No último post, falei sobre o Kubernetes, como o ThoughtSpot o usa para suas próprias necessidades de suporte ao desenvolvimento. Hoje eu gostaria de continuar a conversa sobre um histórico breve, mas não menos interessante, que ocorreu recentemente. O artigo é baseado no fato de que a conteinerização! = Virtualização. Além disso, é mostrado como os processos em contêineres competem por recursos, mesmo com restrições ideais no cgroup e no alto desempenho da máquina.
Anteriormente, lançamos uma série de operações relacionadas ao desenvolvimento de b CI / CD no cluster interno Kubernetes. Tudo ficaria bem, mas quando você inicia um aplicativo "dockerized", o desempenho diminui drasticamente. Não economizamos: em cada um dos contêineres havia limitações na capacidade de computação e memória (5 CPU / 30 GB RAM) definidas na configuração do Pod. Em uma máquina virtual com esses parâmetros, todas as nossas solicitações de um pequeno conjunto de dados (10 Kb) para testes seriam executadas. No entanto, no Docker & Kubernetes com 72 CPU / 512 GB de RAM, conseguimos lançar 3-4 cópias do produto e, então, os freios começaram. As solicitações que costumavam ser concluídas em alguns milissegundos agora eram interrompidas por 1 a 2 segundos, e isso causava todos os tipos de falhas no pipeline de tarefas de IC. Eu tive que lidar de perto com a depuração.
Como regra, todos os tipos de erros de configuração ao compactar um aplicativo no Docker são suspeitos. No entanto, não encontramos nada que pudesse causar pelo menos algum tipo de lentidão (quando comparado às instalações em hardware simples ou em máquinas virtuais). Tudo parece estar certo. Em seguida, tentamos todos os tipos de testes do pacote Sysbench . Verificamos o desempenho da CPU, disco, memória - tudo era o mesmo que no bare metal. Alguns serviços de nosso produto armazenam informações detalhadas sobre todas as ações: elas podem ser usadas no desempenho do perfil. Como regra, quando há falta de um recurso (CPU, RAM, disco, rede) em algumas chamadas, é observada uma falha significativa no tempo - para descobrirmos exatamente o que diminui e onde. No entanto, nada aconteceu neste caso. As proporções temporais não diferiram da configuração de trabalho - com a única diferença de que cada chamada era muito mais lenta que no bare metal. Nada indicava a fonte real do problema. Estávamos prontos para desistir quando de repente descobrimos isso .
Neste artigo, o autor analisa um caso misterioso semelhante em que dois, em princípio, processos leves se matam quando executados no Docker na mesma máquina, e os limites de recursos foram definidos com valores muito modestos. Fizemos duas conclusões importantes:
- O principal motivo estava no próprio kernel do Linux. Devido à estrutura dos objetos de cache de dentry no kernel, o comportamento de um processo inibiu bastante a chamada para o kernel
__d_lookup_loop , o que afetou diretamente o desempenho de outro. - O autor usou o
perf para detectar erros no kernel. Uma ótima ferramenta de depuração que nunca usamos antes (o que é uma pena!).
perf (às vezes chamado perf_events ou perf tools; anteriormente conhecido como Performance Counters for Linux, PCL) é uma ferramenta de análise de desempenho do Linux disponível no kernel versão 2.6.31. O utilitário de gerenciamento de espaço do usuário, perf, está disponível na linha de comandos e é uma coleção de subcomandos.
Ele realiza a criação de perfil estatístico de todo o sistema (kernel e espaço do usuário). Essa ferramenta suporta contadores de desempenho de plataformas de hardware e software (por exemplo, hrtimer), pontos de rastreio e amostras dinâmicas (por exemplo, kprobes ou uprobes). Em 2012, dois engenheiros da IBM reconheceram o perf (junto com o OProfile) como uma das duas ferramentas de perfil de desempenho mais usadas no Linux.
Então pensamos: talvez tenhamos a mesma coisa? Iniciamos centenas de processos diferentes em contêineres e todos tinham o mesmo núcleo. Sentimos que tínhamos atacado a trilha! Armado com perf , repetimos a depuração e, no final, estávamos esperando por uma descoberta muito interessante.
Abaixo estão as entradas perf dos primeiros 10 segundos do ThoughtSpot em execução em uma máquina saudável (rápida) (esquerda) e dentro do contêiner (direita).
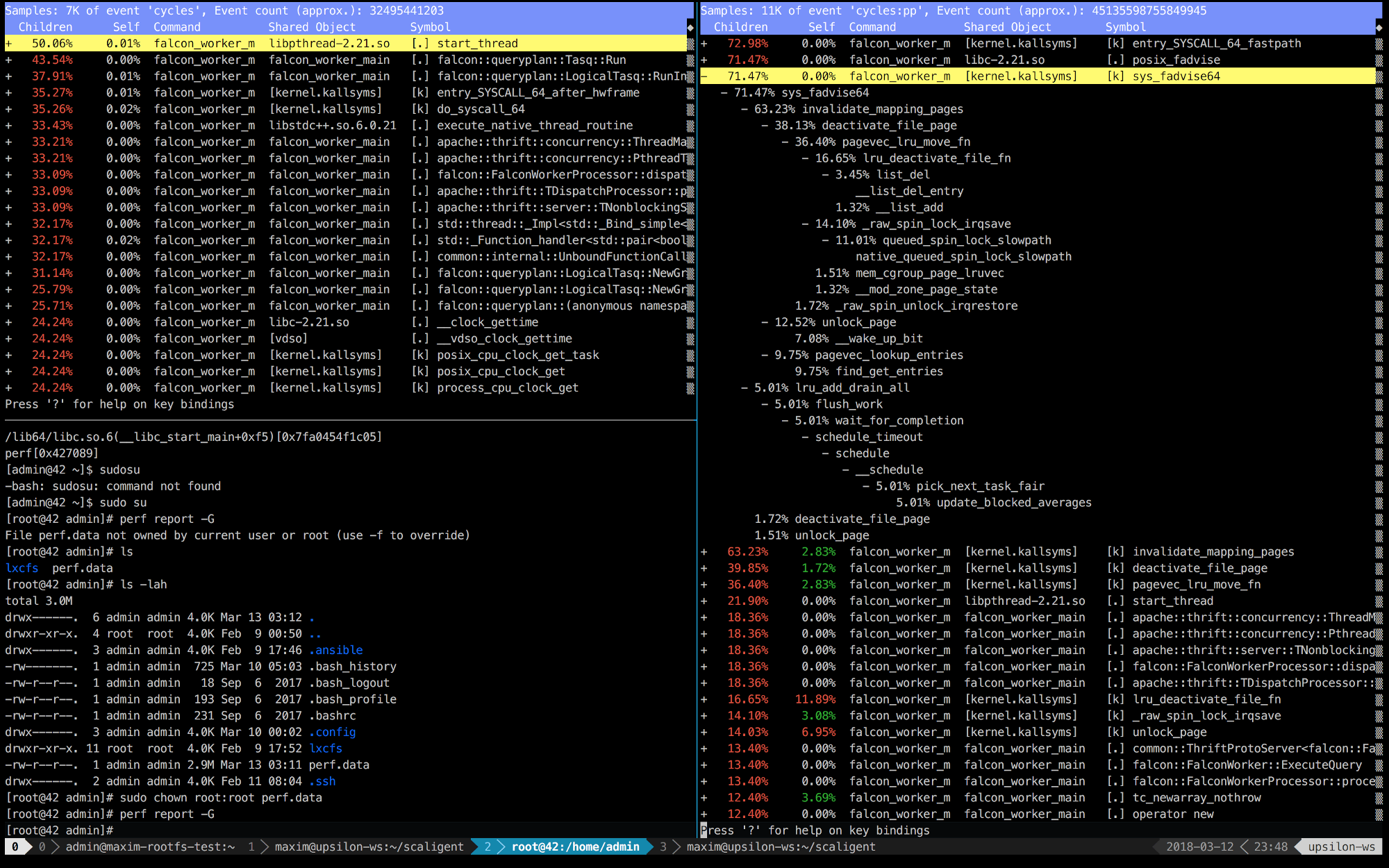
É imediatamente claro que, à direita, as 5 primeiras chamadas estão conectadas ao kernel. O tempo é gasto principalmente no espaço do kernel, enquanto no lado esquerdo - a maior parte do tempo é gasto em nossos próprios processos em execução no espaço do usuário. Mas o mais interessante é que a chamada posix_fadvise leva o tempo todo.
Os programas usam posix_fadvise (), declarando sua intenção de acessar dados do arquivo de acordo com um padrão específico no futuro. Isso dá ao kernel a oportunidade de realizar a otimização necessária.
A chamada é usada para qualquer situação; portanto, não indica explicitamente a origem do problema. No entanto, ao pesquisar o código, encontrei apenas um lugar que, teoricamente, afetava todos os processos do sistema:
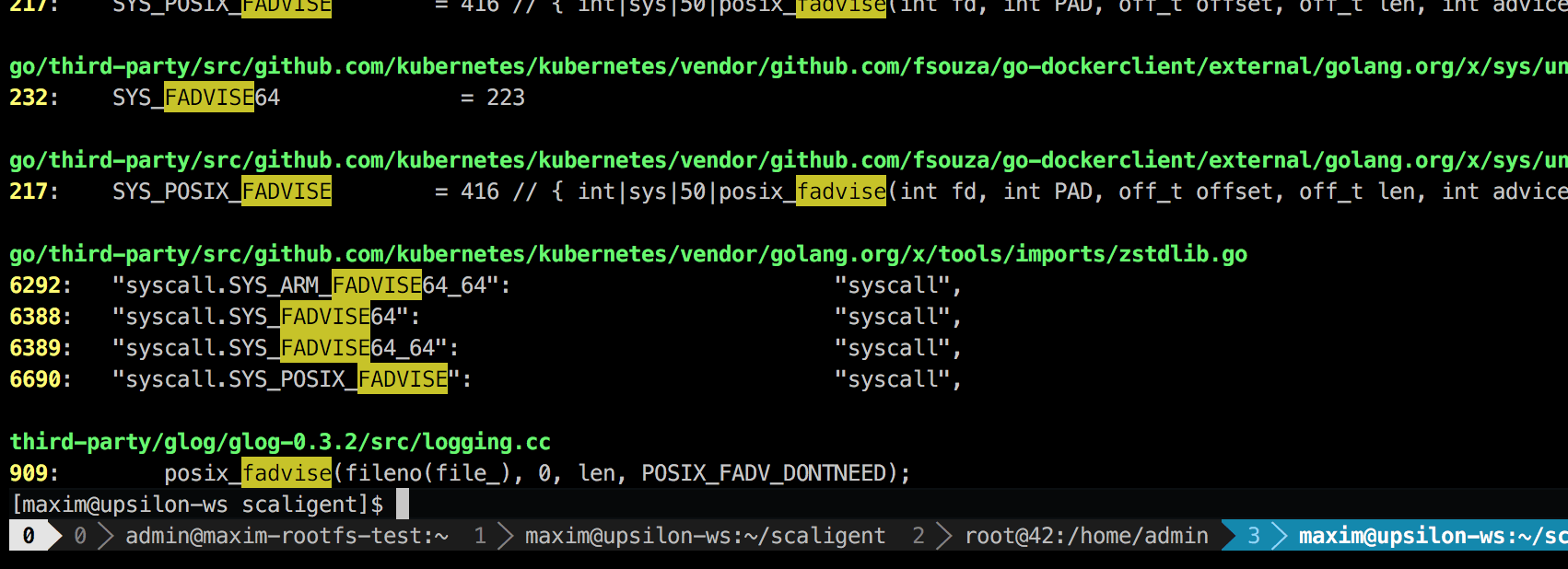
Esta é uma biblioteca de registro de terceiros chamada glog . Nós o usamos no projeto. Especificamente, essa linha (em LogFileObject::Write ) é provavelmente o caminho mais crítico de toda a biblioteca. É chamado para todos os eventos “log para arquivo” (log para arquivo) e para muitas instâncias do nosso produto com bastante frequência. Uma rápida olhada no código fonte sugere que a parte fadvise pode ser desativada configurando o parâmetro --drop_log_memory=false :
if (file_length_ >= logging::kPageSize) {
o que nós, é claro, fizemos e ... no alvo!
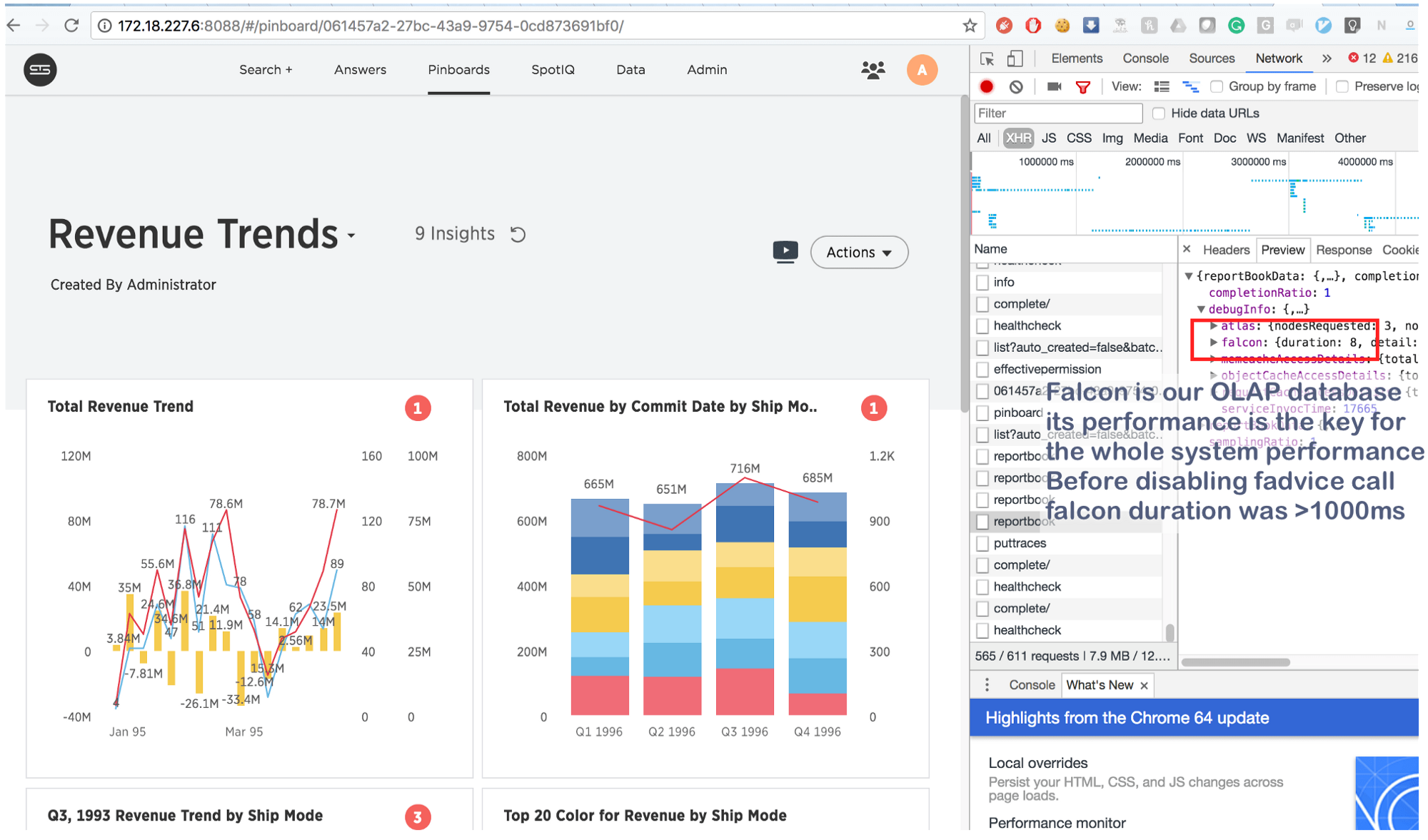
O que costumava levar alguns segundos agora é feito em 8 (oito!) Milissegundos. Pesquisando um pouco, descobrimos o seguinte: https://issues.apache.org/jira/browse/MESOS-920 e também este: https://github.com/google/glog/pull/145 , que mais uma vez confirmou nosso palpite sobre a verdadeira causa da inibição. Provavelmente, o mesmo aconteceu na máquina virtual / bare metal, mas como tínhamos 1 cópia do processo por máquina / kernel, a intensidade da chamada fadvise foi muito menor, o que explicava a falta de consumo adicional de recursos. Aumentando os processos de registro em log em 3-4 vezes e destacando um núcleo comum para eles, vimos que ele realmente parou de funcionar.
E em conclusão:
Essas informações não são novas, mas por algum motivo muitas pessoas esquecem o principal: nos casos com contêineres, processos "isolados" competem por todos os recursos principais , e não apenas por CPU , RAM , espaço em disco e rede . E como o kernel é uma estrutura extremamente complexa, as falhas podem ocorrer em qualquer lugar (como, por exemplo, em __d_lookup_loop , no __d_lookup_loop do Sysdig ). Isso, no entanto, não significa que os contêineres sejam piores ou melhores que a virtualização tradicional. Eles são uma excelente ferramenta que resolve suas tarefas. Lembre-se: o kernel é um recurso compartilhado e prepare-se para depurar conflitos inesperados no espaço do kernel. Além disso, esses conflitos são uma grande oportunidade para os invasores romperem o isolamento "reduzido" e criarem canais ocultos entre os contêineres. E, finalmente, existe o perf - uma excelente ferramenta que mostra o que está acontecendo no sistema e ajuda a depurar qualquer problema de desempenho. Se você planeja executar aplicativos altamente carregados no Docker, não deixe de aprender perf .