Vladimir Ivanov vivanov879 , Sr. O Deep Learning Engineer da NVIDIA continua a falar sobre o aprendizado por reforço. Este artigo se concentrará em treinar o agente para concluir missões e como as redes neurais usam filtros para reconhecer imagens.
Em um
artigo anterior, foi discutido o treinamento de agentes para atiradores simples.
Vladimir falará sobre a aplicação do aprendizado reforçado na prática na
Conferência da
AI em 22 de novembro.
A última vez que vimos exemplos de videogames, nos quais o treinamento por reforço ajuda a resolver o problema. Curiosamente, para o sucesso da rede neural, apenas informações visuais eram necessárias. Cada rede neural do quarto quadro analisa a captura de tela e toma uma decisão.
À primeira vista, parece mágica. Uma certa estrutura complexa, que é uma rede neural, recebe uma imagem na entrada e emite a solução certa. Vamos descobrir o que acontece por dentro: o que transforma um conjunto de pixels em ação?
Antes de passar para o computador, vamos descobrir o que uma pessoa vê.Quando uma pessoa olha para uma imagem, seu olhar se apega a pequenos detalhes (rostos, figuras de pessoas, árvores) e à imagem como um todo. Seja um jogo infantil no beco ou uma partida de futebol, uma pessoa pode entender o conteúdo, o humor e o contexto da imagem com base em sua experiência de vida.

Quando admiramos o trabalho de um mestre em uma galeria de arte, nossa experiência de vida ainda nos diz que os personagens estão escondidos atrás de camadas de tinta. Você pode adivinhar suas intenções e movimento na imagem.

No caso da pintura abstrata, o olho encontra figuras simples na imagem: círculos, triângulos, quadrados. Eles são muito mais fáceis de encontrar. Às vezes, isso é tudo o que pode ser visto.

Os itens podem ser organizados de forma que a imagem tenha um tom inesperado.

Ou seja, podemos perceber a imagem como um todo, abstraindo-se de seus componentes específicos. Ao contrário de nós, um computador inicialmente não possui esse recurso. Temos uma vasta experiência de vida que nos diz quais itens são importantes e quais propriedades físicas eles têm. Vamos pensar em como dotar a máquina de uma ferramenta para que ela possa estudar imagens.
Muitos proprietários felizes de telefones com câmeras de alta qualidade antes de postar uma foto de um telefone em uma rede social impõem vários filtros. Usando o filtro, você pode alterar o humor da foto. Você pode destacar alguns objetos mais claramente.
Além disso, o filtro pode destacar as bordas dos objetos na foto.
Como os filtros têm essa capacidade de destacar objetos diferentes em uma imagem, vamos dar ao computador a oportunidade de buscá-los. O que é uma imagem digital? Essa é uma matriz quadrada de números, em cada ponto em que existem valores de intensidade para três canais de cores: vermelho, verde e azul. Agora daremos à rede neural, por exemplo, 32 filtros. Cada filtro, por sua vez, é sobreposto à imagem. O núcleo do filtro é aplicado aos pixels vizinhos.
Inicialmente, os valores principais de cada filtro são aleatórios. Mas daremos às redes neurais a capacidade de configurá-las, dependendo da tarefa. Após a primeira camada com filtros, podemos colocar um pouco mais. Como temos muitos filtros, precisamos de muitos dados para configurá-los. Para isso, é adequado um grande banco de fotos marcadas. Por exemplo, conjunto de dados do MSCoco.

A rede neural ajustará os pesos para resolver este problema. No nosso caso, para segmentação de imagem, ou seja, a definição da classe de cada pixel da imagem. Agora vamos ver como as imagens ficarão após cada camada de filtros.
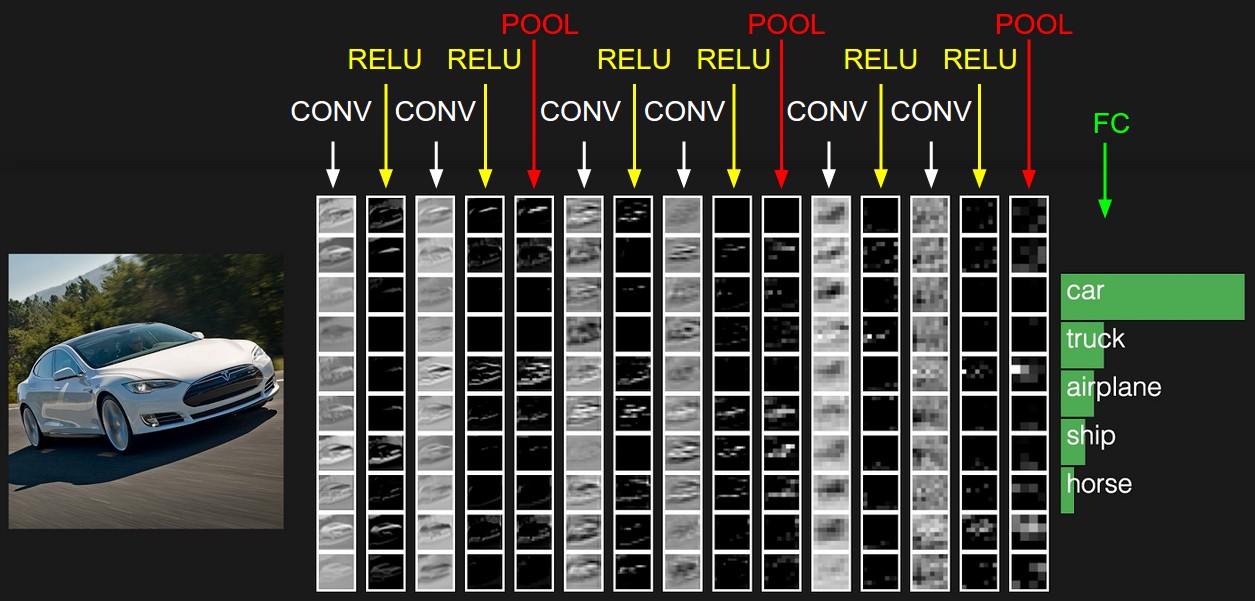
Se você observar de perto, notará que os filtros, em um grau ou outro, deixam o carro e limpam a área circundante - a estrada, as árvores e o céu.
De volta ao agente que aprende a jogar. Por exemplo, considere o jogo de corrida Mario Kart.
Demos a ele uma poderosa ferramenta de análise de imagem - uma rede neural. Vamos ver quais filtros ele escolhe para aprender a andar. Vamos dar uma área aberta para iniciantes.
Vamos ver como é a imagem depois dos primeiros 24 filmes. Aqui eles estão localizados na forma de uma tabela 8x3.
É completamente opcional que cada uma das 24 saídas tenha um significado óbvio, porque as imagens vão mais longe na entrada com os seguintes filtros. Dependências podem ser completamente diferentes. No entanto, neste caso, você pode encontrar alguma lógica nas saídas. Por exemplo, o segundo filtro na primeira linha destaca a estrada em preto. O primeiro filtro da sétima linha duplica sua função. E na maioria dos outros filtros, os cartões que controlamos são claramente visíveis.
Neste jogo, a área circundante muda e um túnel se encontra. A que uma rede neural de corrida presta atenção quando encontra uma entrada em um túnel?
As saídas da primeira camada de filtros:
Na sexta linha, o primeiro filtro destaca a entrada do túnel. Assim, durante o percurso, a rede aprendeu a identificá-los.
E o que acontece quando a máquina entra no túnel?
O resultado dos 24 primeiros filtros:
Apesar do fato de a iluminação da cena ter mudado, assim como do ambiente, a rede neural captura o mais importante - a estrada e os mapas. Novamente, o segundo filtro na primeira linha, responsável por encontrar o caminho a céu aberto, no túnel mantém suas funções. E da mesma maneira, o primeiro filtro da sétima linha, como antes, encontra o caminho.
Agora que descobrimos o que a rede neural vê, vamos tentar usá-la para resolver problemas mais complexos. Antes disso, consideramos tarefas nas quais você praticamente não precisa pensar no futuro, mas precisa resolver o problema que está enfrentando agora. Nos jogos e corridas de tiro, você precisa agir "reflexivamente", respondendo rapidamente a mudanças repentinas no jogo. Que tal completar o jogo de missões? Por exemplo, o jogo Montezuma Revenge, no qual você precisa encontrar as chaves e abrir as portas trancadas para sair da pirâmide.

No momento anterior, discutimos que o agente não aprenderá a procurar novas chaves e portas, pois essas ações levam muito tempo no jogo e, portanto, o sinal na forma de pontos recebidos será muito raro. Se você usar pontos para inimigos derrotados como recompensa ao agente, ele constantemente nocauteará crânios rolantes e não procurará novos movimentos.
Vamos recompensar o agente por abrir novas salas. Usaremos o fato conhecido a priori de que essa é uma missão, e todos os quartos nela são diferentes.

Portanto, se a imagem na tela for fundamentalmente diferente da que vimos antes, o agente receberá uma recompensa.
Antes disso, consideramos agentes de jogos que dependem apenas de dados visuais durante o treinamento. Mas se tivermos acesso a outros dados do jogo, também os usaremos. Considere, por exemplo, o jogo de Dot. Aqui, a rede recebe vinte mil números na entrada, que descrevem completamente o estado do jogo. Por exemplo, a posição dos aliados, a saúde das torres.

Os jogadores são divididos em duas equipes, cinco pessoas cada. Um jogo dura em média 40 minutos. Cada jogador seleciona um herói com habilidades únicas. E cada jogador pode comprar itens que alteram os parâmetros de dano, velocidade e campo de visão.
Apesar do jogo à primeira vista ser significativamente diferente de Doom, o processo de aprendizado permanece o mesmo. Exceto por alguns pontos. Como o horizonte de planejamento neste jogo é maior que no Doom, processaremos os últimos 16 quadros para tomar decisões. E o sinal de recompensas que o agente recebe será um pouco mais complicado. Inclui o número de inimigos derrotados, o dano infligido e o dinheiro ganho no jogo. Para que as redes neurais funcionem juntas, incluiremos o bem-estar dos membros da equipe do agente como recompensa.
Como resultado, a equipe de bots
derrota equipes de pessoas bastante fortes, mas perde para os campeões. O motivo da derrota é que os bots raramente jogavam partidas de uma hora. E jogos com pessoas reais duravam mais do que aqueles que eram jogados em simuladores. Ou seja, se um agente se encontra em uma situação para a qual não treinou, começam a surgir dificuldades.