Nós já
falamos sobre
estatísticas interessantes
de textos , fizemos uma
revisão de artigos sobre o uso de autocoders na análise de textos e nos surpreendemos com nossos novos algoritmos de
busca para empréstimos e
paráfrase transferíveis . Decidi continuar nossa tradição corporativa e, em primeiro lugar, iniciar o artigo com "T" e, em segundo lugar, informar:
- como encontrar rapidamente um parágrafo de texto entre centenas de milhões de artigos;
- em que o documento se transforma após o carregamento no sistema antiplágio e o que fazer em seguida;
- como é formado um relatório que quase ninguém olha, mas valeria a pena;
- como indexar não todos, mas o suficiente.

Como tudo começou
Em 2005, o reitor de uma das maiores universidades de Moscou veio a nós na
Forecsys para resolver um problema muito sério - nas instituições de ensino, os alunos aprovaram diplomas e documentos de
conclusão totalmente anulados . Pegamos centenas de trabalhos de excelentes alunos e os procuramos na rede com consultas simples. Mais da metade dos
“excelentes estudantes” acabaram sendo vigaristas que baixaram um diploma da Internet e substituíram apenas a página de rosto. Mais da metade dos excelentes alunos, Karl! É difícil imaginar o que aconteceu com os alunos comuns. A maneira mais fácil de procurar um emprego é uma consulta que contenha palavras com "buracos negros". Nós tomamos consciência da escala do desastre. Era urgente resolver alguma coisa. Naquela época, as universidades estrangeiras de língua inglesa já estavam usando soluções de busca de empréstimos, mas por algum motivo ninguém verificou o trabalho em russo.
Jogadores estrangeiros não queriam adaptar suas soluções para o idioma russo na época. Como resultado, em 17 de março de 2005, começou o desenvolvimento do primeiro sistema doméstico de busca de empréstimos. A palavra "Anti-plágio" foi cunhada um pouco mais tarde e o domínio antiplagiat.ru foi registrado em 28 de abril de 2005. Planejamos lançar o site até 1º de setembro de 2005, mas, como costuma acontecer com os programadores, não havia tempo. O aniversário oficial da nossa empresa é o dia em que o antiplagiat.ru recebeu os primeiros usuários, ou seja, 4 de setembro. Sabe, estou até feliz com isso, porque durante a festa corporativa, por ocasião do aniversário da empresa, todos podem comemorar com calma e não se preocupar com o primeiro dia escolar dos filhos.
Mas algo que eu estava distraído. Em 2005, criamos um tipo de mecanismo de pesquisa, no qual, diferentemente do Yandex e do Google, a consulta não é de duas ou três palavras, mas um texto inteiro que consiste em várias frases. Portanto, é razoável usar o "Anti-plágio" se você tiver um texto com 1.000 caracteres (cerca de meia página).
Durante o desenvolvimento do serviço, foi feito um protótipo no php (web part) e no Microsoft SQL Server (mecanismo de pesquisa). Imediatamente ficou claro que isso não decolaria e funcionaria lentamente em vários milhões de documentos. Portanto, tive que cortar meu mecanismo de pesquisa. Agora, o sistema está escrito em C # e python, usa PostgreSQL e MongoDB (de fato, muito mais, mas mais sobre isso no próximo artigo). O mecanismo de pesquisa ainda é completamente desenvolvido por nós.
Coloque curtidas Escreva nos comentários se quiser aprender sobre a história do desenvolvimento do sistema, a mudança nos processos da empresa e o hardware em que o Antiplagiarism trabalhou em diferentes momentos da sua vida e está trabalhando agora.
A palavra que deu o nome da empresa agora se tornou uma palavra familiar. Freqüentemente, em um mecanismo de busca, é possível encontrar expressões como "verificar antipagiarismo", "aumentar antipagiarismo". Todo mundo que está de alguma forma conectado ao campo de busca de empréstimos na Rússia e nos países vizinhos está tentando usar a palavra "anti-plágio" para aumentá-la nos resultados de busca. Muitas vezes nos perguntam sobre outro "anti-plágio". Então, “Anti-plágio” é um, é uma marca comercial e o nome da nossa empresa.
No início da implementação do serviço de busca de empréstimos, decidimos trabalhar com o texto como uma sequência de caracteres. Várias construções semânticas dos textos, a busca de significados, a análise de sentenças etc. foram imediatamente rejeitadas. A solução que escolhemos oferece duas vantagens enormes: alta velocidade de pesquisa e volume relativamente pequeno de índices de pesquisa.
Atualmente, existem três produtos em nossa linha. Eles são diferenciados pela funcionalidade, mas contêm basicamente o mesmo princípio de busca de empréstimo. Neste artigo, falarei sobre como funciona nossa pesquisa clássica de empréstimos - a funcionalidade que se tornou a base do serviço desde o início e ainda não mudou conceitualmente. O esquema de busca de empréstimos, como você vê na imagem, é simples e direto, como desenhar uma coruja. Primeiro, obtemos o documento do usuário e extraímos o texto. Em seguida, procuramos empréstimos neste texto, obtemos "revisões" (como chamamos o relatório para um módulo de pesquisa) e, finalmente, coletamos revisões em um grande relatório, que mostramos como resultado ao usuário.
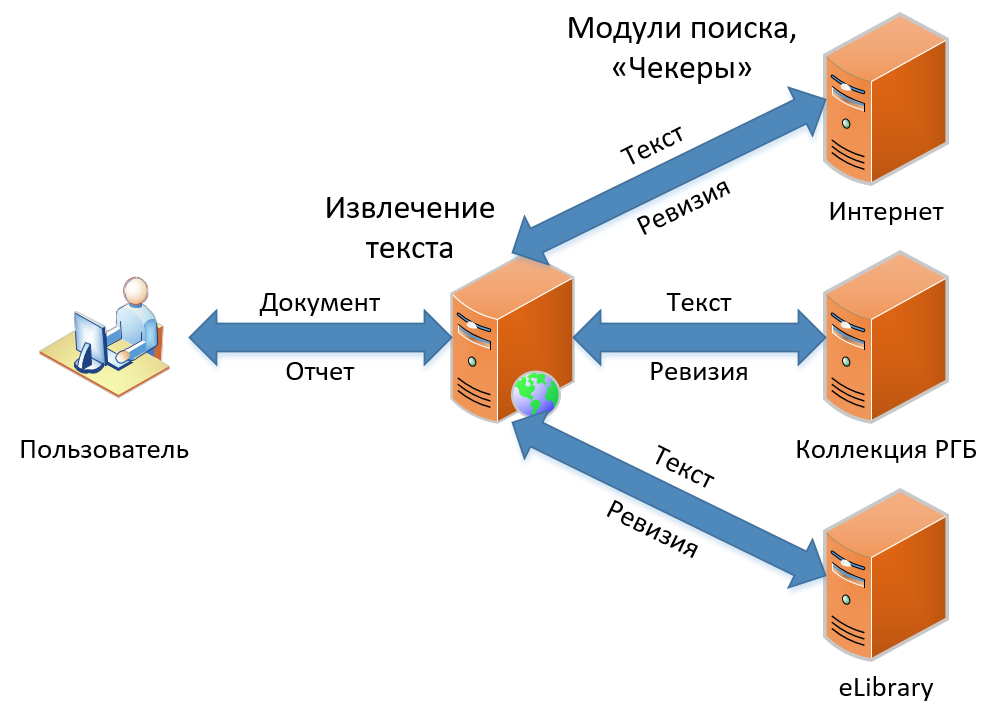
Vamos ver como tudo isso acontece em detalhes.
Extração de texto
Antes de tudo, o “Anti-plágio” é um serviço para pesquisar apenas empréstimos de
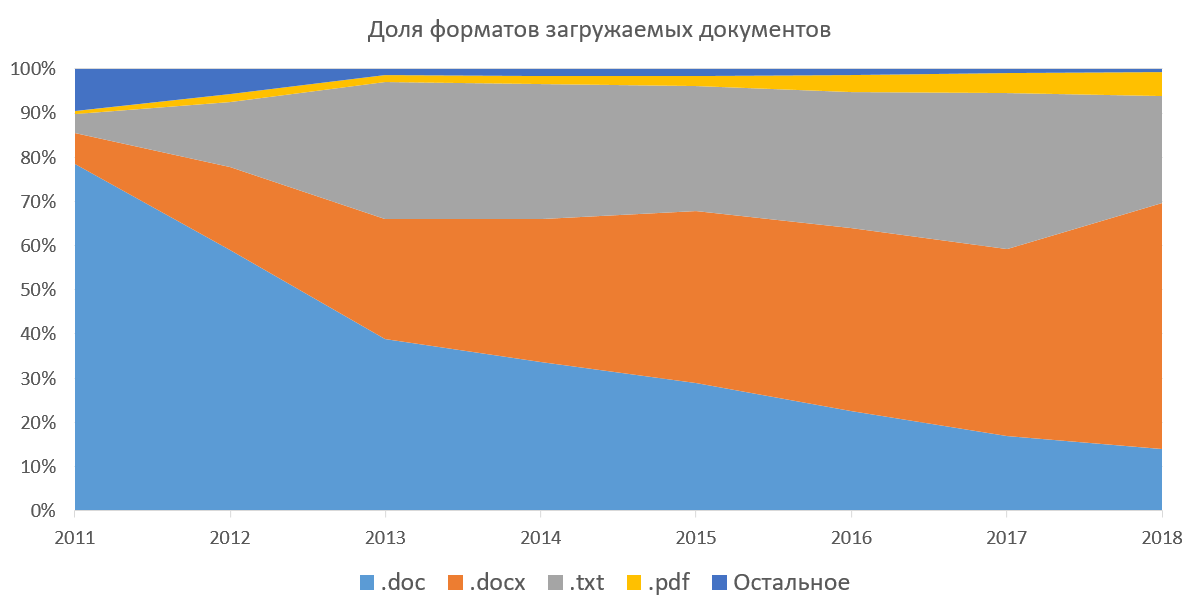
texto , o que significa que precisamos extrair o texto de todos os documentos para continuar trabalhando com ele. O sistema suporta a capacidade de baixar documentos nos formatos docx, doc, txt, pdf, rtf, odt, html, pptx e vários outros formatos (nunca usados). Você também pode baixar todos esses documentos em arquivos (7z, zip, rar). Esse método era popular quando não era possível fazer upload de vários documentos de uma só vez através da interface da web. Abaixo está um gráfico da popularidade dos formatos de documentos para download na parte corporativa do nosso sistema. Ele mostra como o docx foi substituído pelo doc por vários anos e a proporção de pdf está aumentando gradualmente. Se você não considera o txt (a extração de texto é trivial), então para nós o mais agradável é o pdf. No exterior, o pdf é o padrão de fato, publica artigos, prepara o trabalho do aluno. De acordo com nossas estatísticas, o pdf está gradualmente ganhando popularidade na Rússia e nos países da CEI. Nós mesmos estamos promovendo esse formato para as massas, recomendando o download de documentos nele.
Limitamos os formatos de download de documentos para clientes particulares a pdf e txt, e é por isso que reduzimos o consumo de recursos e o custo do suporte a um serviço gratuito. Afinal, você precisa verificar o texto e não testar o sistema? Então, qual é a diferença em que formato para enviá-lo?
A próxima maneira mais fácil de extrair texto é docx, porque, de fato, é um arquivo zip com xml interno, é bastante simples de processar e muito pode ser feito em um nível baixo.
A coisa mais difícil para nós é o documento. Este formato foi fechado por um longo tempo e agora existem várias implementações. O último Microsoft Word, que não suportava .docx (embora por meio do Microsoft Office Compatibility Pack), foi lançado há 20 anos e foi incluído no Microsoft Office 97. O formato usa OLE, que mais tarde se transformou em COM e ActiveX, tudo é binário, às vezes incompatível entre versões. Em geral, o terrível sonho de um programador moderno. É bom que o formato .doc esteja saindo gradualmente da cena. Acho que chegou a hora de ajudá-lo a se aposentar. Em breve, avisaremos intencionalmente os usuários que esse formato está desatualizado.
Então, voltando ao relatório. Pegamos o arquivo e começamos a extrair o texto. Juntamente com o texto, o sistema também extrai as posições das palavras nas páginas para que, no futuro, seja possível mostrar aos nossos usuários a marcação do relatório de empréstimo no próprio documento. Além disso, no mesmo estágio, estamos procurando soluções técnicas para o Anti-Plágio.
Assim que o “Anti-plágio” apareceu, mostrando a porcentagem de originalidade, havia pessoas que queriam passar no cheque por empréstimos com o mínimo esforço, além de pessoas que ofereciam esse serviço por dinheiro. O problema é que o parâmetro numérico pede para se tornar uma estimativa. Afinal, é tão simples - em vez de ler um trabalho usando o sistema como ferramenta, não o leia, mas avalie-o pela porcentagem de originalidade! Foi esse infortúnio que deu origem a uma direção como a afinação de obras (uma mudança no texto para aumentar a porcentagem de originalidade da obra). Leia mais sobre problemas nos processos universitários no artigo
"Sobre a prática de detectar empréstimos em universidades russas" .
Em sistemas de pesquisa estrangeiros, os problemas de detecção de soluções técnicas e combatê-las praticamente não valem a pena. O fato é que a descoberta "finta com ouvidos" será seguida por uma punição muito severa - expulsão e posição indelével na reputação científica, incompatível com outras carreiras. No nosso caso, a situação é ridiculamente simples: "Oh, esse sistema estragou alguma coisa!", "Oh, não sou eu, sou ela mesma!" É provável que o aluno seja enviado para refazer. O fato é que, infelizmente, não é algo vergonhoso.
Mas novamente distraído. Outra maneira de extrair texto é o OCR. Imprimimos o documento em uma impressora virtual e o reconhecemos. Leia mais sobre isso no artigo
“Reconhecimento de imagens a serviço do antiplágio” .
Agora, um pouco da nossa história sobre a extração de textos. Primeiro, extraímos textos usando IFilters. Eles são lentos, apenas no Windows e não retornam informações de formatação (não está claro onde o texto em branco está sobre o fundo branco, então você não pode marcar os blocos de empréstimo diretamente no documento do usuário). Pensamos que esses problemas seriam resolvidos se começássemos a usar bibliotecas pagas, mas também encontramos limitações: como antes no Windows, elas não veem fórmulas, às vezes caem em documentos especialmente preparados (bibliotecas diferentes em diferentes!). A próxima idéia era registrar todos os documentos recebidos, mas essa abordagem consome muitos recursos (processando apenas 10 páginas por minuto em um núcleo) e, em alguns locais, o texto não é extraído com precisão.
Não encontramos uma bala de prata, embora algumas vezes pensássemos que era Felicidade. No entanto, depois de viver um pouco com isso, eles perceberam que era novamente uma experiência. A extração de texto se equilibra em uma linha tênue entre desempenho (você precisa extrair texto de centenas de documentos por minuto), confiabilidade (você precisa extrair texto de tudo), funcionalidade (formatação, soluções alternativas, isso é tudo). Agora, todos os itens acima e um pouco mais de trabalho para nós. Estamos constantemente experimentando essa área e continuamos buscando nossa felicidade.
O texto é extraído, as rodadas são encontradas e parcialmente eliminadas, partimos para procurar empréstimos!
Pesquisa de empréstimos
A idéia implementada no procedimento de pesquisa foi proposta por Ilya Segalovich e Yuri Zelenkov (você pode ler, por exemplo, no artigo:
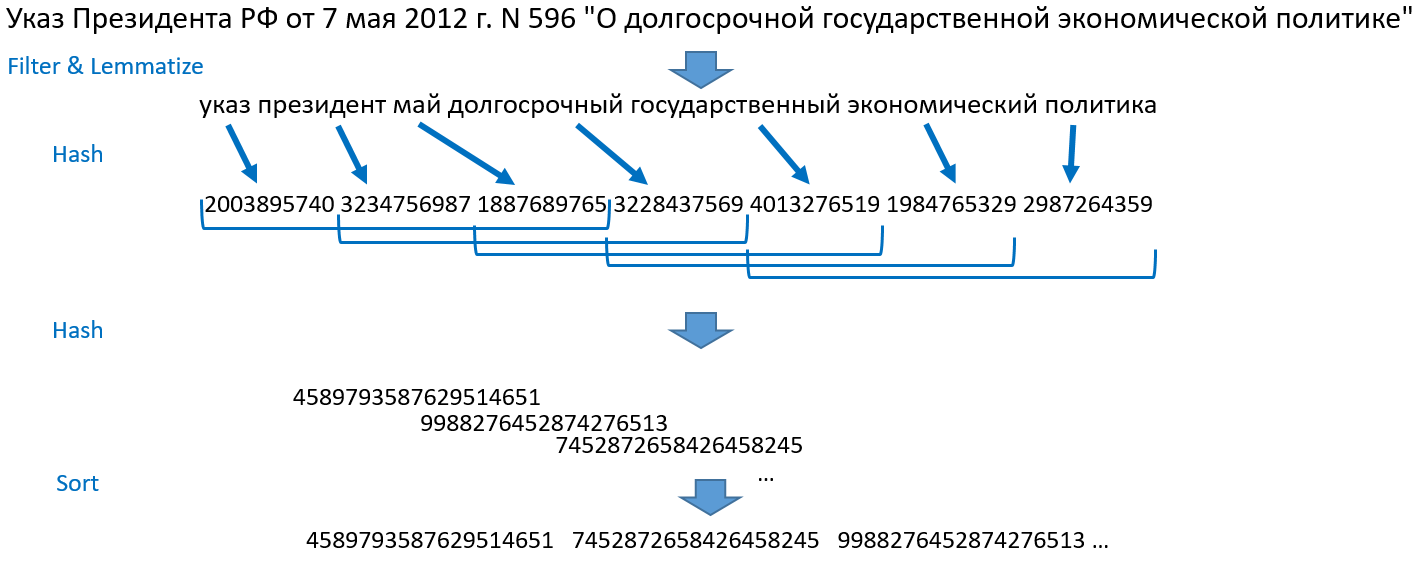
Análise comparativa de métodos para determinar duplicatas nebulosas para documentos da Web ). Vou lhe contar como isso funciona para nós. Tomemos, por exemplo, a frase: "Decreto do Presidente da Federação Russa de 7 de maio de 2012 N 596" Sobre política econômica do estado a longo prazo "."
- Dividimos frases em palavras, jogamos fora números, sinais de pontuação, paramos palavras. Lematize (leve à forma normal) todas as palavras.
- Transformamos as palavras em números inteiros por hash, obtemos uma matriz de números.
- Tomamos os três primeiros hashes, depois o segundo, terceiro, quarto hash, depois o terceiro, quarto, quinto e assim por diante até o final da matriz de hash. Isso é telha de telha. Esse método recebeu esse nome devido a esses conjuntos sobrepostos em mosaico. Mesclamos cada bloco em um objeto e hash novamente.
- Classificamos os números resultantes, obtemos uma matriz ordenada de números inteiros. Essa é a base da pesquisa.
Agora, para a pesquisa, precisamos de uma função mágica que, de acordo com essa lista de hashes, transforme documentos, classificados em ordem decrescente do número de hashes correspondentes, em um documento de origem. Esta função deve funcionar rapidamente porque queremos pesquisar bilhões de documentos. Para encontrar rapidamente esse conjunto, precisamos de um índice reverso, que por hash retorne uma lista de documentos em que esse hash está. Implementamos uma tabela de hash tão gigante. Ao contrário dos nossos irmãos de busca mais antigos, armazenamos esta tabela no ssd, não na memória. Estamos com pouco desempenho. A pesquisa de índice ocupa uma pequena parte de todo o ciclo de processamento de documentos. Veja como a pesquisa vai:
Etapa 1. Pesquisa de Índice
Para cada hash do texto da solicitação, obtemos uma lista de identificadores dos documentos de origem nos quais ele ocorre. Em seguida, classificamos a lista de identificadores de documentos de origem pelo número de hashes encontrados no texto da solicitação. Recebemos uma lista ordenada de documentos candidatos para a fonte do empréstimo.
Etapa 2. Construção da auditoria
Para uma grande solicitação de texto dos candidatos, pode haver cerca de 10 mil, e ainda há muito para comparar cada documento com o texto da solicitação. Agimos com avidez, mas decisivamente. Pegamos o primeiro documento de origem, fazemos uma comparação com o texto da solicitação e excluímos de todos os outros candidatos os hashes que já estavam neste primeiro documento. Nós removemos da lista de candidatos aqueles que possuem zero hashes e reorganizamos os candidatos de acordo com o novo número de hashes. Pegamos o primeiro documento da nova lista, comparamos com o texto de origem, excluímos os hashes, excluímos os zero candidatos, reorganizamos os candidatos. Fazemos isso de 10 a 20 vezes, geralmente isso é suficiente para fazer com que a lista acabe ou apenas os documentos que correspondem a vários hashes permanecem nela.
O uso de hashes de palavras nos permite realizar operações de comparação mais rapidamente, economizar memória e armazenar não os textos dos documentos de origem, mas suas transmissões digitais (TextSpirit, como os chamamos afetuosamente) obtidas durante a indexação, violando assim os direitos autorais. A seleção de fragmentos de empréstimos específicos é feita usando a árvore de sufixos.
Como resultado da verificação com um módulo de pesquisa, obtemos uma revisão, que contém uma lista de fontes, seus metadados e as coordenadas das unidades de empréstimo em relação ao texto da solicitação.
Montagem de relatório
A propósito, e se um dos 10-15 módulos não responder a tempo? Pesquisamos nas coleções da RSL, eLibrary e Garantidor. Esses módulos de pesquisa estão localizados no território de organizações de terceiros e não podem ser transferidos para o nosso site por motivos de direitos autorais. O ponto de falha aqui sempre pode ser um canal de comunicação e força maior em data centers não controlados por nós. Por um lado, o empréstimo pode ser encontrado em qualquer módulo de pesquisa; por outro lado, se um dos componentes do sistema estiver indisponível, você pode degradar a qualidade da pesquisa, mas fornecer a maior parte do resultado, enquanto avisa o usuário que o resultado para alguns módulos de pesquisa ainda não está pronto. Qual opção você aplicaria? Aplicamos essas duas opções conforme apropriado.

Finalmente, todas as revisões são recebidas, iniciamos a montagem do relatório. Ele usa uma abordagem semelhante à preparação de uma revisão. Parece não ser nada complicado, mas também há tarefas interessantes. Temos dois tipos de empréstimos. As "citações" são indicadas em verde - citações corretamente citadas (de acordo com GOST) do módulo "Citação", expressões do tipo "o que era necessário para provar" do módulo "Expressões comuns", documentos legais das bases de dados do garantidor e da Lexpro. Todos os outros empréstimos estão marcados em laranja. Os verdes têm precedência sobre as laranjas, a menos que entrem em todo o bloco laranja.
Como resultado, o relatório pode ser comparado com o texto impresso em papel sobre a mesa, sobre o qual rabiscos multicoloridos (blocos de empréstimos e cotações) são rabiscados, fantasiando-se. O que vemos acima é um relatório. Temos dois indicadores para cada fonte:
A participação no relatório é a proporção do volume de empréstimos, que é levado em consideração a partir dessa fonte, para o volume total do documento. Se o mesmo texto foi encontrado em várias fontes, ele será levado em consideração apenas em uma delas. Quando você altera a configuração do relatório (ativar ou desativar fontes), esse indicador da fonte pode mudar. No total, fornece a porcentagem de empréstimos e citações (dependendo da cor da fonte).
Compartilhar no texto - a proporção do volume emprestado da fonte fornecida do texto para o volume total do documento. Não faz sentido resumir os compartilhamentos no texto por fontes, resultará facilmente 146% ou mais. Este indicador não muda quando o relatório é alterado.
Naturalmente, o relatório pode ser editado. Essa é uma função especial para o especialista que verifica o trabalho para desativar o empréstimo dos trabalhos do autor (pode parecer que esse fragmento não está apenas no trabalho do autor, mas também em outro lugar) e separa os blocos de empréstimo, altera o tipo de fonte de empréstimos para citação. Como resultado da edição do relatório, o especialista recebe o valor real do empréstimo. Qualquer trabalho para verificação deve ser lido. É conveniente fazer isso observando a forma original do documento, na qual os blocos de empréstimos estão marcados e imediatamente, enquanto você lê, edita o relatório. Infelizmente, essa não é uma ação lógica de todos; muitos estão satisfeitos com o percentual de originalidade, sem sequer olhar para o relatório.
No entanto, vamos voltar um passo e descobrir o que entra no índice do módulo de pesquisa na Internet criado pelo Anti-Plágio.
Indexação na Internet
O anti-plágio é amplamente focado no trabalho do aluno, publicações científicas, trabalhos de qualificação final, dissertações, etc. Indexamos a Internet de maneira direcional - estamos procurando grandes grupos de textos científicos, resumos, artigos, dissertações, periódicos científicos, etc. A indexação acontece assim:
- Nosso robô vem, se apresenta e, guiado pelo robots.txt (temos um bom robô), baixa documentos com uma carga razoável em cada host (centenas de sites estão sendo executados ao mesmo tempo, para que possamos esperar um pouco entre o carregamento da página);
- O robô passa o documento e seus metadados para a fila de processamento, o texto é extraído do documento;
- O texto é analisado quanto à "qualidade" - como você se lembra do artigo sobre o aterro, podemos determinar o gênero do documento, adicionar heurísticas simples ao volume aqui e entender se um texto adequado chegou até nós ou algum lixo;
- O texto qualitativo vai além e se transforma em hashes. Hashes e metadados são enviados para o principal índice da Internet;
- Comparamos o texto recebido com os textos indexados anteriormente por nós. Um novato é adicionado apenas se for realmente novo , ou seja, 90% - . , url .
Assim, indexamos textos de alta qualidade, e todos os textos indexados são significativamente diferentes para nós. O crescimento do volume indexado na Internet é mostrado na figura abaixo. Agora, em média, adicionamos ao índice 15-20 milhões de documentos por mês.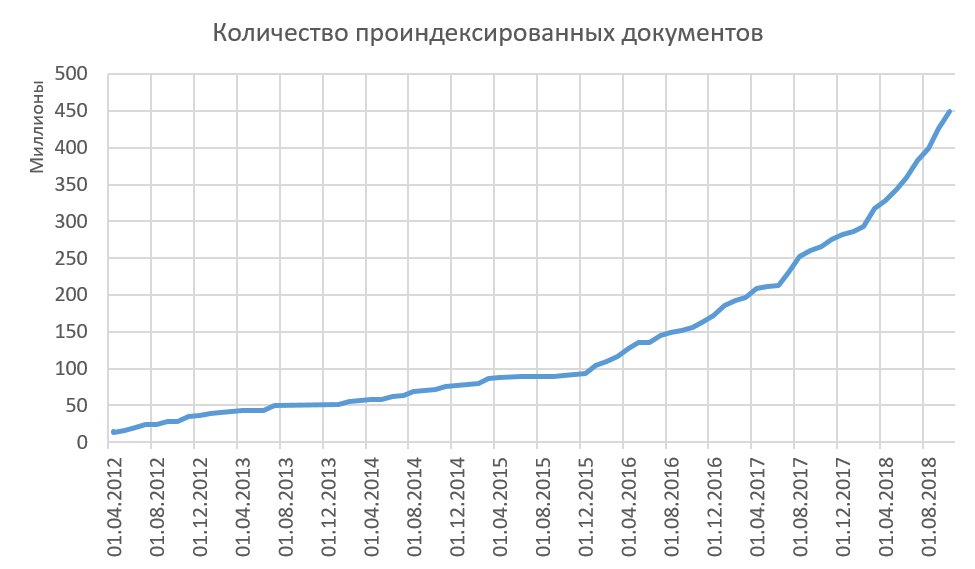 Percebeu que o procedimento para remover do índice não está descrito em nenhum lugar? E ela não é! Basicamente, não excluímos documentos do índice. Acreditamos que, se pudéssemos ver algo na Internet, outras pessoas poderiam ver esse texto e usá-lo de uma maneira ou de outra. Nesse sentido, há uma estatística interessante do que existia na Internet e agora não está mais lá. Sim, imagine a expressão "Uma vez que a Internet ficará lá para sempre" não é verdadeira! Algo desaparece da Internet para sempre. Você está interessado em aprender sobre nossas estatísticas sobre isso?
Percebeu que o procedimento para remover do índice não está descrito em nenhum lugar? E ela não é! Basicamente, não excluímos documentos do índice. Acreditamos que, se pudéssemos ver algo na Internet, outras pessoas poderiam ver esse texto e usá-lo de uma maneira ou de outra. Nesse sentido, há uma estatística interessante do que existia na Internet e agora não está mais lá. Sim, imagine a expressão "Uma vez que a Internet ficará lá para sempre" não é verdadeira! Algo desaparece da Internet para sempre. Você está interessado em aprender sobre nossas estatísticas sobre isso?Conclusão
É incrível como as soluções técnicas adotadas há mais de 10 anos ainda permanecem relevantes. Agora, estamos nos preparando para lançar a versão 4 do índice, que é mais rápida, tecnologicamente avançada e melhor, no entanto, é baseada nas mesmas soluções. Novas direções de busca apareceram - empréstimos transferíveis, parafraseando, mas nosso índice também é usado lá, realizando até uma parte pequena, mas importante do trabalho.Caros leitores, o que você gostaria de saber sobre nosso serviço ainda?