O reconhecimento óptico de caracteres (OCR) é o processo de obtenção de textos impressos em formato digitalizado. Se você leu um romance clássico em um dispositivo digital ou pediu a um médico para buscar registros médicos antigos através do sistema de computador do hospital, provavelmente usou o OCR.
O OCR torna o conteúdo anteriormente estático editável, pesquisável e compartilhável. Mas muitos documentos que precisam ser digitalizados contêm manchas de café, páginas com cantos enrolados e muitas rugas que mantêm alguns documentos impressos não digitalizados.
Todo mundo sabe que há milhões de livros antigos armazenados em armazenamento. É proibido o uso desses livros devido à sua dilapidação e decrepitude e, portanto, a digitalização desses livros é muito importante.
O artigo considera a tarefa de limpar o texto do ruído, reconhecendo o texto em uma imagem e convertendo-o para o formato de texto.

Para o treinamento, 144 fotos foram usadas. O tamanho pode ser diferente, mas de preferência deve estar dentro da razão. As imagens devem estar no formato PNG. Depois de ler a imagem, a binarização é usada - o processo de conversão de uma imagem colorida em preto e branco, ou seja, cada pixel é normalizado para um intervalo de 0 a 255, onde 0 é preto e 255 é branco.
Para treinar uma rede convolucional, você precisa de mais imagens do que existem. Foi decidido dividir as imagens em partes. Como a amostra de treinamento consiste em imagens de tamanhos diferentes, cada imagem foi compactada para 448x448 pixels. O resultado foi 144 imagens em uma resolução de 448x448 pixels. Todos eles foram cortados em janelas sem sobreposição, com 112 x 112 pixels de tamanho.

Assim, das 144 imagens iniciais, foram obtidas cerca de 2304 imagens no conjunto de treinamento. Mas isso não foi suficiente. É necessário mais treinamento para um bom treinamento em rede convolucional. Como resultado disso, a melhor opção era girar as imagens 90 graus, depois 180 e 270 graus. Como resultado, uma matriz com o tamanho [16.112.112,1] é fornecida à entrada da rede. Onde 16 é o número de imagens, 112 é a largura e a altura de cada imagem, 1 são os canais de cores. Foram 9216 exemplos de treinamento. Isso é suficiente para treinar uma rede convolucional.
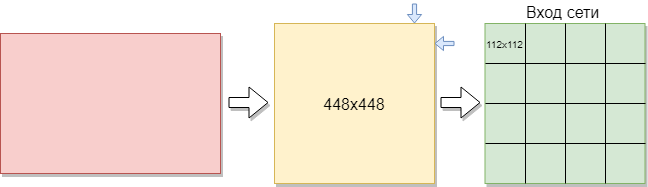
Cada imagem tem um tamanho de 112x112 pixels. Se o tamanho for muito grande, a complexidade computacional aumentará, respectivamente, as restrições à velocidade de resposta serão violadas, a determinação do tamanho neste problema será resolvida pelo método de seleção. Se você selecionar um tamanho muito pequeno, a rede não poderá identificar os principais sinais. Cada imagem tem um formato preto e branco, portanto, é dividida em 1 canal. As imagens coloridas são divididas em 3 canais: vermelho, azul, verde. Como temos imagens em preto e branco, o tamanho de cada imagem é 112x122x1 pixels.
Antes de tudo, é necessário treinar uma rede neural convolucional em imagens processadas e preparadas. Para esta tarefa, a arquitetura U-Net foi selecionada.
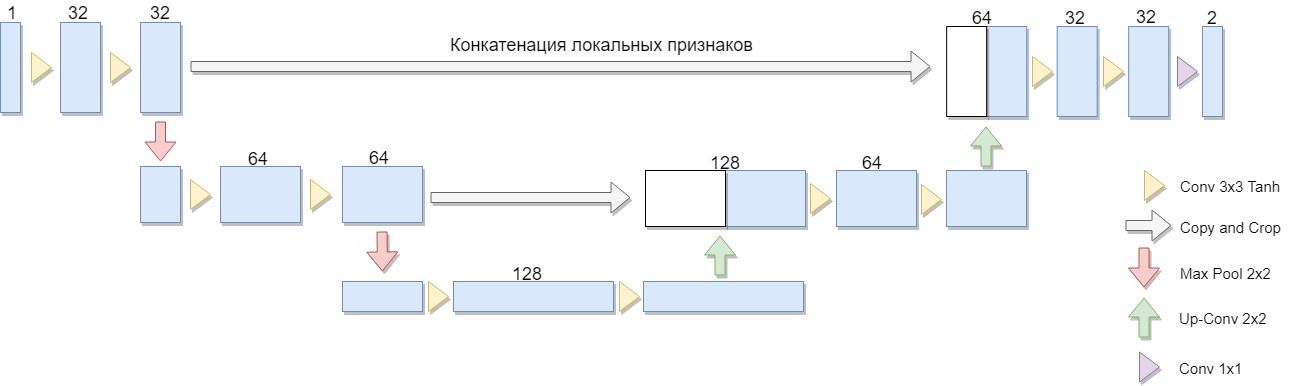
Uma versão reduzida da arquitetura foi selecionada, consistindo em apenas dois blocos (a versão original de quatro). Uma consideração importante foi o fato de que uma grande classe de algoritmos de binarização conhecidos é expressa explicitamente em uma arquitetura ou arquitetura semelhante (como exemplo, podemos modificar o algoritmo Niblack substituindo o desvio padrão pelo desvio médio, caso em que a rede é construída de maneira especialmente simples).
A vantagem dessa arquitetura é que, para treinar a rede, você pode criar uma quantidade suficiente de dados de treinamento a partir de um pequeno número de imagens de origem. Além disso, a rede possui um número relativamente pequeno de pesos devido à sua arquitetura convolucional. Mas existem algumas nuances. Em particular, a rede neural artificial usada, estritamente falando, não resolve o problema de binarização: para cada pixel da imagem de origem, associa um número de 0 a 1, que caracteriza o grau em que esse pixel pertence a uma das classes (preenchimento significativo ou plano de fundo) e que é necessário ainda converter para a resposta binária final. [1]
O U-Net consiste em um caminho de compactação e descompactação e "encaminha" entre eles. O caminho da compactação, nessa arquitetura, consiste em dois blocos (na versão original de quatro). Cada bloco possui duas convoluções com um filtro 3x3 (usando a função de ativação Tanh após a convolução) e um pool com um tamanho de filtro 2x2 nas etapas de 2. O número de canais em cada etapa para baixo dobra.
O caminho do aperto também consiste em dois blocos. Cada um deles consiste em uma "varredura" com um tamanho de filtro de 2x2, reduzindo pela metade o número de canais, concatenação com um mapa de recurso cortado correspondente do caminho de compressão ("encaminhamento") e duas convoluções com um filtro 3x3 (usando a função de ativação Tanh após a convolução). Em seguida, na última camada, uma convolução 1x1 (usando a função de ativação Sigmoid) para obter uma imagem plana e de saída. Observe que o corte do mapa de recursos durante a concatenação é essencial devido à perda de pixels de limite para cada convolução. Adam foi escolhido como o método de otimização estocástica.
Em geral, a arquitetura é uma sequência de convolução + camadas de pool que reduzem a resolução espacial da imagem e aumentam combinando-a com os dados da imagem com antecedência e passando pelas outras camadas da convolução. Assim, a rede atua como uma espécie de filtro. [2]
A amostra de teste consistiu em imagens semelhantes, as diferenças foram apenas na textura do ruído e no texto. Os testes de rede ocorreram nesta imagem.

Na saída da rede neural convolucional, é obtida uma matriz de números com um tamanho de [16.112.112,1]. Cada número é um pixel separado processado pela rede. As imagens têm um formato de 112x112 pixels, como antes, foram cortadas em pedaços. Ela precisa trair a aparência original. Combinamos as imagens obtidas em uma parte, como resultado, a imagem tem um formato de 448x448. Em seguida, multiplicamos cada número na matriz por 255 para obter um intervalo de 0 a 255, onde 0 é preto e 255 é branco. Retornamos a imagem ao seu tamanho original, como antes, ela foi compactada. O resultado é a figura abaixo na figura.

Neste exemplo, observa-se que a rede convolucional lidou com a maior parte do ruído e mostrou-se eficiente. Mas é claramente visível que a imagem ficou mais nublada e os ruídos perdidos são visíveis. No futuro, isso pode afetar a precisão do reconhecimento de texto.
Com base nesse fato, decidiu-se usar outra rede neural - um perceptron multicamada. No resultado esperado, a rede deve tornar o texto na imagem mais nítido e remover o ruído que está faltando na rede neural convolucional.
Uma imagem já processada pela rede de convolução é enviada para a entrada do perceptron de múltiplas camadas. Nesse caso, a amostra de treinamento para esta rede será diferente da amostra da rede convolucional, uma vez que as redes processam a imagem de maneira diferente. A rede convolucional é considerada a rede principal e remove a maior parte do ruído na imagem, enquanto o perceptron multicamada processa o que o convolucional não conseguiu.
Aqui estão alguns exemplos do conjunto de treinamento para um perceptron de várias camadas.

Os dados da imagem foram obtidos através do processamento da amostra de treinamento para a rede convolucional com um perceptron multicamada. Ao mesmo tempo, o perceptron foi treinado na mesma amostra, mas em um pequeno número de exemplos e um pequeno número de épocas.
Para o treinamento de perceptron, 36 imagens foram processadas. A rede é treinada pixel por pixel, ou seja, um pixel da imagem é enviado para a entrada da rede. Na saída da rede, também temos um neurônio de saída - um pixel, ou seja, a resposta da rede. Para aumentar a precisão do processamento, foram feitos 29 neurônios de entrada. E na imagem obtida após o processamento pela rede de convolução, 28 filtros são sobrepostos. O resultado são 29 imagens com filtros diferentes. Enviamos um pixel de cada imagem 29 para a entrada da rede e apenas um pixel é recebido na saída da rede, ou seja, a resposta da rede.
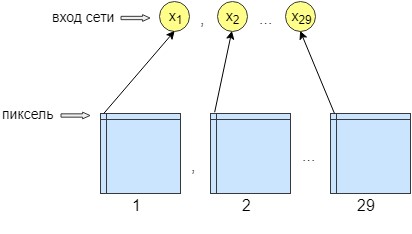
Isso foi feito para melhor treinamento e networking. Depois disso, a rede começou a aumentar a precisão e o contraste da imagem. Ele também limpa pequenos erros que não conseguiam limpar a rede convolucional.
Como resultado, a rede neural possui 29 neurônios de entrada, um pixel de cada imagem. Após os experimentos, verificou-se que era necessária apenas uma camada oculta, na qual 500 neurônios. Existe apenas uma saída da rede. Como o treinamento ocorreu pixel por pixel, a rede foi acessada n * m vezes, onde n é a largura da imagem e m é a altura, respectivamente.

Depois de processar a imagem sequencialmente por duas redes neurais, a principal coisa que resta é reconhecer o texto. Para isso, foi utilizada uma solução pronta, a biblioteca Python Pytesseract. O Pytesseract não fornece ligações Python verdadeiras. Em vez disso, é um invólucro simples para o binário tesseract. Nesse caso, o tesseract é instalado separadamente no computador. O Pytesseract salva a imagem em um arquivo temporário no disco e, em seguida, chama o arquivo binário do tesseract e grava o resultado em um arquivo.
Este wrapper foi desenvolvido pelo Google e é gratuito e gratuito. Pode ser usado tanto para fins pessoais quanto comerciais. A biblioteca funciona sem conexão à Internet, suporta vários idiomas para reconhecimento e impressiona com sua velocidade. Sua aplicação pode ser encontrada em várias aplicações populares.
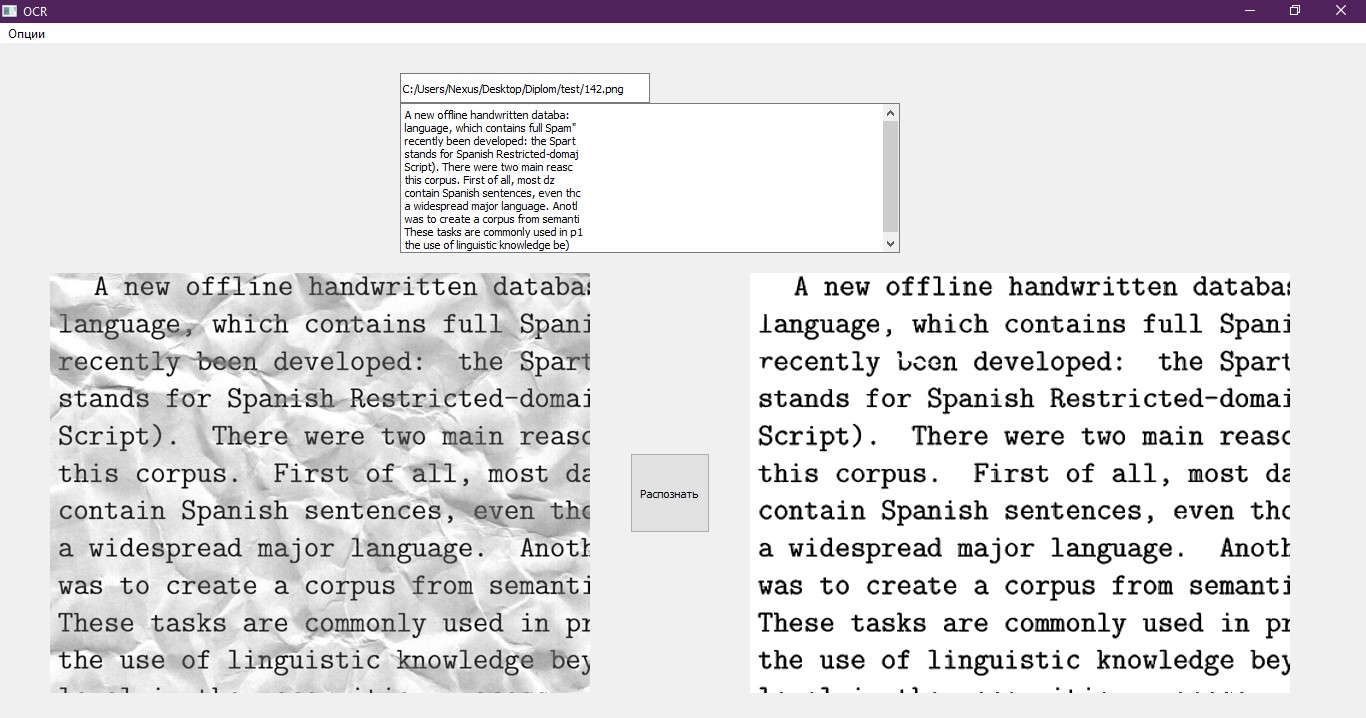
O último item que resta é gravar o texto reconhecido em um arquivo em um formato adequado para processá-lo. Utilizamos para isso um notebook comum, que é aberto após o término do programa. Além disso, o texto é exibido na interface de teste. Um bom exemplo de uma interface.
Referências:
- A história da vitória no concurso internacional de reconhecimento de documentos da equipe SmartEngines [Recurso eletrônico]. Modo de acesso: https://habr.com/company/smartengines/blog/344550/
- Segmentação de imagens usando uma rede neural: U-Net [Recurso eletrônico]. Modo de acesso: http://robocraft.ru/blog/machinelearning/3671.html
> Repositório do Github