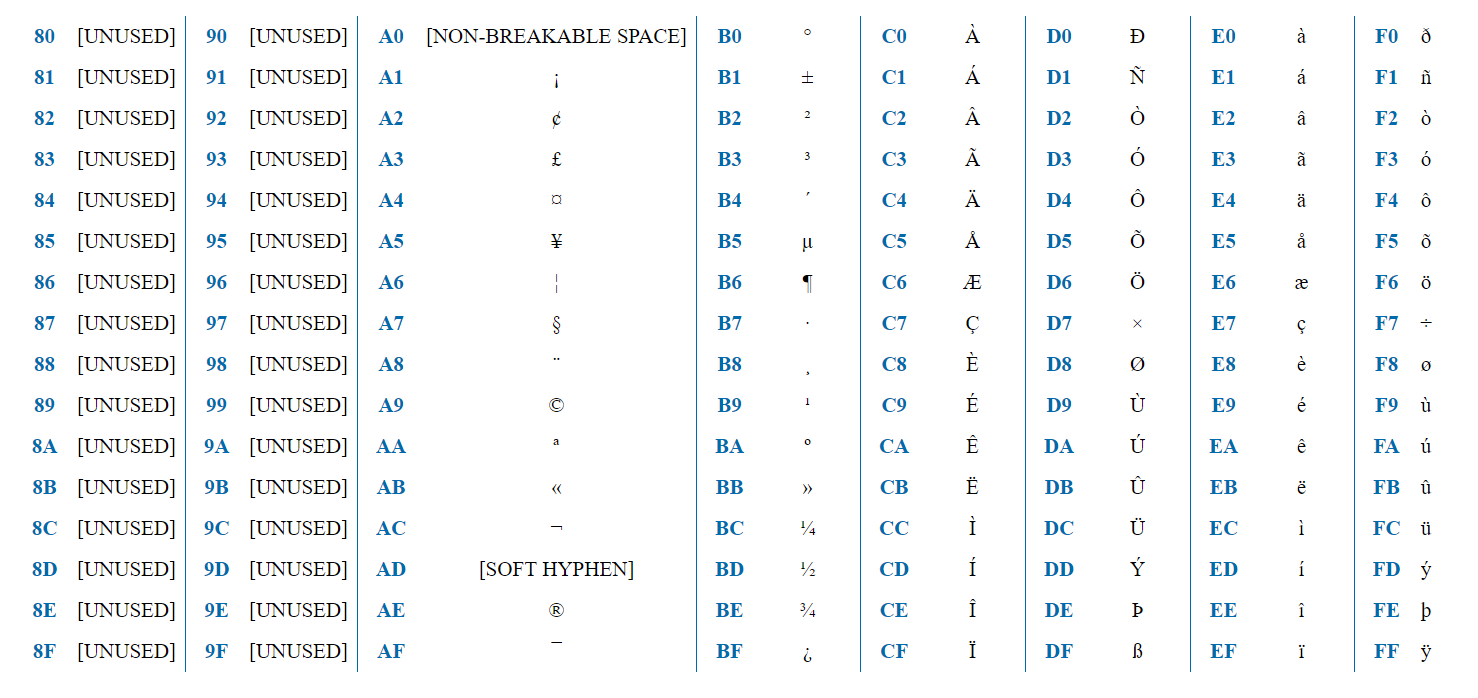
A codificação contém 256 caracteres e, portanto, pode ser representada por um byte. A primeira metade (128 caracteres) é exatamente igual à ASCII. Portanto, se o primeiro bit = 0, esse é um caractere ASCII comum. Se 1, esse é um caractere específico da ISO-8859-1.
UTF-8 é uma das codificações mais famosas junto com o ASCII. Capaz de codificar 1.112.064 caracteres.
O tamanho de cada caractere varia de 1 a 4 bytes (
anteriormente, até 6 bytes eram permitidos).

O programa que trabalha com essa codificação determina pelos primeiros bits quantos bytes estão incluídos no caractere. Se o octeto começar em 0, o caractere será representado por um byte. 110 - dois bytes, 1110 - três bytes, 11110 - 4 bytes.
Assim como no ISO-8859-1, os primeiros 128 caracteres são totalmente compatíveis com ASCII. Portanto, textos usando apenas caracteres ASCII serão absolutamente idênticos na representação binária, independentemente de US-ASCII, ISO-8859-1 ou UTF-8 ter sido usado para codificação.
Usando UTF-8 no corpo de uma mensagem
Antes de passar para os cabeçalhos, vamos dar uma rápida olhada em como usar o UTF-8 no corpo das mensagens. Para fazer isso, use o cabeçalho
"Content-Type" .

Se o "Tipo de conteúdo" não for especificado, o navegador deverá processar as mensagens como se elas estivessem escritas na ISO-8859-1.
O navegador não deve tentar adivinhar a codificação e, além disso, ignorar o "Tipo de conteúdo". Mas o que realmente aparece em uma situação em que o "Tipo de Conteúdo" não é transmitido depende da implementação do navegador. Por exemplo, o Firefox fará as especificações e lerá a mensagem como se estivesse codificada na ISO-8859-1. O Google Chrome, por outro lado, usará a codificação do sistema operacional, que para muitos usuários russos é igual ao Windows-1251. De qualquer forma, se a mensagem estiver em UTF-8, ela não será exibida corretamente.

Colocamos a mensagem UTF-8 no valor do cabeçalho
Com o corpo da mensagem, tudo é bem simples. O corpo da mensagem sempre segue os cabeçalhos, portanto, não há problemas técnicos. Mas e as manchetes? A especificação
declara explicitamente que a ordem dos cabeçalhos na mensagem não importa. I.e. não é possível especificar a codificação em um cabeçalho através de outro cabeçalho.
O que acontece se você pegar e gravar o valor UTF-8 no valor do cabeçalho? Vimos que esse truque com o corpo da mensagem resultará na simples leitura do valor na ISO-8859-1. Seria lógico supor que o mesmo acontecerá com o título. Mas isso não é verdade. De fato, em muitos, se não na maioria dos casos, essa solução funcionará. Isso inclui iPhones antigos, IE11, Firefox, Google Chrome. O único navegador na ponta dos meus dedos, quando escrevi este artigo que não queria trabalhar com esse título, era o Edge.

Esse comportamento não é registrado nas especificações. Talvez os desenvolvedores do navegador tenham decidido facilitar a vida dos desenvolvedores e detectar automaticamente que os cabeçalhos das mensagens foram codificados em UTF-8. Em geral, essa não é uma tarefa tão difícil. Nós olhamos para o primeiro bit: se 0, então ASCII, se 1 - então, possivelmente, UTF-8.
Existe alguma interseção com a ISO-8859-1 neste caso? De fato, quase nenhum. Tomemos, por exemplo, UTF-8 um caractere de 2 octetos (as letras russas são representadas por dois octetos). O símbolo no binário apresentado será semelhante a:
110xxxxx 10xxxxxx . Na representação HEX:
[0xC0-0x6F] [0x80-0xBF] . Na ISO-8859-1, esses caracteres dificilmente podem codificar algo que carrega uma carga semântica. Portanto, o risco de o navegador descriptografar a mensagem incorretamente é muito pequeno.
No entanto, ao tentar usar esse método, você pode encontrar problemas técnicos: seu servidor ou estrutura da Web pode simplesmente não permitir a gravação de caracteres UTF-8 no valor do cabeçalho. Por exemplo, o Apache Tomcat coloca 0x3F (ponto de interrogação) em vez de todos os caracteres UTF-8. Obviamente, essa restrição pode ser contornada, mas se o aplicativo em si estiver apertando as mãos e não permitir que algo seja feito, talvez você não precise fazer isso.
Mas, independentemente de sua estrutura ou servidor permitir que você escreva mensagens UTF-8 no cabeçalho ou não, eu não recomendo fazer isso. Esta não é uma solução documentada que pode parar de funcionar em navegadores a qualquer momento.
Translit
Eu acho que o translit é usado - para bolee horoshee reshenie. Muitos grandes recursos populares da Rússia não desdenham de usar a transliteração nos nomes de arquivos. Esta é uma solução garantida que não será interrompida com o lançamento de novos navegadores e que não precisará ser testada separadamente em cada plataforma. Embora, é claro, você precise pensar em como converter todo o espectro de caracteres possíveis, o que pode não ser completamente trivial. Por exemplo, se o aplicativo foi projetado para um público russo, as letras atar e T do Tatar podem aparecer no nome do arquivo, que deve ser processado de alguma forma e não apenas substituído por "?".
RFC 2047
Como já mencionei, o tomkat não me permitiu colocar UTF-8 no cabeçalho da mensagem. Esse recurso de comportamento é refletido nos documentos Java para servlets? Sim, refletido:
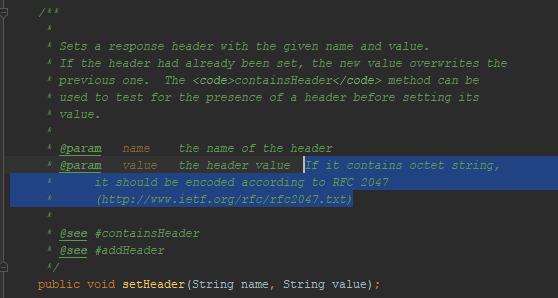
Mencionado
RFC 2047 . Tentei codificar mensagens usando este formato - o navegador não me entendeu. Este método de codificação não funciona em HTTP. Embora ele tenha trabalhado antes. Por exemplo, um
ticket para remover o suporte para essa codificação do Firefox.
RFC 6266
No tíquete, cujo link está na seção anterior,
há referências de que, mesmo após o término do suporte à RFC 2047, ainda há uma maneira de transferir valores UTF-8 no nome dos arquivos baixados:
RFC 6266 . Na minha opinião, esta é a decisão mais correta até o momento. Muitos recursos online populares o utilizam. Nós da
Plataforma CUBA também usamos essa RFC específica para gerar a "Disposição de Conteúdo".
O RFC 6266 é uma especificação que descreve o uso do cabeçalho "Disposição de conteúdo". O próprio método de codificação é descrito em detalhes em outra especificação,
RFC 8187 .

O parâmetro "filename" contém o nome do arquivo em ASCII, "filename *" - em qualquer codificação necessária. Com os dois atributos, o "nome do arquivo" é ignorado em todos os navegadores modernos (incluindo o IE11 e versões anteriores do Safari). A maioria dos navegadores antigos, por outro lado, ignora "filename *".
Ao usar esse método de codificação, o parâmetro primeiro indica a codificação, seguida pelo valor codificado. Caracteres visíveis da codificação ASCII não requerem. Os caracteres restantes são simplesmente escritos em representação hexadecimal, com um "%" antes de cada octeto.
O que fazer com outros cabeçalhos?
A codificação descrita na RFC 8187 não é universal. Sim, você pode colocar um parâmetro com um prefixo * no cabeçalho, e isso pode até funcionar para alguns navegadores, mas a
especificação prescreve que não o faça.
Nos dois casos em que o UTF-8 é suportado nos cabeçalhos, atualmente há uma menção explícita disso no RFC relevante. Além da Disposição de Conteúdo, essa codificação é usada, por exemplo, em
Vinculação na
Web e
Autenticação de Acesso Digest .
Note-se que os padrões nesta área estão mudando constantemente. O uso da codificação descrita acima no HTTP foi
proposto apenas em 2010 . O uso dessa codificação em "Content-Disposition" foi
corrigido no padrão em 2011 . Apesar de esses padrões estarem apenas
no estágio "Padrão proposto" , eles são suportados em todos os lugares. A opção de que, no futuro, esperamos novos padrões que permitam um trabalho mais uniforme com diferentes codificações nos cabeçalhos não está descartada. Portanto, resta apenas acompanhar as novidades no mundo dos padrões HTTP e seu nível de suporte no lado dos navegadores.