
No coração dos mecanismos de pesquisa Meltwater e
Fairhair.ai está o Elasticsearch, uma coleção de clusters com bilhões de mídias e artigos em mídias sociais.
Os shards de índice nos clusters variam muito em estrutura de acesso, carga de trabalho e tamanho, o que levanta alguns problemas muito interessantes.
Neste artigo, descreveremos como usamos a programação linear (otimização linear) para distribuir a carga de trabalho de pesquisa e indexação da maneira mais uniforme possível em todos os nós nos clusters. Essa solução reduz a probabilidade de um nó se tornar um gargalo no sistema. Como resultado, aumentamos a velocidade da pesquisa e economizamos na infraestrutura.
Antecedentes
Os mecanismos de busca da Fairhair.ai contêm cerca de 40 bilhões de postagens de mídias sociais e editoriais, processando milhões de consultas diariamente. A plataforma fornece aos clientes resultados de pesquisa, gráficos, análises, exportação de dados para análises mais avançadas.
Esses conjuntos de dados massivos residem em vários clusters Elasticsearch de 750 nós com milhares de índices em mais de 50.000 shards.
Para obter mais informações sobre nosso cluster, consulte os artigos anteriores sobre
sua arquitetura e
balanceador de carga de aprendizado de máquina .
Distribuição desigual da carga de trabalho
Nossas consultas de dados e de usuários geralmente são vinculadas à data. A maioria das solicitações ocorre em um determinado período de tempo, por exemplo, na semana passada, no mês passado, no último trimestre ou em um intervalo arbitrário. Para simplificar a indexação e as consultas, usamos a
indexação de tempo , semelhante à
pilha ELK .
Essa arquitetura de índice oferece várias vantagens. Por exemplo, você pode executar uma indexação em massa eficiente, bem como excluir índices inteiros quando os dados estiverem obsoletos. Isso também significa que a carga de trabalho para um determinado índice varia muito com o tempo.
Exponencialmente mais consultas vão para os índices mais recentes, em comparação com os antigos.
 Fig. 1. Esquema de acesso para índices de tempo. O eixo vertical representa o número de consultas concluídas, o eixo horizontal representa a idade do índice. Os platôs semanais, mensais e anuais são claramente visíveis, seguidos por uma longa cauda de menor carga de trabalho nos índices mais antigos
Fig. 1. Esquema de acesso para índices de tempo. O eixo vertical representa o número de consultas concluídas, o eixo horizontal representa a idade do índice. Os platôs semanais, mensais e anuais são claramente visíveis, seguidos por uma longa cauda de menor carga de trabalho nos índices mais antigosOs padrões na fig. 1 eram bastante previsíveis, pois nossos clientes estão mais interessados em novas informações e comparam regularmente o mês atual com o passado e / ou este ano com o ano passado. O problema é que o Elasticsearch não conhece esse padrão e não otimiza automaticamente para a carga de trabalho observada!
O algoritmo de alocação de shards Elasticsearch interno leva em consideração apenas dois fatores:
- O número de shards em cada nó. O algoritmo tenta equilibrar uniformemente o número de shards por nó em todo o cluster.
- Rótulos de espaço livre em disco. O Elasticsearch considera o espaço em disco disponível em um nó antes de decidir se deseja alocar novos shards para esse nó ou mover segmentos desse nó para outros. Com 80% do disco usado, é proibido colocar novos shards em um nó, 90% do sistema começará a transferir ativamente shards desse nó.
A suposição fundamental do algoritmo é que cada segmento no cluster recebe aproximadamente a mesma quantidade de carga de trabalho e que todos têm o mesmo tamanho. No nosso caso, isso está muito longe da verdade.
O balanceamento de carga padrão leva rapidamente a pontos de acesso no cluster. Eles aparecem e desaparecem aleatoriamente, conforme a carga de trabalho muda com o tempo.
Um hot spot é essencialmente um host que opera próximo ao limite de um ou mais recursos do sistema, como CPU, E / S de disco ou largura de banda da rede. Quando isso acontece, o nó primeiro enfileira as solicitações por um tempo, o que aumenta o tempo de resposta à solicitação. Mas se a sobrecarga durar muito tempo, as solicitações serão rejeitadas e os usuários obterão erros.
Outra consequência comum do congestionamento é a pressão instável do lixo da JVM devido a consultas e operações de indexação, o que leva ao fenômeno do "inferno assustador" do coletor de lixo da JVM. Em tal situação, a JVM não consegue obter a memória com rapidez suficiente e fica sem memória ou fica presa em um ciclo interminável de coleta de lixo, congela e para de responder a solicitações e pings do cluster.
O problema piorou quando
refatoramos nossa arquitetura na AWS . Anteriormente, éramos "salvos" pelo fato de termos executado até quatro nós do Elasticsearch em nossos próprios servidores poderosos (24 núcleos) em nosso data center. Isso ocultou a influência da distribuição assimétrica de estilhaços: a carga foi suavizada em grande parte por um número relativamente grande de núcleos na máquina.
Após a refatoração, colocamos apenas um nó de cada vez em máquinas menos potentes (8 núcleos) - e os primeiros testes revelaram imediatamente grandes problemas com os “pontos de acesso”.
O Elasticsearch atribui shards em ordem aleatória e, com mais de 500 nós em um cluster, a probabilidade de muitos shards "quentes" em um único nó aumentou muito - e esses nós transbordaram rapidamente.
Para os usuários, isso significaria uma grave deterioração no trabalho, pois os nós congestionados respondem lentamente e, às vezes, rejeitam completamente as solicitações ou falhas. Se você colocar esse sistema em produção, os usuários verão freqüentes, ao que parece, lentidões aleatórias na interface do usuário e tempos limite aleatórios.
Ao mesmo tempo, permanece um grande número de nós com shards sem muita carga, que são realmente inativos. Isso leva ao uso ineficiente de nossos recursos de cluster.
Ambos os problemas poderiam ser evitados se o Elasticsearch distribuísse os shards de maneira mais inteligente, pois o uso médio dos recursos do sistema em todos os nós está em um nível saudável de 40%.
Alteração contínua de cluster
Ao trabalhar em mais de 500 nós, observamos mais uma coisa: uma constante mudança no estado dos nós. Os fragmentos se movem constantemente para a frente e para trás nos nós, sob a influência dos seguintes fatores:
- Novos índices são criados e antigos são descartados.
- Os rótulos de disco são acionados devido à indexação e outras alterações de fragmento.
- O Elasticsearch decide aleatoriamente que há muito pouco ou muitos shards no nó em comparação com o valor médio do cluster.
- Falhas de hardware e falhas no nível do sistema operacional fazem com que novas instâncias da AWS sejam iniciadas e ingressadas no cluster. Com 500 nós, isso acontece em média várias vezes por semana.
- Novos sites são adicionados quase toda semana devido ao crescimento normal dos dados.
Com tudo isso levado em consideração, chegamos à conclusão de que uma solução complexa e contínua de todos os problemas requer um algoritmo de re-otimização contínuo e dinâmico.
Solução: Shardonnay
Após um longo estudo das opções disponíveis, chegamos à conclusão de que queremos:
- Crie sua própria solução. Não encontramos bons artigos, códigos ou outras idéias existentes que funcionassem bem em nossa escala e para nossas tarefas.
- Inicie o processo de reequilíbrio fora do Elasticsearch e use as APIs de redirecionamento em cluster em vez de tentar criar um plug-in . Queríamos um rápido retorno de feedback, e a implantação de um plug-in em um cluster dessa escala pode levar várias semanas.
- Use a programação linear para calcular os movimentos ideais do fragmento a qualquer momento.
- Execute a otimização continuamente para que o estado do cluster gradualmente chegue ao melhor.
- Não mova muitos fragmentos de cada vez.
Percebemos uma coisa interessante: se você mover muitos fragmentos ao mesmo tempo, é muito fácil desencadear uma
tempestade em cascata de movimento de fragmentos . Após o início de uma tempestade, ela pode continuar por horas, quando os fragmentos se movem incontrolavelmente para frente e para trás, causando o aparecimento de marcas sobre o nível crítico de espaço em disco em vários locais. Por sua vez, isso leva a novos movimentos de fragmentos e assim por diante.
Para entender o que está acontecendo, é importante saber que, quando você move um segmento indexado ativamente, ele começa a usar muito mais espaço no disco do qual está se movendo. Isso se deve à maneira como o Elasticsearch armazena
logs de transações . Vimos casos em que, ao mover um nó, o índice dobrou. Isso significa que o nó que iniciou o movimento do shard devido ao alto uso do espaço em disco usará
ainda mais espaço em disco por um tempo até que ele mova shards suficientes para outros nós.
Para resolver esse problema, desenvolvemos o serviço
Shardonnay em homenagem à famosa casta Chardonnay.
Otimização linear
A otimização linear (ou
programação linear , LP) é um método para obter o melhor resultado, como lucro máximo ou custo mais baixo, em um modelo matemático cujos requisitos são representados por relacionamentos lineares.
O método de otimização é baseado em um sistema de variáveis lineares, em algumas restrições que devem ser atendidas e em uma função objetivo que determina a aparência de uma solução bem-sucedida. O objetivo da otimização linear é encontrar os valores das variáveis que minimizam a função objetivo, sujeitas a restrições.
Distribuição de fragmentos como um problema de otimização linear
Shardonnay deve funcionar continuamente e, a cada iteração, executa o seguinte algoritmo:
- Usando a API, o Elasticsearch recupera informações sobre shards, índices e nós existentes no cluster, bem como sua localização atual.
- Modela o estado de um cluster como um conjunto de variáveis LP binárias. Cada combinação (nó, índice, fragmento, réplica) obtém sua própria variável. No modelo LP, há várias heurísticas cuidadosamente projetadas, restrições e uma função objetiva, mais sobre isso abaixo.
- Envia o modelo de LP para um solucionador linear, que fornece uma solução ideal, levando em consideração as restrições e a função objetivo. A solução é reatribuir shards para nós.
- Interpreta a solução do LP e a converte em uma sequência de movimentos de fragmentos.
- Instrui o Elasticsearch a mover shards pela API de redirecionamento de cluster.
- Aguarda o cluster mover os fragmentos.
- Retorna à etapa 1.
O principal é desenvolver as restrições certas e a função objetiva. O restante será feito pelo Solver LP e Elasticsearch.
Não é de surpreender que a tarefa tenha sido muito difícil para um cluster desse tamanho e complexidade!
Limitações
Baseamos algumas restrições no modelo com base nas regras ditadas pelo próprio Elasticsearch. Por exemplo, sempre mantenha etiquetas de disco ou proíba a colocação de uma réplica no mesmo nó que outra réplica do mesmo fragmento.
Outros são adicionados com base na experiência adquirida ao longo dos anos de trabalho com grandes grupos. Aqui estão alguns exemplos de nossas próprias limitações:
- Não mova os índices atuais, pois eles são os mais quentes e recebem uma carga quase constante de leitura e escrita.
- Dê preferência à movimentação de fragmentos menores, porque o Elasticsearch lida com eles mais rapidamente.
- É aconselhável criar e colocar futuros shards alguns dias antes de se tornarem ativos, começarem a ser indexados e sofrerem uma carga pesada.
Função de custo
Nossa função de custo avalia vários fatores diferentes. Por exemplo, queremos:
- minimizar a variação das consultas de indexação e pesquisa para reduzir o número de "pontos de acesso";
- mantenha a variação mínima do uso do disco para operação estável do sistema;
- minimize o número de movimentos do fragmento para que não ocorram "tempestades" com uma reação em cadeia, como descrito acima.
Redução de variáveis LP
Em nossa escala, o tamanho desses modelos de LP se torna um problema. Logo percebemos que os problemas não podiam ser resolvidos em um tempo razoável com mais de 60 milhões de variáveis. Portanto, aplicamos muitos truques de otimização e modelagem para reduzir drasticamente o número de variáveis. Entre eles estão amostragem tendenciosa, heurísticas, método de dividir e conquistar, relaxamento iterativo e otimização.
 Fig. 2. O mapa de calor mostra a carga desequilibrada no cluster Elasticsearch. Isso se manifesta em uma grande dispersão do uso de recursos no lado esquerdo do gráfico. Através da otimização contínua, a situação está se estabilizando gradualmente
Fig. 2. O mapa de calor mostra a carga desequilibrada no cluster Elasticsearch. Isso se manifesta em uma grande dispersão do uso de recursos no lado esquerdo do gráfico. Através da otimização contínua, a situação está se estabilizando gradualmente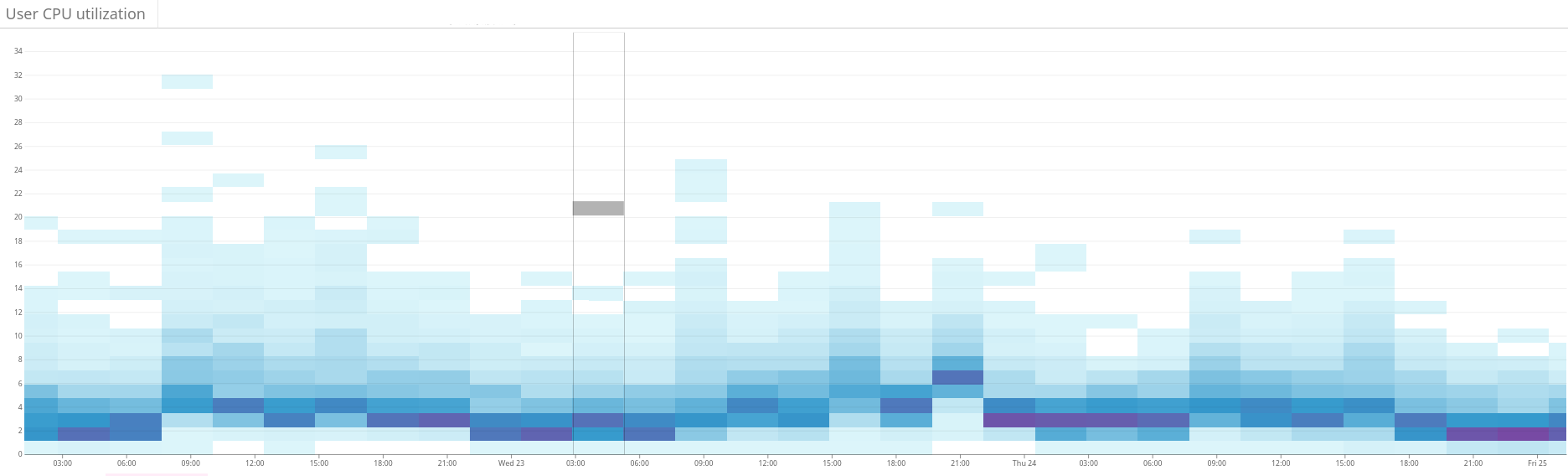 Fig. 3. O mapa de calor mostra o uso da CPU em todos os nós do cluster antes e depois de configurar a função de quente em Shardonnay. Uma mudança significativa no uso da CPU é vista com carga de trabalho constante.
Fig. 3. O mapa de calor mostra o uso da CPU em todos os nós do cluster antes e depois de configurar a função de quente em Shardonnay. Uma mudança significativa no uso da CPU é vista com carga de trabalho constante. Fig. 4. O mapa de calor mostra a taxa de transferência de leitura dos discos durante o mesmo período que na fig. 3. As operações de leitura também são distribuídas de maneira mais uniforme pelo cluster.
Fig. 4. O mapa de calor mostra a taxa de transferência de leitura dos discos durante o mesmo período que na fig. 3. As operações de leitura também são distribuídas de maneira mais uniforme pelo cluster.Resultados
Como resultado, nosso solucionador de LP encontra boas soluções em alguns minutos, mesmo para o nosso enorme cluster. Assim, o sistema melhora iterativamente o estado do cluster na direção da otimização.
E a melhor parte é que a dispersão da carga de trabalho e do uso do disco converge conforme o esperado - e esse estado quase ideal é mantido após muitas alterações intencionais e inesperadas no estado do cluster desde então!
Agora, oferecemos suporte à distribuição de carga de trabalho saudável em nossos clusters do Elasticsearch. Tudo graças à otimização linear e ao nosso serviço, que adoramos chamar de
Chardonnay .