
Olá pessoal!
Continuando o estudo do tópico de
aprendizagem profunda , uma vez quisemos conversar com você sobre
por que as ovelhas parecem estar em toda parte nas redes neurais . Este tópico é
discutido no capítulo 9 do livro de François Scholl.
Assim, fomos aos maravilhosos estudos da Positive Technologies,
apresentados em Habré , bem como ao excelente trabalho de dois funcionários do MIT, que consideram que o “aprendizado de máquina malicioso” não é apenas um obstáculo e um problema, mas também uma maravilhosa ferramenta de diagnóstico.
Próximo - sob o corte.
Nos últimos anos, casos de interferência maliciosa atraíram muita atenção na comunidade de aprendizado profundo. Neste artigo, gostaríamos de descrever esse fenômeno em termos gerais e discutir como ele se encaixa no contexto mais amplo da confiabilidade do aprendizado de máquina.
Intervenções maliciosas: um fenômeno intrigantePara delinear o escopo de nossa discussão, damos alguns exemplos dessa interferência maliciosa. Acreditamos que a maioria dos pesquisadores envolvidos na região de Moscou encontrou imagens semelhantes:
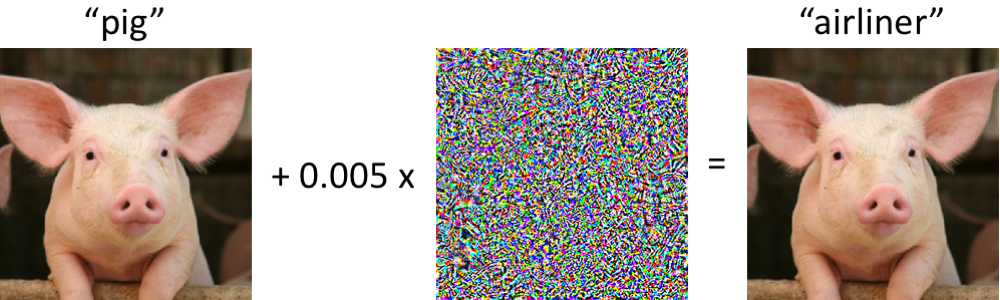
À esquerda, um porquinho, classificado corretamente como leitão pela moderna rede neural convolucional. Depois que fazemos alterações mínimas na imagem (todos os pixels estão no intervalo [0, 1] e cada um muda em não mais que 0,005) - e agora a rede retorna a classe "avião comercial" com alta confiabilidade. Esses ataques a classificadores treinados são conhecidos desde pelo menos 2004 (
link ), e os primeiros trabalhos sobre interferência maliciosa nos classificadores de imagem datam de 2006 (
link ). Então, esse fenômeno começou a atrair significativamente mais atenção desde 2013, quando as redes neurais são vulneráveis a ataques desse tipo (veja
aqui e
aqui ). Desde então, muitos pesquisadores propuseram opções para a construção de exemplos maliciosos, bem como formas de aumentar a resistência dos classificadores a esses distúrbios patológicos.
No entanto, é importante lembrar que não é necessário mergulhar nas redes neurais para observar exemplos maliciosos.
Quão robustos são os exemplos de malware?Talvez a situação em que o computador confunda o leitão com o avião possa ser alarmante no começo. No entanto, deve-se notar que o classificador usado neste caso (
rede Inception-v3 ) não é tão frágil quanto parece à primeira vista. Embora a rede provavelmente esteja enganada ao tentar classificar um leitão distorcido, isso só acontece no caso de violações especialmente selecionadas.
A rede é muito mais resistente a perturbações aleatórias de magnitude comparável. Portanto, a questão principal é se são distúrbios maliciosos que causam a fragilidade das redes. Se a maldade, como tal, é extremamente dependente do controle sobre cada pixel de entrada, ao classificar imagens em condições realistas, essas amostras maliciosas não parecem ser um problema sério.
Estudos recentes indicam o contrário: é possível garantir a estabilidade de perturbações a vários efeitos de canal em cenários físicos específicos. Por exemplo, amostras maliciosas podem ser impressas em uma impressora comum, para que as imagens fotografadas pela câmera de um smartphone
ainda não sejam classificadas corretamente . Você também pode fazer adesivos, por causa das quais as redes neurais classificam incorretamente várias cenas reais (consulte, por exemplo,
link1 ,
link2 e
link3 ). Finalmente, recentemente, os pesquisadores imprimiram uma tartaruga 3D em uma impressora 3D, que a rede Inception padrão
considera erroneamente
um rifle em quase qualquer ângulo de visão.
Preparação de ataque de classificação errôneaComo criar tais distúrbios maliciosos? Existem muitas abordagens, mas a otimização nos permite reduzir todos esses vários métodos a uma representação generalizada. Como você sabe, o treinamento do classificador é frequentemente formulado como localizando parâmetros do modelo
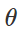
para minimizar a função de perda empírica para um determinado conjunto de exemplos

:
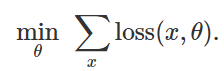
Portanto, para provocar uma classificação incorreta para um modelo fixo
e entrada "inofensiva"
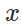
naturalmente tente encontrar um distúrbio limitado

de tal forma que as perdas em

acabou sendo o máximo:
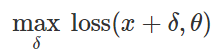
Com base nessa formulação, muitos métodos para criar dados maliciosos podem ser considerados vários algoritmos de otimização (etapas individuais do gradiente, descida projetada do gradiente etc.) para vários conjuntos de restrições (pequenos
perturbação normal, pequenas alterações em pixels, etc.). Vários exemplos são fornecidos nos seguintes artigos:
link1 ,
link2 ,
link3 ,
link4 e
link5 .
Como explicado acima, muitos métodos bem-sucedidos para gerar amostras maliciosas funcionam com um classificador de destino fixo. Portanto, a questão importante é: esses distúrbios não afetam apenas um modelo de alvo específico? Curiosamente, não. Ao usar muitos métodos de perturbação, as amostras maliciosas resultantes são transferidas do classificador para o classificador treinado com um conjunto diferente de valores aleatórios iniciais (sementes aleatórias) ou diferentes arquiteturas de modelo. Além disso, você pode criar amostras mal-intencionadas que têm apenas acesso limitado ao modelo de destino (às vezes, nesse caso, elas falam sobre "ataques de caixa preta"). Consulte, por exemplo, os cinco artigos a seguir:
link1 ,
link2 ,
link3 ,
link4 e
link5 .
Não apenas imagensAmostras maliciosas são encontradas não apenas na classificação das imagens. Fenômenos semelhantes são conhecidos no
reconhecimento de fala , nos
sistemas de perguntas e respostas , no
aprendizado reforçado e na solução de outros problemas. Como você já sabe, o estudo de amostras maliciosas já dura mais de dez anos:
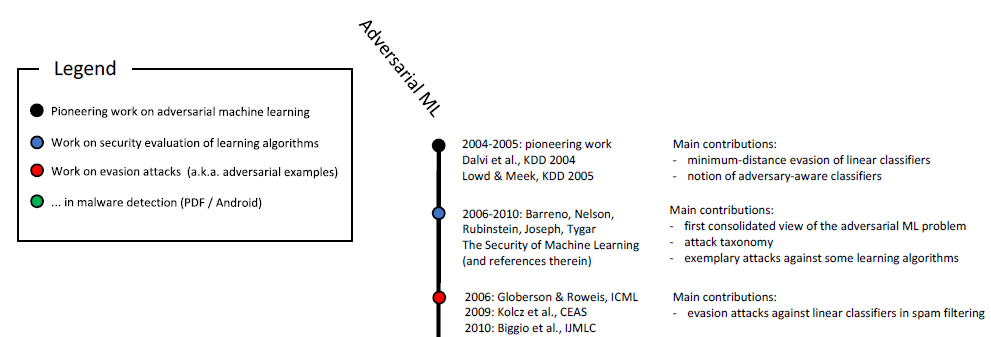
Escala cronológica do aprendizado de máquina mal-intencionado (início). A escala completa é mostrada na fig. 6
neste estudo .
Além disso, os aplicativos relacionados à segurança são um meio natural para estudar os aspectos maliciosos do aprendizado de máquina. Se um invasor puder enganar o classificador e transmitir informações maliciosas (por exemplo, spam ou vírus) como inofensivas, um detector de spam ou um antivírus baseado no aprendizado de máquina será
ineficaz . Deve-se enfatizar que essas considerações não são puramente acadêmicas. Por exemplo, a equipe do Google Safebrowsing em 2011 publicou um
estudo de
vários anos sobre como os invasores tentavam burlar seus sistemas de detecção de malware. Consulte também este
artigo sobre amostras maliciosas no contexto da filtragem de spam no e-mail do GMail.
Não apenas segurançaTodo o trabalho mais recente sobre o estudo de amostras mal-intencionadas é claramente sustentado na chave para garantir a segurança. Esse é um ponto de vista razoável, mas acreditamos que essas amostras devem ser consideradas em um contexto mais amplo.
ConfiabilidadeAntes de tudo, amostras maliciosas levantam a questão da confiabilidade de todo o sistema. Antes de podermos discutir razoavelmente as propriedades do classificador do ponto de vista da segurança, precisamos garantir que o mecanismo ofereça alta precisão de classificação. No final, se vamos implantar nossos modelos treinados em cenários do mundo real, é necessário que eles demonstrem um alto grau de confiabilidade ao alterar a distribuição dos dados subjacentes - independentemente de essas alterações serem causadas por interferência maliciosa ou apenas flutuações naturais.
Nesse contexto, as amostras de malware são uma ferramenta de diagnóstico útil para avaliar a confiabilidade dos sistemas de aprendizado de máquina. Em particular, a abordagem sensível a malware permite ir além do protocolo de avaliação padrão, onde o classificador treinado é executado em um conjunto de testes cuidadosamente selecionado (e geralmente estático).
Então você pode chegar a conclusões surpreendentes. Por exemplo, pode-se criar facilmente amostras maliciosas sem sequer recorrer a métodos sofisticados de otimização. Em um
artigo recente, mostramos que classificadores de imagem de ponta são surpreendentemente vulneráveis a pequenas transições ou voltas patológicas. (Veja
aqui e
aqui outros trabalhos sobre este tópico.)

Portanto, mesmo se não atribuirmos importância a, digamos, perturbações da descarga, problemas com confiabilidade devido a rotações e transições frequentemente surgem. Em um sentido mais amplo, é necessário entender os indicadores de confiabilidade de nossos classificadores antes que eles possam ser integrados em sistemas maiores como componentes realmente confiáveis.
O conceito de classificadoresPara entender como um classificador treinado funciona, você precisa encontrar exemplos de suas operações claramente bem-sucedidas ou malsucedidas. Nesse caso, amostras maliciosas ilustram que as redes neurais treinadas geralmente não correspondem à nossa compreensão intuitiva do que significa "aprender" um conceito específico. Isso é especialmente importante na aprendizagem profunda, onde algoritmos e redes biologicamente plausíveis, cujo sucesso não é inferior ao sucesso humano, são frequentemente reivindicados (veja, por exemplo,
aqui ,
aqui ou
aqui ). Amostras maliciosas claramente fazem uma dúvida sobre isso em muitos contextos:
- Ao classificar imagens, se o conjunto de pixels for minimamente alterado ou a imagem girar levemente, isso dificilmente impedirá uma pessoa de atribuí-la à categoria correta. No entanto, essas mudanças são completamente cortadas pelos classificadores mais modernos. Se você colocar objetos em um local incomum (por exemplo, ovelhas em uma árvore ), também é fácil garantir que a rede neural interprete a cena de maneira bem diferente de um ser humano.
- Se você substituir as palavras necessárias em uma passagem de texto, poderá confundir seriamente o sistema de perguntas e respostas , embora, do ponto de vista de uma pessoa, o significado do texto não seja alterado devido a essas inserções.
- Neste artigo , exemplos de texto cuidadosamente selecionados mostram os limites do Google Translate.
Nos três casos, exemplos maliciosos ajudam a testar a força de nossos modelos atuais e enfatizam em quais situações esses modelos agem de maneira completamente diferente do que uma pessoa faria.
SegurançaPor fim, amostras maliciosas representam um perigo em áreas onde o aprendizado de máquina já está atingindo uma certa precisão no material "inofensivo". Há apenas alguns anos, tarefas como a classificação de imagens ainda eram muito ruins, portanto o problema de segurança nesse caso parecia secundário. No final, o grau de segurança de um sistema de aprendizado de máquina se torna significativo somente quando esse sistema começa a processar a entrada "inofensiva" com qualidade suficiente. Caso contrário, ainda não podemos confiar nas previsões dela.
Agora, em várias áreas, a precisão desses classificadores melhorou significativamente, e sua implantação em situações em que as considerações de segurança são críticas é apenas uma questão de tempo. Se queremos abordar isso de forma responsável, é importante investigar suas propriedades precisamente no contexto da segurança. Mas a questão da segurança precisa de uma abordagem holística. A criação de alguns recursos (por exemplo, um conjunto de pixels) é muito mais fácil do que, por exemplo, outras modalidades sensoriais, recursos categóricos ou metadados. No final, ao garantir a segurança, é melhor contar com precisão com os sinais difíceis ou mesmo quase impossíveis de mudar.
Resultados (é muito cedo para falhar?)Apesar do impressionante progresso no aprendizado de máquina que vimos nos últimos anos, é necessário levar em conta os limites de recursos das ferramentas que temos à nossa disposição. Há uma grande variedade de problemas (por exemplo, aqueles relacionados à honestidade, privacidade ou efeitos de feedback), e a confiabilidade é a maior preocupação. A percepção e a cognição humanas são resistentes a uma variedade de interferências ambientais de fundo. No entanto, amostras maliciosas demonstram que as redes neurais ainda estão muito longe da resiliência comparável.
Portanto, temos certeza da importância de estudar exemplos maliciosos. Sua aplicabilidade no aprendizado de máquina está longe de se limitar a questões de segurança, mas pode servir como um
padrão de diagnóstico para avaliar modelos treinados. A abordagem que utiliza amostras maliciosas se compara favoravelmente com procedimentos de avaliação padrão e testes estáticos, pois identifica falhas potencialmente não-óbvias. Se queremos entender a confiabilidade do aprendizado de máquina moderno, as conquistas mais recentes são importantes para investigar do ponto de vista de um invasor (selecionando corretamente amostras maliciosas).
Desde que nossos classificadores falhem, mesmo com alterações mínimas entre a distribuição de treinamento e teste, não podemos obter confiabilidade garantida satisfatória. No final, nos esforçamos para criar modelos que não apenas sejam confiáveis, mas que sejam consistentes com nossas idéias intuitivas sobre o que significa "estudar" um problema. Eles serão seguros, confiáveis e fáceis de implantar em uma ampla variedade de ambientes.