Olá% username%!
Mais recentemente, a conferência Highload ++ terminou (obrigado novamente a toda a equipe de organizadores e
olegbunin pessoalmente. Foi muito legal!).
Na véspera da conferência, Alexey
Fisher propôs a criação de um grupo de iniciativas de “perseguidores” na conferência. Durante os relatórios, escrevemos pequenas anotações que trocamos. Algumas notas foram bastante detalhadas e detalhadas.
A comunidade nas redes sociais avaliou positivamente esse formato, então eu (com permissão) decidi publicar uma sinopse do primeiro relatório. Se esse formato for interessante, eu posso preparar vários outros artigos.

Dirigiu
O Avito tem muitos serviços e muitas conexões entre eles. Isso causa problemas:
- Muitos repositórios. É difícil mudar o código em todos os lugares ao mesmo tempo
- As equipes são limitadas pelo seu contexto. Sobreposição máxima ligeiramente e nem todos
- A fragmentação dos dados é adicionada.
Um grande número de elementos de infraestrutura:
- Registo
- Solicitar rastreamento (Jaeger)
- Agregação de Erros (Sentinela)
- Status / Mensagens / Eventos do Kubernetes
- Limite de corrida / disjuntor (Hystrix)
- Conectividade de Serviço (Istio)
- Monitoramento (Grafana)
- Montagem (Teamcity)
- Comunicação
- Rastreador de tarefas
- A documentação
- ...
Há várias camadas; o relatório descreve apenas uma (PaaS).
A plataforma possui 3 partes principais:
- Geradores controlados por cli
- Agregador (coletor), controlado por um painel
- Armazenamento com gatilhos para determinadas ações.
Pipeline de desenvolvimento de microsserviço padrão
CLI-push -> CI -> Bake -> Implementar -> Teste -> Canárias -> ProduçãoCLI-push
Durante muito tempo ensinou a fazer os desenvolvedores certos. Mesmo assim, permaneceu um ponto fraco.
Automatizado através do utilitário cli que ajuda a criar uma base para o microsserviço:
- Cria um serviço de modelo (modelos para vários PLs são suportados).
- Implanta automaticamente a infraestrutura para desenvolvimento local
- Conecta um banco de dados (não requer configuração, o desenvolvedor não pensa em acessar nenhum banco de dados).
- Construção ao vivo
- Gerar autoteste de disco.
A configuração é descrita no arquivo toml.
Arquivo de exemplo:
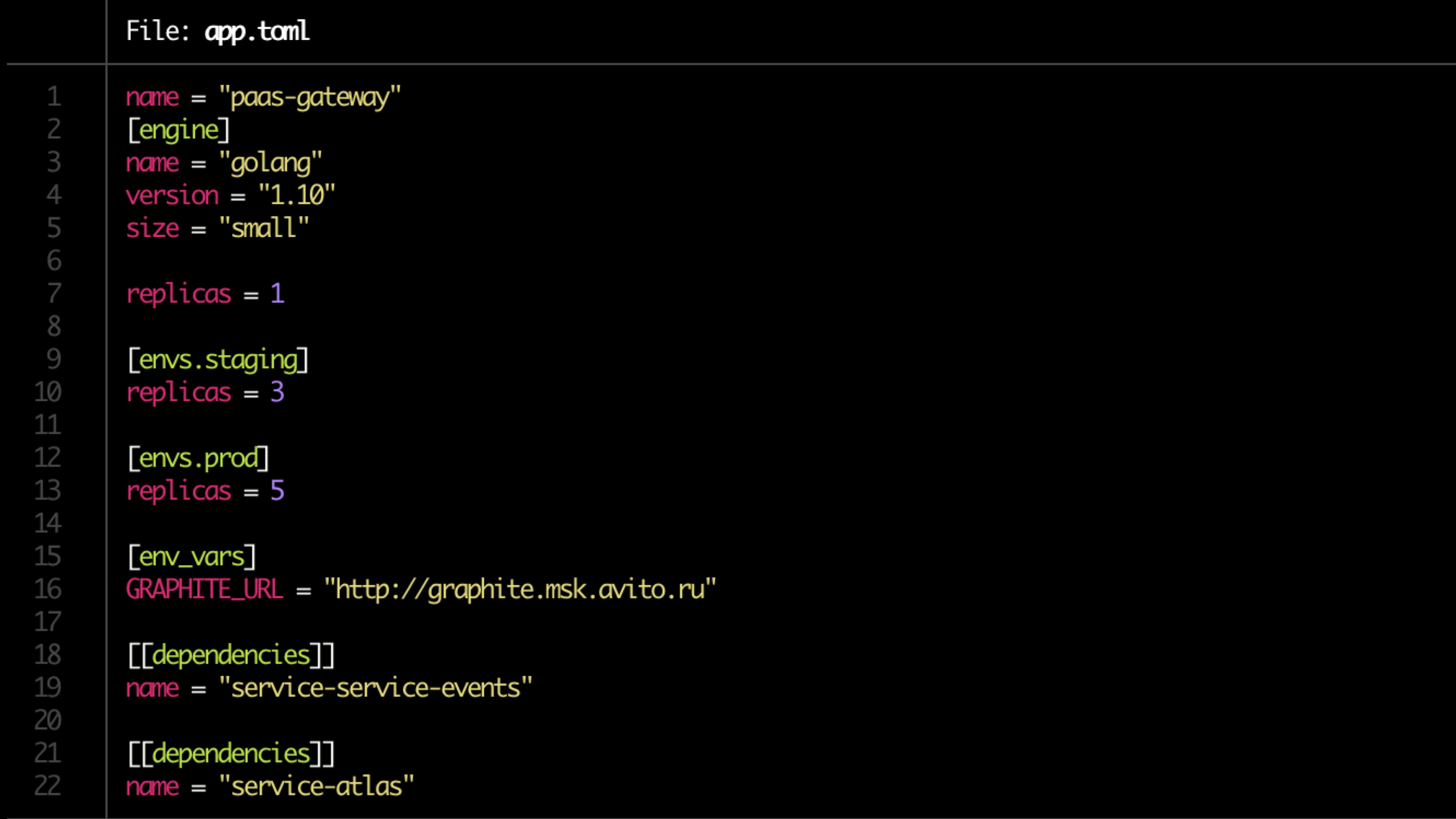
Validação
Verificações básicas de validação:
- Disponibilidade do Dockerfile
- app.toml
- Disponibilidade de documentação
- Dependências
- Regras de alerta para monitoramento (definidas pelo proprietário do serviço)
A documentação
Todos devem ter documentação, mas quase ninguém a possui
A documentação deve incluir:
- Descrição do serviço (breve)
- Link para o diagrama da arquitetura
- Runbook
- Perguntas frequentes
- Descrição da API do nó de extremidade
- Etiquetas (encadernação ao produto, funcionalidade, divisão estrutural)
- O proprietário do serviço (pode haver vários, na maioria dos casos, pode ser determinado automaticamente).
A documentação precisa ser revisada.
Preparação de tubulação
- Repositórios de cozinha
- Criando um pipeline no TeamCity
- Nós estabelecemos os direitos
- Estamos à procura do proprietário (dois, um não confiável)
- Registrar serviço no Atlas (produto interno)
- Verifique a migração.
Assar
- Construindo o aplicativo na imagem do Docker.
- Geração de gráficos de helm para o próprio serviço e recursos relacionados (banco de dados, cache)
- Os tickets são criados para os administradores abrirem portas, as restrições de memória e CPU são levadas em consideração.
- Execute testes de unidade. A cobertura do código está sendo mantida. Se abaixo de um certo, a implantação termina. Se a cobertura não progredir, as notificações serão enviadas.
A procura do proprietário é determinada pelo envio (o número de envio e a quantidade de código neles).
Se houver migrações potencialmente perigosas (alter), o gatilho será registrado no Atlas e o serviço será colocado em quarentena.
A quarentena é resolvida através do envio aos proprietários (no modo manual?)
Verificação da Convenção
Verificamos:
- Terminal de serviço
- Correspondência de respostas ao esquema
- Formato de log
- Configurando cabeçalhos (incluindo X-Source-ID ao enviar mensagens ao barramento para rastrear a conectividade através do barramento)
Testes
O teste é realizado em um circuito fechado (por exemplo, hoverfly.io) - uma carga típica é registrada. Em seguida, é emulado em um loop fechado.
A correspondência do consumo de recursos é verificada (analisamos separadamente casos extremos - poucos / muitos recursos), cortados por rps.
O teste de carga também mostra um delta de desempenho entre as versões.
Testes de canário
Iniciamos o lançamento com um número muito pequeno de usuários (<0,1%).
Carga mínima de 5 minutos. As 2 horas principais. Então o volume de usuários aumenta se tudo estiver ok.
Nós olhamos:
- Métricas do produto (antes de tudo) - existem muitas (100500)
- Erros de sentinela
- Status de resposta,
- Tempo dos respondentes - tempo exato e médio de resposta
- Latência
- Exceções (processadas e não processadas)
- Mais específico para o idioma métrico (por exemplo, trabalhadores php-fpm)
Teste de compressão
Teste de extrusão.
Carregamos usuários reais 1 instância até o ponto de falha. Nós olhamos para o seu teto. Em seguida, adicione outra instância e carregue-a. Nós olhamos para o próximo teto. Nós olhamos para a regressão. Enriquecemos ou substituímos os dados dos testes de carga no Atlas.
Dimensionamento
Somente a CPU é ruim, é necessário adicionar métricas do produto.
O esquema final:
- CPU + RAM
- Número de pedidos
- Tempo de resposta
- Previsão Histórica
Ao dimensionar, não se esqueça de examinar as dependências de serviço. Lembre-se da cascata de escala (nível +1). Examinamos os dados históricos do serviço de inicialização.
Opcional
- Manipulação de gatilho - migrações se não houver uma versão abaixo de X
- O serviço não é atualizado há muito tempo
- Quarentena
- Atualizações seguras
Dashboard
Analisamos tudo de cima de forma agregada e tiramos conclusões.
- Serviço e filtragem de etiquetas
- Integração com rastreamento, registro em log, monitoramento
- Documentação de serviço de ponto único
- Um único ponto de exibição de todos os eventos de serviço
Um exemplo:
