Existe uma classe de tarefas tão popular na qual é necessário realizar uma análise suficientemente profunda de todo o volume de cadeias de trabalho registradas por qualquer sistema de informação (SI). Como um IP, pode haver um fluxo de documentos, uma central de atendimento, um rastreador de erros, um diário eletrônico, contabilidade de armazém, etc. As nuances se manifestam em modelos de dados, APIs, volumes de dados e outros aspectos, mas os princípios para resolver esses problemas são aproximadamente os mesmos. E o rake em que você pode pisar também é muito semelhante.
Para resolver essa classe de problemas, R se encaixa perfeitamente. Mas, para não encolher os ombros de maneira decepcionante, R pode ser bom, mas muito lento, é importante prestar atenção ao desempenho dos métodos de processamento de dados selecionados.
É uma continuação de publicações anteriores .
Geralmente, uma abordagem superficial da "testa" não é a mais eficaz. 99% das tarefas associadas à análise e processamento de dados começam com a importação. Neste breve ensaio, consideraremos os problemas que surgem no estágio básico de importação de dados com dados no formato json , usando o exemplo de uma tarefa típica de análise "profunda" dos dados de instalação do Jira. json suporta um modelo de objeto complexo, diferentemente do csv , portanto, analisá-lo no caso de estruturas complexas pode se tornar muito difícil e demorado.
Declaração do problema
Dado:
- O jira é implementado e usado no processo de desenvolvimento de software como um sistema de gerenciamento de tarefas e rastreador de erros.
- Não há acesso direto ao banco de dados jira, a interação é via API REST (isolamento galvânico).
- Os arquivos json a serem obtidos possuem uma estrutura de árvore muito complexa com tuplas aninhadas necessárias para fazer upload de todo o histórico de ações. O cálculo das métricas requer um número relativamente pequeno de parâmetros espalhados por diferentes níveis da hierarquia.
Um exemplo de jira json regular na figura.
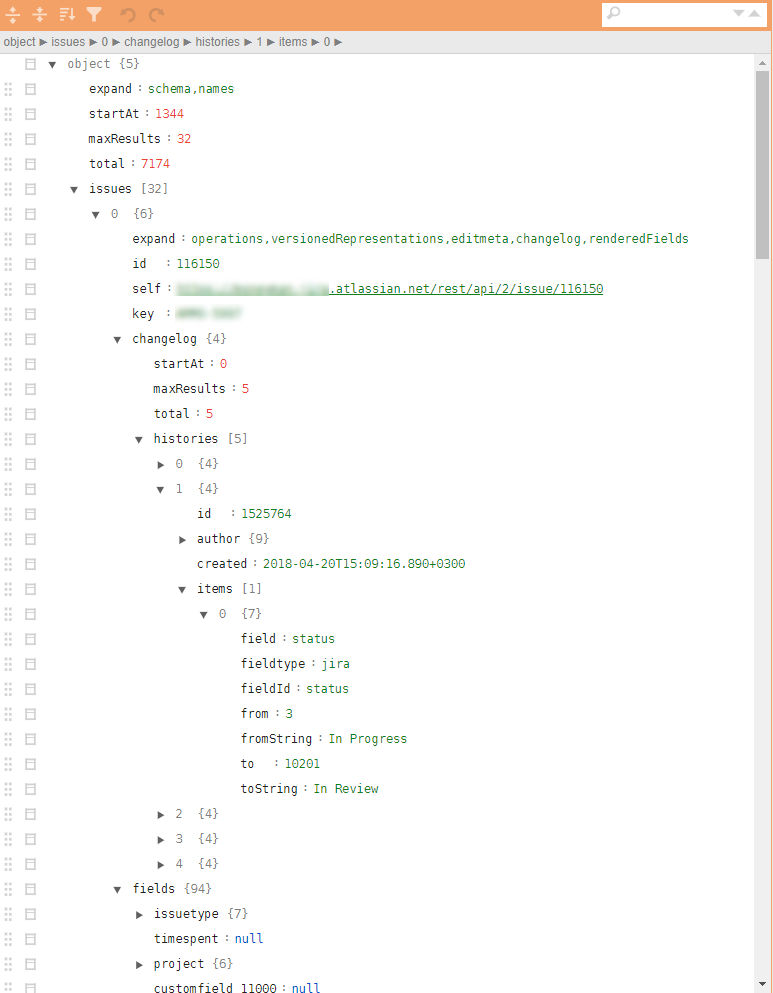
É necessário:
- Com base nos dados do jira, é necessário encontrar gargalos e pontos de um possível aumento na eficiência dos processos de desenvolvimento e melhorar a qualidade do produto resultante com base na análise de todas as ações registradas.
Solução
Teoricamente, existem vários pacotes diferentes no R para carregar o json e convertê-los em data.frame . O pacote mais conveniente é o jsonlite . No entanto, a conversão direta da hierarquia json em data.frame difícil devido ao aninhamento em vários níveis e à forte parametrização da estrutura de registros. A junção de parâmetros específicos relacionados, por exemplo, ao histórico de ações, pode exigir várias extensões. verificações e loops. I.e. o problema pode ser resolvido, mas para um arquivo json de 32 tarefas (inclui todos os artefatos e todo o histórico das tarefas), essa análise não linear usando jsonlite e tidyverse leva aproximadamente 10 segundos em um laptop com desempenho médio.
10 segundos por si só não é muito. Mas exatamente até o momento em que não há muitos desses arquivos. A avaliação em uma amostra analisando e carregando usando um método "direto" semelhante ~ 4000 arquivos (~ 4 GB) deu 8-9 horas de trabalho.
Um número tão grande de arquivos apareceu por um motivo. Em primeiro lugar, jira tem limites de tempo para uma sessão REST, é impossível extrair tudo com uma viga. Em segundo lugar, sendo incorporado ao circuito produtivo, é esperado o upload diário de dados em tarefas atualizadas. Em terceiro lugar, e isso será mencionado abaixo, a tarefa é muito boa para o dimensionamento linear e você precisa pensar em paralelização desde o primeiro passo.
Mesmo 10 a 15 iterações no estágio de análise de dados, identificando o conjunto mínimo necessário de parâmetros, detectando situações excepcionais ou errôneas e desenvolvendo algoritmos de pós-processamento, geram custos na quantidade de 2-3 semanas (apenas o tempo de contagem).
Naturalmente, esse "desempenho" não é adequado para análises operacionais, integradas ao circuito produtivo, e é muito ineficaz na fase inicial da análise de dados e do desenvolvimento do protótipo.
Ignorando todos os detalhes intermediários, volto-me imediatamente à resposta. Lembramos de Donald Knuth, arregaçamos as mangas e começamos a microbenching todas as operações principais, cortando impiedosamente tudo o que é possível.
A solução resultante é reduzida para as 10 linhas a seguir (este é um esqueleto falso, sem o kit para o corpo não funcional subsequente):
library(tidyverse) library(jsonlite) library(readtext) fnames <- fs::dir_ls(here::here("input_data"), glob = "*.txt") ff <- function(fname){ json_vec <- readtext(fname, text_field = "texts", encoding = "UTF-8") %>% .$text %>% jqr::jq('[. | {issues: .issues}[] | .[]', '{id: .id, key: .key, created: .fields.created, type: .fields.issuetype.name, summary: .fields.summary, descr: .fields.description}]') jsonlite::fromJSON(json_vec, flatten = TRUE) } tictoc::tic("Loading with jqr-jsonlite single-threaded technique") issues_df <- fnames %>% purrr::map(ff) %>% data.table::rbindlist(use.names = FALSE) tictoc::toc() system.time({fst::write_fst(issues_df, here::here("data", "issues.fst"))})
O que é interessante aqui?
- Para acelerar o processo de carregamento, é bom usar pacotes especializados com perfil, como
readtext . - O uso do analisador de fluxo
jq permite converter todos os atributos necessários em um idioma funcional, reduzi-lo ao nível do CPP e minimizar a manipulação manual de listas ou listas aninhadas no data.frame . - Um pacote de
bench muito promissor para marcas de micropigmentação apareceu. Ele permite que você estude não apenas o tempo de execução das operações, mas também a manipulação da memória. Não é segredo que você pode perder muito ao copiar dados na memória. - Para grandes quantidades de dados e processamento simples, geralmente é necessário, na decisão final, abandonar o
tidyverse e transferir as peças demoradas para data.table , em particular, as tabelas são mescladas usando data.table . E também todas as transformações no estágio de pós-processamento (incluídas no ciclo através da função ff também são feitas usando ferramentas data.table com a abordagem de alterar dados por referência ou pacotes construídos usando Rcpp , por exemplo, pacote a anytime para trabalhar com datas e horas. - O pacote
fst é muito bom para despejar dados em um arquivo e depois lê-lo. Em particular, leva apenas uma fração de segundo para salvar todas as análises de histórico do jira por 4 anos, e os dados são salvos exatamente como os tipos de dados R, o que é bom para a reutilização subsequente.
Durante a solução, uma abordagem usando o pacote rjson foi rjson . A jsonlite::fromJSON cerca de 2 vezes mais lenta que rjson = rjson::fromJSON(json_vec) , mas foi necessário deixá-lo, porque existem valores NULL nos dados e, no estágio de conversão de NULL para NA nas listas rjson por rjson , perdemos vantagem, e o código fica mais pesado.
Conclusão
- Essa refatoração levou a uma alteração no tempo de processamento de todos os arquivos json no modo de thread único no mesmo laptop de 8 a 9 horas para 10 minutos.
- Adicionar paralelismo da tarefa usando o
foreach praticamente não sobrecarregou o código (+ 5 linhas), mas reduziu o tempo de execução para 5 minutos. - Transferir a solução para um servidor linux fraco (apenas 4 núcleos), mas rodar em um SSD no modo multithread reduziu o tempo de execução para 40 segundos.
- A publicação em um circuito produtivo (20 núcleos, 3 GHz, SSD) reduziu o tempo de execução para 6-8 segundos, o que é mais do que aceitável para tarefas de análise operacional.
No total, permanecendo na estrutura da plataforma R, uma refatoração de código simples conseguiu reduzir o tempo de execução de ~ 9 horas para ~ 9 segundos.
As decisões sobre R podem ser bastante rápidas. Se algo não der certo para você, tente analisá-lo de um ângulo diferente e usar novas técnicas.
Publicação anterior - “Pára-quedas analítico para gerente” .