Quero falar sobre nossa experiência no desenvolvimento de aplicativos com base na plataforma de pesquisa de texto completo do Apache Solr.
Nossa tarefa era desenvolver um sistema de análise de fala para centros de contato. O sistema é baseado em duas tecnologias básicas: reconhecimento de fala e pesquisa indexada. Para reconhecimento, usamos nossos mecanismos e, para indexação e pesquisa, escolhemos o Solr.
Por que Solr? Não realizamos nossa própria pesquisa comparativa de mecanismos de pesquisa indexados, mas examinamos cuidadosamente as
opiniões de nossos colegas . Certamente, a escolha poderia ser feita em favor da Elasticsearch ou da Sphinx, mas, aparentemente, as estrelas do nosso projeto se formaram em favor do Solr, nós a “serramos”. Já durante o curso do projeto, determinamos que as configurações disponíveis no Solr são suficientes para configurar nossas tarefas.
Características do nosso projeto
O sistema foi desenvolvido para análise de chamadas de clientes, que são registradas no contact center para monitorar a qualidade do serviço. Não analisa o som, mas o texto obtido como resultado do reconhecimento automático do diálogo. Os textos de fala reconhecida são fundamentalmente diferentes dos que encontramos regularmente em sites ou e-mail. Mesmo com 100% de precisão de reconhecimento, os textos de fala espontânea reconhecida podem parecer não ter significado.
Isto é devido a dois fatores principais. Em primeiro lugar, na fala oral, expressões não verbais e faciais são usadas com muita frequência, que não são reconhecidas no texto, mas são importantes para a compreensão do que foi dito. Em segundo lugar, na fala, abreviações e omissões de estruturas de linguagem são constantemente usadas, que podem ser restauradas a partir do contexto de uma situação comunicativa. Esse fenômeno na linguística é chamado de elipse.
Para ver com seus próprios olhos o texto do discurso reconhecido com todos os seus recursos, observe as legendas automáticas do vídeo no youtube com o som desativado. É sobre esse conteúdo, o material vai para a entrada do sistema de análise de fala.
Consultas complicadas
Embora o Solr suporte
declarações e
agrupamentos condicionais padrão, geralmente esses recursos não são suficientes para implementar todos os cenários para analistas.
Freqüentemente, o analista precisa criar uma consulta com parâmetros não incluídos no índice Solr. Por exemplo, encontre todas as palavras "obrigado" que foram pronunciadas nos últimos 30 segundos da conversa. As palavras são indexadas pelo Solr, mas nenhuma posição temporária das palavras. Chamamos essas consultas de "complexas" - consultas que incluem os parâmetros do índice Solr e quaisquer outros parâmetros de seleção de dados que não estejam incluídos no índice Solr.
Como um analista forma consultas?
O analista não tem idéia da composição do índice Solr; é importante que ele pesquise e recorte todos os atributos dos fonogramas das chamadas e suas transcrições de texto. Portanto, o conceito de "consulta complexa" para o analista é puramente pragmático: consultas nas quais existem muitos parâmetros de seleção ou consultas organizadas em uma hierarquia.
Descrevendo as ações do analista na linguagem da teoria dos conjuntos, podemos dizer que, com a ajuda de consultas, o analista explora as relações entre diferentes subconjuntos: interseções, diferenças, adições. Usando consultas hierárquicas, o analista analisa a matriz de dados para o nível de detalhe necessário de sua estrutura.
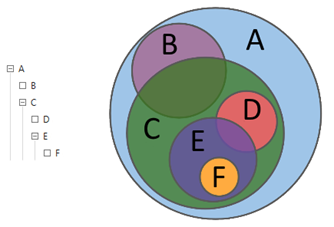 Figura 1. Consultas hierárquicas
Figura 1. Consultas hierárquicasA Figura 2 mostra um exemplo clássico de uma consulta complexa que contém critérios de seleção textual e numérica.
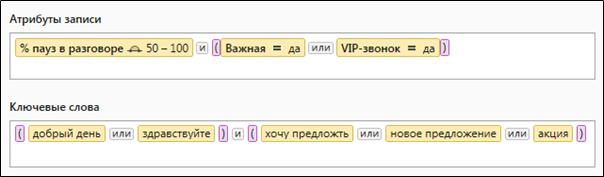 Figura 2. Uma consulta complexa contendo parâmetros de seleção de dados quantitativos e lexicais
Figura 2. Uma consulta complexa contendo parâmetros de seleção de dados quantitativos e lexicaisComo são as consultas para o Solr?
Considere o mecanismo geral para executar uma consulta no Solr usando o exemplo da consulta
B na Figura 1. Como podemos ver, a consulta
B possui uma consulta pai
A , ou seja,
B⊆A . Na análise da fala, uma solicitação não pode ser atendida enquanto pelo menos um de seus "pais" não for atendido. Portanto, a consulta
A é executada primeiro e somente depois
B. Obviamente,
B deve conter as condições da consulta
A.A primeira coisa que vem à mente é combinar as condições de ambas as consultas por meio de
AND e colá-las na
query :
q=key:A AND key:BNo entanto, se simplesmente combinarmos todas as consultas consecutivas em uma
query , ela será grande, será diferente para cada consulta e será calculada na sua totalidade. Além disso, as condições
A afetarão a relevância dos resultados da consulta
B , o que não seria desejável.
Vamos tentar adicionar consultas pai como
FilterQuery . Nesse caso, a consulta
A não será afetada por falta de relevância e podemos esperar que ela já tenha sido concluída e que seus resultados estejam no cache. Assim, o Solr terá que calcular apenas a consulta
B , enquanto o Solr classificará a seleção resultante da maneira que precisamos:
q=keyword:B &fq=keyword:ASe considerarmos esquematicamente o formato da solicitação para o Solr, podemos distinguir duas entidades principais:
MainQuery - a consulta principal com um conjunto de parâmetros que o documento deve atender. Por exemplo, uma solicitação de pesquisa para operadores educados ficaria assim: text_operator: ” ” .
Isso significa que o campo text_operator do documento de pesquisa deve conter a frase “ ”
FilterQuery - um conjunto de filtros adicionais que limitam a seleção resultante. FilterQuery formato MainQuery corresponde ao MainQuery
Dividir a solicitação em
Main e
Filter permite:
- indique explicitamente quais parâmetros de consulta devem afetar a classificação do documento na seleção e quais servem apenas para seleção na seleção resultante. A relevância para a construção da classificação dos documentos é calculada quando a parte da consulta MainQuery é executada e quando a parte da consulta
FilterQuery é FilterQuery documentos que não atendem às condições da consulta são eliminados. - reduz significativamente a carga no mecanismo de pesquisa, pois a amostra resultante obtida após os cálculos do
FilterQuery é armazenada em cache completamente, enquanto os resultados do cálculo do MainQuery são armazenados no cache apenas para os primeiros na classificação de 50 valores
MainQuery e
FiletrQuery têm efeitos diferentes nas funções do Solr. Por exemplo, para
destacar , a função responsável por destacar fragmentos de documentos relevantes, apenas
MainQuery e os parâmetros
FilterQuery não afetam o
highlighting . Isso é lógico, porque a relevância é calculada exatamente na parte da consulta
MainQuery . É assim que os resultados de
highlighting são exibidos em uma pesquisa real por textos com as palavras "olá" e "serviços".
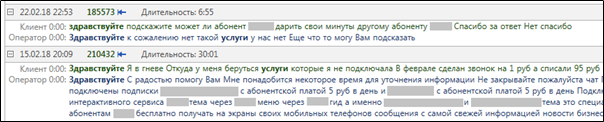 Figura 3. Destaque para palavras relevantes após a conclusão de uma consulta
Figura 3. Destaque para palavras relevantes após a conclusão de uma consulta MainQuery .
Consultas complicadas no Solr
Vamos voltar ao exemplo de um operador educado. Neste exemplo, determinamos as chamadas apropriadas pela presença da frase "boa tarde" na fala do operador, mas não indicamos o intervalo de tempo no qual procurar palavras-chave relativas ao início ou ao final da conversa.
Parece que há tudo o que é necessário para isso - a transcrição do texto da conversa telefônica contém o carimbo de data / hora de cada palavra, além de informações sobre qual dos participantes do diálogo pertence. Esses dados também podem ser usados na pesquisa.
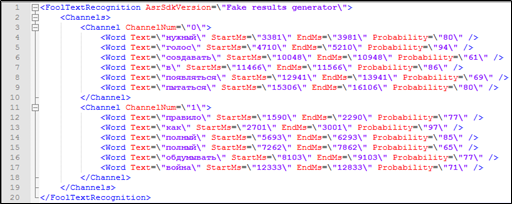 Figura 4. Um fragmento de descriptografia textual com marcação que não está incluído no índice Solr: afiliação do orador, registros de data e hora.
Figura 4. Um fragmento de descriptografia textual com marcação que não está incluído no índice Solr: afiliação do orador, registros de data e hora.Mas como processar uma consulta de pesquisa no Solr, se parâmetros não indexáveis estiverem envolvidos na consulta - a hora em que a palavra é pronunciada?
Surgem duas maneiras óbvias de resolver esse problema:
- adicione parâmetros não indexados ao índice Solr. Ao mesmo tempo, o consumo de memória aumentará um pouco, mas o índice será significativamente mais pesado
- a seleção dos dados por parâmetros não indexáveis deve ser realizada utilizando o seu serviço e, na coleta de documentos obtidos após essa seleção, a pesquisa utilizando o índice Solr. Ao mesmo tempo, o consumo de memória será significativamente maior do que no primeiro caso, mas o desempenho será previsível
Nós escolhemos a segunda opção. Para isso, desenvolvemos um serviço que calcula coleções por solicitações que contêm parâmetros lógicos e numéricos que não estão incluídos no índice Solr. Como resultado do trabalho deste serviço, a parte da coleção que não atendeu à solicitação foi marcada com uma tag especial ("escapada") e, em seguida, não participou do cálculo dos resultados da consulta.
Imagine que queremos impor uma restrição à pesquisa na consulta
B que já conhecemos, apenas nos primeiros 30 segundos da caixa de diálogo. No primeiro estágio, executamos
B como uma consulta simples e, em seguida, “selecionamos” as palavras que vão além do intervalo selecionado, para que não caiam no índice Solr, mas, ao mesmo tempo, podemos restaurar o documento original. Os documentos resultantes são colocados em uma coleção Solr separada e a pesquisa pela consulta
B é reiniciada nela.
Aqui, devo dizer que as restrições no início ou no final da conversa são flores, bagas são restrições nos resultados da solicitação dos pais. Considere executar uma consulta semelhante.
Imagine que nossos documentos consistam em bolas com números. Vamos tentar encontrar todas as bolas "6" localizadas em não mais do que duas bolas à direita de "5".
Você já percebeu que os números das bolas estão incluídos no índice Solr e não há distância entre elas.
|  |
Encontre todos os documentos com as bolas “6” e “5”. Como MainQuery usamos uma consulta para as bolas “5” e uma consulta para “6”, enviaremos para o FilterQuery . Como resultado, o Solr destacará as bolas “5” nos resultados da pesquisa, o que simplificará bastante nossa vida na próxima etapa. | 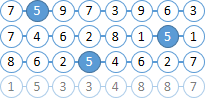 |
| Selecionamos todas as bolas, exceto aquelas que estão na distância desejada de "5". Os documentos recebidos (documentos com as bolas desejadas) serão colocados em uma coleção separada. |  |
Vamos executar o FilterQuery nas bolas "6" na coleção resultante, o resultado são os documentos que estamos FilterQuery . |  |
Na prática, as bolas 5 e 6 geralmente ocultam consultas que ocupam várias telas em sua representação textual. Fico feliz por termos implementado essa pesquisa em vão - os analistas costumam usar consultas com restrições dos pais.
Conclusão
O que aprendemos, o que aprendemos e o que alcançamos como resultado do projeto?
Sabemos como usar efetivamente o Solr para trabalhar com dados de vários tipos. Podemos "ensinar" o Solr a processar consultas com parâmetros que não estão incluídos no seu índice de pesquisa.
Desenvolvemos um sistema industrial de análise de voz que opera sob alta carga: consultas complexas de pesquisa de analistas são calculadas para amostras de até cinco milhões de documentos de texto. É possível e mais, mas não havia necessidade prática. A amostra de trabalho usual do analista é de cerca de 500 mil textos de chamadas reconhecidas e o número total de chamadas pode chegar a 15 milhões.
Para nossos clientes em centros de contato, o sistema oferece oportunidades sem precedentes para análises de natureza muito diferente: análise de tópicos e motivos de solicitações, análise de satisfação do cliente e muitos outros.
Agora, estamos conectando novas fontes às nossas análises - conversas em texto de clientes com operadoras. Implementamos um único aplicativo para análise de chamadas de clientes em todos os canais do contact center: telefone, chat, formulários nos sites, etc.
Teremos o maior prazer em responder às suas perguntas.
Obrigada
O PS Solr é uma coisa muito difícil e requer um bom ajuste para obter bons resultados. Vamos contar sobre a nossa experiência neste campo nos seguintes artigos.